
datasetId
large_stringlengths 6
116
| author
large_stringlengths 2
42
| last_modified
large_stringdate 2021-04-29 15:34:29
2025-06-06 02:32:15
| downloads
int64 0
3.97M
| likes
int64 0
7.74k
| tags
large listlengths 1
7.92k
| task_categories
large listlengths 0
48
| createdAt
large_stringdate 2022-03-02 23:29:22
2025-06-06 00:34:34
| trending_score
float64 0
40
⌀ | card
large_stringlengths 31
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
MWeste/large_MCQA | MWeste | 2025-06-05T15:08:28Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T15:08:16Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: choices
dtype: string
- name: answer
dtype: string
- name: dataset
dtype: string
- name: topic
dtype: string
splits:
- name: train
num_bytes: 238508989
num_examples: 737439
download_size: 119978441
dataset_size: 238508989
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Cadenza-Labs/apollo-llama3.3-sandbagging-v2-wmdp-mmlu | Cadenza-Labs | 2025-06-05T13:06:41Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T13:06:39Z | null | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: dishonest
dtype: bool
splits:
- name: train
num_bytes: 4854583
num_examples: 932
download_size: 1326342
dataset_size: 4854583
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Cadenza-Labs/apollo-llama3.3-ai-audit-a1-2-reasoning | Cadenza-Labs | 2025-06-05T13:06:31Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T13:06:30Z | null | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: dishonest
dtype: bool
splits:
- name: train
num_bytes: 1525081
num_examples: 50
download_size: 64965
dataset_size: 1525081
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Cadenza-Labs/apollo-llama3.3-ai-audit-a1-2 | Cadenza-Labs | 2025-06-05T13:06:29Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T13:06:27Z | null | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: dishonest
dtype: bool
splits:
- name: train
num_bytes: 1173675
num_examples: 50
download_size: 45658
dataset_size: 1173675
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
amathislab/LEMONADE | amathislab | 2025-06-05T11:50:07Z | 52 | 0 | [
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:10K<n<100K",
"arxiv:2506.01608",
"region:us",
"behavior",
"motion",
"human",
"egocentric",
"language",
"llm",
"vlm",
"esk"
] | [
"question-answering"
] | 2025-04-25T11:52:28Z | null | ---
license: mit
language:
- en
tags:
- behavior
- motion
- human
- egocentric
- language
- llm
- vlm
- esk
size_categories:
- 10K<n<100K
task_categories:
- question-answering
---
# 🍋 EPFL-Smart-Kitchen: Lemonade benchmark

## 📚 Introduction
we introduce Lemonade: **L**anguage models **E**valuation of **MO**tion a**N**d **A**ction-**D**riven **E**nquiries.
Lemonade consists of <span style="color: orange;">36,521</span> closed-ended QA pairs linked to egocentric video clips, categorized in three groups and six subcategories. <span style="color: orange;">18,857</span> QAs focus on behavior understanding, leveraging the rich ground truth behavior annotations of the EPFL-Smart Kitchen to interrogate models about perceived actions <span style="color: tomato;">(Perception)</span> and reason over unseen behaviors <span style="color: tomato;">(Reasoning)</span>. <span style="color: orange;">8,210</span> QAs involve longer video clips, challenging models in summarization <span style="color: gold;">(Summarization)</span> and session-level inference <span style="color: gold;">(Session properties)</span>. The remaining <span style="color: orange;">9,463</span> QAs leverage the 3D pose estimation data to infer hand shapes, joint angles <span style="color: skyblue;">(Physical attributes)</span>, or trajectory velocities <span style="color: skyblue;">(Kinematics)</span> from visual information.
## 💾 Content
The current repository contains all egocentric videos recorded in the EPFL-Smart-Kitchen-30 dataset and the question answer pairs of the Lemonade benchmark. Please refer to the [main GitHub repository](https://github.com/amathislab/EPFL-Smart-Kitchen#) to find the other benchmarks and links to download other modalities of the EPFL-Smart-Kitchen-30 dataset.
### 🗃️ Repository structure
```
Lemonade
├── MCQs
| └── lemonade_benchmark.csv
├── videos
| ├── YH2002_2023_12_04_10_15_23_hololens.mp4
| └── ..
└── README.md
```
`lemonade_benchmark.csv` : Table with the following fields:
**Question** : Question to be answered. </br>
**QID** : Question identifier, an integer from 0 to 30. </br>
**Answers** : A list of possible answers to the question. This can be a multiple-choice set or open-ended responses. </br>
**Correct Answer** : The answer that is deemed correct from the list of provided answers. </br>
**Clip** : A reference to the video clip related to the question. </br>
**Start** : The timestamp (in frames) in the clip where the question context begins. </br>
**End** : The timestamp (in frames) in the clip where the question context ends. </br>
**Category** : The broad topic under which the question falls (Behavior understanding, Long-term understanding or Motion and Biomechanics). </br>
**Subcategory** : A more refined classification within the category (Perception, Reasoning, Summarization, Session properties, Physical attributes, Kinematics). </br>
**Difficulty** : The complexity level of the question (e.g., Easy, Medium, Hard).
`videos` : Folder with all egocentric videos from the EPFL-Smart-Kitchen-30 benchmark. Video names are structured as `[Participant_ID]_[Session_name]_hololens.mp4`.
> We refer the reader to the associated publication for details about data processing and tasks description.
## 📈 Evaluation results

## 🌈 Usage
The evaluation of the benchmark can be done through the following github repository: [https://github.com/amathislab/lmms-eval-lemonade](https://github.com/amathislab/lmms-eval-lemonade)
## 🌟 Citations
Please cite our work!
```
@misc{bonnetto2025epflsmartkitchen,
title={EPFL-Smart-Kitchen-30: Densely annotated cooking dataset with 3D kinematics to challenge video and language models},
author={Andy Bonnetto and Haozhe Qi and Franklin Leong and Matea Tashkovska and Mahdi Rad and Solaiman Shokur and Friedhelm Hummel and Silvestro Micera and Marc Pollefeys and Alexander Mathis},
year={2025},
eprint={2506.01608},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.01608},
}
```
## ❤️ Acknowledgments
Our work was funded by EPFL, Swiss SNF grant (320030-227871), Microsoft Swiss Joint Research Center and a Boehringer Ingelheim Fonds PhD stipend (H.Q.). We are grateful to the Brain Mind Institute for providing funds for hardware and to the Neuro-X Institute for providing funds for services.
|
Jeevesh2009/so101_test | Jeevesh2009 | 2025-06-05T10:32:27Z | 448 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so101",
"tutorial"
] | [
"robotics"
] | 2025-05-26T12:08:55Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so101
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so101",
"total_episodes": 2,
"total_frames": 294,
"total_tasks": 1,
"total_videos": 4,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:2"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.realsense1": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"observation.images.realsense2": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
cmulgy/ArxivCopilot_data | cmulgy | 2025-06-05T10:02:27Z | 858 | 2 | [
"arxiv:2409.04593",
"region:us"
] | [] | 2024-05-21T04:18:24Z | null | ---
title: ArxivCopilot
emoji: 🏢
colorFrom: indigo
colorTo: pink
sdk: gradio
sdk_version: 4.31.0
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
```
@misc{lin2024papercopilotselfevolvingefficient,
title={Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance},
author={Guanyu Lin and Tao Feng and Pengrui Han and Ge Liu and Jiaxuan You},
year={2024},
eprint={2409.04593},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2409.04593},
}
``` |
qiqiuyi6/TravelPlanner_RL_validation_revision_easy_exmaple | qiqiuyi6 | 2025-06-05T09:42:22Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T09:42:15Z | null | ---
dataset_info:
features:
- name: org
dtype: string
- name: dest
dtype: string
- name: days
dtype: int64
- name: visiting_city_number
dtype: int64
- name: date
dtype: string
- name: people_number
dtype: int64
- name: local_constraint
dtype: string
- name: budget
dtype: int64
- name: query
dtype: string
- name: level
dtype: string
- name: reference_information
dtype: string
- name: problem
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 10021267
num_examples: 180
download_size: 3102796
dataset_size: 10021267
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
kozakvoj/so101_test4 | kozakvoj | 2025-06-05T08:55:57Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so101",
"tutorial"
] | [
"robotics"
] | 2025-06-05T08:55:50Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so101
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so101",
"total_episodes": 1,
"total_frames": 580,
"total_tasks": 1,
"total_videos": 1,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:1"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.front": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
SKIML-ICL/legal_qa | SKIML-ICL | 2025-06-05T08:28:29Z | 78 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-25T07:31:34Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: context
dtype: string
- name: answers
sequence: string
- name: source
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: test
num_bytes: 6138202
num_examples: 3816
download_size: 3075435
dataset_size: 6138202
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
ngumus/OWI-english | ngumus | 2025-06-05T08:01:20Z | 23 | 1 | [
"task_categories:text-classification",
"language:en",
"license:mit",
"size_categories:100K<n<1M",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"legal",
"tfidf",
"20newsgroups",
"text-classification",
"cf-weighting",
"openwebindex",
"weak-supervision",
"legal-tech",
"probabilistic-labeling"
] | [
"text-classification"
] | 2025-06-03T14:42:05Z | null | ---
language:
- "en"
pretty_name: "OWI-IT4I Legal Dataset (Annotated with CF-TFIDF and 20News Labels)"
tags:
- legal
- tfidf
- 20newsgroups
- text-classification
- cf-weighting
- openwebindex
- weak-supervision
- legal-tech
- probabilistic-labeling
license: "mit"
task_categories:
- text-classification
---
# **🧾 OWI-IT4I Legal Dataset (Annotated with TFIDF-CF and 20News Labels)**
This dataset contains legal and technical documents derived from the [Open Web Index (OWI)](https://openwebindex.eu/), automatically annotated using a probabilistic CF-TFIDF model trained on the 20 Newsgroups corpus. It is intended for use in legal-tech research, weak supervision tasks, and domain adaptation studies involving text classification or semantic modeling.
---
## **📁 Dataset Structure**
- **Format**: CSV
- **Main Column**:
- text: Raw text of the legal or technical document.
- consensus If all 3 methods agree on class which means assigned label
- **Other Columns**:
Column Description
- predicted_class_hard Final class using hard assignment CF
- confidence_hard Confidence score for that prediction
- initial_class Original class predicted before CF
- initial_confidence Original model confidence before CF
- predicted_class_prob Final class from probabilistic CF
- confidence_prob Confidence from probabilistic CF
- predicted_class_maxcf Final class from max CF weighting
- confidence_maxcf Confidence from max CF
- high_confidence Whether any method had confidence > 0.8
- avg_confidence Average of the 3 confidence scores
- **Label Descriptions**
Consensus Label 20 Newsgroups Label
- 0 alt.atheism
- 1 comp.graphics
- 2 comp.os.ms-windows.misc
- 3 comp.sys.ibm.pc.hardware
- 4 comp.sys.mac.hardware
- 5 comp.windows.x
- 6 misc.forsale
- 7 rec.autos
- 8 rec.motorcycles
- 9 rec.sport.baseball
- 10 rec.sport.hockey
- 11 sci.crypt
- 12 sci.electronics
- 13 sci.med
- 14 sci.space
- 15 soc.religion.christian
- 16 talk.politics.guns
- 17 talk.politics.mideast
- 18 talk.politics.misc
- 19 talk.religion.misc
---
# **🧠 Annotation Methodology**
The annotations were generated using a custom hybrid model that combines **TF-IDF vectorization** with **class-specific feature (CF) weights** derived from the 20 Newsgroups dataset. The selected method, **probabilistic CF weighting**, adjusts TF-IDF scores by class probabilities, producing a context-aware and semantically rich feature representation. The final labels were selected based on highest-confidence predictions across multiple strategies. This approach allows scalable and interpretable weak supervision for large unlabeled corpora.
Here’s how the dataset is annotated based on the code you provided and the chunk-based script:
---
🧾 1. Explanation: How the Dataset is Annotated
The annotation pipeline uses a custom prediction system built which enhances a logistic regression (LR) classifier with Concept Frequency (CF) weighting. The process includes predictions using three different CF-based methods and annotates each text document with rich prediction metadata.
📚 2. TF-IDF Vectorization + CF Weighting
Each document in a chunk is transformed into a TF-IDF vector. Then, CF weights—term importance scores per class—are applied in three different ways:
a. Hard Assignment (predicted_class)
• Predict the class of each document.
• Use the predicted class to apply CF weights to each term.
• Re-classify the document with the new weighted TF-IDF.
b. Probabilistic Weighting (probabilistic)
• Predict class probabilities for each document.
• Apply a weighted average of CF values across classes (based on probabilities).
• Re-classify with this probabilistically weighted input.
c. Max CF (max_cf)
• For each term, apply the maximum CF it has across all classes.
• Use this to reweight the TF-IDF vector and re-classify.
---
🔍 3. Predicting and Analyzing Each Document
Each document is passed through all 3 prediction methods. The result includes:
• Final predicted class and confidence for each method.
• Initial class prediction (before CF weighting).
• Whether the methods agree (consensus).
• Whether any method is confident above a threshold (default: 0.8).
• Average confidence across methods.
---
# **📊 Source & Motivation**
The raw documents are sourced from the **OWI crawl**, with a focus on texts from legal and IT domains. The 20 Newsgroups label schema was adopted because of its broad topical coverage and relevance to both general and technical content. Many OWI entries naturally align with categories such as comp.sys.ibm.pc.hardware, misc.legal, and talk.politics.mideast, enabling effective domain transfer and reuse of pretrained class-specific weights.
---
# **✅ Use Cases**
- Legal-tech classification
- Domain-adaptive learning
- Zero-shot and weakly supervised labeling
- CF-TFIDF and interpretability research
- Legal document triage and thematic clustering
---
# **📜 Citation**
If you use this dataset in your research, please cite the corresponding work (placeholder below):
```
@misc{owi_tfidfcf_2025,
title={OWI-IT4I Legal Dataset Annotated with CF-TFIDF},
author={Nurullah Gümüş},
year={2025},
note={Annotated using a probabilistic TF-IDF+CF method trained on 20 Newsgroups.},
url={https://huggingface.co/datasets/your-username/owi-legal-cf-tfidf}
}
```
---
# **🛠️ License**
MIT
|
khanhdang/info | khanhdang | 2025-06-05T07:09:44Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T07:02:07Z | null | ---
dataset_info:
features:
- name: answer
dtype: string
- name: question
dtype: string
splits:
- name: train
num_bytes: 268545
num_examples: 960
download_size: 32114
dataset_size: 268545
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
TAUR-dev/rg_eval_dataset__arc | TAUR-dev | 2025-06-05T06:51:46Z | 20 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T02:34:02Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: metadata
dtype: string
- name: dataset_source
dtype: string
splits:
- name: train
num_bytes: 162274
num_examples: 60
download_size: 42334
dataset_size: 162274
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
louisbrulenaudet/code-action-sociale-familles | louisbrulenaudet | 2025-06-05T06:45:42Z | 513 | 0 | [
"task_categories:text-generation",
"task_categories:table-question-answering",
"task_categories:summarization",
"task_categories:text-retrieval",
"task_categories:question-answering",
"task_categories:text-classification",
"multilinguality:monolingual",
"source_datasets:original",
"language:fr",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"finetuning",
"legal",
"french law",
"droit français",
"Code de l'action sociale et des familles"
] | [
"text-generation",
"table-question-answering",
"summarization",
"text-retrieval",
"question-answering",
"text-classification"
] | 2024-03-25T18:57:59Z | null | ---
license: apache-2.0
language:
- fr
multilinguality:
- monolingual
tags:
- finetuning
- legal
- french law
- droit français
- Code de l'action sociale et des familles
source_datasets:
- original
pretty_name: Code de l'action sociale et des familles
task_categories:
- text-generation
- table-question-answering
- summarization
- text-retrieval
- question-answering
- text-classification
size_categories:
- 1K<n<10K
---
# Code de l'action sociale et des familles, non-instruct (2025-06-04)
The objective of this project is to provide researchers, professionals and law students with simplified, up-to-date access to all French legal texts, enriched with a wealth of data to facilitate their integration into Community and European projects.
