diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..f7535c13a2ef8123341f1f697fc50dbca8cafbe4
Binary files /dev/null and b/.DS_Store differ
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..6b1e3dba671318e3576aea1ef913a5ca3180ed96
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2024 AIRI - Artificial Intelligence Research Institute
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b92342ea91e82d3d812b5dba0d47eb1da42b70a0
--- /dev/null
+++ b/README.md
@@ -0,0 +1,169 @@
+# HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach
+
+ +
+ +
+ +[](./LICENSE)
+
+
+> Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100.
+>
+
+
+[](./LICENSE)
+
+
+> Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100.
+>
+
+
+  +
+
+The proposed HairFast framework allows to edit a hairstyle on an arbitrary photo based on an example from other photos. Here we have an example of how the method works by transferring a hairstyle from one photo and a hair color from another.
+
+
+## Updates
+
+- [25/09/2024] 🎉🎉🎉 HairFastGAN has been accepted by [NeurIPS 2024](https://nips.cc/virtual/2024/poster/93397).
+- [24/05/2024] 🌟🌟🌟 Release of the [official demo](https://huggingface.co/spaces/AIRI-Institute/HairFastGAN) on Hugging Face 🤗.
+- [01/04/2024] 🔥🔥🔥 HairFastGAN release.
+
+## Prerequisites
+You need following hardware and python version to run our method.
+- Linux
+- NVIDIA GPU + CUDA CuDNN
+- Python 3.10
+- PyTorch 1.13.1+
+
+## Installation
+
+* Clone this repo:
+```bash
+git clone https://github.com/AIRI-Institute/HairFastGAN
+cd HairFastGAN
+```
+
+* Download all pretrained models:
+```bash
+git clone https://huggingface.co/AIRI-Institute/HairFastGAN
+cd HairFastGAN && git lfs pull && cd ..
+mv HairFastGAN/pretrained_models pretrained_models
+mv HairFastGAN/input input
+rm -rf HairFastGAN
+```
+
+* Setting the environment
+
+**Option 1 [recommended]**, install [Poetry](https://python-poetry.org/docs/) and then:
+```bash
+poetry install
+```
+
+**Option 2**, just install the dependencies in your environment:
+```bash
+pip install -r requirements.txt
+```
+
+## Inference
+You can use `main.py` to run the method, either for a single run or for a batch of experiments.
+
+* An example of running a single experiment:
+
+```
+python main.py --face_path=6.png --shape_path=7.png --color_path=8.png \
+ --input_dir=input --result_path=output/result.png
+```
+
+* To run the batch version, first create an image triples file (face/shape/color):
+```
+cat > example.txt << EOF
+6.png 7.png 8.png
+8.png 4.jpg 5.jpg
+EOF
+```
+
+And now you can run the method:
+```
+python main.py --file_path=example.txt --input_dir=input --output_dir=output
+```
+
+* You can use HairFast in the code directly:
+
+```python
+from hair_swap import HairFast, get_parser
+
+# Init HairFast
+hair_fast = HairFast(get_parser().parse_args([]))
+
+# Inference
+result = hair_fast(face_img, shape_img, color_img)
+```
+
+See the code for input parameters and output formats.
+
+* Alternatively, you can use our [Colab Notebook](https://colab.research.google.com/#fileId=https://huggingface.co/AIRI-Institute/HairFastGAN/blob/main/notebooks/HairFast_inference.ipynb) to prepare the environment, download the code, pretrained weights, and allow you to run experiments with a convenient form.
+
+* You can also try our method on the [Hugging Face demo](https://huggingface.co/spaces/AIRI-Institute/HairFastGAN) 🤗.
+
+## Scripts
+
+There is a list of scripts below, see arguments via --help for details.
+
+| Path | Description ![]() +|:----------------------------------------| :---
+| scripts/align_face.py | Processing of raw photos for inference
+| scripts/fid_metric.py | Metrics calculation
+| scripts/rotate_gen.py | Dataset generation for rotate encoder training
+| scripts/blending_gen.py | Dataset generation for color encoder training
+| scripts/pp_gen.py | Dataset generation for refinement encoder training
+| scripts/rotate_train.py | Rotate encoder training
+| scripts/blending_train.py | Color encoder training
+| scripts/pp_train.py | Refinement encoder training
+
+
+## Training
+For training, you need to generate a dataset and then run the scripts for training. See the scripts section above.
+
+We use [Weights & Biases](https://wandb.ai/home) to track experiments. Before training, you should put your W&B API key into the `WANDB_KEY` environment variable.
+
+## Method diagram
+
+
+|:----------------------------------------| :---
+| scripts/align_face.py | Processing of raw photos for inference
+| scripts/fid_metric.py | Metrics calculation
+| scripts/rotate_gen.py | Dataset generation for rotate encoder training
+| scripts/blending_gen.py | Dataset generation for color encoder training
+| scripts/pp_gen.py | Dataset generation for refinement encoder training
+| scripts/rotate_train.py | Rotate encoder training
+| scripts/blending_train.py | Color encoder training
+| scripts/pp_train.py | Refinement encoder training
+
+
+## Training
+For training, you need to generate a dataset and then run the scripts for training. See the scripts section above.
+
+We use [Weights & Biases](https://wandb.ai/home) to track experiments. Before training, you should put your W&B API key into the `WANDB_KEY` environment variable.
+
+## Method diagram
+
+
+  +
+
+Overview of HairFast: the images first pass through the Pose alignment module, which generates a pose-aligned face mask with the desired hair shape. Then we transfer the desired hairstyle shape using Shape alignment and the desired hair color using Color alignment. In the last step, Refinement alignment returns the lost details of the original image where they are needed.
+
+
+## Repository structure
+
+ .
+ ├── 📂 datasets # Implementation of torch datasets for inference
+ ├── 📂 docs # Folder with method diagram and teaser
+ ├── 📂 models # Folder containting all the models
+ │ ├── ...
+ │ ├── 📄 Embedding.py # Implementation of Embedding module
+ │ ├── 📄 Alignment.py # Implementation of Pose and Shape alignment modules
+ │ ├── 📄 Blending.py # Implementation of Color and Refinement alignment modules
+ │ ├── 📄 Encoders.py # Implementation of encoder architectures
+ │ └── 📄 Net.py # Implementation of basic models
+ │
+ ├── 📂 losses # Folder containing various loss criterias for training
+ ├── 📂 scripts # Folder with various scripts
+ ├── 📂 utils # Folder with utility functions
+ │
+ ├── 📜 poetry.lock # Records exact dependency versions.
+ ├── 📜 pyproject.toml # Poetry configuration for dependencies.
+ ├── 📜 requirements.txt # Lists required Python packages.
+ ├── 📄 hair_swap.py # Implementation of the HairFast main class
+ └── 📄 main.py # Script for inference
+
+## References & Acknowledgments
+
+The repository was started from [Barbershop](https://github.com/ZPdesu/Barbershop).
+
+The code [CtrlHair](https://github.com/XuyangGuo/CtrlHair), [SEAN](https://github.com/ZPdesu/SEAN), [HairCLIP](https://github.com/wty-ustc/HairCLIP), [FSE](https://github.com/InterDigitalInc/FeatureStyleEncoder), [E4E](https://github.com/omertov/encoder4editing) and [STAR](https://github.com/ZhenglinZhou/STAR) was also used.
+
+## Citation
+
+If you use this code for your research, please cite our paper:
+```
+@article{nikolaev2024hairfastgan,
+ title={HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach},
+ author={Nikolaev, Maxim and Kuznetsov, Mikhail and Vetrov, Dmitry and Alanov, Aibek},
+ journal={arXiv preprint arXiv:2404.01094},
+ year={2024}
+}
+```
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/datasets/__init__.py b/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/datasets/image_dataset.py b/datasets/image_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e56368ac37ba10cb1a29b5172699589035fd22d
--- /dev/null
+++ b/datasets/image_dataset.py
@@ -0,0 +1,29 @@
+import torch
+from torch.utils.data import Dataset
+
+
+class ImagesDataset(Dataset):
+ def __init__(self, images: dict[torch.Tensor, list[str]] | list[torch.Tensor]):
+ if isinstance(images, list):
+ images = dict.fromkeys(images)
+
+ self.images = list(images)
+ self.names = list(images.values())
+
+ def __len__(self):
+ return len(self.images)
+
+ def __getitem__(self, index):
+ image = self.images[index]
+
+ if image.dtype is torch.uint8:
+ image = image / 255
+
+ names = self.names[index]
+ return image, names
+
+
+def image_collate(batch):
+ images = torch.stack([item[0] for item in batch])
+ names = [item[1] for item in batch]
+ return images, names
diff --git a/docs/assets/diagram.webp b/docs/assets/diagram.webp
new file mode 100644
index 0000000000000000000000000000000000000000..84275e3a2b7ab57c8b83139d9245194aab07219b
--- /dev/null
+++ b/docs/assets/diagram.webp
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:82e7fce0312bcc7931243fb1d834539bc9d24bbd07a87135d89974987b217882
+size 742106
diff --git a/docs/assets/logo.webp b/docs/assets/logo.webp
new file mode 100644
index 0000000000000000000000000000000000000000..e0c09a628ed9e6d650287c68468d7a044d85e046
--- /dev/null
+++ b/docs/assets/logo.webp
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3262e841eadcdd85ccdb9519e6ac7cf0f486857fc32a5bd59eb363594ad2b66d
+size 426760
diff --git a/hair_swap.py b/hair_swap.py
new file mode 100644
index 0000000000000000000000000000000000000000..18e044919d4ade45f9b6b621756ab0da3b2e57b9
--- /dev/null
+++ b/hair_swap.py
@@ -0,0 +1,139 @@
+import argparse
+import typing as tp
+from collections import defaultdict
+from functools import wraps
+from pathlib import Path
+
+import numpy as np
+import torch
+import torchvision.transforms.functional as F
+from PIL import Image
+from torchvision.io import read_image, ImageReadMode
+
+from models.Alignment import Alignment
+from models.Blending import Blending
+from models.Embedding import Embedding
+from models.Net import Net
+from utils.image_utils import equal_replacer
+from utils.seed import seed_setter
+from utils.shape_predictor import align_face
+from utils.time import bench_session
+
+TImage = tp.TypeVar('TImage', torch.Tensor, Image.Image, np.ndarray)
+TPath = tp.TypeVar('TPath', Path, str)
+TReturn = tp.TypeVar('TReturn', torch.Tensor, tuple[torch.Tensor, ...])
+
+
+class HairFast:
+ """
+ HairFast implementation with hairstyle transfer interface
+ """
+
+ def __init__(self, args):
+ self.args = args
+ self.net = Net(self.args)
+ self.embed = Embedding(args, net=self.net)
+ self.align = Alignment(args, self.embed.get_e4e_embed, net=self.net)
+ self.blend = Blending(args, net=self.net)
+
+ @seed_setter
+ @bench_session
+ def __swap_from_tensors(self, face: torch.Tensor, shape: torch.Tensor, color: torch.Tensor,
+ **kwargs) -> torch.Tensor:
+ images_to_name = defaultdict(list)
+ for image, name in zip((face, shape, color), ('face', 'shape', 'color')):
+ images_to_name[image].append(name)
+
+ # Embedding stage
+ name_to_embed = self.embed.embedding_images(images_to_name, **kwargs)
+
+ # Alignment stage
+ align_shape = self.align.align_images('face', 'shape', name_to_embed, **kwargs)
+
+ # Shape Module stage for blending
+ if shape is not color:
+ align_color = self.align.shape_module('face', 'color', name_to_embed, **kwargs)
+ else:
+ align_color = align_shape
+
+ # Blending and Post Process stage
+ final_image = self.blend.blend_images(align_shape, align_color, name_to_embed, **kwargs)
+ return final_image
+
+ def swap(self, face_img: TImage | TPath, shape_img: TImage | TPath, color_img: TImage | TPath,
+ benchmark=False, align=False, seed=None, exp_name=None, **kwargs) -> TReturn:
+ """
+ Run HairFast on the input images to transfer hair shape and color to the desired images.
+ :param face_img: face image in Tensor, PIL Image, array or file path format
+ :param shape_img: shape image in Tensor, PIL Image, array or file path format
+ :param color_img: color image in Tensor, PIL Image, array or file path format
+ :param benchmark: starts counting the speed of the session
+ :param align: for arbitrary photos crops images to faces
+ :param seed: fixes seed for reproducibility, default 3407
+ :param exp_name: used as a folder name when 'save_all' model is enabled
+ :return: returns the final image as a Tensor
+ """
+ images: list[torch.Tensor] = []
+ path_to_images: dict[TPath, torch.Tensor] = {}
+
+ for img in (face_img, shape_img, color_img):
+ if isinstance(img, (torch.Tensor, Image.Image, np.ndarray)):
+ if not isinstance(img, torch.Tensor):
+ img = F.to_tensor(img)
+ elif isinstance(img, (Path, str)):
+ path_img = img
+ if path_img not in path_to_images:
+ path_to_images[path_img] = read_image(str(path_img), mode=ImageReadMode.RGB)
+ img = path_to_images[path_img]
+ else:
+ raise TypeError(f'Unsupported image format {type(img)}')
+
+ images.append(img)
+
+ if align:
+ images = align_face(images)
+ images = equal_replacer(images)
+
+ final_image = self.__swap_from_tensors(*images, seed=seed, benchmark=benchmark, exp_name=exp_name, **kwargs)
+
+ if align:
+ return final_image, *images
+ return final_image
+
+ @wraps(swap)
+ def __call__(self, *args, **kwargs):
+ return self.swap(*args, **kwargs)
+
+
+def get_parser():
+ parser = argparse.ArgumentParser(description='HairFast')
+
+ # I/O arguments
+ parser.add_argument('--save_all_dir', type=Path, default=Path('output'),
+ help='the directory to save the latent codes and inversion images')
+
+ # StyleGAN2 setting
+ parser.add_argument('--size', type=int, default=1024)
+ parser.add_argument('--ckpt', type=str, default="pretrained_models/StyleGAN/ffhq.pt")
+ parser.add_argument('--channel_multiplier', type=int, default=2)
+ parser.add_argument('--latent', type=int, default=512)
+ parser.add_argument('--n_mlp', type=int, default=8)
+
+ # Arguments
+ parser.add_argument('--device', type=str, default='cuda')
+ parser.add_argument('--batch_size', type=int, default=3, help='batch size for encoding images')
+ parser.add_argument('--save_all', action='store_true', help='save and print mode information')
+
+ # HairFast setting
+ parser.add_argument('--mixing', type=float, default=0.95, help='hair blending in alignment')
+ parser.add_argument('--smooth', type=int, default=5, help='dilation and erosion parameter')
+ parser.add_argument('--rotate_checkpoint', type=str, default='pretrained_models/Rotate/rotate_best.pth')
+ parser.add_argument('--blending_checkpoint', type=str, default='pretrained_models/Blending/checkpoint.pth')
+ parser.add_argument('--pp_checkpoint', type=str, default='pretrained_models/PostProcess/pp_model.pth')
+ return parser
+
+
+if __name__ == '__main__':
+ model_args = get_parser()
+ args = model_args.parse_args()
+ hair_fast = HairFast(args)
diff --git a/inference_server.py b/inference_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f35d3c0d64915d9cd8f8a3db3322610192d4d5b
--- /dev/null
+++ b/inference_server.py
@@ -0,0 +1,5 @@
+if __name__ == "__main__":
+ server = grpc.server(...)
+ ...
+ server.start()
+ server.wait_for_termination()
diff --git a/losses/.DS_Store b/losses/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..924c6ff93402ee0e429fcc6d9e7f887b7cfee310
Binary files /dev/null and b/losses/.DS_Store differ
diff --git a/losses/__init__.py b/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/losses/lpips/__init__.py b/losses/lpips/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2dd73e7b248bd9bbc814df6210f14f95fc5045ae
--- /dev/null
+++ b/losses/lpips/__init__.py
@@ -0,0 +1,160 @@
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import numpy as np
+from skimage.metrics import structural_similarity
+import torch
+from torch.autograd import Variable
+
+from ..lpips import dist_model
+
+class PerceptualLoss(torch.nn.Module):
+ def __init__(self, model='net-lin', net='alex', colorspace='rgb', spatial=False, use_gpu=True, gpu_ids=[0]): # VGG using our perceptually-learned weights (LPIPS metric)
+ # def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
+ super(PerceptualLoss, self).__init__()
+ print('Setting up Perceptual loss...')
+ self.use_gpu = use_gpu
+ self.spatial = spatial
+ self.gpu_ids = gpu_ids
+ self.model = dist_model.DistModel()
+ self.model.initialize(model=model, net=net, use_gpu=use_gpu, colorspace=colorspace, spatial=self.spatial, gpu_ids=gpu_ids)
+ print('...[%s] initialized'%self.model.name())
+ print('...Done')
+
+ def forward(self, pred, target, normalize=False):
+ """
+ Pred and target are Variables.
+ If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
+ If normalize is False, assumes the images are already between [-1,+1]
+
+ Inputs pred and target are Nx3xHxW
+ Output pytorch Variable N long
+ """
+
+ if normalize:
+ target = 2 * target - 1
+ pred = 2 * pred - 1
+
+ return self.model.forward(target, pred)
+
+def normalize_tensor(in_feat,eps=1e-10):
+ norm_factor = torch.sqrt(torch.sum(in_feat**2,dim=1,keepdim=True))
+ return in_feat/(norm_factor+eps)
+
+def l2(p0, p1, range=255.):
+ return .5*np.mean((p0 / range - p1 / range)**2)
+
+def psnr(p0, p1, peak=255.):
+ return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
+
+def dssim(p0, p1, range=255.):
+ return (1 - structural_similarity(p0, p1, data_range=range, multichannel=True)) / 2.
+
+def rgb2lab(in_img,mean_cent=False):
+ from skimage import color
+ img_lab = color.rgb2lab(in_img)
+ if(mean_cent):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ return img_lab
+
+def tensor2np(tensor_obj):
+ # change dimension of a tensor object into a numpy array
+ return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
+
+def np2tensor(np_obj):
+ # change dimenion of np array into tensor array
+ return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
+
+def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
+ # image tensor to lab tensor
+ from skimage import color
+
+ img = tensor2im(image_tensor)
+ img_lab = color.rgb2lab(img)
+ if(mc_only):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ if(to_norm and not mc_only):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ img_lab = img_lab/100.
+
+ return np2tensor(img_lab)
+
+def tensorlab2tensor(lab_tensor,return_inbnd=False):
+ from skimage import color
+ import warnings
+ warnings.filterwarnings("ignore")
+
+ lab = tensor2np(lab_tensor)*100.
+ lab[:,:,0] = lab[:,:,0]+50
+
+ rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
+ if(return_inbnd):
+ # convert back to lab, see if we match
+ lab_back = color.rgb2lab(rgb_back.astype('uint8'))
+ mask = 1.*np.isclose(lab_back,lab,atol=2.)
+ mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
+ return (im2tensor(rgb_back),mask)
+ else:
+ return im2tensor(rgb_back)
+
+def rgb2lab(input):
+ from skimage import color
+ return color.rgb2lab(input / 255.)
+
+def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
+ image_numpy = image_tensor[0].cpu().float().numpy()
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
+ return image_numpy.astype(imtype)
+
+def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
+ return torch.Tensor((image / factor - cent)
+ [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
+
+def tensor2vec(vector_tensor):
+ return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
+
+def voc_ap(rec, prec, use_07_metric=False):
+ """ ap = voc_ap(rec, prec, [use_07_metric])
+ Compute VOC AP given precision and recall.
+ If use_07_metric is true, uses the
+ VOC 07 11 point method (default:False).
+ """
+ if use_07_metric:
+ # 11 point metric
+ ap = 0.
+ for t in np.arange(0., 1.1, 0.1):
+ if np.sum(rec >= t) == 0:
+ p = 0
+ else:
+ p = np.max(prec[rec >= t])
+ ap = ap + p / 11.
+ else:
+ # correct AP calculation
+ # first append sentinel values at the end
+ mrec = np.concatenate(([0.], rec, [1.]))
+ mpre = np.concatenate(([0.], prec, [0.]))
+
+ # compute the precision envelope
+ for i in range(mpre.size - 1, 0, -1):
+ mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
+
+ # to calculate area under PR curve, look for points
+ # where X axis (recall) changes value
+ i = np.where(mrec[1:] != mrec[:-1])[0]
+
+ # and sum (\Delta recall) * prec
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
+ return ap
+
+def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
+# def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
+ image_numpy = image_tensor[0].cpu().float().numpy()
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
+ return image_numpy.astype(imtype)
+
+def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
+# def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
+ return torch.Tensor((image / factor - cent)
+ [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
diff --git a/losses/lpips/base_model.py b/losses/lpips/base_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..8de1d16f0c7fa52d8067139abc6e769e96d0a6a1
--- /dev/null
+++ b/losses/lpips/base_model.py
@@ -0,0 +1,58 @@
+import os
+import numpy as np
+import torch
+from torch.autograd import Variable
+from pdb import set_trace as st
+from IPython import embed
+
+class BaseModel():
+ def __init__(self):
+ pass;
+
+ def name(self):
+ return 'BaseModel'
+
+ def initialize(self, use_gpu=True, gpu_ids=[0]):
+ self.use_gpu = use_gpu
+ self.gpu_ids = gpu_ids
+
+ def forward(self):
+ pass
+
+ def get_image_paths(self):
+ pass
+
+ def optimize_parameters(self):
+ pass
+
+ def get_current_visuals(self):
+ return self.input
+
+ def get_current_errors(self):
+ return {}
+
+ def save(self, label):
+ pass
+
+ # helper saving function that can be used by subclasses
+ def save_network(self, network, path, network_label, epoch_label):
+ save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
+ save_path = os.path.join(path, save_filename)
+ torch.save(network.state_dict(), save_path)
+
+ # helper loading function that can be used by subclasses
+ def load_network(self, network, network_label, epoch_label):
+ save_filename = '%s_net_%s.pth' % (epoch_label, network_label)
+ save_path = os.path.join(self.save_dir, save_filename)
+ print('Loading network from %s'%save_path)
+ network.load_state_dict(torch.load(save_path))
+
+ def update_learning_rate():
+ pass
+
+ def get_image_paths(self):
+ return self.image_paths
+
+ def save_done(self, flag=False):
+ np.save(os.path.join(self.save_dir, 'done_flag'),flag)
+ np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
diff --git a/losses/lpips/dist_model.py b/losses/lpips/dist_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c69380084f412a7f8d3d4e64466d251c4e6f19e
--- /dev/null
+++ b/losses/lpips/dist_model.py
@@ -0,0 +1,284 @@
+
+from __future__ import absolute_import
+
+import sys
+import numpy as np
+import torch
+from torch import nn
+import os
+from collections import OrderedDict
+from torch.autograd import Variable
+import itertools
+from .base_model import BaseModel
+from scipy.ndimage import zoom
+import fractions
+import functools
+import skimage.transform
+from tqdm import tqdm
+
+from IPython import embed
+
+from . import networks_basic as networks
+from losses import lpips as util
+
+class DistModel(BaseModel):
+ def name(self):
+ return self.model_name
+
+ def initialize(self, model='net-lin', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
+ use_gpu=True, printNet=False, spatial=False,
+ is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
+ '''
+ INPUTS
+ model - ['net-lin'] for linearly calibrated network
+ ['net'] for off-the-shelf network
+ ['L2'] for L2 distance in Lab colorspace
+ ['SSIM'] for ssim in RGB colorspace
+ net - ['squeeze','alex','vgg']
+ model_path - if None, will look in weights/[NET_NAME].pth
+ colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
+ use_gpu - bool - whether or not to use a GPU
+ printNet - bool - whether or not to print network architecture out
+ spatial - bool - whether to output an array containing varying distances across spatial dimensions
+ spatial_shape - if given, output spatial shape. if None then spatial shape is determined automatically via spatial_factor (see below).
+ spatial_factor - if given, specifies upsampling factor relative to the largest spatial extent of a convolutional layer. if None then resized to size of input images.
+ spatial_order - spline order of filter for upsampling in spatial mode, by default 1 (bilinear).
+ is_train - bool - [True] for training mode
+ lr - float - initial learning rate
+ beta1 - float - initial momentum term for adam
+ version - 0.1 for latest, 0.0 was original (with a bug)
+ gpu_ids - int array - [0] by default, gpus to use
+ '''
+ BaseModel.initialize(self, use_gpu=use_gpu, gpu_ids=gpu_ids)
+
+ self.model = model
+ self.net = net
+ self.is_train = is_train
+ self.spatial = spatial
+ self.gpu_ids = gpu_ids
+ self.model_name = '%s [%s]'%(model,net)
+
+ if(self.model == 'net-lin'): # pretrained net + linear layer
+ self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_tune=pnet_tune, pnet_type=net,
+ use_dropout=True, spatial=spatial, version=version, lpips=True)
+ kw = {}
+ if not use_gpu:
+ kw['map_location'] = 'cpu'
+ if(model_path is None):
+ import inspect
+ model_path = os.path.abspath(os.path.join(inspect.getfile(self.initialize), '..', 'weights/v%s/%s.pth'%(version,net)))
+
+ if(not is_train):
+ print('Loading model from: %s'%model_path)
+ self.net.load_state_dict(torch.load(model_path, **kw), strict=False)
+
+ elif(self.model=='net'): # pretrained network
+ self.net = networks.PNetLin(pnet_rand=pnet_rand, pnet_type=net, lpips=False)
+ elif(self.model in ['L2','l2']):
+ self.net = networks.L2(use_gpu=use_gpu,colorspace=colorspace) # not really a network, only for testing
+ self.model_name = 'L2'
+ elif(self.model in ['DSSIM','dssim','SSIM','ssim']):
+ self.net = networks.DSSIM(use_gpu=use_gpu,colorspace=colorspace)
+ self.model_name = 'SSIM'
+ else:
+ raise ValueError("Model [%s] not recognized." % self.model)
+
+ self.parameters = list(self.net.parameters())
+
+ if self.is_train: # training mode
+ # extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
+ self.rankLoss = networks.BCERankingLoss()
+ self.parameters += list(self.rankLoss.net.parameters())
+ self.lr = lr
+ self.old_lr = lr
+ self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
+ else: # test mode
+ self.net.eval()
+
+ if(use_gpu):
+ self.net.to(gpu_ids[0])
+ self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
+ if(self.is_train):
+ self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
+
+ if(printNet):
+ print('---------- Networks initialized -------------')
+ networks.print_network(self.net)
+ print('-----------------------------------------------')
+
+ def forward(self, in0, in1, retPerLayer=False):
+ ''' Function computes the distance between image patches in0 and in1
+ INPUTS
+ in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
+ OUTPUT
+ computed distances between in0 and in1
+ '''
+
+ return self.net.forward(in0, in1, retPerLayer=retPerLayer)
+
+ # ***** TRAINING FUNCTIONS *****
+ def optimize_parameters(self):
+ self.forward_train()
+ self.optimizer_net.zero_grad()
+ self.backward_train()
+ self.optimizer_net.step()
+ self.clamp_weights()
+
+ def clamp_weights(self):
+ for module in self.net.modules():
+ if(hasattr(module, 'weight') and module.kernel_size==(1,1)):
+ module.weight.data = torch.clamp(module.weight.data,min=0)
+
+ def set_input(self, data):
+ self.input_ref = data['ref']
+ self.input_p0 = data['p0']
+ self.input_p1 = data['p1']
+ self.input_judge = data['judge']
+
+ if(self.use_gpu):
+ self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
+ self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
+ self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
+ self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
+
+ self.var_ref = Variable(self.input_ref,requires_grad=True)
+ self.var_p0 = Variable(self.input_p0,requires_grad=True)
+ self.var_p1 = Variable(self.input_p1,requires_grad=True)
+
+ def forward_train(self): # run forward pass
+ # print(self.net.module.scaling_layer.shift)
+ # print(torch.norm(self.net.module.net.slice1[0].weight).item(), torch.norm(self.net.module.lin0.model[1].weight).item())
+
+ self.d0 = self.forward(self.var_ref, self.var_p0)
+ self.d1 = self.forward(self.var_ref, self.var_p1)
+ self.acc_r = self.compute_accuracy(self.d0,self.d1,self.input_judge)
+
+ self.var_judge = Variable(1.*self.input_judge).view(self.d0.size())
+
+ self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge*2.-1.)
