Spaces:
Build error

Build error
amanSethSmava
commited on
Commit
·
6d314be
1
Parent(s):
ad9e404
new commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .DS_Store +0 -0
- LICENSE +21 -0
- README.md +169 -0
- app.py +0 -0
- datasets/__init__.py +0 -0
- datasets/image_dataset.py +29 -0
- docs/assets/diagram.webp +3 -0
- docs/assets/logo.webp +3 -0
- hair_swap.py +139 -0
- inference_server.py +5 -0
- losses/.DS_Store +0 -0
- losses/__init__.py +0 -0
- losses/lpips/__init__.py +160 -0
- losses/lpips/base_model.py +58 -0
- losses/lpips/dist_model.py +284 -0
- losses/lpips/networks_basic.py +187 -0
- losses/lpips/pretrained_networks.py +181 -0
- losses/masked_lpips/__init__.py +199 -0
- losses/masked_lpips/base_model.py +65 -0
- losses/masked_lpips/dist_model.py +325 -0
- losses/masked_lpips/networks_basic.py +331 -0
- losses/masked_lpips/pretrained_networks.py +190 -0
- losses/pp_losses.py +677 -0
- losses/style/__init__.py +0 -0
- losses/style/custom_loss.py +67 -0
- losses/style/style_loss.py +113 -0
- losses/style/vgg_activations.py +187 -0
- losses/vgg_loss.py +51 -0
- main.py +80 -0
- models/.DS_Store +0 -0
- models/Alignment.py +181 -0
- models/Blending.py +81 -0
- models/CtrlHair/.gitignore +8 -0
- models/CtrlHair/README.md +270 -0
- models/CtrlHair/color_texture_branch/__init__.py +8 -0
- models/CtrlHair/color_texture_branch/config.py +141 -0
- models/CtrlHair/color_texture_branch/dataset.py +158 -0
- models/CtrlHair/color_texture_branch/model.py +159 -0
- models/CtrlHair/color_texture_branch/model_eigengan.py +89 -0
- models/CtrlHair/color_texture_branch/module.py +61 -0
- models/CtrlHair/color_texture_branch/predictor/__init__.py +8 -0
- models/CtrlHair/color_texture_branch/predictor/predictor_config.py +119 -0
- models/CtrlHair/color_texture_branch/predictor/predictor_model.py +41 -0
- models/CtrlHair/color_texture_branch/predictor/predictor_solver.py +51 -0
- models/CtrlHair/color_texture_branch/predictor/predictor_train.py +159 -0
- models/CtrlHair/color_texture_branch/script_find_direction.py +74 -0
- models/CtrlHair/color_texture_branch/solver.py +299 -0
- models/CtrlHair/color_texture_branch/train.py +166 -0
- models/CtrlHair/color_texture_branch/validation_in_train.py +299 -0
- models/CtrlHair/common_dataset.py +104 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 AIRI - Artificial Intelligence Research Institute
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach
|
| 2 |
+
|
| 3 |
+
<a href="https://arxiv.org/abs/2404.01094"><img src="https://img.shields.io/badge/arXiv-2404.01094-b31b1b.svg" height=22.5></a>
|
| 4 |
+
<a href="https://huggingface.co/spaces/AIRI-Institute/HairFastGAN"><img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/open-in-hf-spaces-md.svg" height=22.5></a>
|
| 5 |
+
<a href="https://colab.research.google.com/#fileId=https://huggingface.co/AIRI-Institute/HairFastGAN/blob/main/notebooks/HairFast_inference.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" height=22.5></a>
|
| 6 |
+
[](./LICENSE)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
> Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100.
|
| 10 |
+
>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<img src="docs/assets/logo.webp" alt="Teaser"/>
|
| 14 |
+
<br>
|
| 15 |
+
The proposed HairFast framework allows to edit a hairstyle on an arbitrary photo based on an example from other photos. Here we have an example of how the method works by transferring a hairstyle from one photo and a hair color from another.
|
| 16 |
+
</p>
|
| 17 |
+
|
| 18 |
+
## Updates
|
| 19 |
+
|
| 20 |
+
- [25/09/2024] 🎉🎉🎉 HairFastGAN has been accepted by [NeurIPS 2024](https://nips.cc/virtual/2024/poster/93397).
|
| 21 |
+
- [24/05/2024] 🌟🌟🌟 Release of the [official demo](https://huggingface.co/spaces/AIRI-Institute/HairFastGAN) on Hugging Face 🤗.
|
| 22 |
+
- [01/04/2024] 🔥🔥🔥 HairFastGAN release.
|
| 23 |
+
|
| 24 |
+
## Prerequisites
|
| 25 |
+
You need following hardware and python version to run our method.
|
| 26 |
+
- Linux
|
| 27 |
+
- NVIDIA GPU + CUDA CuDNN
|
| 28 |
+
- Python 3.10
|
| 29 |
+
- PyTorch 1.13.1+
|
| 30 |
+
|
| 31 |
+
## Installation
|
| 32 |
+
|
| 33 |
+
* Clone this repo:
|
| 34 |
+
```bash
|
| 35 |
+
git clone https://github.com/AIRI-Institute/HairFastGAN
|
| 36 |
+
cd HairFastGAN
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
* Download all pretrained models:
|
| 40 |
+
```bash
|
| 41 |
+
git clone https://huggingface.co/AIRI-Institute/HairFastGAN
|
| 42 |
+
cd HairFastGAN && git lfs pull && cd ..
|
| 43 |
+
mv HairFastGAN/pretrained_models pretrained_models
|
| 44 |
+
mv HairFastGAN/input input
|
| 45 |
+
rm -rf HairFastGAN
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
* Setting the environment
|
| 49 |
+
|
| 50 |
+
**Option 1 [recommended]**, install [Poetry](https://python-poetry.org/docs/) and then:
|
| 51 |
+
```bash
|
| 52 |
+
poetry install
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
**Option 2**, just install the dependencies in your environment:
|
| 56 |
+
```bash
|
| 57 |
+
pip install -r requirements.txt
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## Inference
|
| 61 |
+
You can use `main.py` to run the method, either for a single run or for a batch of experiments.
|
| 62 |
+
|
| 63 |
+
* An example of running a single experiment:
|
| 64 |
+
|
| 65 |
+
```
|
| 66 |
+
python main.py --face_path=6.png --shape_path=7.png --color_path=8.png \
|
| 67 |
+
--input_dir=input --result_path=output/result.png
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
* To run the batch version, first create an image triples file (face/shape/color):
|
| 71 |
+
```
|
| 72 |
+
cat > example.txt << EOF
|
| 73 |
+
6.png 7.png 8.png
|
| 74 |
+
8.png 4.jpg 5.jpg
|
| 75 |
+
EOF
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
And now you can run the method:
|
| 79 |
+
```
|
| 80 |
+
python main.py --file_path=example.txt --input_dir=input --output_dir=output
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
* You can use HairFast in the code directly:
|
| 84 |
+
|
| 85 |
+
```python
|
| 86 |
+
from hair_swap import HairFast, get_parser
|
| 87 |
+
|
| 88 |
+
# Init HairFast
|
| 89 |
+
hair_fast = HairFast(get_parser().parse_args([]))
|
| 90 |
+
|
| 91 |
+
# Inference
|
| 92 |
+
result = hair_fast(face_img, shape_img, color_img)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
See the code for input parameters and output formats.
|
| 96 |
+
|
| 97 |
+
* Alternatively, you can use our [Colab Notebook](https://colab.research.google.com/#fileId=https://huggingface.co/AIRI-Institute/HairFastGAN/blob/main/notebooks/HairFast_inference.ipynb) to prepare the environment, download the code, pretrained weights, and allow you to run experiments with a convenient form.
|
| 98 |
+
|
| 99 |
+
* You can also try our method on the [Hugging Face demo](https://huggingface.co/spaces/AIRI-Institute/HairFastGAN) 🤗.
|
| 100 |
+
|
| 101 |
+
## Scripts
|
| 102 |
+
|
| 103 |
+
There is a list of scripts below, see arguments via --help for details.
|
| 104 |
+
|
| 105 |
+
| Path | Description <img width=200>
|
| 106 |
+
|:----------------------------------------| :---
|
| 107 |
+
| scripts/align_face.py | Processing of raw photos for inference
|
| 108 |
+
| scripts/fid_metric.py | Metrics calculation
|
| 109 |
+
| scripts/rotate_gen.py | Dataset generation for rotate encoder training
|
| 110 |
+
| scripts/blending_gen.py | Dataset generation for color encoder training
|
| 111 |
+
| scripts/pp_gen.py | Dataset generation for refinement encoder training
|
| 112 |
+
| scripts/rotate_train.py | Rotate encoder training
|
| 113 |
+
| scripts/blending_train.py | Color encoder training
|
| 114 |
+
| scripts/pp_train.py | Refinement encoder training
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
## Training
|
| 118 |
+
For training, you need to generate a dataset and then run the scripts for training. See the scripts section above.
|
| 119 |
+
|
| 120 |
+
We use [Weights & Biases](https://wandb.ai/home) to track experiments. Before training, you should put your W&B API key into the `WANDB_KEY` environment variable.
|
| 121 |
+
|
| 122 |
+
## Method diagram
|
| 123 |
+
|
| 124 |
+
<p align="center">
|
| 125 |
+
<img src="https://huggingface.co/AIRI-Institute/HairFastGAN/resolve/main/docs/assets/diagram.webp" alt="Diagram"/>
|
| 126 |
+
<br>
|
| 127 |
+
Overview of HairFast: the images first pass through the Pose alignment module, which generates a pose-aligned face mask with the desired hair shape. Then we transfer the desired hairstyle shape using Shape alignment and the desired hair color using Color alignment. In the last step, Refinement alignment returns the lost details of the original image where they are needed.
|
| 128 |
+
</p>
|
| 129 |
+
|
| 130 |
+
## Repository structure
|
| 131 |
+
|
| 132 |
+
.
|
| 133 |
+
├── 📂 datasets # Implementation of torch datasets for inference
|
| 134 |
+
├── 📂 docs # Folder with method diagram and teaser
|
| 135 |
+
├── 📂 models # Folder containting all the models
|
| 136 |
+
│ ├── ...
|
| 137 |
+
│ ├── 📄 Embedding.py # Implementation of Embedding module
|
| 138 |
+
│ ├── 📄 Alignment.py # Implementation of Pose and Shape alignment modules
|
| 139 |
+
│ ├── 📄 Blending.py # Implementation of Color and Refinement alignment modules
|
| 140 |
+
│ ├── 📄 Encoders.py # Implementation of encoder architectures
|
| 141 |
+
│ └── 📄 Net.py # Implementation of basic models
|
| 142 |
+
│
|
| 143 |
+
├── 📂 losses # Folder containing various loss criterias for training
|
| 144 |
+
├── 📂 scripts # Folder with various scripts
|
| 145 |
+
├── 📂 utils # Folder with utility functions
|
| 146 |
+
│
|
| 147 |
+
├── 📜 poetry.lock # Records exact dependency versions.
|
| 148 |
+
├── 📜 pyproject.toml # Poetry configuration for dependencies.
|
| 149 |
+
├── 📜 requirements.txt # Lists required Python packages.
|
| 150 |
+
├── 📄 hair_swap.py # Implementation of the HairFast main class
|
| 151 |
+
└── 📄 main.py # Script for inference
|
| 152 |
+
|
| 153 |
+
## References & Acknowledgments
|
| 154 |
+
|
| 155 |
+
The repository was started from [Barbershop](https://github.com/ZPdesu/Barbershop).
|
| 156 |
+
|
| 157 |
+
The code [CtrlHair](https://github.com/XuyangGuo/CtrlHair), [SEAN](https://github.com/ZPdesu/SEAN), [HairCLIP](https://github.com/wty-ustc/HairCLIP), [FSE](https://github.com/InterDigitalInc/FeatureStyleEncoder), [E4E](https://github.com/omertov/encoder4editing) and [STAR](https://github.com/ZhenglinZhou/STAR) was also used.
|
| 158 |
+
|
| 159 |
+
## Citation
|
| 160 |
+
|
| 161 |
+
If you use this code for your research, please cite our paper:
|
| 162 |
+
```
|
| 163 |
+
@article{nikolaev2024hairfastgan,
|
| 164 |
+
title={HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach},
|
| 165 |
+
author={Nikolaev, Maxim and Kuznetsov, Mikhail and Vetrov, Dmitry and Alanov, Aibek},
|
| 166 |
+
journal={arXiv preprint arXiv:2404.01094},
|
| 167 |
+
year={2024}
|
| 168 |
+
}
|
| 169 |
+
```
|
app.py
ADDED
|
File without changes
|
datasets/__init__.py
ADDED
|
File without changes
|
datasets/image_dataset.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class ImagesDataset(Dataset):
|
| 6 |
+
def __init__(self, images: dict[torch.Tensor, list[str]] | list[torch.Tensor]):
|
| 7 |
+
if isinstance(images, list):
|
| 8 |
+
images = dict.fromkeys(images)
|
| 9 |
+
|
| 10 |
+
self.images = list(images)
|
| 11 |
+
self.names = list(images.values())
|
| 12 |
+
|
| 13 |
+
def __len__(self):
|
| 14 |
+
return len(self.images)
|
| 15 |
+
|
| 16 |
+
def __getitem__(self, index):
|
| 17 |
+
image = self.images[index]
|
| 18 |
+
|
| 19 |
+
if image.dtype is torch.uint8:
|
| 20 |
+
image = image / 255
|
| 21 |
+
|
| 22 |
+
names = self.names[index]
|
| 23 |
+
return image, names
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def image_collate(batch):
|
| 27 |
+
images = torch.stack([item[0] for item in batch])
|
| 28 |
+
names = [item[1] for item in batch]
|
| 29 |
+
return images, names
|
docs/assets/diagram.webp
ADDED

|
Git LFS Details
|
docs/assets/logo.webp
ADDED
|
|
Git LFS Details
|
hair_swap.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import typing as tp
|
| 3 |
+
from collections import defaultdict
|
| 4 |
+
from functools import wraps
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torchvision.transforms.functional as F
|
| 10 |
+
from PIL import Image
|
| 11 |
+
from torchvision.io import read_image, ImageReadMode
|
| 12 |
+
|
| 13 |
+
from models.Alignment import Alignment
|
| 14 |
+
from models.Blending import Blending
|
| 15 |
+
from models.Embedding import Embedding
|
| 16 |
+
from models.Net import Net
|
| 17 |
+
from utils.image_utils import equal_replacer
|
| 18 |
+
from utils.seed import seed_setter
|
| 19 |
+
from utils.shape_predictor import align_face
|
| 20 |
+
from utils.time import bench_session
|
| 21 |
+
|
| 22 |
+
TImage = tp.TypeVar('TImage', torch.Tensor, Image.Image, np.ndarray)
|
| 23 |
+
TPath = tp.TypeVar('TPath', Path, str)
|
| 24 |
+
TReturn = tp.TypeVar('TReturn', torch.Tensor, tuple[torch.Tensor, ...])
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class HairFast:
|
| 28 |
+
"""
|
| 29 |
+
HairFast implementation with hairstyle transfer interface
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
def __init__(self, args):
|
| 33 |
+
self.args = args
|
| 34 |
+
self.net = Net(self.args)
|
| 35 |
+
self.embed = Embedding(args, net=self.net)
|
| 36 |
+
self.align = Alignment(args, self.embed.get_e4e_embed, net=self.net)
|
| 37 |
+
self.blend = Blending(args, net=self.net)
|
| 38 |
+
|
| 39 |
+
@seed_setter
|
| 40 |
+
@bench_session
|
| 41 |
+
def __swap_from_tensors(self, face: torch.Tensor, shape: torch.Tensor, color: torch.Tensor,
|
| 42 |
+
**kwargs) -> torch.Tensor:
|
| 43 |
+
images_to_name = defaultdict(list)
|
| 44 |
+
for image, name in zip((face, shape, color), ('face', 'shape', 'color')):
|
| 45 |
+
images_to_name[image].append(name)
|
| 46 |
+
|
| 47 |
+
# Embedding stage
|
| 48 |
+
name_to_embed = self.embed.embedding_images(images_to_name, **kwargs)
|
| 49 |
+
|
| 50 |
+
# Alignment stage
|
| 51 |
+
align_shape = self.align.align_images('face', 'shape', name_to_embed, **kwargs)
|
| 52 |
+
|
| 53 |
+
# Shape Module stage for blending
|
| 54 |
+
if shape is not color:
|
| 55 |
+
align_color = self.align.shape_module('face', 'color', name_to_embed, **kwargs)
|
| 56 |
+
else:
|
| 57 |
+
align_color = align_shape
|
| 58 |
+
|
| 59 |
+
# Blending and Post Process stage
|
| 60 |
+
final_image = self.blend.blend_images(align_shape, align_color, name_to_embed, **kwargs)
|
| 61 |
+
return final_image
|
| 62 |
+
|
| 63 |
+
def swap(self, face_img: TImage | TPath, shape_img: TImage | TPath, color_img: TImage | TPath,
|
| 64 |
+
benchmark=False, align=False, seed=None, exp_name=None, **kwargs) -> TReturn:
|
| 65 |
+
"""
|
| 66 |
+
Run HairFast on the input images to transfer hair shape and color to the desired images.
|
| 67 |
+
:param face_img: face image in Tensor, PIL Image, array or file path format
|
| 68 |
+
:param shape_img: shape image in Tensor, PIL Image, array or file path format
|
| 69 |
+
:param color_img: color image in Tensor, PIL Image, array or file path format
|
| 70 |
+
:param benchmark: starts counting the speed of the session
|
| 71 |
+
:param align: for arbitrary photos crops images to faces
|
| 72 |
+
:param seed: fixes seed for reproducibility, default 3407
|
| 73 |
+
:param exp_name: used as a folder name when 'save_all' model is enabled
|
| 74 |
+
:return: returns the final image as a Tensor
|
| 75 |
+
"""
|
| 76 |
+
images: list[torch.Tensor] = []
|
| 77 |
+
path_to_images: dict[TPath, torch.Tensor] = {}
|
| 78 |
+
|
| 79 |
+
for img in (face_img, shape_img, color_img):
|
| 80 |
+
if isinstance(img, (torch.Tensor, Image.Image, np.ndarray)):
|
| 81 |
+
if not isinstance(img, torch.Tensor):
|
| 82 |
+
img = F.to_tensor(img)
|
| 83 |
+
elif isinstance(img, (Path, str)):
|
| 84 |
+
path_img = img
|
| 85 |
+
if path_img not in path_to_images:
|
| 86 |
+
path_to_images[path_img] = read_image(str(path_img), mode=ImageReadMode.RGB)
|
| 87 |
+
img = path_to_images[path_img]
|
| 88 |
+
else:
|
| 89 |
+
raise TypeError(f'Unsupported image format {type(img)}')
|
| 90 |
+
|
| 91 |
+
images.append(img)
|
| 92 |
+
|
| 93 |
+
if align:
|
| 94 |
+
images = align_face(images)
|
| 95 |
+
images = equal_replacer(images)
|
| 96 |
+
|
| 97 |
+
final_image = self.__swap_from_tensors(*images, seed=seed, benchmark=benchmark, exp_name=exp_name, **kwargs)
|
| 98 |
+
|
| 99 |
+
if align:
|
| 100 |
+
return final_image, *images
|
| 101 |
+
return final_image
|
| 102 |
+
|
| 103 |
+
@wraps(swap)
|
| 104 |
+
def __call__(self, *args, **kwargs):
|
| 105 |
+
return self.swap(*args, **kwargs)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def get_parser():
|
| 109 |
+
parser = argparse.ArgumentParser(description='HairFast')
|
| 110 |
+
|
| 111 |
+
# I/O arguments
|
| 112 |
+
parser.add_argument('--save_all_dir', type=Path, default=Path('output'),
|
| 113 |
+
help='the directory to save the latent codes and inversion images')
|
| 114 |
+
|
| 115 |
+
# StyleGAN2 setting
|
| 116 |
+
parser.add_argument('--size', type=int, default=1024)
|
| 117 |
+
parser.add_argument('--ckpt', type=str, default="pretrained_models/StyleGAN/ffhq.pt")
|
| 118 |
+
parser.add_argument('--channel_multiplier', type=int, default=2)
|
| 119 |
+
parser.add_argument('--latent', type=int, default=512)
|
| 120 |
+
parser.add_argument('--n_mlp', type=int, default=8)
|
| 121 |
+
|
| 122 |
+
# Arguments
|
| 123 |
+
parser.add_argument('--device', type=str, default='cuda')
|
| 124 |
+
parser.add_argument('--batch_size', type=int, default=3, help='batch size for encoding images')
|
| 125 |
+
parser.add_argument('--save_all', action='store_true', help='save and print mode information')
|
| 126 |
+
|
| 127 |
+
# HairFast setting
|
| 128 |
+
parser.add_argument('--mixing', type=float, default=0.95, help='hair blending in alignment')
|
| 129 |
+
parser.add_argument('--smooth', type=int, default=5, help='dilation and erosion parameter')
|
| 130 |
+
parser.add_argument('--rotate_checkpoint', type=str, default='pretrained_models/Rotate/rotate_best.pth')
|
| 131 |
+
parser.add_argument('--blending_checkpoint', type=str, default='pretrained_models/Blending/checkpoint.pth')
|
| 132 |
+
parser.add_argument('--pp_checkpoint', type=str, default='pretrained_models/PostProcess/pp_model.pth')
|
| 133 |
+
return parser
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
if __name__ == '__main__':
|
| 137 |
+
model_args = get_parser()
|
| 138 |
+
args = model_args.parse_args()
|
| 139 |
+
hair_fast = HairFast(args)
|
inference_server.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
if __name__ == "__main__":
|
| 2 |
+
server = grpc.server(...)
|
| 3 |
+
...
|
| 4 |
+
server.start()
|
| 5 |
+
server.wait_for_termination()
|
losses/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
losses/__init__.py
ADDED
|
File without changes
|
losses/lpips/__init__.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
from __future__ import division
|
| 4 |
+
from __future__ import print_function
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
from skimage.metrics import structural_similarity
|
| 8 |
+
import torch
|
| 9 |
+
from torch.autograd import Variable
|
| 10 |
+
|
| 11 |
+
from ..lpips import dist_model
|
| 12 |
+
|
| 13 |
+
class PerceptualLoss(torch.nn.Module):
|
| 14 |
+
def __init__(self, model='net-lin', net='alex', colorspace='rgb', spatial=False, use_gpu=True, gpu_ids=[0]): # VGG using our perceptually-learned weights (LPIPS metric)
|
| 15 |
+
# def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
|
| 16 |
+
super(PerceptualLoss, self).__init__()
|
| 17 |
+
print('Setting up Perceptual loss...')
|
| 18 |
+
self.use_gpu = use_gpu
|
| 19 |
+
self.spatial = spatial
|
| 20 |
+
self.gpu_ids = gpu_ids
|
| 21 |
+
self.model = dist_model.DistModel()
|
| 22 |
+
self.model.initialize(model=model, net=net, use_gpu=use_gpu, colorspace=colorspace, spatial=self.spatial, gpu_ids=gpu_ids)
|
| 23 |
+
print('...[%s] initialized'%self.model.name())
|
| 24 |
+
print('...Done')
|
| 25 |
+
|
| 26 |
+
def forward(self, pred, target, normalize=False):
|
| 27 |
+
"""
|
| 28 |
+
Pred and target are Variables.
|
| 29 |
+
If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
|
| 30 |
+
If normalize is False, assumes the images are already between [-1,+1]
|
| 31 |
+
|
| 32 |
+
Inputs pred and target are Nx3xHxW
|
| 33 |
+
Output pytorch Variable N long
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
if normalize:
|
| 37 |
+
target = 2 * target - 1
|
| 38 |
+
pred = 2 * pred - 1
|
| 39 |
+
|
| 40 |
+
return self.model.forward(target, pred)
|
| 41 |
+
|
| 42 |
+
def normalize_tensor(in_feat,eps=1e-10):
|
| 43 |
+
norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
|
| 44 |
+
return in_feat/(norm_factor+eps)
|
| 45 |
+
|
| 46 |
+
def l2(p0, p1, range=255.):
|
| 47 |
+
return .5*np.mean((p0 / range - p1 / range)**2)
|
| 48 |
+
|
| 49 |
+
def psnr(p0, p1, peak=255.):
|
| 50 |
+
return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
|
| 51 |
+
|
| 52 |
+
def dssim(p0, p1, range=255.):
|
| 53 |
+
return (1 - structural_similarity(p0, p1, data_range=range, multichannel=True)) / 2.
|
| 54 |
+
|
| 55 |
+
def rgb2lab(in_img,mean_cent=False):
|
| 56 |
+
from skimage import color
|
| 57 |
+
img_lab = color.rgb2lab(in_img)
|
| 58 |
+
if(mean_cent):
|
| 59 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 60 |
+
return img_lab
|
| 61 |
+
|
| 62 |
+
def tensor2np(tensor_obj):
|
| 63 |
+
# change dimension of a tensor object into a numpy array
|
| 64 |
+
return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
|
| 65 |
+
|
| 66 |
+
def np2tensor(np_obj):
|
| 67 |
+
# change dimenion of np array into tensor array
|
| 68 |
+
return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
| 69 |
+
|
| 70 |
+
def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
|
| 71 |
+
# image tensor to lab tensor
|
| 72 |
+
from skimage import color
|
| 73 |
+
|
| 74 |
+
img = tensor2im(image_tensor)
|
| 75 |
+
img_lab = color.rgb2lab(img)
|
| 76 |
+
if(mc_only):
|
| 77 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 78 |
+
if(to_norm and not mc_only):
|
| 79 |
+
img_lab[:,:,0] = img_lab[:,:,0]-50
|
| 80 |
+
img_lab = img_lab/100.
|
| 81 |
+
|
| 82 |
+
return np2tensor(img_lab)
|
| 83 |
+
|
| 84 |
+
def tensorlab2tensor(lab_tensor,return_inbnd=False):
|
| 85 |
+
from skimage import color
|
| 86 |
+
import warnings
|
| 87 |
+
warnings.filterwarnings("ignore")
|
| 88 |
+
|
| 89 |
+
lab = tensor2np(lab_tensor)*100.
|
| 90 |
+
lab[:,:,0] = lab[:,:,0]+50
|
| 91 |
+
|
| 92 |
+
rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
|
| 93 |
+
if(return_inbnd):
|
| 94 |
+
# convert back to lab, see if we match
|
| 95 |
+
lab_back = color.rgb2lab(rgb_back.astype('uint8'))
|
| 96 |
+
mask = 1.*np.isclose(lab_back,lab,atol=2.)
|
| 97 |
+
mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
|
| 98 |
+
return (im2tensor(rgb_back),mask)
|
| 99 |
+
else:
|
| 100 |
+
return im2tensor(rgb_back)
|
| 101 |
+
|
| 102 |
+
def rgb2lab(input):
|
| 103 |
+
from skimage import color
|
| 104 |
+
return color.rgb2lab(input / 255.)
|
| 105 |
+
|
| 106 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
|
| 107 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 108 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 109 |
+
return image_numpy.astype(imtype)
|
| 110 |
+
|
| 111 |
+
def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
|
| 112 |
+
return torch.Tensor((image / factor - cent)
|
| 113 |
+
[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
| 114 |
+
|
| 115 |
+
def tensor2vec(vector_tensor):
|
| 116 |
+
return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
|
| 117 |
+
|
| 118 |
+
def voc_ap(rec, prec, use_07_metric=False):
|
| 119 |
+
""" ap = voc_ap(rec, prec, [use_07_metric])
|
| 120 |
+
Compute VOC AP given precision and recall.
|
| 121 |
+
If use_07_metric is true, uses the
|
| 122 |
+
VOC 07 11 point method (default:False).
|
| 123 |
+
"""
|
| 124 |
+
if use_07_metric:
|
| 125 |
+
# 11 point metric
|
| 126 |
+
ap = 0.
|
| 127 |
+
for t in np.arange(0., 1.1, 0.1):
|
| 128 |
+
if np.sum(rec >= t) == 0:
|
| 129 |
+
p = 0
|
| 130 |
+
else:
|
| 131 |
+
p = np.max(prec[rec >= t])
|
| 132 |
+
ap = ap + p / 11.
|
| 133 |
+
else:
|
| 134 |
+
# correct AP calculation
|
| 135 |
+
# first append sentinel values at the end
|
| 136 |
+
mrec = np.concatenate(([0.], rec, [1.]))
|
| 137 |
+
mpre = np.concatenate(([0.], prec, [0.]))
|
| 138 |
+
|
| 139 |
+
# compute the precision envelope
|
| 140 |
+
for i in range(mpre.size - 1, 0, -1):
|
| 141 |
+
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
|
| 142 |
+
|
| 143 |
+
# to calculate area under PR curve, look for points
|
| 144 |
+
# where X axis (recall) changes value
|
| 145 |
+
i = np.where(mrec[1:] != mrec[:-1])[0]
|
| 146 |
+
|
| 147 |
+
# and sum (\Delta recall) * prec
|
| 148 |
+
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
|
| 149 |
+
return ap
|
| 150 |
+
|
| 151 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
|
| 152 |
+
# def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
|
| 153 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 154 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 155 |
+
return image_numpy.astype(imtype)
|
| 156 |
+
|
| 157 |
+
def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
|
| 158 |
+
# def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
|
| 159 |
+
return torch.Tensor((image / factor - cent)
|
| 160 |
+
[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
losses/lpips/base_model.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch.autograd import Variable
|
| 5 |
+
from pdb import set_trace as st
|
| 6 |
+
from IPython import embed
|
| 7 |
+
|
| 8 |
+
class BaseModel():
|
| 9 |
+
def __init__(self):
|
| 10 |
+
pass;
|
| 11 |
+
|
| 12 |
+
def name(self):
|
| 13 |
+
return 'BaseModel'
|
| 14 |
+
|
| 15 |
+
def initialize(self, use_gpu=True, gpu_ids=[0]):
|
| 16 |
+
self.use_gpu = use_gpu
|
| 17 |
+
self.gpu_ids = gpu_ids
|
| 18 |
+
|
| 19 |
+
def forward(self):
|
| 20 |
+
pass
|
| 21 |
+
|
| 22 |
+
def get_image_paths(self):
|
| 23 |
+
pass
|
| 24 |
+
|
| 25 |
+
def optimize_parameters(self):
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
def get_current_visuals(self):
|
| 29 |
+
return self.input
|
| 30 |
+
|
| 31 |
+
def get_current_errors(self):
|
| 32 |
+
return {}
|
| 33 |
+
|
| 34 |
+
def save(self, label):
|
| 35 |
+
pass
|
| 36 |
+
|
| 37 |
+
# helper saving function that can be used by subclasses
|
| 38 |
+
def save_network(self, network, path, network_label, epoch_label):
|
| 39 |
+
save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
|
| 40 |
+
save_path = os.path.join(path, save_filename)
|
| 41 |
+
torch.save(network.state_dict(), save_path)
|
| 42 |
+
|
| 43 |
+
# helper loading function that can be used by subclasses
|
| 44 |
+
def load_network(self, network, network_label, epoch_label):
|
| 45 |
+
save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
|
| 46 |
+
save_path = os.path.join(self.save_dir, save_filename)
|
| 47 |
+
print('Loading network from %s'%save_path)
|
| 48 |
+
network.load_state_dict(torch.load(save_path))
|
| 49 |
+
|
| 50 |
+
def update_learning_rate():
|
| 51 |
+
pass
|
| 52 |
+
|
| 53 |
+
def get_image_paths(self):
|
| 54 |
+
return self.image_paths
|
| 55 |
+
|
| 56 |
+
def save_done(self, flag=False):
|
| 57 |
+
np.save(os.path.join(self.save_dir, 'done_flag'),flag)
|
| 58 |
+
np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
|
losses/lpips/dist_model.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
|
| 4 |
+
import sys
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
import os
|
| 9 |
+
from collections import OrderedDict
|
| 10 |
+
from torch.autograd import Variable
|
| 11 |
+
import itertools
|
| 12 |
+
from .base_model import BaseModel
|
| 13 |
+
from scipy.ndimage import zoom
|
| 14 |
+
import fractions
|
| 15 |
+
import functools
|
| 16 |
+
import skimage.transform
|
| 17 |
+
from tqdm import tqdm
|
| 18 |
+
|
| 19 |
+
from IPython import embed
|
| 20 |
+
|
| 21 |
+
from . import networks_basic as networks
|
| 22 |
+
from losses import lpips as util
|
| 23 |
+
|
| 24 |
+
class DistModel(BaseModel):
|
| 25 |
+
def name(self):
|
| 26 |
+
return self.model_name
|
| 27 |
+
|
| 28 |
+
def initialize(self, model='net-lin', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
|
| 29 |
+
use_gpu=True, printNet=False, spatial=False,
|
| 30 |
+
is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
|
| 31 |
+
'''
|
| 32 |
+
INPUTS
|
| 33 |
+
model - ['net-lin'] for linearly calibrated network
|
| 34 |
+
['net'] for off-the-shelf network
|
| 35 |
+
['L2'] for L2 distance in Lab colorspace
|
| 36 |
+
['SSIM'] for ssim in RGB colorspace
|
| 37 |
+
net - ['squeeze','alex','vgg']
|
| 38 |
+
model_path - if None, will look in weights/[NET_NAME].pth
|
| 39 |
+
colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
|
| 40 |
+
use_gpu - bool - whether or not to use a GPU
|
| 41 |
+
printNet - bool - whether or not to print network architecture out
|
| 42 |
+
spatial - bool - whether to output an array containing varying distances across spatial dimensions
|
| 43 |
+
spatial_shape - if given, output spatial shape. if None then spatial shape is determined automatically via spatial_factor (see below).
|
| 44 |
+
spatial_factor - if given, specifies upsampling factor relative to the largest spatial extent of a convolutional layer. if None then resized to size of input images.
|
| 45 |
+
spatial_order - spline order of filter for upsampling in spatial mode, by default 1 (bilinear).
|
| 46 |
+
is_train - bool - [True] for training mode
|
| 47 |
+
lr - float - initial learning rate
|
| 48 |
+
beta1 - float - initial momentum term for adam
|
| 49 |
+
version - 0.1 for latest, 0.0 was original (with a bug)
|
| 50 |
+
gpu_ids - int array - [0] by default, gpus to use
|
| 51 |
+
'''
|
| 52 |
+
BaseModel.initialize(self, use_gpu=use_gpu, gpu_ids=gpu_ids)
|
| 53 |
+
|
| 54 |
+
self.model = model
|
| 55 |
+
self.net = net
|
| 56 |
+
self.is_train = is_train
|
| 57 |
+
self.spatial = spatial
|
| 58 |
+
self.gpu_ids = gpu_ids
|
| 59 |
+
self.model_name = '%s [%s]'%(model,net)
|
| 60 |
+
|
| 61 |
+
if(self.model == 'net-lin'): # pretrained net + linear layer
|
| 62 |
+
self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_tune=pnet_tune, pnet_type=net,
|
| 63 |
+
use_dropout=True, spatial=spatial, version=version, lpips=True)
|
| 64 |
+
kw = {}
|
| 65 |
+
if not use_gpu:
|
| 66 |
+
kw['map_location'] = 'cpu'
|
| 67 |
+
if(model_path is None):
|
| 68 |
+
import inspect
|
| 69 |
+
model_path = os.path.abspath(os.path.join(inspect.getfile(self.initialize), '..', 'weights/v%s/%s.pth'%(version,net)))
|
| 70 |
+
|
| 71 |
+
if(not is_train):
|
| 72 |
+
print('Loading model from: %s'%model_path)
|
| 73 |
+
self.net.load_state_dict(torch.load(model_path, **kw), strict=False)
|
| 74 |
+
|
| 75 |
+
elif(self.model=='net'): # pretrained network
|
| 76 |
+
self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_type=net, lpips=False)
|
| 77 |
+
elif(self.model in ['L2','l2']):
|
| 78 |
+
self.net = networks.L2(use_gpu=use_gpu,colorspace=colorspace) # not really a network, only for testing
|
| 79 |
+
self.model_name = 'L2'
|
| 80 |
+
elif(self.model in ['DSSIM','dssim','SSIM','ssim']):
|
| 81 |
+
self.net = networks.DSSIM(use_gpu=use_gpu,colorspace=colorspace)
|
| 82 |
+
self.model_name = 'SSIM'
|
| 83 |
+
else:
|
| 84 |
+
raise ValueError("Model [%s] not recognized." % self.model)
|
| 85 |
+
|
| 86 |
+
self.parameters = list(self.net.parameters())
|
| 87 |
+
|
| 88 |
+
if self.is_train: # training mode
|
| 89 |
+
# extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
|
| 90 |
+
self.rankLoss = networks.BCERankingLoss()
|
| 91 |
+
self.parameters += list(self.rankLoss.net.parameters())
|
| 92 |
+
self.lr = lr
|
| 93 |
+
self.old_lr = lr
|
| 94 |
+
self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
|
| 95 |
+
else: # test mode
|
| 96 |
+
self.net.eval()
|
| 97 |
+
|
| 98 |
+
if(use_gpu):
|
| 99 |
+
self.net.to(gpu_ids[0])
|
| 100 |
+
self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
|
| 101 |
+
if(self.is_train):
|
| 102 |
+
self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
|
| 103 |
+
|
| 104 |
+
if(printNet):
|
| 105 |
+
print('---------- Networks initialized -------------')
|
| 106 |
+
networks.print_network(self.net)
|
| 107 |
+
print('-----------------------------------------------')
|
| 108 |
+
|
| 109 |
+
def forward(self, in0, in1, retPerLayer=False):
|
| 110 |
+
''' Function computes the distance between image patches in0 and in1
|
| 111 |
+
INPUTS
|
| 112 |
+
in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
|
| 113 |
+
OUTPUT
|
| 114 |
+
computed distances between in0 and in1
|
| 115 |
+
'''
|
| 116 |
+
|
| 117 |
+
return self.net.forward(in0, in1, retPerLayer=retPerLayer)
|
| 118 |
+
|
| 119 |
+
# ***** TRAINING FUNCTIONS *****
|
| 120 |
+
def optimize_parameters(self):
|
| 121 |
+
self.forward_train()
|
| 122 |
+
self.optimizer_net.zero_grad()
|
| 123 |
+
self.backward_train()
|
| 124 |
+
self.optimizer_net.step()
|
| 125 |
+
self.clamp_weights()
|
| 126 |
+
|
| 127 |
+
def clamp_weights(self):
|
| 128 |
+
for module in self.net.modules():
|
| 129 |
+
if(hasattr(module, 'weight') and module.kernel_size==(1,1)):
|
| 130 |
+
module.weight.data = torch.clamp(module.weight.data,min=0)
|
| 131 |
+
|
| 132 |
+
def set_input(self, data):
|
| 133 |
+
self.input_ref = data['ref']
|
| 134 |
+
self.input_p0 = data['p0']
|
| 135 |
+
self.input_p1 = data['p1']
|
| 136 |
+
self.input_judge = data['judge']
|
| 137 |
+
|
| 138 |
+
if(self.use_gpu):
|
| 139 |
+
self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
|
| 140 |
+
self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
|
| 141 |
+
self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
|
| 142 |
+
self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
|
| 143 |
+
|
| 144 |
+
self.var_ref = Variable(self.input_ref,requires_grad=True)
|
| 145 |
+
self.var_p0 = Variable(self.input_p0,requires_grad=True)
|
| 146 |
+
self.var_p1 = Variable(self.input_p1,requires_grad=True)
|
| 147 |
+
|
| 148 |
+
def forward_train(self): # run forward pass
|
| 149 |
+
# print(self.net.module.scaling_layer.shift)
|
| 150 |
+
# print(torch.norm(self.net.module.net.slice1[0].weight).item(), torch.norm(self.net.module.lin0.model[1].weight).item())
|
| 151 |
+
|
| 152 |
+
self.d0 = self.forward(self.var_ref, self.var_p0)
|
| 153 |
+
self.d1 = self.forward(self.var_ref, self.var_p1)
|
| 154 |
+
self.acc_r = self.compute_accuracy(self.d0,self.d1,self.input_judge)
|
| 155 |
+
|
| 156 |
+
self.var_judge = Variable(1.*self.input_judge).view(self.d0.size())
|
| 157 |
+
|
| 158 |
+
self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge*2.-1.)