Normally, the data is refreshed daily on all legal codes, and aims to simplify the production of training sets and labeling pipelines for the development of free, open-source language models based on open data accessible to all.
## Concurrent reading of the LegalKit
[<img src="https://raw.githubusercontent.com/louisbrulenaudet/ragoon/main/assets/badge.svg" alt="Built with RAGoon" width="200" height="32"/>](https://github.com/louisbrulenaudet/ragoon)
To use all the legal data published on LegalKit, you can use RAGoon:
```bash
pip3 install ragoon
```
Then, you can load multiple datasets using this code snippet:
```python
# -*- coding: utf-8 -*-
from ragoon import load_datasets
req = [
"louisbrulenaudet/code-artisanat",
"louisbrulenaudet/code-action-sociale-familles",
# ...
]
datasets_list = load_datasets(
req=req,
streaming=False
)
dataset = datasets.concatenate_datasets(
datasets_list
)
```
### Data Structure for Article Information
This section provides a detailed overview of the elements contained within the `item` dictionary. Each key represents a specific attribute of the legal article, with its associated value providing detailed information.
1. **Basic Information**
- `ref` (string): **Reference** - A reference to the article, combining the title_main and the article `number` (e.g., "Code Général des Impôts, art. 123").
- `texte` (string): **Text Content** - The textual content of the article.
- `dateDebut` (string): **Start Date** - The date when the article came into effect.
- `dateFin` (string): **End Date** - The date when the article was terminated or superseded.
- `num` (string): **Article Number** - The number assigned to the article.
- `id` (string): **Article ID** - Unique identifier for the article.
- `cid` (string): **Chronical ID** - Chronical identifier for the article.
- `type` (string): **Type** - The type or classification of the document (e.g., "AUTONOME").
- `etat` (string): **Legal Status** - The current legal status of the article (e.g., "MODIFIE_MORT_NE").
2. **Content and Notes**
- `nota` (string): **Notes** - Additional notes or remarks associated with the article.
- `version_article` (string): **Article Version** - The version number of the article.
- `ordre` (integer): **Order Number** - A numerical value used to sort articles within their parent section.
3. **Additional Metadata**
- `conditionDiffere` (string): **Deferred Condition** - Specific conditions related to collective agreements.
- `infosComplementaires` (string): **Additional Information** - Extra information pertinent to the article.
- `surtitre` (string): **Subtitle** - A subtitle or additional title information related to collective agreements.
- `nature` (string): **Nature** - The nature or category of the document (e.g., "Article").
- `texteHtml` (string): **HTML Content** - The article's content in HTML format.
4. **Versioning and Extensions**
- `dateFinExtension` (string): **End Date of Extension** - The end date if the article has an extension.
- `versionPrecedente` (string): **Previous Version** - Identifier for the previous version of the article.
- `refInjection` (string): **Injection Reference** - Technical reference to identify the date of injection.
- `idTexte` (string): **Text ID** - Identifier for the legal text to which the article belongs.
- `idTechInjection` (string): **Technical Injection ID** - Technical identifier for the injected element.
5. **Origin and Relationships**
- `origine` (string): **Origin** - The origin of the document (e.g., "LEGI").
- `dateDebutExtension` (string): **Start Date of Extension** - The start date if the article has an extension.
- `idEliAlias` (string): **ELI Alias** - Alias for the European Legislation Identifier (ELI).
- `cidTexte` (string): **Text Chronical ID** - Chronical identifier of the text.
6. **Hierarchical Relationships**
- `sectionParentId` (string): **Parent Section ID** - Technical identifier of the parent section.
- `multipleVersions` (boolean): **Multiple Versions** - Indicates if the article has multiple versions.
- `comporteLiensSP` (boolean): **Contains Public Service Links** - Indicates if the article contains links to public services.
- `sectionParentTitre` (string): **Parent Section Title** - Title of the parent section (e.g., "I : Revenu imposable").
- `infosRestructurationBranche` (string): **Branch Restructuring Information** - Information about branch restructuring.
- `idEli` (string): **ELI ID** - European Legislation Identifier (ELI) for the article.
- `sectionParentCid` (string): **Parent Section Chronical ID** - Chronical identifier of the parent section.
7. **Additional Content and History**
- `numeroBo` (string): **Official Bulletin Number** - Number of the official bulletin where the article was published.
- `infosRestructurationBrancheHtml` (string): **Branch Restructuring Information (HTML)** - Branch restructuring information in HTML format.
- `historique` (string): **History** - Historical context or changes specific to collective agreements.
- `infosComplementairesHtml` (string): **Additional Information (HTML)** - Additional information in HTML format.
- `renvoi` (string): **Reference** - References to content within the article (e.g., "(1)").
- `fullSectionsTitre` (string): **Full Section Titles** - Concatenation of all titles in the parent chain.
- `notaHtml` (string): **Notes (HTML)** - Additional notes or remarks in HTML format.
- `inap` (string): **INAP** - A placeholder for INAP-specific information.
## Feedback
If you have any feedback, please reach out at [louisbrulenaudet@icloud.com](mailto:louisbrulenaudet@icloud.com). |
ChavyvAkvar/synthetic-trades-ADA-cleaned_ohlc | ChavyvAkvar | 2025-06-05T06:42:05Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T06:33:06Z | null | ---
dataset_info:
features:
- name: scenario_id
dtype: string
- name: synthetic_ohlc_open
sequence: float64
- name: synthetic_ohlc_high
sequence: float64
- name: synthetic_ohlc_low
sequence: float64
- name: synthetic_ohlc_close
sequence: float64
splits:
- name: train
num_bytes: 13295809456
num_examples: 14426
download_size: 13326248946
dataset_size: 13295809456
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ChavyvAkvar/synthetic-trades-ETH-cleaned_ohlc | ChavyvAkvar | 2025-06-05T05:57:40Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T05:44:02Z | null | ---
dataset_info:
features:
- name: scenario_id
dtype: string
- name: synthetic_ohlc_open
sequence: float64
- name: synthetic_ohlc_high
sequence: float64
- name: synthetic_ohlc_low
sequence: float64
- name: synthetic_ohlc_close
sequence: float64
splits:
- name: train
num_bytes: 20229427544
num_examples: 21949
download_size: 20273558693
dataset_size: 20229427544
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
abhayesian/miserable_roleplay_formatted | abhayesian | 2025-06-05T05:48:53Z | 32 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-03T03:38:27Z | null | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 1434220
num_examples: 1000
download_size: 89589
dataset_size: 1434220
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
igorcouto/cv21-pt-audio-sentence | igorcouto | 2025-06-05T05:19:54Z | 9 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T04:54:58Z | null | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 5973704143.359349
num_examples: 216685
- name: validation
num_bytes: 318475335.30389816
num_examples: 11405
download_size: 6203689221
dataset_size: 6292179478.663247
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
robert-1111/x_dataset_040849 | robert-1111 | 2025-06-05T05:15:33Z | 721 | 0 | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"task_ids:sentiment-analysis",
"task_ids:topic-classification",
"task_ids:named-entity-recognition",
"task_ids:language-modeling",
"task_ids:text-scoring",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"task_ids:extractive-qa",
"task_ids:news-articles-summarization",
"multilinguality:multilingual",
"source_datasets:original",
"license:mit",
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-classification",
"token-classification",
"question-answering",
"summarization",
"text-generation"
] | 2025-01-25T07:10:57Z | null | ---
license: mit
multilinguality:
- multilingual
source_datasets:
- original
task_categories:
- text-classification
- token-classification
- question-answering
- summarization
- text-generation
task_ids:
- sentiment-analysis
- topic-classification
- named-entity-recognition
- language-modeling
- text-scoring
- multi-class-classification
- multi-label-classification
- extractive-qa
- news-articles-summarization
---
# Bittensor Subnet 13 X (Twitter) Dataset
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/bittensor.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/macrocosmos-black.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
## Dataset Description
- **Repository:** robert-1111/x_dataset_040849
- **Subnet:** Bittensor Subnet 13
- **Miner Hotkey:** 5CZw3NP1Uq3jrN3auP83MsRXgUs3eiZpoAMJuYyPpVnHvXY2
### Miner Data Compliance Agreement
In uploading this dataset, I am agreeing to the [Macrocosmos Miner Data Compliance Policy](https://github.com/macrocosm-os/data-universe/blob/add-miner-policy/docs/miner_policy.md).
### Dataset Summary
This dataset is part of the Bittensor Subnet 13 decentralized network, containing preprocessed data from X (formerly Twitter). The data is continuously updated by network miners, providing a real-time stream of tweets for various analytical and machine learning tasks.
For more information about the dataset, please visit the [official repository](https://github.com/macrocosm-os/data-universe).
### Supported Tasks
The versatility of this dataset allows researchers and data scientists to explore various aspects of social media dynamics and develop innovative applications. Users are encouraged to leverage this data creatively for their specific research or business needs.
For example:
- Sentiment Analysis
- Trend Detection
- Content Analysis
- User Behavior Modeling
### Languages
Primary language: Datasets are mostly English, but can be multilingual due to decentralized ways of creation.
## Dataset Structure
### Data Instances
Each instance represents a single tweet with the following fields:
### Data Fields
- `text` (string): The main content of the tweet.
- `label` (string): Sentiment or topic category of the tweet.
- `tweet_hashtags` (list): A list of hashtags used in the tweet. May be empty if no hashtags are present.
- `datetime` (string): The date when the tweet was posted.
- `username_encoded` (string): An encoded version of the username to maintain user privacy.
- `url_encoded` (string): An encoded version of any URLs included in the tweet. May be empty if no URLs are present.
### Data Splits
This dataset is continuously updated and does not have fixed splits. Users should create their own splits based on their requirements and the data's timestamp.
## Dataset Creation
### Source Data
Data is collected from public tweets on X (Twitter), adhering to the platform's terms of service and API usage guidelines.
### Personal and Sensitive Information
All usernames and URLs are encoded to protect user privacy. The dataset does not intentionally include personal or sensitive information.
## Considerations for Using the Data
### Social Impact and Biases
Users should be aware of potential biases inherent in X (Twitter) data, including demographic and content biases. This dataset reflects the content and opinions expressed on X and should not be considered a representative sample of the general population.
### Limitations
- Data quality may vary due to the decentralized nature of collection and preprocessing.
- The dataset may contain noise, spam, or irrelevant content typical of social media platforms.
- Temporal biases may exist due to real-time collection methods.
- The dataset is limited to public tweets and does not include private accounts or direct messages.
- Not all tweets contain hashtags or URLs.
## Additional Information
### Licensing Information
The dataset is released under the MIT license. The use of this dataset is also subject to X Terms of Use.
### Citation Information
If you use this dataset in your research, please cite it as follows:
```
@misc{robert-11112025datauniversex_dataset_040849,
title={The Data Universe Datasets: The finest collection of social media data the web has to offer},
author={robert-1111},
year={2025},
url={https://huggingface.co/datasets/robert-1111/x_dataset_040849},
}
```
### Contributions
To report issues or contribute to the dataset, please contact the miner or use the Bittensor Subnet 13 governance mechanisms.
## Dataset Statistics
[This section is automatically updated]
- **Total Instances:** 2009620
- **Date Range:** 2025-01-02T00:00:00Z to 2025-05-26T00:00:00Z
- **Last Updated:** 2025-06-05T05:15:33Z
### Data Distribution
- Tweets with hashtags: 4.91%
- Tweets without hashtags: 95.09%
### Top 10 Hashtags
For full statistics, please refer to the `stats.json` file in the repository.
| Rank | Topic | Total Count | Percentage |
|------|-------|-------------|-------------|
| 1 | NULL | 1082102 | 91.65% |
| 2 | #riyadh | 16192 | 1.37% |
| 3 | #thameposeriesep9 | 7605 | 0.64% |
| 4 | #smackdown | 4844 | 0.41% |
| 5 | #कबीर_परमेश्वर_निर्वाण_दिवस | 4843 | 0.41% |
| 6 | #tiktok | 4292 | 0.36% |
| 7 | #اجازاااااااات_مرضيه_o58o67ち179 | 3682 | 0.31% |
| 8 | #ad | 3502 | 0.30% |
| 9 | #delhielectionresults | 3476 | 0.29% |
| 10 | #فلك_اااااااالنصابين | 3363 | 0.28% |
## Update History
| Date | New Instances | Total Instances |
|------|---------------|-----------------|
| 2025-01-25T07:10:27Z | 414446 | 414446 |
| 2025-01-25T07:10:56Z | 414446 | 828892 |
| 2025-01-25T07:11:27Z | 414446 | 1243338 |
| 2025-02-18T03:37:50Z | 463345 | 1706683 |
| 2025-06-05T05:15:33Z | 302937 | 2009620 |
|
robert-1111/x_dataset_0405200 | robert-1111 | 2025-06-05T05:12:56Z | 1,147 | 0 | [
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"task_ids:sentiment-analysis",
"task_ids:topic-classification",
"task_ids:named-entity-recognition",
"task_ids:language-modeling",
"task_ids:text-scoring",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"task_ids:extractive-qa",
"task_ids:news-articles-summarization",
"multilinguality:multilingual",
"source_datasets:original",
"license:mit",
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-classification",
"token-classification",
"question-answering",
"summarization",
"text-generation"
] | 2025-01-25T07:09:57Z | null | ---
license: mit
multilinguality:
- multilingual
source_datasets:
- original
task_categories:
- text-classification
- token-classification
- question-answering
- summarization
- text-generation
task_ids:
- sentiment-analysis
- topic-classification
- named-entity-recognition
- language-modeling
- text-scoring
- multi-class-classification
- multi-label-classification
- extractive-qa
- news-articles-summarization
---
# Bittensor Subnet 13 X (Twitter) Dataset
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/bittensor.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/macrocosmos-black.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
## Dataset Description
- **Repository:** robert-1111/x_dataset_0405200
- **Subnet:** Bittensor Subnet 13
- **Miner Hotkey:** 5H9AFS5tcgBKAxV7gg51QR5pAv25tyUUoWX3Eo7h1sfNL1TQ
### Miner Data Compliance Agreement
In uploading this dataset, I am agreeing to the [Macrocosmos Miner Data Compliance Policy](https://github.com/macrocosm-os/data-universe/blob/add-miner-policy/docs/miner_policy.md).
### Dataset Summary
This dataset is part of the Bittensor Subnet 13 decentralized network, containing preprocessed data from X (formerly Twitter). The data is continuously updated by network miners, providing a real-time stream of tweets for various analytical and machine learning tasks.
For more information about the dataset, please visit the [official repository](https://github.com/macrocosm-os/data-universe).
### Supported Tasks
The versatility of this dataset allows researchers and data scientists to explore various aspects of social media dynamics and develop innovative applications. Users are encouraged to leverage this data creatively for their specific research or business needs.
For example:
- Sentiment Analysis
- Trend Detection
- Content Analysis
- User Behavior Modeling
### Languages
Primary language: Datasets are mostly English, but can be multilingual due to decentralized ways of creation.
## Dataset Structure
### Data Instances
Each instance represents a single tweet with the following fields:
### Data Fields
- `text` (string): The main content of the tweet.
- `label` (string): Sentiment or topic category of the tweet.
- `tweet_hashtags` (list): A list of hashtags used in the tweet. May be empty if no hashtags are present.
- `datetime` (string): The date when the tweet was posted.
- `username_encoded` (string): An encoded version of the username to maintain user privacy.
- `url_encoded` (string): An encoded version of any URLs included in the tweet. May be empty if no URLs are present.
### Data Splits
This dataset is continuously updated and does not have fixed splits. Users should create their own splits based on their requirements and the data's timestamp.
## Dataset Creation
### Source Data
Data is collected from public tweets on X (Twitter), adhering to the platform's terms of service and API usage guidelines.