+
+ return self.loss_total
+
+ def backward_train(self):
+ torch.mean(self.loss_total).backward()
+
+ def compute_accuracy(self,d0,d1,judge):
+ ''' d0, d1 are Variables, judge is a Tensor '''
+ d1_lt_d0 = (d1 %f' % (type,self.old_lr, lr))
+ self.old_lr = lr
+
+def score_2afc_dataset(data_loader, func, name=''):
+ ''' Function computes Two Alternative Forced Choice (2AFC) score using
+ distance function 'func' in dataset 'data_loader'
+ INPUTS
+ data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
+ func - callable distance function - calling d=func(in0,in1) should take 2
+ pytorch tensors with shape Nx3xXxY, and return numpy array of length N
+ OUTPUTS
+ [0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
+ [1] - dictionary with following elements
+ d0s,d1s - N arrays containing distances between reference patch to perturbed patches
+ gts - N array in [0,1], preferred patch selected by human evaluators
+ (closer to "0" for left patch p0, "1" for right patch p1,
+ "0.6" means 60pct people preferred right patch, 40pct preferred left)
+ scores - N array in [0,1], corresponding to what percentage function agreed with humans
+ CONSTS
+ N - number of test triplets in data_loader
+ '''
+
+ d0s = []
+ d1s = []
+ gts = []
+
+ for data in tqdm(data_loader.load_data(), desc=name):
+ d0s+=func(data['ref'],data['p0']).data.cpu().numpy().flatten().tolist()
+ d1s+=func(data['ref'],data['p1']).data.cpu().numpy().flatten().tolist()
+ gts+=data['judge'].cpu().numpy().flatten().tolist()
+
+ d0s = np.array(d0s)
+ d1s = np.array(d1s)
+ gts = np.array(gts)
+ scores = (d0s= t) == 0:
+ p = 0
+ else:
+ p = np.max(prec[rec >= t])
+ ap = ap + p / 11.0
+ else:
+ # correct AP calculation
+ # first append sentinel values at the end
+ mrec = np.concatenate(([0.0], rec, [1.0]))
+ mpre = np.concatenate(([0.0], prec, [0.0]))
+
+ # compute the precision envelope
+ for i in range(mpre.size - 1, 0, -1):
+ mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
+
+ # to calculate area under PR curve, look for points
+ # where X axis (recall) changes value
+ i = np.where(mrec[1:] != mrec[:-1])[0]
+
+ # and sum (\Delta recall) * prec
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
+ return ap
+
+
+def tensor2im(image_tensor, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
+ # def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
+ image_numpy = image_tensor[0].cpu().float().numpy()
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
+ return image_numpy.astype(imtype)
+
+
+def im2tensor(image, imtype=np.uint8, cent=1.0, factor=255.0 / 2.0):
+ # def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
+ return torch.Tensor(
+ (image / factor - cent)[:, :, :, np.newaxis].transpose((3, 2, 0, 1))
+ )
diff --git a/losses/masked_lpips/base_model.py b/losses/masked_lpips/base_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..20b3b3458bd4a6751708e3ec501f1a59c619a1c4
--- /dev/null
+++ b/losses/masked_lpips/base_model.py
@@ -0,0 +1,65 @@
+import os
+import numpy as np
+import torch
+from torch.autograd import Variable
+from pdb import set_trace as st
+from IPython import embed
+
+
+class BaseModel:
+ def __init__(self):
+ pass
+
+ def name(self):
+ return "BaseModel"
+
+ def initialize(self, use_gpu=True, gpu_ids=[0]):
+ self.use_gpu = use_gpu
+ self.gpu_ids = gpu_ids
+
+ def forward(self):
+ pass
+
+ def get_image_paths(self):
+ pass
+
+ def optimize_parameters(self):
+ pass
+
+ def get_current_visuals(self):
+ return self.input
+
+ def get_current_errors(self):
+ return {}
+
+ def save(self, label):
+ pass
+
+ # helper saving function that can be used by subclasses
+ def save_network(self, network, path, network_label, epoch_label):
+ save_filename = "%s_net_%s.pth" % (epoch_label, network_label)
+ save_path = os.path.join(path, save_filename)
+ torch.save(network.state_dict(), save_path)
+
+ # helper loading function that can be used by subclasses
+ def load_network(self, network, network_label, epoch_label):
+ save_filename = "%s_net_%s.pth" % (epoch_label, network_label)
+ save_path = os.path.join(self.save_dir, save_filename)
+ print("Loading network from %s" % save_path)
+ network.load_state_dict(torch.load(save_path))
+
+ def update_learning_rate():
+ pass
+
+ def get_image_paths(self):
+ return self.image_paths
+
+ def save_done(self, flag=False):
+ np.save(os.path.join(self.save_dir, "done_flag"), flag)
+ np.savetxt(
+ os.path.join(self.save_dir, "done_flag"),
+ [
+ flag,
+ ],
+ fmt="%i",
+ )
diff --git a/losses/masked_lpips/dist_model.py b/losses/masked_lpips/dist_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddee6c38c14a43e4171ac485b86483918492e84c
--- /dev/null
+++ b/losses/masked_lpips/dist_model.py
@@ -0,0 +1,325 @@
+from __future__ import absolute_import
+
+import sys
+import numpy as np
+import torch
+from torch import nn
+import os
+from collections import OrderedDict
+from torch.autograd import Variable
+import itertools
+from .base_model import BaseModel
+from scipy.ndimage import zoom
+import fractions
+import functools
+import skimage.transform
+from tqdm import tqdm
+
+from IPython import embed
+
+from . import networks_basic as netw
+from losses import masked_lpips as util
+
+
+class DistModel(BaseModel):
+ def name(self):
+ return self.model_name
+
+ def initialize(
+ self,
+ model="net-lin",
+ net="alex",
+ vgg_blocks=[1, 2, 3, 4, 5],
+ colorspace="Lab",
+ pnet_rand=False,
+ pnet_tune=False,
+ model_path=None,
+ use_gpu=True,
+ printNet=False,
+ spatial=False,
+ is_train=False,
+ lr=0.0001,
+ beta1=0.5,
+ version="0.1",
+ gpu_ids=[0],
+ ):
+ """
+ INPUTS
+ model - ['net-lin'] for linearly calibrated network
+ ['net'] for off-the-shelf network
+ ['L2'] for L2 distance in Lab colorspace
+ ['SSIM'] for ssim in RGB colorspace
+ net - ['squeeze','alex','vgg']
+ model_path - if None, will look in weights/[NET_NAME].pth
+ colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
+ use_gpu - bool - whether or not to use a GPU
+ printNet - bool - whether or not to print network architecture out
+ spatial - bool - whether to output an array containing varying distances across spatial dimensions
+ spatial_shape - if given, output spatial shape. if None then spatial shape is determined automatically via spatial_factor (see below).
+ spatial_factor - if given, specifies upsampling factor relative to the largest spatial extent of a convolutional layer. if None then resized to size of input images.
+ spatial_order - spline order of filter for upsampling in spatial mode, by default 1 (bilinear).
+ is_train - bool - [True] for training mode
+ lr - float - initial learning rate
+ beta1 - float - initial momentum term for adam
+ version - 0.1 for latest, 0.0 was original (with a bug)
+ gpu_ids - int array - [0] by default, gpus to use
+ """
+ BaseModel.initialize(self, use_gpu=use_gpu, gpu_ids=gpu_ids)
+
+ self.model = model
+ self.net = net
+ self.is_train = is_train
+ self.spatial = spatial
+ self.gpu_ids = gpu_ids
+ self.model_name = "%s [%s]" % (model, net)
+
+ if self.model == "net-lin": # pretrained net + linear layer
+ self.net = netw.PNetLin(
+ pnet_rand=pnet_rand,
+ pnet_tune=pnet_tune,
+ pnet_type=net,
+ use_dropout=True,
+ spatial=spatial,
+ version=version,
+ lpips=True,
+ vgg_blocks=vgg_blocks,
+ )
+ kw = {}
+ if not use_gpu:
+ kw["map_location"] = "cpu"
+ if model_path is None:
+ import inspect
+
+ model_path = os.path.abspath(
+ os.path.join(
+ inspect.getfile(self.initialize),
+ "..",
+ "weights/v%s/%s.pth" % (version, net),
+ )
+ )
+
+ if not is_train:
+ print("Loading model from: %s" % model_path)
+ self.net.load_state_dict(torch.load(model_path, **kw), strict=False)
+
+ elif self.model == "net": # pretrained network
+ self.net = netw.PNetLin(pnet_rand=pnet_rand, pnet_type=net, lpips=False)
+ elif self.model in ["L2", "l2"]:
+ self.net = netw.L2(
+ use_gpu=use_gpu, colorspace=colorspace
+ ) # not really a network, only for testing
+ self.model_name = "L2"
+ elif self.model in ["DSSIM", "dssim", "SSIM", "ssim"]:
+ self.net = netw.DSSIM(use_gpu=use_gpu, colorspace=colorspace)
+ self.model_name = "SSIM"
+ else:
+ raise ValueError("Model [%s] not recognized." % self.model)
+
+ self.parameters = list(self.net.parameters())
+
+ if self.is_train: # training mode
+ # extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
+ self.rankLoss = netw.BCERankingLoss()
+ self.parameters += list(self.rankLoss.net.parameters())
+ self.lr = lr
+ self.old_lr = lr
+ self.optimizer_net = torch.optim.Adam(
+ self.parameters, lr=lr, betas=(beta1, 0.999)
+ )
+ else: # test mode
+ self.net.eval()
+
+ if use_gpu:
+ self.net.to(gpu_ids[0])
+ self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
+ if self.is_train:
+ self.rankLoss = self.rankLoss.to(
+ device=gpu_ids[0]
+ ) # just put this on GPU0
+
+ if printNet:
+ print("---------- Networks initialized -------------")
+ netw.print_network(self.net)
+ print("-----------------------------------------------")
+
+ def forward(self, in0, in1, mask=None, retPerLayer=False):
+ """Function computes the distance between image patches in0 and in1
+ INPUTS
+ in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
+ OUTPUT
+ computed distances between in0 and in1
+ """
+
+ return self.net.forward(in0, in1, mask=mask, retPerLayer=retPerLayer)
+
+ # ***** TRAINING FUNCTIONS *****
+ def optimize_parameters(self):
+ self.forward_train()
+ self.optimizer_net.zero_grad()
+ self.backward_train()
+ self.optimizer_net.step()
+ self.clamp_weights()
+
+ def clamp_weights(self):
+ for module in self.net.modules():
+ if hasattr(module, "weight") and module.kernel_size == (1, 1):
+ module.weight.data = torch.clamp(module.weight.data, min=0)
+
+ def set_input(self, data):
+ self.input_ref = data["ref"]
+ self.input_p0 = data["p0"]
+ self.input_p1 = data["p1"]
+ self.input_judge = data["judge"]
+
+ if self.use_gpu:
+ self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
+ self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
+ self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
+ self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
+
+ self.var_ref = Variable(self.input_ref, requires_grad=True)
+ self.var_p0 = Variable(self.input_p0, requires_grad=True)
+ self.var_p1 = Variable(self.input_p1, requires_grad=True)
+
+ def forward_train(self): # run forward pass
+ # print(self.net.module.scaling_layer.shift)
+ # print(torch.norm(self.net.module.net.slice1[0].weight).item(), torch.norm(self.net.module.lin0.model[1].weight).item())
+
+ self.d0 = self.forward(self.var_ref, self.var_p0)
+ self.d1 = self.forward(self.var_ref, self.var_p1)
+ self.acc_r = self.compute_accuracy(self.d0, self.d1, self.input_judge)
+
+ self.var_judge = Variable(1.0 * self.input_judge).view(self.d0.size())
+
+ self.loss_total = self.rankLoss.forward(
+ self.d0, self.d1, self.var_judge * 2.0 - 1.0
+ )
+
+ return self.loss_total
+
+ def backward_train(self):
+ torch.mean(self.loss_total).backward()
+
+ def compute_accuracy(self, d0, d1, judge):
+ """ d0, d1 are Variables, judge is a Tensor """
+ d1_lt_d0 = (d1 < d0).cpu().data.numpy().flatten()
+ judge_per = judge.cpu().numpy().flatten()
+ return d1_lt_d0 * judge_per + (1 - d1_lt_d0) * (1 - judge_per)
+
+ def get_current_errors(self):
+ retDict = OrderedDict(
+ [("loss_total", self.loss_total.data.cpu().numpy()), ("acc_r", self.acc_r)]
+ )
+
+ for key in retDict.keys():
+ retDict[key] = np.mean(retDict[key])
+
+ return retDict
+
+ def get_current_visuals(self):
+ zoom_factor = 256 / self.var_ref.data.size()[2]
+
+ ref_img = util.tensor2im(self.var_ref.data)
+ p0_img = util.tensor2im(self.var_p0.data)
+ p1_img = util.tensor2im(self.var_p1.data)
+
+ ref_img_vis = zoom(ref_img, [zoom_factor, zoom_factor, 1], order=0)
+ p0_img_vis = zoom(p0_img, [zoom_factor, zoom_factor, 1], order=0)
+ p1_img_vis = zoom(p1_img, [zoom_factor, zoom_factor, 1], order=0)
+
+ return OrderedDict(
+ [("ref", ref_img_vis), ("p0", p0_img_vis), ("p1", p1_img_vis)]
+ )
+
+ def save(self, path, label):
+ if self.use_gpu:
+ self.save_network(self.net.module, path, "", label)
+ else:
+ self.save_network(self.net, path, "", label)
+ self.save_network(self.rankLoss.net, path, "rank", label)
+
+ def update_learning_rate(self, nepoch_decay):
+ lrd = self.lr / nepoch_decay
+ lr = self.old_lr - lrd
+
+ for param_group in self.optimizer_net.param_groups:
+ param_group["lr"] = lr
+
+ print("update lr [%s] decay: %f -> %f" % (type, self.old_lr, lr))
+ self.old_lr = lr
+
+
+def score_2afc_dataset(data_loader, func, name=""):
+ """Function computes Two Alternative Forced Choice (2AFC) score using
+ distance function 'func' in dataset 'data_loader'
+ INPUTS
+ data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
+ func - callable distance function - calling d=func(in0,in1) should take 2
+ pytorch tensors with shape Nx3xXxY, and return numpy array of length N
+ OUTPUTS
+ [0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
+ [1] - dictionary with following elements
+ d0s,d1s - N arrays containing distances between reference patch to perturbed patches
+ gts - N array in [0,1], preferred patch selected by human evaluators
+ (closer to "0" for left patch p0, "1" for right patch p1,
+ "0.6" means 60pct people preferred right patch, 40pct preferred left)
+ scores - N array in [0,1], corresponding to what percentage function agreed with humans
+ CONSTS
+ N - number of test triplets in data_loader
+ """
+
+ d0s = []
+ d1s = []
+ gts = []
+
+ for data in tqdm(data_loader.load_data(), desc=name):
+ d0s += func(data["ref"], data["p0"]).data.cpu().numpy().flatten().tolist()
+ d1s += func(data["ref"], data["p1"]).data.cpu().numpy().flatten().tolist()
+ gts += data["judge"].cpu().numpy().flatten().tolist()
+
+ d0s = np.array(d0s)
+ d1s = np.array(d1s)
+ gts = np.array(gts)
+ scores = (d0s < d1s) * (1.0 - gts) + (d1s < d0s) * gts + (d1s == d0s) * 0.5
+
+ return (np.mean(scores), dict(d0s=d0s, d1s=d1s, gts=gts, scores=scores))
+
+
+def score_jnd_dataset(data_loader, func, name=""):
+ """Function computes JND score using distance function 'func' in dataset 'data_loader'
+ INPUTS
+ data_loader - CustomDatasetDataLoader object - contains a JNDDataset inside
+ func - callable distance function - calling d=func(in0,in1) should take 2
+ pytorch tensors with shape Nx3xXxY, and return pytorch array of length N
+ OUTPUTS
+ [0] - JND score in [0,1], mAP score (area under precision-recall curve)
+ [1] - dictionary with following elements
+ ds - N array containing distances between two patches shown to human evaluator
+ sames - N array containing fraction of people who thought the two patches were identical
+ CONSTS
+ N - number of test triplets in data_loader
+ """
+
+ ds = []
+ gts = []
+
+ for data in tqdm(data_loader.load_data(), desc=name):
+ ds += func(data["p0"], data["p1"]).data.cpu().numpy().tolist()
+ gts += data["same"].cpu().numpy().flatten().tolist()
+
+ sames = np.array(gts)
+ ds = np.array(ds)
+
+ sorted_inds = np.argsort(ds)
+ ds_sorted = ds[sorted_inds]
+ sames_sorted = sames[sorted_inds]
+
+ TPs = np.cumsum(sames_sorted)
+ FPs = np.cumsum(1 - sames_sorted)
+ FNs = np.sum(sames_sorted) - TPs
+
+ precs = TPs / (TPs + FPs)
+ recs = TPs / (TPs + FNs)
+ score = util.voc_ap(recs, precs)
+
+ return (score, dict(ds=ds, sames=sames))
diff --git a/losses/masked_lpips/networks_basic.py b/losses/masked_lpips/networks_basic.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea81e39c338bc13c7597f57e260e35612b8d2aab
--- /dev/null
+++ b/losses/masked_lpips/networks_basic.py
@@ -0,0 +1,331 @@
+from __future__ import absolute_import
+
+import sys
+import torch
+import torch.nn as nn
+import torch.nn.init as init
+from torch.autograd import Variable
+from torch.nn import functional as F
+import numpy as np
+from pdb import set_trace as st
+from skimage import color
+from IPython import embed
+from . import pretrained_networks as pn
+
+from losses import masked_lpips as util
+
+
+def spatial_average(in_tens, mask=None, keepdim=True):
+ if mask is None:
+ return in_tens.mean([2, 3], keepdim=keepdim)
+ else:
+ in_tens = in_tens * mask
+
+ # sum masked_in_tens across spatial dims
+ in_tens = in_tens.sum([2, 3], keepdim=keepdim)
+ in_tens = in_tens / torch.sum(mask)
+
+ return in_tens
+
+
+def upsample(in_tens, out_H=64): # assumes scale factor is same for H and W
+ in_H = in_tens.shape[2]
+ scale_factor = 1.0 * out_H / in_H
+
+ return nn.Upsample(scale_factor=scale_factor, mode="bilinear", align_corners=False)(
+ in_tens
+ )
+
+
+# Learned perceptual metric
+class PNetLin(nn.Module):
+ def __init__(
+ self,
+ pnet_type="vgg",
+ pnet_rand=False,
+ pnet_tune=False,
+ use_dropout=True,
+ spatial=False,
+ version="0.1",
+ lpips=True,
+ vgg_blocks=[1, 2, 3, 4, 5]
+ ):
+ super(PNetLin, self).__init__()
+
+ self.pnet_type = pnet_type
+ self.pnet_tune = pnet_tune
+ self.pnet_rand = pnet_rand
+ self.spatial = spatial
+ self.lpips = lpips
+ self.version = version
+ self.scaling_layer = ScalingLayer()
+
+ if self.pnet_type in ["vgg", "vgg16"]:
+ net_type = pn.vgg16
+ self.blocks = vgg_blocks
+ self.chns = []
+ self.chns = [64, 128, 256, 512, 512]
+
+ elif self.pnet_type == "alex":
+ net_type = pn.alexnet
+ self.chns = [64, 192, 384, 256, 256]
+ elif self.pnet_type == "squeeze":
+ net_type = pn.squeezenet
+ self.chns = [64, 128, 256, 384, 384, 512, 512]
+ self.L = len(self.chns)
+
+ self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
+
+ if lpips:
+ self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
+ self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
+ self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
+ self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
+ self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
+ self.lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
+ #self.lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
+ if self.pnet_type == "squeeze": # 7 layers for squeezenet
+ self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
+ self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
+ self.lins += [self.lin5, self.lin6]
+
+ def forward(self, in0, in1, mask=None, retPerLayer=False):
+ # blocks: list of layer names
+
+ # v0.0 - original release had a bug, where input was not scaled
+ in0_input, in1_input = (
+ (self.scaling_layer(in0), self.scaling_layer(in1))
+ if self.version == "0.1"
+ else (in0, in1)
+ )
+ outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
+ feats0, feats1, diffs = {}, {}, {}
+
+ # prepare list of masks at different resolutions
+ if mask is not None:
+ masks = []
+ if len(mask.shape) == 3:
+ mask = torch.unsqueeze(mask, axis=0) # 4D
+
+ for kk in range(self.L):
+ N, C, H, W = outs0[kk].shape
+ mask = F.interpolate(mask, size=(H, W), mode="nearest")
+ masks.append(mask)
+
+ """
+ outs0 has 5 feature maps
+ 1. [1, 64, 256, 256]
+ 2. [1, 128, 128, 128]
+ 3. [1, 256, 64, 64]
+ 4. [1, 512, 32, 32]
+ 5. [1, 512, 16, 16]
+ """
+ for kk in range(self.L):
+ feats0[kk], feats1[kk] = (
+ util.normalize_tensor(outs0[kk]),
+ util.normalize_tensor(outs1[kk]),
+ )
+ diffs[kk] = (feats0[kk] - feats1[kk]) ** 2
+
+ if self.lpips:
+ if self.spatial:
+ res = [
+ upsample(self.lins[kk].model(diffs[kk]), out_H=in0.shape[2])
+ for kk in range(self.L)
+ ]
+ else:
+ # NOTE: this block is used
+ # self.lins has 5 elements, where each element is a layer of LIN
+ """
+ self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
+ self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
+ self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
+ self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
+ self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
+ self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
+ """
+
+ # NOTE:
+ # Each lins is applying a 1x1 conv on the spatial tensor to output 1 channel
+ # Therefore, to prevent this problem, we can simply mask out the activations
+ # in the spatial_average block. Right now, spatial_average does a spatial mean.
+ # We can mask out the tensor and then consider only on pixels for the mean op.
+ res = [
+ spatial_average(
+ self.lins[kk].model(diffs[kk]),
+ mask=masks[kk] if mask is not None else None,
+ keepdim=True,
+ )
+ for kk in range(self.L)
+ ]
+ else:
+ if self.spatial:
+ res = [
+ upsample(diffs[kk].sum(dim=1, keepdim=True), out_H=in0.shape[2])
+ for kk in range(self.L)
+ ]
+ else:
+ res = [
+ spatial_average(diffs[kk].sum(dim=1, keepdim=True), keepdim=True)
+ for kk in range(self.L)
+ ]
+
+ '''
+ val = res[0]
+ for l in range(1, self.L):
+ val += res[l]
+ '''
+
+ val = 0.0
+ for l in range(self.L):
+ # l is going to run from 0 to 4
+ # check if (l + 1), i.e., [1 -> 5] in self.blocks, then count the loss
+ if str(l + 1) in self.blocks:
+ val += res[l]
+
+ if retPerLayer:
+ return (val, res)
+ else:
+ return val
+
+
+class ScalingLayer(nn.Module):
+ def __init__(self):
+ super(ScalingLayer, self).__init__()
+ self.register_buffer(
+ "shift", torch.Tensor([-0.030, -0.088, -0.188])[None, :, None, None]
+ )
+ self.register_buffer(
+ "scale", torch.Tensor([0.458, 0.448, 0.450])[None, :, None, None]
+ )
+
+ def forward(self, inp):
+ return (inp - self.shift) / self.scale
+
+
+class NetLinLayer(nn.Module):
+ """ A single linear layer which does a 1x1 conv """
+
+ def __init__(self, chn_in, chn_out=1, use_dropout=False):
+ super(NetLinLayer, self).__init__()
+
+ layers = (
+ [
+ nn.Dropout(),
+ ]
+ if (use_dropout)
+ else []
+ )
+ layers += [
+ nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),
+ ]
+ self.model = nn.Sequential(*layers)
+
+
+class Dist2LogitLayer(nn.Module):
+ """ takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) """
+
+ def __init__(self, chn_mid=32, use_sigmoid=True):
+ super(Dist2LogitLayer, self).__init__()
+
+ layers = [
+ nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),
+ ]
+ layers += [
+ nn.LeakyReLU(0.2, True),
+ ]
+ layers += [
+ nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),
+ ]
+ layers += [
+ nn.LeakyReLU(0.2, True),
+ ]
+ layers += [
+ nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),
+ ]
+ if use_sigmoid:
+ layers += [
+ nn.Sigmoid(),
+ ]
+ self.model = nn.Sequential(*layers)
+
+ def forward(self, d0, d1, eps=0.1):
+ return self.model.forward(
+ torch.cat((d0, d1, d0 - d1, d0 / (d1 + eps), d1 / (d0 + eps)), dim=1)
+ )
+
+
+class BCERankingLoss(nn.Module):
+ def __init__(self, chn_mid=32):
+ super(BCERankingLoss, self).__init__()
+ self.net = Dist2LogitLayer(chn_mid=chn_mid)
+ # self.parameters = list(self.net.parameters())
+ self.loss = torch.nn.BCELoss()
+
+ def forward(self, d0, d1, judge):
+ per = (judge + 1.0) / 2.0
+ self.logit = self.net.forward(d0, d1)
+ return self.loss(self.logit, per)
+
+
+# L2, DSSIM metrics
+class FakeNet(nn.Module):
+ def __init__(self, use_gpu=True, colorspace="Lab"):
+ super(FakeNet, self).__init__()
+ self.use_gpu = use_gpu
+ self.colorspace = colorspace
+
+
+class L2(FakeNet):
+ def forward(self, in0, in1, retPerLayer=None):
+ assert in0.size()[0] == 1 # currently only supports batchSize 1
+
+ if self.colorspace == "RGB":
+ (N, C, X, Y) = in0.size()
+ value = torch.mean(
+ torch.mean(
+ torch.mean((in0 - in1) ** 2, dim=1).view(N, 1, X, Y), dim=2
+ ).view(N, 1, 1, Y),
+ dim=3,
+ ).view(N)
+ return value
+ elif self.colorspace == "Lab":
+ value = util.l2(
+ util.tensor2np(util.tensor2tensorlab(in0.data, to_norm=False)),
+ util.tensor2np(util.tensor2tensorlab(in1.data, to_norm=False)),
+ range=100.0,
+ ).astype("float")
+ ret_var = Variable(torch.Tensor((value,)))
+ if self.use_gpu:
+ ret_var = ret_var.cuda()
+ return ret_var
+
+
+class DSSIM(FakeNet):
+ def forward(self, in0, in1, retPerLayer=None):
+ assert in0.size()[0] == 1 # currently only supports batchSize 1
+
+ if self.colorspace == "RGB":
+ value = util.dssim(
+ 1.0 * util.tensor2im(in0.data),
+ 1.0 * util.tensor2im(in1.data),
+ range=255.0,
+ ).astype("float")
+ elif self.colorspace == "Lab":
+ value = util.dssim(
+ util.tensor2np(util.tensor2tensorlab(in0.data, to_norm=False)),
+ util.tensor2np(util.tensor2tensorlab(in1.data, to_norm=False)),
+ range=100.0,
+ ).astype("float")
+ ret_var = Variable(torch.Tensor((value,)))
+ if self.use_gpu:
+ ret_var = ret_var.cuda()
+ return ret_var
+
+
+def print_network(net):
+ num_params = 0
+ for param in net.parameters():
+ num_params += param.numel()
+ print("Network", net)
+ print("Total number of parameters: %d" % num_params)
diff --git a/losses/masked_lpips/pretrained_networks.py b/losses/masked_lpips/pretrained_networks.py
new file mode 100644
index 0000000000000000000000000000000000000000..c251390679737ebf7ae279cd93571d369b41796e
--- /dev/null
+++ b/losses/masked_lpips/pretrained_networks.py
@@ -0,0 +1,190 @@
+from collections import namedtuple
+import torch
+from torchvision import models as tv
+from IPython import embed
+
+
+class squeezenet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(squeezenet, self).__init__()
+ pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.slice6 = torch.nn.Sequential()
+ self.slice7 = torch.nn.Sequential()
+ self.N_slices = 7
+ for x in range(2):
+ self.slice1.add_module(str(x), pretrained_features[x])
+ for x in range(2, 5):
+ self.slice2.add_module(str(x), pretrained_features[x])
+ for x in range(5, 8):
+ self.slice3.add_module(str(x), pretrained_features[x])
+ for x in range(8, 10):
+ self.slice4.add_module(str(x), pretrained_features[x])
+ for x in range(10, 11):
+ self.slice5.add_module(str(x), pretrained_features[x])
+ for x in range(11, 12):
+ self.slice6.add_module(str(x), pretrained_features[x])
+ for x in range(12, 13):
+ self.slice7.add_module(str(x), pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1 = h
+ h = self.slice2(h)
+ h_relu2 = h
+ h = self.slice3(h)
+ h_relu3 = h
+ h = self.slice4(h)
+ h_relu4 = h
+ h = self.slice5(h)
+ h_relu5 = h
+ h = self.slice6(h)
+ h_relu6 = h
+ h = self.slice7(h)
+ h_relu7 = h
+ vgg_outputs = namedtuple(
+ "SqueezeOutputs",
+ ["relu1", "relu2", "relu3", "relu4", "relu5", "relu6", "relu7"],
+ )
+ out = vgg_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5, h_relu6, h_relu7)
+
+ return out
+
+
+class alexnet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(alexnet, self).__init__()
+ alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.N_slices = 5
+ for x in range(2):
+ self.slice1.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(2, 5):
+ self.slice2.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(5, 8):
+ self.slice3.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(8, 10):
+ self.slice4.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(10, 12):
+ self.slice5.add_module(str(x), alexnet_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1 = h
+ h = self.slice2(h)
+ h_relu2 = h
+ h = self.slice3(h)
+ h_relu3 = h
+ h = self.slice4(h)
+ h_relu4 = h
+ h = self.slice5(h)
+ h_relu5 = h
+ alexnet_outputs = namedtuple(
+ "AlexnetOutputs", ["relu1", "relu2", "relu3", "relu4", "relu5"]
+ )
+ out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
+
+ return out
+
+
+class vgg16(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(vgg16, self).__init__()
+ vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.N_slices = 5
+ for x in range(4):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(4, 9):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(9, 16):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(16, 23):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(23, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1_2 = h
+ h = self.slice2(h)
+ h_relu2_2 = h
+ h = self.slice3(h)
+ h_relu3_3 = h
+ h = self.slice4(h)
+ h_relu4_3 = h
+ h = self.slice5(h)
+ h_relu5_3 = h
+
+ vgg_outputs = namedtuple(
+ "VggOutputs", ["relu1_2", "relu2_2", "relu3_3", "relu4_3", "relu5_3"]
+ )
+ out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
+
+ return out
+
+
+class resnet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True, num=18):
+ super(resnet, self).__init__()
+ if num == 18:
+ self.net = tv.resnet18(pretrained=pretrained)
+ elif num == 34:
+ self.net = tv.resnet34(pretrained=pretrained)
+ elif num == 50:
+ self.net = tv.resnet50(pretrained=pretrained)
+ elif num == 101:
+ self.net = tv.resnet101(pretrained=pretrained)
+ elif num == 152:
+ self.net = tv.resnet152(pretrained=pretrained)
+ self.N_slices = 5
+
+ self.conv1 = self.net.conv1
+ self.bn1 = self.net.bn1
+ self.relu = self.net.relu
+ self.maxpool = self.net.maxpool
+ self.layer1 = self.net.layer1
+ self.layer2 = self.net.layer2
+ self.layer3 = self.net.layer3
+ self.layer4 = self.net.layer4
+
+ def forward(self, X):
+ h = self.conv1(X)
+ h = self.bn1(h)
+ h = self.relu(h)
+ h_relu1 = h
+ h = self.maxpool(h)
+ h = self.layer1(h)
+ h_conv2 = h
+ h = self.layer2(h)
+ h_conv3 = h
+ h = self.layer3(h)
+ h_conv4 = h
+ h = self.layer4(h)
+ h_conv5 = h
+
+ outputs = namedtuple("Outputs", ["relu1", "conv2", "conv3", "conv4", "conv5"])
+ out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
+
+ return out
diff --git a/losses/pp_losses.py b/losses/pp_losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..29d2d5694a748f9a77d74774fbcc10dd8a7efee8
--- /dev/null
+++ b/losses/pp_losses.py
@@ -0,0 +1,677 @@
+from dataclasses import dataclass
+
+import torch.nn as nn
+import torch.nn.functional as F
+from torchvision import transforms as T
+
+from utils.bicubic import BicubicDownSample
+
+normalize = T.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
+
+@dataclass
+class DefaultPaths:
+ psp_path: str = "pretrained_models/psp_ffhq_encode.pt"
+ ir_se50_path: str = "pretrained_models/ArcFace/ir_se50.pth"
+ stylegan_weights: str = "pretrained_models/stylegan2-ffhq-config-f.pt"
+ stylegan_car_weights: str = "pretrained_models/stylegan2-car-config-f-new.pkl"
+ stylegan_weights_pkl: str = (
+ "pretrained_models/stylegan2-ffhq-config-f.pkl"
+ )
+ arcface_model_path: str = "pretrained_models/ArcFace/backbone_ir50.pth"
+ moco: str = "pretrained_models/moco_v2_800ep_pretrain.pt"
+
+
+from collections import namedtuple
+from torch.nn import (
+ Conv2d,
+ BatchNorm2d,
+ PReLU,
+ ReLU,
+ Sigmoid,
+ MaxPool2d,
+ AdaptiveAvgPool2d,
+ Sequential,
+ Module,
+ Dropout,
+ Linear,
+ BatchNorm1d,
+)
+
+"""
+ArcFace implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
+"""
+
+
+class Flatten(Module):
+ def forward(self, input):
+ return input.view(input.size(0), -1)
+
+
+def l2_norm(input, axis=1):
+ norm = torch.norm(input, 2, axis, True)
+ output = torch.div(input, norm)
+ return output
+
+
+class Bottleneck(namedtuple("Block", ["in_channel", "depth", "stride"])):
+ """A named tuple describing a ResNet block."""