|
| 159 |
+
|
| 160 |
+
return self.loss_total
|
| 161 |
+
|
| 162 |
+
def backward_train(self):
|
| 163 |
+
torch.mean(self.loss_total).backward()
|
| 164 |
+
|
| 165 |
+
def compute_accuracy(self,d0,d1,judge):
|
| 166 |
+
''' d0, d1 are Variables, judge is a Tensor '''
|
| 167 |
+
d1_lt_d0 = (d1<d0).cpu().data.numpy().flatten()
|
| 168 |
+
judge_per = judge.cpu().numpy().flatten()
|
| 169 |
+
return d1_lt_d0*judge_per + (1-d1_lt_d0)*(1-judge_per)
|
| 170 |
+
|
| 171 |
+
def get_current_errors(self):
|
| 172 |
+
retDict = OrderedDict([('loss_total', self.loss_total.data.cpu().numpy()),
|
| 173 |
+
('acc_r', self.acc_r)])
|
| 174 |
+
|
| 175 |
+
for key in retDict.keys():
|
| 176 |
+
retDict[key] = np.mean(retDict[key])
|
| 177 |
+
|
| 178 |
+
return retDict
|
| 179 |
+
|
| 180 |
+
def get_current_visuals(self):
|
| 181 |
+
zoom_factor = 256/self.var_ref.data.size()[2]
|
| 182 |
+
|
| 183 |
+
ref_img = util.tensor2im(self.var_ref.data)
|
| 184 |
+
p0_img = util.tensor2im(self.var_p0.data)
|
| 185 |
+
p1_img = util.tensor2im(self.var_p1.data)
|
| 186 |
+
|
| 187 |
+
ref_img_vis = zoom(ref_img,[zoom_factor, zoom_factor, 1],order=0)
|
| 188 |
+
p0_img_vis = zoom(p0_img,[zoom_factor, zoom_factor, 1],order=0)
|
| 189 |
+
p1_img_vis = zoom(p1_img,[zoom_factor, zoom_factor, 1],order=0)
|
| 190 |
+
|
| 191 |
+
return OrderedDict([('ref', ref_img_vis),
|
| 192 |
+
('p0', p0_img_vis),
|
| 193 |
+
('p1', p1_img_vis)])
|
| 194 |
+
|
| 195 |
+
def save(self, path, label):
|
| 196 |
+
if(self.use_gpu):
|
| 197 |
+
self.save_network(self.net.module, path, '', label)
|
| 198 |
+
else:
|
| 199 |
+
self.save_network(self.net, path, '', label)
|
| 200 |
+
self.save_network(self.rankLoss.net, path, 'rank', label)
|
| 201 |
+
|
| 202 |
+
def update_learning_rate(self,nepoch_decay):
|
| 203 |
+
lrd = self.lr / nepoch_decay
|
| 204 |
+
lr = self.old_lr - lrd
|
| 205 |
+
|
| 206 |
+
for param_group in self.optimizer_net.param_groups:
|
| 207 |
+
param_group['lr'] = lr
|
| 208 |
+
|
| 209 |
+
print('update lr [%s] decay: %f -> %f' % (type,self.old_lr, lr))
|
| 210 |
+
self.old_lr = lr
|
| 211 |
+
|
| 212 |
+
def score_2afc_dataset(data_loader, func, name=''):
|
| 213 |
+
''' Function computes Two Alternative Forced Choice (2AFC) score using
|
| 214 |
+
distance function 'func' in dataset 'data_loader'
|
| 215 |
+
INPUTS
|
| 216 |
+
data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
|
| 217 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 218 |
+
pytorch tensors with shape Nx3xXxY, and return numpy array of length N
|
| 219 |
+
OUTPUTS
|
| 220 |
+
[0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
|
| 221 |
+
[1] - dictionary with following elements
|
| 222 |
+
d0s,d1s - N arrays containing distances between reference patch to perturbed patches
|
| 223 |
+
gts - N array in [0,1], preferred patch selected by human evaluators
|
| 224 |
+
(closer to "0" for left patch p0, "1" for right patch p1,
|
| 225 |
+
"0.6" means 60pct people preferred right patch, 40pct preferred left)
|
| 226 |
+
scores - N array in [0,1], corresponding to what percentage function agreed with humans
|
| 227 |
+
CONSTS
|
| 228 |
+
N - number of test triplets in data_loader
|
| 229 |
+
'''
|
| 230 |
+
|
| 231 |
+
d0s = []
|
| 232 |
+
d1s = []
|
| 233 |
+
gts = []
|
| 234 |
+
|
| 235 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 236 |
+
d0s+=func(data['ref'],data['p0']).data.cpu().numpy().flatten().tolist()
|
| 237 |
+
d1s+=func(data['ref'],data['p1']).data.cpu().numpy().flatten().tolist()
|
| 238 |
+
gts+=data['judge'].cpu().numpy().flatten().tolist()
|
| 239 |
+
|
| 240 |
+
d0s = np.array(d0s)
|
| 241 |
+
d1s = np.array(d1s)
|
| 242 |
+
gts = np.array(gts)
|
| 243 |
+
scores = (d0s<d1s)*(1.-gts) + (d1s<d0s)*gts + (d1s==d0s)*.5
|
| 244 |
+
|
| 245 |
+
return(np.mean(scores), dict(d0s=d0s,d1s=d1s,gts=gts,scores=scores))
|
| 246 |
+
|
| 247 |
+
def score_jnd_dataset(data_loader, func, name=''):
|
| 248 |
+
''' Function computes JND score using distance function 'func' in dataset 'data_loader'
|
| 249 |
+
INPUTS
|
| 250 |
+
data_loader - CustomDatasetDataLoader object - contains a JNDDataset inside
|
| 251 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 252 |
+
pytorch tensors with shape Nx3xXxY, and return pytorch array of length N
|
| 253 |
+
OUTPUTS
|
| 254 |
+
[0] - JND score in [0,1], mAP score (area under precision-recall curve)
|
| 255 |
+
[1] - dictionary with following elements
|
| 256 |
+
ds - N array containing distances between two patches shown to human evaluator
|
| 257 |
+
sames - N array containing fraction of people who thought the two patches were identical
|
| 258 |
+
CONSTS
|
| 259 |
+
N - number of test triplets in data_loader
|
| 260 |
+
'''
|
| 261 |
+
|
| 262 |
+
ds = []
|
| 263 |
+
gts = []
|
| 264 |
+
|
| 265 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 266 |
+
ds+=func(data['p0'],data['p1']).data.cpu().numpy().tolist()
|
| 267 |
+
gts+=data['same'].cpu().numpy().flatten().tolist()
|
| 268 |
+
|
| 269 |
+
sames = np.array(gts)
|
| 270 |
+
ds = np.array(ds)
|
| 271 |
+
|
| 272 |
+
sorted_inds = np.argsort(ds)
|
| 273 |
+
ds_sorted = ds[sorted_inds]
|
| 274 |
+
sames_sorted = sames[sorted_inds]
|
| 275 |
+
|
| 276 |
+
TPs = np.cumsum(sames_sorted)
|
| 277 |
+
FPs = np.cumsum(1-sames_sorted)
|
| 278 |
+
FNs = np.sum(sames_sorted)-TPs
|
| 279 |
+
|
| 280 |
+
precs = TPs/(TPs+FPs)
|
| 281 |
+
recs = TPs/(TPs+FNs)
|
| 282 |
+
score = util.voc_ap(recs,precs)
|
| 283 |
+
|
| 284 |
+
return(score, dict(ds=ds,sames=sames))
|
losses/lpips/networks_basic.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import absolute_import
|
| 3 |
+
|
| 4 |
+
import sys
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.init as init
|
| 8 |
+
from torch.autograd import Variable
|
| 9 |
+
import numpy as np
|
| 10 |
+
from pdb import set_trace as st
|
| 11 |
+
from skimage import color
|
| 12 |
+
from IPython import embed
|
| 13 |
+
from . import pretrained_networks as pn
|
| 14 |
+
|
| 15 |
+
from losses import lpips as util
|
| 16 |
+
|
| 17 |
+
def spatial_average(in_tens, keepdim=True):
|
| 18 |
+
return in_tens.mean([2,3],keepdim=keepdim)
|
| 19 |
+
|
| 20 |
+
def upsample(in_tens, out_H=64): # assumes scale factor is same for H and W
|
| 21 |
+
in_H = in_tens.shape[2]
|
| 22 |
+
scale_factor = 1.*out_H/in_H
|
| 23 |
+
|
| 24 |
+
return nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=False)(in_tens)
|
| 25 |
+
|
| 26 |
+
# Learned perceptual metric
|
| 27 |
+
class PNetLin(nn.Module):
|
| 28 |
+
def __init__(self, pnet_type='vgg', pnet_rand=False, pnet_tune=False, use_dropout=True, spatial=False, version='0.1', lpips=True):
|
| 29 |
+
super(PNetLin, self).__init__()
|
| 30 |
+
|
| 31 |
+
self.pnet_type = pnet_type
|
| 32 |
+
self.pnet_tune = pnet_tune
|
| 33 |
+
self.pnet_rand = pnet_rand
|
| 34 |
+
self.spatial = spatial
|
| 35 |
+
self.lpips = lpips
|
| 36 |
+
self.version = version
|
| 37 |
+
self.scaling_layer = ScalingLayer()
|
| 38 |
+
|
| 39 |
+
if(self.pnet_type in ['vgg','vgg16']):
|
| 40 |
+
net_type = pn.vgg16
|
| 41 |
+
self.chns = [64,128,256,512,512]
|
| 42 |
+
elif(self.pnet_type=='alex'):
|
| 43 |
+
net_type = pn.alexnet
|
| 44 |
+
self.chns = [64,192,384,256,256]
|
| 45 |
+
elif(self.pnet_type=='squeeze'):
|
| 46 |
+
net_type = pn.squeezenet
|
| 47 |
+
self.chns = [64,128,256,384,384,512,512]
|
| 48 |
+
self.L = len(self.chns)
|
| 49 |
+
|
| 50 |
+
self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
|
| 51 |
+
|
| 52 |
+
if(lpips):
|
| 53 |
+
self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
|
| 54 |
+
self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
|
| 55 |
+
self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
|
| 56 |
+
self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
|
| 57 |
+
self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
|
| 58 |
+
self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
|
| 59 |
+
if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
|
| 60 |
+
self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
|
| 61 |
+
self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
|
| 62 |
+
self.lins+=[self.lin5,self.lin6]
|
| 63 |
+
|
| 64 |
+
def forward(self, in0, in1, retPerLayer=False):
|
| 65 |
+
# v0.0 - original release had a bug, where input was not scaled
|
| 66 |
+
in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
|
| 67 |
+
outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
|
| 68 |
+
feats0, feats1, diffs = {}, {}, {}
|
| 69 |
+
|
| 70 |
+
for kk in range(self.L):
|
| 71 |
+
feats0[kk], feats1[kk] = util.normalize_tensor(outs0[kk]), util.normalize_tensor(outs1[kk])
|
| 72 |
+
diffs[kk] = (feats0[kk]-feats1[kk])**2
|
| 73 |
+
|
| 74 |
+
if(self.lpips):
|
| 75 |
+
if(self.spatial):
|
| 76 |
+
res = [upsample(self.lins[kk].model(diffs[kk]), out_H=in0.shape[2]) for kk in range(self.L)]
|
| 77 |
+
else:
|
| 78 |
+
res = [spatial_average(self.lins[kk].model(diffs[kk]), keepdim=True) for kk in range(self.L)]
|
| 79 |
+
else:
|
| 80 |
+
if(self.spatial):
|
| 81 |
+
res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_H=in0.shape[2]) for kk in range(self.L)]
|
| 82 |
+
else:
|
| 83 |
+
res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
|
| 84 |
+
|
| 85 |
+
val = res[0]
|
| 86 |
+
for l in range(1,self.L):
|
| 87 |
+
val += res[l]
|
| 88 |
+
|
| 89 |
+
if(retPerLayer):
|
| 90 |
+
return (val, res)
|
| 91 |
+
else:
|
| 92 |
+
return val
|
| 93 |
+
|
| 94 |
+
class ScalingLayer(nn.Module):
|
| 95 |
+
def __init__(self):
|
| 96 |
+
super(ScalingLayer, self).__init__()
|
| 97 |
+
self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
|
| 98 |
+
self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
|
| 99 |
+
|
| 100 |
+
def forward(self, inp):
|
| 101 |
+
return (inp - self.shift) / self.scale
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class NetLinLayer(nn.Module):
|
| 105 |
+
''' A single linear layer which does a 1x1 conv '''
|
| 106 |
+
def __init__(self, chn_in, chn_out=1, use_dropout=False):
|
| 107 |
+
super(NetLinLayer, self).__init__()
|
| 108 |
+
|
| 109 |
+
layers = [nn.Dropout(),] if(use_dropout) else []
|
| 110 |
+
layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
|
| 111 |
+
self.model = nn.Sequential(*layers)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class Dist2LogitLayer(nn.Module):
|
| 115 |
+
''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
|
| 116 |
+
def __init__(self, chn_mid=32, use_sigmoid=True):
|
| 117 |
+
super(Dist2LogitLayer, self).__init__()
|
| 118 |
+
|
| 119 |
+
layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
|
| 120 |
+
layers += [nn.LeakyReLU(0.2,True),]
|
| 121 |
+
layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
|
| 122 |
+
layers += [nn.LeakyReLU(0.2,True),]
|
| 123 |
+
layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
|
| 124 |
+
if(use_sigmoid):
|
| 125 |
+
layers += [nn.Sigmoid(),]
|
| 126 |
+
self.model = nn.Sequential(*layers)
|
| 127 |
+
|
| 128 |
+
def forward(self,d0,d1,eps=0.1):
|
| 129 |
+
return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
|
| 130 |
+
|
| 131 |
+
class BCERankingLoss(nn.Module):
|
| 132 |
+
def __init__(self, chn_mid=32):
|
| 133 |
+
super(BCERankingLoss, self).__init__()
|
| 134 |
+
self.net = Dist2LogitLayer(chn_mid=chn_mid)
|
| 135 |
+
# self.parameters = list(self.net.parameters())
|
| 136 |
+
self.loss = torch.nn.BCELoss()
|
| 137 |
+
|
| 138 |
+
def forward(self, d0, d1, judge):
|
| 139 |
+
per = (judge+1.)/2.
|
| 140 |
+
self.logit = self.net.forward(d0,d1)
|
| 141 |
+
return self.loss(self.logit, per)
|
| 142 |
+
|
| 143 |
+
# L2, DSSIM metrics
|
| 144 |
+
class FakeNet(nn.Module):
|
| 145 |
+
def __init__(self, use_gpu=True, colorspace='Lab'):
|
| 146 |
+
super(FakeNet, self).__init__()
|
| 147 |
+
self.use_gpu = use_gpu
|
| 148 |
+
self.colorspace=colorspace
|
| 149 |
+
|
| 150 |
+
class L2(FakeNet):
|
| 151 |
+
|
| 152 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 153 |
+
assert(in0.size()[0]==1) # currently only supports batchSize 1
|
| 154 |
+
|
| 155 |
+
if(self.colorspace=='RGB'):
|
| 156 |
+
(N,C,X,Y) = in0.size()
|
| 157 |
+
value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
|
| 158 |
+
return value
|
| 159 |
+
elif(self.colorspace=='Lab'):
|
| 160 |
+
value = util.l2(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
|
| 161 |
+
util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
|
| 162 |
+
ret_var = Variable( torch.Tensor((value,) ) )
|
| 163 |
+
if(self.use_gpu):
|
| 164 |
+
ret_var = ret_var.cuda()
|
| 165 |
+
return ret_var
|
| 166 |
+
|
| 167 |
+
class DSSIM(FakeNet):
|
| 168 |
+
|
| 169 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 170 |
+
assert(in0.size()[0]==1) # currently only supports batchSize 1
|
| 171 |
+
|
| 172 |
+
if(self.colorspace=='RGB'):
|
| 173 |
+
value = util.dssim(1.*util.tensor2im(in0.data), 1.*util.tensor2im(in1.data), range=255.).astype('float')
|
| 174 |
+
elif(self.colorspace=='Lab'):
|
| 175 |
+
value = util.dssim(util.tensor2np(util.tensor2tensorlab(in0.data,to_norm=False)),
|
| 176 |
+
util.tensor2np(util.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
|
| 177 |
+
ret_var = Variable( torch.Tensor((value,) ) )
|
| 178 |
+
if(self.use_gpu):
|
| 179 |
+
ret_var = ret_var.cuda()
|
| 180 |
+
return ret_var
|
| 181 |
+
|
| 182 |
+
def print_network(net):
|
| 183 |
+
num_params = 0
|
| 184 |
+
for param in net.parameters():
|
| 185 |
+
num_params += param.numel()
|
| 186 |
+
print('Network',net)
|
| 187 |
+
print('Total number of parameters: %d' % num_params)
|
losses/lpips/pretrained_networks.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import namedtuple
|
| 2 |
+
import torch
|
| 3 |
+
from torchvision import models as tv
|
| 4 |
+
from IPython import embed
|
| 5 |
+
|
| 6 |
+
class squeezenet(torch.nn.Module):
|
| 7 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 8 |
+
super(squeezenet, self).__init__()
|
| 9 |
+
pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
|
| 10 |
+
self.slice1 = torch.nn.Sequential()
|
| 11 |
+
self.slice2 = torch.nn.Sequential()
|
| 12 |
+
self.slice3 = torch.nn.Sequential()
|
| 13 |
+
self.slice4 = torch.nn.Sequential()
|
| 14 |
+
self.slice5 = torch.nn.Sequential()
|
| 15 |
+
self.slice6 = torch.nn.Sequential()
|
| 16 |
+
self.slice7 = torch.nn.Sequential()
|
| 17 |
+
self.N_slices = 7
|
| 18 |
+
for x in range(2):
|
| 19 |
+
self.slice1.add_module(str(x), pretrained_features[x])
|
| 20 |
+
for x in range(2,5):
|
| 21 |
+
self.slice2.add_module(str(x), pretrained_features[x])
|
| 22 |
+
for x in range(5, 8):
|
| 23 |
+
self.slice3.add_module(str(x), pretrained_features[x])
|
| 24 |
+
for x in range(8, 10):
|
| 25 |
+
self.slice4.add_module(str(x), pretrained_features[x])
|
| 26 |
+
for x in range(10, 11):
|
| 27 |
+
self.slice5.add_module(str(x), pretrained_features[x])
|
| 28 |
+
for x in range(11, 12):
|
| 29 |
+
self.slice6.add_module(str(x), pretrained_features[x])
|
| 30 |
+
for x in range(12, 13):
|
| 31 |
+
self.slice7.add_module(str(x), pretrained_features[x])
|
| 32 |
+
if not requires_grad:
|
| 33 |
+
for param in self.parameters():
|
| 34 |
+
param.requires_grad = False
|
| 35 |
+
|
| 36 |
+
def forward(self, X):
|
| 37 |
+
h = self.slice1(X)
|
| 38 |
+
h_relu1 = h
|
| 39 |
+
h = self.slice2(h)
|
| 40 |
+
h_relu2 = h
|
| 41 |
+
h = self.slice3(h)
|
| 42 |
+
h_relu3 = h
|
| 43 |
+
h = self.slice4(h)
|
| 44 |
+
h_relu4 = h
|
| 45 |
+
h = self.slice5(h)
|
| 46 |
+
h_relu5 = h
|
| 47 |
+
h = self.slice6(h)
|
| 48 |
+
h_relu6 = h
|
| 49 |
+
h = self.slice7(h)
|
| 50 |
+
h_relu7 = h
|
| 51 |
+
vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
|
| 52 |
+
out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
|
| 53 |
+
|
| 54 |
+
return out
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class alexnet(torch.nn.Module):
|
| 58 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 59 |
+
super(alexnet, self).__init__()
|
| 60 |
+
alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
|
| 61 |
+
self.slice1 = torch.nn.Sequential()
|
| 62 |
+
self.slice2 = torch.nn.Sequential()
|
| 63 |
+
self.slice3 = torch.nn.Sequential()
|
| 64 |
+
self.slice4 = torch.nn.Sequential()
|
| 65 |
+
self.slice5 = torch.nn.Sequential()
|
| 66 |
+
self.N_slices = 5
|
| 67 |
+
for x in range(2):
|
| 68 |
+
self.slice1.add_module(str(x), alexnet_pretrained_features[x])
|
| 69 |
+
for x in range(2, 5):
|
| 70 |
+
self.slice2.add_module(str(x), alexnet_pretrained_features[x])
|
| 71 |
+
for x in range(5, 8):
|
| 72 |
+
self.slice3.add_module(str(x), alexnet_pretrained_features[x])
|
| 73 |
+
for x in range(8, 10):
|
| 74 |
+
self.slice4.add_module(str(x), alexnet_pretrained_features[x])
|
| 75 |
+
for x in range(10, 12):
|
| 76 |
+
self.slice5.add_module(str(x), alexnet_pretrained_features[x])
|
| 77 |
+
if not requires_grad:
|
| 78 |
+
for param in self.parameters():
|
| 79 |
+
param.requires_grad = False
|
| 80 |
+
|
| 81 |
+
def forward(self, X):
|
| 82 |
+
h = self.slice1(X)
|
| 83 |
+
h_relu1 = h
|
| 84 |
+
h = self.slice2(h)
|
| 85 |
+
h_relu2 = h
|
| 86 |
+
h = self.slice3(h)
|
| 87 |
+
h_relu3 = h
|
| 88 |
+
h = self.slice4(h)
|
| 89 |
+
h_relu4 = h
|
| 90 |
+
h = self.slice5(h)
|
| 91 |
+
h_relu5 = h
|
| 92 |
+
alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
|
| 93 |
+
out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
|
| 94 |
+
|
| 95 |
+
return out
|
| 96 |
+
|
| 97 |
+
class vgg16(torch.nn.Module):
|
| 98 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 99 |
+
super(vgg16, self).__init__()
|
| 100 |
+
vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
|
| 101 |
+
self.slice1 = torch.nn.Sequential()
|
| 102 |
+
self.slice2 = torch.nn.Sequential()
|
| 103 |
+
self.slice3 = torch.nn.Sequential()
|
| 104 |
+
self.slice4 = torch.nn.Sequential()
|
| 105 |
+
self.slice5 = torch.nn.Sequential()
|
| 106 |
+
self.N_slices = 5
|
| 107 |
+
for x in range(4):
|
| 108 |
+
self.slice1.add_module(str(x), vgg_pretrained_features[x])
|
| 109 |
+
for x in range(4, 9):
|
| 110 |
+
self.slice2.add_module(str(x), vgg_pretrained_features[x])
|
| 111 |
+
for x in range(9, 16):
|
| 112 |
+
self.slice3.add_module(str(x), vgg_pretrained_features[x])
|
| 113 |
+
for x in range(16, 23):
|
| 114 |
+
self.slice4.add_module(str(x), vgg_pretrained_features[x])
|
| 115 |
+
for x in range(23, 30):
|
| 116 |
+
self.slice5.add_module(str(x), vgg_pretrained_features[x])
|
| 117 |
+
if not requires_grad:
|
| 118 |
+
for param in self.parameters():
|
| 119 |
+
param.requires_grad = False
|
| 120 |
+
|
| 121 |
+
def forward(self, X):
|
| 122 |
+
h = self.slice1(X)
|
| 123 |
+
h_relu1_2 = h
|
| 124 |
+
h = self.slice2(h)
|
| 125 |
+
h_relu2_2 = h
|
| 126 |
+
h = self.slice3(h)
|
| 127 |
+
h_relu3_3 = h
|
| 128 |
+
h = self.slice4(h)
|
| 129 |
+
h_relu4_3 = h
|
| 130 |
+
h = self.slice5(h)
|
| 131 |
+
h_relu5_3 = h
|
| 132 |
+
vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
|
| 133 |
+
out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
|
| 134 |
+
|
| 135 |
+
return out
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class resnet(torch.nn.Module):
|
| 140 |
+
def __init__(self, requires_grad=False, pretrained=True, num=18):
|
| 141 |
+
super(resnet, self).__init__()
|
| 142 |
+
if(num==18):
|
| 143 |
+
self.net = tv.resnet18(pretrained=pretrained)
|
| 144 |
+
elif(num==34):
|
| 145 |
+
self.net = tv.resnet34(pretrained=pretrained)
|
| 146 |
+
elif(num==50):
|
| 147 |
+
self.net = tv.resnet50(pretrained=pretrained)
|
| 148 |
+
elif(num==101):
|
| 149 |
+
self.net = tv.resnet101(pretrained=pretrained)
|
| 150 |
+
elif(num==152):
|
| 151 |
+
self.net = tv.resnet152(pretrained=pretrained)
|
| 152 |
+
self.N_slices = 5
|
| 153 |
+
|
| 154 |
+
self.conv1 = self.net.conv1
|
| 155 |
+
self.bn1 = self.net.bn1
|
| 156 |
+
self.relu = self.net.relu
|
| 157 |
+
self.maxpool = self.net.maxpool
|
| 158 |
+
self.layer1 = self.net.layer1
|
| 159 |
+
self.layer2 = self.net.layer2
|
| 160 |
+
self.layer3 = self.net.layer3
|
| 161 |
+
self.layer4 = self.net.layer4
|
| 162 |
+
|
| 163 |
+
def forward(self, X):
|
| 164 |
+
h = self.conv1(X)
|
| 165 |
+
h = self.bn1(h)
|
| 166 |
+
h = self.relu(h)
|
| 167 |
+
h_relu1 = h
|
| 168 |
+
h = self.maxpool(h)
|
| 169 |
+
h = self.layer1(h)
|
| 170 |
+
h_conv2 = h
|
| 171 |
+
h = self.layer2(h)
|
| 172 |
+
h_conv3 = h
|
| 173 |
+
h = self.layer3(h)
|
| 174 |
+
h_conv4 = h
|
| 175 |
+
h = self.layer4(h)
|
| 176 |
+
h_conv5 = h
|
| 177 |
+
|
| 178 |
+
outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
|
| 179 |
+
out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
|
| 180 |
+
|
| 181 |
+
return out
|
losses/masked_lpips/__init__.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import absolute_import
|
| 2 |
+
from __future__ import division
|
| 3 |
+
from __future__ import print_function
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
from skimage.metrics import structural_similarity
|
| 7 |
+
import torch
|
| 8 |
+
from torch.autograd import Variable
|
| 9 |
+
|
| 10 |
+
from ..masked_lpips import dist_model
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class PerceptualLoss(torch.nn.Module):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
model="net-lin",
|
| 17 |
+
net="alex",
|
| 18 |
+
vgg_blocks=[1, 2, 3, 4, 5],
|
| 19 |
+
colorspace="rgb",
|
| 20 |
+
spatial=False,
|
| 21 |
+
use_gpu=True,
|
| 22 |
+
gpu_ids=[0],
|
| 23 |
+
): # VGG using our perceptually-learned weights (LPIPS metric)
|
| 24 |
+
# def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
|
| 25 |
+
super(PerceptualLoss, self).__init__()
|
| 26 |
+
print("Setting up Perceptual loss...")
|
| 27 |
+
self.use_gpu = use_gpu
|
| 28 |
+
self.spatial = spatial
|
| 29 |
+
self.gpu_ids = gpu_ids
|
| 30 |
+
self.model = dist_model.DistModel()
|
| 31 |
+
self.model.initialize(
|
| 32 |
+
model=model,
|
| 33 |
+
net=net,
|
| 34 |
+
vgg_blocks=vgg_blocks,
|
| 35 |
+
use_gpu=use_gpu,
|
| 36 |
+
colorspace=colorspace,
|
| 37 |
+
spatial=self.spatial,
|
| 38 |
+
gpu_ids=gpu_ids,
|
| 39 |
+
)
|
| 40 |
+
print("...[%s] initialized" % self.model.name())
|
| 41 |
+
print("...Done")
|
| 42 |
+
|
| 43 |
+
def forward(self, pred, target, mask=None, normalize=False):
|
| 44 |
+
"""
|
| 45 |
+
Pred and target are Variables.
|
| 46 |
+
If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
|
| 47 |
+
If normalize is False, assumes the images are already between [-1,+1]
|
| 48 |
+
|
| 49 |
+
Inputs pred and target are Nx3xHxW
|
| 50 |
+
Output pytorch Variable N long
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
if normalize:
|
| 54 |
+
target = 2 * target - 1
|
| 55 |
+
pred = 2 * pred - 1
|
| 56 |
+
|
| 57 |
+
return self.model.forward(target, pred, mask=mask)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def normalize_tensor(in_feat, eps=1e-10):
|
| 61 |
+
# takes care of masked tensors implicitly.
|
| 62 |
+
norm_factor = torch.sqrt(torch.sum(in_feat ** 2, dim=1, keepdim=True))
|
| 63 |
+
return in_feat / (norm_factor + eps)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def l2(p0, p1, range=255.0):
|
| 67 |
+
return 0.5 * np.mean((p0 / range - p1 / range) ** 2)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def psnr(p0, p1, peak=255.0):
|
| 71 |
+
return 10 * np.log10(peak ** 2 / np.mean((1.0 * p0 - 1.0 * p1) ** 2))
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def dssim(p0, p1, range=255.0):
|
| 75 |
+
return (1 - compare_ssim(p0, p1, data_range=range, multichannel=True)) / 2.0
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def rgb2lab(in_img, mean_cent=False):
|
| 79 |
+
from skimage import color
|
| 80 |
+
|
| 81 |
+
img_lab = color.rgb2lab(in_img)
|
| 82 |
+
if mean_cent:
|
| 83 |
+
img_lab[:, :, 0] = img_lab[:, :, 0] - 50
|
| 84 |
+
return img_lab
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def tensor2np(tensor_obj):
|
| 88 |
+
# change dimension of a tensor object into a numpy array
|
| 89 |
+
return tensor_obj[0].cpu().float().numpy().transpose((1, 2, 0))
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def np2tensor(np_obj):
|
| 93 |
+
# change dimenion of np array into tensor array
|
| 94 |
+
return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def tensor2tensorlab(image_tensor, to_norm=True, mc_only=False):
|
| 98 |
+
# image tensor to lab tensor
|
| 99 |
+
from skimage import color
|
| 100 |
+
|
| 101 |
+
img = tensor2im(image_tensor)
|
| 102 |
+
img_lab = color.rgb2lab(img)
|
| 103 |
+
if mc_only:
|
| 104 |
+
img_lab[:, :, 0] = img_lab[:, :, 0] - 50
|
| 105 |
+
if to_norm and not mc_only:
|
| 106 |
+
img_lab[:, :, 0] = img_lab[:, :, 0] - 50
|
| 107 |
+
img_lab = img_lab / 100.0
|
| 108 |
+
|
| 109 |
+
return np2tensor(img_lab)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def tensorlab2tensor(lab_tensor, return_inbnd=False):
|
| 113 |
+
from skimage import color
|
| 114 |
+
import warnings
|
| 115 |
+
|
| 116 |
+
warnings.filterwarnings("ignore")
|
| 117 |
+
|
| 118 |
+
lab = tensor2np(lab_tensor) * 100.0
|
| 119 |
+
lab[:, :, 0] = lab[:, :, 0] + 50
|
| 120 |
+
|
| 121 |
+
rgb_back = 255.0 * np.clip(color.lab2rgb(lab.astype("float")), 0, 1)
|
| 122 |
+
if return_inbnd:
|
| 123 |
+
# convert back to lab, see if we match
|
| 124 |
+
lab_back = color.rgb2lab(rgb_back.astype("uint8"))
|
| 125 |
+
mask = 1.0 * np.isclose(lab_back, lab, atol=2.0)
|
| 126 |
+
mask = np2tensor(np.prod(mask, axis=2)[:, :, np.newaxis])
|
| 127 |
+
return (im2tensor(rgb_back), mask)
|
| 128 |
+
else:
|
| 129 |
+
return im2tensor(rgb_back)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def rgb2lab(input):
|
| 133 |
+
from skimage import color
|
| 134 |
+
|
| 135 |
+
return color.rgb2lab(input / 255.0)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
|
| 139 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 140 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 141 |
+
return image_numpy.astype(imtype)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def im2tensor(image, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
|
| 145 |
+
return torch.Tensor(
|
| 146 |
+
(image / factor - cent)[:, :, :, np.newaxis].transpose((3, 2, 0, 1))
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def tensor2vec(vector_tensor):
|
| 151 |
+
return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def voc_ap(rec, prec, use_07_metric=False):
|
| 155 |
+
"""ap = voc_ap(rec, prec, [use_07_metric])
|
| 156 |
+
Compute VOC AP given precision and recall.
|
| 157 |
+
If use_07_metric is true, uses the
|
| 158 |
+
VOC 07 11 point method (default:False).
|
| 159 |
+
"""
|
| 160 |
+
if use_07_metric:
|
| 161 |
+
# 11 point metric
|
| 162 |
+
ap = 0.0
|
| 163 |
+
for t in np.arange(0.0, 1.1, 0.1):
|
| 164 |
+
if np.sum(rec >= t) == 0:
|
| 165 |
+
p = 0
|
| 166 |
+
else:
|
| 167 |
+
p = np.max(prec[rec >= t])
|
| 168 |
+
ap = ap + p / 11.0
|
| 169 |
+
else:
|
| 170 |
+
# correct AP calculation
|
| 171 |
+
# first append sentinel values at the end
|
| 172 |
+
mrec = np.concatenate(([0.0], rec, [1.0]))
|
| 173 |
+
mpre = np.concatenate(([0.0], prec, [0.0]))
|
| 174 |
+
|
| 175 |
+
# compute the precision envelope
|
| 176 |
+
for i in range(mpre.size - 1, 0, -1):
|
| 177 |
+
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
|
| 178 |
+
|
| 179 |
+
# to calculate area under PR curve, look for points
|
| 180 |
+
# where X axis (recall) changes value
|
| 181 |
+
i = np.where(mrec[1:] != mrec[:-1])[0]
|
| 182 |
+
|
| 183 |
+
# and sum (\Delta recall) * prec
|
| 184 |
+
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
|
| 185 |
+
return ap
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def tensor2im(image_tensor, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
|
| 189 |
+
# def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
|
| 190 |
+
image_numpy = image_tensor[0].cpu().float().numpy()
|
| 191 |
+
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
|
| 192 |
+
return image_numpy.astype(imtype)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def im2tensor(image, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
|
| 196 |
+
# def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
|
| 197 |
+
return torch.Tensor(
|
| 198 |
+
(image / factor - cent)[:, :, :, np.newaxis].transpose((3, 2, 0, 1))
|
| 199 |
+
)
|
losses/masked_lpips/base_model.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch.autograd import Variable
|
| 5 |
+
from pdb import set_trace as st
|
| 6 |
+
from IPython import embed
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class BaseModel:
|
| 10 |
+
def __init__(self):
|
| 11 |
+
pass
|
| 12 |
+
|
| 13 |
+
def name(self):
|
| 14 |
+
return "BaseModel"
|
| 15 |
+
|
| 16 |
+
def initialize(self, use_gpu=True, gpu_ids=[0]):
|
| 17 |
+
self.use_gpu = use_gpu
|
| 18 |
+
self.gpu_ids = gpu_ids
|
| 19 |
+
|
| 20 |
+
def forward(self):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def get_image_paths(self):
|
| 24 |
+
pass
|
| 25 |
+
|
| 26 |
+
def optimize_parameters(self):
|
| 27 |
+
pass
|
| 28 |
+
|
| 29 |
+
def get_current_visuals(self):
|
| 30 |
+
return self.input
|
| 31 |
+
|
| 32 |
+
def get_current_errors(self):
|
| 33 |
+
return {}
|
| 34 |
+
|
| 35 |
+
def save(self, label):
|
| 36 |
+
pass
|
| 37 |
+
|
| 38 |
+
# helper saving function that can be used by subclasses
|
| 39 |
+
def save_network(self, network, path, network_label, epoch_label):
|
| 40 |
+
save_filename = "%s_net_%s.pth" % (epoch_label, network_label)
|
| 41 |
+
save_path = os.path.join(path, save_filename)
|
| 42 |
+
torch.save(network.state_dict(), save_path)
|
| 43 |
+
|
| 44 |
+
# helper loading function that can be used by subclasses
|
| 45 |
+
def load_network(self, network, network_label, epoch_label):
|
| 46 |
+
save_filename = "%s_net_%s.pth" % (epoch_label, network_label)
|
| 47 |
+
save_path = os.path.join(self.save_dir, save_filename)
|
| 48 |
+
print("Loading network from %s" % save_path)
|
| 49 |
+
network.load_state_dict(torch.load(save_path))
|
| 50 |
+
|
| 51 |
+
def update_learning_rate():
|
| 52 |
+
pass
|
| 53 |
+
|
| 54 |
+
def get_image_paths(self):
|
| 55 |
+
return self.image_paths
|
| 56 |
+
|
| 57 |
+
def save_done(self, flag=False):
|
| 58 |
+
np.save(os.path.join(self.save_dir, "done_flag"), flag)
|
| 59 |
+
np.savetxt(
|
| 60 |
+
os.path.join(self.save_dir, "done_flag"),
|
| 61 |
+
[
|
| 62 |
+
flag,
|
| 63 |
+
],
|
| 64 |
+
fmt="%i",
|
| 65 |
+
)
|
losses/masked_lpips/dist_model.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import absolute_import
|
| 2 |
+
|
| 3 |
+
import sys
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
import os
|
| 8 |
+
from collections import OrderedDict
|
| 9 |
+
from torch.autograd import Variable
|
| 10 |
+
import itertools
|
| 11 |
+
from .base_model import BaseModel
|
| 12 |
+
from scipy.ndimage import zoom
|
| 13 |
+
import fractions
|
| 14 |
+
import functools
|
| 15 |
+
import skimage.transform
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
|
| 18 |
+
from IPython import embed
|
| 19 |
+
|
| 20 |
+
from . import networks_basic as netw
|
| 21 |
+
from losses import masked_lpips as util
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class DistModel(BaseModel):
|
| 25 |
+
def name(self):
|
| 26 |
+
return self.model_name
|
| 27 |
+
|
| 28 |
+
def initialize(
|
| 29 |
+
self,
|
| 30 |
+
model="net-lin",
|
| 31 |
+
net="alex",
|
| 32 |
+
vgg_blocks=[1, 2, 3, 4, 5],
|
| 33 |
+
colorspace="Lab",
|
| 34 |
+
pnet_rand=False,
|
| 35 |
+
pnet_tune=False,
|
| 36 |
+
model_path=None,
|
| 37 |
+
use_gpu=True,
|
| 38 |
+
printNet=False,
|
| 39 |
+
spatial=False,
|
| 40 |
+
is_train=False,
|
| 41 |
+
lr=0.0001,
|
| 42 |
+
beta1=0.5,
|
| 43 |
+
version="0.1",
|
| 44 |
+
gpu_ids=[0],
|
| 45 |
+
):
|
| 46 |
+
"""
|
| 47 |
+
INPUTS
|
| 48 |
+
model - ['net-lin'] for linearly calibrated network
|
| 49 |
+
['net'] for off-the-shelf network
|
| 50 |
+
['L2'] for L2 distance in Lab colorspace
|
| 51 |
+
['SSIM'] for ssim in RGB colorspace
|
| 52 |
+
net - ['squeeze','alex','vgg']
|
| 53 |
+
model_path - if None, will look in weights/[NET_NAME].pth
|
| 54 |
+
colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
|
| 55 |
+
use_gpu - bool - whether or not to use a GPU
|
| 56 |
+
printNet - bool - whether or not to print network architecture out
|
| 57 |
+
spatial - bool - whether to output an array containing varying distances across spatial dimensions
|
| 58 |
+
spatial_shape - if given, output spatial shape. if None then spatial shape is determined automatically via spatial_factor (see below).
|
| 59 |
+
spatial_factor - if given, specifies upsampling factor relative to the largest spatial extent of a convolutional layer. if None then resized to size of input images.
|
| 60 |
+
spatial_order - spline order of filter for upsampling in spatial mode, by default 1 (bilinear).