### Personal and Sensitive Information
All usernames and URLs are encoded to protect user privacy. The dataset does not intentionally include personal or sensitive information.
## Considerations for Using the Data
### Social Impact and Biases
Users should be aware of potential biases inherent in X (Twitter) data, including demographic and content biases. This dataset reflects the content and opinions expressed on X and should not be considered a representative sample of the general population.
### Limitations
- Data quality may vary due to the decentralized nature of collection and preprocessing.
- The dataset may contain noise, spam, or irrelevant content typical of social media platforms.
- Temporal biases may exist due to real-time collection methods.
- The dataset is limited to public tweets and does not include private accounts or direct messages.
- Not all tweets contain hashtags or URLs.
## Additional Information
### Licensing Information
The dataset is released under the MIT license. The use of this dataset is also subject to X Terms of Use.
### Citation Information
If you use this dataset in your research, please cite it as follows:
```
@misc{robert-11112025datauniversex_dataset_0405200,
title={The Data Universe Datasets: The finest collection of social media data the web has to offer},
author={robert-1111},
year={2025},
url={https://huggingface.co/datasets/robert-1111/x_dataset_0405200},
}
```
### Contributions
To report issues or contribute to the dataset, please contact the miner or use the Bittensor Subnet 13 governance mechanisms.
## Dataset Statistics
[This section is automatically updated]
- **Total Instances:** 1180728
- **Date Range:** 2025-01-02T00:00:00Z to 2025-05-26T00:00:00Z
- **Last Updated:** 2025-06-05T05:12:56Z
### Data Distribution
- Tweets with hashtags: 8.35%
- Tweets without hashtags: 91.65%
### Top 10 Hashtags
For full statistics, please refer to the `stats.json` file in the repository.
| Rank | Topic | Total Count | Percentage |
|------|-------|-------------|-------------|
| 1 | NULL | 1082102 | 91.65% |
| 2 | #riyadh | 16192 | 1.37% |
| 3 | #thameposeriesep9 | 7605 | 0.64% |
| 4 | #smackdown | 4844 | 0.41% |
| 5 | #कबीर_परमेश्वर_निर्वाण_दिवस | 4843 | 0.41% |
| 6 | #tiktok | 4292 | 0.36% |
| 7 | #اجازاااااااات_مرضيه_o58o67ち179 | 3682 | 0.31% |
| 8 | #ad | 3502 | 0.30% |
| 9 | #delhielectionresults | 3476 | 0.29% |
| 10 | #فلك_اااااااالنصابين | 3363 | 0.28% |
## Update History
| Date | New Instances | Total Instances |
|------|---------------|-----------------|
| 2025-01-25T07:10:27Z | 414446 | 414446 |
| 2025-02-18T03:36:42Z | 463345 | 877791 |
| 2025-06-05T05:12:56Z | 302937 | 1180728 |
|
hazelyan60/github-issues | hazelyan60 | 2025-06-05T04:37:53Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T04:37:45Z | null | ---
dataset_info:
features:
- name: url
dtype: string
- name: repository_url
dtype: string
- name: labels_url
dtype: string
- name: comments_url
dtype: string
- name: events_url
dtype: string
- name: html_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: user
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: user_view_type
dtype: string
- name: site_admin
dtype: bool
- name: labels
list:
- name: id
dtype: int64
- name: node_id
dtype: string
- name: url
dtype: string
- name: name
dtype: string
- name: color
dtype: string
- name: default
dtype: bool
- name: description
dtype: string
- name: state
dtype: string
- name: locked
dtype: bool
- name: assignee
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: user_view_type
dtype: string
- name: site_admin
dtype: bool
- name: assignees
list:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: user_view_type
dtype: string
- name: site_admin
dtype: bool
- name: milestone
struct:
- name: url
dtype: string
- name: html_url
dtype: string
- name: labels_url
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: number
dtype: int64
- name: title
dtype: string
- name: description
dtype: string
- name: creator
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: user_view_type
dtype: string
- name: site_admin
dtype: bool
- name: open_issues
dtype: int64
- name: closed_issues
dtype: int64
- name: state
dtype: string
- name: created_at
dtype: timestamp[s]
- name: updated_at
dtype: timestamp[s]
- name: due_on
dtype: 'null'
- name: closed_at
dtype: 'null'
- name: comments
sequence: string
- name: created_at
dtype: timestamp[s]
- name: updated_at
dtype: timestamp[s]
- name: closed_at
dtype: timestamp[s]
- name: author_association
dtype: string
- name: type
dtype: 'null'
- name: active_lock_reason
dtype: 'null'
- name: sub_issues_summary
struct:
- name: total
dtype: int64
- name: completed
dtype: int64
- name: percent_completed
dtype: int64
- name: body
dtype: string
- name: closed_by
struct:
- name: login
dtype: string
- name: id
dtype: int64
- name: node_id
dtype: string
- name: avatar_url
dtype: string
- name: gravatar_id
dtype: string
- name: url
dtype: string
- name: html_url
dtype: string
- name: followers_url
dtype: string
- name: following_url
dtype: string
- name: gists_url
dtype: string
- name: starred_url
dtype: string
- name: subscriptions_url
dtype: string
- name: organizations_url
dtype: string
- name: repos_url
dtype: string
- name: events_url
dtype: string
- name: received_events_url
dtype: string
- name: type
dtype: string
- name: user_view_type
dtype: string
- name: site_admin
dtype: bool
- name: reactions
struct:
- name: url
dtype: string
- name: total_count
dtype: int64
- name: '+1'
dtype: int64
- name: '-1'
dtype: int64
- name: laugh
dtype: int64
- name: hooray
dtype: int64
- name: confused
dtype: int64
- name: heart
dtype: int64
- name: rocket
dtype: int64
- name: eyes
dtype: int64
- name: timeline_url
dtype: string
- name: performed_via_github_app
dtype: 'null'
- name: state_reason
dtype: string
- name: draft
dtype: bool
- name: pull_request
struct:
- name: url
dtype: string
- name: html_url
dtype: string
- name: diff_url
dtype: string
- name: patch_url
dtype: string
- name: merged_at
dtype: timestamp[s]
- name: is_pull_request
dtype: bool
splits:
- name: train
num_bytes: 34697825
num_examples: 4684
download_size: 9633773
dataset_size: 34697825
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
QuanHoangNgoc/lock_dataset_prc | QuanHoangNgoc | 2025-06-05T03:01:29Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:timeseries",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T02:50:57Z | null | ---
dataset_info:
features:
- name: input_values
sequence: float32
- name: input_length
dtype: int64
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 18795189628.0
num_examples: 15023
- name: dev
num_bytes: 118626900.0
num_examples: 95
download_size: 18886646995
dataset_size: 18913816528.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: dev
path: data/dev-*
---
|
benjamintli/synthetic_text_to_sql_formatted | benjamintli | 2025-06-05T02:29:59Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T02:26:29Z | null | ---
dataset_info:
features:
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 52558692
num_examples: 100000
- name: test
num_bytes: 3061665
num_examples: 5851
download_size: 22881926
dataset_size: 55620357
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
nskwal/rover | nskwal | 2025-06-05T02:22:57Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T02:21:00Z | null | ---
dataset_info:
features:
- name: reasoning
dtype: string
- name: label
dtype: string
- name: summary
dtype: string
- name: claim
dtype: string
- name: evidence
dtype: string
- name: golden_label
dtype: string
splits:
- name: train
num_bytes: 1569029
num_examples: 1029
download_size: 548231
dataset_size: 1569029
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
antoine-444/MNLP_M3_mcqa_dataset | antoine-444 | 2025-06-05T00:27:16Z | 0 | 1 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-05T00:27:08Z | 1 | ---
dataset_info:
features:
- name: dataset
dtype: string
- name: id
dtype: string
- name: question
dtype: string
- name: choices
sequence: string
- name: rationale
dtype: string
- name: answer
dtype: string
- name: subject
dtype: string
splits:
- name: train
num_bytes: 96584598
num_examples: 187660
- name: test
num_bytes: 3198004
num_examples: 7750
- name: validation
num_bytes: 1248321
num_examples: 2691
download_size: 51566324
dataset_size: 101030923
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
---
|
matthewchung74/nflx-1_0y-5min-bars | matthewchung74 | 2025-06-04T23:59:25Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T23:59:21Z | null | ---
dataset_info:
features:
- name: symbol
dtype: string
- name: timestamp
dtype: string
- name: open
dtype: float64
- name: high
dtype: float64
- name: low
dtype: float64
- name: close
dtype: float64
- name: volume
dtype: float64
- name: trade_count
dtype: float64
- name: vwap
dtype: float64
configs:
- config_name: default
data_files:
- split: train
path: data/nflx_1_0_years_5min.csv
download_size: 1708812
dataset_size: 19755
---
# NFLX 5-Minute Stock Data (1.0 Years)
This dataset contains 1.0 years of NFLX stock market data downloaded from Alpaca Markets.
## Dataset Description
- **Symbol**: NFLX
- **Duration**: 1.0 years
- **Timeframe**: 5-minute bars
- **Market Hours**: 9:30 AM - 4:00 PM EST only
- **Data Source**: Alpaca Markets API
- **Last Updated**: 2025-06-04
## Features
- `symbol`: Stock symbol (always "NFLX")
- `timestamp`: Timestamp in Eastern Time (EST/EDT)
- `open`: Opening price for the 5-minute period
- `high`: Highest price during the 5-minute period
- `low`: Lowest price during the 5-minute period
- `close`: Closing price for the 5-minute period
- `volume`: Number of shares traded
- `trade_count`: Number of individual trades
- `vwap`: Volume Weighted Average Price
## Data Quality
- Only includes data during regular market hours (9:30 AM - 4:00 PM EST)
- Excludes weekends and holidays when markets are closed
- Approximately 19,755 records covering ~1.0 years of trading data
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("matthewchung74/nflx-1_0y-5min-bars")
df = dataset['train'].to_pandas()
```
## Price Statistics
- **Price Range**: $587.04 - $1242.56
- **Average Volume**: 44,956
- **Date Range**: 2024-06-04 09:30:00-04:00 to 2025-06-04 16:00:00-04:00
## License
This dataset is provided under the MIT license. The underlying market data is sourced from Alpaca Markets.
|
cfahlgren1/hub-stats | cfahlgren1 | 2025-06-04T23:34:52Z | 2,408 | 47 | [
"license:apache-2.0",
"modality:image",
"region:us"
] | [] | 2024-07-24T18:20:02Z | null | ---
license: apache-2.0
configs:
- config_name: models
data_files: "models.parquet"
- config_name: datasets
data_files: "datasets.parquet"
- config_name: spaces
data_files: "spaces.parquet"
- config_name: posts
data_files: "posts.parquet"
- config_name: papers
data_files: "daily_papers.parquet"
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/648a374f00f7a3374ee64b99/QoLLMgnFmeGqUTA5Bkgjw.png" width=800/>
**NEW** Changes Feb 27th
- Added new fields on the `models` split: `downloadsAllTime`, `safetensors`, `gguf`
- Added new field on the `datasets` split: `downloadsAllTime`
- Added new split: `papers` which is all of the [Daily Papers](https://huggingface.co/papers)
**Updated Daily** |
VisualSphinx/VisualSphinx-V1-RL-20K | VisualSphinx | 2025-06-04T23:34:24Z | 195 | 1 | [
"task_categories:image-text-to-text",
"task_categories:visual-question-answering",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2505.23977",
"region:us"
] | [
"image-text-to-text",
"visual-question-answering"
] | 2025-05-12T21:28:45Z | 1 | ---
language:
- en
license: cc-by-nc-4.0
task_categories:
- image-text-to-text
- visual-question-answering
dataset_info:
features:
- name: id
dtype: string
- name: images
sequence: image
- name: problem
dtype: string
- name: choice
dtype: string
- name: answer
dtype: string
- name: explanation
dtype: string
- name: has_duplicate
dtype: bool
- name: reasonableness
dtype: int32
- name: readability
dtype: int32
- name: accuracy
dtype: float32
splits:
- name: train
num_bytes: 1192196287
num_examples: 20000
download_size: 1184324044
dataset_size: 1192196287
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# 🦁 VisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL
VisualSphinx is the largest fully-synthetic open-source dataset providing vision logic puzzles. It consists of over **660K** automatically generated logical visual puzzles. Each logical puzzle is grounded with an interpretable rule and accompanied by both correct answers and plausible distractors.
- 🌐 [Project Website](https://visualsphinx.github.io/) - Learn more about VisualSphinx
- 📖 [Technical Report](https://arxiv.org/abs/2505.23977) - Discover the methodology and technical details behind VisualSphinx
- 🔧 [Github Repo](https://github.com/VisualSphinx/VisualSphinx) - Access the complete pipeline used to produce VisualSphinx-V1
- 🤗 HF Datasets:
- [VisualSphinx-V1 (Raw)](https://huggingface.co/datasets/VisualSphinx/VisualSphinx-V1-Raw);
- [VisualSphinx-V1 (For RL)](https://huggingface.co/datasets/VisualSphinx/VisualSphinx-V1-RL-20K); [📍| You are here!]
- [VisualSphinx-V1 (Benchmark)](https://huggingface.co/datasets/VisualSphinx/VisualSphinx-V1-Benchmark);
- [VisualSphinx (Seeds)](https://huggingface.co/datasets/VisualSphinx/VisualSphinx-Seeds);
- [VisualSphinx (Rules)](https://huggingface.co/datasets/VisualSphinx/VisualSphinx-V1-Rules).
## 📊 Dataset Details
### 🎯 Purpose
This dataset is **specifically curated for reinforcement learning (RL) applications**, containing 20K high-quality visual logic puzzles optimized for RL. It represents a carefully filtered and balanced subset from the VisualSphinx-V1-Raw collection.