+
+
+def get_block(in_channel, depth, num_units, stride=2):
+ return [Bottleneck(in_channel, depth, stride)] + [
+ Bottleneck(depth, depth, 1) for i in range(num_units - 1)
+ ]
+
+
+def get_blocks(num_layers):
+ if num_layers == 50:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=4),
+ get_block(in_channel=128, depth=256, num_units=14),
+ get_block(in_channel=256, depth=512, num_units=3),
+ ]
+ elif num_layers == 100:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=13),
+ get_block(in_channel=128, depth=256, num_units=30),
+ get_block(in_channel=256, depth=512, num_units=3),
+ ]
+ elif num_layers == 152:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=8),
+ get_block(in_channel=128, depth=256, num_units=36),
+ get_block(in_channel=256, depth=512, num_units=3),
+ ]
+ else:
+ raise ValueError(
+ "Invalid number of layers: {}. Must be one of [50, 100, 152]".format(
+ num_layers
+ )
+ )
+ return blocks
+
+
+class SEModule(Module):
+ def __init__(self, channels, reduction):
+ super(SEModule, self).__init__()
+ self.avg_pool = AdaptiveAvgPool2d(1)
+ self.fc1 = Conv2d(
+ channels, channels // reduction, kernel_size=1, padding=0, bias=False
+ )
+ self.relu = ReLU(inplace=True)
+ self.fc2 = Conv2d(
+ channels // reduction, channels, kernel_size=1, padding=0, bias=False
+ )
+ self.sigmoid = Sigmoid()
+
+ def forward(self, x):
+ module_input = x
+ x = self.avg_pool(x)
+ x = self.fc1(x)
+ x = self.relu(x)
+ x = self.fc2(x)
+ x = self.sigmoid(x)
+ return module_input * x
+
+
+class bottleneck_IR(Module):
+ def __init__(self, in_channel, depth, stride):
+ super(bottleneck_IR, self).__init__()
+ if in_channel == depth:
+ self.shortcut_layer = MaxPool2d(1, stride)
+ else:
+ self.shortcut_layer = Sequential(
+ Conv2d(in_channel, depth, (1, 1), stride, bias=False),
+ BatchNorm2d(depth),
+ )
+ self.res_layer = Sequential(
+ BatchNorm2d(in_channel),
+ Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
+ PReLU(depth),
+ Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
+ BatchNorm2d(depth),
+ )
+
+ def forward(self, x):
+ shortcut = self.shortcut_layer(x)
+ res = self.res_layer(x)
+ return res + shortcut
+
+
+class bottleneck_IR_SE(Module):
+ def __init__(self, in_channel, depth, stride):
+ super(bottleneck_IR_SE, self).__init__()
+ if in_channel == depth:
+ self.shortcut_layer = MaxPool2d(1, stride)
+ else:
+ self.shortcut_layer = Sequential(
+ Conv2d(in_channel, depth, (1, 1), stride, bias=False),
+ BatchNorm2d(depth),
+ )
+ self.res_layer = Sequential(
+ BatchNorm2d(in_channel),
+ Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
+ PReLU(depth),
+ Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
+ BatchNorm2d(depth),
+ SEModule(depth, 16),
+ )
+
+ def forward(self, x):
+ shortcut = self.shortcut_layer(x)
+ res = self.res_layer(x)
+ return res + shortcut
+
+
+"""
+Modified Backbone implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
+"""
+
+
+class Backbone(Module):
+ def __init__(self, input_size, num_layers, mode="ir", drop_ratio=0.4, affine=True):
+ super(Backbone, self).__init__()
+ assert input_size in [112, 224], "input_size should be 112 or 224"
+ assert num_layers in [50, 100, 152], "num_layers should be 50, 100 or 152"
+ assert mode in ["ir", "ir_se"], "mode should be ir or ir_se"
+ blocks = get_blocks(num_layers)
+ if mode == "ir":
+ unit_module = bottleneck_IR
+ elif mode == "ir_se":
+ unit_module = bottleneck_IR_SE
+ self.input_layer = Sequential(
+ Conv2d(3, 64, (3, 3), 1, 1, bias=False), BatchNorm2d(64), PReLU(64)
+ )
+ if input_size == 112:
+ self.output_layer = Sequential(
+ BatchNorm2d(512),
+ Dropout(drop_ratio),
+ Flatten(),
+ Linear(512 * 7 * 7, 512),
+ BatchNorm1d(512, affine=affine),
+ )
+ else:
+ self.output_layer = Sequential(
+ BatchNorm2d(512),
+ Dropout(drop_ratio),
+ Flatten(),
+ Linear(512 * 14 * 14, 512),
+ BatchNorm1d(512, affine=affine),
+ )
+
+ modules = []
+ for block in blocks:
+ for bottleneck in block:
+ modules.append(
+ unit_module(
+ bottleneck.in_channel, bottleneck.depth, bottleneck.stride
+ )
+ )
+ self.body = Sequential(*modules)
+
+ def forward(self, x):
+ x = self.input_layer(x)
+ x = self.body(x)
+ x = self.output_layer(x)
+ return l2_norm(x)
+
+
+def IR_50(input_size):
+ """Constructs a ir-50 model."""
+ model = Backbone(input_size, num_layers=50, mode="ir", drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_101(input_size):
+ """Constructs a ir-101 model."""
+ model = Backbone(
+ input_size, num_layers=100, mode="ir", drop_ratio=0.4, affine=False
+ )
+ return model
+
+
+def IR_152(input_size):
+ """Constructs a ir-152 model."""
+ model = Backbone(
+ input_size, num_layers=152, mode="ir", drop_ratio=0.4, affine=False
+ )
+ return model
+
+
+def IR_SE_50(input_size):
+ """Constructs a ir_se-50 model."""
+ model = Backbone(
+ input_size, num_layers=50, mode="ir_se", drop_ratio=0.4, affine=False
+ )
+ return model
+
+
+def IR_SE_101(input_size):
+ """Constructs a ir_se-101 model."""
+ model = Backbone(
+ input_size, num_layers=100, mode="ir_se", drop_ratio=0.4, affine=False
+ )
+ return model
+
+
+def IR_SE_152(input_size):
+ """Constructs a ir_se-152 model."""
+ model = Backbone(
+ input_size, num_layers=152, mode="ir_se", drop_ratio=0.4, affine=False
+ )
+ return model
+
+class IDLoss(nn.Module):
+ def __init__(self):
+ super(IDLoss, self).__init__()
+ print("Loading ResNet ArcFace")
+ self.facenet = Backbone(
+ input_size=112, num_layers=50, drop_ratio=0.6, mode="ir_se"
+ )
+ self.facenet.load_state_dict(torch.load(DefaultPaths.ir_se50_path))
+ self.face_pool = torch.nn.AdaptiveAvgPool2d((112, 112))
+ self.facenet.eval()
+
+ def extract_feats(self, x):
+ x = x[:, :, 35:223, 32:220] # Crop interesting region
+ x = self.face_pool(x)
+ x_feats = self.facenet(x)
+ return x_feats
+
+ def forward(self, y_hat, y):
+ n_samples = y.shape[0]
+ y_feats = self.extract_feats(y)
+ y_hat_feats = self.extract_feats(y_hat)
+ y_feats = y_feats.detach()
+ loss = 0
+ count = 0
+ for i in range(n_samples):
+ diff_target = y_hat_feats[i].dot(y_feats[i])
+ loss += 1 - diff_target
+ count += 1
+
+ return loss / count
+
+class FeatReconLoss(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.loss_fn = nn.MSELoss()
+
+ def forward(self, recon_1, recon_2):
+ return self.loss_fn(recon_1, recon_2).mean()
+
+class EncoderAdvLoss:
+ def __call__(self, fake_preds):
+ loss_G_adv = F.softplus(-fake_preds).mean()
+ return loss_G_adv
+
+class AdvLoss:
+ def __init__(self, coef=0.0):
+ self.coef = coef
+
+ def __call__(self, disc, real_images, generated_images):
+ fake_preds = disc(generated_images, None)
+ real_preds = disc(real_images, None)
+ loss = self.d_logistic_loss(real_preds, fake_preds)
+
+ return {'disc adv': loss}
+
+ def d_logistic_loss(self, real_preds, fake_preds):
+ real_loss = F.softplus(-real_preds)
+ fake_loss = F.softplus(fake_preds)
+
+ return (real_loss.mean() + fake_loss.mean()) / 2
+
+from models.face_parsing.model import BiSeNet, seg_mean, seg_std
+
+class DiceLoss(nn.Module):
+ def __init__(self, gamma=2):
+ super().__init__()
+ self.gamma = gamma
+ self.seg = BiSeNet(n_classes=16)
+ self.seg.to('cuda')
+ self.seg.load_state_dict(torch.load('pretrained_models/BiSeNet/seg.pth'))
+ for param in self.seg.parameters():
+ param.requires_grad = False
+ self.seg.eval()
+ self.downsample_512 = BicubicDownSample(factor=2)
+
+ def calc_landmark(self, x):
+ IM = (self.downsample_512(x) - seg_mean) / seg_std
+ out, _, _ = self.seg(IM)
+ return out
+
+ def dice_loss(self, input, target):
+ smooth = 1.
+
+ iflat = input.view(input.size(0), -1)
+ tflat = target.view(target.size(0), -1)
+ intersection = (iflat * tflat).sum(dim=1)
+
+ fn = torch.sum((tflat * (1-iflat))**self.gamma, dim=1)
+ fp = torch.sum(((1-tflat) * iflat)**self.gamma, dim=1)
+
+ return 1 - ((2. * intersection + smooth) /
+ (iflat.sum(dim=1) + tflat.sum(dim=1) + fn + fp + smooth))
+
+ def __call__(self, in_logit, tg_logit):
+ probs1 = F.softmax(in_logit, dim=1)
+ probs2 = F.softmax(tg_logit, dim=1)
+ return self.dice_loss(probs1, probs2).mean()
+
+
+from typing import Sequence
+
+from itertools import chain
+
+import torch
+import torch.nn as nn
+from torchvision import models
+
+
+def get_network(net_type: str):
+ if net_type == "alex":
+ return AlexNet()
+ elif net_type == "squeeze":
+ return SqueezeNet()
+ elif net_type == "vgg":
+ return VGG16()
+ else:
+ raise NotImplementedError("choose net_type from [alex, squeeze, vgg].")
+
+
+class LinLayers(nn.ModuleList):
+ def __init__(self, n_channels_list: Sequence[int]):
+ super(LinLayers, self).__init__(
+ [
+ nn.Sequential(nn.Identity(), nn.Conv2d(nc, 1, 1, 1, 0, bias=False))
+ for nc in n_channels_list
+ ]
+ )
+
+ for param in self.parameters():
+ param.requires_grad = False
+
+
+class BaseNet(nn.Module):
+ def __init__(self):
+ super(BaseNet, self).__init__()
+
+ # register buffer
+ self.register_buffer(
+ "mean", torch.Tensor([-0.030, -0.088, -0.188])[None, :, None, None]
+ )
+ self.register_buffer(
+ "std", torch.Tensor([0.458, 0.448, 0.450])[None, :, None, None]
+ )
+
+ def set_requires_grad(self, state: bool):
+ for param in chain(self.parameters(), self.buffers()):
+ param.requires_grad = state
+
+ def z_score(self, x: torch.Tensor):
+ return (x - self.mean) / self.std
+
+ def forward(self, x: torch.Tensor):
+ x = self.z_score(x)
+
+ output = []
+ for i, (_, layer) in enumerate(self.layers._modules.items(), 1):
+ x = layer(x)
+ if i in self.target_layers:
+ output.append(normalize_activation(x))
+ if len(output) == len(self.target_layers):
+ break
+ return output
+
+
+class SqueezeNet(BaseNet):
+ def __init__(self):
+ super(SqueezeNet, self).__init__()
+
+ self.layers = models.squeezenet1_1(True).features
+ self.target_layers = [2, 5, 8, 10, 11, 12, 13]
+ self.n_channels_list = [64, 128, 256, 384, 384, 512, 512]
+
+ self.set_requires_grad(False)
+
+
+class AlexNet(BaseNet):
+ def __init__(self):
+ super(AlexNet, self).__init__()
+
+ self.layers = models.alexnet(True).features
+ self.target_layers = [2, 5, 8, 10, 12]
+ self.n_channels_list = [64, 192, 384, 256, 256]
+
+ self.set_requires_grad(False)
+
+
+class VGG16(BaseNet):
+ def __init__(self):
+ super(VGG16, self).__init__()
+
+ self.layers = models.vgg16(True).features
+ self.target_layers = [4, 9, 16, 23, 30]
+ self.n_channels_list = [64, 128, 256, 512, 512]
+
+ self.set_requires_grad(False)
+
+
+from collections import OrderedDict
+
+import torch
+
+
+def normalize_activation(x, eps=1e-10):
+ norm_factor = torch.sqrt(torch.sum(x**2, dim=1, keepdim=True))
+ return x / (norm_factor + eps)
+
+
+def get_state_dict(net_type: str = "alex", version: str = "0.1"):
+ # build url
+ url = (
+ "https://raw.githubusercontent.com/richzhang/PerceptualSimilarity/"
+ + f"master/lpips/weights/v{version}/{net_type}.pth"
+ )
+
+ # download
+ old_state_dict = torch.hub.load_state_dict_from_url(
+ url,
+ progress=True,
+ map_location=None if torch.cuda.is_available() else torch.device("cpu"),
+ )
+
+ # rename keys
+ new_state_dict = OrderedDict()
+ for key, val in old_state_dict.items():
+ new_key = key
+ new_key = new_key.replace("lin", "")
+ new_key = new_key.replace("model.", "")
+ new_state_dict[new_key] = val
+
+ return new_state_dict
+
+class LPIPS(nn.Module):
+ r"""Creates a criterion that measures
+ Learned Perceptual Image Patch Similarity (LPIPS).
+ Arguments:
+ net_type (str): the network type to compare the features:
+ 'alex' | 'squeeze' | 'vgg'. Default: 'alex'.
+ version (str): the version of LPIPS. Default: 0.1.
+ """
+
+ def __init__(self, net_type: str = "alex", version: str = "0.1"):
+
+ assert version in ["0.1"], "v0.1 is only supported now"
+
+ super(LPIPS, self).__init__()
+
+ # pretrained network
+ self.net = get_network(net_type).to("cuda")
+
+ # linear layers
+ self.lin = LinLayers(self.net.n_channels_list).to("cuda")
+ self.lin.load_state_dict(get_state_dict(net_type, version))
+
+ def forward(self, x: torch.Tensor, y: torch.Tensor):
+ feat_x, feat_y = self.net(x), self.net(y)
+
+ diff = [(fx - fy) ** 2 for fx, fy in zip(feat_x, feat_y)]
+ res = [l(d).mean((2, 3), True) for d, l in zip(diff, self.lin)]
+
+ return torch.sum(torch.cat(res, 0)) / x.shape[0]
+
+class LPIPSLoss(LPIPS):
+ pass
+
+class LPIPSScaleLoss(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.loss_fn = LPIPSLoss()
+
+ def forward(self, x, y):
+ out = 0
+ for res in [256, 128, 64]:
+ x_scale = F.interpolate(x, size=(res, res), mode="bilinear", align_corners=False)
+ y_scale = F.interpolate(y, size=(res, res), mode="bilinear", align_corners=False)
+ out += self.loss_fn.forward(x_scale, y_scale).mean()
+ return out
+
+class SyntMSELoss(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.loss_fn = nn.MSELoss()
+
+ def forward(self, im1, im2):
+ return self.loss_fn(im1, im2).mean()
+
+class R1Loss:
+ def __init__(self, coef=10.0):
+ self.coef = coef
+
+ def __call__(self, disc, real_images):
+ real_images.requires_grad = True
+
+ real_preds = disc(real_images, None)
+ real_preds = real_preds.view(real_images.size(0), -1)
+ real_preds = real_preds.mean(dim=1).unsqueeze(1)
+ r1_loss = self.d_r1_loss(real_preds, real_images)
+
+ loss_D_R1 = self.coef / 2 * r1_loss * 16 + 0 * real_preds[0]
+ return {'disc r1 loss': loss_D_R1}
+
+ def d_r1_loss(self, real_pred, real_img):
+ (grad_real,) = torch.autograd.grad(
+ outputs=real_pred.sum(), inputs=real_img, create_graph=True
+ )
+ grad_penalty = grad_real.pow(2).reshape(grad_real.shape[0], -1).sum(1).mean()
+
+ return grad_penalty
+
+
+class DilatedMask:
+ def __init__(self, kernel_size=5):
+ self.kernel_size = kernel_size
+
+ cords_x = torch.arange(0, kernel_size).view(1, -1).expand(kernel_size, -1) - kernel_size // 2
+ cords_y = cords_x.clone().permute(1, 0)
+ self.kernel = torch.as_tensor((cords_x ** 2 + cords_y ** 2) <= (kernel_size // 2) ** 2, dtype=torch.float).view(1, 1, kernel_size, kernel_size).cuda()
+ self.kernel /= self.kernel.sum()
+
+ def __call__(self, mask):
+ smooth_mask = F.conv2d(mask, self.kernel, padding=self.kernel_size // 2)
+ return smooth_mask ** 0.25
+
+
+class LossBuilder:
+ def __init__(self, losses_dict, device='cuda'):
+ self.losses_dict = losses_dict
+ self.device = device
+
+ self.EncoderAdvLoss = EncoderAdvLoss()
+ self.AdvLoss = AdvLoss()
+ self.R1Loss = R1Loss()
+ self.FeatReconLoss = FeatReconLoss().to(device).eval()
+ self.IDLoss = IDLoss().to(device).eval()
+ self.LPIPS = LPIPSScaleLoss().to(device).eval()
+ self.SyntMSELoss = SyntMSELoss().to(device).eval()
+ self.downsample_256 = BicubicDownSample(factor=4)
+
+ def CalcAdvLoss(self, disc, gen_F):
+ fake_preds_F = disc(gen_F, None)
+
+ return {'adv': self.losses_dict['adv'] * self.EncoderAdvLoss(fake_preds_F)}
+
+ def CalcDisLoss(self, disc, real_images, generated_images):
+ return self.AdvLoss(disc, real_images, generated_images)
+
+ def CalcR1Loss(self, disc, real_images):
+ return self.R1Loss(disc, real_images)
+
+ def __call__(self, source, target, target_mask, HT_E, gen_w, F_w, gen_F, F_gen, **kwargs):
+ losses = {}
+
+ gen_w_256 = self.downsample_256(gen_w)
+ gen_F_256 = self.downsample_256(gen_F)
+
+ # ID loss
+ losses['rec id'] = self.losses_dict['id'] * (self.IDLoss(normalize(source), gen_w_256) + self.IDLoss(normalize(source), gen_F_256))
+
+ # Feat Recons Loss
+ losses['rec feat_rec'] = self.losses_dict['feat_rec'] * self.FeatReconLoss(F_w.detach(), F_gen)
+
+ # LPIPS loss
+ losses['rec lpips_scale'] = self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(source), gen_w_256) + self.LPIPS(normalize(source), gen_F_256))
+
+ # Synt loss
+ # losses['l2_synt'] = self.losses_dict['l2_synt'] * self.SyntMSELoss(target * HT_E, (gen_F_256 + 1) / 2 * HT_E)
+
+ return losses
+
+
+class LossBuilderMulti(LossBuilder):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.DiceLoss = DiceLoss().to(kwargs.get('device', 'cuda')).eval()
+ self.dilated = DilatedMask(25)
+
+ def __call__(self, source, target, target_mask, HT_E, gen_w, F_w, gen_F, F_gen, **kwargs):
+ losses = {}
+
+ gen_w_256 = self.downsample_256(gen_w)
+ gen_F_256 = self.downsample_256(gen_F)
+
+ # Dice loss
+ with torch.no_grad():
+ target_512 = F.interpolate(target, size=(512, 512), mode='bilinear').clip(0, 1)
+ seg_target = self.DiceLoss.calc_landmark(target_512)
+ seg_target = F.interpolate(seg_target, size=(256, 256), mode='nearest')
+ seg_gen = F.interpolate(self.DiceLoss.calc_landmark((gen_F + 1) / 2), size=(256, 256), mode='nearest')
+
+ losses['DiceLoss'] = self.losses_dict['landmark'] * self.DiceLoss(seg_gen, seg_target)
+
+ # ID loss
+ losses['id'] = self.losses_dict['id'] * (self.IDLoss(normalize(source) * target_mask, gen_w_256 * target_mask) +
+ self.IDLoss(normalize(source) * target_mask, gen_F_256 * target_mask))
+
+ # Feat Recons loss
+ losses['feat_rec'] = self.losses_dict['feat_rec'] * self.FeatReconLoss(F_w.detach(), F_gen)
+
+ # LPIPS loss
+ losses['lpips_face'] = 0.5 * self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(source) * target_mask, gen_w_256 * target_mask) +
+ self.LPIPS(normalize(source) * target_mask, gen_F_256 * target_mask))
+ losses['lpips_hair'] = 0.5 * self.losses_dict['lpips_scale'] * (self.LPIPS(normalize(target) * HT_E, gen_w_256 * HT_E) +
+ self.LPIPS(normalize(target) * HT_E, gen_F_256 * HT_E))
+
+ # Inpaint loss
+ if self.losses_dict['inpaint'] != 0.:
+ M_Inp = (1 - target_mask) * (1 - HT_E)
+ Smooth_M = self.dilated(M_Inp)
+ losses['inpaint'] = 0.5 * self.losses_dict['inpaint'] * self.LPIPS(normalize(target) * Smooth_M, gen_F_256 * Smooth_M)
+ losses['inpaint'] += 0.5 * self.losses_dict['inpaint'] * self.LPIPS(gen_w_256.detach() * Smooth_M * (1 - HT_E), gen_F_256 * Smooth_M * (1 - HT_E))
+
+ return losses
diff --git a/losses/style/__init__.py b/losses/style/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/losses/style/custom_loss.py b/losses/style/custom_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..cceb6775b1df8bf5768a1f6614461054b86287f8
--- /dev/null
+++ b/losses/style/custom_loss.py
@@ -0,0 +1,67 @@
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+
+mse_loss = nn.MSELoss(reduction="mean")
+
+
+def custom_loss(x, y, mask=None, loss_type="l2", include_bkgd=True):
+ """
+ x, y: [N, C, H, W]
+ Computes L1/L2 loss
+
+ if include_bkgd is True:
+ use traditional MSE and L1 loss
+ else:
+ mask out background info using :mask
+ normalize loss with #1's in mask
+ """
+ if include_bkgd:
+ # perform simple mse or l1 loss
+ if loss_type == "l2":
+ loss_rec = mse_loss(x, y)
+ elif loss_type == "l1":
+ loss_rec = F.l1_loss(x, y)
+
+ return loss_rec
+
+ Nx, Cx, Hx, Wx = x.shape
+ Nm, Cm, Hm, Wm = mask.shape
+ mask = prepare_mask(x, mask)
+
+ x_reshape = torch.reshape(x, [Nx, -1])
+ y_reshape = torch.reshape(y, [Nx, -1])
+ mask_reshape = torch.reshape(mask, [Nx, -1])
+
+ if loss_type == "l2":
+ diff = (x_reshape - y_reshape) ** 2
+ elif loss_type == "l1":
+ diff = torch.abs(x_reshape - y_reshape)
+
+ # diff: [N, Cx * Hx * Wx]
+ # set elements in diff to 0 using mask
+ masked_diff = diff * mask_reshape
+ sum_diff = torch.sum(masked_diff, axis=-1)
+ # count non-zero elements; add :mask_reshape elements
+ norm_count = torch.sum(mask_reshape, axis=-1)
+ diff_norm = sum_diff / (norm_count + 1.0)
+
+ loss_rec = torch.mean(diff_norm)
+
+ return loss_rec
+
+
+def prepare_mask(x, mask):
+ """
+ Make mask similar to x.
+ Mask contains values in [0, 1].
+ Adjust channels and spatial dimensions.
+ """
+ Nx, Cx, Hx, Wx = x.shape
+ Nm, Cm, Hm, Wm = mask.shape
+ if Cm == 1:
+ mask = mask.repeat(1, Cx, 1, 1)
+
+ mask = F.interpolate(mask, scale_factor=Hx / Hm, mode="nearest")
+
+ return mask
diff --git a/losses/style/style_loss.py b/losses/style/style_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..750aa6523151a62b4cf9a6f42dbc240239f10093
--- /dev/null
+++ b/losses/style/style_loss.py
@@ -0,0 +1,113 @@
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+
+import os
+
+from losses.style.custom_loss import custom_loss, prepare_mask
+from losses.style.vgg_activations import VGG16_Activations, VGG19_Activations, Vgg_face_dag
+
+
+class StyleLoss(nn.Module):
+ def __init__(self, VGG16_ACTIVATIONS_LIST=[21], normalize=False, distance="l2"):
+
+ super(StyleLoss, self).__init__()
+
+ self.vgg16_act = VGG16_Activations(VGG16_ACTIVATIONS_LIST)
+ self.vgg16_act.eval()
+
+ self.normalize = normalize
+ self.distance = distance
+
+ def get_features(self, model, x):
+
+ return model(x)
+
+ def mask_features(self, x, mask):
+
+ mask = prepare_mask(x, mask)
+ return x * mask
+
+ def gram_matrix(self, x):
+ """
+ :x is an activation tensor
+ """
+ N, C, H, W = x.shape
+ x = x.view(N * C, H * W)
+ G = torch.mm(x, x.t())
+
+ return G.div(N * H * W * C)
+
+ def cal_style(self, model, x, x_hat, mask1=None, mask2=None):
+ # Get features from the model for x and x_hat
+ with torch.no_grad():
+ act_x = self.get_features(model, x)
+ for layer in range(0, len(act_x)):
+ act_x[layer].detach_()
+
+ act_x_hat = self.get_features(model, x_hat)
+
+ loss = 0.0
+ for layer in range(0, len(act_x)):
+
+ # mask features if present
+ if mask1 is not None:
+ feat_x = self.mask_features(act_x[layer], mask1)
+ else:
+ feat_x = act_x[layer]
+ if mask2 is not None:
+ feat_x_hat = self.mask_features(act_x_hat[layer], mask2)
+ else:
+ feat_x_hat = act_x_hat[layer]
+
+ """
+ import ipdb; ipdb.set_trace()
+ fx = feat_x[0, ...].detach().cpu().numpy()
+ fx = (fx - fx.min()) / (fx.max() - fx.min())
+ fx = fx * 255.
+ fxhat = feat_x_hat[0, ...].detach().cpu().numpy()
+ fxhat = (fxhat - fxhat.min()) / (fxhat.max() - fxhat.min())
+ fxhat = fxhat * 255
+ from PIL import Image
+ import numpy as np
+ for idx, img in enumerate(fx):
+ img = fx[idx, ...]
+ img = img.astype(np.uint8)
+ img = Image.fromarray(img)
+ img.save('plot/feat_x/{}.png'.format(str(idx)))
+ img = fxhat[idx, ...]