|
| 61 |
+
is_train - bool - [True] for training mode
|
| 62 |
+
lr - float - initial learning rate
|
| 63 |
+
beta1 - float - initial momentum term for adam
|
| 64 |
+
version - 0.1 for latest, 0.0 was original (with a bug)
|
| 65 |
+
gpu_ids - int array - [0] by default, gpus to use
|
| 66 |
+
"""
|
| 67 |
+
BaseModel.initialize(self, use_gpu=use_gpu, gpu_ids=gpu_ids)
|
| 68 |
+
|
| 69 |
+
self.model = model
|
| 70 |
+
self.net = net
|
| 71 |
+
self.is_train = is_train
|
| 72 |
+
self.spatial = spatial
|
| 73 |
+
self.gpu_ids = gpu_ids
|
| 74 |
+
self.model_name = "%s [%s]" % (model, net)
|
| 75 |
+
|
| 76 |
+
if self.model == "net-lin": # pretrained net + linear layer
|
| 77 |
+
self.net = netw.PNetLin(
|
| 78 |
+
pnet_rand=pnet_rand,
|
| 79 |
+
pnet_tune=pnet_tune,
|
| 80 |
+
pnet_type=net,
|
| 81 |
+
use_dropout=True,
|
| 82 |
+
spatial=spatial,
|
| 83 |
+
version=version,
|
| 84 |
+
lpips=True,
|
| 85 |
+
vgg_blocks=vgg_blocks,
|
| 86 |
+
)
|
| 87 |
+
kw = {}
|
| 88 |
+
if not use_gpu:
|
| 89 |
+
kw["map_location"] = "cpu"
|
| 90 |
+
if model_path is None:
|
| 91 |
+
import inspect
|
| 92 |
+
|
| 93 |
+
model_path = os.path.abspath(
|
| 94 |
+
os.path.join(
|
| 95 |
+
inspect.getfile(self.initialize),
|
| 96 |
+
"..",
|
| 97 |
+
"weights/v%s/%s.pth" % (version, net),
|
| 98 |
+
)
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
if not is_train:
|
| 102 |
+
print("Loading model from: %s" % model_path)
|
| 103 |
+
self.net.load_state_dict(torch.load(model_path, **kw), strict=False)
|
| 104 |
+
|
| 105 |
+
elif self.model == "net": # pretrained network
|
| 106 |
+
self.net = netw.PNetLin(pnet_rand=pnet_rand, pnet_type=net, lpips=False)
|
| 107 |
+
elif self.model in ["L2", "l2"]:
|
| 108 |
+
self.net = netw.L2(
|
| 109 |
+
use_gpu=use_gpu, colorspace=colorspace
|
| 110 |
+
) # not really a network, only for testing
|
| 111 |
+
self.model_name = "L2"
|
| 112 |
+
elif self.model in ["DSSIM", "dssim", "SSIM", "ssim"]:
|
| 113 |
+
self.net = netw.DSSIM(use_gpu=use_gpu, colorspace=colorspace)
|
| 114 |
+
self.model_name = "SSIM"
|
| 115 |
+
else:
|
| 116 |
+
raise ValueError("Model [%s] not recognized." % self.model)
|
| 117 |
+
|
| 118 |
+
self.parameters = list(self.net.parameters())
|
| 119 |
+
|
| 120 |
+
if self.is_train: # training mode
|
| 121 |
+
# extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
|
| 122 |
+
self.rankLoss = netw.BCERankingLoss()
|
| 123 |
+
self.parameters += list(self.rankLoss.net.parameters())
|
| 124 |
+
self.lr = lr
|
| 125 |
+
self.old_lr = lr
|
| 126 |
+
self.optimizer_net = torch.optim.Adam(
|
| 127 |
+
self.parameters, lr=lr, betas=(beta1, 0.999)
|
| 128 |
+
)
|
| 129 |
+
else: # test mode
|
| 130 |
+
self.net.eval()
|
| 131 |
+
|
| 132 |
+
if use_gpu:
|
| 133 |
+
self.net.to(gpu_ids[0])
|
| 134 |
+
self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
|
| 135 |
+
if self.is_train:
|
| 136 |
+
self.rankLoss = self.rankLoss.to(
|
| 137 |
+
device=gpu_ids[0]
|
| 138 |
+
) # just put this on GPU0
|
| 139 |
+
|
| 140 |
+
if printNet:
|
| 141 |
+
print("---------- Networks initialized -------------")
|
| 142 |
+
netw.print_network(self.net)
|
| 143 |
+
print("-----------------------------------------------")
|
| 144 |
+
|
| 145 |
+
def forward(self, in0, in1, mask=None, retPerLayer=False):
|
| 146 |
+
"""Function computes the distance between image patches in0 and in1
|
| 147 |
+
INPUTS
|
| 148 |
+
in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
|
| 149 |
+
OUTPUT
|
| 150 |
+
computed distances between in0 and in1
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
return self.net.forward(in0, in1, mask=mask, retPerLayer=retPerLayer)
|
| 154 |
+
|
| 155 |
+
# ***** TRAINING FUNCTIONS *****
|
| 156 |
+
def optimize_parameters(self):
|
| 157 |
+
self.forward_train()
|
| 158 |
+
self.optimizer_net.zero_grad()
|
| 159 |
+
self.backward_train()
|
| 160 |
+
self.optimizer_net.step()
|
| 161 |
+
self.clamp_weights()
|
| 162 |
+
|
| 163 |
+
def clamp_weights(self):
|
| 164 |
+
for module in self.net.modules():
|
| 165 |
+
if hasattr(module, "weight") and module.kernel_size == (1, 1):
|
| 166 |
+
module.weight.data = torch.clamp(module.weight.data, min=0)
|
| 167 |
+
|
| 168 |
+
def set_input(self, data):
|
| 169 |
+
self.input_ref = data["ref"]
|
| 170 |
+
self.input_p0 = data["p0"]
|
| 171 |
+
self.input_p1 = data["p1"]
|
| 172 |
+
self.input_judge = data["judge"]
|
| 173 |
+
|
| 174 |
+
if self.use_gpu:
|
| 175 |
+
self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
|
| 176 |
+
self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
|
| 177 |
+
self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
|
| 178 |
+
self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
|
| 179 |
+
|
| 180 |
+
self.var_ref = Variable(self.input_ref, requires_grad=True)
|
| 181 |
+
self.var_p0 = Variable(self.input_p0, requires_grad=True)
|
| 182 |
+
self.var_p1 = Variable(self.input_p1, requires_grad=True)
|
| 183 |
+
|
| 184 |
+
def forward_train(self): # run forward pass
|
| 185 |
+
# print(self.net.module.scaling_layer.shift)
|
| 186 |
+
# print(torch.norm(self.net.module.net.slice1[0].weight).item(), torch.norm(self.net.module.lin0.model[1].weight).item())
|
| 187 |
+
|
| 188 |
+
self.d0 = self.forward(self.var_ref, self.var_p0)
|
| 189 |
+
self.d1 = self.forward(self.var_ref, self.var_p1)
|
| 190 |
+
self.acc_r = self.compute_accuracy(self.d0, self.d1, self.input_judge)
|
| 191 |
+
|
| 192 |
+
self.var_judge = Variable(1.0 * self.input_judge).view(self.d0.size())
|
| 193 |
+
|
| 194 |
+
self.loss_total = self.rankLoss.forward(
|
| 195 |
+
self.d0, self.d1, self.var_judge * 2.0 - 1.0
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
return self.loss_total
|
| 199 |
+
|
| 200 |
+
def backward_train(self):
|
| 201 |
+
torch.mean(self.loss_total).backward()
|
| 202 |
+
|
| 203 |
+
def compute_accuracy(self, d0, d1, judge):
|
| 204 |
+
""" d0, d1 are Variables, judge is a Tensor """
|
| 205 |
+
d1_lt_d0 = (d1 < d0).cpu().data.numpy().flatten()
|
| 206 |
+
judge_per = judge.cpu().numpy().flatten()
|
| 207 |
+
return d1_lt_d0 * judge_per + (1 - d1_lt_d0) * (1 - judge_per)
|
| 208 |
+
|
| 209 |
+
def get_current_errors(self):
|
| 210 |
+
retDict = OrderedDict(
|
| 211 |
+
[("loss_total", self.loss_total.data.cpu().numpy()), ("acc_r", self.acc_r)]
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
for key in retDict.keys():
|
| 215 |
+
retDict[key] = np.mean(retDict[key])
|
| 216 |
+
|
| 217 |
+
return retDict
|
| 218 |
+
|
| 219 |
+
def get_current_visuals(self):
|
| 220 |
+
zoom_factor = 256 / self.var_ref.data.size()[2]
|
| 221 |
+
|
| 222 |
+
ref_img = util.tensor2im(self.var_ref.data)
|
| 223 |
+
p0_img = util.tensor2im(self.var_p0.data)
|
| 224 |
+
p1_img = util.tensor2im(self.var_p1.data)
|
| 225 |
+
|
| 226 |
+
ref_img_vis = zoom(ref_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 227 |
+
p0_img_vis = zoom(p0_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 228 |
+
p1_img_vis = zoom(p1_img, [zoom_factor, zoom_factor, 1], order=0)
|
| 229 |
+
|
| 230 |
+
return OrderedDict(
|
| 231 |
+
[("ref", ref_img_vis), ("p0", p0_img_vis), ("p1", p1_img_vis)]
|
| 232 |
+
)
|
| 233 |
+
|
| 234 |
+
def save(self, path, label):
|
| 235 |
+
if self.use_gpu:
|
| 236 |
+
self.save_network(self.net.module, path, "", label)
|
| 237 |
+
else:
|
| 238 |
+
self.save_network(self.net, path, "", label)
|
| 239 |
+
self.save_network(self.rankLoss.net, path, "rank", label)
|
| 240 |
+
|
| 241 |
+
def update_learning_rate(self, nepoch_decay):
|
| 242 |
+
lrd = self.lr / nepoch_decay
|
| 243 |
+
lr = self.old_lr - lrd
|
| 244 |
+
|
| 245 |
+
for param_group in self.optimizer_net.param_groups:
|
| 246 |
+
param_group["lr"] = lr
|
| 247 |
+
|
| 248 |
+
print("update lr [%s] decay: %f -> %f" % (type, self.old_lr, lr))
|
| 249 |
+
self.old_lr = lr
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def score_2afc_dataset(data_loader, func, name=""):
|
| 253 |
+
"""Function computes Two Alternative Forced Choice (2AFC) score using
|
| 254 |
+
distance function 'func' in dataset 'data_loader'
|
| 255 |
+
INPUTS
|
| 256 |
+
data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
|
| 257 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 258 |
+
pytorch tensors with shape Nx3xXxY, and return numpy array of length N
|
| 259 |
+
OUTPUTS
|
| 260 |
+
[0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
|
| 261 |
+
[1] - dictionary with following elements
|
| 262 |
+
d0s,d1s - N arrays containing distances between reference patch to perturbed patches
|
| 263 |
+
gts - N array in [0,1], preferred patch selected by human evaluators
|
| 264 |
+
(closer to "0" for left patch p0, "1" for right patch p1,
|
| 265 |
+
"0.6" means 60pct people preferred right patch, 40pct preferred left)
|
| 266 |
+
scores - N array in [0,1], corresponding to what percentage function agreed with humans
|
| 267 |
+
CONSTS
|
| 268 |
+
N - number of test triplets in data_loader
|
| 269 |
+
"""
|
| 270 |
+
|
| 271 |
+
d0s = []
|
| 272 |
+
d1s = []
|
| 273 |
+
gts = []
|
| 274 |
+
|
| 275 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 276 |
+
d0s += func(data["ref"], data["p0"]).data.cpu().numpy().flatten().tolist()
|
| 277 |
+
d1s += func(data["ref"], data["p1"]).data.cpu().numpy().flatten().tolist()
|
| 278 |
+
gts += data["judge"].cpu().numpy().flatten().tolist()
|
| 279 |
+
|
| 280 |
+
d0s = np.array(d0s)
|
| 281 |
+
d1s = np.array(d1s)
|
| 282 |
+
gts = np.array(gts)
|
| 283 |
+
scores = (d0s < d1s) * (1.0 - gts) + (d1s < d0s) * gts + (d1s == d0s) * 0.5
|
| 284 |
+
|
| 285 |
+
return (np.mean(scores), dict(d0s=d0s, d1s=d1s, gts=gts, scores=scores))
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
def score_jnd_dataset(data_loader, func, name=""):
|
| 289 |
+
"""Function computes JND score using distance function 'func' in dataset 'data_loader'
|
| 290 |
+
INPUTS
|
| 291 |
+
data_loader - CustomDatasetDataLoader object - contains a JNDDataset inside
|
| 292 |
+
func - callable distance function - calling d=func(in0,in1) should take 2
|
| 293 |
+
pytorch tensors with shape Nx3xXxY, and return pytorch array of length N
|
| 294 |
+
OUTPUTS
|
| 295 |
+
[0] - JND score in [0,1], mAP score (area under precision-recall curve)
|
| 296 |
+
[1] - dictionary with following elements
|
| 297 |
+
ds - N array containing distances between two patches shown to human evaluator
|
| 298 |
+
sames - N array containing fraction of people who thought the two patches were identical
|
| 299 |
+
CONSTS
|
| 300 |
+
N - number of test triplets in data_loader
|
| 301 |
+
"""
|
| 302 |
+
|
| 303 |
+
ds = []
|
| 304 |
+
gts = []
|
| 305 |
+
|
| 306 |
+
for data in tqdm(data_loader.load_data(), desc=name):
|
| 307 |
+
ds += func(data["p0"], data["p1"]).data.cpu().numpy().tolist()
|
| 308 |
+
gts += data["same"].cpu().numpy().flatten().tolist()
|
| 309 |
+
|
| 310 |
+
sames = np.array(gts)
|
| 311 |
+
ds = np.array(ds)
|
| 312 |
+
|
| 313 |
+
sorted_inds = np.argsort(ds)
|
| 314 |
+
ds_sorted = ds[sorted_inds]
|
| 315 |
+
sames_sorted = sames[sorted_inds]
|
| 316 |
+
|
| 317 |
+
TPs = np.cumsum(sames_sorted)
|
| 318 |
+
FPs = np.cumsum(1 - sames_sorted)
|
| 319 |
+
FNs = np.sum(sames_sorted) - TPs
|
| 320 |
+
|
| 321 |
+
precs = TPs / (TPs + FPs)
|
| 322 |
+
recs = TPs / (TPs + FNs)
|
| 323 |
+
score = util.voc_ap(recs, precs)
|
| 324 |
+
|
| 325 |
+
return (score, dict(ds=ds, sames=sames))
|
losses/masked_lpips/networks_basic.py
ADDED
|
@@ -0,0 +1,331 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import absolute_import
|
| 2 |
+
|
| 3 |
+
import sys
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.init as init
|
| 7 |
+
from torch.autograd import Variable
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
import numpy as np
|
| 10 |
+
from pdb import set_trace as st
|
| 11 |
+
from skimage import color
|
| 12 |
+
from IPython import embed
|
| 13 |
+
from . import pretrained_networks as pn
|
| 14 |
+
|
| 15 |
+
from losses import masked_lpips as util
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def spatial_average(in_tens, mask=None, keepdim=True):
|
| 19 |
+
if mask is None:
|
| 20 |
+
return in_tens.mean([2, 3], keepdim=keepdim)
|
| 21 |
+
else:
|
| 22 |
+
in_tens = in_tens * mask
|
| 23 |
+
|
| 24 |
+
# sum masked_in_tens across spatial dims
|
| 25 |
+
in_tens = in_tens.sum([2, 3], keepdim=keepdim)
|
| 26 |
+
in_tens = in_tens / torch.sum(mask)
|
| 27 |
+
|
| 28 |
+
return in_tens
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def upsample(in_tens, out_H=64): # assumes scale factor is same for H and W
|
| 32 |
+
in_H = in_tens.shape[2]
|
| 33 |
+
scale_factor = 1.0 * out_H / in_H
|
| 34 |
+
|
| 35 |
+
return nn.Upsample(scale_factor=scale_factor, mode="bilinear", align_corners=False)(
|
| 36 |
+
in_tens
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# Learned perceptual metric
|
| 41 |
+
class PNetLin(nn.Module):
|
| 42 |
+
def __init__(
|
| 43 |
+
self,
|
| 44 |
+
pnet_type="vgg",
|
| 45 |
+
pnet_rand=False,
|
| 46 |
+
pnet_tune=False,
|
| 47 |
+
use_dropout=True,
|
| 48 |
+
spatial=False,
|
| 49 |
+
version="0.1",
|
| 50 |
+
lpips=True,
|
| 51 |
+
vgg_blocks=[1, 2, 3, 4, 5]
|
| 52 |
+
):
|
| 53 |
+
super(PNetLin, self).__init__()
|
| 54 |
+
|
| 55 |
+
self.pnet_type = pnet_type
|
| 56 |
+
self.pnet_tune = pnet_tune
|
| 57 |
+
self.pnet_rand = pnet_rand
|
| 58 |
+
self.spatial = spatial
|
| 59 |
+
self.lpips = lpips
|
| 60 |
+
self.version = version
|
| 61 |
+
self.scaling_layer = ScalingLayer()
|
| 62 |
+
|
| 63 |
+
if self.pnet_type in ["vgg", "vgg16"]:
|
| 64 |
+
net_type = pn.vgg16
|
| 65 |
+
self.blocks = vgg_blocks
|
| 66 |
+
self.chns = []
|
| 67 |
+
self.chns = [64, 128, 256, 512, 512]
|
| 68 |
+
|
| 69 |
+
elif self.pnet_type == "alex":
|
| 70 |
+
net_type = pn.alexnet
|
| 71 |
+
self.chns = [64, 192, 384, 256, 256]
|
| 72 |
+
elif self.pnet_type == "squeeze":
|
| 73 |
+
net_type = pn.squeezenet
|
| 74 |
+
self.chns = [64, 128, 256, 384, 384, 512, 512]
|
| 75 |
+
self.L = len(self.chns)
|
| 76 |
+
|
| 77 |
+
self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
|
| 78 |
+
|
| 79 |
+
if lpips:
|
| 80 |
+
self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
|
| 81 |
+
self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
|
| 82 |
+
self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
|
| 83 |
+
self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
|
| 84 |
+
self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
|
| 85 |
+
self.lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
|
| 86 |
+
#self.lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
|
| 87 |
+
if self.pnet_type == "squeeze": # 7 layers for squeezenet
|
| 88 |
+
self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
|
| 89 |
+
self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
|
| 90 |
+
self.lins += [self.lin5, self.lin6]
|
| 91 |
+
|
| 92 |
+
def forward(self, in0, in1, mask=None, retPerLayer=False):
|
| 93 |
+
# blocks: list of layer names
|
| 94 |
+
|
| 95 |
+
# v0.0 - original release had a bug, where input was not scaled
|
| 96 |
+
in0_input, in1_input = (
|
| 97 |
+
(self.scaling_layer(in0), self.scaling_layer(in1))
|
| 98 |
+
if self.version == "0.1"
|
| 99 |
+
else (in0, in1)
|
| 100 |
+
)
|
| 101 |
+
outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
|
| 102 |
+
feats0, feats1, diffs = {}, {}, {}
|
| 103 |
+
|
| 104 |
+
# prepare list of masks at different resolutions
|
| 105 |
+
if mask is not None:
|
| 106 |
+
masks = []
|
| 107 |
+
if len(mask.shape) == 3:
|
| 108 |
+
mask = torch.unsqueeze(mask, axis=0) # 4D
|
| 109 |
+
|
| 110 |
+
for kk in range(self.L):
|
| 111 |
+
N, C, H, W = outs0[kk].shape
|
| 112 |
+
mask = F.interpolate(mask, size=(H, W), mode="nearest")
|
| 113 |
+
masks.append(mask)
|
| 114 |
+
|
| 115 |
+
"""
|
| 116 |
+
outs0 has 5 feature maps
|
| 117 |
+
1. [1, 64, 256, 256]
|
| 118 |
+
2. [1, 128, 128, 128]
|
| 119 |
+
3. [1, 256, 64, 64]
|
| 120 |
+
4. [1, 512, 32, 32]
|
| 121 |
+
5. [1, 512, 16, 16]
|
| 122 |
+
"""
|
| 123 |
+
for kk in range(self.L):
|
| 124 |
+
feats0[kk], feats1[kk] = (
|
| 125 |
+
util.normalize_tensor(outs0[kk]),
|
| 126 |
+
util.normalize_tensor(outs1[kk]),
|
| 127 |
+
)
|
| 128 |
+
diffs[kk] = (feats0[kk] - feats1[kk]) ** 2
|
| 129 |
+
|
| 130 |
+
if self.lpips:
|
| 131 |
+
if self.spatial:
|
| 132 |
+
res = [
|
| 133 |
+
upsample(self.lins[kk].model(diffs[kk]), out_H=in0.shape[2])
|
| 134 |
+
for kk in range(self.L)
|
| 135 |
+
]
|
| 136 |
+
else:
|
| 137 |
+
# NOTE: this block is used
|
| 138 |
+
# self.lins has 5 elements, where each element is a layer of LIN
|
| 139 |
+
"""
|
| 140 |
+
self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
|
| 141 |
+
self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
|
| 142 |
+
self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
|
| 143 |
+
self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
|
| 144 |
+
self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
|
| 145 |
+
self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
# NOTE:
|
| 149 |
+
# Each lins is applying a 1x1 conv on the spatial tensor to output 1 channel
|
| 150 |
+
# Therefore, to prevent this problem, we can simply mask out the activations
|
| 151 |
+
# in the spatial_average block. Right now, spatial_average does a spatial mean.
|
| 152 |
+
# We can mask out the tensor and then consider only on pixels for the mean op.
|
| 153 |
+
res = [
|
| 154 |
+
spatial_average(
|
| 155 |
+
self.lins[kk].model(diffs[kk]),
|
| 156 |
+
mask=masks[kk] if mask is not None else None,
|
| 157 |
+
keepdim=True,
|
| 158 |
+
)
|
| 159 |
+
for kk in range(self.L)
|
| 160 |
+
]
|
| 161 |
+
else:
|
| 162 |
+
if self.spatial:
|
| 163 |
+
res = [
|
| 164 |
+
upsample(diffs[kk].sum(dim=1, keepdim=True), out_H=in0.shape[2])
|
| 165 |
+
for kk in range(self.L)
|
| 166 |
+
]
|
| 167 |
+
else:
|
| 168 |
+
res = [
|
| 169 |
+
spatial_average(diffs[kk].sum(dim=1, keepdim=True), keepdim=True)
|
| 170 |
+
for kk in range(self.L)
|
| 171 |
+
]
|
| 172 |
+
|
| 173 |
+
'''
|
| 174 |
+
val = res[0]
|
| 175 |
+
for l in range(1, self.L):
|
| 176 |
+
val += res[l]
|
| 177 |
+
'''
|
| 178 |
+
|
| 179 |
+
val = 0.0
|
| 180 |
+
for l in range(self.L):
|
| 181 |
+
# l is going to run from 0 to 4
|
| 182 |
+
# check if (l + 1), i.e., [1 -> 5] in self.blocks, then count the loss
|
| 183 |
+
if str(l + 1) in self.blocks:
|
| 184 |
+
val += res[l]
|
| 185 |
+
|
| 186 |
+
if retPerLayer:
|
| 187 |
+
return (val, res)
|
| 188 |
+
else:
|
| 189 |
+
return val
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class ScalingLayer(nn.Module):
|
| 193 |
+
def __init__(self):
|
| 194 |
+
super(ScalingLayer, self).__init__()
|
| 195 |
+
self.register_buffer(
|
| 196 |
+
"shift", torch.Tensor([-0.030, -0.088, -0.188])[None, :, None, None]
|
| 197 |
+
)
|
| 198 |
+
self.register_buffer(
|
| 199 |
+
"scale", torch.Tensor([0.458, 0.448, 0.450])[None, :, None, None]
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
def forward(self, inp):
|
| 203 |
+
return (inp - self.shift) / self.scale
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class NetLinLayer(nn.Module):
|
| 207 |
+
""" A single linear layer which does a 1x1 conv """
|
| 208 |
+
|
| 209 |
+
def __init__(self, chn_in, chn_out=1, use_dropout=False):
|
| 210 |
+
super(NetLinLayer, self).__init__()
|
| 211 |
+
|
| 212 |
+
layers = (
|
| 213 |
+
[
|
| 214 |
+
nn.Dropout(),
|
| 215 |
+
]
|
| 216 |
+
if (use_dropout)
|
| 217 |
+
else []
|
| 218 |
+
)
|
| 219 |
+
layers += [
|
| 220 |
+
nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),
|
| 221 |
+
]
|
| 222 |
+
self.model = nn.Sequential(*layers)
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
class Dist2LogitLayer(nn.Module):
|
| 226 |
+
""" takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) """
|
| 227 |
+
|
| 228 |
+
def __init__(self, chn_mid=32, use_sigmoid=True):
|
| 229 |
+
super(Dist2LogitLayer, self).__init__()
|
| 230 |
+
|
| 231 |
+
layers = [
|
| 232 |
+
nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),
|
| 233 |
+
]
|
| 234 |
+
layers += [
|
| 235 |
+
nn.LeakyReLU(0.2, True),
|
| 236 |
+
]
|
| 237 |
+
layers += [
|
| 238 |
+
nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),
|
| 239 |
+
]
|
| 240 |
+
layers += [
|
| 241 |
+
nn.LeakyReLU(0.2, True),
|
| 242 |
+
]
|
| 243 |
+
layers += [
|
| 244 |
+
nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),
|
| 245 |
+
]
|
| 246 |
+
if use_sigmoid:
|
| 247 |
+
layers += [
|
| 248 |
+
nn.Sigmoid(),
|
| 249 |
+
]
|
| 250 |
+
self.model = nn.Sequential(*layers)
|
| 251 |
+
|
| 252 |
+
def forward(self, d0, d1, eps=0.1):
|
| 253 |
+
return self.model.forward(
|
| 254 |
+
torch.cat((d0, d1, d0 - d1, d0 / (d1 + eps), d1 / (d0 + eps)), dim=1)
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
class BCERankingLoss(nn.Module):
|
| 259 |
+
def __init__(self, chn_mid=32):
|
| 260 |
+
super(BCERankingLoss, self).__init__()
|
| 261 |
+
self.net = Dist2LogitLayer(chn_mid=chn_mid)
|
| 262 |
+
# self.parameters = list(self.net.parameters())
|
| 263 |
+
self.loss = torch.nn.BCELoss()
|
| 264 |
+
|
| 265 |
+
def forward(self, d0, d1, judge):
|
| 266 |
+
per = (judge + 1.0) / 2.0
|
| 267 |
+
self.logit = self.net.forward(d0, d1)
|
| 268 |
+
return self.loss(self.logit, per)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
# L2, DSSIM metrics
|
| 272 |
+
class FakeNet(nn.Module):
|
| 273 |
+
def __init__(self, use_gpu=True, colorspace="Lab"):
|
| 274 |
+
super(FakeNet, self).__init__()
|
| 275 |
+
self.use_gpu = use_gpu
|
| 276 |
+
self.colorspace = colorspace
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
class L2(FakeNet):
|
| 280 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 281 |
+
assert in0.size()[0] == 1 # currently only supports batchSize 1
|
| 282 |
+
|
| 283 |
+
if self.colorspace == "RGB":
|
| 284 |
+
(N, C, X, Y) = in0.size()
|
| 285 |
+
value = torch.mean(
|
| 286 |
+
torch.mean(
|
| 287 |
+
torch.mean((in0 - in1) ** 2, dim=1).view(N, 1, X, Y), dim=2
|
| 288 |
+
).view(N, 1, 1, Y),
|
| 289 |
+
dim=3,
|
| 290 |
+
).view(N)
|
| 291 |
+
return value
|
| 292 |
+
elif self.colorspace == "Lab":
|
| 293 |
+
value = util.l2(
|
| 294 |
+
util.tensor2np(util.tensor2tensorlab(in0.data, to_norm=False)),
|
| 295 |
+
util.tensor2np(util.tensor2tensorlab(in1.data, to_norm=False)),
|
| 296 |
+
range=100.0,
|
| 297 |
+
).astype("float")
|
| 298 |
+
ret_var = Variable(torch.Tensor((value,)))
|
| 299 |
+
if self.use_gpu:
|
| 300 |
+
ret_var = ret_var.cuda()
|
| 301 |
+
return ret_var
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
class DSSIM(FakeNet):
|
| 305 |
+
def forward(self, in0, in1, retPerLayer=None):
|
| 306 |
+
assert in0.size()[0] == 1 # currently only supports batchSize 1
|
| 307 |
+
|
| 308 |
+
if self.colorspace == "RGB":
|
| 309 |
+
value = util.dssim(
|
| 310 |
+
1.0 * util.tensor2im(in0.data),
|
| 311 |
+
1.0 * util.tensor2im(in1.data),
|
| 312 |
+
range=255.0,
|
| 313 |
+
).astype("float")
|
| 314 |
+
elif self.colorspace == "Lab":
|
| 315 |
+
value = util.dssim(
|
| 316 |
+
util.tensor2np(util.tensor2tensorlab(in0.data, to_norm=False)),
|
| 317 |
+
util.tensor2np(util.tensor2tensorlab(in1.data, to_norm=False)),
|
| 318 |
+
range=100.0,
|
| 319 |
+
).astype("float")
|
| 320 |
+
ret_var = Variable(torch.Tensor((value,)))
|
| 321 |
+
if self.use_gpu:
|
| 322 |
+
ret_var = ret_var.cuda()
|
| 323 |
+
return ret_var
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
def print_network(net):
|
| 327 |
+
num_params = 0
|
| 328 |
+
for param in net.parameters():
|
| 329 |
+
num_params += param.numel()
|
| 330 |
+
print("Network", net)
|
| 331 |
+
print("Total number of parameters: %d" % num_params)
|
losses/masked_lpips/pretrained_networks.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import namedtuple
|
| 2 |
+
import torch
|
| 3 |
+
from torchvision import models as tv
|
| 4 |
+
from IPython import embed
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class squeezenet(torch.nn.Module):
|
| 8 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 9 |
+
super(squeezenet, self).__init__()
|
| 10 |
+
pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
|
| 11 |
+
self.slice1 = torch.nn.Sequential()
|
| 12 |
+
self.slice2 = torch.nn.Sequential()
|
| 13 |
+
self.slice3 = torch.nn.Sequential()
|
| 14 |
+
self.slice4 = torch.nn.Sequential()
|
| 15 |
+
self.slice5 = torch.nn.Sequential()
|
| 16 |
+
self.slice6 = torch.nn.Sequential()
|
| 17 |
+
self.slice7 = torch.nn.Sequential()
|
| 18 |
+
self.N_slices = 7
|
| 19 |
+
for x in range(2):
|
| 20 |
+
self.slice1.add_module(str(x), pretrained_features[x])
|
| 21 |
+
for x in range(2, 5):
|
| 22 |
+
self.slice2.add_module(str(x), pretrained_features[x])
|
| 23 |
+
for x in range(5, 8):
|
| 24 |
+
self.slice3.add_module(str(x), pretrained_features[x])
|
| 25 |
+
for x in range(8, 10):
|
| 26 |
+
self.slice4.add_module(str(x), pretrained_features[x])
|
| 27 |
+
for x in range(10, 11):
|
| 28 |
+
self.slice5.add_module(str(x), pretrained_features[x])
|
| 29 |
+
for x in range(11, 12):
|
| 30 |
+
self.slice6.add_module(str(x), pretrained_features[x])
|
| 31 |
+
for x in range(12, 13):
|
| 32 |
+
self.slice7.add_module(str(x), pretrained_features[x])
|
| 33 |
+
if not requires_grad:
|
| 34 |
+
for param in self.parameters():
|
| 35 |
+
param.requires_grad = False
|
| 36 |
+
|
| 37 |
+
def forward(self, X):
|
| 38 |
+
h = self.slice1(X)
|
| 39 |
+
h_relu1 = h
|
| 40 |
+
h = self.slice2(h)
|
| 41 |
+
h_relu2 = h
|
| 42 |
+
h = self.slice3(h)
|
| 43 |
+
h_relu3 = h
|
| 44 |
+
h = self.slice4(h)
|
| 45 |
+
h_relu4 = h
|
| 46 |
+
h = self.slice5(h)
|
| 47 |
+
h_relu5 = h
|
| 48 |
+
h = self.slice6(h)
|
| 49 |
+
h_relu6 = h
|
| 50 |
+
h = self.slice7(h)
|
| 51 |
+
h_relu7 = h
|
| 52 |
+
vgg_outputs = namedtuple(
|
| 53 |
+
"SqueezeOutputs",
|
| 54 |
+
["relu1", "relu2", "relu3", "relu4", "relu5", "relu6", "relu7"],
|
| 55 |
+
)
|
| 56 |
+
out = vgg_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5, h_relu6, h_relu7)
|
| 57 |
+
|
| 58 |
+
return out
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class alexnet(torch.nn.Module):
|
| 62 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 63 |
+
super(alexnet, self).__init__()
|
| 64 |
+
alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
|
| 65 |
+
self.slice1 = torch.nn.Sequential()
|
| 66 |
+
self.slice2 = torch.nn.Sequential()
|
| 67 |
+
self.slice3 = torch.nn.Sequential()
|
| 68 |
+
self.slice4 = torch.nn.Sequential()
|
| 69 |
+
self.slice5 = torch.nn.Sequential()
|
| 70 |
+
self.N_slices = 5
|
| 71 |
+
for x in range(2):
|
| 72 |
+
self.slice1.add_module(str(x), alexnet_pretrained_features[x])
|
| 73 |
+
for x in range(2, 5):
|
| 74 |
+
self.slice2.add_module(str(x), alexnet_pretrained_features[x])
|
| 75 |
+
for x in range(5, 8):
|
| 76 |
+
self.slice3.add_module(str(x), alexnet_pretrained_features[x])
|
| 77 |
+
for x in range(8, 10):
|
| 78 |
+
self.slice4.add_module(str(x), alexnet_pretrained_features[x])
|
| 79 |
+
for x in range(10, 12):
|
| 80 |
+
self.slice5.add_module(str(x), alexnet_pretrained_features[x])
|
| 81 |
+
if not requires_grad:
|
| 82 |
+
for param in self.parameters():
|
| 83 |
+
param.requires_grad = False
|
| 84 |
+
|
| 85 |
+
def forward(self, X):
|
| 86 |
+
h = self.slice1(X)
|
| 87 |
+
h_relu1 = h
|
| 88 |
+
h = self.slice2(h)
|
| 89 |
+
h_relu2 = h
|
| 90 |
+
h = self.slice3(h)
|
| 91 |
+
h_relu3 = h
|
| 92 |
+
h = self.slice4(h)
|
| 93 |
+
h_relu4 = h
|
| 94 |
+
h = self.slice5(h)
|
| 95 |
+
h_relu5 = h
|
| 96 |
+
alexnet_outputs = namedtuple(
|
| 97 |
+
"AlexnetOutputs", ["relu1", "relu2", "relu3", "relu4", "relu5"]
|
| 98 |
+
)
|
| 99 |
+
out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
|
| 100 |
+
|
| 101 |
+
return out
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class vgg16(torch.nn.Module):
|
| 105 |
+
def __init__(self, requires_grad=False, pretrained=True):
|
| 106 |
+
super(vgg16, self).__init__()
|
| 107 |
+
vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
|
| 108 |
+
self.slice1 = torch.nn.Sequential()
|
| 109 |
+
self.slice2 = torch.nn.Sequential()
|
| 110 |
+
self.slice3 = torch.nn.Sequential()
|
| 111 |
+
self.slice4 = torch.nn.Sequential()
|
| 112 |
+
self.slice5 = torch.nn.Sequential()
|
| 113 |
+
self.N_slices = 5
|
| 114 |
+
for x in range(4):
|
| 115 |
+
self.slice1.add_module(str(x), vgg_pretrained_features[x])
|
| 116 |
+
for x in range(4, 9):
|
| 117 |
+
self.slice2.add_module(str(x), vgg_pretrained_features[x])
|
| 118 |
+
for x in range(9, 16):
|
| 119 |
+
self.slice3.add_module(str(x), vgg_pretrained_features[x])
|
| 120 |
+
for x in range(16, 23):
|
| 121 |
+
self.slice4.add_module(str(x), vgg_pretrained_features[x])
|
| 122 |
+
for x in range(23, 30):
|
| 123 |
+
self.slice5.add_module(str(x), vgg_pretrained_features[x])
|
| 124 |
+
if not requires_grad:
|
| 125 |
+
for param in self.parameters():
|
| 126 |
+
param.requires_grad = False
|
| 127 |
+
|
| 128 |
+
def forward(self, X):
|
| 129 |
+
h = self.slice1(X)
|
| 130 |
+
h_relu1_2 = h
|
| 131 |
+
h = self.slice2(h)
|
| 132 |
+
h_relu2_2 = h
|
| 133 |
+
h = self.slice3(h)
|
| 134 |
+
h_relu3_3 = h
|
| 135 |
+
h = self.slice4(h)
|
| 136 |
+
h_relu4_3 = h
|
| 137 |
+
h = self.slice5(h)
|
| 138 |
+
h_relu5_3 = h
|
| 139 |
+
|
| 140 |
+
vgg_outputs = namedtuple(
|
| 141 |
+
"VggOutputs", ["relu1_2", "relu2_2", "relu3_3", "relu4_3", "relu5_3"]
|
| 142 |
+
)
|
| 143 |
+
out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
|
| 144 |
+
|
| 145 |
+
return out
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class resnet(torch.nn.Module):
|
| 149 |
+
def __init__(self, requires_grad=False, pretrained=True, num=18):
|
| 150 |
+
super(resnet, self).__init__()
|
| 151 |
+
if num == 18:
|
| 152 |
+
self.net = tv.resnet18(pretrained=pretrained)
|
| 153 |
+
elif num == 34:
|
| 154 |
+
self.net = tv.resnet34(pretrained=pretrained)
|
| 155 |
+
elif num == 50:
|
| 156 |
+
self.net = tv.resnet50(pretrained=pretrained)
|
| 157 |
+
elif num == 101:
|
| 158 |
+
self.net = tv.resnet101(pretrained=pretrained)
|
| 159 |
+
elif num == 152:
|
| 160 |
+
self.net = tv.resnet152(pretrained=pretrained)
|
| 161 |
+
self.N_slices = 5
|
| 162 |
+
|
| 163 |
+
self.conv1 = self.net.conv1
|
| 164 |
+
self.bn1 = self.net.bn1
|
| 165 |
+
self.relu = self.net.relu
|
| 166 |
+
self.maxpool = self.net.maxpool
|
| 167 |
+
self.layer1 = self.net.layer1
|
| 168 |
+
self.layer2 = self.net.layer2
|
| 169 |
+
self.layer3 = self.net.layer3
|
| 170 |
+
self.layer4 = self.net.layer4
|
| 171 |
+
|
| 172 |
+
def forward(self, X):
|
| 173 |
+
h = self.conv1(X)
|
| 174 |
+
h = self.bn1(h)
|
| 175 |
+
h = self.relu(h)
|
| 176 |
+
h_relu1 = h
|
| 177 |
+
h = self.maxpool(h)
|
| 178 |
+
h = self.layer1(h)
|
| 179 |
+
h_conv2 = h
|
| 180 |
+
h = self.layer2(h)
|
| 181 |
+
h_conv3 = h
|
| 182 |
+
h = self.layer3(h)
|
| 183 |
+
h_conv4 = h
|
| 184 |
+
h = self.layer4(h)
|
| 185 |
+
h_conv5 = h
|
| 186 |
+
|
| 187 |
+
outputs = namedtuple("Outputs", ["relu1", "conv2", "conv3", "conv4", "conv5"])
|
| 188 |
+
out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
|
| 189 |
+
|
| 190 |
+
return out
|
losses/pp_losses.py
ADDED
|
@@ -0,0 +1,677 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from torchvision import transforms as T
|
| 6 |
+
|
| 7 |
+
from utils.bicubic import BicubicDownSample
|
| 8 |
+
|
| 9 |
+
normalize = T.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
|
| 10 |
+
|
| 11 |
+
@dataclass
|
| 12 |
+
class DefaultPaths:
|
| 13 |
+
psp_path: str = "pretrained_models/psp_ffhq_encode.pt"
|
| 14 |
+
ir_se50_path: str = "pretrained_models/ArcFace/ir_se50.pth"
|
| 15 |
+
stylegan_weights: str = "pretrained_models/stylegan2-ffhq-config-f.pt"
|
| 16 |
+
stylegan_car_weights: str = "pretrained_models/stylegan2-car-config-f-new.pkl"
|
| 17 |
+
stylegan_weights_pkl: str = (
|
| 18 |
+
"pretrained_models/stylegan2-ffhq-config-f.pkl"
|
| 19 |
+
)
|
| 20 |
+
arcface_model_path: str = "pretrained_models/ArcFace/backbone_ir50.pth"
|
| 21 |
+
moco: str = "pretrained_models/moco_v2_800ep_pretrain.pt"
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
from collections import namedtuple
|
| 25 |
+
from torch.nn import (
|
| 26 |
+
Conv2d,
|
| 27 |
+
BatchNorm2d,
|
| 28 |
+
PReLU,
|
| 29 |
+
ReLU,
|
| 30 |
+
Sigmoid,
|
| 31 |
+
MaxPool2d,
|
| 32 |
+
AdaptiveAvgPool2d,
|
| 33 |
+
Sequential,
|
| 34 |
+
Module,
|
| 35 |
+
Dropout,
|
| 36 |
+
Linear,
|
| 37 |
+
BatchNorm1d,
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
"""
|
| 41 |
+
ArcFace implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class Flatten(Module):
|
| 46 |
+
def forward(self, input):
|
| 47 |
+
return input.view(input.size(0), -1)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def l2_norm(input, axis=1):
|
| 51 |
+
norm = torch.norm(input, 2, axis, True)
|
| 52 |
+
output = torch.div(input, norm)
|
| 53 |
+
return output
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class Bottleneck(namedtuple("Block", ["in_channel", "depth", "stride"])):
|
| 57 |
+
"""A named tuple describing a ResNet block."""