### 📈 Dataset Splits
- **`train`**: Contains 20K visual logic puzzles optimized for RL training scenarios
### 🏗️ Dataset Structure
Each puzzle in the dataset contains the following fields:
| Field | Type | Description |
|-------|------|-------------|
| `id` | `string` | Unique identifier for each puzzle (format: number_variant) |
| `images` | `List[Image]` | Visual puzzle image with geometric patterns and logical relationships |
| `problem` | `string` | Standardized puzzle prompt for pattern completion |
| `choice` | `string` | JSON-formatted multiple choice options (4-10 options: A-J) |
| `answer` | `string` | Correct answer choice |
| `explanation` | `List[string]` | Detailed rule-based explanations for logical reasoning |
| `has_duplicate` | `bool` | Flag indicating if this puzzle has duplicate images in puzzle itself |
| `reasonableness` | `int32` | Logical coherence score (3-5 scale, filtered for quality) |
| `readability` | `int32` | Visual clarity score (3-5 scale, filtered for quality) |
| `accuracy` | `float32` | Pass rate |
### 📏 Dataset Statistics
- **Total Examples**: 20,000 carefully curated puzzles
- **Quality Filtering**: High-quality subset with reasonableness + readability ≥ 8
- **Complexity Range**: Variable choice counts (4-10 options) for diverse difficulty levels
- **RL Optimization**: Balanced difficulty distribution and no duplicates
- **Answer Distribution**: Balanced across all available choice options
## ✨ Performance on Our Benchmarks
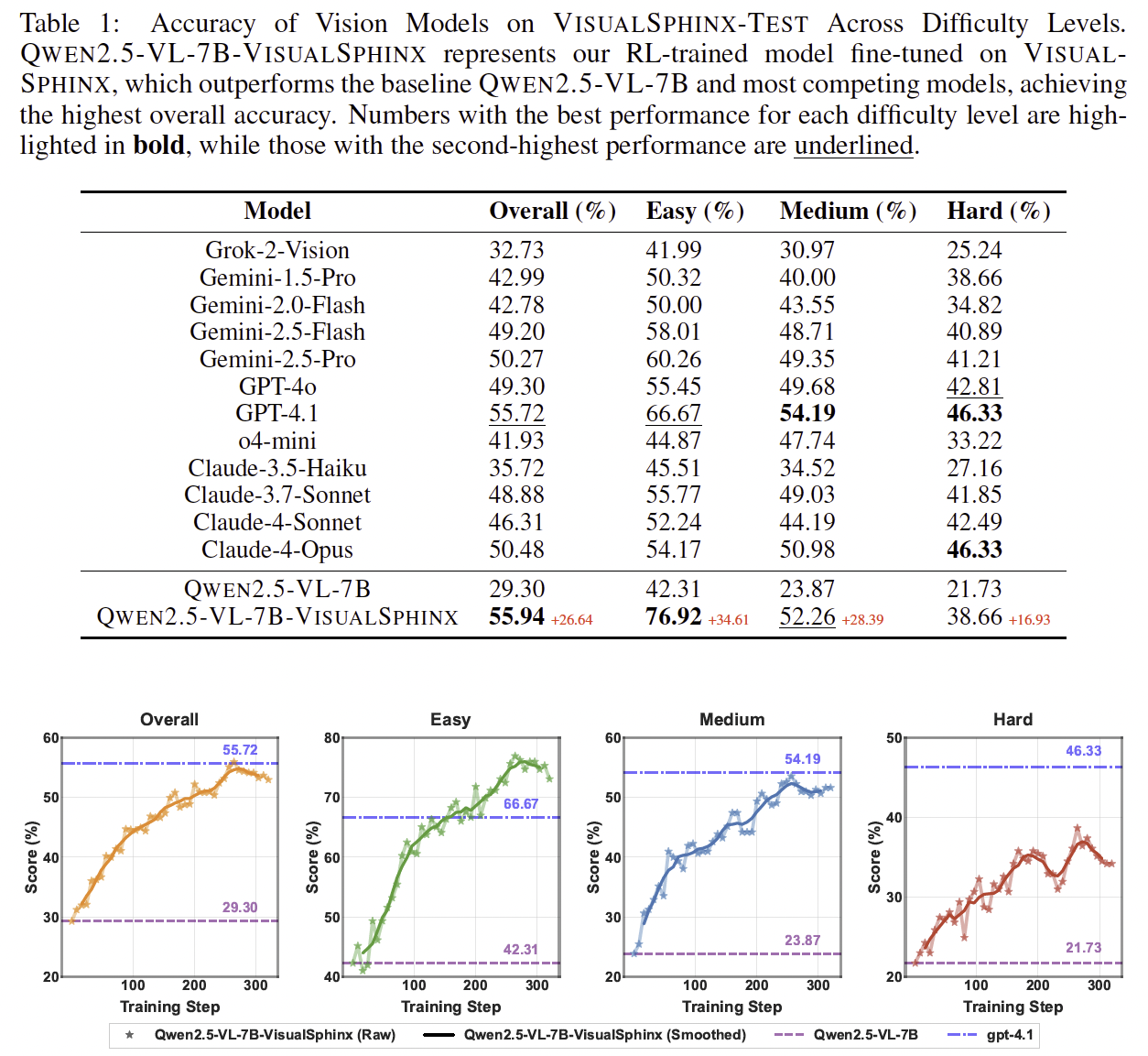
## 🔧 Other Information
**License**: Please follow [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/deed.en).
**Contact**: Please contact [Yichen](mailto:yfeng42@uw.edu) by email.
## 📚 Citation
If you find the data or code useful, please cite:
```
@misc{feng2025visualsphinx,
title={VisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL},
author={Yichen Feng and Zhangchen Xu and Fengqing Jiang and Yuetai Li and Bhaskar Ramasubramanian and Luyao Niu and Bill Yuchen Lin and Radha Poovendran},
year={2025},
eprint={2505.23977},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.23977},
} |
Aravindh25/trossen_pick_high_bin_clothes_3cam_V0000001 | Aravindh25 | 2025-06-04T23:14:48Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"tutorial"
] | [
"robotics"
] | 2025-06-04T23:12:54Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "trossen_ai_stationary",
"total_episodes": 3,
"total_frames": 5135,
"total_tasks": 1,
"total_videos": 9,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 20,
"splits": {
"train": "0:3"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
14
],
"names": [
"left_joint_0",
"left_joint_1",
"left_joint_2",
"left_joint_3",
"left_joint_4",
"left_joint_5",
"left_joint_6",
"right_joint_0",
"right_joint_1",
"right_joint_2",
"right_joint_3",
"right_joint_4",
"right_joint_5",
"right_joint_6"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
14
],
"names": [
"left_joint_0",
"left_joint_1",
"left_joint_2",
"left_joint_3",
"left_joint_4",
"left_joint_5",
"left_joint_6",
"right_joint_0",
"right_joint_1",
"right_joint_2",
"right_joint_3",
"right_joint_4",
"right_joint_5",
"right_joint_6"
]
},
"observation.images.cam_high": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 20.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.cam_left_wrist": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 20.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.cam_right_wrist": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 20.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
oneilsh/lda_pasc | oneilsh | 2025-06-04T22:19:56Z | 0 | 0 | [
"license:cc-by-4.0",
"size_categories:10M<n<100M",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T19:42:10Z | null | ---
license: cc-by-4.0
pretty_name: >-
Topic model data from Finding Long-COVID: temporal topic modeling of
electronic health records from the N3C and RECOVER programs
---
<span style="color: darkred">*Note: very small numbers are rounded to 0 in the HuggingFace dataset viewer.*</span>
These data represent medical concept probabilities for 300 topics generated via Latent Direchlet Allocation applied
to 387M electronic health record conditions for 7.9M patients as described in
[Finding Long-COVID: temporal topic modeling of electronic health records from the N3C and RECOVER programs
](https://www.nature.com/articles/s41746-024-01286-3#Sec7).
*Data were quality filtered and cleaned prior to modeling, including removal of COVID-19 and MIS-C as confounders (see publication).*
Topic `T-23` was most strongly associated with Long-COVID across all demographics.
**If you use these data please cite the publication above.**
Terms are encoded as OMOP CDM standard `concept_id` values;
see details at [OHDSI](https://ohdsi.org/) and [OHDSI ATHENA](https://athena.ohdsi.org).
Columns:
- `topic_name`: topics are named T-1 to T-300, in order of weighted usage; also included in topic name are `U` (aggregate usage of topic in data), `H` (a measure of topic usage uniformity across data contributing sites), and `C` (a z-score normalized coherence value indicating relative topic quality)
- `concept_name`: human-readable name of the OMOP CDM concept
- `concept_id`: OMOP CDM standard concept ID
- `term_weight`: the probability of the `concept_id` being generated by the topic `topic_name`
- `relevance`: A measure of topic-relative weight - positive values indicate concepts more highly weighted in the topic than over all data, negative values less.
|
Simsonsun/JailbreakPrompts | Simsonsun | 2025-06-04T20:11:30Z | 0 | 0 | [
"language:en",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"Jailbreak",
"PromptInjection",
"RedTeaming",
"JailbreakingPrompts",
"ChatGPT"
] | [] | 2025-06-04T19:59:06Z | null | ---
license: mit
language:
- en
tags:
- Jailbreak
- PromptInjection
- RedTeaming
- JailbreakingPrompts
- ChatGPT
pretty_name: Jailbreaking prompts
---
Independent test datasets constructed for the thesis "Contamination Effects: How Training Data Leakage Affects Red Team Evaluation of LLM Jailbreak Detection" |
Suzana/NER_financial_user_assistant | Suzana | 2025-06-04T20:08:30Z | 0 | 0 | [
"task_categories:token-classification",
"language:en",
"license:mit",
"size_categories:n<1K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"NER"
] | [
"token-classification"
] | 2025-06-04T20:05:38Z | null | ---
license: mit
task_categories:
- token-classification
language:
- en
tags:
- NER
size_categories:
- n<1K
source:
- for NER labels; subset of https://huggingface.co/datasets/Josephgflowers/Finance-Instruct-500k
--- |
shanchen/aime_2025_multilingual | shanchen | 2025-06-04T19:59:30Z | 1,619 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2505.22888",
"region:us"
] | [] | 2025-02-24T23:33:43Z | null | ---
dataset_info:
features:
- name: id
dtype: int64
- name: problem
dtype: string
- name: answer
dtype: string
- name: solution
dtype: string
- name: url
dtype: string
- name: year
dtype: int64
- name: __index_level_0__
dtype: int64
splits:
- name: en
num_bytes: 17407
num_examples: 30
- name: ja
num_bytes: 18780
num_examples: 30
- name: zh
num_bytes: 15019
num_examples: 30
- name: ru
num_bytes: 22147
num_examples: 30
- name: es
num_bytes: 18343
num_examples: 30
- name: fr
num_bytes: 16306
num_examples: 30
- name: de
num_bytes: 16304
num_examples: 30
- name: sw
num_bytes: 15688
num_examples: 30
- name: bn
num_bytes: 32004
num_examples: 30
- name: te
num_bytes: 31701
num_examples: 30
- name: th
num_bytes: 28237
num_examples: 30
download_size: 161734
dataset_size: 231936
configs:
- config_name: default
data_files:
- split: en
path: data/en-*
- split: ja
path: data/ja-*
- split: zh
path: data/zh-*
- split: ru
path: data/ru-*
- split: es
path: data/es-*
- split: fr
path: data/fr-*
- split: de
path: data/de-*
- split: sw
path: data/sw-*
- split: bn
path: data/bn-*
- split: te
path: data/te-*
- split: th
path: data/th-*
---
When Models Reason in Your Language: Controlling Thinking Trace Language Comes at the Cost of Accuracy
https://arxiv.org/abs/2505.22888
Jirui Qi, Shan Chen, Zidi Xiong, Raquel Fernández, Danielle S. Bitterman, Arianna Bisazza
Recent Large Reasoning Models (LRMs) with thinking traces have shown strong performance on English reasoning tasks. However, their ability to think in other languages is less studied. This capability is as important as answer accuracy for real world applications because users may find the reasoning trace useful for oversight only when it is expressed in their own language. We comprehensively evaluate two leading families of LRMs on our XReasoning benchmark and find that even the most advanced models often revert to English or produce fragmented reasoning in other languages, revealing a substantial gap in multilingual reasoning. Prompt based interventions that force models to reason in the users language improve readability and oversight but reduce answer accuracy, exposing an important trade off. We further show that targeted post training on just 100 examples mitigates this mismatch, though some accuracy loss remains. Our results highlight the limited multilingual reasoning capabilities of current LRMs and outline directions for future work. Code and data are available at this https URL.
Please cite if you find the data helpful:
```
@misc{qi2025modelsreasonlanguagecontrolling,
title={When Models Reason in Your Language: Controlling Thinking Trace Language Comes at the Cost of Accuracy},
author={Jirui Qi and Shan Chen and Zidi Xiong and Raquel Fernández and Danielle S. Bitterman and Arianna Bisazza},
year={2025},
eprint={2505.22888},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.22888},
}
``` |
automated-analytics/gretel-pii-masking-en-v1-ner | automated-analytics | 2025-06-04T19:27:58Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T19:20:56Z | null | ---
dataset_info:
features:
- name: source_text
dtype: string
- name: target_text
dtype: string
- name: entities
list:
- name: entity
dtype: string
- name: category
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-medical_record_number
'2': I-medical_record_number
'3': B-date_of_birth
'4': I-date_of_birth
'5': B-ssn
'6': I-ssn
'7': B-date
'8': I-date
'9': B-first_name
'10': I-first_name
'11': B-email
'12': I-email
'13': B-last_name
'14': I-last_name
'15': B-customer_id
'16': I-customer_id
'17': B-employee_id
'18': I-employee_id
'19': B-name
'20': I-name
'21': B-street_address
'22': I-street_address
'23': B-phone_number
'24': I-phone_number
'25': B-ipv4
'26': I-ipv4
'27': B-credit_card_number
'28': I-credit_card_number
'29': B-license_plate
'30': I-license_plate
'31': B-address
'32': I-address
'33': B-user_name
'34': I-user_name
'35': B-device_identifier
'36': I-device_identifier
'37': B-bank_routing_number
'38': I-bank_routing_number
'39': B-date_time
'40': I-date_time
'41': B-company_name
'42': I-company_name
'43': B-unique_identifier
'44': I-unique_identifier
'45': B-biometric_identifier
'46': I-biometric_identifier
'47': B-account_number
'48': I-account_number
'49': B-city
'50': I-city
'51': B-certificate_license_number
'52': I-certificate_license_number
'53': B-time
'54': I-time
'55': B-postcode
'56': I-postcode
'57': B-vehicle_identifier
'58': I-vehicle_identifier
'59': B-coordinate
'60': I-coordinate
'61': B-country
'62': I-country
'63': B-api_key
'64': I-api_key
'65': B-ipv6
'66': I-ipv6
'67': B-password
'68': I-password
'69': B-health_plan_beneficiary_number
'70': I-health_plan_beneficiary_number
'71': B-national_id
'72': I-national_id
'73': B-tax_id
'74': I-tax_id
'75': B-url
'76': I-url
'77': B-state
'78': I-state
'79': B-swift_bic
'80': I-swift_bic
'81': B-cvv
'82': I-cvv
'83': B-pin
'84': I-pin
splits:
- name: train
num_bytes: 72231616
num_examples: 50000
- name: validation
num_bytes: 7185881
num_examples: 5000
- name: test
num_bytes: 7224032
num_examples: 5000
download_size: 30904311
dataset_size: 86641529
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
automated-analytics/ai4privacy-pii-masking-en-v1-ner | automated-analytics | 2025-06-04T18:56:31Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T18:56:20Z | null | ---
dataset_info:
features:
- name: source_text
dtype: string
- name: target_text
dtype: string
- name: entities
list:
- name: entity
dtype: string
- name: category
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-medical_record_number
'2': I-medical_record_number
'3': B-date_of_birth
'4': I-date_of_birth
'5': B-ssn
'6': I-ssn
'7': B-date
'8': I-date
'9': B-first_name
'10': I-first_name
'11': B-email
'12': I-email
'13': B-last_name
'14': I-last_name
'15': B-customer_id
'16': I-customer_id
'17': B-employee_id
'18': I-employee_id
'19': B-name
'20': I-name
'21': B-street_address
'22': I-street_address
'23': B-phone_number
'24': I-phone_number
'25': B-ipv4
'26': I-ipv4
'27': B-credit_card_number
'28': I-credit_card_number
'29': B-license_plate
'30': I-license_plate
'31': B-address
'32': I-address
'33': B-user_name
'34': I-user_name
'35': B-device_identifier
'36': I-device_identifier
'37': B-bank_routing_number
'38': I-bank_routing_number
'39': B-date_time
'40': I-date_time
'41': B-company_name
'42': I-company_name
'43': B-unique_identifier
'44': I-unique_identifier
'45': B-biometric_identifier
'46': I-biometric_identifier
'47': B-account_number
'48': I-account_number
'49': B-city
'50': I-city
'51': B-certificate_license_number
'52': I-certificate_license_number
'53': B-time
'54': I-time
'55': B-postcode
'56': I-postcode
'57': B-vehicle_identifier
'58': I-vehicle_identifier
'59': B-coordinate
'60': I-coordinate
'61': B-country
'62': I-country
'63': B-api_key
'64': I-api_key
'65': B-ipv6
'66': I-ipv6
'67': B-password
'68': I-password
'69': B-health_plan_beneficiary_number
'70': I-health_plan_beneficiary_number
'71': B-national_id
'72': I-national_id
'73': B-tax_id
'74': I-tax_id
'75': B-url
'76': I-url
'77': B-state
'78': I-state
'79': B-swift_bic
'80': I-swift_bic
'81': B-cvv
'82': I-cvv
'83': B-pin
'84': I-pin
splits:
- name: train
num_bytes: 61529999
num_examples: 68275
- name: validation
num_bytes: 15380998
num_examples: 17046
download_size: 27101158
dataset_size: 76910997
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
anirudhb11/star-graph-deg-12-path-3-nodes-300 | anirudhb11 | 2025-06-04T18:15:24Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T18:15:20Z | null | ---
dataset_info:
features:
- name: graph
dtype: string
- name: source
dtype: string
- name: destination
dtype: string
- name: path
dtype: string
splits:
- name: train
num_bytes: 40915619
num_examples: 200000
- name: test
num_bytes: 4091831
num_examples: 20000
download_size: 29477161
dataset_size: 45007450
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
erdem-erdem/24-puzzle-game-8k-multisol | erdem-erdem | 2025-06-04T17:40:47Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T17:40:43Z | null | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 7223678
num_examples: 7688
download_size: 2751178
dataset_size: 7223678
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "24-puzzle-game-8k-multisol"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
tsilva/GymnasiumRecording__VizdoomDeathmatch_v0 | tsilva | 2025-06-04T17:28:49Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T17:08:01Z | null | ---
dataset_info:
features:
- name: episode_id
dtype: int64
- name: image
dtype: image
- name: step
dtype: int64
- name: action
struct:
- name: binary
sequence: int64
- name: continuous
sequence: float64
splits:
- name: train
num_bytes: 66980919.0
num_examples: 2277
download_size: 87602123
dataset_size: 66980919.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
birsapula/so101_test | birsapula | 2025-06-04T17:24:48Z | 0 | 0 | [
"license:cc-by-nc-4.0",
"size_categories:n<1K",
"modality:video",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2025-06-04T17:17:31Z | null | ---
license: cc-by-nc-4.0
---
|
SaketR1/bbq_unique_contexts_Religion | SaketR1 | 2025-06-04T17:18:25Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T17:18:24Z | null | ---
dataset_info:
features:
- name: category
dtype: string
- name: context
dtype: string
- name: group1
dtype: string
- name: group2
dtype: string
splits:
- name: test
num_bytes: 58064
num_examples: 300
download_size: 10341
dataset_size: 58064
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
SaketR1/bbq_unique_contexts_Physical_appearance | SaketR1 | 2025-06-04T17:18:06Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T17:18:05Z | null | ---
dataset_info:
features:
- name: category
dtype: string
- name: context
dtype: string
- name: group1
dtype: string
- name: group2
dtype: string
splits:
- name: test
num_bytes: 87102
num_examples: 394
download_size: 14420
dataset_size: 87102
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
Jensen-holm/statcast-era-pitches | Jensen-holm | 2025-06-04T17:13:41Z | 390 | 2 | [
"license:mit",
"size_categories:1M<n<10M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"baseball",
"sports-analytics"
] | [] | 2024-04-24T13:32:40Z | null | ---
license: mit
tags:
- baseball
- sports-analytics
pretty_name: Don't scrape statcast data anymore
size_categories:
- 1M<n<10M
---
# statcast-pitches
[](https://github.com/Jensen-holm/statcast-era-pitches/actions/workflows/update_statcast_data.yml)
[pybaseball](https://github.com/jldbc/pybaseball) is a great tool for downloading baseball data. Even though the library is optimized and scrapes this data in parallel, it can be time consuming.