+ img = img.astype(np.uint8)
+ img = Image.fromarray(img)
+ img.save('plot/feat_x_hat/{}.png'.format(str(idx)))
+ import ipdb; ipdb.set_trace()
+ """
+
+ # compute Gram matrix for x and x_hat
+ G_x = self.gram_matrix(feat_x)
+ G_x_hat = self.gram_matrix(feat_x_hat)
+
+ # compute layer wise loss and aggregate
+ loss += custom_loss(
+ G_x, G_x_hat, mask=None, loss_type=self.distance, include_bkgd=True
+ )
+
+ loss = loss / len(act_x)
+
+ return loss
+
+ def forward(self, x, x_hat, mask1=None, mask2=None):
+ x = x.cuda()
+ x_hat = x_hat.cuda()
+
+ # resize images to 256px resolution
+ N, C, H, W = x.shape
+ upsample2d = nn.Upsample(
+ scale_factor=256 / H, mode="bilinear", align_corners=True
+ )
+
+ x = upsample2d(x)
+ x_hat = upsample2d(x_hat)
+
+ loss = self.cal_style(self.vgg16_act, x, x_hat, mask1=mask1, mask2=mask2)
+
+ return loss
diff --git a/losses/style/vgg_activations.py b/losses/style/vgg_activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..42ef45a5c585cfa4ddf2a10186046887a7edb255
--- /dev/null
+++ b/losses/style/vgg_activations.py
@@ -0,0 +1,187 @@
+import torch
+import torch.nn as nn
+
+import torchvision.models as models
+
+
+def requires_grad(model, flag=True):
+ for p in model.parameters():
+ p.requires_grad = flag
+
+
+class VGG16_Activations(nn.Module):
+ def __init__(self, feature_idx):
+ super(VGG16_Activations, self).__init__()
+ vgg16 = models.vgg16(pretrained=True)
+ features = list(vgg16.features)
+ self.features = nn.ModuleList(features).eval()
+ self.layer_id_list = feature_idx
+
+ def forward(self, x):
+ activations = []
+ for i, model in enumerate(self.features):
+ x = model(x)
+ if i in self.layer_id_list:
+ activations.append(x)
+
+ return activations
+
+
+class VGG19_Activations(nn.Module):
+ def __init__(self, feature_idx, requires_grad=False):
+ super(VGG19_Activations, self).__init__()
+ vgg19 = models.vgg19(pretrained=True)
+ requires_grad(vgg19, flag=False)
+ features = list(vgg19.features)
+ self.features = nn.ModuleList(features).eval()
+ self.layer_id_list = feature_idx
+
+ def forward(self, x):
+ activations = []
+ for i, model in enumerate(self.features):
+ x = model(x)
+ if i in self.layer_id_list:
+ activations.append(x)
+
+ return activations
+
+
+# http://www.robots.ox.ac.uk/~albanie/models/pytorch-mcn/vgg_face_dag.py
+class Vgg_face_dag(nn.Module):
+ def __init__(self):
+ super(Vgg_face_dag, self).__init__()
+ self.meta = {
+ "mean": [129.186279296875, 104.76238250732422, 93.59396362304688],
+ "std": [1, 1, 1],
+ "imageSize": [224, 224, 3],
+ }
+ self.conv1_1 = nn.Conv2d(
+ 3, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu1_1 = nn.ReLU(inplace=True)
+ self.conv1_2 = nn.Conv2d(
+ 64, 64, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu1_2 = nn.ReLU(inplace=True)
+ self.pool1 = nn.MaxPool2d(
+ kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
+ )
+ self.conv2_1 = nn.Conv2d(
+ 64, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu2_1 = nn.ReLU(inplace=True)
+ self.conv2_2 = nn.Conv2d(
+ 128, 128, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu2_2 = nn.ReLU(inplace=True)
+ self.pool2 = nn.MaxPool2d(
+ kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
+ )
+ self.conv3_1 = nn.Conv2d(
+ 128, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu3_1 = nn.ReLU(inplace=True)
+ self.conv3_2 = nn.Conv2d(
+ 256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu3_2 = nn.ReLU(inplace=True)
+ self.conv3_3 = nn.Conv2d(
+ 256, 256, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu3_3 = nn.ReLU(inplace=True)
+ self.pool3 = nn.MaxPool2d(
+ kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
+ )
+ self.conv4_1 = nn.Conv2d(
+ 256, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu4_1 = nn.ReLU(inplace=True)
+ self.conv4_2 = nn.Conv2d(
+ 512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu4_2 = nn.ReLU(inplace=True)
+ self.conv4_3 = nn.Conv2d(
+ 512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu4_3 = nn.ReLU(inplace=True)
+ self.pool4 = nn.MaxPool2d(
+ kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
+ )
+ self.conv5_1 = nn.Conv2d(
+ 512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu5_1 = nn.ReLU(inplace=True)
+ self.conv5_2 = nn.Conv2d(
+ 512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu5_2 = nn.ReLU(inplace=True)
+ self.conv5_3 = nn.Conv2d(
+ 512, 512, kernel_size=[3, 3], stride=(1, 1), padding=(1, 1)
+ )
+ self.relu5_3 = nn.ReLU(inplace=True)
+ self.pool5 = nn.MaxPool2d(
+ kernel_size=[2, 2], stride=[2, 2], padding=0, dilation=1, ceil_mode=False
+ )
+ self.fc6 = nn.Linear(in_features=25088, out_features=4096, bias=True)
+ self.relu6 = nn.ReLU(inplace=True)
+ self.dropout6 = nn.Dropout(p=0.5)
+ self.fc7 = nn.Linear(in_features=4096, out_features=4096, bias=True)
+ self.relu7 = nn.ReLU(inplace=True)
+ self.dropout7 = nn.Dropout(p=0.5)
+ self.fc8 = nn.Linear(in_features=4096, out_features=2622, bias=True)
+
+ def forward(self, x):
+ activations = []
+ x1 = self.conv1_1(x)
+ activations.append(x1)
+
+ x2 = self.relu1_1(x1)
+ x3 = self.conv1_2(x2)
+ x4 = self.relu1_2(x3)
+ x5 = self.pool1(x4)
+ x6 = self.conv2_1(x5)
+ activations.append(x6)
+
+ x7 = self.relu2_1(x6)
+ x8 = self.conv2_2(x7)
+ x9 = self.relu2_2(x8)
+ x10 = self.pool2(x9)
+ x11 = self.conv3_1(x10)
+ activations.append(x11)
+
+ x12 = self.relu3_1(x11)
+ x13 = self.conv3_2(x12)
+ x14 = self.relu3_2(x13)
+ x15 = self.conv3_3(x14)
+ x16 = self.relu3_3(x15)
+ x17 = self.pool3(x16)
+ x18 = self.conv4_1(x17)
+ activations.append(x18)
+
+ x19 = self.relu4_1(x18)
+ x20 = self.conv4_2(x19)
+ x21 = self.relu4_2(x20)
+ x22 = self.conv4_3(x21)
+ x23 = self.relu4_3(x22)
+ x24 = self.pool4(x23)
+ x25 = self.conv5_1(x24)
+ activations.append(x25)
+
+ """
+ x26 = self.relu5_1(x25)
+ x27 = self.conv5_2(x26)
+ x28 = self.relu5_2(x27)
+ x29 = self.conv5_3(x28)
+ x30 = self.relu5_3(x29)
+ x31_preflatten = self.pool5(x30)
+ x31 = x31_preflatten.view(x31_preflatten.size(0), -1)
+ x32 = self.fc6(x31)
+ x33 = self.relu6(x32)
+ x34 = self.dropout6(x33)
+ x35 = self.fc7(x34)
+ x36 = self.relu7(x35)
+ x37 = self.dropout7(x36)
+ x38 = self.fc8(x37)
+ """
+
+ return activations
diff --git a/losses/vgg_loss.py b/losses/vgg_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..4194c6b660008868d852e290faf63f34b3894656
--- /dev/null
+++ b/losses/vgg_loss.py
@@ -0,0 +1,51 @@
+import torch
+import torchvision
+import torch.nn as nn
+
+class VGG19(torch.nn.Module):
+ def __init__(self, requires_grad=False):
+ super().__init__()
+ vgg_pretrained_features = torchvision.models.vgg19(pretrained=True).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ for x in range(2):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(2, 7):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(7, 12):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(12, 21):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(21, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h_relu1 = self.slice1(X)
+ h_relu2 = self.slice2(h_relu1)
+ h_relu3 = self.slice3(h_relu2)
+ h_relu4 = self.slice4(h_relu3)
+ h_relu5 = self.slice5(h_relu4)
+ out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
+ return out
+
+
+# Perceptual loss that uses a pretrained VGG network
+class VGGLoss(nn.Module):
+ def __init__(self):
+ super(VGGLoss, self).__init__()
+ self.vgg = VGG19().cuda()
+ self.criterion = nn.L1Loss()
+ self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
+
+ def forward(self, x, y):
+ x_vgg, y_vgg = self.vgg(x), self.vgg(y)
+ loss = 0
+ for i in range(len(x_vgg)):
+ loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach())
+ return loss
diff --git a/main.py b/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ec1b92ec705000941d68e7cfb30fcd691834efc
--- /dev/null
+++ b/main.py
@@ -0,0 +1,80 @@
+import argparse
+import os
+import sys
+from pathlib import Path
+
+from torchvision.utils import save_image
+from tqdm.auto import tqdm
+
+from hair_swap import HairFast, get_parser
+
+
+def main(model_args, args):
+ hair_fast = HairFast(model_args)
+
+ experiments: list[str | tuple[str, str, str]] = []
+ if args.file_path is not None:
+ with open(args.file_path, 'r') as file:
+ experiments.extend(file.readlines())
+
+ if all(path is not None for path in (args.face_path, args.shape_path, args.color_path)):
+ experiments.append((args.face_path, args.shape_path, args.color_path))
+
+ for exp in tqdm(experiments):
+ if isinstance(exp, str):
+ file_1, file_2, file_3 = exp.split()
+ else:
+ file_1, file_2, file_3 = exp
+
+ face_path = args.input_dir / file_1
+ shape_path = args.input_dir / file_2
+ color_path = args.input_dir / file_3
+
+ base_name = '_'.join([path.stem for path in (face_path, shape_path, color_path)])
+ exp_name = base_name if model_args.save_all else None
+
+ if isinstance(exp, str) or args.result_path is None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ output_image_path = args.output_dir / f'{base_name}.png'
+ else:
+ os.makedirs(args.result_path.parent, exist_ok=True)
+ output_image_path = args.result_path
+
+ final_image = hair_fast.swap(face_path, shape_path, color_path, benchmark=args.benchmark, exp_name=exp_name)
+ save_image(final_image, output_image_path)
+
+
+if __name__ == "__main__":
+ model_parser = get_parser()
+ parser = argparse.ArgumentParser(description='HairFast evaluate')
+ parser.add_argument('--input_dir', type=Path, default='', help='The directory of the images to be inverted')
+ parser.add_argument('--benchmark', action='store_true', help='Calculates the speed of the method during the session')
+
+ # Arguments for a set of experiments
+ parser.add_argument('--file_path', type=Path, default=None,
+ help='File with experiments with the format "face_path.png shape_path.png color_path.png"')
+ parser.add_argument('--output_dir', type=Path, default=Path('output'), help='The directory for final results')
+
+ # Arguments for single experiment
+ parser.add_argument('--face_path', type=Path, default=None, help='Path to the face image')
+ parser.add_argument('--shape_path', type=Path, default=None, help='Path to the shape image')
+ parser.add_argument('--color_path', type=Path, default=None, help='Path to the color image')
+ parser.add_argument('--result_path', type=Path, default=None, help='Path to save the result')
+
+ args, unknown1 = parser.parse_known_args()
+ model_args, unknown2 = model_parser.parse_known_args()
+
+ unknown_args = set(unknown1) & set(unknown2)
+ if unknown_args:
+ file_ = sys.stderr
+ print(f"Unknown arguments: {unknown_args}", file=file_)
+
+ print("\nExpected arguments for the model:", file=file_)
+ model_parser.print_help(file=file_)
+
+ print("\nExpected arguments for evaluate:", file=file_)
+ parser.print_help(file=file_)
+
+ sys.exit(1)
+
+ main(model_args, args)
diff --git a/models/.DS_Store b/models/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..a9e2fa569183c06b0259e640bec0059bf7055292
Binary files /dev/null and b/models/.DS_Store differ
diff --git a/models/Alignment.py b/models/Alignment.py
new file mode 100644
index 0000000000000000000000000000000000000000..062fafc43f924a556112b5bc3c937b38b8337a8c
--- /dev/null
+++ b/models/Alignment.py
@@ -0,0 +1,181 @@
+import torch
+import torch.nn.functional as F
+import torchvision.transforms as T
+from torch import nn
+
+from models.CtrlHair.shape_branch.config import cfg as cfg_mask
+from models.CtrlHair.shape_branch.solver import get_hair_face_code, get_new_shape, Solver as SolverMask
+from models.Encoders import RotateModel
+from models.Net import Net, get_segmentation
+from models.sean_codes.models.pix2pix_model import Pix2PixModel, SEAN_OPT, encode_sean, decode_sean
+from utils.image_utils import DilateErosion
+from utils.save_utils import save_vis_mask, save_gen_image, save_latents
+
+
+class Alignment(nn.Module):
+ """
+ Module for transferring the desired hair shape
+ """
+
+ def __init__(self, opts, latent_encoder=None, net=None):
+ super().__init__()
+ self.opts = opts
+ self.latent_encoder = latent_encoder
+ if not net:
+ self.net = Net(self.opts)
+ else:
+ self.net = net
+
+ self.sean_model = Pix2PixModel(SEAN_OPT)
+ self.sean_model.eval()
+
+ solver_mask = SolverMask(cfg_mask, device=self.opts.device, local_rank=-1, training=False)
+ self.mask_generator = solver_mask.gen
+ self.mask_generator.load_state_dict(torch.load('pretrained_models/ShapeAdaptor/mask_generator.pth'))
+
+ self.rotate_model = RotateModel()
+ self.rotate_model.load_state_dict(torch.load(self.opts.rotate_checkpoint)['model_state_dict'])
+ self.rotate_model.to(self.opts.device).eval()
+
+ self.dilate_erosion = DilateErosion(dilate_erosion=self.opts.smooth, device=self.opts.device)
+ self.to_bisenet = T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
+
+ @torch.inference_mode()
+ def shape_module(self, im_name1: str, im_name2: str, name_to_embed, only_target=True, **kwargs):
+ device = self.opts.device
+
+ # load images
+ img1_in = name_to_embed[im_name1]['image_256']
+ img2_in = name_to_embed[im_name2]['image_256']
+
+ # load latents
+ latent_W_1 = name_to_embed[im_name1]["W"]
+ latent_W_2 = name_to_embed[im_name2]["W"]
+
+ # load masks
+ inp_mask1 = name_to_embed[im_name1]['mask']
+ inp_mask2 = name_to_embed[im_name2]['mask']
+
+ # Rotate stage
+ if img1_in is not img2_in:
+ rotate_to = self.rotate_model(latent_W_2[:, :6], latent_W_1[:, :6])
+ rotate_to = torch.cat((rotate_to, latent_W_2[:, 6:]), dim=1)
+ I_rot, _ = self.net.generator([rotate_to], input_is_latent=True, return_latents=False)
+
+ I_rot_to_seg = ((I_rot + 1) / 2).clip(0, 1)
+ I_rot_to_seg = self.to_bisenet(I_rot_to_seg)
+ rot_mask = get_segmentation(I_rot_to_seg)
+ else:
+ I_rot = None
+ rot_mask = inp_mask2
+
+ # Shape Adaptor
+ if img1_in is not img2_in:
+ face_1, hair_1 = get_hair_face_code(self.mask_generator, inp_mask1[0, 0, ...])
+ face_2, hair_2 = get_hair_face_code(self.mask_generator, rot_mask[0, 0, ...])
+
+ target_mask = get_new_shape(self.mask_generator, face_1, hair_2)[None, None]
+ else:
+ target_mask = inp_mask1
+
+ # Hair mask
+ hair_mask_target = torch.where(target_mask == 13, torch.ones_like(target_mask, device=device),
+ torch.zeros_like(target_mask, device=device))
+
+ if self.opts.save_all:
+ exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
+ output_dir = self.opts.save_all_dir / exp_name
+ if I_rot is not None:
+ save_gen_image(output_dir, 'Shape', f'{im_name2}_rotate_to_{im_name1}.png', I_rot)
+ save_vis_mask(output_dir, 'Shape', f'mask_{im_name1}.png', inp_mask1)
+ save_vis_mask(output_dir, 'Shape', f'mask_{im_name2}.png', inp_mask2)
+ save_vis_mask(output_dir, 'Shape', f'mask_{im_name2}_rotate_to_{im_name1}.png', rot_mask)
+ save_vis_mask(output_dir, 'Shape', f'mask_{im_name1}_{im_name2}_target.png', target_mask)
+
+ if only_target:
+ return {'HM_X': hair_mask_target}
+ else:
+ hair_mask1 = torch.where(inp_mask1 == 13, torch.ones_like(inp_mask1, device=device),
+ torch.zeros_like(inp_mask1, device=device))
+ hair_mask2 = torch.where(inp_mask2 == 13, torch.ones_like(inp_mask2, device=device),
+ torch.zeros_like(inp_mask2, device=device))
+
+ return inp_mask1, hair_mask1, inp_mask2, hair_mask2, target_mask, hair_mask_target
+
+ @torch.inference_mode()
+ def align_images(self, im_name1, im_name2, name_to_embed, **kwargs):
+ # load images
+ img1_in = name_to_embed[im_name1]['image_256']
+ img2_in = name_to_embed[im_name2]['image_256']
+
+ # load latents
+ latent_S_1, latent_F_1 = name_to_embed[im_name1]["S"], name_to_embed[im_name1]["F"]
+ latent_S_2, latent_F_2 = name_to_embed[im_name2]["S"], name_to_embed[im_name2]["F"]
+
+ # Shape Module
+ if img1_in is img2_in:
+ hair_mask_target = self.shape_module(im_name1, im_name2, name_to_embed, only_target=True, **kwargs)['HM_X']
+ return {'latent_F_align': latent_F_1, 'HM_X': hair_mask_target}
+
+ inp_mask1, hair_mask1, inp_mask2, hair_mask2, target_mask, hair_mask_target = (
+ self.shape_module(im_name1, im_name2, name_to_embed, only_target=False, **kwargs)
+ )
+
+ images = torch.cat([img1_in, img2_in], dim=0)
+ labels = torch.cat([inp_mask1, inp_mask2], dim=0)
+
+ # SEAN for inpaint
+ img1_code, img2_code = encode_sean(self.sean_model, images, labels)
+
+ gen1_sean = decode_sean(self.sean_model, img1_code.unsqueeze(0), target_mask)
+ gen2_sean = decode_sean(self.sean_model, img2_code.unsqueeze(0), target_mask)
+
+ # Encoding result in F from E4E
+ enc_imgs = self.latent_encoder([gen1_sean, gen2_sean])
+ intermediate_align, latent_inter = enc_imgs["F"][0].unsqueeze(0), enc_imgs["W"][0].unsqueeze(0)
+ latent_F_out_new, latent_out = enc_imgs["F"][1].unsqueeze(0), enc_imgs["W"][1].unsqueeze(0)
+
+ # Alignment of F space
+ masks = [
+ 1 - (1 - hair_mask1) * (1 - hair_mask_target),
+ hair_mask_target,
+ hair_mask2 * hair_mask_target
+ ]
+ masks = torch.cat(masks, dim=0)
+ # masks = T.functional.resize(masks, (1024, 1024), interpolation=T.InterpolationMode.NEAREST)
+
+ dilate, erosion = self.dilate_erosion.mask(masks)
+ free_mask = [
+ dilate[0],
+ erosion[1],
+ erosion[2]
+ ]
+ free_mask = torch.stack(free_mask, dim=0)
+ free_mask_down_32 = F.interpolate(free_mask.float(), size=(32, 32), mode='bicubic')
+ interpolation_low = 1 - free_mask_down_32
+
+ latent_F_align = intermediate_align + interpolation_low[0] * (latent_F_1 - intermediate_align)
+ latent_F_align = latent_F_out_new + interpolation_low[1] * (latent_F_align - latent_F_out_new)
+ latent_F_align = latent_F_2 + interpolation_low[2] * (latent_F_align - latent_F_2)
+
+ if self.opts.save_all:
+ exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
+ output_dir = self.opts.save_all_dir / exp_name
+ save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_SEAN.png', gen1_sean)
+ save_gen_image(output_dir, 'Align', f'{im_name2}_{im_name1}_SEAN.png', gen2_sean)
+
+ img1_e4e = self.net.generator([latent_inter], input_is_latent=True, return_latents=False, start_layer=4,
+ end_layer=8, layer_in=intermediate_align)[0]
+ img2_e4e = self.net.generator([latent_out], input_is_latent=True, return_latents=False, start_layer=4,
+ end_layer=8, layer_in=latent_F_out_new)[0]
+
+ save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_e4e.png', img1_e4e)
+ save_gen_image(output_dir, 'Align', f'{im_name2}_{im_name1}_e4e.png', img2_e4e)
+
+ gen_im, _ = self.net.generator([latent_S_1], input_is_latent=True, return_latents=False, start_layer=4,
+ end_layer=8, layer_in=latent_F_align)
+
+ save_gen_image(output_dir, 'Align', f'{im_name1}_{im_name2}_output.png', gen_im)
+ save_latents(output_dir, 'Align', f'{im_name1}_{im_name2}_F.npz', latent_F_align=latent_F_align)
+
+ return {'latent_F_align': latent_F_align, 'HM_X': hair_mask_target}
diff --git a/models/Blending.py b/models/Blending.py
new file mode 100644
index 0000000000000000000000000000000000000000..e7dcc87a7a1bdfc39a1b7f03be945fb06f791801
--- /dev/null
+++ b/models/Blending.py
@@ -0,0 +1,81 @@
+import torch
+from torch import nn
+
+from models.Encoders import ClipBlendingModel, PostProcessModel
+from models.Net import Net
+from utils.bicubic import BicubicDownSample
+from utils.image_utils import DilateErosion
+from utils.save_utils import save_gen_image, save_latents
+
+
+class Blending(nn.Module):
+ """
+ Module for transferring the desired hair color and post processing
+ """
+
+ def __init__(self, opts, net=None):
+ super().__init__()
+ self.opts = opts
+ if net is None:
+ self.net = Net(self.opts)
+ else:
+ self.net = net
+
+ blending_checkpoint = torch.load(self.opts.blending_checkpoint)
+ self.blending_encoder = ClipBlendingModel(blending_checkpoint.get('clip', "ViT-B/32"))
+ self.blending_encoder.load_state_dict(blending_checkpoint['model_state_dict'], strict=False)
+ self.blending_encoder.to(self.opts.device).eval()
+
+ self.post_process = PostProcessModel().to(self.opts.device).eval()
+ self.post_process.load_state_dict(torch.load(self.opts.pp_checkpoint)['model_state_dict'])
+
+ self.dilate_erosion = DilateErosion(dilate_erosion=self.opts.smooth, device=self.opts.device)
+ self.downsample_256 = BicubicDownSample(factor=4)
+
+ @torch.inference_mode()
+ def blend_images(self, align_shape, align_color, name_to_embed, **kwargs):
+ I_1 = name_to_embed['face']['image_norm_256']
+ I_2 = name_to_embed['shape']['image_norm_256']
+ I_3 = name_to_embed['color']['image_norm_256']
+
+ mask_de = self.dilate_erosion.hair_from_mask(
+ torch.cat([name_to_embed[x]['mask'] for x in ['face', 'color']], dim=0)
+ )
+ HM_1D, _ = mask_de[0][0].unsqueeze(0), mask_de[1][0].unsqueeze(0)
+ HM_3D, HM_3E = mask_de[0][1].unsqueeze(0), mask_de[1][1].unsqueeze(0)
+
+ latent_S_1, latent_F_align = name_to_embed['face']['S'], align_shape['latent_F_align']
+ HM_X = align_color['HM_X']
+
+ latent_S_3 = name_to_embed['color']["S"]
+
+ HM_XD, _ = self.dilate_erosion.mask(HM_X)
+ target_mask = (1 - HM_1D) * (1 - HM_3D) * (1 - HM_XD)
+
+ # Blending
+ if I_1 is not I_3 or I_1 is not I_2:
+ S_blend_6_18 = self.blending_encoder(latent_S_1[:, 6:], latent_S_3[:, 6:], I_1 * target_mask, I_3 * HM_3E)
+ S_blend = torch.cat((latent_S_1[:, :6], S_blend_6_18), dim=1)
+ else:
+ S_blend = latent_S_1
+
+ I_blend, _ = self.net.generator([S_blend], input_is_latent=True, return_latents=False, start_layer=4,
+ end_layer=8, layer_in=latent_F_align)
+ I_blend_256 = self.downsample_256(I_blend)
+
+ # Post Process
+ S_final, F_final = self.post_process(I_1, I_blend_256)
+ I_final, _ = self.net.generator([S_final], input_is_latent=True, return_latents=False,
+ start_layer=5, end_layer=8, layer_in=F_final)
+
+ if self.opts.save_all:
+ exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
+ output_dir = self.opts.save_all_dir / exp_name
+ save_gen_image(output_dir, 'Blending', 'blending.png', I_blend)
+ save_latents(output_dir, 'Blending', 'blending.npz', S_blend=S_blend)
+
+ save_gen_image(output_dir, 'Final', 'final.png', I_final)
+ save_latents(output_dir, 'Final', 'final.npz', S_final=S_final, F_final=F_final)
+
+ final_image = ((I_final[0] + 1) / 2).clip(0, 1)
+ return final_image
diff --git a/models/CtrlHair/.gitignore b/models/CtrlHair/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..ed7a7d64d933d04668e59c7ea3b88c1460e6a766
--- /dev/null
+++ b/models/CtrlHair/.gitignore
@@ -0,0 +1,8 @@
+.idea/
+.DS_Store
+/dataset_info_ctrlhair/
+/external_model_params/
+/model_trained/
+**/__pycache__/**
+
+
diff --git a/models/CtrlHair/README.md b/models/CtrlHair/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6111f3531fe612e0bab5efb53e7ad388cbb198a4
--- /dev/null
+++ b/models/CtrlHair/README.md
@@ -0,0 +1,270 @@
+# [GAN with Multivariate Disentangling for Controllable Hair Editing (ECCV 2022)](https://github.com/XuyangGuo/xuyangguo.github.io/raw/master/database/CtrlHair/CtrlHair.pdf)
+
+[Xuyang Guo](https://xuyangguo.github.io/), [Meina Kan](http://vipl.ict.ac.cn/homepage/mnkan/Publication/), Tianle Chen, [Shiguang Shan](https://scholar.google.com/citations?user=Vkzd7MIAAAAJ)
+
+
+
+
+
+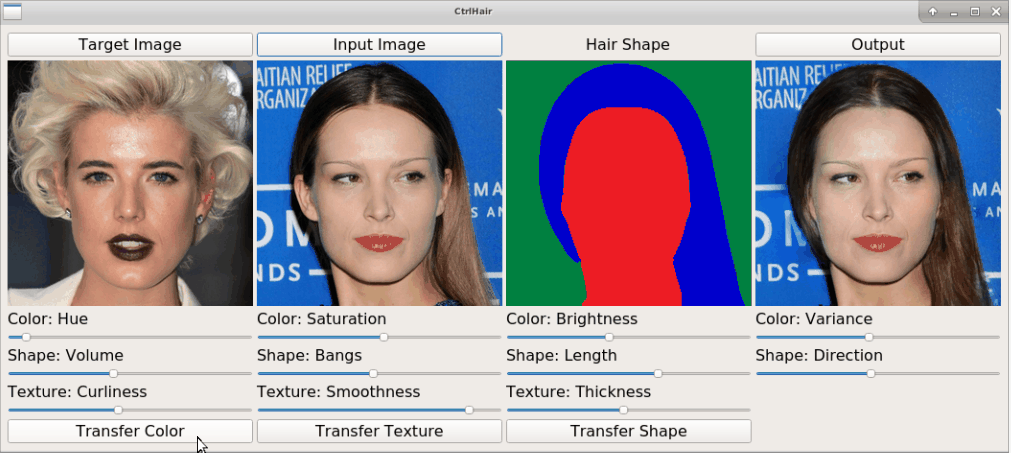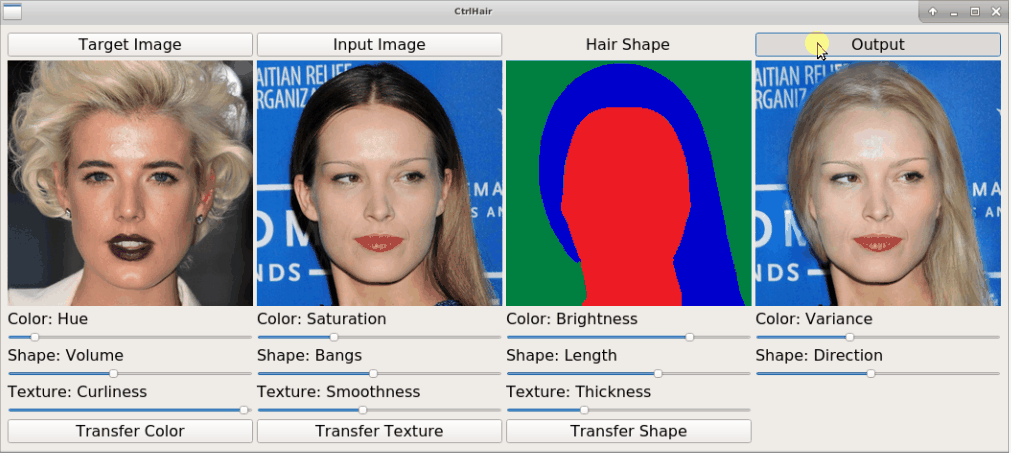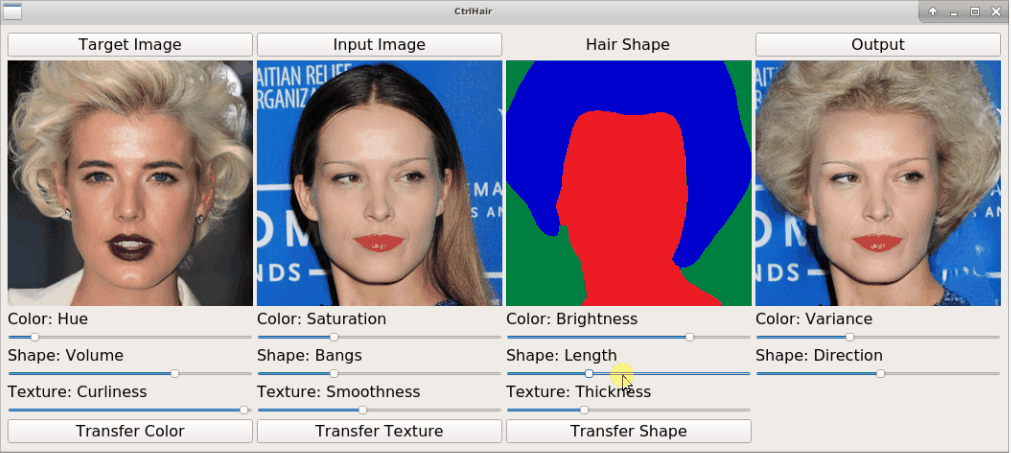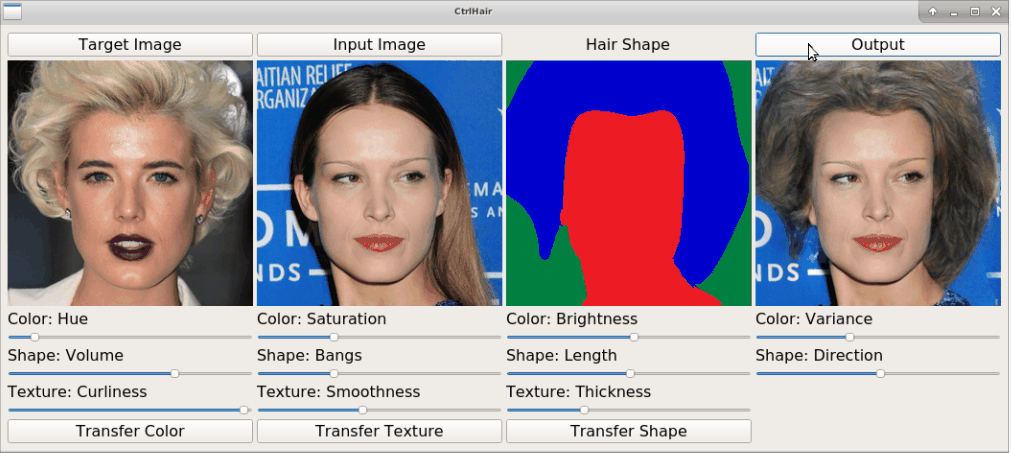
+
+## Abstract
+
+> Hair editing is an essential but challenging task in portrait editing considering the complex geometry and material of hair. Existing methods have achieved promising results by editing through a reference photo, user-painted mask, or guiding strokes. However, when a user provides no reference photo or hardly paints a desirable mask, these works fail to edit. Going a further step, we propose an efficiently controllable method that can provide a set of sliding bars to do continuous and fine hair editing. Meanwhile, it also naturally supports discrete editing through a reference photo and user-painted mask. Specifically, we propose a generative adversarial network with a multivariate Gaussian disentangling module. Firstly, an encoder disentangles the hair's major attributes, including color, texture, and shape, to separate latent representations. The latent representation of each attribute is modeled as a standard multivariate Gaussian distribution, to make each dimension of an attribute be changed continuously and finely. Benefiting from the Gaussian distribution, any manual editing including sliding a bar, providing a reference photo, and painting a mask can be easily made, which is flexible and friendly for users to interact with. Finally, with changed latent representations, the decoder outputs a portrait with the edited hair. Experiments show that our method can edit each attribute's dimension continuously and separately. Besides, when editing through reference images and painted masks like existing methods, our method achieves comparable results in terms of FID and visualization. Codes can be found at [https://github.com/XuyangGuo/CtrlHair](https://github.com/XuyangGuo/CtrlHair).