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def get_block(in_channel, depth, num_units, stride=2):
|
| 61 |
+
return [Bottleneck(in_channel, depth, stride)] + [
|
| 62 |
+
Bottleneck(depth, depth, 1) for i in range(num_units - 1)
|
| 63 |
+
]
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_blocks(num_layers):
|
| 67 |
+
if num_layers == 50:
|
| 68 |
+
blocks = [
|
| 69 |
+
get_block(in_channel=64, depth=64, num_units=3),
|
| 70 |
+
get_block(in_channel=64, depth=128, num_units=4),
|
| 71 |
+
get_block(in_channel=128, depth=256, num_units=14),
|
| 72 |
+
get_block(in_channel=256, depth=512, num_units=3),
|
| 73 |
+
]
|
| 74 |
+
elif num_layers == 100:
|
| 75 |
+
blocks = [
|
| 76 |
+
get_block(in_channel=64, depth=64, num_units=3),
|
| 77 |
+
get_block(in_channel=64, depth=128, num_units=13),
|
| 78 |
+
get_block(in_channel=128, depth=256, num_units=30),
|
| 79 |
+
get_block(in_channel=256, depth=512, num_units=3),
|
| 80 |
+
]
|
| 81 |
+
elif num_layers == 152:
|
| 82 |
+
blocks = [
|
| 83 |
+
get_block(in_channel=64, depth=64, num_units=3),
|
| 84 |
+
get_block(in_channel=64, depth=128, num_units=8),
|
| 85 |
+
get_block(in_channel=128, depth=256, num_units=36),
|
| 86 |
+
get_block(in_channel=256, depth=512, num_units=3),
|
| 87 |
+
]
|
| 88 |
+
else:
|
| 89 |
+
raise ValueError(
|
| 90 |
+
"Invalid number of layers: {}. Must be one of [50, 100, 152]".format(
|
| 91 |
+
num_layers
|
| 92 |
+
)
|
| 93 |
+
)
|
| 94 |
+
return blocks
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class SEModule(Module):
|
| 98 |
+
def __init__(self, channels, reduction):
|
| 99 |
+
super(SEModule, self).__init__()
|
| 100 |
+
self.avg_pool = AdaptiveAvgPool2d(1)
|
| 101 |
+
self.fc1 = Conv2d(
|
| 102 |
+
channels, channels // reduction, kernel_size=1, padding=0, bias=False
|
| 103 |
+
)
|
| 104 |
+
self.relu = ReLU(inplace=True)
|
| 105 |
+
self.fc2 = Conv2d(
|
| 106 |
+
channels // reduction, channels, kernel_size=1, padding=0, bias=False
|
| 107 |
+
)
|
| 108 |
+
self.sigmoid = Sigmoid()
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
module_input = x
|
| 112 |
+
x = self.avg_pool(x)
|
| 113 |
+
x = self.fc1(x)
|
| 114 |
+
x = self.relu(x)
|
| 115 |
+
x = self.fc2(x)
|
| 116 |
+
x = self.sigmoid(x)
|
| 117 |
+
return module_input * x
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class bottleneck_IR(Module):
|
| 121 |
+
def __init__(self, in_channel, depth, stride):
|
| 122 |
+
super(bottleneck_IR, self).__init__()
|
| 123 |
+
if in_channel == depth:
|
| 124 |
+
self.shortcut_layer = MaxPool2d(1, stride)
|
| 125 |
+
else:
|
| 126 |
+
self.shortcut_layer = Sequential(
|
| 127 |
+
Conv2d(in_channel, depth, (1, 1), stride, bias=False),
|
| 128 |
+
BatchNorm2d(depth),
|
| 129 |
+
)
|
| 130 |
+
self.res_layer = Sequential(
|
| 131 |
+
BatchNorm2d(in_channel),
|
| 132 |
+
Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
|
| 133 |
+
PReLU(depth),
|
| 134 |
+
Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
|
| 135 |
+
BatchNorm2d(depth),
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
def forward(self, x):
|
| 139 |
+
shortcut = self.shortcut_layer(x)
|
| 140 |
+
res = self.res_layer(x)
|
| 141 |
+
return res + shortcut
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class bottleneck_IR_SE(Module):
|
| 145 |
+
def __init__(self, in_channel, depth, stride):
|
| 146 |
+
super(bottleneck_IR_SE, self).__init__()
|
| 147 |
+
if in_channel == depth:
|
| 148 |
+
self.shortcut_layer = MaxPool2d(1, stride)
|
| 149 |
+
else:
|
| 150 |
+
self.shortcut_layer = Sequential(
|
| 151 |
+
Conv2d(in_channel, depth, (1, 1), stride, bias=False),
|
| 152 |
+
BatchNorm2d(depth),
|
| 153 |
+
)
|
| 154 |
+
self.res_layer = Sequential(
|
| 155 |
+
BatchNorm2d(in_channel),
|
| 156 |
+
Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
|
| 157 |
+
PReLU(depth),
|
| 158 |
+
Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
|
| 159 |
+
BatchNorm2d(depth),
|
| 160 |
+
SEModule(depth, 16),
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
def forward(self, x):
|
| 164 |
+
shortcut = self.shortcut_layer(x)
|
| 165 |
+
res = self.res_layer(x)
|
| 166 |
+
return res + shortcut
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
"""
|
| 170 |
+
Modified Backbone implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
|
| 171 |
+
"""
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
class Backbone(Module):
|
| 175 |
+
def __init__(self, input_size, num_layers, mode="ir", drop_ratio=0.4, affine=True):
|
| 176 |
+
super(Backbone, self).__init__()
|
| 177 |
+
assert input_size in [112, 224], "input_size should be 112 or 224"
|
| 178 |
+
assert num_layers in [50, 100, 152], "num_layers should be 50, 100 or 152"
|
| 179 |
+
assert mode in ["ir", "ir_se"], "mode should be ir or ir_se"
|
| 180 |
+
blocks = get_blocks(num_layers)
|
| 181 |
+
if mode == "ir":
|
| 182 |
+
unit_module = bottleneck_IR
|
| 183 |
+
elif mode == "ir_se":
|
| 184 |
+
unit_module = bottleneck_IR_SE
|
| 185 |
+
self.input_layer = Sequential(
|
| 186 |
+
Conv2d(3, 64, (3, 3), 1, 1, bias=False), BatchNorm2d(64), PReLU(64)
|
| 187 |
+
)
|
| 188 |
+
if input_size == 112:
|
| 189 |
+
self.output_layer = Sequential(
|
| 190 |
+
BatchNorm2d(512),
|
| 191 |
+
Dropout(drop_ratio),
|
| 192 |
+
Flatten(),
|
| 193 |
+
Linear(512 * 7 * 7, 512),
|
| 194 |
+
BatchNorm1d(512, affine=affine),
|
| 195 |
+
)
|
| 196 |
+
else:
|
| 197 |
+
self.output_layer = Sequential(
|
| 198 |
+
BatchNorm2d(512),
|
| 199 |
+
Dropout(drop_ratio),
|
| 200 |
+
Flatten(),
|
| 201 |
+
Linear(512 * 14 * 14, 512),
|
| 202 |
+
BatchNorm1d(512, affine=affine),
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
modules = []
|
| 206 |
+
for block in blocks:
|
| 207 |
+
for bottleneck in block:
|
| 208 |
+
modules.append(
|
| 209 |
+
unit_module(
|
| 210 |
+
bottleneck.in_channel, bottleneck.depth, bottleneck.stride
|
| 211 |
+
)
|
| 212 |
+
)
|
| 213 |
+
self.body = Sequential(*modules)
|
| 214 |
+
|
| 215 |
+
def forward(self, x):
|
| 216 |
+
x = self.input_layer(x)
|
| 217 |
+
x = self.body(x)
|
| 218 |
+
x = self.output_layer(x)
|
| 219 |
+
return l2_norm(x)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def IR_50(input_size):
|
| 223 |
+
"""Constructs a ir-50 model."""
|
| 224 |
+
model = Backbone(input_size, num_layers=50, mode="ir", drop_ratio=0.4, affine=False)
|
| 225 |
+
return model
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def IR_101(input_size):
|
| 229 |
+
"""Constructs a ir-101 model."""
|
| 230 |
+
model = Backbone(
|
| 231 |
+
input_size, num_layers=100, mode="ir", drop_ratio=0.4, affine=False
|
| 232 |
+
)
|
| 233 |
+
return model
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def IR_152(input_size):
|
| 237 |
+
"""Constructs a ir-152 model."""
|
| 238 |
+
model = Backbone(
|
| 239 |
+
input_size, num_layers=152, mode="ir", drop_ratio=0.4, affine=False
|
| 240 |
+
)
|
| 241 |
+
return model
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def IR_SE_50(input_size):
|
| 245 |
+
"""Constructs a ir_se-50 model."""
|
| 246 |
+
model = Backbone(
|
| 247 |
+
input_size, num_layers=50, mode="ir_se", drop_ratio=0.4, affine=False
|
| 248 |
+
)
|
| 249 |
+
return model
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def IR_SE_101(input_size):
|
| 253 |
+
"""Constructs a ir_se-101 model."""
|
| 254 |
+
model = Backbone(
|
| 255 |
+
input_size, num_layers=100, mode="ir_se", drop_ratio=0.4, affine=False
|
| 256 |
+
)
|
| 257 |
+
return model
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def IR_SE_152(input_size):
|
| 261 |
+
"""Constructs a ir_se-152 model."""
|
| 262 |
+
model = Backbone(
|
| 263 |
+
input_size, num_layers=152, mode="ir_se", drop_ratio=0.4, affine=False
|
| 264 |
+
)
|
| 265 |
+
return model
|
| 266 |
+
|
| 267 |
+
class IDLoss(nn.Module):
|
| 268 |
+
def __init__(self):
|
| 269 |
+
super(IDLoss, self).__init__()
|
| 270 |
+
print("Loading ResNet ArcFace")
|
| 271 |
+
self.facenet = Backbone(
|
| 272 |
+
input_size=112, num_layers=50, drop_ratio=0.6, mode="ir_se"
|
| 273 |
+
)
|
| 274 |
+
self.facenet.load_state_dict(torch.load(DefaultPaths.ir_se50_path))
|
| 275 |
+
self.face_pool = torch.nn.AdaptiveAvgPool2d((112, 112))
|
| 276 |
+
self.facenet.eval()
|
| 277 |
+
|
| 278 |
+
def extract_feats(self, x):
|
| 279 |
+
x = x[:, :, 35:223, 32:220] # Crop interesting region
|
| 280 |
+
x = self.face_pool(x)
|
| 281 |
+
x_feats = self.facenet(x)
|
| 282 |
+
return x_feats
|
| 283 |
+
|
| 284 |
+
def forward(self, y_hat, y):
|
| 285 |
+
n_samples = y.shape[0]
|
| 286 |
+
y_feats = self.extract_feats(y)
|
| 287 |
+
y_hat_feats = self.extract_feats(y_hat)
|
| 288 |
+
y_feats = y_feats.detach()
|
| 289 |
+
loss = 0
|
| 290 |
+
count = 0
|
| 291 |
+
for i in range(n_samples):
|
| 292 |
+
diff_target = y_hat_feats[i].dot(y_feats[i])
|
| 293 |
+
loss += 1 - diff_target
|
| 294 |
+
count += 1
|
| 295 |
+
|
| 296 |
+
return loss / count
|
| 297 |
+
|
| 298 |
+
class FeatReconLoss(nn.Module):
|
| 299 |
+
def __init__(self):
|
| 300 |
+
super().__init__()
|
| 301 |
+
self.loss_fn = nn.MSELoss()
|
| 302 |
+
|
| 303 |
+
def forward(self, recon_1, recon_2):
|
| 304 |
+
return self.loss_fn(recon_1, recon_2).mean()
|
| 305 |
+
|
| 306 |
+
class EncoderAdvLoss:
|
| 307 |
+
def __call__(self, fake_preds):
|
| 308 |
+
loss_G_adv = F.softplus(-fake_preds).mean()
|
| 309 |
+
return loss_G_adv
|
| 310 |
+
|
| 311 |
+
class AdvLoss:
|
| 312 |
+
def __init__(self, coef=0.0):
|
| 313 |
+
self.coef = coef
|
| 314 |
+
|
| 315 |
+
def __call__(self, disc, real_images, generated_images):
|
| 316 |
+
fake_preds = disc(generated_images, None)
|
| 317 |
+
real_preds = disc(real_images, None)
|
| 318 |
+
loss = self.d_logistic_loss(real_preds, fake_preds)
|
| 319 |
+
|
| 320 |
+
return {'disc adv': loss}
|
| 321 |
+
|
| 322 |
+
def d_logistic_loss(self, real_preds, fake_preds):
|
| 323 |
+
real_loss = F.softplus(-real_preds)
|
| 324 |
+
fake_loss = F.softplus(fake_preds)
|
| 325 |
+
|
| 326 |
+
return (real_loss.mean() + fake_loss.mean()) / 2
|
| 327 |
+
|
| 328 |
+
from models.face_parsing.model import BiSeNet, seg_mean, seg_std
|
| 329 |
+
|
| 330 |
+
class DiceLoss(nn.Module):
|
| 331 |
+
def __init__(self, gamma=2):
|
| 332 |
+
super().__init__()
|
| 333 |
+
self.gamma = gamma
|
| 334 |
+
self.seg = BiSeNet(n_classes=16)
|
| 335 |
+
self.seg.to('cuda')
|
| 336 |
+
self.seg.load_state_dict(torch.load('pretrained_models/BiSeNet/seg.pth'))
|
| 337 |
+
for param in self.seg.parameters():
|
| 338 |
+
param.requires_grad = False
|
| 339 |
+
self.seg.eval()
|
| 340 |
+
self.downsample_512 = BicubicDownSample(factor=2)
|
| 341 |
+
|
| 342 |
+
def calc_landmark(self, x):
|
| 343 |
+
IM = (self.downsample_512(x) - seg_mean) / seg_std
|
| 344 |
+
out, _, _ = self.seg(IM)
|
| 345 |
+
return out
|
| 346 |
+
|
| 347 |
+
def dice_loss(self, input, target):
|
| 348 |
+
smooth = 1.
|
| 349 |
+
|
| 350 |
+
iflat = input.view(input.size(0), -1)
|
| 351 |
+
tflat = target.view(target.size(0), -1)
|
| 352 |
+
intersection = (iflat * tflat).sum(dim=1)
|
| 353 |
+
|
| 354 |
+
fn = torch.sum((tflat * (1-iflat))**self.gamma, dim=1)
|
| 355 |
+
fp = torch.sum(((1-tflat) * iflat)**self.gamma, dim=1)
|
| 356 |
+
|
| 357 |
+
return 1 - ((2. * intersection + smooth) /
|
| 358 |
+
(iflat.sum(dim=1) + tflat.sum(dim=1) + fn + fp + smooth))
|
| 359 |
+
|
| 360 |
+
def __call__(self, in_logit, tg_logit):
|
| 361 |
+
probs1 = F.softmax(in_logit, dim=1)
|
| 362 |
+
probs2 = F.softmax(tg_logit, dim=1)
|
| 363 |
+
return self.dice_loss(probs1, probs2).mean()
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
from typing import Sequence
|
| 367 |
+
|
| 368 |
+
from itertools import chain
|
| 369 |
+
|
| 370 |
+
import torch
|
| 371 |
+
import torch.nn as nn
|
| 372 |
+
from torchvision import models
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
def get_network(net_type: str):
|
| 376 |
+
if net_type == "alex":
|
| 377 |
+
return AlexNet()
|
| 378 |
+
elif net_type == "squeeze":
|
| 379 |
+
return SqueezeNet()
|
| 380 |
+
elif net_type == "vgg":
|
| 381 |
+
return VGG16()
|
| 382 |
+
else:
|
| 383 |
+
raise NotImplementedError("choose net_type from [alex, squeeze, vgg].")
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
class LinLayers(nn.ModuleList):
|
| 387 |
+
def __init__(self, n_channels_list: Sequence[int]):
|
| 388 |
+
super(LinLayers, self).__init__(
|
| 389 |
+
[
|
| 390 |
+
nn.Sequential(nn.Identity(), nn.Conv2d(nc, 1, 1, 1, 0, bias=False))
|
| 391 |
+
for nc in n_channels_list
|
| 392 |
+
]
|
| 393 |
+
)
|
| 394 |
+
|
| 395 |
+
for param in self.parameters():
|
| 396 |
+
param.requires_grad = False
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
class BaseNet(nn.Module):
|
| 400 |
+
def __init__(self):
|
| 401 |
+
super(BaseNet, self).__init__()
|
| 402 |
+
|
| 403 |
+
# register buffer
|
| 404 |
+
self.register_buffer(
|
| 405 |
+
"mean", torch.Tensor([-0.030, -0.088, -0.188])[None, :, None, None]
|
| 406 |
+
)
|
| 407 |
+
self.register_buffer(
|
| 408 |
+
"std", torch.Tensor([0.458, 0.448, 0.450])[None, :, None, None]
|
| 409 |
+
)
|
| 410 |
+
|
| 411 |
+
def set_requires_grad(self, state: bool):
|
| 412 |
+
for param in chain(self.parameters(), self.buffers()):
|
| 413 |
+
param.requires_grad = state
|
| 414 |
+
|
| 415 |
+
def z_score(self, x: torch.Tensor):
|
| 416 |
+
return (x - self.mean) / self.std
|
| 417 |
+
|
| 418 |
+
def forward(self, x: torch.Tensor):
|
| 419 |
+
x = self.z_score(x)
|
| 420 |
+
|
| 421 |
+
output = []
|
| 422 |
+
for i, (_, layer) in enumerate(self.layers._modules.items(), 1):
|
| 423 |
+
x = layer(x)
|
| 424 |
+
if i in self.target_layers:
|
| 425 |
+
output.append(normalize_activation(x))
|
| 426 |
+
if len(output) == len(self.target_layers):
|
| 427 |
+
break
|
| 428 |
+
return output
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
class SqueezeNet(BaseNet):
|
| 432 |
+
def __init__(self):
|
| 433 |
+
super(SqueezeNet, self).__init__()
|
| 434 |
+
|
| 435 |
+
self.layers = models.squeezenet1_1(True).features
|
| 436 |
+
self.target_layers = [2, 5, 8, 10, 11, 12, 13]
|
| 437 |
+
self.n_channels_list = [64, 128, 256, 384, 384, 512, 512]
|
| 438 |
+
|
| 439 |
+
self.set_requires_grad(False)
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
class AlexNet(BaseNet):
|
| 443 |
+
def __init__(self):
|
| 444 |
+
super(AlexNet, self).__init__()
|
| 445 |
+
|
| 446 |
+
self.layers = models.alexnet(True).features
|
| 447 |
+
self.target_layers = [2, 5, 8, 10, 12]
|
| 448 |
+
self.n_channels_list = [64, 192, 384, 256, 256]
|
| 449 |
+
|
| 450 |
+
self.set_requires_grad(False)
|
| 451 |
+
|
| 452 |
+
|
| 453 |
+
class VGG16(BaseNet):
|
| 454 |
+
def __init__(self):
|
| 455 |
+
super(VGG16, self).__init__()
|
| 456 |
+
|
| 457 |
+
self.layers = models.vgg16(True).features
|
| 458 |
+
self.target_layers = [4, 9, 16, 23, 30]
|
| 459 |
+
self.n_channels_list = [64, 128, 256, 512, 512]
|
| 460 |
+
|
| 461 |
+
self.set_requires_grad(False)
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
from collections import OrderedDict
|
| 465 |
+
|
| 466 |
+
import torch
|
| 467 |
+
|
| 468 |
+
|
| 469 |
+
def normalize_activation(x, eps=1e-10):
|
| 470 |
+
norm_factor = torch.sqrt(torch.sum(x**2, dim=1, keepdim=True))
|
| 471 |
+
return x / (norm_factor + eps)
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
def get_state_dict(net_type: str = "alex", version: str = "0.1"):
|
| 475 |
+
# build url
|
| 476 |
+
url = (
|
| 477 |
+
"https://raw.githubusercontent.com/richzhang/PerceptualSimilarity/"
|
| 478 |
+
+ f"master/lpips/weights/v{version}/{net_type}.pth"
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
# download
|
| 482 |
+
old_state_dict = torch.hub.load_state_dict_from_url(
|
| 483 |
+
url,
|
| 484 |
+
progress=True,
|
| 485 |
+
map_location=None if torch.cuda.is_available() else torch.device("cpu"),
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
# rename keys
|
| 489 |
+
new_state_dict = OrderedDict()
|
| 490 |
+
for key, val in old_state_dict.items():
|
| 491 |
+
new_key = key
|
| 492 |
+
new_key = new_key.replace("lin", "")
|
| 493 |
+
new_key = new_key.replace("model.", "")
|
| 494 |
+
new_state_dict[new_key] = val
|
| 495 |
+
|
| 496 |
+
return new_state_dict
|
| 497 |
+
|
| 498 |
+
class LPIPS(nn.Module):
|
| 499 |
+
r"""Creates a criterion that measures
|
| 500 |
+
Learned Perceptual Image Patch Similarity (LPIPS).
|
| 501 |
+
Arguments:
|
| 502 |
+
net_type (str): the network type to compare the features:
|
| 503 |
+
'alex' | 'squeeze' | 'vgg'. Default: 'alex'.
|
| 504 |
+
version (str): the version of LPIPS. Default: 0.1.
|
| 505 |
+
"""
|
| 506 |
+
|
| 507 |
+
def __init__(self, net_type: str = "alex", version: str = "0.1"):
|
| 508 |
+
|
| 509 |
+
assert version in ["0.1"], "v0.1 is only supported now"
|
| 510 |
+
|
| 511 |
+
super(LPIPS, self).__init__()
|
| 512 |
+
|
| 513 |
+
# pretrained network
|
| 514 |
+
self.net = get_network(net_type).to("cuda")
|
| 515 |
+
|
| 516 |
+
# linear layers
|
| 517 |
+
self.lin = LinLayers(self.net.n_channels_list).to("cuda")
|
| 518 |
+
self.lin.load_state_dict(get_state_dict(net_type, version))
|
| 519 |
+
|
| 520 |
+
def forward(self, x: torch.Tensor, y: torch.Tensor):
|
| 521 |
+
feat_x, feat_y = self.net(x), self.net(y)
|
| 522 |
+
|
| 523 |
+
diff = [(fx - fy) ** 2 for fx, fy in zip(feat_x, feat_y)]
|
| 524 |
+
res = [l(d).mean((2, 3), True) for d, l in zip(diff, self.lin)]
|
| 525 |
+
|
| 526 |
+
return torch.sum(torch.cat(res, 0)) / x.shape[0]
|
| 527 |
+
|
| 528 |
+
class LPIPSLoss(LPIPS):
|
| 529 |
+
pass
|
| 530 |
+
|
| 531 |
+
class LPIPSScaleLoss(nn.Module):
|
| 532 |
+
def __init__(self):
|
| 533 |
+
super().__init__()
|
| 534 |
+
self.loss_fn = LPIPSLoss()
|
| 535 |
+
|
| 536 |
+
def forward(self, x, y):
|
| 537 |
+
out = 0
|
| 538 |
+
for res in [256, 128, 64]:
|
| 539 |
+
x_scale = F.interpolate(x, size=(res, res), mode="bilinear", align_corners=False)
|
| 540 |
+
y_scale = F.interpolate(y, size=(res, res), mode="bilinear", align_corners=False)
|
| 541 |
+
out += self.loss_fn.forward(x_scale, y_scale).mean()
|
| 542 |
+
return out
|
| 543 |
+
|
| 544 |
+
class SyntMSELoss(nn.Module):
|
| 545 |
+
def __init__(self):
|
| 546 |
+
super().__init__()
|
| 547 |
+
self.loss_fn = nn.MSELoss()
|
| 548 |
+
|
| 549 |
+
def forward(self, im1, im2):
|
| 550 |
+
return self.loss_fn(im1, im2).mean()
|
| 551 |
+
|
| 552 |
+
class R1Loss:
|
| 553 |
+
def __init__(self, coef=10.0):
|
| 554 |
+
self.coef = coef
|
| 555 |
+
|
| 556 |
+
def __call__(self, disc, real_images):
|
| 557 |
+
real_images.requires_grad = True
|
| 558 |
+
|
| 559 |
+
real_preds = disc(real_images, None)
|
| 560 |
+
real_preds = real_preds.view(real_images.size(0), -1)
|
| 561 |
+
real_preds = real_preds.mean(dim=1).unsqueeze(1)
|
| 562 |
+
r1_loss = self.d_r1_loss(real_preds, real_images)
|
| 563 |
+
|
| 564 |
+
loss_D_R1 = self.coef / 2 * r1_loss * 16 + 0 * real_preds[0]
|
| 565 |
+
return {'disc r1 loss': loss_D_R1}
|
| 566 |
+
|
| 567 |
+
def d_r1_loss(self, real_pred, real_img):
|
| 568 |
+
(grad_real,) = torch.autograd.grad(
|
| 569 |
+
outputs=real_pred.sum(), inputs=real_img, create_graph=True
|
| 570 |
+
)
|
| 571 |
+
grad_penalty = grad_real.pow(2).reshape(grad_real.shape[0], -1).sum(1).mean()
|
| 572 |
+
|
| 573 |
+
return grad_penalty
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
class DilatedMask:
|
| 577 |
+
def __init__(self, kernel_size=5):
|
| 578 |
+
self.kernel_size = kernel_size
|
| 579 |
+
|
| 580 |
+
cords_x = torch.arange(0, kernel_size).view(1, -1).expand(kernel_size, -1) - kernel_size // 2
|
| 581 |
+
cords_y = cords_x.clone().permute(1, 0)
|
| 582 |
+
self.kernel = torch.as_tensor((cords_x ** 2 + cords_y ** 2) <= (kernel_size // 2) ** 2, dtype=torch.float).view(1, 1, kernel_size, kernel_size).cuda()
|
| 583 |
+
self.kernel /= self.kernel.sum()
|
| 584 |
+
|
| 585 |
+
def __call__(self, mask):
|
| 586 |
+
smooth_mask = F.conv2d(mask, self.kernel, padding=self.kernel_size // 2)
|
| 587 |
+
return smooth_mask ** 0.25
|
| 588 |
+
|
| 589 |
+
|
| 590 |
+
class LossBuilder:
|
| 591 |
+
def __init__(self, losses_dict, device='cuda'):
|
| 592 |
+
self.losses_dict = losses_dict
|
| 593 |
+
self.device = device
|
| 594 |
+
|
| 595 |
+
self.EncoderAdvLoss = EncoderAdvLoss()
|
| 596 |
+
self.AdvLoss = AdvLoss()
|
| 597 |
+
self.R1Loss = R1Loss()
|
| 598 |
+
self.FeatReconLoss = FeatReconLoss().to(device).eval()
|
| 599 |
+
self.IDLoss = IDLoss().to(device).eval()
|
| 600 |
+
self.LPIPS = LPIPSScaleLoss().to(device).eval()
|
| 601 |
+
self.SyntMSELoss = SyntMSELoss().to(device).eval()
|
| 602 |
+
self.downsample_256 = BicubicDownSample(factor=4)
|
| 603 |
+
|
| 604 |
+
def CalcAdvLoss(self, disc, gen_F):
|
| 605 |
+
fake_preds_F = disc(gen_F, None)
|
| 606 |
+
|
| 607 |
+
return {'adv': self.losses_dict['adv'] * self.EncoderAdvLoss(fake_preds_F)}
|
| 608 |
+
|
| 609 |
+
def CalcDisLoss(self, disc, real_images, generated_images):
|
| 610 |
+
return self.AdvLoss(disc, real_images, generated_images)
|
| 611 |
+
|
| 612 |
+
def CalcR1Loss(self, disc, real_images):
|
| 613 |
+
return self.R1Loss(disc, real_images)
|
| 614 |
+
|
| 615 |
+
def __call__(self, source, target, target_mask, HT_E, gen_w, F_w, gen_F, F_gen, **kwargs):
|
| 616 |
+
losses = {}
|
| 617 |
+
|
| 618 |
+
gen_w_256 = self.downsample_256(gen_w)
|
| 619 |
+
gen_F_256 = self.downsample_256(gen_F)
|
| 620 |
+
|
| 621 |
+
# ID loss
|
| 622 |
+
losses['rec id'] = self.losses_dict['id'] * (self.IDLoss(normalize(source), gen_w_256) + self.IDLoss(normalize(source), gen_F_256))
|
| 623 |
+
|
| 624 |
+
# Feat Recons Loss
|
| 625 |
+
losses['rec feat_rec'] = self.losses_dict['feat_rec'] * self.FeatReconLoss(F_w.detach(), F_gen)
|
| 626 |
+
|
| 627 |
+
# LPIPS loss
|
| 628 |
+
losses['rec lpips_scale'] = self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(source), gen_w_256) + self.LPIPS(normalize(source), gen_F_256))
|
| 629 |
+
|
| 630 |
+
# Synt loss
|
| 631 |
+
# losses['l2_synt'] = self.losses_dict['l2_synt'] * self.SyntMSELoss(target * HT_E, (gen_F_256 + 1) / 2 * HT_E)
|
| 632 |
+
|
| 633 |
+
return losses
|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
class LossBuilderMulti(LossBuilder):
|
| 637 |
+
def __init__(self, *args, **kwargs):
|
| 638 |
+
super().__init__(*args, **kwargs)
|
| 639 |
+
self.DiceLoss = DiceLoss().to(kwargs.get('device', 'cuda')).eval()
|
| 640 |
+
self.dilated = DilatedMask(25)
|
| 641 |
+
|
| 642 |
+
def __call__(self, source, target, target_mask, HT_E, gen_w, F_w, gen_F, F_gen, **kwargs):
|
| 643 |
+
losses = {}
|
| 644 |
+
|
| 645 |
+
gen_w_256 = self.downsample_256(gen_w)
|
| 646 |
+
gen_F_256 = self.downsample_256(gen_F)
|
| 647 |
+
|
| 648 |
+
# Dice loss
|
| 649 |
+
with torch.no_grad():
|
| 650 |
+
target_512 = F.interpolate(target, size=(512, 512), mode='bilinear').clip(0, 1)
|
| 651 |
+
seg_target = self.DiceLoss.calc_landmark(target_512)
|
| 652 |
+
seg_target = F.interpolate(seg_target, size=(256, 256), mode='nearest')
|
| 653 |
+
seg_gen = F.interpolate(self.DiceLoss.calc_landmark((gen_F + 1) / 2), size=(256, 256), mode='nearest')
|
| 654 |
+
|
| 655 |
+
losses['DiceLoss'] = self.losses_dict['landmark'] * self.DiceLoss(seg_gen, seg_target)
|
| 656 |
+
|
| 657 |
+
# ID loss
|
| 658 |
+
losses['id'] = self.losses_dict['id'] * (self.IDLoss(normalize(source) * target_mask, gen_w_256 * target_mask) +
|
| 659 |
+
self.IDLoss(normalize(source) * target_mask, gen_F_256 * target_mask))
|
| 660 |
+
|
| 661 |
+
# Feat Recons loss
|
| 662 |
+
losses['feat_rec'] = self.losses_dict['feat_rec'] * self.FeatReconLoss(F_w.detach(), F_gen)
|
| 663 |
+
|
| 664 |
+
# LPIPS loss
|
| 665 |
+
losses['lpips_face'] = 0.5 * self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(source) * target_mask, gen_w_256 * target_mask) +
|
| 666 |
+
self.LPIPS(normalize(source) * target_mask, gen_F_256 * target_mask))
|
| 667 |
+
losses['lpips_hair'] = 0.5 * self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(target) * HT_E, gen_w_256 * HT_E) +
|
| 668 |
+
self.LPIPS(normalize(target) * HT_E, gen_F_256 * HT_E))
|
| 669 |
+
|
| 670 |
+
# Inpaint loss
|
| 671 |
+
if self.losses_dict['inpaint'] != 0.:
|
| 672 |
+
M_Inp = (1 - target_mask) * (1 - HT_E)
|
| 673 |
+
Smooth_M = self.dilated(M_Inp)
|
| 674 |
+
losses['inpaint'] = 0.5 * self.losses_dict['inpaint'] * self.LPIPS(normalize(target) * Smooth_M, gen_F_256 * Smooth_M)
|
| 675 |
+
losses['inpaint'] += 0.5 * self.losses_dict['inpaint'] * self.LPIPS(gen_w_256.detach() * Smooth_M * (1 - HT_E), gen_F_256 * Smooth_M * (1 - HT_E))
|
| 676 |
+
|
| 677 |
+
return losses
|
losses/style/__init__.py
ADDED
|
File without changes
|
losses/style/custom_loss.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
mse_loss = nn.MSELoss(reduction="mean")
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def custom_loss(x, y, mask=None, loss_type="l2", include_bkgd=True):
|
| 9 |
+
"""
|
| 10 |
+
x, y: [N, C, H, W]
|
| 11 |
+
Computes L1/L2 loss
|
| 12 |
+
|
| 13 |
+
if include_bkgd is True:
|
| 14 |
+
use traditional MSE and L1 loss
|
| 15 |
+
else:
|
| 16 |
+
mask out background info using :mask
|
| 17 |
+
normalize loss with #1's in mask
|
| 18 |
+
"""
|
| 19 |
+
if include_bkgd:
|
| 20 |
+
# perform simple mse or l1 loss
|
| 21 |
+
if loss_type == "l2":
|
| 22 |
+
loss_rec = mse_loss(x, y)
|
| 23 |
+
elif loss_type == "l1":
|
| 24 |
+
loss_rec = F.l1_loss(x, y)
|
| 25 |
+
|
| 26 |
+
return loss_rec
|
| 27 |
+
|
| 28 |
+
Nx, Cx, Hx, Wx = x.shape
|
| 29 |
+
Nm, Cm, Hm, Wm = mask.shape
|
| 30 |
+
mask = prepare_mask(x, mask)
|
| 31 |
+
|
| 32 |
+
x_reshape = torch.reshape(x, [Nx, -1])
|
| 33 |
+
y_reshape = torch.reshape(y, [Nx, -1])
|
| 34 |
+
mask_reshape = torch.reshape(mask, [Nx, -1])
|
| 35 |
+
|
| 36 |
+
if loss_type == "l2":
|
| 37 |
+
diff = (x_reshape - y_reshape) ** 2
|
| 38 |
+
elif loss_type == "l1":
|
| 39 |
+
diff = torch.abs(x_reshape - y_reshape)
|
| 40 |
+
|
| 41 |
+
# diff: [N, Cx * Hx * Wx]
|
| 42 |
+
# set elements in diff to 0 using mask
|
| 43 |
+
masked_diff = diff * mask_reshape
|
| 44 |
+
sum_diff = torch.sum(masked_diff, axis=-1)
|
| 45 |
+
# count non-zero elements; add :mask_reshape elements
|
| 46 |
+
norm_count = torch.sum(mask_reshape, axis=-1)
|
| 47 |
+
diff_norm = sum_diff / (norm_count + 1.0)
|
| 48 |
+
|
| 49 |
+
loss_rec = torch.mean(diff_norm)
|
| 50 |
+
|
| 51 |
+
return loss_rec
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def prepare_mask(x, mask):
|
| 55 |
+
"""
|
| 56 |
+
Make mask similar to x.
|
| 57 |
+
Mask contains values in [0, 1].
|
| 58 |
+
Adjust channels and spatial dimensions.
|
| 59 |
+
"""
|
| 60 |
+
Nx, Cx, Hx, Wx = x.shape
|
| 61 |
+
Nm, Cm, Hm, Wm = mask.shape
|
| 62 |
+
if Cm == 1:
|
| 63 |
+
mask = mask.repeat(1, Cx, 1, 1)
|
| 64 |
+
|
| 65 |
+
mask = F.interpolate(mask, scale_factor=Hx / Hm, mode="nearest")
|
| 66 |
+
|
| 67 |
+
return mask
|
losses/style/style_loss.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.nn import functional as F
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
from losses.style.custom_loss import custom_loss, prepare_mask
|
| 8 |
+
from losses.style.vgg_activations import VGG16_Activations, VGG19_Activations, Vgg_face_dag
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class StyleLoss(nn.Module):
|
| 12 |
+
def __init__(self, VGG16_ACTIVATIONS_LIST=[21], normalize=False, distance="l2"):
|
| 13 |
+
|
| 14 |
+
super(StyleLoss, self).__init__()
|
| 15 |
+
|
| 16 |
+
self.vgg16_act = VGG16_Activations(VGG16_ACTIVATIONS_LIST)
|
| 17 |
+
self.vgg16_act.eval()
|
| 18 |
+
|
| 19 |
+
self.normalize = normalize
|
| 20 |
+
self.distance = distance
|
| 21 |
+
|
| 22 |
+
def get_features(self, model, x):
|
| 23 |
+
|
| 24 |
+
return model(x)
|
| 25 |
+
|
| 26 |
+
def mask_features(self, x, mask):
|
| 27 |
+
|
| 28 |
+
mask = prepare_mask(x, mask)
|
| 29 |
+
return x * mask
|
| 30 |
+
|
| 31 |
+
def gram_matrix(self, x):
|
| 32 |
+
"""
|
| 33 |
+
:x is an activation tensor
|
| 34 |
+
"""
|
| 35 |
+
N, C, H, W = x.shape
|
| 36 |
+
x = x.view(N * C, H * W)
|
| 37 |
+
G = torch.mm(x, x.t())
|
| 38 |
+
|
| 39 |
+
return G.div(N * H * W * C)
|
| 40 |
+
|
| 41 |
+
def cal_style(self, model, x, x_hat, mask1=None, mask2=None):
|
| 42 |
+
# Get features from the model for x and x_hat
|
| 43 |
+
with torch.no_grad():
|
| 44 |
+
act_x = self.get_features(model, x)
|
| 45 |
+
for layer in range(0, len(act_x)):
|
| 46 |
+
act_x[layer].detach_()
|
| 47 |
+
|
| 48 |
+
act_x_hat = self.get_features(model, x_hat)
|
| 49 |
+
|
| 50 |
+
loss = 0.0
|
| 51 |
+
for layer in range(0, len(act_x)):
|
| 52 |
+
|
| 53 |
+
# mask features if present
|
| 54 |
+
if mask1 is not None:
|
| 55 |
+
feat_x = self.mask_features(act_x[layer], mask1)
|
| 56 |
+
else:
|
| 57 |
+
feat_x = act_x[layer]
|
| 58 |
+
if mask2 is not None:
|
| 59 |
+
feat_x_hat = self.mask_features(act_x_hat[layer], mask2)
|
| 60 |
+
else:
|
| 61 |
+
feat_x_hat = act_x_hat[layer]
|
| 62 |
+
|
| 63 |
+
"""
|
| 64 |
+
import ipdb; ipdb.set_trace()
|
| 65 |
+
fx = feat_x[0, ...].detach().cpu().numpy()
|
| 66 |
+
fx = (fx - fx.min()) / (fx.max() - fx.min())
|
| 67 |
+
fx = fx * 255.
|
| 68 |
+
fxhat = feat_x_hat[0, ...].detach().cpu().numpy()
|
| 69 |
+
fxhat = (fxhat - fxhat.min()) / (fxhat.max() - fxhat.min())
|
| 70 |
+
fxhat = fxhat * 255
|
| 71 |
+
from PIL import Image
|
| 72 |
+
import numpy as np
|
| 73 |
+
for idx, img in enumerate(fx):
|
| 74 |
+
img = fx[idx, ...]
|
| 75 |
+
img = img.astype(np.uint8)
|
| 76 |
+
img = Image.fromarray(img)
|
| 77 |
+
img.save('plot/feat_x/{}.png'.format(str(idx)))
|
| 78 |
+
img = fxhat[idx, ...]