The point of this repository is to utilize GitHub Actions to scrape new baseball data weekly during the MLB season, and update a parquet file hosted as a huggingface dataset. Reading this data as a huggingface dataset is much faster than scraping the new data each time you re run your code, or just want updated statcast pitch data in general.
The `update.py` script updates each week during the MLB season, updating the [statcast-era-pitches HuggingFace Dataset](https://huggingface.co/datasets/Jensen-holm/statcast-era-pitches) so that you don't have to re scrape this data yourself.
You can explore the entire dataset in your browser [at this link](https://huggingface.co/datasets/Jensen-holm/statcast-era-pitches/viewer/default/train)
# Installation
```bash
pip install statcast-pitches
```
# Usage
### With statcast_pitches package
**Example 1 w/ polars (suggested)**
```python
import statcast_pitches
import polars as pl
# load all pitches from 2015-present
pitches_lf = statcast_pitches.load()
# filter to get 2024 bat speed data
bat_speed_24_df = (pitches_lf
.filter(pl.col("game_date").dt.year() == 2024)
.select("bat_speed", "swing_length")
.collect())
print(bat_speed_24_df.head(3))
```
output:
| | bat_speed | swing_length |
|-|------------|--------------|
| 0 | 73.61710 | 6.92448 |
| 1 | 58.63812 | 7.56904 |
| 2 | 71.71226 | 6.46088 |
**Notes**
- Because `statcast_pitches.load()` uses a LazyFrame, we can load it much faster and even perform operations on it before 'collecting' it into memory. If it were loaded as a DataFrame, this code would execute in ~30-60 seconds, instead it runs between 2-8 seconds.
**Example 2 Duckdb**
```python
import statcast_pitches
# get bat tracking data from 2024
params = ("2024",)
query_2024_bat_speed = f"""
SELECT bat_speed, swing_length
FROM pitches
WHERE
YEAR(game_date) =?
AND bat_speed IS NOT NULL;
"""
bat_speed_24_df = statcast_pitches.load(
query=query_2024_bat_speed,
params=params,
).collect()
print(bat_speed_24_df.head(3))
```
output:
| | bat_speed | swing_length |
|-|------------|--------------|
| 0 | 73.61710 | 6.92448 |
| 1 | 58.63812 | 7.56904 |
| 2 | 71.71226 | 6.46088 |
**Notes**:
- If no query is specified, all data from 2015-present will be loaded into a DataFrame.
- The table in your query MUST be called 'pitches', or it will fail.
- Since `load()` returns a LazyFrame, notice that I had to call `pl.DataFrame.collect()` before calling `head()`
- This is slower than the other polars approach, however sometimes using SQL is fun
### With HuggingFace API (not recommended)
***Pandas***
```python
import pandas as pd
df = pd.read_parquet("hf://datasets/Jensen-holm/statcast-era-pitches/data/statcast_era_pitches.parquet")
```
***Polars***
```python
import polars as pl
df = pl.read_parquet('hf://datasets/Jensen-holm/statcast-era-pitches/data/statcast_era_pitches.parquet')
```
***Duckdb***
```sql
SELECT *
FROM 'hf://datasets/Jensen-holm/statcast-era-pitches/data/statcast_era_pitches.parquet';
```
***HuggingFace Dataset***
```python
from datasets import load_dataset
ds = load_dataset("Jensen-holm/statcast-era-pitches")
```
***Tidyverse***
```r
library(tidyverse)
statcast_pitches <- read_parquet(
"https://huggingface.co/datasets/Jensen-holm/statcast-era-pitches/resolve/main/data/statcast_era_pitches.parquet"
)
```
see the [dataset](https://huggingface.co/datasets/Jensen-holm/statcast-era-pitches) on HugingFace itself for more details.
## Eager Benchmarking

| Eager Load Time (s) | API |
|---------------|-----|
| 1421.103 | pybaseball |
| 26.899 | polars |
| 33.093 | pandas |
| 68.692 | duckdb |
# ⚠️ Data-Quality Warning ⚠️
MLB states that real time `pitch_type` classification is automated and subject to change as data gets reviewed. This is currently not taken into account as the huggingface dataset gets updated. `pitch_type` is the only column that is affected by this.
# Contributing
Feel free to submit issues and PR's if you have a contribution you would like to make. |
cristiano-sartori/college_chemistry | cristiano-sartori | 2025-06-04T16:59:26Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T16:59:23Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: subject
dtype: string
- name: choices
sequence: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 26496
num_examples: 100
download_size: 17169
dataset_size: 26496
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
emiliensilly/rag_data_gpt | emiliensilly | 2025-06-04T16:27:46Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T16:23:54Z | null | ---
dataset_info:
features:
- name: text
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 2041614
num_examples: 770
download_size: 1014945
dataset_size: 2041614
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
fh1628/open_answer | fh1628 | 2025-06-04T16:25:23Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T15:46:32Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: openr1_source
dtype: string
- name: id
dtype: string
- name: dataset
dtype: string
- name: choices
sequence: string
splits:
- name: train
num_bytes: 261029707.08138365
num_examples: 209224
- name: eval
num_bytes: 261029707.08138365
num_examples: 209224
download_size: 418683482
dataset_size: 522059414.1627673
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: eval
path: data/eval-*
---
|
zuozhuan/so100_catch_test | zuozhuan | 2025-06-04T16:22:19Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so100",
"tutorial"
] | [
"robotics"
] | 2025-06-04T16:22:03Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so100
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so100",
"total_episodes": 2,
"total_frames": 1792,
"total_tasks": 1,
"total_videos": 2,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:2"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.laptop": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
ainewtrend01/HTrade_Analyze | ainewtrend01 | 2025-06-04T16:17:10Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T16:17:02Z | null | ---
dataset_info:
features:
- name: Question
dtype: string
- name: Answer
dtype: string
splits:
- name: train
num_bytes: 128389288
num_examples: 36588
download_size: 56595815
dataset_size: 128389288
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ML5562/M3_Documents_BestPerf_david_test | ML5562 | 2025-06-04T16:15:09Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T16:15:05Z | null | ---
dataset_info:
features:
- name: source
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 23808661
num_examples: 32986
download_size: 11764839
dataset_size: 23808661
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mih12345/spanish_04_june | mih12345 | 2025-06-04T16:15:08Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T14:46:35Z | null | ---
dataset_info:
features:
- name: text
dtype: string
- name: stringlengths
dtype: int64
- name: audio
dtype: audio
- name: audioduration(s)
dtype: float64
splits:
- name: train
num_bytes: 282198402.0
num_examples: 511
download_size: 244100623
dataset_size: 282198402.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "spanish_04_june"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
moazeldegwy/CoachAgentDataset | moazeldegwy | 2025-06-04T16:08:44Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:10:34Z | null | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 11803239
num_examples: 1925
download_size: 1669560
dataset_size: 11803239
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
kreasof-ai/KAC-QuantFin-1M | kreasof-ai | 2025-06-04T16:04:25Z | 52 | 0 | [
"license:cc-by-nc-sa-4.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"finance"
] | [] | 2025-06-01T08:18:54Z | null | ---
dataset_info:
features:
- name: scenario_id
dtype: string
- name: final_pnl_ratio
dtype: float64
- name: max_drawdown
dtype: float64
- name: total_trades
dtype: int64
- name: synthetic_ohlcv_close
sequence: float64
- name: garch_params_used_for_sim_str
dtype: string
- name: strategy_params_str
dtype: string
- name: strategy_exit_rules_str
dtype: string
splits:
- name: train
num_bytes: 9935009874
num_examples: 1000000
download_size: 0
dataset_size: 9935009874
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-nc-sa-4.0
tags:
- finance
---
# Kreasof AI Capital (KAC) QuantFin-1M
We employ GARCH-based synthetic price generation, combined with our proprietary trading algorithm. The synthetic price path originally length in 28800 steps with 1-minute interval, but subsampled to 1028 steps with 28-minutes interval to save storage.
**License:** cc-by-nc-sa-4.0 (non-commercial) |
mahdilotfi/IR-LPR-corners | mahdilotfi | 2025-06-04T15:54:30Z | 0 | 0 | [
"license:gpl-3.0",
"size_categories:1K<n<10K",
"format:imagefolder",
"modality:image",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2025-06-04T15:34:37Z | null | ---
license: gpl-3.0
pretty_name: f
size_categories:
- 1K<n<10K
---
# Iranian Car Plate Corner Detection Dataset
This dataset contains **1,883 manually annotated images** of Iranian vehicles, each labeled with the **4 corner points of the license plate**.
For more information see [github repository](https://github.com/mahdilotfi167/IR-LPR-corners). |
casimiir/openr1_mot | casimiir | 2025-06-04T15:53:55Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T15:50:10Z | null | ---
dataset_info:
features:
- name: dataset
dtype: string
- name: id
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 7066517987
num_examples: 349317
download_size: 3065153327
dataset_size: 7066517987
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
NFX74/SFT_STEM_100k-test | NFX74 | 2025-06-04T15:50:00Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T15:49:42Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 925969706
num_examples: 100000
download_size: 414237251
dataset_size: 925969706
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
hirundo-io/FaithEval-unanswerable-train | hirundo-io | 2025-06-04T15:08:59Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T15:08:56Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 3887207.341894061
num_examples: 1993
download_size: 2280309
dataset_size: 3887207.341894061
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
IbratDO/cv_malemaleb7808eea_dataset_splitted | IbratDO | 2025-06-04T15:03:07Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T15:02:24Z | null | ---
dataset_info:
features:
- name: audio_filepath
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 528697488.0
num_examples: 4800
- name: validation
num_bytes: 135098148.0
num_examples: 1200
download_size: 483125637
dataset_size: 663795636.0
---
# Dataset Card for "cv_malemaleb7808eea_dataset_splitted"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
Slicky325/IQTest | Slicky325 | 2025-06-04T14:56:14Z | 65 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-31T14:25:26Z | null | ---
dataset_info:
features:
- name: pid
dtype: string
- name: question
dtype: string
- name: image
dtype: string
- name: decoded_image
dtype: image
- name: choices
sequence: string
- name: unit
dtype: string
- name: precision
dtype: float64
- name: answer
dtype: string
- name: question_type
dtype: string
- name: answer_type
dtype: string
- name: metadata
struct:
- name: category
dtype: string
- name: context
dtype: string
- name: grade
dtype: string
- name: img_height
dtype: int64
- name: img_width
dtype: int64
- name: language
dtype: string
- name: skills
sequence: string
- name: source
dtype: string
- name: split
dtype: string
- name: task
dtype: string
- name: query
dtype: string
- name: subquestions
dtype: string
splits:
- name: train
num_bytes: 17443717.0
num_examples: 228
download_size: 16770435
dataset_size: 17443717.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
anas-gouda/MTevent | anas-gouda | 2025-06-04T14:39:17Z | 723 | 1 | [
"language:en",
"arxiv:2505.11282",
"region:us",
"EventCamera",
"6DPose",
"3DboundingBox",
"StereoEventCamera"
] | [] | 2025-04-01T09:45:58Z | null | ---
language:
- en
tags:
- EventCamera
- 6DPose
- 3DboundingBox
- StereoEventCamera
---
# MTevent: A Multi-Task Event Camera Dataset for 6D Pose Estimation and Moving Object Detection
Read the scenes_info.docx and scenes_info.xlsx to get an overview of the recorded scenes.
A sampßle scene_data.json file has been added.
The github repository the code: https://github.com/shrutarv/MTevent_toolkit/tree/main
The full paper can be viewed at: https://arxiv.org/abs/2505.11282 |
sysuyy/ImgEdit | sysuyy | 2025-06-04T14:35:02Z | 14,876 | 7 | [
"license:apache-2.0",
"arxiv:2505.20275",
"region:us"
] | [] | 2025-05-14T10:47:47Z | null | ---
license: apache-2.0
---
[ImgEdit: A Unified Image Editing Dataset and Benchmark](https://huggingface.co/papers/2505.20275)
# 🌍 Introduction
**ImgEdit** is a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks.
To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality.
Using ImgEdit, we train **ImgEdit-E1**, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design.
For comprehensive evaluation, we introduce **ImgEdit-Bench**, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation.
It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite.
We evaluate both open-source and proprietary models, as well as ImgEdit-E1.
# 📜 Citation
If you find our paper and code useful in your research, please consider giving a star ⭐ and citation 📝.