+
+
+
+
+## Installation
+
+Clone this repo.
+
+```bash
+git clone https://github.com/XuyangGuo/CtrlHair.git
+cd CtrlHair
+```
+
+The code requires python 3.6.
+
+We recommend using Anaconda to regulate packages.
+
+Dependencies:
+- PyTorch 1.8.2
+- torchvision, tensorboardX, dlib
+- pillow, pandas, scikit-learn, opencv-python
+- PyQt5, tqdm, addict, dill
+
+Please download all [external trained models](https://drive.google.com/drive/folders/1X0y82o7-JB6nGYIWdbbJa4MTFbtV9bei?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1vnldtoT9G-5gfvUjjUSVOA?pwd=1234) with password `1234` alternatively), move it to `./` with the correct path `CtrlHair/external_model_params`. (The directory contains the model parameters of face analysis tools required by our project, including SEAN for face encoding and generator with masks, BiSeNet for face parsing, and 68/81 facial landmark detector.)
+
+## Editing by Pretrained Model
+
+Firstly, refer to the "Installation" section above.
+
+Please download [the pre-trained model of CtrlHair](https://drive.google.com/drive/folders/1opQhmc7ckS3J8qdLii_EMqmxYCcBLznO?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1O_Hu5dnk4GwmUrIBDWpwFA?pwd=1234) with password `1234` alternatively), move it to `./` with the correct path `CtrlHair/model_trained`.
+
+#### Editing with UI directly (recommended)
+
+```bash
+python ui/frontend_demo.py
+```
+
+Here are some parameters of it:
+
+- `-g D` Use the gpu `D`. (default is `0`)
+- `-n True|False` Whether the input image need crop. (default is `True`)
+- `--no_blending` Do not use poisson blending as post processing. If not blend, the result image will look slightly different from the input image in some details in non-hair region, but the image quality will be better.
+
+The edited results can be found in `temp_folder/demo_output/out_img.png`, and the edited shape is in `temp_folder/demo_output/input_parsing.png`. The `temp_folder` is created automaticly during running, which could be removed after closing the procedure.
+
+#### Editing with Batch
+
+If you want to edit with a mass batch, or want to achieve editing functions such as interpolation, multi style sampling, and continuous gradient, etc, please use the interfaces of `ui/backend.py/Backend` and code your own python script.`Backend` class is the convenient encapsulation of basic functions of CtrlHair, and there are detailed comments for each function. The `main` scetion in the final of `backend.py` shows an simle example of usage of `Backend`.
+
+## Training New Models
+
+#### Data Preparation
+In addition to the images in the dataset, training also involves many image annotations, including face parsing, facial landmarks, sean codes, color annotations, face rotation angle, a small amount of annotations (Curliness of Hair), etc.
+
+Please download [the dataset information](https://drive.google.com/drive/folders/10p87Mobgueg9rdHyLPkX8xqEIvga6p2C?usp=sharing) ([using Baidu Netdisk](https://pan.baidu.com/s/1D3D2JqxIR6miCeMNssucKw?pwd=1234) with password `1234` alternatively) that we have partially processed, move it to `./` with the correct path `CtrlHair/dataset_info_ctrlhair`.
+
+Then execute the following scripts sequentially for preprocessing.
+
+Get facial segmentation mask
+```bash
+python dataset_scripts/script_get_mask.py
+```
+
+Get 68 facial landmarks and 81 facial landmarks
+```bash
+python dataset_scripts/script_landmark_detection.py
+```
+
+Get SEAN feature codes of the dataset
+```bash
+python dataset_scripts/script_get_sean_code.py
+```
+
+Get color label of the dataset
+```bash
+python dataset_scripts/script_get_rgb_hsv_label.py
+python dataset_scripts/script_color_var_label.py
+```
+
+After complete processing, for training, the correct directory structure in `CtrlHair/dataset_info_ctrlhair` is as follows:
+
+- `CelebaMask_HQ` / `ffhq` (if you want to add your own dataset, please regulate them as these two cases)
+ - `images_256` -> cropped images with the resolution 256.
+ - `label` -> mask label (0, 1, 2, ..., 20) for each pixel
+ - `angle.csv` restore face rotation angle of each image
+ - `attr_gender.csv` restore gender of each image
+- `color_var_stat_dict.pkl`, `rgb_stat_dict.pkl`, `hsv_stat_dict_ordered.pkl` store the label of variance, rgb of hair color, and the hsv distribution
+- `sean_code_dict.pkl` store the sean feature code of images in dataset
+- `landmark68.pkl`, `landmark81.pkl` store the facial landmarks of the dataset
+- `manual_label`
+ - `curliness`
+ - `-1.txt`, `1.txt`, `test_1.txt`, `test_-1.txt` labeled data list
+
+#### Training Networks
+In order to better control the parameters in the model, we train the entire model separately and divide it into four parts, including curliness classifier, color encoder, color & texture branch, shape branch.
+
+**1. Train the curliness classifier**
+```bash
+python color_texture_branch/predictor/predictor_train.py -c p002 -g 0
+```
+
+Here are some parameters of it:
+
+- `-g D` Use the gpu `D`. (default is `0`)
+- `-c pxxx` Using the model hyper-parameters config named `pxxx`. Please see the config detail in `color_texture_branch/predictor/predictor_config.py`
+
+The trained model and its tensorboard summary are saved in `model_trained/curliness_classifier`.
+
+**2. Train the color encoder**
+```bash
+python color_texture_branch/predictor/predictor_train.py -c p004 -g 0
+```
+
+The parameters are similar like the curliness classifier.
+
+The trained model and its tensorboard summary are saved in `model_trained/color_encoder`.
+
+**3. Train the color & texture branch**
+```bash
+python color_texture_branch/scripts.py -c 045 -g 0
+```
+
+This part depends on the curliness classifier and the color encoder as seen in `color_texture_branch/config.py`:
+
+```python
+...
+'predictor': {'curliness': 'p002', 'rgb': 'p004'},
+...
+```
+
+Here are some parameters of it:
+
+- `-g D` Use the gpu `D`. (default is `0`)
+- `-c xxx` Using the model hyper-parameters config named `xxx`. Please see the config detail in `color_texture_branch/config.py`
+
+The trained model, its tensorboard, editing results in training are saved in `model_trained/color_texture`.
+
+
+Since the training of texture is unsupervised, we need to find some semantic orthogonal directions after training for sliding bars. Please run:
+```bash
+python color_texture_branch/script_find_direction.py -c xxx
+```
+The parameter `-c xxx` is same as above shape config.
+This process will generate a folder named `direction_find` in the directory `model_trained/color_texture/yourConfigName`,
+where `direction_find/texture_dir_n` stores many random `n`-th directions to be selected,
+and the corresponding visual changes can be seen in `direction_find/texture_n`.
+When the choice is decided, move the corresponding `texture_dir_n/xxx.pkl` file to `../texture_dir_used` and rename it as you wish (the pretrained No.045 texture model shows an example).
+Afterthat, run `python color_texture_branch/script_find_direction.py -c xxx` again, and repeat the process until the amount of semantic directions is enough.
+
+
+**4. Train the shape branch**
+
+Shape editing employs a transfer-like training process. Before transferring, we use 68 feature points to pre-align the face of the target hairstyle, so as to achieve a certain degree of face adaptation. In order to speed up this process during training, it is necessary to generate some buffer pools to store the pre-aligned masks of the training set and test set respectively.
+
+Generate buffer pool for testing
+```bash
+python shape_branch/script_adaptor_test_pool.py
+```
+The testing buffer pool will be saved in `dataset_info_ctrlhair/shape_testing_wrap_pool`.
+
+Generate buffer pool for training
+```bash
+python shape_branch/script_adaptor_train_pool.py
+```
+The training buffer pool will be saved in `dataset_info_ctrlhair/shape_training_wrap_pool`.
+
+Note that the `script_adaptor_train_pool.py` process will execute for a very very long time until the setting of maximum number of files for buffering is reached.
+This process can be performed concurrently with the subsequent shape training process.
+The training data for shape training are all dynamically picked from this buffer pool.
+
+Training the shape branch model
+```bash
+python shape_branch/scripts.py -c 054 -g 0
+```
+
+Here are some parameters of it:
+
+- `-g D` Use the gpu `D`. (default is `0`)
+- `-c xxx` Using the model hyper-parameters config named `xxx`. Please see the config detail in `shape_branch/config.py`
+
+The trained model, its tensorboard, editing results in training are saved in `model_trained/shape`.
+
+Since the training is unsupervised, we need to find some semantic orthogonal directions after training for sliding bars. Please run:
+```bash
+python shape_branch/script_find_direction.py -c xxx
+```
+The parameter `-c xxx` is same as above shape config.
+The entire usage method is similar to texture, but the folder is changed to the `model_trained/shape` directory (the pretrained No.054 shape model shows an example).
+
+After all the above training, use `python ui/frontend_demo.py` to edit.
+You can also use interfaces in `ui/backend.py/Backend` to program your editing scripts.
+
+## Training New Models with Your Own Images Dataset
+
+Our method only needs unlabeled face images to augment the dataset, which is convenient and is a strength of CtrlHair.
+
+#### Data Preparation
+
+For your own images dataset, firstly, crop and resize them. Please collect them into a single directory, and modify `root_dir` and `dataset_name` for your dataset in `dataset_scripts/script_crop.py`. Then execute
+```bash
+python dataset_scripts/script_crop.py
+```
+After cropping, the dataset should be cropped at `dataset_info_ctrlhair/your_dataset_name/images_256`. Your dataset should have similar structure like `dataset_info_ctrlhair/ffhq`.
+
+Modify `DATASET_NAME` in `global_value_utils.py ` for your dataset.
+
+Do the same steps as the section "Data Preparation" of "Training New Models" in this README.
+
+Predict face rotation angle and gender for your dataset.
+This will be used to filter the dataset.
+You can use tools like [3DDFA](https://github.com/cleardusk/3DDFA) and [deepface](https://github.com/serengil/deepface), then output them to `angle.csv` and `attr_gender.csv` in `dataset_info_ctrlhair/yourdataset` (pandas is recommended for generating csv). `dataset_info_ctrlhair/ffhq` shows a preprocessing example.
+Sorry for that we don't provide these code. Alternatively, if you don't want to depend and use these filter, please modify `angle_filter` and `gender_filter` to `False` in `common_dataset.py`.
+
+#### Training Networks
+
+Add and adjust your config in `color_texture_branch/predictor/predictor_config.py`, `color_texture_branch/config.py`, `shape/config.py`.
+
+Do the same steps as the section "Training Networks" of "Training New Models" in this README, but with your config.
+
+Finally, change the `DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH` and `DEFAULT_CONFIG_SHAPE_BRANCH` as yours in `global_value_utils.py`.
+Use `python ui/frontend_demo.py` to edit. Or you can also use interfaces in `ui/backend.py/Backend` to program your editing scripts.
+
+
+## Code Structure
+- `color_texture_branch`: color and texture editing branch
+ - `predictor`: color encoder and curliness classifier
+- `shape_branch`: shape editing branch
+- `ui`: encapsulated backend interfaces and frontend UI
+- `dataset_scripts`: scripts for preprocessing dataset
+- `external_code`: codes of external tools
+- `sean_codes`: modified from SEAN project, which is used for image feature extraction and generation
+- `my_pylib`, `my_torchlib`, `utils`: auxiliary code library
+- `wrap_codes`: used for shape align before shape transfer
+- `dataset_info_ctrlhair`: the root directory of dataset
+- `model_trained`: trained model parameters, tensorboard and visual results during training
+- `external_model_params`: pretrained model parameters used for external codes
+- `imgs`: some example images are provided for testing
+
+## Citation
+If you use this code for your research, please cite our papers.
+```
+@inproceedings{guo2022gan,
+ title={GAN with Multivariate Disentangling for Controllable Hair Editing},
+ author={Guo, Xuyang and Kan, Meina and Chen, Tianle and Shan, Shiguang},
+ booktitle={European Conference on Computer Vision},
+ year={2022},
+ pages={655--670},
+ organization={Springer}
+}
+```
+
+This work is also inspired by our previous work [X. Guo, et al., STD-GAN (CVIU2021)](https://github.com/XuyangGuo/STD-GAN) for instance-level facial attributes editing.
+
+## References & Acknowledgments
+- [ZPdesu / SEAN](https://github.com/ZPdesu/SEAN)
+- [zhhoper / RI_render_DPR](https://github.com/zhhoper/RI_render_DPR)
+- [zllrunning / face-parsing.PyTorch](https://github.com/zllrunning/face-parsing.PyTorch)
diff --git a/models/CtrlHair/color_texture_branch/__init__.py b/models/CtrlHair/color_texture_branch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..01eede24e15d0c9bb2f34b35ae02d518c810373f
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py.py
+# Time : 2021/11/15 11:18
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/color_texture_branch/config.py b/models/CtrlHair/color_texture_branch/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..b161a1d470aa3b5ed9613a2976f6bd3538251c81
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/config.py
@@ -0,0 +1,141 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: config.py
+# Time : 2021/11/17 13:10
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import addict # nesting dict
+import os
+import argparse
+
+from global_value_utils import GLOBAL_DATA_ROOT, DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH
+
+configs = [
+ addict.Dict({
+ "experiment_name": "045__color_texture_final",
+ 'lambda_rgb': 0.01,
+ 'lambda_pca_std': 0.01,
+ 'noise_dim': 8,
+ 'filter_female_and_frontal': True,
+ 'g_hidden_layer_num': 4,
+ 'd_hidden_layer_num': 4,
+ 'lambda_moment_1': 0.01,
+ 'lambda_moment_2': 0.01,
+ 'lambda_cls_curliness': {0: 0.1},
+ 'lambda_info_curliness': 1.0,
+ 'lambda_info': 1.0,
+ 'curliness_dim': 1,
+ 'predictor': {'curliness': 'p002', 'rgb': 'p004'},
+ 'gan_input_from_encoder_prob': 0.3,
+ 'curliness_with_weight': True,
+ 'lambda_rec': 1000.0,
+ 'lambda_rec_img': {0: 0, 600000: 1000},
+ 'gen_mode': 'eigengan',
+ 'lambda_orthogonal': 0.1,
+ }),
+]
+
+
+def get_config(configs, config_id):
+ for c in configs:
+ if c.experiment_name.startswith(config_id):
+ check_add_default_value_to_base_cfg(c)
+ return c
+ cfg = addict.Dict({})
+ check_add_default_value_to_base_cfg(cfg)
+ return cfg
+
+
+def check_add_default_value_to_base_cfg(cfg):
+ add_default_value_to_cfg(cfg, 'lr_d', 0.0002)
+ add_default_value_to_cfg(cfg, 'lr_g', 0.0002)
+ add_default_value_to_cfg(cfg, 'beta1', 0.5)
+ add_default_value_to_cfg(cfg, 'beta2', 0.999)
+
+ add_default_value_to_cfg(cfg, 'total_step', 650100)
+ add_default_value_to_cfg(cfg, 'log_step', 10)
+ add_default_value_to_cfg(cfg, 'sample_step', 25000)
+ add_default_value_to_cfg(cfg, 'model_save_step', 20000)
+ add_default_value_to_cfg(cfg, 'sample_batch_size', 32)
+ add_default_value_to_cfg(cfg, 'max_save', 2)
+ add_default_value_to_cfg(cfg, 'vae_var_output', 'var')
+ add_default_value_to_cfg(cfg, 'SEAN_code', 512)
+
+ # Model configuration
+ add_default_value_to_cfg(cfg, 'total_batch_size', 128)
+ add_default_value_to_cfg(cfg, 'g_hidden_layer_num', 4)
+ add_default_value_to_cfg(cfg, 'd_hidden_layer_num', 4)
+ add_default_value_to_cfg(cfg, 'd_noise_hidden_layer_num', 3)
+ add_default_value_to_cfg(cfg, 'g_hidden_dim', 256)
+ add_default_value_to_cfg(cfg, 'd_hidden_dim', 256)
+ add_default_value_to_cfg(cfg, 'gan_type', 'wgan_gp')
+ add_default_value_to_cfg(cfg, 'lambda_gp', 10.0)
+ add_default_value_to_cfg(cfg, 'lambda_adv', 1.0)
+
+ add_default_value_to_cfg(cfg, 'noise_dim', 8)
+ add_default_value_to_cfg(cfg, 'g_norm', 'none')
+ add_default_value_to_cfg(cfg, 'd_norm', 'none')
+ add_default_value_to_cfg(cfg, 'g_activ', 'relu')
+ add_default_value_to_cfg(cfg, 'd_activ', 'lrelu')
+ add_default_value_to_cfg(cfg, 'init_type', 'normal')
+ add_default_value_to_cfg(cfg, 'G_D_train_num', {'G': 1, 'D': 1}, )
+
+ output_root_dir = 'model_trained/color_texture/%s' % cfg['experiment_name']
+ add_default_value_to_cfg(cfg, 'root_dir', output_root_dir)
+ add_default_value_to_cfg(cfg, 'log_dir', output_root_dir + '/logs')
+ add_default_value_to_cfg(cfg, 'model_save_dir', output_root_dir + '/models')
+ add_default_value_to_cfg(cfg, 'sample_dir', output_root_dir + '/samples')
+ try:
+ add_default_value_to_cfg(cfg, 'gpu_num', len(args.gpu.split(',')))
+ except:
+ add_default_value_to_cfg(cfg, 'gpu_num', 1)
+
+ add_default_value_to_cfg(cfg, 'data_root', GLOBAL_DATA_ROOT)
+
+
+def add_default_value_to_cfg(cfg, key, value):
+ if key not in cfg:
+ cfg[key] = value
+
+
+def merge_config_in_place(ori_cfg, new_cfg):
+ for k in new_cfg:
+ ori_cfg[k] = new_cfg[k]
+
+
+def back_process(cfg):
+ cfg.batch_size = cfg.total_batch_size // cfg.gpu_num
+ if cfg.predictor:
+ from color_texture_branch.predictor import predictor_config
+ for ke in cfg.predictor:
+ pred_cfg = predictor_config.get_config(predictor_config.configs, cfg.predictor[ke])
+ predictor_config.back_process(pred_cfg)
+ cfg.predictor[ke] = pred_cfg
+
+ if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
+ cfg.subspace_dim = cfg.noise_dim // cfg.g_hidden_layer_num
+
+
+def get_basic_arg_parser():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, help='Specify config number', default=DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH)
+ parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
+ parser.add_argument('--local_rank', type=int, default=-1)
+ return parser
+
+
+import sys
+
+if sys.argv[0].endswith('color_texture_branch/scripts.py'):
+ parser = get_basic_arg_parser()
+ args = parser.parse_args()
+ cfg = get_config(configs, args.config)
+ os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
+ back_process(cfg)
+else:
+ cfg = get_config(configs, DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH)
+ # cfg = get_config(configs, '046')
+ back_process(cfg)
diff --git a/models/CtrlHair/color_texture_branch/dataset.py b/models/CtrlHair/color_texture_branch/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..7af6f199871c8f550644ff907508f463ba3ad38d
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/dataset.py
@@ -0,0 +1,158 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: dataset.py
+# Time : 2021/11/16 21:24
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+
+from common_dataset import DataFilter
+
+import random
+import numpy as np
+from global_value_utils import HAIR_IDX, GLOBAL_DATA_ROOT
+import pickle
+import torch
+
+
+class Dataset:
+ """A general image-attributes dataset class."""
+
+ def valid_hair(self, item):
+ if np.isnan(self.rgb_stat_dict[item][0]).any(): # not have hair
+ return False
+ if (self.sean_code_dict[item][HAIR_IDX] == 0).all():
+ return False
+ if item not in self.color_var_stat_dict:
+ return False
+ return True
+
+ def __init__(self, cfg, rank=0, test_part=0.096):
+ # super().__init__()
+ self.cfg = cfg
+
+ self.random_seed = 7 # Do not change the random seed, which determines the split of scripts and test set
+ self.hair_root = GLOBAL_DATA_ROOT
+ with open(os.path.join(self.hair_root, 'sean_code_dict.pkl'), 'rb') as f:
+ self.sean_code_dict = pickle.load(f)
+ with open(os.path.join(self.hair_root, 'rgb_stat_dict.pkl'), 'rb') as f:
+ self.rgb_stat_dict = pickle.load(f)
+ with open(os.path.join(self.hair_root, 'color_var_stat_dict.pkl'), 'rb') as f:
+ self.color_var_stat_dict = pickle.load(f)
+
+ self.local_rank = rank
+ random.seed(self.random_seed + self.local_rank + 1)
+
+ self.data_list = [dd for dd in list(self.sean_code_dict) if self.valid_hair(dd)]
+ random.shuffle(self.data_list)
+
+ self.data_filter = DataFilter(cfg, test_part)
+
+ self.test_list = []
+ for ll in self.data_filter.test_list:
+ path_part = ll.split('/')
+ self.test_list.append('%s___%s' % (path_part[-3], path_part[-1][:-4]))
+
+ self.train_filter = []
+ for ll in self.data_filter.train_list:
+ path_part = ll.split('/')
+ self.train_filter.append('%s___%s' % (path_part[-3], path_part[-1][:-4]))
+ self.train_filter = set(self.train_filter)
+ self.train_list = [ll for ll in self.data_list if ll not in self.test_list]
+ if cfg.filter_female_and_frontal:
+ self.train_list = [ll for ll in self.train_list if ll in self.train_filter]
+ self.train_set = set(self.train_list)
+
+ ### curliness code
+ self.curliness_hair_list = {}
+ self.curliness_hair_list_test = {}
+ self.curliness_hair_dict = {ke: 0 for ke in self.color_var_stat_dict}
+
+ for label in [-1, 1]:
+ img_file = os.path.join(cfg.data_root, 'manual_label', 'curliness', '%d.txt' % label)
+ with open(img_file, 'r') as f:
+ imgs = [l.strip() for l in f.readlines()]
+ imgs = [ii for ii in imgs if ii in self.train_set]
+ self.curliness_hair_list[label] = imgs
+ for ii in imgs:
+ self.curliness_hair_dict[ii] = label
+
+ img_file = os.path.join(cfg.data_root, 'manual_label', 'curliness', 'test_%d.txt' % label)
+ with open(img_file, 'r') as f:
+ imgs = [l.strip() for l in f.readlines()]
+ self.curliness_hair_list_test[label] = imgs
+ for ii in imgs:
+ self.curliness_hair_dict[ii] = label
+
+ def get_sean_code(self, ke):
+ return self.sean_code_dict[ke]
+
+ def get_list_by_items(self, items):
+ res_code, res_rgb_mean, res_pca_std, res_sean_code, res_curliness = [], [], [], [], []
+ for item in items:
+ code = self.sean_code_dict[item][HAIR_IDX]
+ res_code.append(code)
+ rgb_mean = self.rgb_stat_dict[item][0]
+ res_rgb_mean.append(rgb_mean)
+ pca_std = self.color_var_stat_dict[item]['var_pca']
+ # here the 'var' is 'std'
+ res_pca_std.append(pca_std[..., None])
+ res_sean_code.append(self.get_sean_code(ke=item))
+ res_curliness.append(self.curliness_hair_dict[item])
+ res_code = torch.tensor(np.stack(res_code), dtype=torch.float32)
+ res_rgb_mean = torch.tensor(np.stack(res_rgb_mean), dtype=torch.float32)
+ res_pca_std = torch.tensor(np.stack(res_pca_std), dtype=torch.float32)
+ res_curliness = torch.tensor(np.stack(res_curliness), dtype=torch.int)[..., None]
+ data = {'code': res_code, 'rgb_mean': res_rgb_mean, 'pca_std': res_pca_std, 'items': items,
+ 'sean_code': res_sean_code, 'curliness_label': res_curliness}
+ return data
+
+ def get_training_batch(self, batch_size):
+ items = []
+ while len(items) < batch_size:
+ item = random.choice(self.train_list)
+ # if not self.valid_hair(item):
+ # continue
+ items.append(item)
+ data = self.get_list_by_items(items)
+ return data
+
+ def get_testing_batch(self, batch_size):
+ ptr = 0
+ items = []
+ while len(items) < batch_size:
+ item = self.test_list[ptr]
+ ptr += 1
+ if not self.valid_hair(item):
+ continue
+ items.append(item)
+ data = self.get_list_by_items(items)
+ return data
+
+ def get_curliness_hair(self, labels):
+ labels = labels.cpu().numpy()
+ items = []
+ for label in labels:
+ item_list = self.curliness_hair_list[label[0]]
+ items.append(np.random.choice(item_list))
+ data = self.get_list_by_items(items)
+ return data
+
+ def get_curliness_hair_test(self):
+ return self.get_list_by_items(self.curliness_hair_list_test[-1] + self.curliness_hair_list_test[1])
+
+
+# if __name__ == '__main__':
+# ds = Dataset(cfg)
+# resources = ds.get_training_batch(8)
+# pass
+
+
+# for label in [-1, 1]:
+# img_dir = os.path.join(cfg.data_root, 'manual_label', 'curliness', 'test_%d' % label)
+# imgs = [pat[:-4] + '\n' for pat in os.listdir(img_dir)]
+# imgs.sort()
+# with open(img_dir + '.txt', 'w') as f:
+# f.writelines(imgs)
diff --git a/models/CtrlHair/color_texture_branch/model.py b/models/CtrlHair/color_texture_branch/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ced35665953cb023054dd21642518dff73c956a
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/model.py
@@ -0,0 +1,159 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: model.py
+# Time : 2021/11/17 15:37
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch.nn as nn
+from my_torchlib.module import LinearBlock
+import torch
+from torch.nn import init
+
+
+def init_weights(net, init_type='normal', init_gain=0.02):
+ """Initialize network weights.
+
+ Parameters:
+ net (network) -- network to be initialized
+ init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
+ init_gain (float) -- scaling factor for normal, xavier and orthogonal.
+
+ We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
+ work better for some applications. Feel free to try yourself.
+ """
+
+ def init_func(m): # define the initialization function
+ classname = m.__class__.__name__
+ if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0.0, init_gain)
+ elif init_type == 'xavier':
+ init.xavier_normal_(m.weight.data, gain=init_gain)
+ elif init_type == 'kaiming':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=init_gain)
+ else:
+ raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+ elif classname.find(
+ 'BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
+ init.normal_(m.weight.data, 1.0, init_gain)
+ init.constant_(m.bias.data, 0.0)
+
+ print('initialize network with %s' % init_type)
+ net.apply(init_func) # apply the initialization function
+
+
+class Generator(nn.Module):
+ """Generator network."""
+
+ def __init__(self, cfg):
+ super(Generator, self).__init__()
+ self.cfg = cfg
+
+ input_dim = cfg.noise_dim
+ if cfg.lambda_rgb:
+ input_dim += 3
+ if cfg.lambda_pca_std:
+ input_dim += 1
+ if cfg.lambda_cls_curliness:
+ input_dim += cfg.curliness_dim
+
+ layers = [LinearBlock(input_dim, cfg.g_hidden_dim, cfg.g_norm, activation=cfg.g_activ)]
+ for _ in range(cfg.g_hidden_layer_num - 1):
+ layers.append(LinearBlock(cfg.g_hidden_dim, cfg.g_hidden_dim, cfg.g_norm, activation=cfg.g_activ))
+ layers.append(LinearBlock(cfg.g_hidden_dim, cfg.SEAN_code, 'none', 'none'))
+ self.net = nn.Sequential(*layers)
+
+ def forward(self, data):
+ x = data['noise']
+ if self.cfg.lambda_cls_curliness:
+ x = torch.cat([x, data['noise_curliness']], dim=1)
+ if self.cfg.lambda_rgb:
+ x = torch.cat([x, data['rgb_mean']], dim=1)
+ if self.cfg.lambda_pca_std:
+ x = torch.cat([x, data['pca_std']], dim=1)
+ output = self.net(x)
+ res = {'code': output}
+ return res
+
+
+class Discriminator(nn.Module):
+ """Discriminator network."""
+
+ def __init__(self, cfg):
+ super(Discriminator, self).__init__()
+ self.cfg = cfg
+ layers = [LinearBlock(cfg.SEAN_code, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ)]
+ for _ in range(cfg.d_hidden_layer_num - 1):
+ layers.append(LinearBlock(cfg.d_hidden_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ))
+ output_dim = 1 + cfg.noise_dim
+ if cfg.lambda_rgb and 'curliness' not in cfg.predictor:
+ output_dim += 3
+ if cfg.lambda_pca_std:
+ output_dim += 1
+ if cfg.lambda_cls_curliness:
+ output_dim += cfg.curliness_dim
+ if 'curliness' not in cfg.predictor:
+ output_dim += 1
+ layers.append(LinearBlock(cfg.d_hidden_dim, output_dim, 'none', 'none'))
+ self.net = nn.Sequential(*layers)
+ self.input_name = 'code'
+
+ def forward(self, data_in):
+ x = data_in[self.input_name]
+ out = self.net(x)
+ data = {'adv': out[:, [0]]}
+ ptr = 1
+ data['noise'] = out[:, ptr:(ptr + self.cfg.noise_dim)]
+ ptr += self.cfg.noise_dim
+ if self.cfg.lambda_cls_curliness:
+ data['noise_curliness'] = out[:, ptr:(ptr + self.cfg.curliness_dim)]
+ ptr += self.cfg.curliness_dim
+ if not 'curliness' in self.cfg.predictor:
+ data['cls_curliness'] = out[:, ptr: ptr + 1]
+ ptr += 1
+ if self.cfg.lambda_rgb and 'rgb' not in self.cfg.predictor:
+ data['rgb_mean'] = out[:, ptr:ptr + 3]
+ ptr += 3
+ if self.cfg.lambda_pca_std and 'rgb' not in self.cfg.predictor:
+ data['pca_std'] = out[:, ptr:]
+ ptr += 1
+ return data
+
+ def forward_adv_direct(self, x):
+ return self.net(x)[:, [0]]
+
+
+class DiscriminatorNoise(nn.Module):
+ """Discriminator network."""