|
| 79 |
+
img = img.astype(np.uint8)
|
| 80 |
+
img = Image.fromarray(img)
|
| 81 |
+
img.save('plot/feat_x_hat/{}.png'.format(str(idx)))
|
| 82 |
+
import ipdb; ipdb.set_trace()
|
| 83 |
+
"""
|
| 84 |
+
|
| 85 |
+
# compute Gram matrix for x and x_hat
|
| 86 |
+
G_x = self.gram_matrix(feat_x)
|
| 87 |
+
G_x_hat = self.gram_matrix(feat_x_hat)
|
| 88 |
+
|
| 89 |
+
# compute layer wise loss and aggregate
|
| 90 |
+
loss += custom_loss(
|
| 91 |
+
G_x, G_x_hat, mask=None, loss_type=self.distance, include_bkgd=True
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
loss = loss / len(act_x)
|
| 95 |
+
|
| 96 |
+
return loss
|
| 97 |
+
|
| 98 |
+
def forward(self, x, x_hat, mask1=None, mask2=None):
|
| 99 |
+
x = x.cuda()
|
| 100 |
+
x_hat = x_hat.cuda()
|
| 101 |
+
|
| 102 |
+
# resize images to 256px resolution
|
| 103 |
+
N, C, H, W = x.shape
|
| 104 |
+
upsample2d = nn.Upsample(
|
| 105 |
+
scale_factor=256 / H, mode="bilinear", align_corners=True
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
x = upsample2d(x)
|
| 109 |
+
x_hat = upsample2d(x_hat)
|
| 110 |
+
|
| 111 |
+
loss = self.cal_style(self.vgg16_act, x, x_hat, mask1=mask1, mask2=mask2)
|
| 112 |
+
|
| 113 |
+
return loss
|
losses/style/vgg_activations.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
import torchvision.models as models
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def requires_grad(model, flag=True):
|
| 8 |
+
for p in model.parameters():
|
| 9 |
+
p.requires_grad = flag
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class VGG16_Activations(nn.Module):
|
| 13 |
+
def __init__(self, feature_idx):
|
| 14 |
+
super(VGG16_Activations, self).__init__()
|
| 15 |
+
vgg16 = models.vgg16(pretrained=True)
|
| 16 |
+
features = list(vgg16.features)
|
| 17 |
+
self.features = nn.ModuleList(features).eval()
|
| 18 |
+
self.layer_id_list = feature_idx
|
| 19 |
+
|
| 20 |
+
def forward(self, x):
|
| 21 |
+
activations = []
|
| 22 |
+
for i, model in enumerate(self.features):
|
| 23 |
+
x = model(x)
|
| 24 |
+
if i in self.layer_id_list:
|
| 25 |
+
activations.append(x)
|
| 26 |
+
|
| 27 |
+
return activations
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class VGG19_Activations(nn.Module):
|
| 31 |
+
def __init__(self, feature_idx, requires_grad=False):
|
| 32 |
+
super(VGG19_Activations, self).__init__()
|
| 33 |
+
vgg19 = models.vgg19(pretrained=True)
|
| 34 |
+
requires_grad(vgg19, flag=False)
|
| 35 |
+
features = list(vgg19.features)
|
| 36 |
+
self.features = nn.ModuleList(features).eval()
|
| 37 |
+
self.layer_id_list = feature_idx
|
| 38 |
+
|
| 39 |
+
def forward(self, x):
|
| 40 |
+
activations = []
|
| 41 |
+
for i, model in enumerate(self.features):
|
| 42 |
+
x = model(x)
|
| 43 |
+
if i in self.layer_id_list:
|
| 44 |
+
activations.append(x)
|
| 45 |
+
|
| 46 |
+
return activations
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# http://www.robots.ox.ac.uk/~albanie/models/pytorch-mcn/vgg_face_dag.py
|
| 50 |
+
class Vgg_face_dag(nn.Module):
|
| 51 |
+
def __init__(self):
|
| 52 |
+
super(Vgg_face_dag, self).__init__()
|
| 53 |
+
self.meta = {
|
| 54 |
+
"mean": [129.186279296875, 104.76238250732422, 93.59396362304688],
|
| 55 |
+
"std": [1, 1, 1],
|
| 56 |
+
"imageSize": [224, 224, 3],
|
| 57 |
+
}
|
| 58 |
+
self.conv1_1 = nn.Conv2d(
|
| 59 |
+
3, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 60 |
+
)
|
| 61 |
+
self.relu1_1 = nn.ReLU(inplace=True)
|
| 62 |
+
self.conv1_2 = nn.Conv2d(
|
| 63 |
+
64, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 64 |
+
)
|
| 65 |
+
self.relu1_2 = nn.ReLU(inplace=True)
|
| 66 |
+
self.pool1 = nn.MaxPool2d(
|
| 67 |
+
kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
|
| 68 |
+
)
|
| 69 |
+
self.conv2_1 = nn.Conv2d(
|
| 70 |
+
64, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 71 |
+
)
|
| 72 |
+
self.relu2_1 = nn.ReLU(inplace=True)
|
| 73 |
+
self.conv2_2 = nn.Conv2d(
|
| 74 |
+
128, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 75 |
+
)
|
| 76 |
+
self.relu2_2 = nn.ReLU(inplace=True)
|
| 77 |
+
self.pool2 = nn.MaxPool2d(
|
| 78 |
+
kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
|
| 79 |
+
)
|
| 80 |
+
self.conv3_1 = nn.Conv2d(
|
| 81 |
+
128, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 82 |
+
)
|
| 83 |
+
self.relu3_1 = nn.ReLU(inplace=True)
|
| 84 |
+
self.conv3_2 = nn.Conv2d(
|
| 85 |
+
256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 86 |
+
)
|
| 87 |
+
self.relu3_2 = nn.ReLU(inplace=True)
|
| 88 |
+
self.conv3_3 = nn.Conv2d(
|
| 89 |
+
256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 90 |
+
)
|
| 91 |
+
self.relu3_3 = nn.ReLU(inplace=True)
|
| 92 |
+
self.pool3 = nn.MaxPool2d(
|
| 93 |
+
kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
|
| 94 |
+
)
|
| 95 |
+
self.conv4_1 = nn.Conv2d(
|
| 96 |
+
256, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 97 |
+
)
|
| 98 |
+
self.relu4_1 = nn.ReLU(inplace=True)
|
| 99 |
+
self.conv4_2 = nn.Conv2d(
|
| 100 |
+
512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 101 |
+
)
|
| 102 |
+
self.relu4_2 = nn.ReLU(inplace=True)
|
| 103 |
+
self.conv4_3 = nn.Conv2d(
|
| 104 |
+
512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 105 |
+
)
|
| 106 |
+
self.relu4_3 = nn.ReLU(inplace=True)
|
| 107 |
+
self.pool4 = nn.MaxPool2d(
|
| 108 |
+
kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
|
| 109 |
+
)
|
| 110 |
+
self.conv5_1 = nn.Conv2d(
|
| 111 |
+
512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 112 |
+
)
|
| 113 |
+
self.relu5_1 = nn.ReLU(inplace=True)
|
| 114 |
+
self.conv5_2 = nn.Conv2d(
|
| 115 |
+
512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 116 |
+
)
|
| 117 |
+
self.relu5_2 = nn.ReLU(inplace=True)
|
| 118 |
+
self.conv5_3 = nn.Conv2d(
|
| 119 |
+
512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
|
| 120 |
+
)
|
| 121 |
+
self.relu5_3 = nn.ReLU(inplace=True)
|
| 122 |
+
self.pool5 = nn.MaxPool2d(
|
| 123 |
+
kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
|
| 124 |
+
)
|
| 125 |
+
self.fc6 = nn.Linear(in_features=25088, out_features=4096, bias=True)
|
| 126 |
+
self.relu6 = nn.ReLU(inplace=True)
|
| 127 |
+
self.dropout6 = nn.Dropout(p=0.5)
|
| 128 |
+
self.fc7 = nn.Linear(in_features=4096, out_features=4096, bias=True)
|
| 129 |
+
self.relu7 = nn.ReLU(inplace=True)
|
| 130 |
+
self.dropout7 = nn.Dropout(p=0.5)
|
| 131 |
+
self.fc8 = nn.Linear(in_features=4096, out_features=2622, bias=True)
|
| 132 |
+
|
| 133 |
+
def forward(self, x):
|
| 134 |
+
activations = []
|
| 135 |
+
x1 = self.conv1_1(x)
|
| 136 |
+
activations.append(x1)
|
| 137 |
+
|
| 138 |
+
x2 = self.relu1_1(x1)
|
| 139 |
+
x3 = self.conv1_2(x2)
|
| 140 |
+
x4 = self.relu1_2(x3)
|
| 141 |
+
x5 = self.pool1(x4)
|
| 142 |
+
x6 = self.conv2_1(x5)
|
| 143 |
+
activations.append(x6)
|
| 144 |
+
|
| 145 |
+
x7 = self.relu2_1(x6)
|
| 146 |
+
x8 = self.conv2_2(x7)
|
| 147 |
+
x9 = self.relu2_2(x8)
|
| 148 |
+
x10 = self.pool2(x9)
|
| 149 |
+
x11 = self.conv3_1(x10)
|
| 150 |
+
activations.append(x11)
|
| 151 |
+
|
| 152 |
+
x12 = self.relu3_1(x11)
|
| 153 |
+
x13 = self.conv3_2(x12)
|
| 154 |
+
x14 = self.relu3_2(x13)
|
| 155 |
+
x15 = self.conv3_3(x14)
|
| 156 |
+
x16 = self.relu3_3(x15)
|
| 157 |
+
x17 = self.pool3(x16)
|
| 158 |
+
x18 = self.conv4_1(x17)
|
| 159 |
+
activations.append(x18)
|
| 160 |
+
|
| 161 |
+
x19 = self.relu4_1(x18)
|
| 162 |
+
x20 = self.conv4_2(x19)
|
| 163 |
+
x21 = self.relu4_2(x20)
|
| 164 |
+
x22 = self.conv4_3(x21)
|
| 165 |
+
x23 = self.relu4_3(x22)
|
| 166 |
+
x24 = self.pool4(x23)
|
| 167 |
+
x25 = self.conv5_1(x24)
|
| 168 |
+
activations.append(x25)
|
| 169 |
+
|
| 170 |
+
"""
|
| 171 |
+
x26 = self.relu5_1(x25)
|
| 172 |
+
x27 = self.conv5_2(x26)
|
| 173 |
+
x28 = self.relu5_2(x27)
|
| 174 |
+
x29 = self.conv5_3(x28)
|
| 175 |
+
x30 = self.relu5_3(x29)
|
| 176 |
+
x31_preflatten = self.pool5(x30)
|
| 177 |
+
x31 = x31_preflatten.view(x31_preflatten.size(0), -1)
|
| 178 |
+
x32 = self.fc6(x31)
|
| 179 |
+
x33 = self.relu6(x32)
|
| 180 |
+
x34 = self.dropout6(x33)
|
| 181 |
+
x35 = self.fc7(x34)
|
| 182 |
+
x36 = self.relu7(x35)
|
| 183 |
+
x37 = self.dropout7(x36)
|
| 184 |
+
x38 = self.fc8(x37)
|
| 185 |
+
"""
|
| 186 |
+
|
| 187 |
+
return activations
|
losses/vgg_loss.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchvision
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
class VGG19(torch.nn.Module):
|
| 6 |
+
def __init__(self, requires_grad=False):
|
| 7 |
+
super().__init__()
|
| 8 |
+
vgg_pretrained_features = torchvision.models.vgg19(pretrained=True).features
|
| 9 |
+
self.slice1 = torch.nn.Sequential()
|
| 10 |
+
self.slice2 = torch.nn.Sequential()
|
| 11 |
+
self.slice3 = torch.nn.Sequential()
|
| 12 |
+
self.slice4 = torch.nn.Sequential()
|
| 13 |
+
self.slice5 = torch.nn.Sequential()
|
| 14 |
+
for x in range(2):
|
| 15 |
+
self.slice1.add_module(str(x), vgg_pretrained_features[x])
|
| 16 |
+
for x in range(2, 7):
|
| 17 |
+
self.slice2.add_module(str(x), vgg_pretrained_features[x])
|
| 18 |
+
for x in range(7, 12):
|
| 19 |
+
self.slice3.add_module(str(x), vgg_pretrained_features[x])
|
| 20 |
+
for x in range(12, 21):
|
| 21 |
+
self.slice4.add_module(str(x), vgg_pretrained_features[x])
|
| 22 |
+
for x in range(21, 30):
|
| 23 |
+
self.slice5.add_module(str(x), vgg_pretrained_features[x])
|
| 24 |
+
if not requires_grad:
|
| 25 |
+
for param in self.parameters():
|
| 26 |
+
param.requires_grad = False
|
| 27 |
+
|
| 28 |
+
def forward(self, X):
|
| 29 |
+
h_relu1 = self.slice1(X)
|
| 30 |
+
h_relu2 = self.slice2(h_relu1)
|
| 31 |
+
h_relu3 = self.slice3(h_relu2)
|
| 32 |
+
h_relu4 = self.slice4(h_relu3)
|
| 33 |
+
h_relu5 = self.slice5(h_relu4)
|
| 34 |
+
out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
|
| 35 |
+
return out
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Perceptual loss that uses a pretrained VGG network
|
| 39 |
+
class VGGLoss(nn.Module):
|
| 40 |
+
def __init__(self):
|
| 41 |
+
super(VGGLoss, self).__init__()
|
| 42 |
+
self.vgg = VGG19().cuda()
|
| 43 |
+
self.criterion = nn.L1Loss()
|
| 44 |
+
self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
|
| 45 |
+
|
| 46 |
+
def forward(self, x, y):
|
| 47 |
+
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
|
| 48 |
+
loss = 0
|
| 49 |
+
for i in range(len(x_vgg)):
|
| 50 |
+
loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach())
|
| 51 |
+
return loss
|
main.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
from torchvision.utils import save_image
|
| 7 |
+
from tqdm.auto import tqdm
|
| 8 |
+
|
| 9 |
+
from hair_swap import HairFast, get_parser
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def main(model_args, args):
|
| 13 |
+
hair_fast = HairFast(model_args)
|
| 14 |
+
|
| 15 |
+
experiments: list[str | tuple[str, str, str]] = []
|
| 16 |
+
if args.file_path is not None:
|
| 17 |
+
with open(args.file_path, 'r') as file:
|
| 18 |
+
experiments.extend(file.readlines())
|
| 19 |
+
|
| 20 |
+
if all(path is not None for path in (args.face_path, args.shape_path, args.color_path)):
|
| 21 |
+
experiments.append((args.face_path, args.shape_path, args.color_path))
|
| 22 |
+
|
| 23 |
+
for exp in tqdm(experiments):
|
| 24 |
+
if isinstance(exp, str):
|
| 25 |
+
file_1, file_2, file_3 = exp.split()
|
| 26 |
+
else:
|
| 27 |
+
file_1, file_2, file_3 = exp
|
| 28 |
+
|
| 29 |
+
face_path = args.input_dir / file_1
|
| 30 |
+
shape_path = args.input_dir / file_2
|
| 31 |
+
color_path = args.input_dir / file_3
|
| 32 |
+
|
| 33 |
+
base_name = '_'.join([path.stem for path in (face_path, shape_path, color_path)])
|
| 34 |
+
exp_name = base_name if model_args.save_all else None
|
| 35 |
+
|
| 36 |
+
if isinstance(exp, str) or args.result_path is None:
|
| 37 |
+
os.makedirs(args.output_dir, exist_ok=True)
|
| 38 |
+
output_image_path = args.output_dir / f'{base_name}.png'
|
| 39 |
+
else:
|
| 40 |
+
os.makedirs(args.result_path.parent, exist_ok=True)
|
| 41 |
+
output_image_path = args.result_path
|
| 42 |
+
|
| 43 |
+
final_image = hair_fast.swap(face_path, shape_path, color_path, benchmark=args.benchmark, exp_name=exp_name)
|
| 44 |
+
save_image(final_image, output_image_path)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
model_parser = get_parser()
|
| 49 |
+
parser = argparse.ArgumentParser(description='HairFast evaluate')
|
| 50 |
+
parser.add_argument('--input_dir', type=Path, default='', help='The directory of the images to be inverted')
|
| 51 |
+
parser.add_argument('--benchmark', action='store_true', help='Calculates the speed of the method during the session')
|
| 52 |
+
|
| 53 |
+
# Arguments for a set of experiments
|
| 54 |
+
parser.add_argument('--file_path', type=Path, default=None,
|
| 55 |
+
help='File with experiments with the format "face_path.png shape_path.png color_path.png"')
|
| 56 |
+
parser.add_argument('--output_dir', type=Path, default=Path('output'), help='The directory for final results')
|
| 57 |
+
|
| 58 |
+
# Arguments for single experiment
|
| 59 |
+
parser.add_argument('--face_path', type=Path, default=None, help='Path to the face image')
|
| 60 |
+
parser.add_argument('--shape_path', type=Path, default=None, help='Path to the shape image')
|
| 61 |
+
parser.add_argument('--color_path', type=Path, default=None, help='Path to the color image')
|
| 62 |
+
parser.add_argument('--result_path', type=Path, default=None, help='Path to save the result')
|
| 63 |
+
|
| 64 |
+
args, unknown1 = parser.parse_known_args()
|
| 65 |
+
model_args, unknown2 = model_parser.parse_known_args()
|
| 66 |
+
|
| 67 |
+
unknown_args = set(unknown1) & set(unknown2)
|
| 68 |
+
if unknown_args:
|
| 69 |
+
file_ = sys.stderr
|
| 70 |
+
print(f"Unknown arguments: {unknown_args}", file=file_)
|
| 71 |
+
|
| 72 |
+
print("\nExpected arguments for the model:", file=file_)
|
| 73 |
+
model_parser.print_help(file=file_)
|
| 74 |
+
|
| 75 |
+
print("\nExpected arguments for evaluate:", file=file_)
|
| 76 |
+
parser.print_help(file=file_)
|
| 77 |
+
|
| 78 |
+
sys.exit(1)
|
| 79 |
+
|
| 80 |
+
main(model_args, args)
|
models/.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
models/Alignment.py
ADDED
|
@@ -0,0 +1,181 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import torchvision.transforms as T
|
| 4 |
+
from torch import nn
|
| 5 |
+
|
| 6 |
+
from models.CtrlHair.shape_branch.config import cfg as cfg_mask
|
| 7 |
+
from models.CtrlHair.shape_branch.solver import get_hair_face_code, get_new_shape, Solver as SolverMask
|
| 8 |
+
from models.Encoders import RotateModel
|
| 9 |
+
from models.Net import Net, get_segmentation
|
| 10 |
+
from models.sean_codes.models.pix2pix_model import Pix2PixModel, SEAN_OPT, encode_sean, decode_sean
|
| 11 |
+
from utils.image_utils import DilateErosion
|
| 12 |
+
from utils.save_utils import save_vis_mask, save_gen_image, save_latents
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Alignment(nn.Module):
|
| 16 |
+
"""
|
| 17 |
+
Module for transferring the desired hair shape
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, opts, latent_encoder=None, net=None):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.opts = opts
|
| 23 |
+
self.latent_encoder = latent_encoder
|
| 24 |
+
if not net:
|
| 25 |
+
self.net = Net(self.opts)
|
| 26 |
+
else:
|
| 27 |
+
self.net = net
|
| 28 |
+
|
| 29 |
+
self.sean_model = Pix2PixModel(SEAN_OPT)
|
| 30 |
+
self.sean_model.eval()
|
| 31 |
+
|
| 32 |
+
solver_mask = SolverMask(cfg_mask, device=self.opts.device, local_rank=-1, training=False)
|
| 33 |
+
self.mask_generator = solver_mask.gen
|
| 34 |
+
self.mask_generator.load_state_dict(torch.load('pretrained_models/ShapeAdaptor/mask_generator.pth'))
|
| 35 |
+
|
| 36 |
+
self.rotate_model = RotateModel()
|
| 37 |
+
self.rotate_model.load_state_dict(torch.load(self.opts.rotate_checkpoint)['model_state_dict'])
|
| 38 |
+
self.rotate_model.to(self.opts.device).eval()
|
| 39 |
+
|
| 40 |
+
self.dilate_erosion = DilateErosion(dilate_erosion=self.opts.smooth, device=self.opts.device)
|
| 41 |
+
self.to_bisenet = T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
|
| 42 |
+
|
| 43 |
+
@torch.inference_mode()
|
| 44 |
+
def shape_module(self, im_name1: str, im_name2: str, name_to_embed, only_target=True, **kwargs):
|
| 45 |
+
device = self.opts.device
|
| 46 |
+
|
| 47 |
+
# load images
|
| 48 |
+
img1_in = name_to_embed[im_name1]['image_256']
|
| 49 |
+
img2_in = name_to_embed[im_name2]['image_256']
|
| 50 |
+
|
| 51 |
+
# load latents
|
| 52 |
+
latent_W_1 = name_to_embed[im_name1]["W"]
|
| 53 |
+
latent_W_2 = name_to_embed[im_name2]["W"]
|
| 54 |
+
|
| 55 |
+
# load masks
|
| 56 |
+
inp_mask1 = name_to_embed[im_name1]['mask']
|
| 57 |
+
inp_mask2 = name_to_embed[im_name2]['mask']
|
| 58 |
+
|
| 59 |
+
# Rotate stage
|
| 60 |
+
if img1_in is not img2_in:
|
| 61 |
+
rotate_to = self.rotate_model(latent_W_2[:, :6], latent_W_1[:, :6])
|
| 62 |
+
rotate_to = torch.cat((rotate_to, latent_W_2[:, 6:]), dim=1)
|
| 63 |
+
I_rot, _ = self.net.generator([rotate_to], input_is_latent=True, return_latents=False)
|
| 64 |
+
|
| 65 |
+
I_rot_to_seg = ((I_rot + 1) / 2).clip(0, 1)
|
| 66 |
+
I_rot_to_seg = self.to_bisenet(I_rot_to_seg)
|
| 67 |
+
rot_mask = get_segmentation(I_rot_to_seg)
|
| 68 |
+
else:
|
| 69 |
+
I_rot = None
|
| 70 |
+
rot_mask = inp_mask2
|
| 71 |
+
|
| 72 |
+
# Shape Adaptor
|
| 73 |
+
if img1_in is not img2_in:
|
| 74 |
+
face_1, hair_1 = get_hair_face_code(self.mask_generator, inp_mask1[0, 0, ...])
|
| 75 |
+
face_2, hair_2 = get_hair_face_code(self.mask_generator, rot_mask[0, 0, ...])
|
| 76 |
+
|
| 77 |
+
target_mask = get_new_shape(self.mask_generator, face_1, hair_2)[None, None]
|
| 78 |
+
else:
|
| 79 |
+
target_mask = inp_mask1
|
| 80 |
+
|
| 81 |
+
# Hair mask
|
| 82 |
+
hair_mask_target = torch.where(target_mask == 13, torch.ones_like(target_mask, device=device),
|
| 83 |
+
torch.zeros_like(target_mask, device=device))
|
| 84 |
+
|
| 85 |
+
if self.opts.save_all:
|
| 86 |
+
exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
|
| 87 |
+
output_dir = self.opts.save_all_dir / exp_name
|
| 88 |
+
if I_rot is not None:
|
| 89 |
+
save_gen_image(output_dir, 'Shape', f'{im_name2}_rotate_to_{im_name1}.png', I_rot)
|
| 90 |
+
save_vis_mask(output_dir, 'Shape', f'mask_{im_name1}.png', inp_mask1)
|
| 91 |
+
save_vis_mask(output_dir, 'Shape', f'mask_{im_name2}.png', inp_mask2)
|
| 92 |
+
save_vis_mask(output_dir, 'Shape', f'mask_{im_name2}_rotate_to_{im_name1}.png', rot_mask)
|
| 93 |
+
save_vis_mask(output_dir, 'Shape', f'mask_{im_name1}_{im_name2}_target.png', target_mask)
|
| 94 |
+
|
| 95 |
+
if only_target:
|
| 96 |
+
return {'HM_X': hair_mask_target}
|
| 97 |
+
else:
|
| 98 |
+
hair_mask1 = torch.where(inp_mask1 == 13, torch.ones_like(inp_mask1, device=device),
|
| 99 |
+
torch.zeros_like(inp_mask1, device=device))
|
| 100 |
+
hair_mask2 = torch.where(inp_mask2 == 13, torch.ones_like(inp_mask2, device=device),
|
| 101 |
+
torch.zeros_like(inp_mask2, device=device))
|
| 102 |
+
|
| 103 |
+
return inp_mask1, hair_mask1, inp_mask2, hair_mask2, target_mask, hair_mask_target
|
| 104 |
+
|
| 105 |
+
@torch.inference_mode()
|
| 106 |
+
def align_images(self, im_name1, im_name2, name_to_embed, **kwargs):
|
| 107 |
+
# load images
|
| 108 |
+
img1_in = name_to_embed[im_name1]['image_256']
|
| 109 |
+
img2_in = name_to_embed[im_name2]['image_256']
|
| 110 |
+
|
| 111 |
+
# load latents
|
| 112 |
+
latent_S_1, latent_F_1 = name_to_embed[im_name1]["S"], name_to_embed[im_name1]["F"]
|
| 113 |
+
latent_S_2, latent_F_2 = name_to_embed[im_name2]["S"], name_to_embed[im_name2]["F"]
|
| 114 |
+
|
| 115 |
+
# Shape Module
|
| 116 |
+
if img1_in is img2_in:
|
| 117 |
+
hair_mask_target = self.shape_module(im_name1, im_name2, name_to_embed, only_target=True, **kwargs)['HM_X']
|
| 118 |
+
return {'latent_F_align': latent_F_1, 'HM_X': hair_mask_target}
|
| 119 |
+
|
| 120 |
+
inp_mask1, hair_mask1, inp_mask2, hair_mask2, target_mask, hair_mask_target = (
|
| 121 |
+
self.shape_module(im_name1, im_name2, name_to_embed, only_target=False, **kwargs)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
images = torch.cat([img1_in, img2_in], dim=0)
|
| 125 |
+
labels = torch.cat([inp_mask1, inp_mask2], dim=0)
|
| 126 |
+
|
| 127 |
+
# SEAN for inpaint
|
| 128 |
+
img1_code, img2_code = encode_sean(self.sean_model, images, labels)
|
| 129 |
+
|
| 130 |
+
gen1_sean = decode_sean(self.sean_model, img1_code.unsqueeze(0), target_mask)
|
| 131 |
+
gen2_sean = decode_sean(self.sean_model, img2_code.unsqueeze(0), target_mask)
|
| 132 |
+
|
| 133 |
+
# Encoding result in F from E4E
|
| 134 |
+
enc_imgs = self.latent_encoder([gen1_sean, gen2_sean])
|
| 135 |
+
intermediate_align, latent_inter = enc_imgs["F"][0].unsqueeze(0), enc_imgs["W"][0].unsqueeze(0)
|
| 136 |
+
latent_F_out_new, latent_out = enc_imgs["F"][1].unsqueeze(0), enc_imgs["W"][1].unsqueeze(0)
|
| 137 |
+
|
| 138 |
+
# Alignment of F space
|
| 139 |
+
masks = [
|
| 140 |
+
1 - (1 - hair_mask1) * (1 - hair_mask_target),
|
| 141 |
+
hair_mask_target,
|
| 142 |
+
hair_mask2 * hair_mask_target
|
| 143 |
+
]
|
| 144 |
+
masks = torch.cat(masks, dim=0)
|
| 145 |
+
# masks = T.functional.resize(masks, (1024, 1024), interpolation=T.InterpolationMode.NEAREST)
|
| 146 |
+
|
| 147 |
+
dilate, erosion = self.dilate_erosion.mask(masks)
|
| 148 |
+
free_mask = [
|
| 149 |
+
dilate[0],
|
| 150 |
+
erosion[1],
|
| 151 |
+
erosion[2]
|
| 152 |
+
]
|
| 153 |
+
free_mask = torch.stack(free_mask, dim=0)
|
| 154 |
+
free_mask_down_32 = F.interpolate(free_mask.float(), size=(32, 32), mode='bicubic')
|
| 155 |
+
interpolation_low = 1 - free_mask_down_32
|
| 156 |
+
|
| 157 |
+
latent_F_align = intermediate_align + interpolation_low[0] * (latent_F_1 - intermediate_align)
|
| 158 |
+
latent_F_align = latent_F_out_new + interpolation_low[1] * (latent_F_align - latent_F_out_new)
|
| 159 |
+
latent_F_align = latent_F_2 + interpolation_low[2] * (latent_F_align - latent_F_2)
|
| 160 |
+
|
| 161 |
+
if self.opts.save_all:
|
| 162 |
+
exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
|
| 163 |
+
output_dir = self.opts.save_all_dir / exp_name
|
| 164 |
+
save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_SEAN.png', gen1_sean)
|
| 165 |
+
save_gen_image(output_dir, 'Align', f'{im_name2}_{im_name1}_SEAN.png', gen2_sean)
|
| 166 |
+
|
| 167 |
+
img1_e4e = self.net.generator([latent_inter], input_is_latent=True, return_latents=False, start_layer=4,
|
| 168 |
+
end_layer=8, layer_in=intermediate_align)[0]
|
| 169 |
+
img2_e4e = self.net.generator([latent_out], input_is_latent=True, return_latents=False, start_layer=4,
|
| 170 |
+
end_layer=8, layer_in=latent_F_out_new)[0]
|
| 171 |
+
|
| 172 |
+
save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_e4e.png', img1_e4e)
|
| 173 |
+
save_gen_image(output_dir, 'Align', f'{im_name2}_{im_name1}_e4e.png', img2_e4e)
|
| 174 |
+
|
| 175 |
+
gen_im, _ = self.net.generator([latent_S_1], input_is_latent=True, return_latents=False, start_layer=4,
|
| 176 |
+
end_layer=8, layer_in=latent_F_align)
|
| 177 |
+
|
| 178 |
+
save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_output.png', gen_im)
|
| 179 |
+
save_latents(output_dir, 'Align', f'{im_name1}_{im_name2}_F.npz', latent_F_align=latent_F_align)
|
| 180 |
+
|
| 181 |
+
return {'latent_F_align': latent_F_align, 'HM_X': hair_mask_target}
|
models/Blending.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
|
| 4 |
+
from models.Encoders import ClipBlendingModel, PostProcessModel
|
| 5 |
+
from models.Net import Net
|
| 6 |
+
from utils.bicubic import BicubicDownSample
|
| 7 |
+
from utils.image_utils import DilateErosion
|
| 8 |
+
from utils.save_utils import save_gen_image, save_latents
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Blending(nn.Module):
|
| 12 |
+
"""
|
| 13 |
+
Module for transferring the desired hair color and post processing
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, opts, net=None):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.opts = opts
|
| 19 |
+
if net is None:
|
| 20 |
+
self.net = Net(self.opts)
|
| 21 |
+
else:
|
| 22 |
+
self.net = net
|
| 23 |
+
|
| 24 |
+
blending_checkpoint = torch.load(self.opts.blending_checkpoint)
|
| 25 |
+
self.blending_encoder = ClipBlendingModel(blending_checkpoint.get('clip', "ViT-B/32"))
|
| 26 |
+
self.blending_encoder.load_state_dict(blending_checkpoint['model_state_dict'], strict=False)
|
| 27 |
+
self.blending_encoder.to(self.opts.device).eval()
|
| 28 |
+
|
| 29 |
+
self.post_process = PostProcessModel().to(self.opts.device).eval()
|
| 30 |
+
self.post_process.load_state_dict(torch.load(self.opts.pp_checkpoint)['model_state_dict'])
|
| 31 |
+
|
| 32 |
+
self.dilate_erosion = DilateErosion(dilate_erosion=self.opts.smooth, device=self.opts.device)
|
| 33 |
+
self.downsample_256 = BicubicDownSample(factor=4)
|
| 34 |
+
|
| 35 |
+
@torch.inference_mode()
|
| 36 |
+
def blend_images(self, align_shape, align_color, name_to_embed, **kwargs):
|
| 37 |
+
I_1 = name_to_embed['face']['image_norm_256']
|
| 38 |
+
I_2 = name_to_embed['shape']['image_norm_256']
|
| 39 |
+
I_3 = name_to_embed['color']['image_norm_256']
|
| 40 |
+
|
| 41 |
+
mask_de = self.dilate_erosion.hair_from_mask(
|
| 42 |
+
torch.cat([name_to_embed[x]['mask'] for x in ['face', 'color']], dim=0)
|
| 43 |
+
)
|
| 44 |
+
HM_1D, _ = mask_de[0][0].unsqueeze(0), mask_de[1][0].unsqueeze(0)
|
| 45 |
+
HM_3D, HM_3E = mask_de[0][1].unsqueeze(0), mask_de[1][1].unsqueeze(0)
|
| 46 |
+
|
| 47 |
+
latent_S_1, latent_F_align = name_to_embed['face']['S'], align_shape['latent_F_align']
|
| 48 |
+
HM_X = align_color['HM_X']
|
| 49 |
+
|
| 50 |
+
latent_S_3 = name_to_embed['color']["S"]
|
| 51 |
+
|
| 52 |
+
HM_XD, _ = self.dilate_erosion.mask(HM_X)
|
| 53 |
+
target_mask = (1 - HM_1D) * (1 - HM_3D) * (1 - HM_XD)
|
| 54 |
+
|
| 55 |
+
# Blending
|
| 56 |
+
if I_1 is not I_3 or I_1 is not I_2:
|
| 57 |
+
S_blend_6_18 = self.blending_encoder(latent_S_1[:, 6:], latent_S_3[:, 6:], I_1 * target_mask, I_3 * HM_3E)
|
| 58 |
+
S_blend = torch.cat((latent_S_1[:, :6], S_blend_6_18), dim=1)
|
| 59 |
+
else:
|
| 60 |
+
S_blend = latent_S_1
|
| 61 |
+
|
| 62 |
+
I_blend, _ = self.net.generator([S_blend], input_is_latent=True, return_latents=False, start_layer=4,
|
| 63 |
+
end_layer=8, layer_in=latent_F_align)
|
| 64 |
+
I_blend_256 = self.downsample_256(I_blend)
|
| 65 |
+
|
| 66 |
+
# Post Process
|
| 67 |
+
S_final, F_final = self.post_process(I_1, I_blend_256)
|
| 68 |
+
I_final, _ = self.net.generator([S_final], input_is_latent=True, return_latents=False,
|
| 69 |
+
start_layer=5, end_layer=8, layer_in=F_final)
|
| 70 |
+
|
| 71 |
+
if self.opts.save_all:
|
| 72 |
+
exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
|
| 73 |
+
output_dir = self.opts.save_all_dir / exp_name
|
| 74 |
+
save_gen_image(output_dir, 'Blending', 'blending.png', I_blend)
|
| 75 |
+
save_latents(output_dir, 'Blending', 'blending.npz', S_blend=S_blend)
|
| 76 |
+
|
| 77 |
+
save_gen_image(output_dir, 'Final', 'final.png', I_final)
|
| 78 |
+
save_latents(output_dir, 'Final', 'final.npz', S_final=S_final, F_final=F_final)
|
| 79 |
+
|
| 80 |
+
final_image = ((I_final[0] + 1) / 2).clip(0, 1)
|
| 81 |
+
return final_image
|
models/CtrlHair/.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.idea/
|
| 2 |
+
.DS_Store
|
| 3 |
+
/dataset_info_ctrlhair/
|
| 4 |
+
/external_model_params/
|
| 5 |
+
/model_trained/
|
| 6 |
+
**/__pycache__/**
|
| 7 |
+
|
| 8 |
+
|
models/CtrlHair/README.md
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# [GAN with Multivariate Disentangling for Controllable Hair Editing (ECCV 2022)](https://github.com/XuyangGuo/xuyangguo.github.io/raw/master/database/CtrlHair/CtrlHair.pdf)
|
| 2 |
+
|
| 3 |
+
[Xuyang Guo](https://xuyangguo.github.io/), [Meina Kan](http://vipl.ict.ac.cn/homepage/mnkan/Publication/), Tianle Chen, [Shiguang Shan](https://scholar.google.com/citations?user=Vkzd7MIAAAAJ)
|
| 4 |
+
|
| 5 |
+
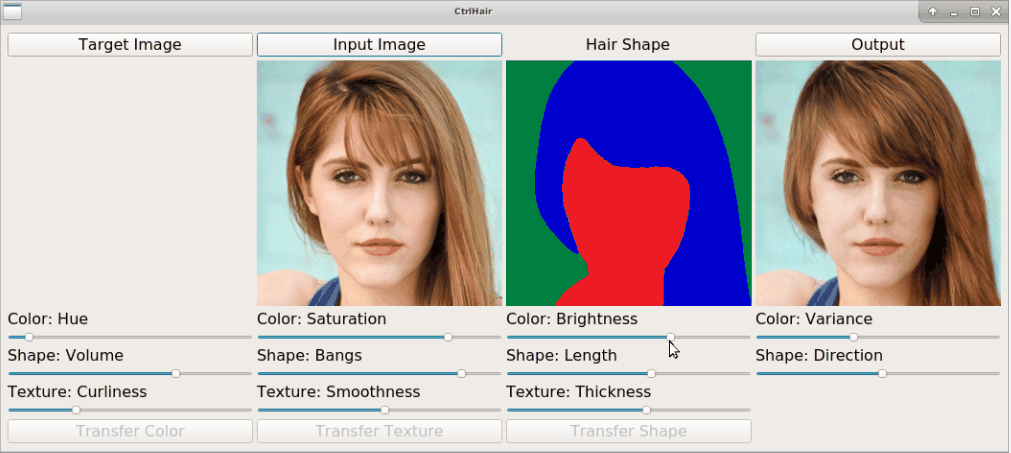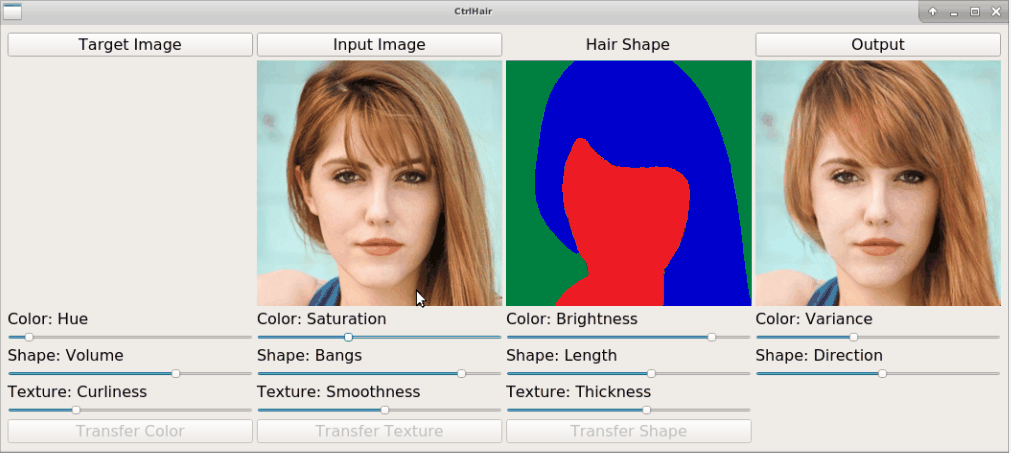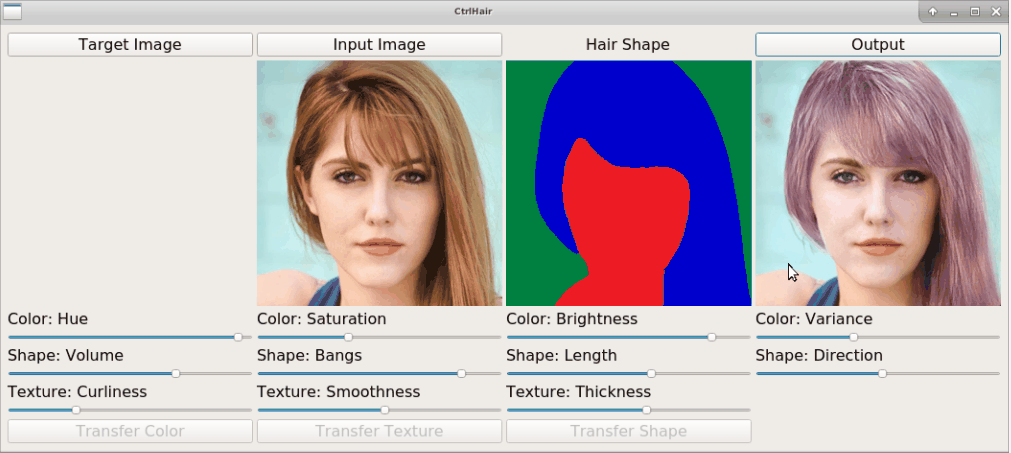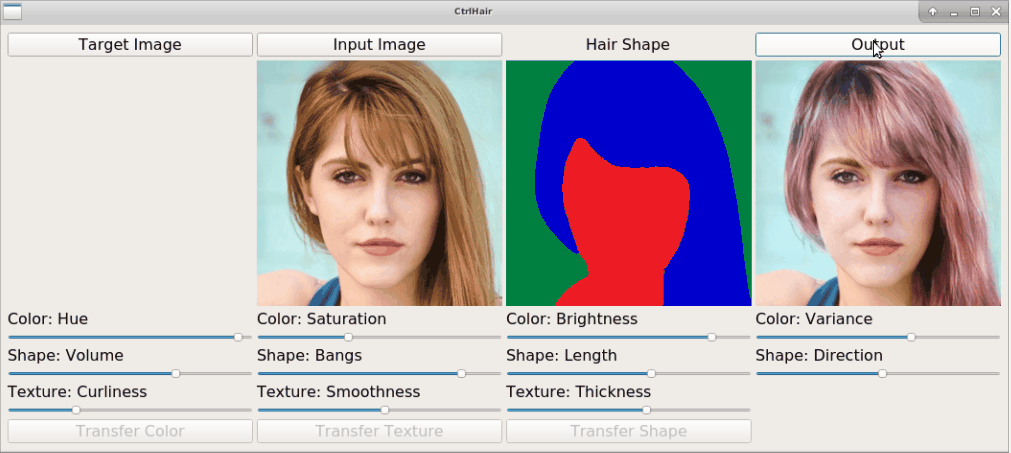
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
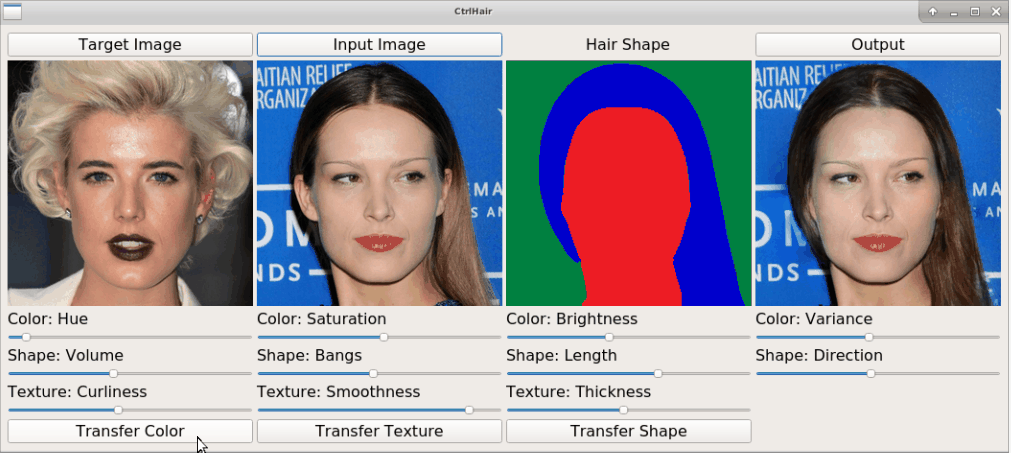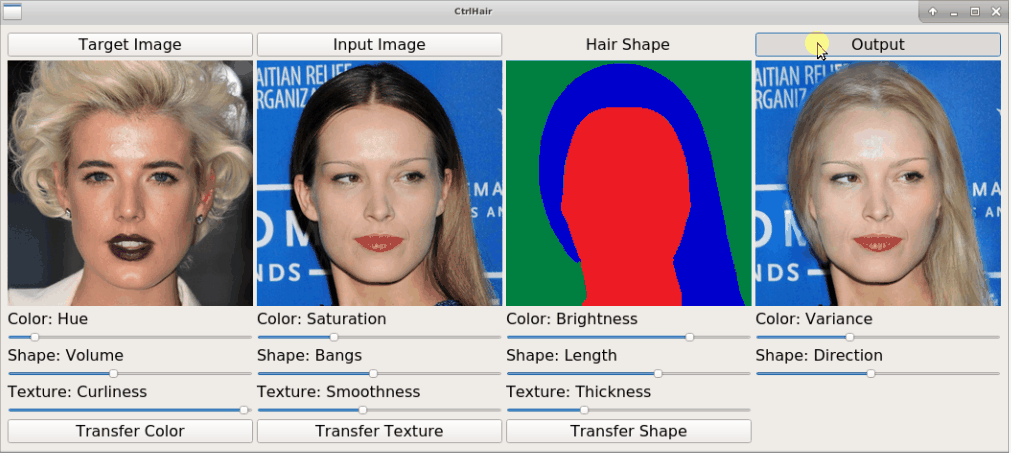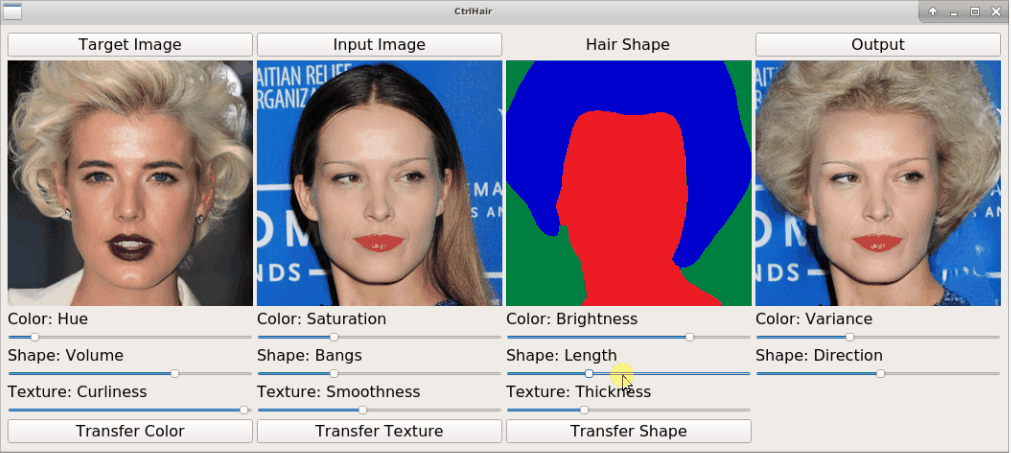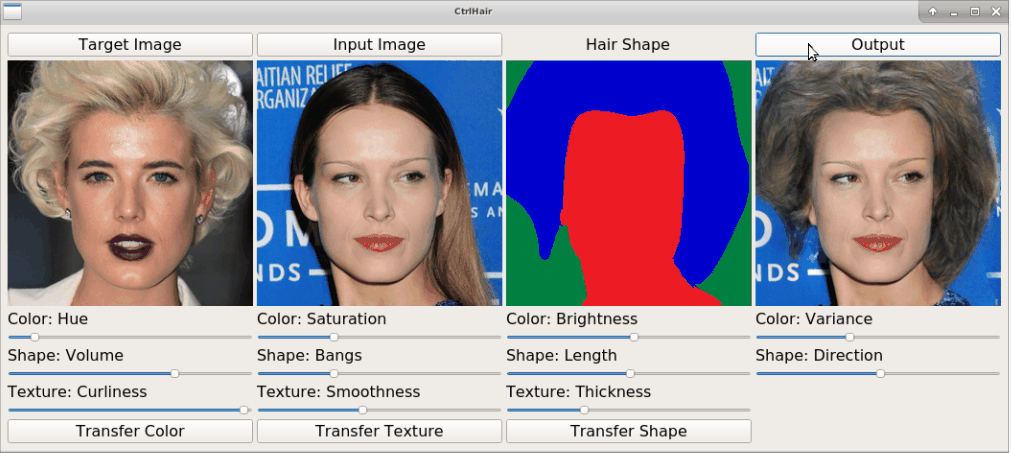
|
| 10 |
+
|
| 11 |
+
## Abstract
|
| 12 |
+
|
| 13 |
+
> Hair editing is an essential but challenging task in portrait editing considering the complex geometry and material of hair. Existing methods have achieved promising results by editing through a reference photo, user-painted mask, or guiding strokes. However, when a user provides no reference photo or hardly paints a desirable mask, these works fail to edit. Going a further step, we propose an efficiently controllable method that can provide a set of sliding bars to do continuous and fine hair editing. Meanwhile, it also naturally supports discrete editing through a reference photo and user-painted mask. Specifically, we propose a generative adversarial network with a multivariate Gaussian disentangling module. Firstly, an encoder disentangles the hair's major attributes, including color, texture, and shape, to separate latent representations. The latent representation of each attribute is modeled as a standard multivariate Gaussian distribution, to make each dimension of an attribute be changed continuously and finely. Benefiting from the Gaussian distribution, any manual editing including sliding a bar, providing a reference photo, and painting a mask can be easily made, which is flexible and friendly for users to interact with. Finally, with changed latent representations, the decoder outputs a portrait with the edited hair. Experiments show that our method can edit each attribute's dimension continuously and separately. Besides, when editing through reference images and painted masks like existing methods, our method achieves comparable results in terms of FID and visualization. Codes can be found at [https://github.com/XuyangGuo/CtrlHair](https://github.com/XuyangGuo/CtrlHair).
|
| 14 |
+
|
| 15 |
+
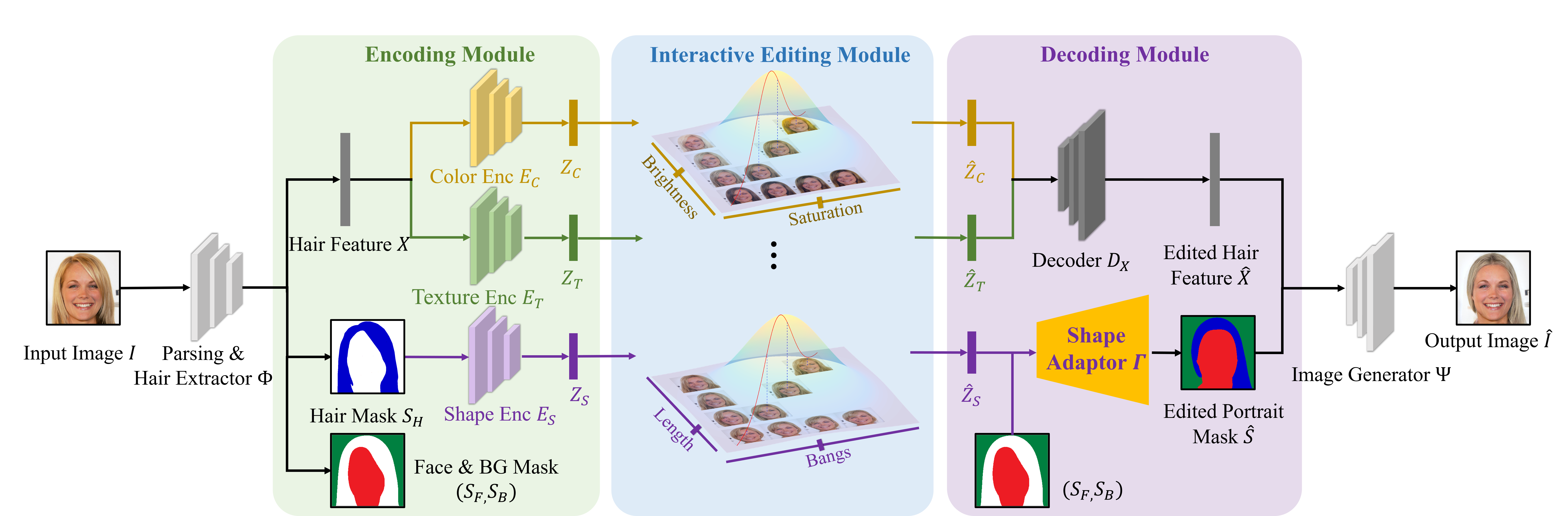
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Installation
|
| 19 |
+
|
| 20 |
+
Clone this repo.