```bibtex
@article{ye2025imgedit,
title={ImgEdit: A Unified Image Editing Dataset and Benchmark},
author={Ye, Yang and He, Xianyi and Li, Zongjian and Lin, Bin and Yuan, Shenghai and Yan, Zhiyuan and Hou, Bohan and Yuan, Li},
journal={arXiv preprint arXiv:2505.20275},
year={2025}
}
```
|
Kgshop/Soola | Kgshop | 2025-06-04T14:30:10Z | 354 | 0 | [
"license:apache-2.0",
"size_categories:n<1K",
"format:imagefolder",
"modality:image",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2025-04-08T07:55:53Z | null | ---
license: apache-2.0
---
|
MossProphet/so100_folding_testrun2 | MossProphet | 2025-06-04T14:24:24Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so100",
"tutorial"
] | [
"robotics"
] | 2025-06-04T14:24:21Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so100
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so100",
"total_episodes": 1,
"total_frames": 113,
"total_tasks": 1,
"total_videos": 3,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:1"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
12
],
"names": [
"left_shoulder_pan",
"left_shoulder_lift",
"left_elbow_flex",
"left_wrist_flex",
"left_wrist_roll",
"left_gripper",
"right_shoulder_pan",
"right_shoulder_lift",
"right_elbow_flex",
"right_wrist_flex",
"right_wrist_roll",
"right_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
12
],
"names": [
"left_shoulder_pan",
"left_shoulder_lift",
"left_elbow_flex",
"left_wrist_flex",
"left_wrist_roll",
"left_gripper",
"right_shoulder_pan",
"right_shoulder_lift",
"right_elbow_flex",
"right_wrist_flex",
"right_wrist_roll",
"right_gripper"
]
},
"observation.images.External": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.Arm_left": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.Arm_right": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
qualifire/ai-grounding-benchmark | qualifire | 2025-06-04T14:22:07Z | 0 | 0 | [
"task_categories:text-classification",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"claim-grounding",
"natural-language-inference",
"reasoning",
"classification",
"grounding",
"hallucination"
] | [
"text-classification"
] | 2025-06-04T14:08:53Z | null | ---
language: en
tags:
- claim-grounding
- natural-language-inference
- reasoning
- classification
- grounding
- hallucination
pretty_name: Grounding Claims Dataset
license: cc-by-nc-4.0
task_categories:
- text-classification
---
The **Grounding Claims Dataset** is a multi-domain dataset for evaluating whether a natural language **claim** is grounded (i.e., supported or entailed) by a **document**. The dataset is organized into four subsets, each requiring different types of reasoning:
- **general** (1500 examples): Broad, everyday reasoning
- **logical** (1000 examples): Logical consistency and inference
- **time_and_dates** (100 examples): Temporal reasoning
- **prices_and_math** (100 examples): Numerical and mathematical reasoning
Each entry consists of:
- `doc`: A short context or passage
- `claim`: A natural language statement to verify against the `doc`
- `label`: A binary label indicating whether the claim is grounded in the document (`1` for grounded, `0` for ungrounded)
- `dataset`: The source subset name (e.g., `"general"`)
---
## 📌 Features
| Feature | Type | Description |
|----------|---------|------------------------------------------------|
| `doc` | string | The document or passage providing the context |
| `claim` | string | A statement to verify against the document |
| `label` | string | grounded or ungrounded |
| `dataset`| string | The domain/subset the instance belongs to |
---
## 📊 Usage
This dataset can be used to train and evaluate models on factual verification, natural language inference (NLI), and claim grounding tasks across multiple domains.
---
## 🏷️ Labels
- `grounded` — The claim is grounded in the document.
- `ungrounded` — The claim is ungrounded or contradicted by the document. |
thucdangvan020999/singaporean_accent_district_names_continuation | thucdangvan020999 | 2025-06-04T14:12:01Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T13:56:50Z | null | ---
dataset_info:
features:
- name: id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: audio_length_s
dtype: float32
- name: text
dtype: string
- name: continuation
dtype: string
- name: voices
dtype: string
- name: district
dtype: string
splits:
- name: train
num_bytes: 569458317.909
num_examples: 2161
- name: validation
num_bytes: 33835383.0
num_examples: 130
- name: test
num_bytes: 65495484.0
num_examples: 252
download_size: 656368555
dataset_size: 668789184.909
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
deeshan-ai/nih-chest-xray-224 | deeshan-ai | 2025-06-04T14:09:08Z | 26 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T12:52:59Z | null | ---
dataset_info:
features:
- name: filename
dtype: string
- name: Atelectasis
dtype: int64
- name: Cardiomegaly
dtype: int64
- name: Consolidation
dtype: int64
- name: Edema
dtype: int64
- name: Effusion
dtype: int64
- name: Emphysema
dtype: int64
- name: Fibrosis
dtype: int64
- name: Hernia
dtype: int64
- name: Infiltration
dtype: int64
- name: Mass
dtype: int64
- name: No Finding
dtype: int64
- name: Nodule
dtype: int64
- name: Pleural_Thickening
dtype: int64
- name: Pneumonia
dtype: int64
- name: Pneumothorax
dtype: int64
splits:
- name: train
num_bytes: 15696800
num_examples: 112120
download_size: 1189640
dataset_size: 15696800
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "nih-chest-xray-224"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
ChavyvAkvar/synthetic-trades-BTC-cleaned | ChavyvAkvar | 2025-06-04T14:03:10Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T13:47:02Z | null | ---
dataset_info:
features:
- name: scenario_id
dtype: string
- name: final_pnl_ratio
dtype: float64
- name: max_drawdown
dtype: float64
- name: total_trades
dtype: int64
- name: synthetic_ohlc_open
sequence: float64
- name: synthetic_ohlc_high
sequence: float64
- name: synthetic_ohlc_low
sequence: float64
- name: synthetic_ohlc_close
sequence: float64
- name: garch_params_used_for_sim_str
dtype: string
- name: strategy_params_str
dtype: string
- name: strategy_exit_rules_str
dtype: string
splits:
- name: train
num_bytes: 22342892199.3927
num_examples: 24195
download_size: 22367441905
dataset_size: 22342892199.3927
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
interstellarninja/salesforce_hermes_thinking | interstellarninja | 2025-06-04T13:41:37Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T12:45:25Z | null | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: task
dtype: string
- name: category
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 11804051
num_examples: 2325
download_size: 3422733
dataset_size: 11804051
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Quantamhash/Deployments | Quantamhash | 2025-06-04T13:36:37Z | 52 | 0 | [
"license:apache-2.0",
"size_categories:n<1K",
"format:text",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2025-06-02T07:07:44Z | null | ---
license: apache-2.0
---
|
nik658/xarm_lift_datasett | nik658 | 2025-06-04T13:32:05Z | 111 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot"
] | [
"robotics"
] | 2025-06-03T13:12:43Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": null,
"total_episodes": 3,
"total_frames": 916,
"total_tasks": 1,
"total_videos": 3,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 15,
"splits": {
"train": "0:3"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"observation.image": {
"dtype": "video",
"shape": [
680,
680,
3
],
"names": [
"height",
"width",
"channel"
],
"info": {
"video.height": 680,
"video.width": 680,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 15,
"video.channels": 3,
"has_audio": false
}
},
"observation.state": {
"dtype": "float32",
"shape": [
28
],
"names": null
},
"action": {
"dtype": "float32",
"shape": [
4
],
"names": null
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"next.reward": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"next.done": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
sghosts/bigjob_1-4 | sghosts | 2025-06-04T13:21:40Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:44:07Z | null | ---
dataset_info:
features:
- name: image_data
dtype: image
- name: document_id
dtype: string
- name: page_num
dtype: int64
- name: total_pages
dtype: int64
- name: predictions
struct:
- name: labels
list:
- name: class
dtype: string
- name: confidence
dtype: float64
- name: polygon
sequence:
sequence: int64
- name: title
dtype: string
- name: abstract_tr
dtype: string
- name: abstract_en
dtype: string
- name: author
dtype: string
- name: thesis_id
dtype: string
- name: university
dtype: string
- name: department
dtype: string
- name: year
dtype: string
- name: language
dtype: string
- name: thesis_type
dtype: string
- name: keyword_abd
dtype: string
- name: original_url
dtype: string
- name: file_path
dtype: string
- name: file_size_bytes
dtype: int64
- name: download_success
dtype: bool
- name: extraction_success
dtype: bool
- name: prediction_success
dtype: bool
- name: download_timestamp
dtype: string
- name: extraction_timestamp
dtype: string
- name: prediction_timestamp
dtype: string
- name: hf_processing_timestamp
dtype: string
splits:
- name: timestamp_2025_06_04T11_44_06_996234
num_bytes: 417396305.0
num_examples: 1000
- name: timestamp_2025_06_04T11_53_16_274210
num_bytes: 374787319.0
num_examples: 1000
- name: timestamp_2025_06_04T12_01_45_768150
num_bytes: 361684328.0
num_examples: 1000
- name: timestamp_2025_06_04T12_11_41_104561
num_bytes: 457153700.0
num_examples: 1000
- name: timestamp_2025_06_04T12_21_46_449968
num_bytes: 427414168.0
num_examples: 1000
- name: timestamp_2025_06_04T12_32_25_308062
num_bytes: 399793024.0
num_examples: 1000
- name: timestamp_2025_06_04T12_42_03_173228
num_bytes: 352752149.0
num_examples: 1000
- name: timestamp_2025_06_04T12_51_36_550461
num_bytes: 428877476.0
num_examples: 1000
- name: timestamp_2025_06_04T13_01_32_708789
num_bytes: 380216468.0
num_examples: 1000
- name: timestamp_2025_06_04T13_11_21_752856
num_bytes: 353682909.0
num_examples: 1000
- name: timestamp_2025_06_04T13_21_11_340676
num_bytes: 465946214.0
num_examples: 1000
download_size: 4313108360
dataset_size: 4419704060.0
configs:
- config_name: default
data_files:
- split: timestamp_2025_06_04T11_44_06_996234
path: data/timestamp_2025_06_04T11_44_06_996234-*
- split: timestamp_2025_06_04T11_53_16_274210
path: data/timestamp_2025_06_04T11_53_16_274210-*
- split: timestamp_2025_06_04T12_01_45_768150
path: data/timestamp_2025_06_04T12_01_45_768150-*
- split: timestamp_2025_06_04T12_11_41_104561
path: data/timestamp_2025_06_04T12_11_41_104561-*
- split: timestamp_2025_06_04T12_21_46_449968
path: data/timestamp_2025_06_04T12_21_46_449968-*
- split: timestamp_2025_06_04T12_32_25_308062
path: data/timestamp_2025_06_04T12_32_25_308062-*
- split: timestamp_2025_06_04T12_42_03_173228
path: data/timestamp_2025_06_04T12_42_03_173228-*
- split: timestamp_2025_06_04T12_51_36_550461
path: data/timestamp_2025_06_04T12_51_36_550461-*
- split: timestamp_2025_06_04T13_01_32_708789
path: data/timestamp_2025_06_04T13_01_32_708789-*
- split: timestamp_2025_06_04T13_11_21_752856
path: data/timestamp_2025_06_04T13_11_21_752856-*
- split: timestamp_2025_06_04T13_21_11_340676
path: data/timestamp_2025_06_04T13_21_11_340676-*
---
|
motigupta/mnist_mlops | motigupta | 2025-06-04T13:09:28Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T13:04:32Z | null | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
'8': '8'
'9': '9'
splits:
- name: train
num_bytes: 17223300.0
num_examples: 60000
- name: test
num_bytes: 2875182.0
num_examples: 10000
download_size: 17619501
dataset_size: 20098482.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
GingerBled/M3_mcqa_context_m1 | GingerBled | 2025-06-04T13:03:58Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T13:03:37Z | null | ---
dataset_info:
features:
- name: id
dtype: string
- name: dataset
dtype: string
- name: question
dtype: string
- name: options
sequence: string
- name: answer
dtype: string
- name: explanation
dtype: string
splits:
- name: train
num_bytes: 421977660.0
num_examples: 47469
download_size: 236386582
dataset_size: 421977660.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jlbaker361/clip-art_coco_captioned-500 | jlbaker361 | 2025-06-04T12:56:37Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T12:56:29Z | null | ---
dataset_info:
features:
- name: image
dtype: image
- name: embedding
sequence:
sequence:
sequence: float32
- name: text
sequence:
sequence:
sequence: float16
- name: prompt
dtype: string
- name: posterior
sequence:
sequence:
sequence: float16
splits:
- name: train
num_bytes: 124953660.0
num_examples: 500
download_size: 121455869
dataset_size: 124953660.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jlbaker361/ssl-league_captioned_splash-500 | jlbaker361 | 2025-06-04T12:47:02Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T12:46:54Z | null | ---
dataset_info:
features:
- name: image
dtype: image
- name: embedding
sequence:
sequence:
sequence: float32
- name: text
sequence:
sequence:
sequence: float16
- name: prompt
dtype: string
- name: posterior
sequence:
sequence:
sequence: float16
splits:
- name: train
num_bytes: 115289757.0
num_examples: 500
download_size: 112584575
dataset_size: 115289757.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jlbaker361/siglip2-coco_captioned-500 | jlbaker361 | 2025-06-04T12:41:44Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T12:41:37Z | null | ---
dataset_info:
features:
- name: image
dtype: image
- name: embedding
sequence:
sequence:
sequence: float16
- name: text
sequence:
sequence:
sequence: float16
- name: prompt
dtype: string
- name: posterior
sequence:
sequence:
sequence: float16
splits:
- name: train
num_bytes: 126980671.0
num_examples: 500
download_size: 122691287
dataset_size: 126980671.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
huggingface-legal/takedown-notices | huggingface-legal | 2025-06-04T12:39:53Z | 652 | 24 | [
"license:cc-by-nc-nd-4.0",
"size_categories:n<1K",
"modality:document",
"library:datasets",
"library:mlcroissant",
"region:us",
"legal"
] | [] | 2022-06-28T09:04:19Z | null | ---
license: cc-by-nc-nd-4.0
tags:
- legal
---
### Takedown notices received by the Hugging Face team
Please click on Files and versions to browse them
Also check out our:
- [Terms of Service](https://huggingface.co/terms-of-service)
- [Community Code of Conduct](https://huggingface.co/code-of-conduct)
- [Content Guidelines](https://huggingface.co/content-guidelines)
|
CoffeBank/Ru-hard-detection-dataset | CoffeBank | 2025-06-04T12:27:13Z | 0 | 0 | [
"task_categories:text-classification",
"task_categories:zero-shot-classification",
"language:ru",
"license:mit",
"region:us"
] | [
"text-classification",
"zero-shot-classification"
] | 2025-06-04T12:23:20Z | null | ---
license: mit
task_categories:
- text-classification
- zero-shot-classification
language:
- ru
--- |
Jakumetsu/A-MMK12-8K | Jakumetsu | 2025-06-04T12:19:33Z | 15 | 0 | [
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2506.02096",
"region:us"
] | [
"question-answering"
] | 2025-05-30T15:56:13Z | null | ---
license: mit
task_categories:
- question-answering
language:
- en
---
# A-MMK12-8K
This dataset is created using the SynthRL pipeline to synthesize 3,380 challenging questions from 8,072 seed samples.