+
+ def __init__(self, cfg):
+ super(DiscriminatorNoise, self).__init__()
+ self.cfg = cfg
+ input_dim = cfg.noise_dim
+ if cfg.lambda_cls_curliness:
+ input_dim += cfg.curliness_dim
+ layers = [LinearBlock(input_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ)]
+ for _ in range(cfg.d_noise_hidden_layer_num - 1):
+ layers.append(LinearBlock(cfg.d_hidden_dim, cfg.d_hidden_dim, cfg.d_norm, activation=cfg.d_activ))
+ output_dim = 1
+ layers.append(LinearBlock(cfg.d_hidden_dim, output_dim, 'none', 'none'))
+ self.net = nn.Sequential(*layers)
+ self.input_name = 'noise'
+
+ def forward(self, data_in):
+ x = data_in[self.input_name]
+ if self.cfg.lambda_cls_curliness:
+ x = torch.cat([x, data_in['noise_curliness']], dim=1)
+ out = self.net(x)
+ data = {'adv': out[:, [0]]}
+ return data
+
+ def forward_adv_direct(self, x):
+ return self.net(x)[:, [0]]
diff --git a/models/CtrlHair/color_texture_branch/model_eigengan.py b/models/CtrlHair/color_texture_branch/model_eigengan.py
new file mode 100644
index 0000000000000000000000000000000000000000..58b90369f67c51f049293332aee7051e452e0fc4
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/model_eigengan.py
@@ -0,0 +1,89 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: model_eigengan.py
+# Time : 2021/12/28 21:57
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch.nn as nn
+import torch
+
+
+class SubspaceLayer(nn.Module):
+ def __init__(self, dim: int, n_basis: int):
+ super().__init__()
+ self.U = nn.Parameter(torch.empty(n_basis, dim), requires_grad=True)
+ nn.init.orthogonal_(self.U)
+ self.L = nn.Parameter(torch.FloatTensor([3 * i for i in range(n_basis, 0, -1)]), requires_grad=True)
+ self.mu = nn.Parameter(torch.zeros(dim), requires_grad=True)
+
+ self.unit_matrix = torch.eye(n_basis, requires_grad=False)
+
+ def forward(self, z):
+ return (self.L * z) @ self.U + self.mu
+
+ def orthogonal_regularizer(self):
+ UUT = self.U @ self.U.t()
+ self.unit_matrix = self.unit_matrix.to(self.U.device)
+ reg = ((UUT - self.unit_matrix) ** 2).mean()
+ return reg
+
+
+class EigenGenerator(nn.Module):
+ def __init__(self, cfg):
+ super(EigenGenerator, self).__init__()
+ self.cfg = cfg
+
+ input_dim = 0
+ if cfg.lambda_rgb:
+ input_dim += 3
+ if cfg.lambda_pca_std:
+ input_dim += 1
+ if cfg.lambda_cls_curliness:
+ input_dim += cfg.curliness_dim
+
+ self.main_layer_in = nn.Linear(input_dim, cfg.g_hidden_dim, bias=True)
+ main_layers_mid = []
+ for _ in range(cfg.g_hidden_layer_num - 1):
+ main_layers_mid.append(nn.Sequential(nn.LeakyReLU(0.2), nn.Linear(cfg.g_hidden_dim,
+ cfg.g_hidden_dim, bias=True)))
+ main_layers_mid.append(nn.Sequential(nn.LeakyReLU(0.2), nn.Linear(cfg.g_hidden_dim, cfg.SEAN_code)))
+
+ subspaces = []
+ for _ in range(cfg.g_hidden_layer_num):
+ sub = SubspaceLayer(cfg.g_hidden_dim, cfg.subspace_dim)
+ subspaces.append(sub)
+
+ self.main_layer_mid = nn.ModuleList(main_layers_mid)
+ self.subspaces = nn.ModuleList(subspaces)
+
+ def forward(self, data):
+ noise = data['noise']
+ noise = noise.reshape(len(data['noise']), self.cfg.g_hidden_layer_num, self.cfg.subspace_dim)
+
+ input_data = []
+ if self.cfg.lambda_cls_curliness:
+ input_data.append(data['noise_curliness'])
+ if self.cfg.lambda_rgb:
+ input_data.append(data['rgb_mean'])
+ if self.cfg.lambda_pca_std:
+ input_data.append(data['pca_std'])
+
+ x = torch.cat(input_data, dim=1)
+ x_mid = self.main_layer_in(x)
+
+ for layer_idx in range(self.cfg.g_hidden_layer_num):
+ subspace_data = self.subspaces[layer_idx](noise[:, layer_idx, :])
+ x_mid = x_mid + subspace_data
+ x_mid = self.main_layer_mid[layer_idx](x_mid)
+
+ res = {'code': x_mid}
+ return res
+
+ def orthogonal_regularizer_loss(self):
+ loss = 0
+ for s in self.subspaces:
+ loss = loss + s.orthogonal_regularizer()
+ return loss
diff --git a/models/CtrlHair/color_texture_branch/module.py b/models/CtrlHair/color_texture_branch/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..ada8738fb429c453bb936cbef88f1b972ee51abc
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/module.py
@@ -0,0 +1,61 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: module.py
+# Time : 2021/11/17 15:38
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch.nn as nn
+
+
+class LinearBlock(nn.Module):
+
+ def __init__(self, input_dim, output_dim, norm, activation='relu', use_bias=True, leaky_slope=0.2, dropout=0):
+ super(LinearBlock, self).__init__()
+ # initialize fully connected layer
+ self.fc = nn.Linear(input_dim, output_dim, bias=use_bias)
+
+ # initialize normalization
+ norm_dim = output_dim
+ if norm == 'bn':
+ self.norm = nn.BatchNorm1d(norm_dim)
+ elif norm == 'in':
+ self.norm = nn.InstanceNorm1d(norm_dim)
+ elif norm == 'ln':
+ self.norm = nn.LayerNorm(norm_dim)
+ elif norm == 'none':
+ self.norm = None
+ else:
+ assert 0, "Unsupported normalization: {}".format(norm)
+
+ # initialize activation
+ if activation == 'relu':
+ self.activation = nn.ReLU(inplace=True)
+ elif activation == 'lrelu':
+ self.activation = nn.LeakyReLU(leaky_slope, inplace=True)
+ elif activation == 'prelu':
+ self.activation = nn.PReLU()
+ elif activation == 'selu':
+ self.activation = nn.SELU(inplace=True)
+ elif activation == 'tanh':
+ self.activation = nn.Tanh()
+ elif activation == 'none':
+ self.activation = None
+ else:
+ assert 0, "Unsupported activation: {}".format(activation)
+
+ self.dropout = dropout
+ if bool(self.dropout) and self.dropout > 0:
+ self.dropout_layer = nn.Dropout(p=self.dropout)
+
+ def forward(self, x):
+ out = self.fc(x)
+ if self.norm:
+ out = self.norm(out)
+ if self.activation:
+ out = self.activation(out)
+ if bool(self.dropout) and self.dropout > 0:
+ out = self.dropout_layer(out)
+ return out
diff --git a/models/CtrlHair/color_texture_branch/predictor/__init__.py b/models/CtrlHair/color_texture_branch/predictor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d04f75c257e1c83b1e1920c2a9fc22a464669da4
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/predictor/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py.py
+# Time : 2021/12/14 22:43
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/color_texture_branch/predictor/predictor_config.py b/models/CtrlHair/color_texture_branch/predictor/predictor_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec1980d5ec9adf2c32107bb6627761a1758c16e8
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/predictor/predictor_config.py
@@ -0,0 +1,119 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: predictor_config.py
+# Time : 2021/12/14 21:03
+# Author: xyguoo@163.com
+"""
+
+import addict # nesting dict
+import os
+import argparse
+import sys
+
+from global_value_utils import GLOBAL_DATA_ROOT
+
+configs = [
+ addict.Dict({
+ "experiment_name": "p002___curliness",
+ 'basic_dir': 'model_trained/curliness_classifier',
+ 'filter_female_and_frontal': True,
+ 'hidden_layer_num': 3,
+ 'hidden_dim': 32,
+ 'lambda_cls_curliness': {0: 1, 200: 0.1, 400: 0.01, 2500: 0.001},
+ 'init_type': 'xavier',
+ 'norm': 'bn',
+ 'dropout': 0.5,
+ 'total_batch_size': 256,
+ 'total_step': 7000,
+ }),
+ addict.Dict({
+ "experiment_name": "p004___pca_std",
+ 'basic_dir': 'model_trained/color_encoder',
+ 'filter_female_and_frontal': True,
+ 'hidden_layer_num': 3,
+ 'hidden_dim': 256,
+ 'lambda_rgb': {0: 1, 7000: 1},
+ 'lambda_pca_std': {0: 1, 7000: 1},
+ 'init_type': 'xavier',
+ 'norm': 'bn',
+ 'dropout': 0.2,
+ 'total_batch_size': 256,
+ 'total_step': 10000,
+ }),
+]
+
+
+def get_config(configs, config_id):
+ for c in configs:
+ if c.experiment_name.startswith(config_id):
+ check_add_default_value_to_base_cfg(c)
+ return c
+
+
+def check_add_default_value_to_base_cfg(cfg):
+ add_default_value_to_cfg(cfg, 'lr', 0.002)
+ add_default_value_to_cfg(cfg, 'beta1', 0.5)
+ add_default_value_to_cfg(cfg, 'beta2', 0.999)
+
+ add_default_value_to_cfg(cfg, 'log_step', 10)
+ add_default_value_to_cfg(cfg, 'model_save_step', 1000)
+ add_default_value_to_cfg(cfg, 'sample_batch_size', 100)
+ add_default_value_to_cfg(cfg, 'max_save', 2)
+ add_default_value_to_cfg(cfg, 'SEAN_code', 512)
+
+ # Model configuration
+ add_default_value_to_cfg(cfg, 'total_batch_size', 64)
+ add_default_value_to_cfg(cfg, 'gan_type', 'wgan_gp')
+
+ add_default_value_to_cfg(cfg, 'norm', 'none')
+ add_default_value_to_cfg(cfg, 'activ', 'lrelu')
+ add_default_value_to_cfg(cfg, 'init_type', 'normal')
+
+ add_default_value_to_cfg(cfg, 'root_dir', '%s/%s' % (cfg.basic_dir, cfg['experiment_name']))
+ add_default_value_to_cfg(cfg, 'log_dir', cfg.root_dir + '/logs')
+ add_default_value_to_cfg(cfg, 'model_save_dir', cfg.root_dir + '/models')
+ add_default_value_to_cfg(cfg, 'sample_dir', cfg.root_dir + '/samples')
+ try:
+ add_default_value_to_cfg(cfg, 'gpu_num', len(args.gpu.split(',')))
+ except:
+ add_default_value_to_cfg(cfg, 'gpu_num', 1)
+
+ add_default_value_to_cfg(cfg, 'data_root', GLOBAL_DATA_ROOT)
+
+
+def add_default_value_to_cfg(cfg, key, value):
+ if key not in cfg:
+ cfg[key] = value
+
+
+def merge_config_in_place(ori_cfg, new_cfg):
+ for k in new_cfg:
+ ori_cfg[k] = new_cfg[k]
+
+
+def back_process(cfg):
+ cfg.batch_size = cfg.total_batch_size // cfg.gpu_num
+ cfg.predict_dict = {}
+ if 'lambda_cls_curliness' in cfg:
+ cfg.predict_dict['cls_curliness'] = 1
+ if 'lambda_rgb' in cfg:
+ cfg.predict_dict['rgb_mean'] = 3
+ if 'lambda_pca_std' in cfg:
+ cfg.predict_dict['pca_std'] = 1
+
+
+def get_basic_arg_parser():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, help='Specify config number', default='000')
+ parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
+ parser.add_argument('--local_rank', type=int, default=-1)
+ return parser
+
+
+if sys.argv[0].endswith('predictor_train.py'):
+ parser = get_basic_arg_parser()
+ args = parser.parse_args()
+ cfg = get_config(configs, args.config)
+ os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
+ back_process(cfg)
diff --git a/models/CtrlHair/color_texture_branch/predictor/predictor_model.py b/models/CtrlHair/color_texture_branch/predictor/predictor_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1b948b62daf474d95a175217f4af333e3516e42
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/predictor/predictor_model.py
@@ -0,0 +1,41 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: predictor_model.py
+# Time : 2021/12/14 20:47
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch.nn as nn
+from my_torchlib.module import LinearBlock
+
+
+class Predictor(nn.Module):
+ """Discriminator network."""
+
+ def __init__(self, cfg):
+ super(Predictor, self).__init__()
+ self.cfg = cfg
+ layers = [LinearBlock(cfg.SEAN_code, cfg.hidden_dim, cfg.norm, activation=cfg.activ, dropout=cfg.dropout)]
+ for _ in range(cfg.hidden_layer_num - 1):
+ layers.append(LinearBlock(cfg.hidden_dim, cfg.hidden_dim, cfg.norm, activation=cfg.activ,
+ dropout=cfg.dropout))
+
+ output_dim = 0
+ for ke in cfg.predict_dict:
+ output_dim += cfg.predict_dict[ke]
+ layers.append(LinearBlock(cfg.hidden_dim, output_dim, 'none', 'none'))
+ self.net = nn.Sequential(*layers)
+ self.input_name = 'code'
+
+ def forward(self, data_in):
+ x = data_in[self.input_name]
+ out = self.net(x)
+ ptr = 0
+ data = {}
+ for ke in self.cfg.predict_dict:
+ cur_dim = self.cfg.predict_dict[ke]
+ data[ke] = out[:, ptr:(ptr + cur_dim)]
+ ptr += cur_dim
+ return data
diff --git a/models/CtrlHair/color_texture_branch/predictor/predictor_solver.py b/models/CtrlHair/color_texture_branch/predictor/predictor_solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..812f1469641eae4aa8dcd83adea96c5dd4eea76c
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/predictor/predictor_solver.py
@@ -0,0 +1,51 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: predictor_solver.py
+# Time : 2021/12/14 21:57
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch
+import torch.nn.functional as F
+from color_texture_branch.predictor.predictor_config import cfg
+from color_texture_branch.predictor.predictor_model import Predictor
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+
+class PredictorSolver:
+
+ def __init__(self, cfg, device, local_rank, training=True):
+ self.mse_loss = torch.nn.MSELoss()
+ self.cfg = cfg
+
+ # model
+ self.pred = Predictor(cfg)
+ self.pred.to(device)
+ self.optimizer = torch.optim.Adam(self.pred.parameters(), lr=cfg.lr, betas=(cfg.beta1, cfg.beta2),
+ weight_decay=0.00)
+
+ if local_rank >= 0:
+ pDDP = lambda m, find_unused: DDP(m, device_ids=[local_rank], output_device=local_rank,
+ find_unused_parameters=False)
+ self.pred = pDDP(self.pred, find_unused=True)
+ self.local_rank = local_rank
+ self.device = device
+
+ def forward(self, data):
+ self.data = data
+ self.pred_res = self.pred(data)
+
+ def forward_d(self, loss_dict):
+ if 'lambda_rgb' in cfg:
+ loss_dict['lambda_rgb'] = self.mse_loss(self.pred_res['rgb_mean'], self.data['rgb_mean'])
+ if 'lambda_pca_std' in cfg:
+ d_pca_std = self.pred_res['pca_std']
+ loss_dict['lambda_pca_std'] = self.mse_loss(d_pca_std, self.data['pca_std'])
+
+ def forward_d_curliness(self, data_curliness, loss_dict):
+ if cfg.lambda_cls_curliness:
+ cls_curliness = self.pred_res['cls_curliness']
+ loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(
+ torch.sigmoid(cls_curliness), data_curliness['curliness_label'].float() / 2 + 0.5)
diff --git a/models/CtrlHair/color_texture_branch/predictor/predictor_train.py b/models/CtrlHair/color_texture_branch/predictor/predictor_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..dab04b3012f5aaea1979fd852f3fbef4de13cceb
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/predictor/predictor_train.py
@@ -0,0 +1,159 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: predictor_train.py
+# Time : 2021/12/14 20:58
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+
+sys.path.append('.')
+
+import tensorboardX
+import torch
+import tqdm
+import numpy as np
+from color_texture_branch.predictor.predictor_config import cfg, args
+from color_texture_branch.dataset import Dataset
+import my_pylib
+# distributed training
+import torch.distributed as dist
+from color_texture_branch.predictor.predictor_solver import PredictorSolver
+from my_torchlib.train_utils import LossUpdater, to_device, train
+import my_torchlib
+from color_texture_branch.model import init_weights
+
+
+def get_total_step():
+ total = 0
+ for key in cfg.iter:
+ total += cfg.iter[key]
+ return total
+
+
+def worker(proc, nprocs, args):
+ local_rank = args.local_rank
+ if local_rank >= 0:
+ torch.cuda.set_device(local_rank)
+ dist.init_process_group(backend='nccl',
+ init_method='tcp://localhost:%d' % (6030 + int(cfg.experiment_name[:3])),
+ rank=args.local_rank,
+ world_size=cfg.gpu_num)
+ print('setup rank %d' % local_rank)
+ device = torch.device('cuda', max(0, local_rank))
+
+ # config
+ out_dir = cfg.root_dir
+
+ # data
+ ds = Dataset(cfg)
+
+ # Loss class
+ solver = PredictorSolver(cfg, device, local_rank, training=True)
+
+ loss_updater = LossUpdater(cfg)
+
+ # load checkpoint
+ ckpt_dir = out_dir + '/checkpoints'
+ if local_rank <= 0:
+ my_pylib.mkdir(out_dir)
+ my_pylib.save_json(out_dir + '/setting_hair.json', cfg, indent=4, separators=(',', ': '))
+ my_pylib.mkdir(ckpt_dir)
+
+ try:
+ ckpt = my_torchlib.load_checkpoint(ckpt_dir)
+ start_step = ckpt['step'] + 1
+ for model_name in ['Predictor']:
+ cur_model = ckpt[model_name]
+ if list(cur_model)[0].startswith('module'):
+ ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
+ solver.pred.load_state_dict(ckpt['Predictor'], strict=True)
+ solver.optimizer.load_state_dict(ckpt['optimizer'])
+ print('Load succeed!')
+ except:
+ print(' [*] No checkpoint!')
+ init_weights(solver.pred, init_type=cfg.init_type)
+ start_step = 1
+
+ # writer
+ if local_rank <= 0:
+ writer = tensorboardX.SummaryWriter(out_dir + '/summaries')
+ else:
+ writer = None
+
+ # start training
+ test_batch = ds.get_testing_batch(100)
+ test_batch_curliness = ds.get_curliness_hair_test()
+
+ to_device(test_batch_curliness, device)
+ to_device(test_batch, device)
+
+ if local_rank >= 0:
+ dist.barrier()
+
+ total_step = cfg.total_step + 2
+ for step in tqdm.tqdm(range(start_step, total_step), total=total_step, initial=start_step, desc='step'):
+ loss_updater.update(step)
+ write_log = (writer and step % 11 == 0)
+
+ loss_dict = {}
+ if 'rgb_mean' in cfg.predict_dict or 'pca_std' in cfg.predict_dict:
+ data = ds.get_training_batch(cfg.batch_size)
+ to_device(data, device)
+ solver.forward(data)
+ solver.forward_d(loss_dict)
+ if write_log:
+ solver.pred.eval()
+ if 'rgb_mean' in cfg.predict_dict:
+ loss_dict['test_lambda_rgb'] = solver.mse_loss(
+ solver.pred(test_batch)['rgb_mean'], test_batch['rgb_mean'])
+ print('rgb loss: %f' % loss_dict['test_lambda_rgb'])
+ if 'pca_std' in cfg.predict_dict:
+ loss_dict['test_lambda_pca_std'] = solver.mse_loss(
+ solver.pred(test_batch)['pca_std'], test_batch['pca_std'])
+ print('pca_std loss: %f' % loss_dict['test_lambda_pca_std'])
+ solver.pred.train()
+
+ if cfg.lambda_cls_curliness:
+ data = {}
+ curliness_label = torch.tensor(np.random.choice([-1, 1], (cfg.batch_size, 1)))
+ data['curliness_label'] = curliness_label
+ data_curliness = ds.get_curliness_hair(curliness_label)
+ to_device(data_curliness, device)
+ solver.forward(data_curliness)
+ solver.forward_d_curliness(data_curliness, loss_dict)
+
+ # validation to show whether over-fit
+ if write_log:
+ solver.pred.eval()
+ logit = solver.pred(test_batch_curliness)['cls_curliness']
+ loss_dict['test_cls_curliness'] = torch.nn.functional.binary_cross_entropy_with_logits(
+ logit, test_batch_curliness['curliness_label'] / 2 + 0.5)
+
+ print('cls_curliness: %f' % loss_dict['test_cls_curliness'])
+ print('acc %f' % ((logit * test_batch_curliness['curliness_label'] > 0).sum() / logit.shape[0]))
+ solver.pred.train()
+
+ train(cfg, loss_dict, optimizers=[solver.optimizer],
+ step=step, writer=writer, flag='Pred', write_log=write_log)
+
+ if step > 0 and step % cfg.model_save_step == 0:
+ if local_rank <= 0:
+ save_model(step, solver, ckpt_dir)
+ if local_rank >= 0:
+ dist.barrier()
+
+
+def save_model(step, solver, ckpt_dir):
+ save_dic = {'step': step,
+ 'Predictor': solver.pred.state_dict(),
+ 'optimizer': solver.optimizer.state_dict()}
+ my_torchlib.save_checkpoint(save_dic, '%s/%07d.ckpt' % (ckpt_dir, step), max_keep=cfg.max_save)
+
+
+if __name__ == '__main__':
+ # with torch.autograd.set_detect_anomaly(True):
+ # mp.spawn(worker, nprocs=cfg.gpu_num, args=(cfg.gpu_num, args))
+ worker(proc=None, nprocs=None, args=args)
diff --git a/models/CtrlHair/color_texture_branch/script_find_direction.py b/models/CtrlHair/color_texture_branch/script_find_direction.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8b99fc16656545ef9938a1870135a81fcdb9e67
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/script_find_direction.py
@@ -0,0 +1,74 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_find_direction.py
+# Time : 2022/02/28
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+
+sys.path.append('.')
+
+import os
+import tqdm
+
+from ui.backend import Backend
+from util.canvas_grid import Canvas
+import numpy as np
+
+import pickle
+from common_dataset import DataFilter
+from util.imutil import read_rgb, write_rgb
+from color_texture_branch.config import cfg
+from util.find_semantic_direction import get_random_direction
+
+df = DataFilter(cfg)
+be = Backend(2.5, blending=False)
+
+exist_direction = 'model_trained/color_texture/%s' % cfg.experiment_name
+code_dim = cfg.noise_dim
+att_name = 'texture'
+interpolate_num = 6
+max_val = 2.5
+batch = 10
+
+interpolate_values = np.linspace(-max_val, max_val, interpolate_num)
+
+existing_dirs_dir = os.path.join(exist_direction, '%s_dir_used' % att_name)
+
+existing_dirs_list = os.listdir(existing_dirs_dir)
+existing_dirs = []
+for dd in existing_dirs_list:
+ with open(os.path.join(existing_dirs_dir, dd), 'rb') as f:
+ existing_dirs.append(pickle.load(f))
+
+direction_dir = '%s/direction_find/%s_dir_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
+img_gen_dir = '%s/direction_find/%s_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
+for dd in [direction_dir, img_gen_dir]:
+ if not os.path.exists(dd):
+ os.makedirs(dd)
+
+img_list = df.train_list
+
+for dir_idx in tqdm.tqdm(range(0, 300)):
+ rand_dir = get_random_direction(code_dim, existing_dirs)
+ with open('%s/%d.pkl' % (direction_dir, dir_idx,), 'wb') as f:
+ pickle.dump(rand_dir, f)
+ rand_dir = rand_dir.to(be.device)
+
+ canvas = Canvas(batch, interpolate_num + 1)
+ for img_idx, img_file in tqdm.tqdm(enumerate(img_list[:batch])):
+ img = read_rgb(img_file)
+ _, img_parsing = be.set_input_img(img)
+
+ canvas.process_draw_image(img, img_idx, 0)
+
+ for inter_idx in range(interpolate_num):
+ inter_val = interpolate_values[inter_idx]
+ be.continue_change_with_direction(att_name, rand_dir, inter_val)
+
+ out_img = be.output()
+ canvas.process_draw_image(out_img, img_idx, inter_idx + 1)
+ write_rgb('%s/%d.png' % (img_gen_dir, dir_idx), canvas.canvas)
diff --git a/models/CtrlHair/color_texture_branch/solver.py b/models/CtrlHair/color_texture_branch/solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..58b3ee17579729437c249cd171649be4bbd47f3c
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/solver.py
@@ -0,0 +1,299 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: solver.py
+# Time : 2021/11/17 16:24
+# Author: xyguoo@163.com
+# Description:
+"""
+import torch
+import torch.nn.functional as F
+import numpy as np
+from .config import cfg
+from .model import Discriminator, DiscriminatorNoise
+from torch.nn.parallel import DistributedDataParallel as DDP
+import random
+import os
+import cv2
+
+
+# solver
+class Solver:
+
+ def __init__(self, cfg, device, local_rank, training=True):
+ self.mse_loss = torch.nn.MSELoss()
+ self.cfg = cfg
+
+ # model
+ if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
+ from color_texture_branch.model_eigengan import EigenGenerator
+ self.gen = EigenGenerator(cfg)
+ else:
+ from color_texture_branch.model import Generator
+ self.gen = Generator(cfg)
+ self.gen.to(device)
+
+ self.dis = Discriminator(cfg)
+ self.dis.to(device)
+
+ if 'curliness' in cfg.predictor:
+ from color_texture_branch.predictor.predictor_model import Predictor
+ self.curliness_model = Predictor(cfg.predictor['curliness'])
+ self.curliness_model.to(device)
+ self.curliness_model.eval()
+
+ if 'rgb' in cfg.predictor:
+ from color_texture_branch.predictor.predictor_model import Predictor
+ self.rgb_model = Predictor(cfg.predictor['rgb'])
+ self.rgb_model.to(device)
+ self.rgb_model.eval()
+
+ if training:
+ self.G_optimizer = torch.optim.Adam(self.gen.parameters(), lr=cfg.lr_d, betas=(cfg.beta1, cfg.beta2),
+ weight_decay=0.00)
+ self.D_optimizer = torch.optim.Adam(self.dis.parameters(), lr=cfg.lr_g, betas=(cfg.beta1, cfg.beta2),
+ weight_decay=0.00)
+
+ if cfg.lambda_adv_noise:
+ self.dis_noise = DiscriminatorNoise(cfg)
+ self.dis_noise.to(device)
+ self.D_noise_optimizer = torch.optim.Adam(self.dis_noise.parameters(), lr=cfg.lr_g,
+ betas=(cfg.beta1, cfg.beta2), weight_decay=0.00)
+ else:
+ self.dis_noise = None
+ else:
+ self.gen.eval()
+ self.dis.eval()
+
+ if local_rank >= 0:
+ pDDP = lambda m, find_unused: DDP(m, device_ids=[local_rank], output_device=local_rank,
+ find_unused_parameters=False)
+ self.gen = pDDP(self.gen, find_unused=True)
+ self.dis = pDDP(self.dis, find_unused=True)
+ if cfg.lambda_adv_noise:
+ self.dis_noise = pDDP(self.dis_noise, find_unused=True)
+ self.local_rank = local_rank
+ self.device = device
+
+ def edit_infer(self, hair_code, data):
+ self.inner_code = self.dis({'code': hair_code})
+ for ke in data:
+ self.inner_code[ke] = data[ke]
+ self.res = self.gen(self.inner_code)
+ return self.res['code']
+
+ def forward(self, data):
+ self.ae_in = {'code': data['code']}
+
+ # rec
+ d_res_real = self.dis(self.ae_in)
+ self.ae_mid = {'noise': d_res_real['noise'], 'rgb_mean': data['rgb_mean'], 'pca_std': data['pca_std']}
+ if cfg.lambda_cls_curliness:
+ self.ae_mid['noise_curliness'] = d_res_real['noise_curliness']
+ self.ae_out = self.gen(self.ae_mid)
+
+ # gan
+ random_list = list(range(data['rgb_mean'].shape[0]))
+ random.shuffle(random_list)
+ self.gan_in = {'rgb_mean': data['rgb_mean'][random_list]}
+ self.gan_in['pca_std'] = data['pca_std'][random_list]
+ random.shuffle(random_list)
+ if cfg.lambda_cls_curliness:
+ self.gan_in['noise_curliness'] = data['noise_curliness'][random_list]
+ self.gan_in['curliness_label'] = data['curliness_label'][random_list]
+ random.shuffle(random_list)
+
+ if self.cfg.gan_input_from_encoder_prob and \
+ random.random() < self.cfg.gan_input_from_encoder_prob:
+ self.gan_in['noise'] = d_res_real['noise'][random_list].detach()
+ else:
+ self.gan_in['noise'] = data['noise'][random_list]
+ self.gan_mid = self.gen(self.gan_in)
+ self.gan_out_fake = self.dis(self.gan_mid)
+ self.gan_out_real = d_res_real
+ self.gan_label = {'rgb_mean': data['rgb_mean'], 'pca_std': data['pca_std'], 'curliness_label': data['curliness_label']}
+ self.real_noise = {'noise': data['noise']}
+ if cfg.lambda_cls_curliness:
+ self.real_noise['noise_curliness'] = data['noise_curliness']
+
+ def forward_g(self, loss_dict):
+ self.forward_general_gen(self.gan_out_fake['adv'], loss_dict)
+
+ loss_dict['lambda_info'] = self.mse_loss(self.gan_out_fake['noise'], self.gan_in['noise'])
+ loss_dict['lambda_rec'] = self.mse_loss(self.ae_out['code'], self.ae_in['code'])
+
+ if 'rgb' in cfg.predictor:
+ p_rgb = self.rgb_model(self.gan_mid)
+ if cfg.lambda_rgb:
+ if 'rgb' in cfg.predictor:
+ d_rgb_mean = p_rgb['rgb_mean']
+ else:
+ d_rgb_mean = self.gan_out_fake['rgb_mean']
+ loss_dict['lambda_rgb'] = self.mse_loss(d_rgb_mean, self.gan_in['rgb_mean'])
+
+ if cfg.lambda_pca_std:
+ if 'rgb' in cfg.predictor:
+ d_pca_std = p_rgb['pca_std']
+ else:
+ d_pca_std = self.gan_out_fake['pca_std']
+ loss_dict['lambda_pca_std'] = self.mse_loss(d_pca_std, self.gan_in['pca_std'])
+
+ if cfg.lambda_cls_curliness:
+ d_noise_curliness = self.gan_out_fake['noise_curliness']
+ loss_dict['lambda_info_curliness'] = self.mse_loss(d_noise_curliness, self.gan_in['noise_curliness'])
+ if 'curliness' in cfg.predictor:
+ cls_curliness = self.curliness_model(self.gan_mid)['cls_curliness']
+ else:
+ cls_curliness = self.gan_out_fake['cls_curliness']
+ if cfg.curliness_with_weight:
+ weights = self.gan_in['noise_curliness'].abs()
+ weights = weights / weights.sum() * weights.shape[0]
+ loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
+ self.gan_in['curliness_label'].float() / 2 + 0.5,
+ weight=weights)
+ else:
+ loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
+ self.gan_in['curliness_label'].float() / 2 + 0.5)
+
+ if 'gen_mode' in cfg and cfg.gen_mode is 'eigengan':
+ loss_dict['lambda_orthogonal'] = self.gen.orthogonal_regularizer_loss()
+
+ for loss_d in [loss_dict]:
+ for ke in loss_d:
+ if np.isnan(np.array(loss_d[ke].detach().cpu())):
+ print('!!!!!!!!! %s is nan' % ke)
+ print(loss_d)
+ raise Exception()
+
+ @staticmethod
+ def forward_general_gen(dis_res, loss_dict, loss_name_suffix=''):
+ if cfg.gan_type == 'lsgan':
+ loss_dis = torch.mean((dis_res - 1) ** 2)
+ elif cfg.gan_type == 'nsgan':
+ all1 = torch.ones_like(dis_res.data).cuda()
+ loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis_res), all1))
+ elif cfg.gan_type == 'wgan_gp':
+ loss_dis = - torch.mean(dis_res)
+ elif cfg.gan_type == 'hinge':
+ loss_dis = -torch.mean(dis_res)
+ elif cfg.gan_type == 'hinge2':
+ loss_dis = torch.mean(torch.max(1 - dis_res, torch.zeros_like(dis_res)))
+ else:
+ raise NotImplementedError()
+ loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
+
+ @staticmethod
+ def forward_general_dis(dis1, dis0, dis_model, loss_dict, input_real, input_fake, loss_name_suffix=''):
+
+ if cfg.gan_type == 'lsgan':
+ loss_dis = torch.mean((dis0 - 0) ** 2) + torch.mean((dis1 - 1) ** 2)
+ elif cfg.gan_type == 'nsgan':
+ all0 = torch.zeros_like(dis0.data).cuda()
+ all1 = torch.ones_like(dis1.data).cuda()
+ loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis0), all0) +
+ F.binary_cross_entropy(torch.sigmoid(dis1), all1))
+ elif cfg.gan_type == 'wgan_gp':
+ loss_dis = torch.mean(dis0) - torch.mean(dis1)
+ elif cfg.gan_type == 'hinge' or cfg.gan_type == 'hinge2':
+ loss_dis = torch.mean(torch.max(1 - dis1, torch.zeros_like(dis1)))
+ loss_dis += torch.mean(torch.max(1 + dis0, torch.zeros_like(dis1)))
+ else:
+ assert 0, "Unsupported GAN type: {}".format(dis_model.gan_type)
+ loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
+
+ if cfg.gan_type == 'wgan_gp':
+ loss_gp = 0
+ alpha_gp = torch.rand(input_real.size(0), 1, ).type_as(input_real)
+ x_hat = (alpha_gp * input_real + (1 - alpha_gp) * input_fake).requires_grad_(True)
+ out_hat = dis_model.forward_adv_direct(x_hat)
+ # gradient penalty
+ weight = torch.ones(out_hat.size()).type_as(out_hat)
+ dydx = torch.autograd.grad(outputs=out_hat, inputs=x_hat, grad_outputs=weight, retain_graph=True,
+ create_graph=True, only_inputs=True)[0]
+ dydx = dydx.contiguous().view(dydx.size(0), -1)
+ dydx_l2norm = torch.sqrt(torch.sum(dydx ** 2, dim=1))
+ loss_gp += torch.mean((dydx_l2norm - 1) ** 2)
+ loss_dict['lambda_gp' + loss_name_suffix] = loss_gp
+
+ def forward_d(self, loss_dict):
+ self.forward_general_dis(self.gan_out_real['adv'], self.gan_out_fake['adv'],
+ self.dis, loss_dict, input_real=self.ae_in['code'],
+ input_fake=self.gan_mid['code'])
+
+ loss_dict['lambda_info'] = self.mse_loss(self.gan_out_fake['noise'], self.gan_in['noise'])
+ if cfg.lambda_rgb and 'rgb' not in cfg.predictor:
+ loss_dict['lambda_rgb'] = self.mse_loss(self.gan_in['rgb_mean'], self.gan_out_fake['rgb_mean'])
+ loss_dict['lambda_rec'] = self.mse_loss(self.ae_out['code'], self.ae_in['code'])
+ if cfg.lambda_pca_std and 'rgb' not in cfg.predictor:
+ loss_dict['lambda_pca_std'] = self.mse_loss(self.gan_out_real['pca_std'], self.gan_label['pca_std'])
+
+ if cfg.lambda_adv_noise:
+ self.d_noise_res = self.dis_noise(self.ae_mid)
+ self.forward_general_gen(self.d_noise_res['adv'], loss_dict, loss_name_suffix='_noise')
+
+ if cfg.lambda_moment_1 or cfg.lambda_moment_2:
+ if cfg.lambda_cls_curliness:
+ noise_mid = torch.cat([self.ae_mid['noise_curliness'], self.ae_mid['noise']], dim=1)
+ else:
+ noise_mid = self.ae_mid['noise']
+ if cfg.lambda_moment_1:
+ loss_dict['lambda_moment_1'] = (noise_mid.mean(dim=0) ** 2).mean()
+ if cfg.lambda_moment_2:
+ loss_dict['lambda_moment_2'] = (((noise_mid ** 2).mean(dim=0) - 1) ** 2).mean()
+
+ if cfg.lambda_cls_curliness:
+ loss_dict['lambda_info_curliness'] = self.mse_loss(self.gan_out_fake['noise_curliness'], self.gan_in['noise_curliness'])
+
+ def forward_d_curliness(self, data_curliness, loss_dict):
+ d_res = self.dis(data_curliness)
+ cls_curliness = d_res['cls_curliness']
+ loss_dict['lambda_cls_curliness'] = F.binary_cross_entropy(torch.sigmoid(cls_curliness),
+ data_curliness['curliness_label'].float() / 2 + 0.5)
+
+ def forward_adv_noise(self, loss_dict):
+ dis1 = self.dis_noise(self.real_noise)['adv']
+ self.ae_mid['noise'] = self.ae_mid['noise'].detach()
+ if self.cfg.lambda_cls_curliness:
+ self.ae_mid['noise_curliness'] = self.ae_mid['noise_curliness'].detach()
+ self.d_noise_res = self.dis_noise(self.ae_mid)
+ dis0 = self.d_noise_res['adv']
+
+ input_real = self.real_noise['noise']
+ input_fake = self.ae_mid['noise']
+ if self.cfg.lambda_cls_curliness:
+ input_real = torch.cat([input_real, self.real_noise['noise_curliness']], dim=1)
+ input_fake = torch.cat([input_fake, self.ae_mid['noise_curliness']], dim=1)
+
+ self.forward_general_dis(dis1, dis0, self.dis_noise, loss_dict, input_real=input_real,
+ input_fake=input_fake, loss_name_suffix='_noise')
+
+ def forward_rec_img(self, data, loss_dict, batch_size=4):
+ from .validation_in_train import he
+ from global_value_utils import HAIR_IDX
+
+ items = data['items']
+
+ rec_loss = 0
+ for idx in range(batch_size):
+ item = items[idx]
+ dataset_name, img_name = item.split('___')
+ parsing_img = cv2.imread(os.path.join(self.cfg.data_root, '%s/label/%s.png') %
+ (dataset_name, img_name), cv2.IMREAD_GRAYSCALE)
+ parsing_img = cv2.resize(parsing_img, (256, 256), cv2.INTER_NEAREST)
+
+ sean_code = torch.tensor(data['sean_code'][idx].copy(), dtype=torch.float32).to(self.ae_out['code'].device)
+ sean_code[HAIR_IDX] = self.ae_out['code'][idx, ...]