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
git clone https://github.com/XuyangGuo/CtrlHair.git
|
| 24 |
+
cd CtrlHair
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
The code requires python 3.6.
|
| 28 |
+
|
| 29 |
+
We recommend using Anaconda to regulate packages.
|
| 30 |
+
|
| 31 |
+
Dependencies:
|
| 32 |
+
- PyTorch 1.8.2
|
| 33 |
+
- torchvision, tensorboardX, dlib
|
| 34 |
+
- pillow, pandas, scikit-learn, opencv-python
|
| 35 |
+
- PyQt5, tqdm, addict, dill
|
| 36 |
+
|
| 37 |
+
Please download all [external trained models](https://drive.google.com/drive/folders/1X0y82o7-JB6nGYIWdbbJa4MTFbtV9bei?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1vnldtoT9G-5gfvUjjUSVOA?pwd=1234) with password `1234` alternatively), move it to `./` with the correct path `CtrlHair/external_model_params`. (The directory contains the model parameters of face analysis tools required by our project, including SEAN for face encoding and generator with masks, BiSeNet for face parsing, and 68/81 facial landmark detector.)
|
| 38 |
+
|
| 39 |
+
## Editing by Pretrained Model
|
| 40 |
+
|
| 41 |
+
Firstly, refer to the "Installation" section above.
|
| 42 |
+
|
| 43 |
+
Please download [the pre-trained model of CtrlHair](https://drive.google.com/drive/folders/1opQhmc7ckS3J8qdLii_EMqmxYCcBLznO?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1O_Hu5dnk4GwmUrIBDWpwFA?pwd=1234) with password `1234` alternatively), move it to `./` with the correct path `CtrlHair/model_trained`.
|
| 44 |
+
|
| 45 |
+
#### Editing with UI directly (recommended)
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
python ui/frontend_demo.py
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
Here are some parameters of it:
|
| 52 |
+
|
| 53 |
+
- `-g D` Use the gpu `D`. (default is `0`)
|
| 54 |
+
- `-n True|False` Whether the input image need crop. (default is `True`)
|
| 55 |
+
- `--no_blending` Do not use poisson blending as post processing. If not blend, the result image will look slightly different from the input image in some details in non-hair region, but the image quality will be better.
|
| 56 |
+
|
| 57 |
+
The edited results can be found in `temp_folder/demo_output/out_img.png`, and the edited shape is in `temp_folder/demo_output/input_parsing.png`. The `temp_folder` is created automaticly during running, which could be removed after closing the procedure.
|
| 58 |
+
|
| 59 |
+
#### Editing with Batch
|
| 60 |
+
|
| 61 |
+
If you want to edit with a mass batch, or want to achieve editing functions such as interpolation, multi style sampling, and continuous gradient, etc, please use the interfaces of `ui/backend.py/Backend` and code your own python script.`Backend` class is the convenient encapsulation of basic functions of CtrlHair, and there are detailed comments for each function. The `main` scetion in the final of `backend.py` shows an simle example of usage of `Backend`.
|
| 62 |
+
|
| 63 |
+
## Training New Models
|
| 64 |
+
|
| 65 |
+
#### Data Preparation
|
| 66 |
+
In addition to the images in the dataset, training also involves many image annotations, including face parsing, facial landmarks, sean codes, color annotations, face rotation angle, a small amount of annotations (Curliness of Hair), etc.
|
| 67 |
+
|
| 68 |
+
Please download [the dataset information](https://drive.google.com/drive/folders/10p87Mobgueg9rdHyLPkX8xqEIvga6p2C?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1D3D2JqxIR6miCeMNssucKw?pwd=1234) with password `1234` alternatively) that we have partially processed, move it to `./` with the correct path `CtrlHair/dataset_info_ctrlhair`.
|
| 69 |
+
|
| 70 |
+
Then execute the following scripts sequentially for preprocessing.
|
| 71 |
+
|
| 72 |
+
Get facial segmentation mask
|
| 73 |
+
```bash
|
| 74 |
+
python dataset_scripts/script_get_mask.py
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
Get 68 facial landmarks and 81 facial landmarks
|
| 78 |
+
```bash
|
| 79 |
+
python dataset_scripts/script_landmark_detection.py
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
Get SEAN feature codes of the dataset
|
| 83 |
+
```bash
|
| 84 |
+
python dataset_scripts/script_get_sean_code.py
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
Get color label of the dataset
|
| 88 |
+
```bash
|
| 89 |
+
python dataset_scripts/script_get_rgb_hsv_label.py
|
| 90 |
+
python dataset_scripts/script_color_var_label.py
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
After complete processing, for training, the correct directory structure in `CtrlHair/dataset_info_ctrlhair` is as follows:
|
| 94 |
+
|
| 95 |
+
- `CelebaMask_HQ` / `ffhq` (if you want to add your own dataset, please regulate them as these two cases)
|
| 96 |
+
- `images_256` -> cropped images with the resolution 256.
|
| 97 |
+
- `label` -> mask label (0, 1, 2, ..., 20) for each pixel
|
| 98 |
+
- `angle.csv` restore face rotation angle of each image
|
| 99 |
+
- `attr_gender.csv` restore gender of each image
|
| 100 |
+
- `color_var_stat_dict.pkl`, `rgb_stat_dict.pkl`, `hsv_stat_dict_ordered.pkl` store the label of variance, rgb of hair color, and the hsv distribution
|
| 101 |
+
- `sean_code_dict.pkl` store the sean feature code of images in dataset
|
| 102 |
+
- `landmark68.pkl`, `landmark81.pkl` store the facial landmarks of the dataset
|
| 103 |
+
- `manual_label`
|
| 104 |
+
- `curliness`
|
| 105 |
+
- `-1.txt`, `1.txt`, `test_1.txt`, `test_-1.txt` labeled data list
|
| 106 |
+
|
| 107 |
+
#### Training Networks
|
| 108 |
+
In order to better control the parameters in the model, we train the entire model separately and divide it into four parts, including curliness classifier, color encoder, color & texture branch, shape branch.
|
| 109 |
+
|
| 110 |
+
**1. Train the curliness classifier**
|
| 111 |
+
```bash
|
| 112 |
+
python color_texture_branch/predictor/predictor_train.py -c p002 -g 0
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Here are some parameters of it:
|
| 116 |
+
|
| 117 |
+
- `-g D` Use the gpu `D`. (default is `0`)
|
| 118 |
+
- `-c pxxx` Using the model hyper-parameters config named `pxxx`. Please see the config detail in `color_texture_branch/predictor/predictor_config.py`
|
| 119 |
+
|
| 120 |
+
The trained model and its tensorboard summary are saved in `model_trained/curliness_classifier`.
|
| 121 |
+
|
| 122 |
+
**2. Train the color encoder**
|
| 123 |
+
```bash
|
| 124 |
+
python color_texture_branch/predictor/predictor_train.py -c p004 -g 0
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
The parameters are similar like the curliness classifier.
|
| 128 |
+
|
| 129 |
+
The trained model and its tensorboard summary are saved in `model_trained/color_encoder`.
|
| 130 |
+
|
| 131 |
+
**3. Train the color & texture branch**
|
| 132 |
+
```bash
|
| 133 |
+
python color_texture_branch/scripts.py -c 045 -g 0
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
This part depends on the curliness classifier and the color encoder as seen in `color_texture_branch/config.py`:
|
| 137 |
+
|
| 138 |
+
```python
|
| 139 |
+
...
|
| 140 |
+
'predictor': {'curliness': 'p002', 'rgb': 'p004'},
|
| 141 |
+
...
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
Here are some parameters of it:
|
| 145 |
+
|
| 146 |
+
- `-g D` Use the gpu `D`. (default is `0`)
|
| 147 |
+
- `-c xxx` Using the model hyper-parameters config named `xxx`. Please see the config detail in `color_texture_branch/config.py`
|
| 148 |
+
|
| 149 |
+
The trained model, its tensorboard, editing results in training are saved in `model_trained/color_texture`.
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
Since the training of texture is unsupervised, we need to find some semantic orthogonal directions after training for sliding bars. Please run:
|
| 153 |
+
```bash
|
| 154 |
+
python color_texture_branch/script_find_direction.py -c xxx
|
| 155 |
+
```
|
| 156 |
+
The parameter `-c xxx` is same as above shape config.
|
| 157 |
+
This process will generate a folder named `direction_find` in the directory `model_trained/color_texture/yourConfigName`,
|
| 158 |
+
where `direction_find/texture_dir_n` stores many random `n`-th directions to be selected,
|
| 159 |
+
and the corresponding visual changes can be seen in `direction_find/texture_n`.
|
| 160 |
+
When the choice is decided, move the corresponding `texture_dir_n/xxx.pkl` file to `../texture_dir_used` and rename it as you wish (the pretrained No.045 texture model shows an example).
|
| 161 |
+
Afterthat, run `python color_texture_branch/script_find_direction.py -c xxx` again, and repeat the process until the amount of semantic directions is enough.
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
**4. Train the shape branch**
|
| 165 |
+
|
| 166 |
+
Shape editing employs a transfer-like training process. Before transferring, we use 68 feature points to pre-align the face of the target hairstyle, so as to achieve a certain degree of face adaptation. In order to speed up this process during training, it is necessary to generate some buffer pools to store the pre-aligned masks of the training set and test set respectively.
|
| 167 |
+
|
| 168 |
+
Generate buffer pool for testing
|
| 169 |
+
```bash
|
| 170 |
+
python shape_branch/script_adaptor_test_pool.py
|
| 171 |
+
```
|
| 172 |
+
The testing buffer pool will be saved in `dataset_info_ctrlhair/shape_testing_wrap_pool`.
|
| 173 |
+
|
| 174 |
+
Generate buffer pool for training
|
| 175 |
+
```bash
|
| 176 |
+
python shape_branch/script_adaptor_train_pool.py
|
| 177 |
+
```
|
| 178 |
+
The training buffer pool will be saved in `dataset_info_ctrlhair/shape_training_wrap_pool`.
|
| 179 |
+
|
| 180 |
+
Note that the `script_adaptor_train_pool.py` process will execute for a very very long time until the setting of maximum number of files for buffering is reached.
|
| 181 |
+
This process can be performed concurrently with the subsequent shape training process.
|
| 182 |
+
The training data for shape training are all dynamically picked from this buffer pool.
|
| 183 |
+
|
| 184 |
+
Training the shape branch model
|
| 185 |
+
```bash
|
| 186 |
+
python shape_branch/scripts.py -c 054 -g 0
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
Here are some parameters of it:
|
| 190 |
+
|
| 191 |
+
- `-g D` Use the gpu `D`. (default is `0`)
|
| 192 |
+
- `-c xxx` Using the model hyper-parameters config named `xxx`. Please see the config detail in `shape_branch/config.py`
|
| 193 |
+
|
| 194 |
+
The trained model, its tensorboard, editing results in training are saved in `model_trained/shape`.
|
| 195 |
+
|
| 196 |
+
Since the training is unsupervised, we need to find some semantic orthogonal directions after training for sliding bars. Please run:
|
| 197 |
+
```bash
|
| 198 |
+
python shape_branch/script_find_direction.py -c xxx
|
| 199 |
+
```
|
| 200 |
+
The parameter `-c xxx` is same as above shape config.
|
| 201 |
+
The entire usage method is similar to texture, but the folder is changed to the `model_trained/shape` directory (the pretrained No.054 shape model shows an example).
|
| 202 |
+
|
| 203 |
+
After all the above training, use `python ui/frontend_demo.py` to edit.
|
| 204 |
+
You can also use interfaces in `ui/backend.py/Backend` to program your editing scripts.
|
| 205 |
+
|
| 206 |
+
## Training New Models with Your Own Images Dataset
|
| 207 |
+
|
| 208 |
+
Our method only needs unlabeled face images to augment the dataset, which is convenient and is a strength of CtrlHair.
|
| 209 |
+
|
| 210 |
+
#### Data Preparation
|
| 211 |
+
|
| 212 |
+
For your own images dataset, firstly, crop and resize them. Please collect them into a single directory, and modify `root_dir` and `dataset_name` for your dataset in `dataset_scripts/script_crop.py`. Then execute
|
| 213 |
+
```bash
|
| 214 |
+
python dataset_scripts/script_crop.py
|
| 215 |
+
```
|
| 216 |
+
After cropping, the dataset should be cropped at `dataset_info_ctrlhair/your_dataset_name/images_256`. Your dataset should have similar structure like `dataset_info_ctrlhair/ffhq`.
|
| 217 |
+
|
| 218 |
+
Modify `DATASET_NAME` in `global_value_utils.py ` for your dataset.
|
| 219 |
+
|
| 220 |
+
Do the same steps as the section "Data Preparation" of "Training New Models" in this README.
|
| 221 |
+
|
| 222 |
+
Predict face rotation angle and gender for your dataset.
|
| 223 |
+
This will be used to filter the dataset.
|
| 224 |
+
You can use tools like [3DDFA](https://github.com/cleardusk/3DDFA) and [deepface](https://github.com/serengil/deepface), then output them to `angle.csv` and `attr_gender.csv` in `dataset_info_ctrlhair/yourdataset` (pandas is recommended for generating csv). `dataset_info_ctrlhair/ffhq` shows a preprocessing example.
|
| 225 |
+
Sorry for that we don't provide these code. Alternatively, if you don't want to depend and use these filter, please modify `angle_filter` and `gender_filter` to `False` in `common_dataset.py`.
|
| 226 |
+
|
| 227 |
+
#### Training Networks
|
| 228 |
+
|
| 229 |
+
Add and adjust your config in `color_texture_branch/predictor/predictor_config.py`, `color_texture_branch/config.py`, `shape/config.py`.
|
| 230 |
+
|
| 231 |
+
Do the same steps as the section "Training Networks" of "Training New Models" in this README, but with your config.
|
| 232 |
+
|
| 233 |
+
Finally, change the `DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH` and `DEFAULT_CONFIG_SHAPE_BRANCH` as yours in `global_value_utils.py`.
|
| 234 |
+
Use `python ui/frontend_demo.py` to edit. Or you can also use interfaces in `ui/backend.py/Backend` to program your editing scripts.
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
## Code Structure
|
| 238 |
+
- `color_texture_branch`: color and texture editing branch
|
| 239 |
+
- `predictor`: color encoder and curliness classifier
|
| 240 |
+
- `shape_branch`: shape editing branch
|
| 241 |
+
- `ui`: encapsulated backend interfaces and frontend UI
|
| 242 |
+
- `dataset_scripts`: scripts for preprocessing dataset
|
| 243 |
+
- `external_code`: codes of external tools
|
| 244 |
+
- `sean_codes`: modified from SEAN project, which is used for image feature extraction and generation
|
| 245 |
+
- `my_pylib`, `my_torchlib`, `utils`: auxiliary code library
|
| 246 |
+
- `wrap_codes`: used for shape align before shape transfer
|
| 247 |
+
- `dataset_info_ctrlhair`: the root directory of dataset
|
| 248 |
+
- `model_trained`: trained model parameters, tensorboard and visual results during training
|
| 249 |
+
- `external_model_params`: pretrained model parameters used for external codes
|
| 250 |
+
- `imgs`: some example images are provided for testing
|
| 251 |
+
|
| 252 |
+
## Citation
|
| 253 |
+
If you use this code for your research, please cite our papers.
|
| 254 |
+
```
|
| 255 |
+
@inproceedings{guo2022gan,
|
| 256 |
+
title={GAN with Multivariate Disentangling for Controllable Hair Editing},
|
| 257 |
+
author={Guo, Xuyang and Kan, Meina and Chen, Tianle and Shan, Shiguang},
|
| 258 |
+
booktitle={European Conference on Computer Vision},
|
| 259 |
+
year={2022},
|
| 260 |
+
pages={655--670},
|
| 261 |
+
organization={Springer}
|
| 262 |
+
}
|
| 263 |
+
```
|
| 264 |
+
|
| 265 |
+
This work is also inspired by our previous work [X. Guo, et al., STD-GAN (CVIU2021)](https://github.com/XuyangGuo/STD-GAN) for instance-level facial attributes editing.
|
| 266 |
+
|
| 267 |
+
## References & Acknowledgments
|
| 268 |
+
- [ZPdesu / SEAN](https://github.com/ZPdesu/SEAN)
|
| 269 |
+
- [zhhoper / RI_render_DPR](https://github.com/zhhoper/RI_render_DPR)
|
| 270 |
+
- [zllrunning / face-parsing.PyTorch](https://github.com/zllrunning/face-parsing.PyTorch)
|
models/CtrlHair/color_texture_branch/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: __init__.py.py
|
| 5 |
+
# Time : 2021/11/15 11:18
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
models/CtrlHair/color_texture_branch/config.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: config.py
|
| 5 |
+
# Time : 2021/11/17 13:10
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import addict # nesting dict
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
|
| 14 |
+
from global_value_utils import GLOBAL_DATA_ROOT, DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH
|
| 15 |
+
|
| 16 |
+
configs = [
|
| 17 |
+
addict.Dict({
|
| 18 |
+
"experiment_name": "045__color_texture_final",
|
| 19 |
+
'lambda_rgb': 0.01,
|
| 20 |
+
'lambda_pca_std': 0.01,
|
| 21 |
+
'noise_dim': 8,
|
| 22 |
+
'filter_female_and_frontal': True,
|
| 23 |
+
'g_hidden_layer_num': 4,
|
| 24 |
+
'd_hidden_layer_num': 4,
|
| 25 |
+
'lambda_moment_1': 0.01,
|
| 26 |
+
'lambda_moment_2': 0.01,
|
| 27 |
+
'lambda_cls_curliness': {0: 0.1},
|
| 28 |
+
'lambda_info_curliness': 1.0,
|
| 29 |
+
'lambda_info': 1.0,
|
| 30 |
+
'curliness_dim': 1,
|
| 31 |
+
'predictor': {'curliness': 'p002', 'rgb': 'p004'},
|
| 32 |
+
'gan_input_from_encoder_prob': 0.3,
|
| 33 |
+
'curliness_with_weight': True,
|
| 34 |
+
'lambda_rec': 1000.0,
|
| 35 |
+
'lambda_rec_img': {0: 0, 600000: 1000},
|
| 36 |
+
'gen_mode': 'eigengan',
|
| 37 |
+
'lambda_orthogonal': 0.1,
|
| 38 |
+
}),
|
| 39 |
+
]
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def get_config(configs, config_id):
|
| 43 |
+
for c in configs:
|
| 44 |
+
if c.experiment_name.startswith(config_id):
|
| 45 |
+
check_add_default_value_to_base_cfg(c)
|
| 46 |
+
return c
|
| 47 |
+
cfg = addict.Dict({})
|
| 48 |
+
check_add_default_value_to_base_cfg(cfg)
|
| 49 |
+
return cfg
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def check_add_default_value_to_base_cfg(cfg):
|
| 53 |
+
add_default_value_to_cfg(cfg, 'lr_d', 0.0002)
|
| 54 |
+
add_default_value_to_cfg(cfg, 'lr_g', 0.0002)
|
| 55 |
+
add_default_value_to_cfg(cfg, 'beta1', 0.5)
|
| 56 |
+
add_default_value_to_cfg(cfg, 'beta2', 0.999)
|
| 57 |
+
|
| 58 |
+
add_default_value_to_cfg(cfg, 'total_step', 650100)
|
| 59 |
+
add_default_value_to_cfg(cfg, 'log_step', 10)
|
| 60 |
+
add_default_value_to_cfg(cfg, 'sample_step', 25000)
|
| 61 |
+
add_default_value_to_cfg(cfg, 'model_save_step', 20000)
|
| 62 |
+
add_default_value_to_cfg(cfg, 'sample_batch_size', 32)
|
| 63 |
+
add_default_value_to_cfg(cfg, 'max_save', 2)
|
| 64 |
+
add_default_value_to_cfg(cfg, 'vae_var_output', 'var')
|
| 65 |
+
add_default_value_to_cfg(cfg, 'SEAN_code', 512)
|
| 66 |
+
|
| 67 |
+
# Model configuration
|
| 68 |
+
add_default_value_to_cfg(cfg, 'total_batch_size', 128)
|
| 69 |
+
add_default_value_to_cfg(cfg, 'g_hidden_layer_num', 4)
|
| 70 |
+
add_default_value_to_cfg(cfg, 'd_hidden_layer_num', 4)
|
| 71 |
+
add_default_value_to_cfg(cfg, 'd_noise_hidden_layer_num', 3)
|
| 72 |
+
add_default_value_to_cfg(cfg, 'g_hidden_dim', 256)
|
| 73 |
+
add_default_value_to_cfg(cfg, 'd_hidden_dim', 256)
|
| 74 |
+
add_default_value_to_cfg(cfg, 'gan_type', 'wgan_gp')
|
| 75 |
+
add_default_value_to_cfg(cfg, 'lambda_gp', 10.0)
|
| 76 |
+
add_default_value_to_cfg(cfg, 'lambda_adv', 1.0)
|
| 77 |
+
|
| 78 |
+
add_default_value_to_cfg(cfg, 'noise_dim', 8)
|
| 79 |
+
add_default_value_to_cfg(cfg, 'g_norm', 'none')
|
| 80 |
+
add_default_value_to_cfg(cfg, 'd_norm', 'none')
|
| 81 |
+
add_default_value_to_cfg(cfg, 'g_activ', 'relu')
|
| 82 |
+
add_default_value_to_cfg(cfg, 'd_activ', 'lrelu')
|
| 83 |
+
add_default_value_to_cfg(cfg, 'init_type', 'normal')
|
| 84 |
+
add_default_value_to_cfg(cfg, 'G_D_train_num', {'G': 1, 'D': 1}, )
|
| 85 |
+
|
| 86 |
+
output_root_dir = 'model_trained/color_texture/%s' % cfg['experiment_name']
|
| 87 |
+
add_default_value_to_cfg(cfg, 'root_dir', output_root_dir)
|
| 88 |
+
add_default_value_to_cfg(cfg, 'log_dir', output_root_dir + '/logs')
|
| 89 |
+
add_default_value_to_cfg(cfg, 'model_save_dir', output_root_dir + '/models')
|
| 90 |
+
add_default_value_to_cfg(cfg, 'sample_dir', output_root_dir + '/samples')
|
| 91 |
+
try:
|
| 92 |
+
add_default_value_to_cfg(cfg, 'gpu_num', len(args.gpu.split(',')))
|
| 93 |
+
except:
|
| 94 |
+
add_default_value_to_cfg(cfg, 'gpu_num', 1)
|
| 95 |
+
|
| 96 |
+
add_default_value_to_cfg(cfg, 'data_root', GLOBAL_DATA_ROOT)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def add_default_value_to_cfg(cfg, key, value):
|
| 100 |
+
if key not in cfg:
|
| 101 |
+
cfg[key] = value
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def merge_config_in_place(ori_cfg, new_cfg):
|
| 105 |
+
for k in new_cfg:
|
| 106 |
+
ori_cfg[k] = new_cfg[k]
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def back_process(cfg):
|
| 110 |
+
cfg.batch_size = cfg.total_batch_size // cfg.gpu_num
|
| 111 |
+
if cfg.predictor:
|
| 112 |
+
from color_texture_branch.predictor import predictor_config
|
| 113 |
+
for ke in cfg.predictor:
|
| 114 |
+
pred_cfg = predictor_config.get_config(predictor_config.configs, cfg.predictor[ke])
|
| 115 |
+
predictor_config.back_process(pred_cfg)
|
| 116 |
+
cfg.predictor[ke] = pred_cfg
|
| 117 |
+
|
| 118 |
+
if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
|
| 119 |
+
cfg.subspace_dim = cfg.noise_dim // cfg.g_hidden_layer_num
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def get_basic_arg_parser():
|
| 123 |
+
parser = argparse.ArgumentParser()
|
| 124 |
+
parser.add_argument('-c', '--config', type=str, help='Specify config number', default=DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH)
|
| 125 |
+
parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
|
| 126 |
+
parser.add_argument('--local_rank', type=int, default=-1)
|
| 127 |
+
return parser
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
import sys
|
| 131 |
+
|
| 132 |
+
if sys.argv[0].endswith('color_texture_branch/scripts.py'):
|
| 133 |
+
parser = get_basic_arg_parser()
|
| 134 |
+
args = parser.parse_args()
|
| 135 |
+
cfg = get_config(configs, args.config)
|
| 136 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
|
| 137 |
+
back_process(cfg)
|
| 138 |
+
else:
|
| 139 |
+
cfg = get_config(configs, DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH)
|
| 140 |
+
# cfg = get_config(configs, '046')
|
| 141 |
+
back_process(cfg)
|
models/CtrlHair/color_texture_branch/dataset.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: dataset.py
|
| 5 |
+
# Time : 2021/11/16 21:24
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
from common_dataset import DataFilter
|
| 12 |
+
|
| 13 |
+
import random
|
| 14 |
+
import numpy as np
|
| 15 |
+
from global_value_utils import HAIR_IDX, GLOBAL_DATA_ROOT
|
| 16 |
+
import pickle
|
| 17 |
+
import torch
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class Dataset:
|
| 21 |
+
"""A general image-attributes dataset class."""
|
| 22 |
+
|
| 23 |
+
def valid_hair(self, item):
|
| 24 |
+
if np.isnan(self.rgb_stat_dict[item][0]).any(): # not have hair
|
| 25 |
+
return False
|
| 26 |
+
if (self.sean_code_dict[item][HAIR_IDX] == 0).all():
|
| 27 |
+
return False
|
| 28 |
+
if item not in self.color_var_stat_dict:
|
| 29 |
+
return False
|
| 30 |
+
return True
|
| 31 |
+
|
| 32 |
+
def __init__(self, cfg, rank=0, test_part=0.096):
|
| 33 |
+
# super().__init__()
|
| 34 |
+
self.cfg = cfg
|
| 35 |
+
|
| 36 |
+
self.random_seed = 7 # Do not change the random seed, which determines the split of scripts and test set
|
| 37 |
+
self.hair_root = GLOBAL_DATA_ROOT
|
| 38 |
+
with open(os.path.join(self.hair_root, 'sean_code_dict.pkl'), 'rb') as f:
|
| 39 |
+
self.sean_code_dict = pickle.load(f)
|
| 40 |
+
with open(os.path.join(self.hair_root, 'rgb_stat_dict.pkl'), 'rb') as f:
|
| 41 |
+
self.rgb_stat_dict = pickle.load(f)
|
| 42 |
+
with open(os.path.join(self.hair_root, 'color_var_stat_dict.pkl'), 'rb') as f:
|
| 43 |
+
self.color_var_stat_dict = pickle.load(f)
|
| 44 |
+
|
| 45 |
+
self.local_rank = rank
|
| 46 |
+
random.seed(self.random_seed + self.local_rank + 1)
|
| 47 |
+
|
| 48 |
+
self.data_list = [dd for dd in list(self.sean_code_dict) if self.valid_hair(dd)]
|
| 49 |
+
random.shuffle(self.data_list)
|
| 50 |
+
|
| 51 |
+
self.data_filter = DataFilter(cfg, test_part)
|
| 52 |
+
|
| 53 |
+
self.test_list = []
|
| 54 |
+
for ll in self.data_filter.test_list:
|
| 55 |
+
path_part = ll.split('/')
|
| 56 |
+
self.test_list.append('%s___%s' % (path_part[-3], path_part[-1][:-4]))
|
| 57 |
+
|
| 58 |
+
self.train_filter = []
|
| 59 |
+
for ll in self.data_filter.train_list:
|
| 60 |
+
path_part = ll.split('/')
|
| 61 |
+
self.train_filter.append('%s___%s' % (path_part[-3], path_part[-1][:-4]))
|
| 62 |
+
self.train_filter = set(self.train_filter)
|
| 63 |
+
self.train_list = [ll for ll in self.data_list if ll not in self.test_list]
|
| 64 |
+
if cfg.filter_female_and_frontal:
|
| 65 |
+
self.train_list = [ll for ll in self.train_list if ll in self.train_filter]
|
| 66 |
+
self.train_set = set(self.train_list)
|
| 67 |
+
|
| 68 |
+
### curliness code
|
| 69 |
+
self.curliness_hair_list = {}
|
| 70 |
+
self.curliness_hair_list_test = {}
|
| 71 |
+
self.curliness_hair_dict = {ke: 0 for ke in self.color_var_stat_dict}
|
| 72 |
+
|
| 73 |
+
for label in [-1, 1]:
|
| 74 |
+
img_file = os.path.join(cfg.data_root, 'manual_label', 'curliness', '%d.txt' % label)
|
| 75 |
+
with open(img_file, 'r') as f:
|
| 76 |
+
imgs = [l.strip() for l in f.readlines()]
|
| 77 |
+
imgs = [ii for ii in imgs if ii in self.train_set]
|
| 78 |
+
self.curliness_hair_list[label] = imgs
|
| 79 |
+
for ii in imgs:
|
| 80 |
+
self.curliness_hair_dict[ii] = label
|
| 81 |
+
|
| 82 |
+
img_file = os.path.join(cfg.data_root, 'manual_label', 'curliness', 'test_%d.txt' % label)
|
| 83 |
+
with open(img_file, 'r') as f:
|
| 84 |
+
imgs = [l.strip() for l in f.readlines()]
|
| 85 |
+
self.curliness_hair_list_test[label] = imgs
|
| 86 |
+
for ii in imgs:
|
| 87 |
+
self.curliness_hair_dict[ii] = label
|
| 88 |
+
|
| 89 |
+
def get_sean_code(self, ke):
|
| 90 |
+
return self.sean_code_dict[ke]
|
| 91 |
+
|
| 92 |
+
def get_list_by_items(self, items):
|
| 93 |
+
res_code, res_rgb_mean, res_pca_std, res_sean_code, res_curliness = [], [], [], [], []
|
| 94 |
+
for item in items:
|
| 95 |
+
code = self.sean_code_dict[item][HAIR_IDX]
|
| 96 |
+
res_code.append(code)
|
| 97 |
+
rgb_mean = self.rgb_stat_dict[item][0]
|
| 98 |
+
res_rgb_mean.append(rgb_mean)
|
| 99 |
+
pca_std = self.color_var_stat_dict[item]['var_pca']
|
| 100 |
+
# here the 'var' is 'std'
|
| 101 |
+
res_pca_std.append(pca_std[..., None])
|
| 102 |
+
res_sean_code.append(self.get_sean_code(ke=item))
|
| 103 |
+
res_curliness.append(self.curliness_hair_dict[item])
|
| 104 |
+
res_code = torch.tensor(np.stack(res_code), dtype=torch.float32)
|
| 105 |
+
res_rgb_mean = torch.tensor(np.stack(res_rgb_mean), dtype=torch.float32)
|
| 106 |
+
res_pca_std = torch.tensor(np.stack(res_pca_std), dtype=torch.float32)
|
| 107 |
+
res_curliness = torch.tensor(np.stack(res_curliness), dtype=torch.int)[..., None]
|
| 108 |
+
data = {'code': res_code, 'rgb_mean': res_rgb_mean, 'pca_std': res_pca_std, 'items': items,
|
| 109 |
+
'sean_code': res_sean_code, 'curliness_label': res_curliness}
|
| 110 |
+
return data
|
| 111 |
+
|
| 112 |
+
def get_training_batch(self, batch_size):
|
| 113 |
+
items = []
|
| 114 |
+
while len(items) < batch_size:
|
| 115 |
+
item = random.choice(self.train_list)
|
| 116 |
+
# if not self.valid_hair(item):
|
| 117 |
+
# continue
|
| 118 |
+
items.append(item)
|
| 119 |
+
data = self.get_list_by_items(items)
|
| 120 |
+
return data
|
| 121 |
+
|
| 122 |
+
def get_testing_batch(self, batch_size):
|
| 123 |
+
ptr = 0
|
| 124 |
+
items = []
|
| 125 |
+
while len(items) < batch_size:
|
| 126 |
+
item = self.test_list[ptr]
|
| 127 |
+
ptr += 1
|
| 128 |
+
if not self.valid_hair(item):
|
| 129 |
+
continue
|
| 130 |
+
items.append(item)
|
| 131 |
+
data = self.get_list_by_items(items)
|
| 132 |
+
return data
|
| 133 |
+
|
| 134 |
+
def get_curliness_hair(self, labels):
|
| 135 |
+
labels = labels.cpu().numpy()
|
| 136 |
+
items = []
|
| 137 |
+
for label in labels:
|
| 138 |
+
item_list = self.curliness_hair_list[label[0]]
|
| 139 |
+
items.append(np.random.choice(item_list))
|
| 140 |
+
data = self.get_list_by_items(items)
|
| 141 |
+
return data
|
| 142 |
+
|
| 143 |
+
def get_curliness_hair_test(self):
|
| 144 |
+
return self.get_list_by_items(self.curliness_hair_list_test[-1] + self.curliness_hair_list_test[1])
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
# if __name__ == '__main__':
|
| 148 |
+
# ds = Dataset(cfg)
|
| 149 |
+
# resources = ds.get_training_batch(8)
|
| 150 |
+
# pass
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
# for label in [-1, 1]:
|
| 154 |
+
# img_dir = os.path.join(cfg.data_root, 'manual_label', 'curliness', 'test_%d' % label)
|
| 155 |
+
# imgs = [pat[:-4] + '\n' for pat in os.listdir(img_dir)]
|
| 156 |
+
# imgs.sort()
|
| 157 |
+
# with open(img_dir + '.txt', 'w') as f:
|
| 158 |
+
# f.writelines(imgs)
|
models/CtrlHair/color_texture_branch/model.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: model.py
|
| 5 |
+
# Time : 2021/11/17 15:37
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
from my_torchlib.module import LinearBlock
|
| 12 |
+
import torch
|
| 13 |
+
from torch.nn import init
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def init_weights(net, init_type='normal', init_gain=0.02):
|
| 17 |
+
"""Initialize network weights.
|
| 18 |
+
|
| 19 |
+
Parameters:
|
| 20 |
+
net (network) -- network to be initialized
|
| 21 |
+
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
|
| 22 |
+
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
|
| 23 |
+
|
| 24 |
+
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
|
| 25 |
+
work better for some applications. Feel free to try yourself.