## Dataset Details
- **Synthesis Method**: SynthRL pipeline
- **Total Samples**: 11,452 (8,072 seed + 3,380 synthesized)
- **Seed Data**: MMK12 dataset
- **Purpose**: Training data for VLM reinforcement learning with verifiable rewards (RLVR)
## Data Sources
- **Original MMK12**: Proposed in [MM-EUREKA](https://huggingface.co/datasets/FanqingM/MMK12) (thanks to the MM-EUREKA authors)
- **Processed Seed Data**: Our free-form version is available at [K12-Freeform-8K](https://huggingface.co/datasets/Jakumetsu/K12-Freeform-8K)
## Citation
If you use this dataset, please cite our paper:
```bibtex
@misc{wu2025synthrl,
title={SynthRL: Scaling Visual Reasoning with Verifiable Data Synthesis},
author={Zijian Wu and Jinjie Ni and Xiangyan Liu and Zichen Liu and Hang Yan and Michael Qizhe Shieh},
year={2025},
eprint={2506.02096},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.02096},
}
``` |
alozowski/python_test_open | alozowski | 2025-06-04T11:57:13Z | 82 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-07T14:16:55Z | null | ---
dataset_info:
- config_name: chunked
features:
- name: document_id
dtype: string
- name: document_text
dtype: string
- name: document_filename
dtype: string
- name: document_metadata
struct:
- name: file_size
dtype: int64
- name: raw_chunk_summaries
sequence: string
- name: chunk_summaries
sequence: string
- name: raw_document_summary
dtype: string
- name: document_summary
dtype: string
- name: summarization_model
dtype: string
- name: chunks
list:
- name: chunk_id
dtype: string
- name: chunk_text
dtype: string
- name: multihop_chunks
list:
- name: chunk_ids
sequence: string
- name: chunks_text
sequence: string
splits:
- name: train
num_bytes: 400219
num_examples: 1
download_size: 244712
dataset_size: 400219
- config_name: ingested
features:
- name: document_id
dtype: string
- name: document_text
dtype: string
- name: document_filename
dtype: string
- name: document_metadata
struct:
- name: file_size
dtype: int64
splits:
- name: train
num_bytes: 139027
num_examples: 1
download_size: 73224
dataset_size: 139027
- config_name: lighteval
features:
- name: question
dtype: string
- name: additional_instructions
dtype: string
- name: ground_truth_answer
dtype: string
- name: gold
sequence: string
- name: choices
sequence: string
- name: question_category
dtype: string
- name: kind
dtype: string
- name: estimated_difficulty
dtype: int64
- name: citations
sequence: string
- name: document_id
dtype: string
- name: chunk_ids
sequence: string
- name: question_generating_model
dtype: string
- name: chunks
sequence: string
- name: document
dtype: string
- name: document_summary
dtype: string
- name: answer_citation_score
dtype: float64
- name: chunk_citation_score
dtype: float64
- name: citation_score
dtype: float64
splits:
- name: train
num_bytes: 3926271
num_examples: 27
download_size: 119383
dataset_size: 3926271
- config_name: multi_hop_questions
features:
- name: document_id
dtype: string
- name: source_chunk_ids
sequence: string
- name: additional_instructions
dtype: string
- name: question
dtype: string
- name: self_answer
dtype: string
- name: choices
sequence: string
- name: estimated_difficulty
dtype: int64
- name: self_assessed_question_type
dtype: string
- name: generating_model
dtype: string
- name: thought_process
dtype: string
- name: citations
sequence: string
- name: raw_response
dtype: string
splits:
- name: train
num_bytes: 250791
num_examples: 17
download_size: 40909
dataset_size: 250791
- config_name: single_shot_questions
features:
- name: chunk_id
dtype: string
- name: document_id
dtype: string
- name: additional_instructions
dtype: string
- name: question
dtype: string
- name: self_answer
dtype: string
- name: choices
sequence: string
- name: estimated_difficulty
dtype: int64
- name: self_assessed_question_type
dtype: string
- name: generating_model
dtype: string
- name: thought_process
dtype: string
- name: raw_response
dtype: string
- name: citations
sequence: string
splits:
- name: train
num_bytes: 97680
num_examples: 10
download_size: 20170
dataset_size: 97680
- config_name: summarized
features:
- name: document_id
dtype: string
- name: document_text
dtype: string
- name: document_filename
dtype: string
- name: document_metadata
struct:
- name: file_size
dtype: int64
- name: raw_chunk_summaries
sequence: string
- name: chunk_summaries
sequence: string
- name: raw_document_summary
dtype: string
- name: document_summary
dtype: string
- name: summarization_model
dtype: string
splits:
- name: train
num_bytes: 161855
num_examples: 1
download_size: 106135
dataset_size: 161855
configs:
- config_name: chunked
data_files:
- split: train
path: chunked/train-*
- config_name: ingested
data_files:
- split: train
path: ingested/train-*
- config_name: lighteval
data_files:
- split: train
path: lighteval/train-*
- config_name: multi_hop_questions
data_files:
- split: train
path: multi_hop_questions/train-*
- config_name: single_shot_questions
data_files:
- split: train
path: single_shot_questions/train-*
- config_name: summarized
data_files:
- split: train
path: summarized/train-*
---
|
Eathus/github-issues-vul-detection-gpt-few-vul-desc-gpt-enhanced-prompt-results | Eathus | 2025-06-04T11:44:02Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-03T12:17:50Z | null | ---
dataset_info:
features:
- name: cve_id
dtype: string
- name: cve_published
dtype: string
- name: cve_descriptions
dtype: string
- name: cve_metrics
struct:
- name: cvssMetricV2
list:
- name: acInsufInfo
dtype: bool
- name: baseSeverity
dtype: string
- name: cvssData
struct:
- name: accessComplexity
dtype: string
- name: accessVector
dtype: string
- name: authentication
dtype: string
- name: availabilityImpact
dtype: string
- name: baseScore
dtype: float64
- name: confidentialityImpact
dtype: string
- name: integrityImpact
dtype: string
- name: vectorString
dtype: string
- name: version
dtype: string
- name: exploitabilityScore
dtype: float64
- name: impactScore
dtype: float64
- name: obtainAllPrivilege
dtype: bool
- name: obtainOtherPrivilege
dtype: bool
- name: obtainUserPrivilege
dtype: bool
- name: source
dtype: string
- name: type
dtype: string
- name: userInteractionRequired
dtype: bool
- name: cvssMetricV30
list:
- name: cvssData
struct:
- name: attackComplexity
dtype: string
- name: attackVector
dtype: string
- name: availabilityImpact
dtype: string
- name: baseScore
dtype: float64
- name: baseSeverity
dtype: string
- name: confidentialityImpact
dtype: string
- name: integrityImpact
dtype: string
- name: privilegesRequired
dtype: string
- name: scope
dtype: string
- name: userInteraction
dtype: string
- name: vectorString
dtype: string
- name: version
dtype: string
- name: exploitabilityScore
dtype: float64
- name: impactScore
dtype: float64
- name: source
dtype: string
- name: type
dtype: string
- name: cvssMetricV31
list:
- name: cvssData
struct:
- name: attackComplexity
dtype: string
- name: attackVector
dtype: string
- name: availabilityImpact
dtype: string
- name: baseScore
dtype: float64
- name: baseSeverity
dtype: string
- name: confidentialityImpact
dtype: string
- name: integrityImpact
dtype: string
- name: privilegesRequired
dtype: string
- name: scope
dtype: string
- name: userInteraction
dtype: string
- name: vectorString
dtype: string
- name: version
dtype: string
- name: exploitabilityScore
dtype: float64
- name: impactScore
dtype: float64
- name: source
dtype: string
- name: type
dtype: string
- name: cvssMetricV40
list:
- name: cvssData
struct:
- name: Automatable
dtype: string
- name: Recovery
dtype: string
- name: Safety
dtype: string
- name: attackComplexity
dtype: string
- name: attackRequirements
dtype: string
- name: attackVector
dtype: string
- name: availabilityRequirement
dtype: string
- name: baseScore
dtype: float64
- name: baseSeverity
dtype: string
- name: confidentialityRequirement
dtype: string
- name: exploitMaturity
dtype: string
- name: integrityRequirement
dtype: string
- name: modifiedAttackComplexity
dtype: string
- name: modifiedAttackRequirements
dtype: string
- name: modifiedAttackVector
dtype: string
- name: modifiedPrivilegesRequired
dtype: string
- name: modifiedSubAvailabilityImpact
dtype: string
- name: modifiedSubConfidentialityImpact
dtype: string
- name: modifiedSubIntegrityImpact
dtype: string
- name: modifiedUserInteraction
dtype: string
- name: modifiedVulnAvailabilityImpact
dtype: string
- name: modifiedVulnConfidentialityImpact
dtype: string
- name: modifiedVulnIntegrityImpact
dtype: string
- name: privilegesRequired
dtype: string
- name: providerUrgency
dtype: string
- name: subAvailabilityImpact
dtype: string
- name: subConfidentialityImpact
dtype: string
- name: subIntegrityImpact
dtype: string
- name: userInteraction
dtype: string
- name: valueDensity
dtype: string
- name: vectorString
dtype: string
- name: version
dtype: string
- name: vulnAvailabilityImpact
dtype: string
- name: vulnConfidentialityImpact
dtype: string
- name: vulnIntegrityImpact
dtype: string
- name: vulnerabilityResponseEffort
dtype: string
- name: source
dtype: string
- name: type
dtype: string
- name: cve_references
list:
- name: source
dtype: string
- name: tags
sequence: string
- name: url
dtype: string
- name: cve_configurations
list:
- name: nodes
list:
- name: cpeMatch
list:
- name: criteria
dtype: string
- name: matchCriteriaId
dtype: string
- name: versionEndExcluding
dtype: string
- name: versionEndIncluding
dtype: string
- name: versionStartExcluding
dtype: 'null'
- name: versionStartIncluding
dtype: string
- name: vulnerable
dtype: bool
- name: negate
dtype: bool
- name: operator
dtype: string
- name: operator
dtype: string
- name: cve_primary_cwe
dtype: string
- name: cve_tags
sequence: string
- name: issue_owner_repo
sequence: string
- name: issue_body
dtype: string
- name: issue_title
dtype: string
- name: issue_comments_url
dtype: string
- name: issue_comments_count
dtype: int64
- name: issue_created_at
dtype: timestamp[ns]
- name: issue_updated_at
dtype: string
- name: issue_html_url
dtype: string
- name: issue_github_id
dtype: int64
- name: issue_number
dtype: int64
- name: label
dtype: bool
- name: issue_msg
dtype: string
- name: issue_msg_n_tokens
dtype: int64
- name: issue_embedding
sequence: float64
- name: __index_level_0__
dtype: int64
- name: gpt_description
dtype: string
- name: gpt_vulnerability
dtype: string
- name: gpt_confidence
dtype: int64
- name: gpt_is_relevant
dtype: bool
splits:
- name: test
num_bytes: 52929099
num_examples: 1778
download_size: 35896451
dataset_size: 52929099
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
YYama0/RadFig-VQA | YYama0 | 2025-06-04T11:42:04Z | 79 | 0 | [
"task_categories:question-answering",
"language:en",
"license:cc-by-nc-sa-4.0",
"size_categories:100K<n<1M",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"medical"
] | [
"question-answering"
] | 2025-05-31T02:44:35Z | null | ---
license: cc-by-nc-sa-4.0
task_categories:
- question-answering
language:
- en
tags:
- medical
size_categories:
- 100K<n<1M
---
# RadFig-VQA Dataset
## Overview
RadFig-VQA is a large-scale medical visual question answering dataset based on radiological figures from PubMed Central (PMC). The dataset comprises **70,550 images** and **238,294 question-answer pairs** - making it the **largest radiology-specific VQA dataset by number of QA pairs** - generated from radiological figures across diverse imaging modalities and clinical contexts, designed for comprehensive medical VQA evaluation.
## Dataset Structure
- **Total images**: 70,550
- **Total QA pairs**: 238,294
- **Format**: CSV file with the following columns:
- `file_path`: Path to the radiological image
- `id`: Question identifier
- `modality`: Medical imaging type (CT, MRI, X-ray, Ultrasound, PET, SPECT, Mammography, Angiography, Others, Multiple)
- `difficulty`: Question difficulty (Easy, Medium, Hard)
- `category`: Clinical category (Findings, Diagnosis, Treatment, Anatomy, Clinical Significance, Modality)
- `question`: The question text
- `option_A` to `option_F`: Six multiple choice options
- `correct`: Correct answer (A-F)
- `PMC_ID`: PubMed Central article identifier
## Imaging Modalities
- **CT** (Computed Tomography)
- **MRI** (Magnetic Resonance Imaging)
- **X-ray** (Radiography)
- **Ultrasound**
- **PET** (Positron Emission Tomography)
- **SPECT** (Single-Photon Emission Computed Tomography)
- **Mammography**
- **Angiography**
- **Multiple** (Multiple modalities in single figure)
- **Others** (Other imaging modalities)
## Clinical Categories
- **Findings**: Identification of radiological observations and features
- **Diagnosis**: Clinical interpretation and diagnostic conclusions
- **Treatment**: Therapeutic recommendations and treatment planning
- **Anatomy**: Anatomical structure identification and localization
- **Clinical Significance**: Understanding of clinical implications and relevance
- **Modality**: Imaging techniques and technical aspects
## Dataset Construction
The dataset was constructed through a systematic multi-stage pipeline:
1. **Paper Selection**: From 6.28M PMC papers, we filtered to 40,850 radiology papers using keyword filtering and license restrictions (CC BY, CC BY-NC, CC BY-NC-SA, CC0)
2. **Figure Classification**: An EfficientNetV2-S CNN model with 0.990 ROC AUC was used to identify radiological figures from non-radiological content (RadFig-classifier: Available at [https://huggingface.co/YYama0/RadFig-classifier](https://huggingface.co/YYama0/RadFig-classifier))
3. **VQA Generation**: A two-stage process using GPT-4o-mini for figure description extraction and GPT-4o for structured question generation
Each question is formatted as a 6-option multiple-choice question with exactly one correct answer, systematically categorized across imaging modality, clinical category, and difficulty level.
## Usage
RadFig-VQA is designed for training and evaluating medical VQA models on radiological image interpretation. The dataset supports diverse assessment scenarios from basic anatomical identification to complex clinical reasoning tasks across multiple imaging modalities.
## Zero-shot VLM Model Performance Comparison Results
### Accuracy by Clinical Category
| Model | Anatomy | Clinical Significance | Diagnosis | Findings | Modality | Treatment |
|-------|---------|----------------------|-----------|----------|----------|-----------|
| **Llama3.2 11B Vision** | 51.83% | 63.05% | 52.36% | 54.37% | 68.20% | 58.77% |
| **Gemma3 4B** | 46.78% | 62.23% | 50.91% | 51.63% | 61.22% | 56.14% |
| **MedGemma 4B** | 50.44% | 69.12% | 56.43% | 57.16% | 61.84% | 59.65% |
| **InternVL3 2B** | 52.46% | 71.79% | 58.79% | 60.20% | 69.88% | 67.54% |
| **InternVL3 8B** | 58.13% | 78.51% | 66.49% | 66.80% | 77.56% | 78.95% |
| **InternVL3 14B** | 60.78% | 81.91% | 70.56% | 69.88% | 78.98% | 77.19% |
| **Qwen2.5-VL 3B** | 54.48% | 73.64% | 58.79% | 62.66% | 73.59% | 71.05% |
| **Qwen2.5-VL 7B** | 53.34% | 73.77% | 57.61% | 60.33% | 73.14% | 61.40% |
| **Qwen2.5-VL 3B (Fine-tuned)** | **78.44%** | **89.53%** | **86.14%** | **82.90%** | **88.52%** | **92.98%** |
### Accuracy by Modality
| Model | Angiography | CT | MRI | Mammography | Multiple | Others | PET | SPECT | Ultrasound | X-ray |
|-------|-------------|----|----|-------------|----------|--------|-----|-------|------------|-------|
| **Llama3.2 11B Vision** | 63.88% | 57.01% | 57.85% | 52.35% | 60.74% | 53.59% | 57.24% | 50.00% | 55.94% | 60.37% |
| **Gemma3 4B** | 57.74% | 54.95% | 53.18% | 50.34% | 60.74% | 51.95% | 54.64% | 50.00% | 56.07% | 53.46% |
| **MedGemma 4B** | 63.88% | 61.47% | 56.90% | 49.66% | 65.76% | 56.87% | 60.91% | 61.45% | 58.97% | 59.96% |
| **Qwen2.5-VL 3B** | 69.78% | 65.06% | 65.39% | 65.77% | 69.88% | 61.54% | 65.01% | 60.24% | 65.96% | 63.21% |
| **Qwen2.5-VL 7B** | 69.53% | 63.03% | 64.01% | 59.06% | 67.57% | 63.30% | 62.42% | 55.42% | 64.91% | 64.02% |
| **InternVL3 2B** | 67.08% | 63.13% | 61.40% | 57.05% | 69.48% | 61.92% | 63.93% | 59.64% | 64.51% | 62.20% |
| **InternVL3 8B** | 74.20% | 68.91% | 69.42% | 62.42% | 76.31% | 68.35% | 70.41% | 72.89% | 70.98% | 68.29% |
| **InternVL3 14B** | 74.69% | 72.32% | 71.65% | 67.11% | 78.92% | 71.63% | 73.65% | 75.90% | 74.54% | 74.19% |
| **Qwen2.5-VL 3B (Fine-tuned)** | **90.66%** | **85.10%** | **85.83%** | **78.52%** | **87.25%** | **80.71%** | **84.23%** | **82.53%** | **86.41%** | **82.11%** |
### Accuracy by Difficulty
| Model | Easy | Medium | Hard |
|-------|------|--------|------|
| **Llama3.2 11B Vision** | 60.02% | 57.46% | 56.96% |
| **Gemma3 4B** | 56.83% | 53.67% | 55.80% |
| **MedGemma 4B** | 59.32% | 59.57% | 60.41% |
| **Qwen2.5-VL 3B** | 65.30% | 64.99% | 66.22% |
| **Qwen2.5-VL 7B** | 64.81% | 63.04% | 65.35% |
| **InternVL3 2B** | 63.41% | 62.52% | 64.39% |
| **InternVL3 8B** | 70.29% | 69.31% | 71.34% |
| **InternVL3 14B** | 75.07% | 72.92% | 72.86% |
| **Qwen2.5-VL 3B (Fine-tuned)** | **86.04%** | **84.65%** | **85.77%** |
## Citation
Citation information coming soon.