+
+ render_img = he.gen_img(sean_code[None, ...], parsing_img[None, None, ...])
+
+ input_img = cv2.cvtColor(cv2.imread(os.path.join(self.cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ input_img = input_img / 127.5 - 1.0
+ input_img = input_img.transpose(2, 0, 1)
+
+ input_img = torch.tensor(input_img).to(render_img.device)
+ parsing_img = torch.tensor(parsing_img).to(render_img.device)
+
+ rec_loss = rec_loss + ((input_img - render_img)[:, (parsing_img == HAIR_IDX)] ** 2).mean()
+ rec_loss = rec_loss / batch_size
+ loss_dict['lambda_rec_img'] = rec_loss
diff --git a/models/CtrlHair/color_texture_branch/train.py b/models/CtrlHair/color_texture_branch/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..9797b9063f94b848a5a748fdc1e05dda2e00ccc7
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/train.py
@@ -0,0 +1,166 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: scripts.py.py
+# Time : 2021/11/17 15:24
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+
+sys.path.append('.')
+
+import tensorboardX
+import torch
+import tqdm
+import numpy as np
+from color_texture_branch.config import cfg, args
+from color_texture_branch.dataset import Dataset
+import my_pylib
+from color_texture_branch.validation_in_train import print_val_save_model
+# distributed training
+import torch.distributed as dist
+from color_texture_branch.solver import Solver
+from my_torchlib.train_utils import LossUpdater, to_device, generate_noise, train
+import my_torchlib
+from color_texture_branch.model import init_weights
+
+
+def get_total_step():
+ total = 0
+ for key in cfg.iter:
+ total += cfg.iter[key]
+ return total
+
+
+def worker(proc, nprocs, args):
+ local_rank = args.local_rank
+ if local_rank >= 0:
+ torch.cuda.set_device(local_rank)
+ dist.init_process_group(backend='nccl',
+ init_method='tcp://localhost:%d' % (6030 + int(cfg.experiment_name[:3])),
+ rank=args.local_rank,
+ world_size=cfg.gpu_num)
+ print('setup rank %d' % local_rank)
+ device = torch.device('cuda', max(0, local_rank))
+
+ # config
+ out_dir = cfg.root_dir
+
+ # data
+ ds = Dataset(cfg)
+
+ loss_updater = LossUpdater(cfg)
+ loss_updater.update(0)
+
+ # Loss class
+ solver = Solver(cfg, device, local_rank=local_rank)
+
+ # load checkpoint
+ ckpt_dir = out_dir + '/checkpoints'
+ if local_rank <= 0:
+ my_pylib.mkdir(out_dir)
+ my_pylib.save_json(out_dir + '/setting_hair.json', cfg, indent=4, separators=(',', ': '))
+ my_pylib.mkdir(ckpt_dir)
+
+ try:
+ ckpt = my_torchlib.load_checkpoint(ckpt_dir)
+ start_step = ckpt['step'] + 1
+ for model_name in ['Model_G', 'Model_D']:
+ cur_model = ckpt[model_name]
+ if list(cur_model)[0].startswith('module'):
+ ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
+ solver.gen.load_state_dict(ckpt['Model_G'], strict=True)
+ solver.dis.load_state_dict(ckpt['Model_D'], strict=True)
+ solver.D_optimizer.load_state_dict(ckpt['D_optimizer'])
+ solver.G_optimizer.load_state_dict(ckpt['G_optimizer'])
+ if cfg.lambda_adv_noise:
+ solver.dis_noise.load_state_dict(ckpt['Model_D_noise'], strict=True)
+ solver.D_noise_optimizer.load_state_dict(ckpt['D_noise_optimizer'])
+ print('Load succeed!')
+ except:
+ print(' [*] No checkpoint!')
+ init_weights(solver.gen, init_type=cfg.init_type)
+ init_weights(solver.dis, init_type=cfg.init_type)
+ if cfg.lambda_adv_noise:
+ init_weights(solver.dis_noise, init_type=cfg.init_type)
+ start_step = 1
+
+ if 'curliness' in cfg.predictor:
+ ckpt = my_torchlib.load_checkpoint(cfg.predictor.curliness.root_dir + '/checkpoints')
+ solver.curliness_model.load_state_dict(ckpt['Predictor'], strict=True)
+
+ if 'rgb' in cfg.predictor:
+ ckpt = my_torchlib.load_checkpoint(cfg.predictor.rgb.root_dir + '/checkpoints')
+ solver.rgb_model.load_state_dict(ckpt['Predictor'], strict=True)
+
+ # writer
+ if local_rank <= 0:
+ writer = tensorboardX.SummaryWriter(out_dir + '/summaries')
+ else:
+ writer = None
+
+ # start training
+ test_batch = ds.get_testing_batch(cfg.sample_batch_size)
+ test_batch_curliness = ds.get_curliness_hair_test()
+
+ to_device(test_batch_curliness, device)
+ to_device(test_batch, device)
+
+ if local_rank >= 0:
+ dist.barrier()
+
+ total_step = cfg.total_step + 2
+ for step in tqdm.tqdm(range(start_step, total_step), total=total_step, initial=start_step, desc='step'):
+ loss_updater.update(step)
+ write_log = (writer and step % 23 == 0)
+
+ for i in range(sum(cfg.G_D_train_num.values())):
+ data = ds.get_training_batch(cfg.batch_size)
+ data['noise'] = generate_noise(cfg.batch_size, cfg.noise_dim)
+ if cfg.lambda_cls_curliness:
+ curliness_label = torch.tensor(np.random.choice([-1, 1], (cfg.batch_size, 1)))
+ data['curliness_label'] = curliness_label
+ data['noise_curliness'] = generate_noise(cfg.batch_size, cfg.curliness_dim, curliness_label)
+ to_device(data, device)
+ loss_dict = {}
+ solver.forward(data)
+
+ if 'lambda_rec_img' in cfg and cfg.lambda_rec_img > 0:
+ solver.forward_rec_img(data, loss_dict)
+
+ if i < cfg.G_D_train_num['D']:
+ solver.forward_d(loss_dict)
+ if cfg.lambda_cls_curliness and not 'curliness' in cfg.predictor:
+ data_curliness = ds.get_curliness_hair(curliness_label)
+ to_device(data_curliness, device)
+ solver.forward_d_curliness(data_curliness, loss_dict)
+
+ # validation to show whether over-fit
+ if write_log:
+ loss_dict['test_cls_curliness'] = torch.nn.functional.binary_cross_entropy_with_logits(
+ solver.dis(test_batch_curliness)['cls_curliness'], test_batch_curliness['curliness_label'] / 2 + 0.5)
+ if cfg.lambda_rgb and 'rgb' not in cfg.predictor and write_log:
+ loss_dict['test_lambda_rgb'] = solver.mse_loss(solver.dis(test_batch)['rgb_mean'],
+ test_batch['rgb_mean'])
+ train(cfg, loss_dict, optimizers=[solver.D_optimizer],
+ step=step, writer=writer, flag='D', write_log=write_log)
+ else:
+ solver.forward_g(loss_dict)
+ train(cfg, loss_dict, optimizers=[solver.G_optimizer],
+ step=step, writer=writer, flag='G', write_log=write_log)
+
+ if cfg.lambda_adv_noise:
+ loss_dict = {}
+ solver.forward_adv_noise(loss_dict)
+ train(cfg, loss_dict, optimizers=[solver.D_noise_optimizer], step=step, writer=writer, flag='D_noise',
+ write_log=write_log)
+
+ print_val_save_model(step, out_dir, solver, test_batch, ckpt_dir, local_rank)
+
+
+if __name__ == '__main__':
+ # with torch.autograd.set_detect_anomaly(True):
+ # mp.spawn(worker, nprocs=cfg.gpu_num, args=(cfg.gpu_num, args))
+ worker(proc=None, nprocs=None, args=args)
diff --git a/models/CtrlHair/color_texture_branch/validation_in_train.py b/models/CtrlHair/color_texture_branch/validation_in_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c2c9b460c3b091849d8b148e6f40caf6c0d5a52
--- /dev/null
+++ b/models/CtrlHair/color_texture_branch/validation_in_train.py
@@ -0,0 +1,299 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: validation_in_train.py
+# Time : 2021/12/10 12:55
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import cv2
+import os
+
+from .config import cfg
+import my_pylib
+import torch
+from my_torchlib.train_utils import tensor2numpy, to_device, generate_noise
+from util.canvas_grid import Canvas
+from global_value_utils import HAIR_IDX
+import copy
+import numpy as np
+import torch.distributed as dist
+import my_torchlib
+from hair_editor import HairEditor
+
+he = HairEditor(load_feature_model=False, load_mask_model=False)
+
+
+def gen_by_sean(sean_code, item):
+ dataset_name, img_name = item.split('___')
+ parsing_img = cv2.imread(os.path.join(cfg.data_root, '%s/label/%s.png') %
+ (dataset_name, img_name), cv2.IMREAD_GRAYSCALE)
+ parsing_img = cv2.resize(parsing_img, (256, 256), cv2.INTER_NEAREST)
+ return he.gen_img(sean_code[None, ...], parsing_img[None, None, ...])
+
+
+def save_model(step, solver, ckpt_dir):
+ save_dic = {'step': step,
+ 'Model_G': solver.gen.state_dict(), 'Model_D': solver.dis.state_dict(),
+ 'D_optimizer': solver.D_optimizer.state_dict(), 'G_optimizer': solver.G_optimizer.state_dict()}
+ if cfg.lambda_adv_noise:
+ save_dic['Model_D_noise'] = solver.dis_noise.state_dict()
+ save_dic['D_noise_optimizer'] = solver.D_noise_optimizer.state_dict()
+ my_torchlib.save_checkpoint(save_dic, '%s/%07d.ckpt' % (ckpt_dir, step), max_keep=cfg.max_save)
+
+
+def print_val_save_model(step, out_dir, solver, test_batch, ckpt_dir, local_rank):
+ """
+ :param step:
+ :param validation_data:
+ :param img_size:
+ :param alpha:
+ :return:
+ """
+ if step > 0 and step % cfg.sample_step == 0:
+ gen = solver.gen
+ dis = solver.dis
+ local_rank = solver.local_rank
+ device = solver.device
+
+ save_dir = out_dir + '/sample_training'
+ my_pylib.mkdir(save_dir)
+ gen.eval()
+ dis.eval()
+ # gen.cpu()
+ show_batch_size = 10
+ row_idxs = list(range(show_batch_size))
+ instance_idxs = list(range(show_batch_size))
+
+ with torch.no_grad():
+ items = test_batch['items']
+ decoder_res = dis({'code': test_batch['code'].cuda()})
+ hair_noise = decoder_res['noise'].cpu()
+ test_data = {'noise': hair_noise, 'rgb_mean': test_batch['rgb_mean'],
+ 'pca_std': test_batch['pca_std']}
+ if cfg.lambda_cls_curliness:
+ test_data['noise_curliness'] = decoder_res['noise_curliness'].cpu()
+ to_device(test_data, device)
+ rec_code = gen(test_data)['code']
+
+ # ----------------
+ # generate each noise dim
+ # ----------------
+ # grid_count = 10
+ # lin_space = np.linspace(-3, 3, grid_count)
+ grid_count = 6
+ lin_space = np.linspace(-2.5, 2.5, grid_count)
+ for dim_idx in range(cfg.noise_dim):
+ canvas = Canvas(len(row_idxs), grid_count + 1)
+ for draw_idx, idx in enumerate(row_idxs):
+ item = items[idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+
+ canvas.process_draw_image(ori_img, draw_idx, 0)
+
+ for grid_idx in range(grid_count):
+ temp_noise = hair_noise.clone()
+ temp_noise[:, dim_idx] = lin_space[grid_idx]
+ data = copy.deepcopy(test_data)
+ data['noise'] = temp_noise
+ to_device(data, device)
+ code = gen(data)['code']
+
+ for draw_idx, idx in enumerate(row_idxs):
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = code[idx].cpu().numpy()
+ item = items[idx]
+ out_img = gen_by_sean(cur_code, item)
+ out_img = tensor2numpy(out_img)
+ canvas.process_draw_image(out_img, draw_idx, grid_idx + 1)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, '%06d_noise_%02d.png' % (step, dim_idx)))
+
+ # -------------
+ # direct transfer all content
+ # -------------
+ canvas = Canvas(len(row_idxs) + 1, len(instance_idxs) + 2)
+ for draw_idx, instance_idx in enumerate(instance_idxs):
+ item = items[instance_idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ canvas.process_draw_image(ori_img, 0, draw_idx + 2)
+
+ for draw_idx, idx in enumerate(row_idxs):
+ item_row = items[idx]
+ dataset_name, img_name = item_row.split('___')
+ img_row = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ canvas.process_draw_image(img_row, draw_idx + 1, 0)
+ sean_code = test_batch['sean_code'][idx]
+ rec_img = tensor2numpy(gen_by_sean(sean_code, item_row))
+ canvas.process_draw_image(rec_img, draw_idx + 1, 1)
+ for draw_idx2, instance_idx in enumerate(instance_idxs):
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = test_batch['sean_code'][instance_idx][HAIR_IDX]
+ res_img = gen_by_sean(cur_code, item_row)
+ res_img = tensor2numpy(res_img)
+ canvas.process_draw_image(res_img, draw_idx + 1, draw_idx2 + 2)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, 'rgb_direct.png'))
+
+ # -----------
+ # random choice
+ # -----------
+ grid_count = 10
+ # generate each noise dim
+ canvas = Canvas(len(row_idxs), grid_count + 2)
+ for draw_idx, idx in enumerate(row_idxs):
+ item = items[idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+
+ canvas.process_draw_image(ori_img, draw_idx, 0)
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
+ rec_img = tensor2numpy(gen_by_sean(cur_code, item))
+ canvas.process_draw_image(rec_img, draw_idx, 1)
+
+ temp_noise = generate_noise(grid_count, cfg.noise_dim)
+ for grid_idx in range(grid_count):
+ data = copy.deepcopy(test_data)
+ data['noise'] = torch.tile(temp_noise[[grid_idx]], [test_batch['rgb_mean'].shape[0], 1])
+ to_device(data, device)
+ code = gen(data)['code']
+
+ for draw_idx, idx in enumerate(row_idxs):
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = code[idx].cpu().numpy()
+ item = items[idx]
+ out_img = gen_by_sean(cur_code, item)
+ out_img = tensor2numpy(out_img)
+ canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
+
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, '%06d_random.png' % step))
+
+ # ------------
+ # generate curliness
+ # ------------
+ if cfg.lambda_cls_curliness:
+ grid_count = 10
+ lin_space = np.linspace(-3, 3, grid_count)
+ canvas = Canvas(len(row_idxs), grid_count + 2)
+ for draw_idx, idx in enumerate(row_idxs):
+ item = items[idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ canvas.process_draw_image(ori_img, draw_idx, 0)
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
+ rec_img = tensor2numpy(gen_by_sean(cur_code, item))
+ canvas.process_draw_image(rec_img, draw_idx, 1)
+
+ for grid_idx in range(grid_count):
+ cur_noise_curliness = torch.tensor(lin_space[grid_idx]).reshape([1, 1]).tile([cfg.sample_batch_size, 1]).float()
+ data = copy.deepcopy(test_data)
+ data['noise_curliness'] = cur_noise_curliness
+ to_device(data, device)
+ code = gen(data)['code']
+ for draw_idx, idx in enumerate(row_idxs):
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = code[idx].cpu().numpy()
+ item = items[idx]
+ out_img = gen_by_sean(cur_code, item)
+ out_img = tensor2numpy(out_img)
+ canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, '%06d_curliness.png' % step))
+
+ # ------------
+ # generate variance
+ # ------------
+ if cfg.lambda_pca_std:
+ grid_count = 10
+ lin_space = np.linspace(10, 150, grid_count)
+ canvas = Canvas(len(row_idxs), grid_count + 2)
+ for draw_idx, idx in enumerate(row_idxs):
+ item = items[idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ canvas.process_draw_image(ori_img, draw_idx, 0)
+
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = rec_code[idx].cpu().numpy()
+ rec_img = tensor2numpy(gen_by_sean(cur_code, item))
+ canvas.process_draw_image(rec_img, draw_idx, 1)
+
+ for grid_idx in range(grid_count):
+ cur_pca_std = torch.tensor(lin_space[grid_idx]).reshape([1, 1]).tile([cfg.sample_batch_size, 1]).float()
+ data = copy.deepcopy(test_data)
+ data['pca_std'] = cur_pca_std
+ to_device(data, device)
+ code = gen(data)['code']
+
+ for draw_idx, idx in enumerate(row_idxs):
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = code[idx].cpu().numpy()
+ item = items[idx]
+ out_img = gen_by_sean(cur_code, item)
+ out_img = tensor2numpy(out_img)
+ canvas.process_draw_image(out_img, draw_idx, grid_idx + 2)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, '%06d_variance.png' % step))
+
+ # -------------
+ # generate each rgb
+ # -------------
+ canvas = Canvas(len(row_idxs) + 1, len(instance_idxs) + 1)
+ for draw_idx, instance_idx in enumerate(instance_idxs):
+ item = items[instance_idx]
+ dataset_name, img_name = item.split('___')
+ # generate origin and reconstruction
+ ori_img = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ ori_img[5:45, 5:45, :] = test_batch['rgb_mean'][instance_idx].cpu().numpy()
+ canvas.process_draw_image(ori_img, 0, draw_idx + 1)
+ for draw_idx, idx in enumerate(row_idxs):
+ item_row = items[idx]
+ dataset_name, img_name = item_row.split('___')
+ img_row = cv2.cvtColor(cv2.imread(os.path.join(cfg.data_root, '%s/images_256/%s.png') %
+ (dataset_name, img_name)), cv2.COLOR_BGR2RGB)
+ canvas.process_draw_image(img_row, draw_idx + 1, 0)
+ for draw_idx2, instance_idx in enumerate(instance_idxs):
+ color = test_batch['rgb_mean'][[instance_idx]]
+ data = copy.deepcopy(test_data)
+ data['rgb_mean'] = torch.tile(color, [cfg.sample_batch_size, 1])
+ data['pca_std'] = torch.tile(test_batch['pca_std'][[instance_idx]], [cfg.sample_batch_size, 1])
+ to_device(data, device)
+ hair_code = gen(data)['code']
+ for draw_idx, idx in enumerate(row_idxs):
+ item_row = items[idx]
+ cur_code = test_batch['sean_code'][idx].copy()
+ cur_code[HAIR_IDX] = hair_code[idx].cpu().numpy()
+ res_img = gen_by_sean(cur_code, item_row)
+ res_img = tensor2numpy(res_img)
+ canvas.process_draw_image(res_img, draw_idx + 1, draw_idx2 + 1)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(save_dir, '%06d_rgb.png' % step))
+
+ gen.train()
+ dis.train()
+ if local_rank >= 0:
+ dist.barrier()
+
+ if step > 0 and step % cfg.model_save_step == 0:
+ if local_rank <= 0:
+ save_model(step, solver, ckpt_dir)
+ if local_rank >= 0:
+ dist.barrier()
diff --git a/models/CtrlHair/common_dataset.py b/models/CtrlHair/common_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..c825ab92540c6c16a1fc63797c397293aecab210
--- /dev/null
+++ b/models/CtrlHair/common_dataset.py
@@ -0,0 +1,104 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: common_dataset.py
+# Time : 2021/12/31 19:19
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import random
+
+import numpy as np
+import pandas as pd
+
+from global_value_utils import GLOBAL_DATA_ROOT, HAIR_IDX, HAT_IDX, DATASET_NAME
+from util.util import path_join_abs
+import cv2
+
+
+class DataFilter:
+ def __init__(self, cfg=None, test_part=0.096):
+ # cfg
+ if cfg is None:
+ from color_texture_branch.config import cfg
+ self.cfg = cfg
+
+ base_dataset_dir = GLOBAL_DATA_ROOT
+
+ dataset_dir = [os.path.join(base_dataset_dir, dn) for dn in DATASET_NAME]
+
+ self.data_dirs = dataset_dir
+
+ self.random_seed = 7
+ random.seed(self.random_seed)
+
+ ####################################################################
+ # Please modify these if you don't want to use these filters
+ angle_filter = True
+ gender_filter = True
+ gender = ['female']
+ # gender = ['male', 'female']
+ gender = set([{'male': 1, 'female': -1}[g] for g in gender])
+ ####################################################################
+
+ self.total_list = []
+ for data_dir in self.data_dirs:
+ img_dir = os.path.join(data_dir, 'images_256')
+
+ if angle_filter:
+ angle_csv = pd.read_csv(os.path.join(data_dir, 'angle.csv'), index_col=0)
+ angle_filter_imgs = list(angle_csv.index[angle_csv['angle'] < 5])
+ cur_list = ['%05d.png' % dd for dd in angle_filter_imgs]
+ else:
+ cur_list = os.listdir(img_dir)
+
+ if gender_filter:
+ attr_filter = pd.read_csv(os.path.join(data_dir, 'attr_gender.csv'))
+ cur_list = [p for p in cur_list if attr_filter.Male[int(p[:-4])] in gender]
+
+ self.total_list += [os.path.join(img_dir, p) for p in cur_list]
+
+ random.shuffle(self.total_list)
+ self.test_start = int(len(self.total_list) * (1 - test_part))
+ self.test_list = self.total_list[self.test_start:]
+ self.train_list = [st for st in self.total_list if st not in self.test_list]
+
+ idx = 0
+ # make sure the area of hair is big enough
+ self.hair_region_threshold = 0.07
+ self.test_face_list = []
+ while len(self.test_face_list) < cfg.sample_batch_size:
+ test_file = self.test_list[idx]
+ if self.valid_face(path_join_abs(test_file, '../..'), test_file[-9:-4]):
+ self.test_face_list.append(test_file)
+ idx += 1
+
+ self.test_hair_list = []
+ while len(self.test_hair_list) < cfg.sample_batch_size:
+ test_file = self.test_list[idx]
+ if self.valid_hair(path_join_abs(test_file, '../..'), test_file[-9:-4]):
+ self.test_hair_list.append(test_file)
+ idx += 1
+
+ def valid_face(self, data_dir, img_idx_str):
+ label_path = os.path.join(data_dir, 'label', img_idx_str + '.png')
+ label_img = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
+ hat_region = label_img == HAT_IDX
+
+ if hat_region.mean() > 0.03:
+ return False
+ return True
+
+ def valid_hair(self, data_dir, img_idx_str):
+ label_path = os.path.join(data_dir, 'label', img_idx_str + '.png')
+ label_img = cv2.imread(label_path, cv2.IMREAD_GRAYSCALE)
+ hair_region = label_img == HAIR_IDX
+ hat_region = label_img == HAT_IDX
+
+ if hat_region.mean() > 0.03:
+ return False
+ if hair_region.mean() < self.hair_region_threshold:
+ return False
+ return True
+
diff --git a/models/CtrlHair/dataset_scripts/__init__.py b/models/CtrlHair/dataset_scripts/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f506a5ea11d8716ff556d6868d67965bcb34bdf
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py
+# Time : 2022/07/15
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/dataset_scripts/script_crop.py b/models/CtrlHair/dataset_scripts/script_crop.py
new file mode 100644
index 0000000000000000000000000000000000000000..71fcb12d1642ebe5365d934f2406e4ed1f236afd
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_crop.py
@@ -0,0 +1,46 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_crop.py
+# Time : 2022/07/17
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+sys.path.append('.')