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
def init_func(m): # define the initialization function
|
| 29 |
+
classname = m.__class__.__name__
|
| 30 |
+
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
|
| 31 |
+
if init_type == 'normal':
|
| 32 |
+
init.normal_(m.weight.data, 0.0, init_gain)
|
| 33 |
+
elif init_type == 'xavier':
|
| 34 |
+
init.xavier_normal_(m.weight.data, gain=init_gain)
|
| 35 |
+
elif init_type == 'kaiming':
|
| 36 |
+
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
| 37 |
+
elif init_type == 'orthogonal':
|
| 38 |
+
init.orthogonal_(m.weight.data, gain=init_gain)
|
| 39 |
+
else:
|
| 40 |
+
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
|
| 41 |
+
if hasattr(m, 'bias') and m.bias is not None:
|
| 42 |
+
init.constant_(m.bias.data, 0.0)
|
| 43 |
+
elif classname.find(
|
| 44 |
+
'BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
|
| 45 |
+
init.normal_(m.weight.data, 1.0, init_gain)
|
| 46 |
+
init.constant_(m.bias.data, 0.0)
|
| 47 |
+
|
| 48 |
+
print('initialize network with %s' % init_type)
|
| 49 |
+
net.apply(init_func) # apply the initialization function <init_func>
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class Generator(nn.Module):
|
| 53 |
+
"""Generator network."""
|
| 54 |
+
|
| 55 |
+
def __init__(self, cfg):
|
| 56 |
+
super(Generator, self).__init__()
|
| 57 |
+
self.cfg = cfg
|
| 58 |
+
|
| 59 |
+
input_dim = cfg.noise_dim
|
| 60 |
+
if cfg.lambda_rgb:
|
| 61 |
+
input_dim += 3
|
| 62 |
+
if cfg.lambda_pca_std:
|
| 63 |
+
input_dim += 1
|
| 64 |
+
if cfg.lambda_cls_curliness:
|
| 65 |
+
input_dim += cfg.curliness_dim
|
| 66 |
+
|
| 67 |
+
layers = [LinearBlock(input_dim, cfg.g_hidden_dim, cfg.g_norm, activation=cfg.g_activ)]
|
| 68 |
+
for _ in range(cfg.g_hidden_layer_num - 1):
|
| 69 |
+
layers.append(LinearBlock(cfg.g_hidden_dim, cfg.g_hidden_dim, cfg.g_norm, activation=cfg.g_activ))
|
| 70 |
+
layers.append(LinearBlock(cfg.g_hidden_dim, cfg.SEAN_code, 'none', 'none'))
|
| 71 |
+
self.net = nn.Sequential(*layers)
|
| 72 |
+
|
| 73 |
+
def forward(self, data):
|
| 74 |
+
x = data['noise']
|
| 75 |
+
if self.cfg.lambda_cls_curliness:
|
| 76 |
+
x = torch.cat([x, data['noise_curliness']], dim=1)
|
| 77 |
+
if self.cfg.lambda_rgb:
|
| 78 |
+
x = torch.cat([x, data['rgb_mean']], dim=1)
|
| 79 |
+
if self.cfg.lambda_pca_std:
|
| 80 |
+
x = torch.cat([x, data['pca_std']], dim=1)
|
| 81 |
+
output = self.net(x)
|
| 82 |
+
res = {'code': output}
|
| 83 |
+
return res
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class Discriminator(nn.Module):
|
| 87 |
+
"""Discriminator network."""
|
| 88 |
+
|
| 89 |
+
def __init__(self, cfg):
|
| 90 |
+
super(Discriminator, self).__init__()
|
| 91 |
+
self.cfg = cfg
|
| 92 |
+
layers = [LinearBlock(cfg.SEAN_code, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ)]
|
| 93 |
+
for _ in range(cfg.d_hidden_layer_num - 1):
|
| 94 |
+
layers.append(LinearBlock(cfg.d_hidden_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ))
|
| 95 |
+
output_dim = 1 + cfg.noise_dim
|
| 96 |
+
if cfg.lambda_rgb and 'curliness' not in cfg.predictor:
|
| 97 |
+
output_dim += 3
|
| 98 |
+
if cfg.lambda_pca_std:
|
| 99 |
+
output_dim += 1
|
| 100 |
+
if cfg.lambda_cls_curliness:
|
| 101 |
+
output_dim += cfg.curliness_dim
|
| 102 |
+
if 'curliness' not in cfg.predictor:
|
| 103 |
+
output_dim += 1
|
| 104 |
+
layers.append(LinearBlock(cfg.d_hidden_dim, output_dim, 'none', 'none'))
|
| 105 |
+
self.net = nn.Sequential(*layers)
|
| 106 |
+
self.input_name = 'code'
|
| 107 |
+
|
| 108 |
+
def forward(self, data_in):
|
| 109 |
+
x = data_in[self.input_name]
|
| 110 |
+
out = self.net(x)
|
| 111 |
+
data = {'adv': out[:, [0]]}
|
| 112 |
+
ptr = 1
|
| 113 |
+
data['noise'] = out[:, ptr:(ptr + self.cfg.noise_dim)]
|
| 114 |
+
ptr += self.cfg.noise_dim
|
| 115 |
+
if self.cfg.lambda_cls_curliness:
|
| 116 |
+
data['noise_curliness'] = out[:, ptr:(ptr + self.cfg.curliness_dim)]
|
| 117 |
+
ptr += self.cfg.curliness_dim
|
| 118 |
+
if not 'curliness' in self.cfg.predictor:
|
| 119 |
+
data['cls_curliness'] = out[:, ptr: ptr + 1]
|
| 120 |
+
ptr += 1
|
| 121 |
+
if self.cfg.lambda_rgb and 'rgb' not in self.cfg.predictor:
|
| 122 |
+
data['rgb_mean'] = out[:, ptr:ptr + 3]
|
| 123 |
+
ptr += 3
|
| 124 |
+
if self.cfg.lambda_pca_std and 'rgb' not in self.cfg.predictor:
|
| 125 |
+
data['pca_std'] = out[:, ptr:]
|
| 126 |
+
ptr += 1
|
| 127 |
+
return data
|
| 128 |
+
|
| 129 |
+
def forward_adv_direct(self, x):
|
| 130 |
+
return self.net(x)[:, [0]]
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class DiscriminatorNoise(nn.Module):
|
| 134 |
+
"""Discriminator network."""
|
| 135 |
+
|
| 136 |
+
def __init__(self, cfg):
|
| 137 |
+
super(DiscriminatorNoise, self).__init__()
|
| 138 |
+
self.cfg = cfg
|
| 139 |
+
input_dim = cfg.noise_dim
|
| 140 |
+
if cfg.lambda_cls_curliness:
|
| 141 |
+
input_dim += cfg.curliness_dim
|
| 142 |
+
layers = [LinearBlock(input_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ)]
|
| 143 |
+
for _ in range(cfg.d_noise_hidden_layer_num - 1):
|
| 144 |
+
layers.append(LinearBlock(cfg.d_hidden_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ))
|
| 145 |
+
output_dim = 1
|
| 146 |
+
layers.append(LinearBlock(cfg.d_hidden_dim, output_dim, 'none', 'none'))
|
| 147 |
+
self.net = nn.Sequential(*layers)
|
| 148 |
+
self.input_name = 'noise'
|
| 149 |
+
|
| 150 |
+
def forward(self, data_in):
|
| 151 |
+
x = data_in[self.input_name]
|
| 152 |
+
if self.cfg.lambda_cls_curliness:
|
| 153 |
+
x = torch.cat([x, data_in['noise_curliness']], dim=1)
|
| 154 |
+
out = self.net(x)
|
| 155 |
+
data = {'adv': out[:, [0]]}
|
| 156 |
+
return data
|
| 157 |
+
|
| 158 |
+
def forward_adv_direct(self, x):
|
| 159 |
+
return self.net(x)[:, [0]]
|
models/CtrlHair/color_texture_branch/model_eigengan.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: model_eigengan.py
|
| 5 |
+
# Time : 2021/12/28 21:57
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class SubspaceLayer(nn.Module):
|
| 15 |
+
def __init__(self, dim: int, n_basis: int):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.U = nn.Parameter(torch.empty(n_basis, dim), requires_grad=True)
|
| 18 |
+
nn.init.orthogonal_(self.U)
|
| 19 |
+
self.L = nn.Parameter(torch.FloatTensor([3 * i for i in range(n_basis, 0, -1)]), requires_grad=True)
|
| 20 |
+
self.mu = nn.Parameter(torch.zeros(dim), requires_grad=True)
|
| 21 |
+
|
| 22 |
+
self.unit_matrix = torch.eye(n_basis, requires_grad=False)
|
| 23 |
+
|
| 24 |
+
def forward(self, z):
|
| 25 |
+
return (self.L * z) @ self.U + self.mu
|
| 26 |
+
|
| 27 |
+
def orthogonal_regularizer(self):
|
| 28 |
+
UUT = self.U @ self.U.t()
|
| 29 |
+
self.unit_matrix = self.unit_matrix.to(self.U.device)
|
| 30 |
+
reg = ((UUT - self.unit_matrix) ** 2).mean()
|
| 31 |
+
return reg
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class EigenGenerator(nn.Module):
|
| 35 |
+
def __init__(self, cfg):
|
| 36 |
+
super(EigenGenerator, self).__init__()
|
| 37 |
+
self.cfg = cfg
|
| 38 |
+
|
| 39 |
+
input_dim = 0
|
| 40 |
+
if cfg.lambda_rgb:
|
| 41 |
+
input_dim += 3
|
| 42 |
+
if cfg.lambda_pca_std:
|
| 43 |
+
input_dim += 1
|
| 44 |
+
if cfg.lambda_cls_curliness:
|
| 45 |
+
input_dim += cfg.curliness_dim
|
| 46 |
+
|
| 47 |
+
self.main_layer_in = nn.Linear(input_dim, cfg.g_hidden_dim, bias=True)
|
| 48 |
+
main_layers_mid = []
|
| 49 |
+
for _ in range(cfg.g_hidden_layer_num - 1):
|
| 50 |
+
main_layers_mid.append(nn.Sequential(nn.LeakyReLU(0.2), nn.Linear(cfg.g_hidden_dim,
|
| 51 |
+
cfg.g_hidden_dim, bias=True)))
|
| 52 |
+
main_layers_mid.append(nn.Sequential(nn.LeakyReLU(0.2), nn.Linear(cfg.g_hidden_dim, cfg.SEAN_code)))
|
| 53 |
+
|
| 54 |
+
subspaces = []
|
| 55 |
+
for _ in range(cfg.g_hidden_layer_num):
|
| 56 |
+
sub = SubspaceLayer(cfg.g_hidden_dim, cfg.subspace_dim)
|
| 57 |
+
subspaces.append(sub)
|
| 58 |
+
|
| 59 |
+
self.main_layer_mid = nn.ModuleList(main_layers_mid)
|
| 60 |
+
self.subspaces = nn.ModuleList(subspaces)
|
| 61 |
+
|
| 62 |
+
def forward(self, data):
|
| 63 |
+
noise = data['noise']
|
| 64 |
+
noise = noise.reshape(len(data['noise']), self.cfg.g_hidden_layer_num, self.cfg.subspace_dim)
|
| 65 |
+
|
| 66 |
+
input_data = []
|
| 67 |
+
if self.cfg.lambda_cls_curliness:
|
| 68 |
+
input_data.append(data['noise_curliness'])
|
| 69 |
+
if self.cfg.lambda_rgb:
|
| 70 |
+
input_data.append(data['rgb_mean'])
|
| 71 |
+
if self.cfg.lambda_pca_std:
|
| 72 |
+
input_data.append(data['pca_std'])
|
| 73 |
+
|
| 74 |
+
x = torch.cat(input_data, dim=1)
|
| 75 |
+
x_mid = self.main_layer_in(x)
|
| 76 |
+
|
| 77 |
+
for layer_idx in range(self.cfg.g_hidden_layer_num):
|
| 78 |
+
subspace_data = self.subspaces[layer_idx](noise[:, layer_idx, :])
|
| 79 |
+
x_mid = x_mid + subspace_data
|
| 80 |
+
x_mid = self.main_layer_mid[layer_idx](x_mid)
|
| 81 |
+
|
| 82 |
+
res = {'code': x_mid}
|
| 83 |
+
return res
|
| 84 |
+
|
| 85 |
+
def orthogonal_regularizer_loss(self):
|
| 86 |
+
loss = 0
|
| 87 |
+
for s in self.subspaces:
|
| 88 |
+
loss = loss + s.orthogonal_regularizer()
|
| 89 |
+
return loss
|
models/CtrlHair/color_texture_branch/module.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: module.py
|
| 5 |
+
# Time : 2021/11/17 15:38
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class LinearBlock(nn.Module):
|
| 14 |
+
|
| 15 |
+
def __init__(self, input_dim, output_dim, norm, activation='relu', use_bias=True, leaky_slope=0.2, dropout=0):
|
| 16 |
+
super(LinearBlock, self).__init__()
|
| 17 |
+
# initialize fully connected layer
|
| 18 |
+
self.fc = nn.Linear(input_dim, output_dim, bias=use_bias)
|
| 19 |
+
|
| 20 |
+
# initialize normalization
|
| 21 |
+
norm_dim = output_dim
|
| 22 |
+
if norm == 'bn':
|
| 23 |
+
self.norm = nn.BatchNorm1d(norm_dim)
|
| 24 |
+
elif norm == 'in':
|
| 25 |
+
self.norm = nn.InstanceNorm1d(norm_dim)
|
| 26 |
+
elif norm == 'ln':
|
| 27 |
+
self.norm = nn.LayerNorm(norm_dim)
|
| 28 |
+
elif norm == 'none':
|
| 29 |
+
self.norm = None
|
| 30 |
+
else:
|
| 31 |
+
assert 0, "Unsupported normalization: {}".format(norm)
|
| 32 |
+
|
| 33 |
+
# initialize activation
|
| 34 |
+
if activation == 'relu':
|
| 35 |
+
self.activation = nn.ReLU(inplace=True)
|
| 36 |
+
elif activation == 'lrelu':
|
| 37 |
+
self.activation = nn.LeakyReLU(leaky_slope, inplace=True)
|
| 38 |
+
elif activation == 'prelu':
|
| 39 |
+
self.activation = nn.PReLU()
|
| 40 |
+
elif activation == 'selu':
|
| 41 |
+
self.activation = nn.SELU(inplace=True)
|
| 42 |
+
elif activation == 'tanh':
|
| 43 |
+
self.activation = nn.Tanh()
|
| 44 |
+
elif activation == 'none':
|
| 45 |
+
self.activation = None
|
| 46 |
+
else:
|
| 47 |
+
assert 0, "Unsupported activation: {}".format(activation)
|
| 48 |
+
|
| 49 |
+
self.dropout = dropout
|
| 50 |
+
if bool(self.dropout) and self.dropout > 0:
|
| 51 |
+
self.dropout_layer = nn.Dropout(p=self.dropout)
|
| 52 |
+
|
| 53 |
+
def forward(self, x):
|
| 54 |
+
out = self.fc(x)
|
| 55 |
+
if self.norm:
|
| 56 |
+
out = self.norm(out)
|
| 57 |
+
if self.activation:
|
| 58 |
+
out = self.activation(out)
|
| 59 |
+
if bool(self.dropout) and self.dropout > 0:
|
| 60 |
+
out = self.dropout_layer(out)
|
| 61 |
+
return out
|
models/CtrlHair/color_texture_branch/predictor/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: __init__.py.py
|
| 5 |
+
# Time : 2021/12/14 22:43
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
models/CtrlHair/color_texture_branch/predictor/predictor_config.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: predictor_config.py
|
| 5 |
+
# Time : 2021/12/14 21:03
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import addict # nesting dict
|
| 10 |
+
import os
|
| 11 |
+
import argparse
|
| 12 |
+
import sys
|
| 13 |
+
|
| 14 |
+
from global_value_utils import GLOBAL_DATA_ROOT
|
| 15 |
+
|
| 16 |
+
configs = [
|
| 17 |
+
addict.Dict({
|
| 18 |
+
"experiment_name": "p002___curliness",
|
| 19 |
+
'basic_dir': 'model_trained/curliness_classifier',
|
| 20 |
+
'filter_female_and_frontal': True,
|
| 21 |
+
'hidden_layer_num': 3,
|
| 22 |
+
'hidden_dim': 32,
|
| 23 |
+
'lambda_cls_curliness': {0: 1, 200: 0.1, 400: 0.01, 2500: 0.001},
|
| 24 |
+
'init_type': 'xavier',
|
| 25 |
+
'norm': 'bn',
|
| 26 |
+
'dropout': 0.5,
|
| 27 |
+
'total_batch_size': 256,
|
| 28 |
+
'total_step': 7000,
|
| 29 |
+
}),
|
| 30 |
+
addict.Dict({
|
| 31 |
+
"experiment_name": "p004___pca_std",
|
| 32 |
+
'basic_dir': 'model_trained/color_encoder',
|
| 33 |
+
'filter_female_and_frontal': True,
|
| 34 |
+
'hidden_layer_num': 3,
|
| 35 |
+
'hidden_dim': 256,
|
| 36 |
+
'lambda_rgb': {0: 1, 7000: 1},
|
| 37 |
+
'lambda_pca_std': {0: 1, 7000: 1},
|
| 38 |
+
'init_type': 'xavier',
|
| 39 |
+
'norm': 'bn',
|
| 40 |
+
'dropout': 0.2,
|
| 41 |
+
'total_batch_size': 256,
|
| 42 |
+
'total_step': 10000,
|
| 43 |
+
}),
|
| 44 |
+
]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_config(configs, config_id):
|
| 48 |
+
for c in configs:
|
| 49 |
+
if c.experiment_name.startswith(config_id):
|
| 50 |
+
check_add_default_value_to_base_cfg(c)
|
| 51 |
+
return c
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def check_add_default_value_to_base_cfg(cfg):
|
| 55 |
+
add_default_value_to_cfg(cfg, 'lr', 0.002)
|
| 56 |
+
add_default_value_to_cfg(cfg, 'beta1', 0.5)
|
| 57 |
+
add_default_value_to_cfg(cfg, 'beta2', 0.999)
|
| 58 |
+
|
| 59 |
+
add_default_value_to_cfg(cfg, 'log_step', 10)
|
| 60 |
+
add_default_value_to_cfg(cfg, 'model_save_step', 1000)
|
| 61 |
+
add_default_value_to_cfg(cfg, 'sample_batch_size', 100)
|
| 62 |
+
add_default_value_to_cfg(cfg, 'max_save', 2)
|
| 63 |
+
add_default_value_to_cfg(cfg, 'SEAN_code', 512)
|
| 64 |
+
|
| 65 |
+
# Model configuration
|
| 66 |
+
add_default_value_to_cfg(cfg, 'total_batch_size', 64)
|
| 67 |
+
add_default_value_to_cfg(cfg, 'gan_type', 'wgan_gp')
|
| 68 |
+
|
| 69 |
+
add_default_value_to_cfg(cfg, 'norm', 'none')
|
| 70 |
+
add_default_value_to_cfg(cfg, 'activ', 'lrelu')
|
| 71 |
+
add_default_value_to_cfg(cfg, 'init_type', 'normal')
|
| 72 |
+
|
| 73 |
+
add_default_value_to_cfg(cfg, 'root_dir', '%s/%s' % (cfg.basic_dir, cfg['experiment_name']))
|
| 74 |
+
add_default_value_to_cfg(cfg, 'log_dir', cfg.root_dir + '/logs')
|
| 75 |
+
add_default_value_to_cfg(cfg, 'model_save_dir', cfg.root_dir + '/models')
|
| 76 |
+
add_default_value_to_cfg(cfg, 'sample_dir', cfg.root_dir + '/samples')
|
| 77 |
+
try:
|
| 78 |
+
add_default_value_to_cfg(cfg, 'gpu_num', len(args.gpu.split(',')))
|
| 79 |
+
except:
|
| 80 |
+
add_default_value_to_cfg(cfg, 'gpu_num', 1)
|
| 81 |
+
|
| 82 |
+
add_default_value_to_cfg(cfg, 'data_root', GLOBAL_DATA_ROOT)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def add_default_value_to_cfg(cfg, key, value):
|
| 86 |
+
if key not in cfg:
|
| 87 |
+
cfg[key] = value
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def merge_config_in_place(ori_cfg, new_cfg):
|
| 91 |
+
for k in new_cfg:
|
| 92 |
+
ori_cfg[k] = new_cfg[k]
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def back_process(cfg):
|
| 96 |
+
cfg.batch_size = cfg.total_batch_size // cfg.gpu_num
|
| 97 |
+
cfg.predict_dict = {}
|
| 98 |
+
if 'lambda_cls_curliness' in cfg:
|
| 99 |
+
cfg.predict_dict['cls_curliness'] = 1
|
| 100 |
+
if 'lambda_rgb' in cfg:
|
| 101 |
+
cfg.predict_dict['rgb_mean'] = 3
|
| 102 |
+
if 'lambda_pca_std' in cfg:
|
| 103 |
+
cfg.predict_dict['pca_std'] = 1
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def get_basic_arg_parser():
|
| 107 |
+
parser = argparse.ArgumentParser()
|
| 108 |
+
parser.add_argument('-c', '--config', type=str, help='Specify config number', default='000')
|
| 109 |
+
parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
|
| 110 |
+
parser.add_argument('--local_rank', type=int, default=-1)
|
| 111 |
+
return parser
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
if sys.argv[0].endswith('predictor_train.py'):
|
| 115 |
+
parser = get_basic_arg_parser()
|
| 116 |
+
args = parser.parse_args()
|
| 117 |
+
cfg = get_config(configs, args.config)
|
| 118 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
|
| 119 |
+
back_process(cfg)
|
models/CtrlHair/color_texture_branch/predictor/predictor_model.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: predictor_model.py
|
| 5 |
+
# Time : 2021/12/14 20:47
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
from my_torchlib.module import LinearBlock
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Predictor(nn.Module):
|
| 15 |
+
"""Discriminator network."""
|
| 16 |
+
|
| 17 |
+
def __init__(self, cfg):
|
| 18 |
+
super(Predictor, self).__init__()
|
| 19 |
+
self.cfg = cfg
|
| 20 |
+
layers = [LinearBlock(cfg.SEAN_code, cfg.hidden_dim, cfg.norm, activation=cfg.activ, dropout=cfg.dropout)]
|
| 21 |
+
for _ in range(cfg.hidden_layer_num - 1):
|
| 22 |
+
layers.append(LinearBlock(cfg.hidden_dim, cfg.hidden_dim, cfg.norm, activation=cfg.activ,
|
| 23 |
+
dropout=cfg.dropout))
|
| 24 |
+
|
| 25 |
+
output_dim = 0
|
| 26 |
+
for ke in cfg.predict_dict:
|
| 27 |
+
output_dim += cfg.predict_dict[ke]
|
| 28 |
+
layers.append(LinearBlock(cfg.hidden_dim, output_dim, 'none', 'none'))
|
| 29 |
+
self.net = nn.Sequential(*layers)
|
| 30 |
+
self.input_name = 'code'
|
| 31 |
+
|
| 32 |
+
def forward(self, data_in):
|
| 33 |
+
x = data_in[self.input_name]
|
| 34 |
+
out = self.net(x)
|
| 35 |
+
ptr = 0
|
| 36 |
+
data = {}
|
| 37 |
+
for ke in self.cfg.predict_dict:
|
| 38 |
+
cur_dim = self.cfg.predict_dict[ke]
|
| 39 |
+
data[ke] = out[:, ptr:(ptr + cur_dim)]
|
| 40 |
+
ptr += cur_dim
|
| 41 |
+
return data
|
models/CtrlHair/color_texture_branch/predictor/predictor_solver.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: predictor_solver.py
|
| 5 |
+
# Time : 2021/12/14 21:57
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from color_texture_branch.predictor.predictor_config import cfg
|
| 13 |
+
from color_texture_branch.predictor.predictor_model import Predictor
|
| 14 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class PredictorSolver:
|
| 18 |
+
|
| 19 |
+
def __init__(self, cfg, device, local_rank, training=True):
|
| 20 |
+
self.mse_loss = torch.nn.MSELoss()
|
| 21 |
+
self.cfg = cfg
|
| 22 |
+
|
| 23 |
+
# model
|
| 24 |
+
self.pred = Predictor(cfg)
|
| 25 |
+
self.pred.to(device)
|
| 26 |
+
self.optimizer = torch.optim.Adam(self.pred.parameters(), lr=cfg.lr, betas=(cfg.beta1, cfg.beta2),
|
| 27 |
+
weight_decay=0.00)
|
| 28 |
+
|
| 29 |
+
if local_rank >= 0:
|
| 30 |
+
pDDP = lambda m, find_unused: DDP(m, device_ids=[local_rank], output_device=local_rank,
|
| 31 |
+
find_unused_parameters=False)
|
| 32 |
+
self.pred = pDDP(self.pred, find_unused=True)
|
| 33 |
+
self.local_rank = local_rank
|
| 34 |
+
self.device = device
|
| 35 |
+
|
| 36 |
+
def forward(self, data):
|
| 37 |
+
self.data = data
|
| 38 |
+
self.pred_res = self.pred(data)
|
| 39 |
+
|
| 40 |
+
def forward_d(self, loss_dict):
|
| 41 |
+
if 'lambda_rgb' in cfg:
|
| 42 |
+
loss_dict['lambda_rgb'] = self.mse_loss(self.pred_res['rgb_mean'], self.data['rgb_mean'])
|
| 43 |
+
if 'lambda_pca_std' in cfg:
|
| 44 |
+
d_pca_std = self.pred_res['pca_std']
|
| 45 |
+
loss_dict['lambda_pca_std'] = self.mse_loss(d_pca_std, self.data['pca_std'])
|
| 46 |
+
|
| 47 |
+
def forward_d_curliness(self, data_curliness, loss_dict):
|
| 48 |
+
if cfg.lambda_cls_curliness:
|
| 49 |
+
cls_curliness = self.pred_res['cls_curliness']
|
| 50 |
+
loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(
|
| 51 |
+
torch.sigmoid(cls_curliness), data_curliness['curliness_label'].float() / 2 + 0.5)
|
models/CtrlHair/color_texture_branch/predictor/predictor_train.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: predictor_train.py
|
| 5 |
+
# Time : 2021/12/14 20:58
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import sys
|
| 11 |
+
|
| 12 |
+
sys.path.append('.')
|
| 13 |
+
|
| 14 |
+
import tensorboardX
|
| 15 |
+
import torch
|
| 16 |
+
import tqdm
|
| 17 |
+
import numpy as np
|
| 18 |
+
from color_texture_branch.predictor.predictor_config import cfg, args
|
| 19 |
+
from color_texture_branch.dataset import Dataset
|
| 20 |
+
import my_pylib
|
| 21 |
+
# distributed training
|
| 22 |
+
import torch.distributed as dist
|
| 23 |
+
from color_texture_branch.predictor.predictor_solver import PredictorSolver
|
| 24 |
+
from my_torchlib.train_utils import LossUpdater, to_device, train
|
| 25 |
+
import my_torchlib
|
| 26 |
+
from color_texture_branch.model import init_weights
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_total_step():
|
| 30 |
+
total = 0
|
| 31 |
+
for key in cfg.iter:
|
| 32 |
+
total += cfg.iter[key]
|
| 33 |
+
return total
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def worker(proc, nprocs, args):
|
| 37 |
+
local_rank = args.local_rank
|
| 38 |
+
if local_rank >= 0:
|
| 39 |
+
torch.cuda.set_device(local_rank)
|
| 40 |
+
dist.init_process_group(backend='nccl',
|
| 41 |
+
init_method='tcp://localhost:%d' % (6030 + int(cfg.experiment_name[:3])),
|
| 42 |
+
rank=args.local_rank,
|
| 43 |
+
world_size=cfg.gpu_num)
|
| 44 |
+
print('setup rank %d' % local_rank)
|
| 45 |
+
device = torch.device('cuda', max(0, local_rank))
|
| 46 |
+
|
| 47 |
+
# config
|
| 48 |
+
out_dir = cfg.root_dir
|
| 49 |
+
|
| 50 |
+
# data
|
| 51 |
+
ds = Dataset(cfg)
|
| 52 |
+
|
| 53 |
+
# Loss class
|
| 54 |
+
solver = PredictorSolver(cfg, device, local_rank, training=True)
|
| 55 |
+
|
| 56 |
+
loss_updater = LossUpdater(cfg)
|
| 57 |
+
|
| 58 |
+
# load checkpoint
|
| 59 |
+
ckpt_dir = out_dir + '/checkpoints'
|
| 60 |
+
if local_rank <= 0:
|
| 61 |
+
my_pylib.mkdir(out_dir)
|
| 62 |
+
my_pylib.save_json(out_dir + '/setting_hair.json', cfg, indent=4, separators=(',', ': '))
|
| 63 |
+
my_pylib.mkdir(ckpt_dir)
|
| 64 |
+
|
| 65 |
+
try:
|
| 66 |
+
ckpt = my_torchlib.load_checkpoint(ckpt_dir)
|
| 67 |
+
start_step = ckpt['step'] + 1
|
| 68 |
+
for model_name in ['Predictor']:
|
| 69 |
+
cur_model = ckpt[model_name]
|
| 70 |
+
if list(cur_model)[0].startswith('module'):
|
| 71 |
+
ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
|
| 72 |
+
solver.pred.load_state_dict(ckpt['Predictor'], strict=True)
|
| 73 |
+
solver.optimizer.load_state_dict(ckpt['optimizer'])
|
| 74 |
+
print('Load succeed!')
|
| 75 |
+
except:
|
| 76 |
+
print(' [*] No checkpoint!')
|
| 77 |
+
init_weights(solver.pred, init_type=cfg.init_type)
|
| 78 |
+
start_step = 1
|
| 79 |
+
|
| 80 |
+
# writer
|
| 81 |
+
if local_rank <= 0:
|
| 82 |
+
writer = tensorboardX.SummaryWriter(out_dir + '/summaries')
|
| 83 |
+
else:
|
| 84 |
+
writer = None
|
| 85 |
+
|
| 86 |
+
# start training
|
| 87 |
+
test_batch = ds.get_testing_batch(100)
|
| 88 |
+
test_batch_curliness = ds.get_curliness_hair_test()
|
| 89 |
+
|
| 90 |
+
to_device(test_batch_curliness, device)
|
| 91 |
+
to_device(test_batch, device)
|
| 92 |
+
|
| 93 |
+
if local_rank >= 0:
|
| 94 |
+
dist.barrier()
|
| 95 |
+
|
| 96 |
+
total_step = cfg.total_step + 2
|
| 97 |
+
for step in tqdm.tqdm(range(start_step, total_step), total=total_step, initial=start_step, desc='step'):
|
| 98 |
+
loss_updater.update(step)
|
| 99 |
+
write_log = (writer and step % 11 == 0)
|
| 100 |
+
|
| 101 |
+
loss_dict = {}
|
| 102 |
+
if 'rgb_mean' in cfg.predict_dict or 'pca_std' in cfg.predict_dict:
|
| 103 |
+
data = ds.get_training_batch(cfg.batch_size)
|
| 104 |
+
to_device(data, device)
|
| 105 |
+
solver.forward(data)
|
| 106 |
+
solver.forward_d(loss_dict)
|
| 107 |
+
if write_log:
|
| 108 |
+
solver.pred.eval()
|
| 109 |
+
if 'rgb_mean' in cfg.predict_dict:
|
| 110 |
+
loss_dict['test_lambda_rgb'] = solver.mse_loss(
|
| 111 |
+
solver.pred(test_batch)['rgb_mean'], test_batch['rgb_mean'])
|
| 112 |
+
print('rgb loss: %f' % loss_dict['test_lambda_rgb'])
|
| 113 |
+
if 'pca_std' in cfg.predict_dict:
|
| 114 |
+
loss_dict['test_lambda_pca_std'] = solver.mse_loss(
|
| 115 |
+
solver.pred(test_batch)['pca_std'], test_batch['pca_std'])
|
| 116 |
+
print('pca_std loss: %f' % loss_dict['test_lambda_pca_std'])
|
| 117 |
+
solver.pred.train()
|
| 118 |
+
|
| 119 |
+
if cfg.lambda_cls_curliness:
|
| 120 |
+
data = {}
|
| 121 |
+
curliness_label = torch.tensor(np.random.choice([-1, 1], (cfg.batch_size, 1)))
|
| 122 |
+
data['curliness_label'] = curliness_label
|
| 123 |
+
data_curliness = ds.get_curliness_hair(curliness_label)
|
| 124 |
+
to_device(data_curliness, device)
|
| 125 |
+
solver.forward(data_curliness)
|
| 126 |
+
solver.forward_d_curliness(data_curliness, loss_dict)
|
| 127 |
+
|
| 128 |
+
# validation to show whether over-fit
|
| 129 |
+
if write_log:
|
| 130 |
+
solver.pred.eval()
|
| 131 |
+
logit = solver.pred(test_batch_curliness)['cls_curliness']
|
| 132 |
+
loss_dict['test_cls_curliness'] = torch.nn.functional.binary_cross_entropy_with_logits(
|
| 133 |
+
logit, test_batch_curliness['curliness_label'] / 2 + 0.5)
|
| 134 |
+
|
| 135 |
+
print('cls_curliness: %f' % loss_dict['test_cls_curliness'])
|
| 136 |
+
print('acc %f' % ((logit * test_batch_curliness['curliness_label'] > 0).sum() / logit.shape[0]))
|
| 137 |
+
solver.pred.train()
|
| 138 |
+
|
| 139 |
+
train(cfg, loss_dict, optimizers=[solver.optimizer],
|
| 140 |
+
step=step, writer=writer, flag='Pred', write_log=write_log)
|
| 141 |
+
|
| 142 |
+
if step > 0 and step % cfg.model_save_step == 0:
|
| 143 |
+
if local_rank <= 0:
|
| 144 |
+
save_model(step, solver, ckpt_dir)
|
| 145 |
+
if local_rank >= 0:
|
| 146 |
+
dist.barrier()
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def save_model(step, solver, ckpt_dir):
|
| 150 |
+
save_dic = {'step': step,
|
| 151 |
+
'Predictor': solver.pred.state_dict(),
|
| 152 |
+
'optimizer': solver.optimizer.state_dict()}
|
| 153 |
+
my_torchlib.save_checkpoint(save_dic, '%s/%07d.ckpt' % (ckpt_dir, step), max_keep=cfg.max_save)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
if __name__ == '__main__':
|
| 157 |
+
# with torch.autograd.set_detect_anomaly(True):
|
| 158 |
+
# mp.spawn(worker, nprocs=cfg.gpu_num, args=(cfg.gpu_num, args))
|
| 159 |
+
worker(proc=None, nprocs=None, args=args)
|
models/CtrlHair/color_texture_branch/script_find_direction.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: script_find_direction.py
|
| 5 |
+
# Time : 2022/02/28
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import sys
|
| 11 |
+
|
| 12 |
+
sys.path.append('.')
|
| 13 |
+
|
| 14 |
+
import os
|
| 15 |
+
import tqdm
|
| 16 |
+
|
| 17 |
+
from ui.backend import Backend
|
| 18 |
+
from util.canvas_grid import Canvas
|
| 19 |
+
import numpy as np
|
| 20 |
+
|
| 21 |
+
import pickle
|
| 22 |
+
from common_dataset import DataFilter
|
| 23 |
+
from util.imutil import read_rgb, write_rgb
|
| 24 |
+
from color_texture_branch.config import cfg
|
| 25 |
+
from util.find_semantic_direction import get_random_direction
|
| 26 |
+
|
| 27 |
+
df = DataFilter(cfg)
|
| 28 |
+
be = Backend(2.5, blending=False)
|
| 29 |
+
|
| 30 |
+
exist_direction = 'model_trained/color_texture/%s' % cfg.experiment_name
|
| 31 |
+
code_dim = cfg.noise_dim
|
| 32 |
+
att_name = 'texture'
|
| 33 |
+
interpolate_num = 6
|
| 34 |
+
max_val = 2.5
|
| 35 |
+
batch = 10
|
| 36 |
+
|
| 37 |
+
interpolate_values = np.linspace(-max_val, max_val, interpolate_num)
|
| 38 |
+
|
| 39 |
+
existing_dirs_dir = os.path.join(exist_direction, '%s_dir_used' % att_name)
|
| 40 |
+
|
| 41 |
+
existing_dirs_list = os.listdir(existing_dirs_dir)
|
| 42 |
+
existing_dirs = []
|
| 43 |
+
for dd in existing_dirs_list:
|
| 44 |
+
with open(os.path.join(existing_dirs_dir, dd), 'rb') as f:
|
| 45 |
+
existing_dirs.append(pickle.load(f))
|
| 46 |
+
|
| 47 |
+
direction_dir = '%s/direction_find/%s_dir_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
|
| 48 |
+
img_gen_dir = '%s/direction_find/%s_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
|
| 49 |
+
for dd in [direction_dir, img_gen_dir]:
|
| 50 |
+
if not os.path.exists(dd):
|
| 51 |
+
os.makedirs(dd)
|
| 52 |
+
|
| 53 |
+
img_list = df.train_list
|
| 54 |
+
|
| 55 |
+
for dir_idx in tqdm.tqdm(range(0, 300)):
|
| 56 |
+
rand_dir = get_random_direction(code_dim, existing_dirs)
|
| 57 |
+
with open('%s/%d.pkl' % (direction_dir, dir_idx,), 'wb') as f:
|
| 58 |
+
pickle.dump(rand_dir, f)
|
| 59 |
+
rand_dir = rand_dir.to(be.device)
|
| 60 |
+
|
| 61 |
+
canvas = Canvas(batch, interpolate_num + 1)
|
| 62 |
+
for img_idx, img_file in tqdm.tqdm(enumerate(img_list[:batch])):
|
| 63 |
+
img = read_rgb(img_file)
|
| 64 |
+
_, img_parsing = be.set_input_img(img)
|
| 65 |
+
|
| 66 |
+
canvas.process_draw_image(img, img_idx, 0)
|
| 67 |
+
|
| 68 |
+
for inter_idx in range(interpolate_num):
|
| 69 |
+
inter_val = interpolate_values[inter_idx]
|
| 70 |
+
be.continue_change_with_direction(att_name, rand_dir, inter_val)
|
| 71 |
+
|
| 72 |
+
out_img = be.output()
|
| 73 |
+
canvas.process_draw_image(out_img, img_idx, inter_idx + 1)
|
| 74 |
+
write_rgb('%s/%d.png' % (img_gen_dir, dir_idx), canvas.canvas)
|
models/CtrlHair/color_texture_branch/solver.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: solver.py
|
| 5 |
+
# Time : 2021/11/17 16:24
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
import numpy as np
|
| 12 |
+
from .config import cfg
|
| 13 |
+
from .model import Discriminator, DiscriminatorNoise
|
| 14 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 15 |
+
import random
|
| 16 |
+
import os
|
| 17 |
+
import cv2
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# solver
|
| 21 |
+
class Solver:
|
| 22 |
+
|
| 23 |
+
def __init__(self, cfg, device, local_rank, training=True):
|
| 24 |
+
self.mse_loss = torch.nn.MSELoss()
|
| 25 |
+
self.cfg = cfg
|
| 26 |
+
|
| 27 |
+
# model
|
| 28 |
+
if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
|
| 29 |
+
from color_texture_branch.model_eigengan import EigenGenerator
|
| 30 |
+
self.gen = EigenGenerator(cfg)
|
| 31 |
+
else:
|
| 32 |
+
from color_texture_branch.model import Generator
|
| 33 |
+
self.gen = Generator(cfg)
|
| 34 |
+
self.gen.to(device)
|
| 35 |
+
|
| 36 |
+
self.dis = Discriminator(cfg)
|
| 37 |
+
self.dis.to(device)
|
| 38 |
+
|
| 39 |
+
if 'curliness' in cfg.predictor:
|
| 40 |
+
from color_texture_branch.predictor.predictor_model import Predictor
|
| 41 |
+
self.curliness_model = Predictor(cfg.predictor['curliness'])
|
| 42 |
+
self.curliness_model.to(device)
|
| 43 |
+
self.curliness_model.eval()
|
| 44 |
+
|
| 45 |
+
if 'rgb' in cfg.predictor:
|
| 46 |
+
from color_texture_branch.predictor.predictor_model import Predictor
|
| 47 |
+
self.rgb_model = Predictor(cfg.predictor['rgb'])
|
| 48 |
+
self.rgb_model.to(device)
|
| 49 |
+
self.rgb_model.eval()
|
| 50 |
+
|
| 51 |
+
if training:
|
| 52 |
+
self.G_optimizer = torch.optim.Adam(self.gen.parameters(), lr=cfg.lr_d, betas=(cfg.beta1, cfg.beta2),
|
| 53 |
+
weight_decay=0.00)
|
| 54 |
+
self.D_optimizer = torch.optim.Adam(self.dis.parameters(), lr=cfg.lr_g, betas=(cfg.beta1, cfg.beta2),
|
| 55 |
+
weight_decay=0.00)
|
| 56 |
+
|
| 57 |
+
if cfg.lambda_adv_noise:
|
| 58 |
+
self.dis_noise = DiscriminatorNoise(cfg)
|
| 59 |
+
self.dis_noise.to(device)
|
| 60 |
+
self.D_noise_optimizer = torch.optim.Adam(self.dis_noise.parameters(), lr=cfg.lr_g,
|
| 61 |
+
betas=(cfg.beta1, cfg.beta2), weight_decay=0.00)
|
| 62 |
+
else:
|
| 63 |
+
self.dis_noise = None
|
| 64 |
+
else:
|
| 65 |
+
self.gen.eval()
|
| 66 |
+
self.dis.eval()
|
| 67 |
+
|
| 68 |
+
if local_rank >= 0:
|
| 69 |
+
pDDP = lambda m, find_unused: DDP(m, device_ids=[local_rank], output_device=local_rank,
|
| 70 |
+
find_unused_parameters=False)
|
| 71 |
+
self.gen = pDDP(self.gen, find_unused=True)
|
| 72 |
+
self.dis = pDDP(self.dis, find_unused=True)
|
| 73 |
+
if cfg.lambda_adv_noise:
|
| 74 |
+
self.dis_noise = pDDP(self.dis_noise, find_unused=True)
|
| 75 |
+
self.local_rank = local_rank
|
| 76 |
+
self.device = device
|
| 77 |
+
|
| 78 |
+
def edit_infer(self, hair_code, data):
|
| 79 |
+
self.inner_code = self.dis({'code': hair_code})
|
| 80 |
+
for ke in data:
|
| 81 |
+
self.inner_code[ke] = data[ke]
|
| 82 |
+
self.res = self.gen(self.inner_code)
|
| 83 |
+
return self.res['code']
|
| 84 |
+
|
| 85 |
+
def forward(self, data):
|
| 86 |
+
self.ae_in = {'code': data['code']}
|
| 87 |
+
|
| 88 |
+
# rec
|
| 89 |
+
d_res_real = self.dis(self.ae_in)
|
| 90 |
+
self.ae_mid = {'noise': d_res_real['noise'], 'rgb_mean': data['rgb_mean'], 'pca_std': data['pca_std']}
|
| 91 |
+
if cfg.lambda_cls_curliness:
|
| 92 |
+
self.ae_mid['noise_curliness'] = d_res_real['noise_curliness']
|
| 93 |
+
self.ae_out = self.gen(self.ae_mid)
|
| 94 |
+
|
| 95 |
+
# gan
|
| 96 |
+
random_list = list(range(data['rgb_mean'].shape[0]))
|
| 97 |
+
random.shuffle(random_list)
|
| 98 |
+
self.gan_in = {'rgb_mean': data['rgb_mean'][random_list]}
|
| 99 |
+
self.gan_in['pca_std'] = data['pca_std'][random_list]
|
| 100 |
+
random.shuffle(random_list)
|
| 101 |
+
if cfg.lambda_cls_curliness:
|
| 102 |
+
self.gan_in['noise_curliness'] = data['noise_curliness'][random_list]
|
| 103 |
+
self.gan_in['curliness_label'] = data['curliness_label'][random_list]
|
| 104 |
+
random.shuffle(random_list)
|
| 105 |
+
|
| 106 |
+
if self.cfg.gan_input_from_encoder_prob and \
|
| 107 |
+
random.random() < self.cfg.gan_input_from_encoder_prob:
|
| 108 |
+
self.gan_in['noise'] = d_res_real['noise'][random_list].detach()
|
| 109 |
+
else:
|
| 110 |
+
self.gan_in['noise'] = data['noise'][random_list]
|
| 111 |
+
self.gan_mid = self.gen(self.gan_in)
|
| 112 |
+
self.gan_out_fake = self.dis(self.gan_mid)
|
| 113 |
+
self.gan_out_real = d_res_real
|
| 114 |
+
self.gan_label = {'rgb_mean': data['rgb_mean'], 'pca_std': data['pca_std'], 'curliness_label': data['curliness_label']}
|
| 115 |
+
self.real_noise = {'noise': data['noise']}
|
| 116 |
+
if cfg.lambda_cls_curliness:
|
| 117 |
+
self.real_noise['noise_curliness'] = data['noise_curliness']
|
| 118 |
+
|
| 119 |
+
def forward_g(self, loss_dict):
|
| 120 |
+
self.forward_general_gen(self.gan_out_fake['adv'], loss_dict)
|
| 121 |
+
|
| 122 |
+
loss_dict['lambda_info'] = self.mse_loss(self.gan_out_fake['noise'], self.gan_in['noise'])
|
| 123 |
+
loss_dict['lambda_rec'] = self.mse_loss(self.ae_out['code'], self.ae_in['code'])
|
| 124 |
+
|
| 125 |
+
if 'rgb' in cfg.predictor:
|
| 126 |
+
p_rgb = self.rgb_model(self.gan_mid)
|
| 127 |
+
if cfg.lambda_rgb:
|
| 128 |
+
if 'rgb' in cfg.predictor:
|
| 129 |
+
d_rgb_mean = p_rgb['rgb_mean']
|
| 130 |
+
else:
|
| 131 |
+
d_rgb_mean = self.gan_out_fake['rgb_mean']
|
| 132 |
+
loss_dict['lambda_rgb'] = self.mse_loss(d_rgb_mean, self.gan_in['rgb_mean'])
|
| 133 |
+
|
| 134 |
+
if cfg.lambda_pca_std:
|
| 135 |
+
if 'rgb' in cfg.predictor:
|
| 136 |
+
d_pca_std = p_rgb['pca_std']
|
| 137 |
+
else:
|
| 138 |
+
d_pca_std = self.gan_out_fake['pca_std']
|
| 139 |
+
loss_dict['lambda_pca_std'] = self.mse_loss(d_pca_std, self.gan_in['pca_std'])
|
| 140 |
+
|
| 141 |
+
if cfg.lambda_cls_curliness:
|
| 142 |
+
d_noise_curliness = self.gan_out_fake['noise_curliness']
|
| 143 |
+
loss_dict['lambda_info_curliness'] = self.mse_loss(d_noise_curliness, self.gan_in['noise_curliness'])
|
| 144 |
+
if 'curliness' in cfg.predictor:
|
| 145 |
+
cls_curliness = self.curliness_model(self.gan_mid)['cls_curliness']
|
| 146 |
+
else:
|
| 147 |
+
cls_curliness = self.gan_out_fake['cls_curliness']
|
| 148 |
+
if cfg.curliness_with_weight:
|
| 149 |
+
weights = self.gan_in['noise_curliness'].abs()
|
| 150 |
+
weights = weights / weights.sum() * weights.shape[0]
|
| 151 |
+
loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
|
| 152 |
+
self.gan_in['curliness_label'].float() / 2 + 0.5,
|
| 153 |
+
weight=weights)
|
| 154 |
+
else:
|
| 155 |
+
loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
|
| 156 |
+
self.gan_in['curliness_label'].float() / 2 + 0.5)
|
| 157 |
+
|
| 158 |
+
if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
|
| 159 |
+
loss_dict['lambda_orthogonal'] = self.gen.orthogonal_regularizer_loss()
|
| 160 |
+
|
| 161 |
+
for loss_d in [loss_dict]:
|
| 162 |
+
for ke in loss_d:
|
| 163 |
+
if np.isnan(np.array(loss_d[ke].detach().cpu())):
|
| 164 |
+
print('!!!!!!!!! %s is nan' % ke)
|
| 165 |
+
print(loss_d)
|
| 166 |
+
raise Exception()
|
| 167 |
+
|
| 168 |
+
@staticmethod
|
| 169 |
+
def forward_general_gen(dis_res, loss_dict, loss_name_suffix=''):
|
| 170 |
+
if cfg.gan_type == 'lsgan':
|
| 171 |
+
loss_dis = torch.mean((dis_res - 1) ** 2)
|
| 172 |
+
elif cfg.gan_type == 'nsgan':
|
| 173 |
+
all1 = torch.ones_like(dis_res.data).cuda()
|
| 174 |
+
loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis_res), all1))
|
| 175 |
+
elif cfg.gan_type == 'wgan_gp':
|
| 176 |
+
loss_dis = - torch.mean(dis_res)
|
| 177 |
+
elif cfg.gan_type == 'hinge':
|
| 178 |
+
loss_dis = -torch.mean(dis_res)
|
| 179 |
+
elif cfg.gan_type == 'hinge2':
|
| 180 |
+
loss_dis = torch.mean(torch.max(1 - dis_res, torch.zeros_like(dis_res)))
|
| 181 |
+
else:
|
| 182 |
+
raise NotImplementedError()
|
| 183 |
+
loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
|
| 184 |
+
|
| 185 |
+
@staticmethod
|
| 186 |
+
def forward_general_dis(dis1, dis0, dis_model, loss_dict, input_real, input_fake, loss_name_suffix=''):
|
| 187 |
+
|
| 188 |
+
if cfg.gan_type == 'lsgan':
|
| 189 |
+
loss_dis = torch.mean((dis0 - 0) ** 2) + torch.mean((dis1 - 1) ** 2)
|
| 190 |
+
elif cfg.gan_type == 'nsgan':
|
| 191 |
+
all0 = torch.zeros_like(dis0.data).cuda()
|
| 192 |
+
all1 = torch.ones_like(dis1.data).cuda()
|
| 193 |
+
loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis0), all0) +
|
| 194 |
+
F.binary_cross_entropy(torch.sigmoid(dis1), all1))
|
| 195 |
+
elif cfg.gan_type == 'wgan_gp':
|
| 196 |
+
loss_dis = torch.mean(dis0) - torch.mean(dis1)
|
| 197 |
+
elif cfg.gan_type == 'hinge' or cfg.gan_type == 'hinge2':
|
| 198 |
+
loss_dis = torch.mean(torch.max(1 - dis1, torch.zeros_like(dis1)))
|
| 199 |
+
loss_dis += torch.mean(torch.max(1 + dis0, torch.zeros_like(dis1)))
|
| 200 |
+
else:
|
| 201 |
+
assert 0, "Unsupported GAN type: {}".format(dis_model.gan_type)
|
| 202 |
+
loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
|
| 203 |
+
|
| 204 |
+
if cfg.gan_type == 'wgan_gp':
|
| 205 |
+
loss_gp = 0
|
| 206 |
+
alpha_gp = torch.rand(input_real.size(0), 1, ).type_as(input_real)
|
| 207 |
+
x_hat = (alpha_gp * input_real + (1 - alpha_gp) * input_fake).requires_grad_(True)
|
| 208 |
+
out_hat = dis_model.forward_adv_direct(x_hat)
|
| 209 |
+
# gradient penalty
|
| 210 |
+
weight = torch.ones(out_hat.size()).type_as(out_hat)
|
| 211 |
+
dydx = torch.autograd.grad(outputs=out_hat, inputs=x_hat, grad_outputs=weight, retain_graph=True,
|
| 212 |
+
create_graph=True, only_inputs=True)[0]
|
| 213 |
+
dydx = dydx.contiguous().view(dydx.size(0), -1)
|
| 214 |
+
dydx_l2norm = torch.sqrt(torch.sum(dydx ** 2, dim=1))
|
| 215 |
+
loss_gp += torch.mean((dydx_l2norm - 1) ** 2)
|
| 216 |
+
loss_dict['lambda_gp' + loss_name_suffix] = loss_gp
|
| 217 |
+
|
| 218 |
+
def forward_d(self, loss_dict):
|
| 219 |
+
self.forward_general_dis(self.gan_out_real['adv'], self.gan_out_fake['adv'],
|
| 220 |
+
self.dis, loss_dict, input_real=self.ae_in['code'],
|
| 221 |
+
input_fake=self.gan_mid['code'])
|
| 222 |
+
|
| 223 |
+
loss_dict['lambda_info'] = self.mse_loss(self.gan_out_fake['noise'], self.gan_in['noise'])
|
| 224 |
+
if cfg.lambda_rgb and 'rgb' not in cfg.predictor:
|
| 225 |
+
loss_dict['lambda_rgb'] = self.mse_loss(self.gan_in['rgb_mean'], self.gan_out_fake['rgb_mean'])
|
| 226 |
+
loss_dict['lambda_rec'] = self.mse_loss(self.ae_out['code'], self.ae_in['code'])
|
| 227 |
+
if cfg.lambda_pca_std and 'rgb' not in cfg.predictor:
|
| 228 |
+
loss_dict['lambda_pca_std'] = self.mse_loss(self.gan_out_real['pca_std'], self.gan_label['pca_std'])
|
| 229 |
+
|
| 230 |
+
if cfg.lambda_adv_noise:
|
| 231 |
+
self.d_noise_res = self.dis_noise(self.ae_mid)
|
| 232 |
+
self.forward_general_gen(self.d_noise_res['adv'], loss_dict, loss_name_suffix='_noise')
|
| 233 |
+
|
| 234 |
+
if cfg.lambda_moment_1 or cfg.lambda_moment_2:
|
| 235 |
+
if cfg.lambda_cls_curliness:
|
| 236 |
+
noise_mid = torch.cat([self.ae_mid['noise_curliness'], self.ae_mid['noise']], dim=1)
|
| 237 |
+
else:
|
| 238 |
+
noise_mid = self.ae_mid['noise']
|
| 239 |
+
if cfg.lambda_moment_1:
|
| 240 |
+
loss_dict['lambda_moment_1'] = (noise_mid.mean(dim=0) ** 2).mean()
|
| 241 |
+
if cfg.lambda_moment_2:
|
| 242 |
+
loss_dict['lambda_moment_2'] = (((noise_mid ** 2).mean(dim=0) - 1) ** 2).mean()
|
| 243 |
+
|
| 244 |
+
if cfg.lambda_cls_curliness:
|
| 245 |
+
loss_dict['lambda_info_curliness'] = self.mse_loss(self.gan_out_fake['noise_curliness'], self.gan_in['noise_curliness'])
|
| 246 |
+
|
| 247 |
+
def forward_d_curliness(self, data_curliness, loss_dict):
|
| 248 |
+
d_res = self.dis(data_curliness)
|
| 249 |
+
cls_curliness = d_res['cls_curliness']
|
| 250 |
+
loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
|
| 251 |
+
data_curliness['curliness_label'].float() / 2 + 0.5)
|
| 252 |
+
|
| 253 |
+
def forward_adv_noise(self, loss_dict):
|
| 254 |
+
dis1 = self.dis_noise(self.real_noise)['adv']
|
| 255 |
+
self.ae_mid['noise'] = self.ae_mid['noise'].detach()
|
| 256 |
+
if self.cfg.lambda_cls_curliness:
|
| 257 |
+
self.ae_mid['noise_curliness'] = self.ae_mid['noise_curliness'].detach()
|
| 258 |
+
self.d_noise_res = self.dis_noise(self.ae_mid)
|
| 259 |
+
dis0 = self.d_noise_res['adv']
|
| 260 |
+
|
| 261 |
+
input_real = self.real_noise['noise']
|
| 262 |
+
input_fake = self.ae_mid['noise']
|
| 263 |
+
if self.cfg.lambda_cls_curliness:
|
| 264 |
+
input_real = torch.cat([input_real, self.real_noise['noise_curliness']], dim=1)
|
| 265 |
+
input_fake = torch.cat([input_fake, self.ae_mid['noise_curliness']], dim=1)
|
| 266 |
+
|
| 267 |
+
self.forward_general_dis(dis1, dis0, self.dis_noise, loss_dict, input_real=input_real,
|
| 268 |
+
input_fake=input_fake, loss_name_suffix='_noise')
|
| 269 |
+
|
| 270 |
+
def forward_rec_img(self, data, loss_dict, batch_size=4):
|
| 271 |
+
from .validation_in_train import he
|
| 272 |
+
from global_value_utils import HAIR_IDX
|
| 273 |
+
|
| 274 |
+
items = data['items']
|
| 275 |
+
|
| 276 |
+
rec_loss = 0
|
| 277 |
+
for idx in range(batch_size):
|
| 278 |
+
item = items[idx]
|
| 279 |
+
dataset_name, img_name = item.split('___')
|
| 280 |
+
parsing_img = cv2.imread(os.path.join(self.cfg.data_root, '%s/label/%s.png') %
|
| 281 |
+
(dataset_name, img_name), cv2.IMREAD_GRAYSCALE)
|
| 282 |
+
parsing_img = cv2.resize(parsing_img, (256, 256), cv2.INTER_NEAREST)
|
| 283 |
+
|
| 284 |
+
sean_code = torch.tensor(data['sean_code'][idx].copy(), dtype=torch.float32).to(self.ae_out['code'].device)
|
| 285 |
+
sean_code[HAIR_IDX] = self.ae_out['code'][idx, ...]