## License
This dataset is released under **CC BY-NC-SA** (Creative Commons Attribution-NonCommercial-ShareAlike).
Please note that the generated questions were created using OpenAI's GPT models. Users should consider OpenAI's Terms of Use when using this dataset in research or applications.
## Dataset Files
- **Current release**: Question-answer pairs in `radfig-vqa_dataset.csv` (238,294 QA pairs) and `imgs.zip` (70,550 images).
## Data Split
- Official train/test splits coming soon |
NurErtug/MNLP_M3_mcqa_dataset_merged_v4_v2 | NurErtug | 2025-06-04T11:40:52Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:40:48Z | null | ---
dataset_info:
features:
- name: question
dtype: string
- name: explanation
dtype: string
- name: options
sequence: string
- name: answer
dtype: string
- name: dataset
dtype: string
splits:
- name: train
num_bytes: 1433629
num_examples: 1096
download_size: 773306
dataset_size: 1433629
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
LIUMinghao/MedEBench | LIUMinghao | 2025-06-04T11:39:37Z | 122 | 0 | [
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2506.01921",
"region:us",
"medical",
"image-editing",
"text-to-image",
"medical-benchmark"
] | [
"image-to-image"
] | 2025-05-11T07:35:51Z | null | ---
pretty_name: MedEBench
license: cc-by-nc-4.0
language:
- en
tags:
- medical
- image-editing
- text-to-image
- medical-benchmark
task_categories:
- image-to-image
dataset_info:
features:
- name: id
dtype: int32
- name: Organ
dtype: string
- name: Task
dtype: string
- name: prompt
dtype: string
- name: rephrased_prompt
dtype: string
- name: detailed_prompt
dtype: string
- name: previous_image
dtype: image
- name: changed_image
dtype: image
- name: previous_mask
dtype: image
- name: url
dtype: string
splits:
- name: test
num_bytes: 530316641.116
num_examples: 1182
download_size: 564678614
dataset_size: 530316641.116
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
# MedEBench 🩺
**MedEBench** is a comprehensive benchmark for text-guided image editing in the medical domain. It features over **1,200+ real-world medical operation samples** spanning **13 anatomical regions** and **70 clinically relevant editing operations**.
---
## 📁 Dataset Structure
```
MedEBench/
└── editing/
├── changed/ # Ground truth images
├── previous/ # Original images
├── previous_mask/ # ROI masks
└── editing_metadata.json # Metadata file
```
---
Each sample contains:
- `id`: Unique identifier
- `Organ`: Edited anatomical region (e.g., Teeth, Skin)
- `prompt`: Natural language instruction
- `rephrased_prompt`: Rewritten version
- `detailed_prompt`: Detailed description of change and expected effect
- `previous_image`: Path to original image
- `changed_image`: Path to edited image
- `previous_mask`: Binary mask of the target editing region
---
## 🔗 Links
- **Project Website:** [https://mliuby.github.io/MedEBench_Website/](https://mliuby.github.io/MedEBench_Website/)
- **arXiv Paper:** [https://arxiv.org/abs/2506.01921](https://arxiv.org/abs/2506.01921)
---
## 🏷️ License
**License:** [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) – for research and non-commercial use only. |
deeponh/codingdecodingtask | deeponh | 2025-06-04T11:26:48Z | 41 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-29T12:41:26Z | null | ---
dataset_info:
features:
- name: set number
dtype: string
- name: question
dtype: string
- name: reasoning
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 101006
num_examples: 123
download_size: 41100
dataset_size: 101006
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
nyuuzyou/Minecraft-Skins-20M | nyuuzyou | 2025-06-04T11:16:46Z | 0 | 0 | [
"task_categories:image-classification",
"task_categories:text-to-image",
"annotations_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"license:other",
"size_categories:10M<n<100M",
"format:json",
"modality:text",
"modality:image",
"library:datasets",
"library:dask",
"library:mlcroissant",
"region:us",
"image"
] | [
"image-classification",
"text-to-image"
] | 2025-06-03T21:17:18Z | null | ---
pretty_name: Minecraft Skins Dataset
size_categories:
- 10M<n<100M
task_categories:
- image-classification
- text-to-image
annotations_creators:
- found
multilinguality:
- monolingual
source_datasets:
- original
configs:
- config_name: default
data_files:
- split: train
path: "dataset_*.jsonl.zst"
default: true
tags:
- image
license:
- other
---
# Dataset Card for Minecraft Skins
### Dataset Summary
This dataset contains 19,973,928 unique Minecraft player skins collected from various sources. Each skin is stored as a base64-encoded image with a unique identifier.
## Dataset Structure
### Data Fields
This dataset includes the following fields:
- `id`: A randomly generated UUID for each skin entry. These UUIDs are not linked to any external APIs or services (such as Mojang's player UUIDs) and serve solely as unique identifiers within this dataset.
- `image`: The skin image encoded in base64 format.
### Data Splits
All examples are in the train split, there is no validation split.
### Data Format
- **Format**: JSONL (JSON Lines) compressed with Zstandard (.jsonl.zst)
- **File Structure**: Multiple files containing approximately 100,000 entries each
- **Total Entries**: 19,973,928 unique skins
- **Image Format**: Base64-encoded PNG images (64x64 pixels, standard Minecraft skin format)
### Disclaimer
This dataset is not affiliated with, endorsed by, or associated with Microsoft Corporation or Mojang Studios. Minecraft is a trademark of Microsoft Corporation and Mojang Studios. This dataset is provided for research and educational purposes only.
|
myothiha/ontobench_path_vqa | myothiha | 2025-06-04T11:16:15Z | 48 | 0 | [
"license:mit",
"format:parquet",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-28T09:51:18Z | null | ---
license: mit
dataset_info:
features: []
splits:
- name: train
num_bytes: 0
num_examples: 0
download_size: 324
dataset_size: 0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
igzi/MNLP_M3_document_repo | igzi | 2025-06-04T11:06:42Z | 0 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:06:34Z | null | ---
dataset_info:
features:
- name: text
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 77874805
num_examples: 100000
download_size: 45295691
dataset_size: 77874805
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
matthewchung74/mchp-1_0y-5min-bars | matthewchung74 | 2025-06-04T11:05:42Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:05:39Z | null | ---
dataset_info:
features:
- name: symbol
dtype: string
- name: timestamp
dtype: string
- name: open
dtype: float64
- name: high
dtype: float64
- name: low
dtype: float64
- name: close
dtype: float64
- name: volume
dtype: float64
- name: trade_count
dtype: float64
- name: vwap
dtype: float64
configs:
- config_name: default
data_files:
- split: train
path: data/mchp_1_0_years_5min.csv
download_size: 1572319
dataset_size: 19653
---
# MCHP 5-Minute Stock Data (1.0 Years)
This dataset contains 1.0 years of MCHP stock market data downloaded from Alpaca Markets.
## Dataset Description
- **Symbol**: MCHP
- **Duration**: 1.0 years
- **Timeframe**: 5-minute bars
- **Market Hours**: 9:30 AM - 4:00 PM EST only
- **Data Source**: Alpaca Markets API
- **Last Updated**: 2025-06-04
## Features
- `symbol`: Stock symbol (always "MCHP")
- `timestamp`: Timestamp in Eastern Time (EST/EDT)
- `open`: Opening price for the 5-minute period
- `high`: Highest price during the 5-minute period
- `low`: Lowest price during the 5-minute period
- `close`: Closing price for the 5-minute period
- `volume`: Number of shares traded
- `trade_count`: Number of individual trades
- `vwap`: Volume Weighted Average Price
## Data Quality
- Only includes data during regular market hours (9:30 AM - 4:00 PM EST)
- Excludes weekends and holidays when markets are closed
- Approximately 19,653 records covering ~1.0 years of trading data
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("matthewchung74/mchp-1_0y-5min-bars")
df = dataset['train'].to_pandas()
```
## Price Statistics
- **Price Range**: $34.12 - $96.98
- **Average Volume**: 105,885
- **Date Range**: 2024-06-04 09:30:00-04:00 to 2025-06-03 16:00:00-04:00
## License
This dataset is provided under the MIT license. The underlying market data is sourced from Alpaca Markets.
|
mansaripo/corpus_mcm_2023_2024 | mansaripo | 2025-06-04T11:04:50Z | 102 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-02T18:53:53Z | null | ---
dataset_info:
features:
- name: full_prefix
dtype: string
- name: completion
dtype: string
- name: contradiction_0
dtype: string
- name: contradiction_1
dtype: string
- name: contradiction_2
dtype: string
- name: explanation
dtype: string
splits:
- name: test
num_bytes: 1359743
num_examples: 1000
download_size: 766717
dataset_size: 1359743
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
pavan-naik/kan_to_eng_claude_v3 | pavan-naik | 2025-06-04T11:03:22Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T11:03:15Z | null | ---
dataset_info:
features:
- name: id
dtype: uint64
- name: word_range
dtype: string
- name: kannada
dtype: string
- name: english
dtype: string
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 71194749
num_examples: 40000
- name: test
num_bytes: 17950843
num_examples: 10000
- name: test_small
num_bytes: 3590168.6
num_examples: 2000
download_size: 42234638
dataset_size: 92735760.6
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: test_small
path: data/test_small-*
---
|
kaiserbuffle/hanoiv6 | kaiserbuffle | 2025-06-04T10:56:13Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so101",
"hanoi tower"
] | [
"robotics"
] | 2025-06-03T14:50:54Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so101
- hanoi tower
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "so101",
"total_episodes": 6,
"total_frames": 37625,
"total_tasks": 1,
"total_videos": 12,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:6"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.wrist": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"observation.images.base": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
nduque/robustness_e9_2 | nduque | 2025-06-04T10:55:49Z | 0 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"tutorial"
] | [
"robotics"
] | 2025-06-04T10:54:57Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "koch",
"total_episodes": 130,
"total_frames": 67302,
"total_tasks": 1,
"total_videos": 260,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:130"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.front": {
"dtype": "video",
"shape": [
720,
1280,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 720,
"video.width": 1280,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"observation.images.above": {
"dtype": "video",
"shape": [
720,
1280,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 720,
"video.width": 1280,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
ChavyvAkvar/synthetic-trades-BTC-batch-47 | ChavyvAkvar | 2025-06-04T10:49:41Z | 0 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T10:48:38Z | null | ---
dataset_info:
features:
- name: scenario_id
dtype: string
- name: final_pnl_ratio
dtype: float64
- name: max_drawdown
dtype: float64
- name: total_trades
dtype: int64
- name: synthetic_ohlc_open
sequence: float64
- name: synthetic_ohlc_high
sequence: float64
- name: synthetic_ohlc_low
sequence: float64
- name: synthetic_ohlc_close
sequence: float64
- name: garch_params_used_for_sim_str
dtype: string
- name: strategy_params_str
dtype: string
- name: strategy_exit_rules_str
dtype: string
splits:
- name: train
num_bytes: 923450989
num_examples: 1000
download_size: 924489649
dataset_size: 923450989
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
french-datasets/rntc_tmp-multitask-fr-clinical-sft | french-datasets | 2025-06-04T10:47:31Z | 0 | 0 | [
"language:fra",
"region:us"
] | [] | 2025-06-04T10:47:13Z | null | ---
language:
- fra
viewer: false
---
Ce répertoire est vide, il a été créé pour améliorer le référencement du jeu de données [rntc/tmp-multitask-fr-clinical-sft](https://huggingface.co/datasets/rntc/tmp-multitask-fr-clinical-sft). |
raresense/Bracelets_Dataset | raresense | 2025-06-04T10:21:41Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T10:21:13Z | null | ---
dataset_info:
features:
- name: target
dtype: image
- name: mask
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 305176549.0
num_examples: 632
download_size: 296134352
dataset_size: 305176549.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
french-datasets/ahmadSiddiqi_x-stance_fr | french-datasets | 2025-06-04T10:20:21Z | 0 | 0 | [
"task_categories:text-classification",
"language:fra",
"region:us"
] | [
"text-classification"
] | 2025-06-04T10:20:02Z | null | ---
language:
- fra
viewer: false
task_categories:
- text-classification
---
Ce répertoire est vide, il a été créé pour améliorer le référencement du jeu de données [ahmadSiddiqi/x-stance_fr](https://huggingface.co/datasets/ahmadSiddiqi/x-stance_fr). |
french-datasets/ahmadSiddiqi_fr-retrieval-syntec-s2p | french-datasets | 2025-06-04T10:18:43Z | 0 | 0 | [
"task_categories:text-retrieval",
"language:fra",
"region:us"
] | [
"text-retrieval"
] | 2025-06-04T10:18:13Z | null | ---
language:
- fra
viewer: false
task_categories:
- text-retrieval
---
Ce répertoire est vide, il a été créé pour améliorer le référencement du jeu de données [ahmadSiddiqi/fr-retrieval-syntec-s2p](https://huggingface.co/datasets/ahmadSiddiqi/fr-retrieval-syntec-s2p). |
vishwam-101/devanagariScripts | vishwam-101 | 2025-06-04T10:18:19Z | 0 | 0 | [
"license:apache-2.0",
"region:us"
] | [] | 2025-06-04T10:18:19Z | null | ---
license: apache-2.0
---
|
french-datasets/ahmadSiddiqi_mtop_domain_fr | french-datasets | 2025-06-04T10:17:45Z | 0 | 0 | [
"task_categories:text-classification",
"language:fra",
"region:us"
] | [
"text-classification"
] | 2025-06-04T10:17:30Z | null | ---
language:
- fra
viewer: false
task_categories:
- text-classification
---
Ce répertoire est vide, il a été créé pour améliorer le référencement du jeu de données [ahmadSiddiqi/mtop_domain_fr](https://huggingface.co/datasets/ahmadSiddiqi/mtop_domain_fr). |
french-datasets/ahmadSiddiqi_sentiments_fr | french-datasets | 2025-06-04T10:15:23Z | 0 | 0 | [
"task_categories:text-classification",
"language:fra",
"region:us"
] | [
"text-classification"
] | 2025-06-04T10:14:34Z | null | ---
language:
- fra
viewer: false
task_categories:
- text-classification
---
Ce répertoire est vide, il a été créé pour améliorer le référencement du jeu de données [ahmadSiddiqi/sentiments_fr](https://huggingface.co/datasets/ahmadSiddiqi/sentiments_fr). |
dwb2023/azure-ai-engineer-golden-dataset | dwb2023 | 2025-06-04T09:56:52Z | 20 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-02T18:38:26Z | null | ---
dataset_info:
features:
- name: user_input
dtype: string
- name: reference_contexts
sequence: string
- name: reference
dtype: string
- name: synthesizer_name
dtype: string
splits:
- name: train
num_bytes: 223514
num_examples: 34
download_size: 28373
dataset_size: 223514
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Subsets and Splits