|
| 286 |
+
|
| 287 |
+
render_img = he.gen_img(sean_code[None, ...], parsing_img[None, None, ...])
|
| 288 |
+
|
| 289 |
+
input_img = cv2.cvtColor(cv2.imread(os.path.join(self.cfg.data_root, '%s/images_256/%s.png') %
|
| 290 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 291 |
+
input_img = input_img / 127.5 - 1.0
|
| 292 |
+
input_img = input_img.transpose(2, 0, 1)
|
| 293 |
+
|
| 294 |
+
input_img = torch.tensor(input_img).to(render_img.device)
|
| 295 |
+
parsing_img = torch.tensor(parsing_img).to(render_img.device)
|
| 296 |
+
|
| 297 |
+
rec_loss = rec_loss + ((input_img - render_img)[:, (parsing_img == HAIR_IDX)] ** 2).mean()
|
| 298 |
+
rec_loss = rec_loss / batch_size
|
| 299 |
+
loss_dict['lambda_rec_img'] = rec_loss
|
models/CtrlHair/color_texture_branch/train.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: scripts.py.py
|
| 5 |
+
# Time : 2021/11/17 15:24
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import sys
|
| 11 |
+
|
| 12 |
+
sys.path.append('.')
|
| 13 |
+
|
| 14 |
+
import tensorboardX
|
| 15 |
+
import torch
|
| 16 |
+
import tqdm
|
| 17 |
+
import numpy as np
|
| 18 |
+
from color_texture_branch.config import cfg, args
|
| 19 |
+
from color_texture_branch.dataset import Dataset
|
| 20 |
+
import my_pylib
|
| 21 |
+
from color_texture_branch.validation_in_train import print_val_save_model
|
| 22 |
+
# distributed training
|
| 23 |
+
import torch.distributed as dist
|
| 24 |
+
from color_texture_branch.solver import Solver
|
| 25 |
+
from my_torchlib.train_utils import LossUpdater, to_device, generate_noise, train
|
| 26 |
+
import my_torchlib
|
| 27 |
+
from color_texture_branch.model import init_weights
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_total_step():
|
| 31 |
+
total = 0
|
| 32 |
+
for key in cfg.iter:
|
| 33 |
+
total += cfg.iter[key]
|
| 34 |
+
return total
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def worker(proc, nprocs, args):
|
| 38 |
+
local_rank = args.local_rank
|
| 39 |
+
if local_rank >= 0:
|
| 40 |
+
torch.cuda.set_device(local_rank)
|
| 41 |
+
dist.init_process_group(backend='nccl',
|
| 42 |
+
init_method='tcp://localhost:%d' % (6030 + int(cfg.experiment_name[:3])),
|
| 43 |
+
rank=args.local_rank,
|
| 44 |
+
world_size=cfg.gpu_num)
|
| 45 |
+
print('setup rank %d' % local_rank)
|
| 46 |
+
device = torch.device('cuda', max(0, local_rank))
|
| 47 |
+
|
| 48 |
+
# config
|
| 49 |
+
out_dir = cfg.root_dir
|
| 50 |
+
|
| 51 |
+
# data
|
| 52 |
+
ds = Dataset(cfg)
|
| 53 |
+
|
| 54 |
+
loss_updater = LossUpdater(cfg)
|
| 55 |
+
loss_updater.update(0)
|
| 56 |
+
|
| 57 |
+
# Loss class
|
| 58 |
+
solver = Solver(cfg, device, local_rank=local_rank)
|
| 59 |
+
|
| 60 |
+
# load checkpoint
|
| 61 |
+
ckpt_dir = out_dir + '/checkpoints'
|
| 62 |
+
if local_rank <= 0:
|
| 63 |
+
my_pylib.mkdir(out_dir)
|
| 64 |
+
my_pylib.save_json(out_dir + '/setting_hair.json', cfg, indent=4, separators=(',', ': '))
|
| 65 |
+
my_pylib.mkdir(ckpt_dir)
|
| 66 |
+
|
| 67 |
+
try:
|
| 68 |
+
ckpt = my_torchlib.load_checkpoint(ckpt_dir)
|
| 69 |
+
start_step = ckpt['step'] + 1
|
| 70 |
+
for model_name in ['Model_G', 'Model_D']:
|
| 71 |
+
cur_model = ckpt[model_name]
|
| 72 |
+
if list(cur_model)[0].startswith('module'):
|
| 73 |
+
ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
|
| 74 |
+
solver.gen.load_state_dict(ckpt['Model_G'], strict=True)
|
| 75 |
+
solver.dis.load_state_dict(ckpt['Model_D'], strict=True)
|
| 76 |
+
solver.D_optimizer.load_state_dict(ckpt['D_optimizer'])
|
| 77 |
+
solver.G_optimizer.load_state_dict(ckpt['G_optimizer'])
|
| 78 |
+
if cfg.lambda_adv_noise:
|
| 79 |
+
solver.dis_noise.load_state_dict(ckpt['Model_D_noise'], strict=True)
|
| 80 |
+
solver.D_noise_optimizer.load_state_dict(ckpt['D_noise_optimizer'])
|
| 81 |
+
print('Load succeed!')
|
| 82 |
+
except:
|
| 83 |
+
print(' [*] No checkpoint!')
|
| 84 |
+
init_weights(solver.gen, init_type=cfg.init_type)
|
| 85 |
+
init_weights(solver.dis, init_type=cfg.init_type)
|
| 86 |
+
if cfg.lambda_adv_noise:
|
| 87 |
+
init_weights(solver.dis_noise, init_type=cfg.init_type)
|
| 88 |
+
start_step = 1
|
| 89 |
+
|
| 90 |
+
if 'curliness' in cfg.predictor:
|
| 91 |
+
ckpt = my_torchlib.load_checkpoint(cfg.predictor.curliness.root_dir + '/checkpoints')
|
| 92 |
+
solver.curliness_model.load_state_dict(ckpt['Predictor'], strict=True)
|
| 93 |
+
|
| 94 |
+
if 'rgb' in cfg.predictor:
|
| 95 |
+
ckpt = my_torchlib.load_checkpoint(cfg.predictor.rgb.root_dir + '/checkpoints')
|
| 96 |
+
solver.rgb_model.load_state_dict(ckpt['Predictor'], strict=True)
|
| 97 |
+
|
| 98 |
+
# writer
|
| 99 |
+
if local_rank <= 0:
|
| 100 |
+
writer = tensorboardX.SummaryWriter(out_dir + '/summaries')
|
| 101 |
+
else:
|
| 102 |
+
writer = None
|
| 103 |
+
|
| 104 |
+
# start training
|
| 105 |
+
test_batch = ds.get_testing_batch(cfg.sample_batch_size)
|
| 106 |
+
test_batch_curliness = ds.get_curliness_hair_test()
|
| 107 |
+
|
| 108 |
+
to_device(test_batch_curliness, device)
|
| 109 |
+
to_device(test_batch, device)
|
| 110 |
+
|
| 111 |
+
if local_rank >= 0:
|
| 112 |
+
dist.barrier()
|
| 113 |
+
|
| 114 |
+
total_step = cfg.total_step + 2
|
| 115 |
+
for step in tqdm.tqdm(range(start_step, total_step), total=total_step, initial=start_step, desc='step'):
|
| 116 |
+
loss_updater.update(step)
|
| 117 |
+
write_log = (writer and step % 23 == 0)
|
| 118 |
+
|
| 119 |
+
for i in range(sum(cfg.G_D_train_num.values())):
|
| 120 |
+
data = ds.get_training_batch(cfg.batch_size)
|
| 121 |
+
data['noise'] = generate_noise(cfg.batch_size, cfg.noise_dim)
|
| 122 |
+
if cfg.lambda_cls_curliness:
|
| 123 |
+
curliness_label = torch.tensor(np.random.choice([-1, 1], (cfg.batch_size, 1)))
|
| 124 |
+
data['curliness_label'] = curliness_label
|
| 125 |
+
data['noise_curliness'] = generate_noise(cfg.batch_size, cfg.curliness_dim, curliness_label)
|
| 126 |
+
to_device(data, device)
|
| 127 |
+
loss_dict = {}
|
| 128 |
+
solver.forward(data)
|
| 129 |
+
|
| 130 |
+
if 'lambda_rec_img' in cfg and cfg.lambda_rec_img > 0:
|
| 131 |
+
solver.forward_rec_img(data, loss_dict)
|
| 132 |
+
|
| 133 |
+
if i < cfg.G_D_train_num['D']:
|
| 134 |
+
solver.forward_d(loss_dict)
|
| 135 |
+
if cfg.lambda_cls_curliness and not 'curliness' in cfg.predictor:
|
| 136 |
+
data_curliness = ds.get_curliness_hair(curliness_label)
|
| 137 |
+
to_device(data_curliness, device)
|
| 138 |
+
solver.forward_d_curliness(data_curliness, loss_dict)
|
| 139 |
+
|
| 140 |
+
# validation to show whether over-fit
|
| 141 |
+
if write_log:
|
| 142 |
+
loss_dict['test_cls_curliness'] = torch.nn.functional.binary_cross_entropy_with_logits(
|
| 143 |
+
solver.dis(test_batch_curliness)['cls_curliness'], test_batch_curliness['curliness_label'] / 2 + 0.5)
|
| 144 |
+
if cfg.lambda_rgb and 'rgb' not in cfg.predictor and write_log:
|
| 145 |
+
loss_dict['test_lambda_rgb'] = solver.mse_loss(solver.dis(test_batch)['rgb_mean'],
|
| 146 |
+
test_batch['rgb_mean'])
|
| 147 |
+
train(cfg, loss_dict, optimizers=[solver.D_optimizer],
|
| 148 |
+
step=step, writer=writer, flag='D', write_log=write_log)
|
| 149 |
+
else:
|
| 150 |
+
solver.forward_g(loss_dict)
|
| 151 |
+
train(cfg, loss_dict, optimizers=[solver.G_optimizer],
|
| 152 |
+
step=step, writer=writer, flag='G', write_log=write_log)
|
| 153 |
+
|
| 154 |
+
if cfg.lambda_adv_noise:
|
| 155 |
+
loss_dict = {}
|
| 156 |
+
solver.forward_adv_noise(loss_dict)
|
| 157 |
+
train(cfg, loss_dict, optimizers=[solver.D_noise_optimizer], step=step, writer=writer, flag='D_noise',
|
| 158 |
+
write_log=write_log)
|
| 159 |
+
|
| 160 |
+
print_val_save_model(step, out_dir, solver, test_batch, ckpt_dir, local_rank)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
if __name__ == '__main__':
|
| 164 |
+
# with torch.autograd.set_detect_anomaly(True):
|
| 165 |
+
# mp.spawn(worker, nprocs=cfg.gpu_num, args=(cfg.gpu_num, args))
|
| 166 |
+
worker(proc=None, nprocs=None, args=args)
|
models/CtrlHair/color_texture_branch/validation_in_train.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: validation_in_train.py
|
| 5 |
+
# Time : 2021/12/10 12:55
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import cv2
|
| 11 |
+
import os
|
| 12 |
+
|
| 13 |
+
from .config import cfg
|
| 14 |
+
import my_pylib
|
| 15 |
+
import torch
|
| 16 |
+
from my_torchlib.train_utils import tensor2numpy, to_device, generate_noise
|
| 17 |
+
from util.canvas_grid import Canvas
|
| 18 |
+
from global_value_utils import HAIR_IDX
|
| 19 |
+
import copy
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch.distributed as dist
|
| 22 |
+
import my_torchlib
|
| 23 |
+
from hair_editor import HairEditor
|
| 24 |
+
|
| 25 |
+
he = HairEditor(load_feature_model=False, load_mask_model=False)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def gen_by_sean(sean_code, item):
|
| 29 |
+
dataset_name, img_name = item.split('___')
|
| 30 |
+
parsing_img = cv2.imread(os.path.join(cfg.data_root, '%s/label/%s.png') %
|
| 31 |
+
(dataset_name, img_name), cv2.IMREAD_GRAYSCALE)
|
| 32 |
+
parsing_img = cv2.resize(parsing_img, (256, 256), cv2.INTER_NEAREST)
|
| 33 |
+
return he.gen_img(sean_code[None, ...], parsing_img[None, None, ...])
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def save_model(step, solver, ckpt_dir):
|
| 37 |
+
save_dic = {'step': step,
|
| 38 |
+
'Model_G': solver.gen.state_dict(), 'Model_D': solver.dis.state_dict(),
|
| 39 |
+
'D_optimizer': solver.D_optimizer.state_dict(), 'G_optimizer': solver.G_optimizer.state_dict()}
|
| 40 |
+
if cfg.lambda_adv_noise:
|
| 41 |
+
save_dic['Model_D_noise'] = solver.dis_noise.state_dict()
|
| 42 |
+
save_dic['D_noise_optimizer'] = solver.D_noise_optimizer.state_dict()
|
| 43 |
+
my_torchlib.save_checkpoint(save_dic, '%s/%07d.ckpt' % (ckpt_dir, step), max_keep=cfg.max_save)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def print_val_save_model(step, out_dir, solver, test_batch, ckpt_dir, local_rank):
|
| 47 |
+
"""
|
| 48 |
+
:param step:
|
| 49 |
+
:param validation_data:
|
| 50 |
+
:param img_size:
|
| 51 |
+
:param alpha:
|
| 52 |
+
:return:
|
| 53 |
+
"""
|
| 54 |
+
if step > 0 and step % cfg.sample_step == 0:
|
| 55 |
+
gen = solver.gen
|
| 56 |
+
dis = solver.dis
|
| 57 |
+
local_rank = solver.local_rank
|
| 58 |
+
device = solver.device
|
| 59 |
+
|
| 60 |
+
save_dir = out_dir + '/sample_training'
|
| 61 |
+
my_pylib.mkdir(save_dir)
|
| 62 |
+
gen.eval()
|
| 63 |
+
dis.eval()
|
| 64 |
+
# gen.cpu()
|
| 65 |
+
show_batch_size = 10
|
| 66 |
+
row_idxs = list(range(show_batch_size))
|
| 67 |
+
instance_idxs = list(range(show_batch_size))
|
| 68 |
+
|
| 69 |
+
with torch.no_grad():
|
| 70 |
+
items = test_batch['items']
|
| 71 |
+
decoder_res = dis({'code': test_batch['code'].cuda()})
|
| 72 |
+
hair_noise = decoder_res['noise'].cpu()
|
| 73 |
+
test_data = {'noise': hair_noise, 'rgb_mean': test_batch['rgb_mean'],
|
| 74 |
+
'pca_std': test_batch['pca_std']}
|
| 75 |
+
if cfg.lambda_cls_curliness:
|
| 76 |
+
test_data['noise_curliness'] = decoder_res['noise_curliness'].cpu()
|
| 77 |
+
to_device(test_data, device)
|
| 78 |
+
rec_code = gen(test_data)['code']
|
| 79 |
+
|
| 80 |
+
# ----------------
|
| 81 |
+
# generate each noise dim
|
| 82 |
+
# ----------------
|
| 83 |
+
# grid_count = 10
|
| 84 |
+
# lin_space = np.linspace(-3, 3, grid_count)
|
| 85 |
+
grid_count = 6
|
| 86 |
+
lin_space = np.linspace(-2.5, 2.5, grid_count)
|
| 87 |
+
for dim_idx in range(cfg.noise_dim):
|
| 88 |
+
canvas = Canvas(len(row_idxs), grid_count + 1)
|
| 89 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 90 |
+
item = items[idx]
|
| 91 |
+
dataset_name, img_name = item.split('___')
|
| 92 |
+
# generate origin and reconstruction
|
| 93 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 94 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 95 |
+
|
| 96 |
+
canvas.process_draw_image(ori_img, draw_idx, 0)
|
| 97 |
+
|
| 98 |
+
for grid_idx in range(grid_count):
|
| 99 |
+
temp_noise = hair_noise.clone()
|
| 100 |
+
temp_noise[:, dim_idx] = lin_space[grid_idx]
|
| 101 |
+
data = copy.deepcopy(test_data)
|
| 102 |
+
data['noise'] = temp_noise
|
| 103 |
+
to_device(data, device)
|
| 104 |
+
code = gen(data)['code']
|
| 105 |
+
|
| 106 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 107 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 108 |
+
cur_code[HAIR_IDX] = code[idx].cpu().numpy()
|
| 109 |
+
item = items[idx]
|
| 110 |
+
out_img = gen_by_sean(cur_code, item)
|
| 111 |
+
out_img = tensor2numpy(out_img)
|
| 112 |
+
canvas.process_draw_image(out_img, draw_idx, grid_idx + 1)
|
| 113 |
+
if local_rank <= 0:
|
| 114 |
+
canvas.write_(os.path.join(save_dir, '%06d_noise_%02d.png' % (step, dim_idx)))
|
| 115 |
+
|
| 116 |
+
# -------------
|
| 117 |
+
# direct transfer all content
|
| 118 |
+
# -------------
|
| 119 |
+
canvas = Canvas(len(row_idxs) + 1, len(instance_idxs) + 2)
|
| 120 |
+
for draw_idx, instance_idx in enumerate(instance_idxs):
|
| 121 |
+
item = items[instance_idx]
|
| 122 |
+
dataset_name, img_name = item.split('___')
|
| 123 |
+
# generate origin and reconstruction
|
| 124 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 125 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 126 |
+
canvas.process_draw_image(ori_img, 0, draw_idx + 2)
|
| 127 |
+
|
| 128 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 129 |
+
item_row = items[idx]
|
| 130 |
+
dataset_name, img_name = item_row.split('___')
|
| 131 |
+
img_row = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 132 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 133 |
+
canvas.process_draw_image(img_row, draw_idx + 1, 0)
|
| 134 |
+
sean_code = test_batch['sean_code'][idx]
|
| 135 |
+
rec_img = tensor2numpy(gen_by_sean(sean_code, item_row))
|
| 136 |
+
canvas.process_draw_image(rec_img, draw_idx + 1, 1)
|
| 137 |
+
for draw_idx2, instance_idx in enumerate(instance_idxs):
|
| 138 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 139 |
+
cur_code[HAIR_IDX] = test_batch['sean_code'][instance_idx][HAIR_IDX]
|
| 140 |
+
res_img = gen_by_sean(cur_code, item_row)
|
| 141 |
+
res_img = tensor2numpy(res_img)
|
| 142 |
+
canvas.process_draw_image(res_img, draw_idx + 1, draw_idx2 + 2)
|
| 143 |
+
if local_rank <= 0:
|
| 144 |
+
canvas.write_(os.path.join(save_dir, 'rgb_direct.png'))
|
| 145 |
+
|
| 146 |
+
# -----------
|
| 147 |
+
# random choice
|
| 148 |
+
# -----------
|
| 149 |
+
grid_count = 10
|
| 150 |
+
# generate each noise dim
|
| 151 |
+
canvas = Canvas(len(row_idxs), grid_count + 2)
|
| 152 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 153 |
+
item = items[idx]
|
| 154 |
+
dataset_name, img_name = item.split('___')
|
| 155 |
+
# generate origin and reconstruction
|
| 156 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 157 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 158 |
+
|
| 159 |
+
canvas.process_draw_image(ori_img, draw_idx, 0)
|
| 160 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 161 |
+
cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
|
| 162 |
+
rec_img = tensor2numpy(gen_by_sean(cur_code, item))
|
| 163 |
+
canvas.process_draw_image(rec_img, draw_idx, 1)
|
| 164 |
+
|
| 165 |
+
temp_noise = generate_noise(grid_count, cfg.noise_dim)
|
| 166 |
+
for grid_idx in range(grid_count):
|
| 167 |
+
data = copy.deepcopy(test_data)
|
| 168 |
+
data['noise'] = torch.tile(temp_noise[[grid_idx]], [test_batch['rgb_mean'].shape[0], 1])
|
| 169 |
+
to_device(data, device)
|
| 170 |
+
code = gen(data)['code']
|
| 171 |
+
|
| 172 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 173 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 174 |
+
cur_code[HAIR_IDX] = code[idx].cpu().numpy()
|
| 175 |
+
item = items[idx]
|
| 176 |
+
out_img = gen_by_sean(cur_code, item)
|
| 177 |
+
out_img = tensor2numpy(out_img)
|
| 178 |
+
canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
|
| 179 |
+
|
| 180 |
+
if local_rank <= 0:
|
| 181 |
+
canvas.write_(os.path.join(save_dir, '%06d_random.png' % step))
|
| 182 |
+
|
| 183 |
+
# ------------
|
| 184 |
+
# generate curliness
|
| 185 |
+
# ------------
|
| 186 |
+
if cfg.lambda_cls_curliness:
|
| 187 |
+
grid_count = 10
|
| 188 |
+
lin_space = np.linspace(-3, 3, grid_count)
|
| 189 |
+
canvas = Canvas(len(row_idxs), grid_count + 2)
|
| 190 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 191 |
+
item = items[idx]
|
| 192 |
+
dataset_name, img_name = item.split('___')
|
| 193 |
+
# generate origin and reconstruction
|
| 194 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 195 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 196 |
+
canvas.process_draw_image(ori_img, draw_idx, 0)
|
| 197 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 198 |
+
cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
|
| 199 |
+
rec_img = tensor2numpy(gen_by_sean(cur_code, item))
|
| 200 |
+
canvas.process_draw_image(rec_img, draw_idx, 1)
|
| 201 |
+
|
| 202 |
+
for grid_idx in range(grid_count):
|
| 203 |
+
cur_noise_curliness = torch.tensor(lin_space[grid_idx]).reshape([1, 1]).tile([cfg.sample_batch_size, 1]).float()
|
| 204 |
+
data = copy.deepcopy(test_data)
|
| 205 |
+
data['noise_curliness'] = cur_noise_curliness
|
| 206 |
+
to_device(data, device)
|
| 207 |
+
code = gen(data)['code']
|
| 208 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 209 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 210 |
+
cur_code[HAIR_IDX] = code[idx].cpu().numpy()
|
| 211 |
+
item = items[idx]
|
| 212 |
+
out_img = gen_by_sean(cur_code, item)
|
| 213 |
+
out_img = tensor2numpy(out_img)
|
| 214 |
+
canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
|
| 215 |
+
if local_rank <= 0:
|
| 216 |
+
canvas.write_(os.path.join(save_dir, '%06d_curliness.png' % step))
|
| 217 |
+
|
| 218 |
+
# ------------
|
| 219 |
+
# generate variance
|
| 220 |
+
# ------------
|
| 221 |
+
if cfg.lambda_pca_std:
|
| 222 |
+
grid_count = 10
|
| 223 |
+
lin_space = np.linspace(10, 150, grid_count)
|
| 224 |
+
canvas = Canvas(len(row_idxs), grid_count + 2)
|
| 225 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 226 |
+
item = items[idx]
|
| 227 |
+
dataset_name, img_name = item.split('___')
|
| 228 |
+
# generate origin and reconstruction
|
| 229 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 230 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 231 |
+
canvas.process_draw_image(ori_img, draw_idx, 0)
|
| 232 |
+
|
| 233 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 234 |
+
cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
|
| 235 |
+
rec_img = tensor2numpy(gen_by_sean(cur_code, item))
|
| 236 |
+
canvas.process_draw_image(rec_img, draw_idx, 1)
|
| 237 |
+
|
| 238 |
+
for grid_idx in range(grid_count):
|
| 239 |
+
cur_pca_std = torch.tensor(lin_space[grid_idx]).reshape([1, 1]).tile([cfg.sample_batch_size, 1]).float()
|
| 240 |
+
data = copy.deepcopy(test_data)
|
| 241 |
+
data['pca_std'] = cur_pca_std
|
| 242 |
+
to_device(data, device)
|
| 243 |
+
code = gen(data)['code']
|
| 244 |
+
|
| 245 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 246 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 247 |
+
cur_code[HAIR_IDX] = code[idx].cpu().numpy()
|
| 248 |
+
item = items[idx]
|
| 249 |
+
out_img = gen_by_sean(cur_code, item)
|
| 250 |
+
out_img = tensor2numpy(out_img)
|
| 251 |
+
canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
|
| 252 |
+
if local_rank <= 0:
|
| 253 |
+
canvas.write_(os.path.join(save_dir, '%06d_variance.png' % step))
|
| 254 |
+
|
| 255 |
+
# -------------
|
| 256 |
+
# generate each rgb
|
| 257 |
+
# -------------
|
| 258 |
+
canvas = Canvas(len(row_idxs) + 1, len(instance_idxs) + 1)
|
| 259 |
+
for draw_idx, instance_idx in enumerate(instance_idxs):
|
| 260 |
+
item = items[instance_idx]
|
| 261 |
+
dataset_name, img_name = item.split('___')
|
| 262 |
+
# generate origin and reconstruction
|
| 263 |
+
ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 264 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 265 |
+
ori_img[5:45, 5:45, :] = test_batch['rgb_mean'][instance_idx].cpu().numpy()
|
| 266 |
+
canvas.process_draw_image(ori_img, 0, draw_idx + 1)
|
| 267 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 268 |
+
item_row = items[idx]
|
| 269 |
+
dataset_name, img_name = item_row.split('___')
|
| 270 |
+
img_row = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
|
| 271 |
+
(dataset_name, img_name)), cv2.COLOR_BGR2RGB)
|
| 272 |
+
canvas.process_draw_image(img_row, draw_idx + 1, 0)
|
| 273 |
+
for draw_idx2, instance_idx in enumerate(instance_idxs):
|
| 274 |
+
color = test_batch['rgb_mean'][[instance_idx]]
|
| 275 |
+
data = copy.deepcopy(test_data)
|
| 276 |
+
data['rgb_mean'] = torch.tile(color, [cfg.sample_batch_size, 1])
|
| 277 |
+
data['pca_std'] = torch.tile(test_batch['pca_std'][[instance_idx]], [cfg.sample_batch_size, 1])
|
| 278 |
+
to_device(data, device)
|
| 279 |
+
hair_code = gen(data)['code']
|
| 280 |
+
for draw_idx, idx in enumerate(row_idxs):
|
| 281 |
+
item_row = items[idx]
|
| 282 |
+
cur_code = test_batch['sean_code'][idx].copy()
|
| 283 |
+
cur_code[HAIR_IDX] = hair_code[idx].cpu().numpy()
|
| 284 |
+
res_img = gen_by_sean(cur_code, item_row)
|
| 285 |
+
res_img = tensor2numpy(res_img)
|
| 286 |
+
canvas.process_draw_image(res_img, draw_idx + 1, draw_idx2 + 1)
|
| 287 |
+
if local_rank <= 0:
|
| 288 |
+
canvas.write_(os.path.join(save_dir, '%06d_rgb.png' % step))
|
| 289 |
+
|
| 290 |
+
gen.train()
|
| 291 |
+
dis.train()
|
| 292 |
+
if local_rank >= 0:
|
| 293 |
+
dist.barrier()
|
| 294 |
+
|
| 295 |
+
if step > 0 and step % cfg.model_save_step == 0:
|
| 296 |
+
if local_rank <= 0:
|
| 297 |
+
save_model(step, solver, ckpt_dir)
|
| 298 |
+
if local_rank >= 0:
|
| 299 |
+
dist.barrier()
|
models/CtrlHair/common_dataset.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
# File name: common_dataset.py
|
| 5 |
+
# Time : 2021/12/31 19:19
|
| 6 |
+
# Author: xyguoo@163.com
|
| 7 |
+
# Description:
|
| 8 |
+
"""
|
| 9 |
+
import os
|
| 10 |
+
import random
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import pandas as pd
|
| 14 |
+
|
| 15 |
+
from global_value_utils import GLOBAL_DATA_ROOT, HAIR_IDX, HAT_IDX, DATASET_NAME
|
| 16 |
+
from util.util import path_join_abs
|
| 17 |
+
import cv2
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class DataFilter:
|
| 21 |
+
def __init__(self, cfg=None, test_part=0.096):
|
| 22 |
+
# cfg
|
| 23 |
+
if cfg is None:
|
| 24 |
+
from color_texture_branch.config import cfg
|
| 25 |
+
self.cfg = cfg
|
| 26 |
+
|
| 27 |
+
base_dataset_dir = GLOBAL_DATA_ROOT
|
| 28 |
+
|
| 29 |
+
dataset_dir = [os.path.join(base_dataset_dir, dn) for dn in DATASET_NAME]
|
| 30 |
+
|
| 31 |
+
self.data_dirs = dataset_dir
|
| 32 |
+
|
| 33 |
+
self.random_seed = 7
|
| 34 |
+
random.seed(self.random_seed)
|
| 35 |
+
|
| 36 |
+
####################################################################
|
| 37 |
+
# Please modify these if you don't want to use these filters
|
| 38 |
+
angle_filter = True
|
| 39 |
+
gender_filter = True
|
| 40 |
+
gender = ['female']
|
| 41 |
+
# gender = ['male', 'female']
|
| 42 |
+
gender = set([{'male': 1, 'female': -1}[g] for g in gender])
|
| 43 |
+
####################################################################
|
| 44 |
+
|
| 45 |
+
self.total_list = []
|
| 46 |
+
for data_dir in self.data_dirs:
|
| 47 |
+
img_dir = os.path.join(data_dir, 'images_256')
|
| 48 |
+
|
| 49 |
+
if angle_filter:
|
| 50 |
+
angle_csv = pd.read_csv(os.path.join(data_dir, 'angle.csv'), index_col=0)
|
| 51 |
+
angle_filter_imgs = list(angle_csv.index[angle_csv['angle'] < 5])
|
| 52 |
+
cur_list = ['%05d.png' % dd for dd in angle_filter_imgs]
|
| 53 |
+
else:
|
| 54 |
+
cur_list = os.listdir(img_dir)
|
| 55 |
+
|
| 56 |
+
if gender_filter:
|
| 57 |
+
attr_filter = pd.read_csv(os.path.join(data_dir, 'attr_gender.csv'))
|
| 58 |
+
cur_list = [p for p in cur_list if attr_filter.Male[int(p[:-4])] in gender]
|
| 59 |
+
|
| 60 |
+
self.total_list += [os.path.join(img_dir, p) for p in cur_list]
|
| 61 |
+
|
| 62 |
+
random.shuffle(self.total_list)
|
| 63 |
+
self.test_start = int(len(self.total_list) * (1 - test_part))
|
| 64 |
+
self.test_list = self.total_list[self.test_start:]
|
| 65 |
+
self.train_list = [st for st in self.total_list if st not in self.test_list]
|
| 66 |
+
|
| 67 |
+
idx = 0
|
| 68 |
+
# make sure the area of hair is big enough
|
| 69 |
+
self.hair_region_threshold = 0.07
|
| 70 |
+
self.test_face_list = []
|
| 71 |
+
while len(self.test_face_list) < cfg.sample_batch_size:
|
| 72 |
+
test_file = self.test_list[idx]
|
| 73 |
+
if self.valid_face(path_join_abs(test_file, '../..'), test_file[-9:-4]):
|
| 74 |
+
self.test_face_list.append(test_file)
|
| 75 |
+
idx += 1
|
| 76 |
+
|
| 77 |
+
self.test_hair_list = []
|
| 78 |
+
while len(self.test_hair_list) < cfg.sample_batch_size:
|
| 79 |
+
test_file = self.test_list[idx]
|
| 80 |
+
if self.valid_hair(path_join_abs(test_file, '../..'), test_file[-9:-4]):
|
| 81 |
+
self.test_hair_list.append(test_file)
|
| 82 |
+
idx += 1
|
| 83 |
+
|
| 84 |
+
def valid_face(self, data_dir, img_idx_str):
|
| 85 |
+
label_path = os.path.join(data_dir, 'label', img_idx_str + '.png')
|
| 86 |
+
label_img = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
|
| 87 |
+
hat_region = label_img == HAT_IDX
|
| 88 |
+
|
| 89 |
+
if hat_region.mean() > 0.03:
|
| 90 |
+
return False
|
| 91 |
+
return True
|
| 92 |
+
|
| 93 |
+
def valid_hair(self, data_dir, img_idx_str):
|
| 94 |
+
label_path = os.path.join(data_dir, 'label', img_idx_str + '.png')
|
| 95 |
+
label_img = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
|
| 96 |
+
hair_region = label_img == HAIR_IDX
|
| 97 |
+
hat_region = label_img == HAT_IDX
|
| 98 |
+
|
| 99 |
+
if hat_region.mean() > 0.03:
|
| 100 |
+
return False
|
| 101 |
+
if hair_region.mean() < self.hair_region_threshold:
|
| 102 |
+
return False
|
| 103 |
+
return True
|
| 104 |
+
|