+
+from external_code.crop import recreate_aligned_images
+from global_value_utils import GLOBAL_DATA_ROOT
+
+import os
+from external_code.landmarks_util import predictor_dict, detector
+import numpy as np
+import cv2
+
+predictor_68 = predictor_dict[68]
+
+##############################################
+# Please input your dataset dir
+root_dir = 'your/dataset/original/images'
+dataset_name = 'your_dataset_name'
+##############################################
+
+dataset_dir = os.path.join(GLOBAL_DATA_ROOT, dataset_name)
+out_dir = os.path.join(dataset_dir, 'images_256')
+if not os.path.exists(out_dir):
+ os.makedirs(out_dir)
+
+files = os.listdir(root_dir)
+files.sort()
+for face_path in files:
+ face_img_bgr = cv2.imread(os.path.join(root_dir, face_path))
+ face_img_rgb = cv2.cvtColor(face_img_bgr, cv2.COLOR_BGR2RGB)
+ face_img_rgb = cv2.resize(face_img_rgb, dsize=(face_img_rgb.shape[1], face_img_rgb.shape[0]))
+ face_bbox = detector(face_img_rgb, 0)
+ face_lm_68 = np.array([[p.x, p.y] for p in predictor_68(face_img_bgr, face_bbox[0]).parts()])
+
+ face_img_pil, _ = recreate_aligned_images(face_img_rgb, face_lm_68, output_size=256)
+
+ img_np = np.array(face_img_pil)
+ cv2.imwrite(os.path.join(out_dir, face_path), cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR))
\ No newline at end of file
diff --git a/models/CtrlHair/dataset_scripts/script_get_color_var_label.py b/models/CtrlHair/dataset_scripts/script_get_color_var_label.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c7fd6c6c5b57a1024cb9ee002418e4788c22ee4
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_get_color_var_label.py
@@ -0,0 +1,94 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_get_color_var_label.py
+# Time : 2021/11/29 22:10
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import sys
+sys.path.append('.')
+
+from dataset_scripts.utils import merge_pickle_dir_to_dict
+import cv2
+import tqdm
+
+import pickle
+from common_dataset import DataFilter
+from global_value_utils import HAIR_IDX, GLOBAL_DATA_ROOT, DATASET_NAME
+import numpy as np
+
+
+data_name = DATASET_NAME
+
+root_dir = GLOBAL_DATA_ROOT
+imgs_sub_dir = 'images_256'
+target_dir = os.path.join(root_dir, 'hair_info_all_dataset/color_var_stat')
+
+ds = DataFilter()
+ds.total_list.sort()
+
+if not os.path.exists(target_dir):
+ os.makedirs(target_dir)
+
+path_list = []
+for d in data_name:
+ data_dir = os.path.join(root_dir, d, imgs_sub_dir)
+ path_list += [os.path.join(data_dir, pp) for pp in os.listdir(data_dir)]
+
+res_dict = {}
+for img_path in tqdm.tqdm(path_list[:], total=len(path_list)):
+ for dd in data_name:
+ if img_path.find(dd) != -1:
+ dataset_name = dd
+ break
+ else:
+ raise NotImplementedError
+ base_name = os.path.basename(img_path)
+ hair_path = os.path.join(root_dir, dataset_name, imgs_sub_dir, base_name)
+ hair_img = cv2.cvtColor(cv2.imread(hair_path), cv2.COLOR_BGR2RGB)
+ hair_parsing = cv2.imread(os.path.join(root_dir, dataset_name, 'label', base_name), cv2.IMREAD_GRAYSCALE)
+ mask_img = cv2.resize(hair_parsing.astype('uint8'), hair_img.shape[:2], interpolation=cv2.INTER_NEAREST)
+
+ hair_mask = (mask_img == HAIR_IDX).astype('uint8')
+ kernel13 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(19, 19))
+ hair_mask = cv2.erode(hair_mask, kernel13, iterations=1)
+
+ points = hair_img[hair_mask.astype('bool')]
+
+ # points color
+ color_var_stat = []
+ var_rgb = (points / 255).var(axis=0)
+ if len(points) > 5:
+ points_hsv = cv2.cvtColor(points[None, ...], cv2.COLOR_RGB2HSV)
+ points_hsv = points_hsv / np.array([180, 255, 255])
+ var_hsv = points_hsv.var(axis=(0, 1))
+
+ points_hls = cv2.cvtColor(points[None, ...], cv2.COLOR_RGB2HLS)
+ points_hls = points_hls / np.array([180, 255, 255])
+ var_hls = points_hls.var(axis=(0, 1))
+
+ points_lab = cv2.cvtColor(points[None, ...], cv2.COLOR_RGB2LAB)
+ points_lab = points_lab / np.array([255, 100, 100])
+ var_lab = points_lab.var(axis=(0, 1))
+
+ points_yuv = cv2.cvtColor(points[None, ...], cv2.COLOR_RGB2YUV)
+ points_yuv = points_yuv / np.array([255, 200, 200])
+ var_yuv = points_yuv.var(axis=(0, 1))
+ color_var_stat = {'var_rgb': var_rgb, 'var_hsv': var_hsv, 'var_hls': var_hls,
+ 'var_yuv': var_yuv}
+
+ from sklearn.decomposition import PCA
+ pca = PCA(n_components=2)
+ pca.fit(points)
+ pca_dim = pca.transform(points)[:, 0]
+ color_var_stat['var_pca'] = pca_dim.std()
+ color_var_stat['var_pca_mean'] = pca.mean_
+ color_var_stat['var_pca_comp'] = pca.components_
+
+ target_file = os.path.join(target_dir, '%s___%s.pkl' % (dataset_name, base_name[:-4]))
+ with open(target_file, 'wb') as f:
+ pickle.dump(color_var_stat, f)
+
+merge_pickle_dir_to_dict(target_dir, os.path.join(root_dir, 'color_var_stat_dict.pkl'))
\ No newline at end of file
diff --git a/models/CtrlHair/dataset_scripts/script_get_mask.py b/models/CtrlHair/dataset_scripts/script_get_mask.py
new file mode 100644
index 0000000000000000000000000000000000000000..114cea8adf40068e0efafaaddc0141bc3b37ff88
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_get_mask.py
@@ -0,0 +1,71 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+import sys
+sys.path.append('.')
+
+import tqdm
+
+import os
+import os.path as osp
+import numpy as np
+import cv2
+from global_value_utils import GLOBAL_DATA_ROOT, PARSING_COLOR_LIST, DATASET_NAME
+from util.imutil import read_rgb, write_rgb
+from external_code.face_parsing.my_parsing_util import FaceParsing
+
+
+data_name = [d for d in DATASET_NAME if d != 'CelebaMask_HQ']
+
+def makedir(pat):
+ if not os.path.exists(pat):
+ os.makedirs(pat)
+
+
+def vis_parsing_maps(im, parsing_anno, stride, save_im, save_path, img_path):
+ # Colors for all 20 parts
+
+ label_path = os.path.join(save_path, 'label')
+ vis_path = os.path.join(save_path, 'vis')
+ makedir(pat=label_path)
+ makedir(pat=vis_path)
+
+ im = np.array(im)
+ vis_im = im.copy().astype(np.uint8)
+ vis_parsing_anno = parsing_anno.copy().astype(np.uint8)
+ vis_parsing_anno = cv2.resize(vis_parsing_anno, None, fx=stride, fy=stride, interpolation=cv2.INTER_NEAREST)
+ vis_parsing_anno_color = np.zeros((vis_parsing_anno.shape[0], vis_parsing_anno.shape[1], 3)) + 255
+
+ num_of_class = np.max(vis_parsing_anno)
+
+ img_path = img_path[:-4] + '.png'
+
+ for pi in range(0, num_of_class + 1):
+ index = np.where(vis_parsing_anno == pi)
+ if len(index[0]) > 0:
+ vis_parsing_anno_color[index[0], index[1], :] = PARSING_COLOR_LIST[pi]
+
+ vis_parsing_anno_color = vis_parsing_anno_color.astype(np.uint8)
+ vis_im = cv2.addWeighted(vis_im, 0.4, vis_parsing_anno_color, 0.6, 0)
+
+ cv2.imwrite(os.path.join(label_path, img_path), vis_parsing_anno)
+ write_rgb(os.path.join(vis_path, img_path), vis_im)
+
+
+def evaluate(respth, dspth):
+ if not os.path.exists(respth):
+ os.makedirs(respth)
+
+ files = os.listdir(dspth)
+ files.sort()
+ for image_path in tqdm.tqdm(files):
+ parsing, image = FaceParsing.parsing_img(read_rgb(osp.join(dspth, image_path)))
+ parsing = FaceParsing.swap_parsing_label_to_celeba_mask(parsing)
+ vis_parsing_maps(image, parsing, stride=1, save_im=True, save_path=respth, img_path=image_path)
+
+
+if __name__ == "__main__":
+ for dn in data_name:
+ input_dir = os.path.join(GLOBAL_DATA_ROOT, dn, 'images_256')
+ target_root_dir = os.path.join(GLOBAL_DATA_ROOT, dn)
+ evaluate(respth=target_root_dir, dspth=input_dir)
diff --git a/models/CtrlHair/dataset_scripts/script_get_rgb_hsv_label.py b/models/CtrlHair/dataset_scripts/script_get_rgb_hsv_label.py
new file mode 100644
index 0000000000000000000000000000000000000000..46d0361d3467b0633c2b949af4aa65f8c0980b26
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_get_rgb_hsv_label.py
@@ -0,0 +1,90 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_get_rgb_hsv_label.py
+# Time : 2021/11/16 21:23
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import sys
+
+sys.path.append('.')
+
+from dataset_scripts.utils import merge_pickle_dir_to_dict
+import cv2
+import tqdm
+import pickle
+from common_dataset import DataFilter
+import numpy as np
+from global_value_utils import HAIR_IDX, GLOBAL_DATA_ROOT, DATASET_NAME
+
+data_name = DATASET_NAME
+
+root_dir = GLOBAL_DATA_ROOT
+imgs_sub_dir = 'images_256'
+target_dir = os.path.join(root_dir, 'hair_info_all_dataset/rgb_stat')
+
+ds = DataFilter()
+ds.total_list.sort()
+
+path_list = []
+for d in data_name:
+ data_dir = os.path.join(root_dir, d, imgs_sub_dir)
+ path_list += [os.path.join(data_dir, pp) for pp in os.listdir(data_dir)]
+
+if not os.path.exists(target_dir):
+ os.makedirs(target_dir)
+
+print('Building RGB dict...')
+res_dict = {}
+for img_path in tqdm.tqdm(path_list[:], total=len(path_list)):
+ for dd in data_name:
+ if img_path.find(dd) != -1:
+ dataset_name = dd
+ break
+ else:
+ raise NotImplementedError
+ base_name = os.path.basename(img_path)
+ hair_path = os.path.join(root_dir, dataset_name, imgs_sub_dir, base_name)
+ hair_img = cv2.cvtColor(cv2.imread(hair_path), cv2.COLOR_BGR2RGB)
+ hair_parsing = cv2.imread(os.path.join(root_dir, dataset_name, 'label', base_name), cv2.IMREAD_GRAYSCALE)
+ mask_img = cv2.resize(hair_parsing.astype('uint8'), hair_img.shape[:2], interpolation=cv2.INTER_NEAREST)
+
+ hair_mask = (mask_img == HAIR_IDX).astype('uint8')
+ kernel13 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(19, 19))
+ hair_mask = cv2.erode(hair_mask, kernel13, iterations=1)
+
+ points = hair_img[hair_mask.astype('bool')]
+
+ moment1 = points.mean(axis=0)
+ moment2 = ((points - moment1) ** 2).mean(axis=0)
+ moment3 = ((points - moment1) ** 3).mean(axis=0)
+ moment4 = ((points - moment1) ** 4).mean(axis=0)
+
+ target_file = os.path.join(target_dir, '%s___%s.pkl' % (dataset_name, base_name[:-4]))
+ with open(target_file, 'wb') as f:
+ pickle.dump([moment1, moment2, moment3, moment4], f)
+
+rgb_stat_path = os.path.join(root_dir, 'rgb_stat_dict.pkl')
+merge_pickle_dir_to_dict(target_dir, os.path.join(root_dir, 'rgb_stat_dict.pkl'))
+
+### get hsv dict
+print('Building ordered HSV dict for assisting distribution fitting...')
+data_root = GLOBAL_DATA_ROOT
+output_path = os.path.join(GLOBAL_DATA_ROOT, 'hsv_stat_dict_ordered.pkl')
+
+with open(rgb_stat_path, 'rb') as f:
+ rgb_stat_dict = pickle.load(f)
+
+files = list(rgb_stat_dict)
+
+cols = [rgb_stat_dict[f][0] for f in files]
+cols = np.array(cols)
+cols_hsv = cv2.cvtColor(cols[None, ...].astype('uint8'), cv2.COLOR_RGB2HSV)[0]
+
+for dim in range(3):
+ cols_hsv[:, dim].sort()
+
+with open(output_path, 'wb') as f:
+ pickle.dump(cols_hsv, f)
diff --git a/models/CtrlHair/dataset_scripts/script_get_sean_code.py b/models/CtrlHair/dataset_scripts/script_get_sean_code.py
new file mode 100644
index 0000000000000000000000000000000000000000..95dddb0cc799980f844a20db61cb4d9c0a6a954c
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_get_sean_code.py
@@ -0,0 +1,62 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_get_sean_code.py
+# Time : 2021/11/16 15:56
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import os
+import sys
+sys.path.append('.')
+
+from dataset_scripts.utils import merge_pickle_dir_to_dict
+import cv2
+import tqdm
+from global_value_utils import GLOBAL_DATA_ROOT, DATASET_NAME
+
+from hair_editor import HairEditor
+import pickle
+
+data_name = DATASET_NAME
+
+root_dir = GLOBAL_DATA_ROOT
+imgs_sub_dir = 'images_256'
+target_dir = os.path.join(root_dir, 'hair_info_all_dataset/sean_code')
+
+he = HairEditor(load_mask_model=False)
+path_list = []
+for d in data_name:
+ data_dir = os.path.join(root_dir, d, imgs_sub_dir)
+ path_list += [os.path.join(data_dir, pp) for pp in os.listdir(data_dir)]
+
+path_list.sort()
+# res_dict = {}
+
+if not os.path.exists(target_dir):
+ os.makedirs(target_dir)
+
+for img_path in tqdm.tqdm(path_list):
+ for dd in data_name:
+ if img_path.find(dd) != -1:
+ dataset_name = dd
+ break
+ else:
+ raise NotImplementedError
+ base_name = os.path.basename(img_path)
+ hair_path = os.path.join(root_dir, dataset_name, imgs_sub_dir, base_name)
+ hair_img = cv2.cvtColor(cv2.imread(hair_path), cv2.COLOR_BGR2RGB)
+ hair_parsing = cv2.imread(os.path.join(root_dir, dataset_name, 'label', base_name), cv2.IMREAD_GRAYSCALE)
+ # resize
+ hair_img = he.preprocess_img(hair_img)
+ hair_parsing = he.preprocess_mask(hair_parsing)
+ cur_code = he.get_code(hair_img, hair_parsing)
+ cur_code = cur_code.cpu().numpy()[0]
+ # res_dict['%s___%s' % (dataset_name, base_name)] = cur_code
+
+ target_file = os.path.join(target_dir, '%s___%s.pkl' % (dataset_name, base_name[:-4]))
+ with open(target_file, 'wb') as f:
+ pickle.dump(cur_code, f)
+
+merge_pickle_dir_to_dict(target_dir, os.path.join(root_dir, 'sean_code_dict.pkl'))
diff --git a/models/CtrlHair/dataset_scripts/script_landmark_detection.py b/models/CtrlHair/dataset_scripts/script_landmark_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7978fd3a2943eeed5775d88d8d6c432cbd6c90f
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/script_landmark_detection.py
@@ -0,0 +1,16 @@
+import sys
+sys.path.append('.')
+
+from external_code.landmarks_util import detect_landmarks, predictor_dict
+from global_value_utils import GLOBAL_DATA_ROOT, DATASET_NAME
+
+
+data_name = DATASET_NAME
+
+root_dir = GLOBAL_DATA_ROOT
+
+for landmark_num in [81, 68]:
+ print('detect %d landmarks' % landmark_num)
+ detect_landmarks(root_dir, data_name,
+ landmark_output_file_path=root_dir + '/landmark%d.pkl' % landmark_num,
+ output_dir=None, predictor=predictor_dict[landmark_num])
diff --git a/models/CtrlHair/dataset_scripts/utils.py b/models/CtrlHair/dataset_scripts/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1675f905e95495d5f32207dee988bb98df8a6e3
--- /dev/null
+++ b/models/CtrlHair/dataset_scripts/utils.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: utils.py
+# Time : 2021/11/29 16:36
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import pickle
+import tqdm
+
+
+def merge_pickle_dir_to_dict(dir_name, target_path):
+ files = os.listdir(dir_name)
+ res_dir = {}
+ for f_name in tqdm.tqdm(files):
+ with open(os.path.join(dir_name, f_name), 'rb') as f:
+ res_dir[f_name[:-4]] = pickle.load(f)
+ with open(target_path, 'wb') as f:
+ pickle.dump(res_dir, f)
diff --git a/models/CtrlHair/external_code/__init__.py b/models/CtrlHair/external_code/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..db11b4ed69d71461922f4d9fc1dae30214df11ab
--- /dev/null
+++ b/models/CtrlHair/external_code/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py
+# Time : 2021/9/3 21:14
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/external_code/crop.py b/models/CtrlHair/external_code/crop.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc3f7f4b76d4db5b82cc49c0a7608d075bc26318
--- /dev/null
+++ b/models/CtrlHair/external_code/crop.py
@@ -0,0 +1,117 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: crop.py
+# Time : 2021/9/30 21:20
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import os
+import PIL.Image
+import PIL.ImageFile
+import numpy as np
+import scipy.ndimage
+import cv2
+
+PIL.ImageFile.LOAD_TRUNCATED_IMAGES = True # avoid "Decompressed Data Too Large" error
+
+
+def recreate_aligned_images(img, lm_68, output_size=1024, transform_size=4096, enable_padding=True):
+ pil_img = PIL.Image.fromarray(img)
+ lm_chin = lm_68[0: 17] # left-right
+ lm_eyebrow_left = lm_68[17: 22] # left-right
+ lm_eyebrow_right = lm_68[22: 27] # left-right
+ lm_nose = lm_68[27: 31] # top-down
+ lm_nostrils = lm_68[31: 36] # top-down
+ lm_eye_left = lm_68[36: 42] # left-clockwise
+ lm_eye_right = lm_68[42: 48] # left-clockwise
+ lm_mouth_outer = lm_68[48: 60] # left-clockwise
+ lm_mouth_inner = lm_68[60: 68] # left-clockwise
+
+ # Calculate auxiliary vectors.
+ eye_left = np.mean(lm_eye_left, axis=0)
+ eye_right = np.mean(lm_eye_right, axis=0)
+ eye_avg = (eye_left + eye_right) * 0.5
+ eye_to_eye = eye_right - eye_left
+ mouth_left = lm_mouth_outer[0]
+ mouth_right = lm_mouth_outer[6]
+ mouth_avg = (mouth_left + mouth_right) * 0.5
+ eye_to_mouth = mouth_avg - eye_avg
+
+ # Choose oriented crop rectangle.
+ x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1]
+ x /= np.hypot(*x)
+ x *= max(np.hypot(*eye_to_eye) * 2.0, np.hypot(*eye_to_mouth) * 1.8)
+ y = np.flipud(x) * [-1, 1]
+ c = eye_avg + eye_to_mouth * 0.1
+ quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y])
+ qsize = np.hypot(*x) * 2
+
+ # Load in-the-wild image.
+ img = pil_img
+
+ trans_points = lm_68
+
+ # Shrink.
+ shrink = int(np.floor(qsize / output_size * 0.5))
+ if shrink > 1:
+ rsize = (int(np.rint(float(img.size[0]) / shrink)), int(np.rint(float(img.size[1]) / shrink)))
+ img = img.resize(rsize, PIL.Image.ANTIALIAS)
+ quad /= shrink
+ qsize /= shrink
+ trans_points = trans_points / shrink
+
+ # Crop.
+ border = max(int(np.rint(qsize * 0.1)), 3)
+ crop = (int(np.floor(min(quad[:, 0]))), int(np.floor(min(quad[:, 1]))), int(np.ceil(max(quad[:, 0]))),
+ int(np.ceil(max(quad[:, 1]))))
+ crop = (max(crop[0] - border, 0), max(crop[1] - border, 0), min(crop[2] + border, img.size[0]),
+ min(crop[3] + border, img.size[1]))
+ if crop[2] - crop[0] < img.size[0] or crop[3] - crop[1] < img.size[1]:
+ img = img.crop(crop)
+ quad -= crop[0:2]
+ trans_points = trans_points - np.array([crop[0], crop[1]])
+
+ # Pad.
+ pad = (int(np.floor(min(quad[:, 0]))), int(np.floor(min(quad[:, 1]))), int(np.ceil(max(quad[:, 0]))),
+ int(np.ceil(max(quad[:, 1]))))
+ pad = (max(-pad[0] + border, 0), max(-pad[1] + border, 0), max(pad[2] - img.size[0] + border, 0),
+ max(pad[3] - img.size[1] + border, 0))
+ if enable_padding and max(pad) > border - 4:
+ pad = np.maximum(pad, int(np.rint(qsize * 0.3)))
+ img = np.pad(np.float32(img), ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect')
+ trans_points = trans_points + np.array([pad[0], pad[1]])
+ h, w, _ = img.shape
+ y, x, _ = np.ogrid[:h, :w, :1]
+ mask = np.maximum(1.0 - np.minimum(np.float32(x) / pad[0], np.float32(w - 1 - x) / pad[2]),
+ 1.0 - np.minimum(np.float32(y) / pad[1], np.float32(h - 1 - y) / pad[3]))
+ blur = qsize * 0.02
+ img += (scipy.ndimage.gaussian_filter(img, [blur, blur, 0]) - img) * np.clip(mask * 3.0 + 1.0, 0.0, 1.0)
+ img += (np.median(img, axis=(0, 1)) - img) * np.clip(mask, 0.0, 1.0)
+ img = PIL.Image.fromarray(np.uint8(np.clip(np.rint(img), 0, 255)), 'RGB')
+ quad += pad[:2]
+
+ # Transform.
+ trans_data = (quad + 0.5)
+ img = img.transform((transform_size, transform_size), PIL.Image.QUAD, trans_data.flatten(), PIL.Image.BILINEAR)
+ if output_size < transform_size:
+ img = img.resize((output_size, output_size), PIL.Image.ANTIALIAS)
+
+ projective_matrix = cv2.getPerspectiveTransform(trans_data.astype('float32'),
+ np.array([[0, 0], [0, 1], [1, 1], [1, 0]], dtype='float32'))
+ augmented_lm = projective_matrix @ np.concatenate([trans_points, np.ones([trans_points.shape[0], 1])], axis=1).T
+ trans_points = augmented_lm[:2, :] / augmented_lm[2] * output_size
+ trans_points = trans_points.T
+ trans_points = (trans_points + 0.5).astype('int32')
+ return img, trans_points[:68]
+
+
+def draw_landmarks(landmarks, img_np, font_size=1.0):
+ font = cv2.FONT_HERSHEY_SIMPLEX
+ for idx, point in enumerate(landmarks):
+ pos = (point[0], point[1])
+ cv2.circle(img_np, pos, 2, color=(139, 0, 0))
+ cv2.putText(img_np, str(idx + 1), pos, font, font_size, (0, 0, 255), 1, cv2.LINE_AA)
+ return img_np
+
diff --git a/models/CtrlHair/external_code/face_parsing/.gitignore b/models/CtrlHair/external_code/face_parsing/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..84f4b705b91b81ad5235418eea25eb1fa7669c9f
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/.gitignore
@@ -0,0 +1,110 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+# resources
+res/
+
+.idea/
+
diff --git a/models/CtrlHair/external_code/face_parsing/LICENSE b/models/CtrlHair/external_code/face_parsing/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..bfae0b0c29f885a118e382b445b6eaeca0d3b3e6
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019 zll
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/models/CtrlHair/external_code/face_parsing/README.md b/models/CtrlHair/external_code/face_parsing/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..849d55e2789c8852e01707d1ff755dc74e63a7f5
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/README.md
@@ -0,0 +1,68 @@
+# face-parsing.PyTorch
+
+
+
+  +
+
+
+
+
+### Contents
+- [Training](#training)
+- [Demo](#Demo)
+- [References](#references)
+
+## Training
+
+1. Prepare training data:
+ -- download [CelebAMask-HQ dataset](https://github.com/switchablenorms/CelebAMask-HQ)
+
+ -- change file path in the `prepropess_data.py` and run
+```Shell
+python prepropess_data.py
+```
+
+2. Train the model using CelebAMask-HQ dataset:
+Just run the train script:
+```
+ $ CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
+```
+
+If you do not wish to train the model, you can download [our pre-trained model](https://drive.google.com/open?id=154JgKpzCPW82qINcVieuPH3fZ2e0P812) and save it in `res/cp`.
+
+
+## Demo
+1. Evaluate the trained model using:
+```Shell
+# evaluate using GPU
+python test.py
+```
+
+## Face makeup using parsing maps
+[**face-makeup.PyTorch**](https://github.com/zllrunning/face-makeup.PyTorch)
+
+
+
+| |
+Hair |
+Lip |
+
+
+
+
+| Original Input |
+ |
+ |
+
+
+
+
+| Color |
+ |
+ |
+
+
+
+
+
+## References
+- [BiSeNet](https://github.com/CoinCheung/BiSeNet)
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/__init__.py b/models/CtrlHair/external_code/face_parsing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f506a5ea11d8716ff556d6868d67965bcb34bdf
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py
+# Time : 2022/07/15
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/external_code/face_parsing/evaluate.py b/models/CtrlHair/external_code/face_parsing/evaluate.py
new file mode 100644
index 0000000000000000000000000000000000000000..260d5ba9e52e5dfd108a06ef53e7a49e60ab4ede
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/evaluate.py
@@ -0,0 +1,95 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+from logger import setup_logger
+from model import BiSeNet
+from face_dataset import FaceMask
+
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+import torch.nn.functional as F
+import torch.distributed as dist
+
+import os
+import os.path as osp
+import logging
+import time
+import numpy as np
+from tqdm import tqdm
+import math
+from PIL import Image
+import torchvision.transforms as transforms
+import cv2
+
+def vis_parsing_maps(im, parsing_anno, stride, save_im=False, save_path='vis_results/parsing_map_on_im.jpg'):
+ # Colors for all 20 parts
+ part_colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0],
+ [255, 0, 85], [255, 0, 170],
+ [0, 255, 0], [85, 255, 0], [170, 255, 0],
+ [0, 255, 85], [0, 255, 170],
+ [0, 0, 255], [85, 0, 255], [170, 0, 255],
+ [0, 85, 255], [0, 170, 255],
+ [255, 255, 0], [255, 255, 85], [255, 255, 170],
+ [255, 0, 255], [255, 85, 255], [255, 170, 255],
+ [0, 255, 255], [85, 255, 255], [170, 255, 255]]
+
+ im = np.array(im)
+ vis_im = im.copy().astype(np.uint8)
+ vis_parsing_anno = parsing_anno.copy().astype(np.uint8)
+ vis_parsing_anno = cv2.resize(vis_parsing_anno, None, fx=stride, fy=stride, interpolation=cv2.INTER_NEAREST)
+ vis_parsing_anno_color = np.zeros((vis_parsing_anno.shape[0], vis_parsing_anno.shape[1], 3)) + 255
+
+ num_of_class = np.max(vis_parsing_anno)
+
+ for pi in range(1, num_of_class + 1):
+ index = np.where(vis_parsing_anno == pi)
+ vis_parsing_anno_color[index[0], index[1], :] = part_colors[pi]
+
+ vis_parsing_anno_color = vis_parsing_anno_color.astype(np.uint8)
+ # print(vis_parsing_anno_color.shape, vis_im.shape)
+ vis_im = cv2.addWeighted(cv2.cvtColor(vis_im, cv2.COLOR_RGB2BGR), 0.4, vis_parsing_anno_color, 0.6, 0)
+
+ # Save result or not
+ if save_im:
+ cv2.imwrite(save_path, vis_im, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
+
+ # return vis_im
+
+def evaluate(respth='./resources/test_res', dspth='./data', cp='model_final_diss.pth'):
+
+ if not os.path.exists(respth):
+ os.makedirs(respth)
+
+ n_classes = 19
+ net = BiSeNet(n_classes=n_classes)
+ net.cuda()
+ save_pth = osp.join('res/cp', cp)
+ net.load_state_dict(torch.load(save_pth))
+ net.eval()
+
+ to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ])
+ with torch.no_grad():
+ for image_path in os.listdir(dspth):
+ img = Image.open(osp.join(dspth, image_path))
+ image = img.resize((512, 512), Image.BILINEAR)
+ img = to_tensor(image)
+ img = torch.unsqueeze(img, 0)
+ img = img.cuda()
+ out = net(img)[0]
+ parsing = out.squeeze(0).cpu().numpy().argmax(0)
+
+ vis_parsing_maps(image, parsing, stride=1, save_im=True, save_path=osp.join(respth, image_path))
+
+
+
+
+
+
+
+if __name__ == "__main__":
+ setup_logger('./resources')
+ evaluate()
diff --git a/models/CtrlHair/external_code/face_parsing/face_dataset.py b/models/CtrlHair/external_code/face_parsing/face_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..0721105298e8e59410b570f9c2f4c9177ac51518
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/face_dataset.py
@@ -0,0 +1,106 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+import torch
+from torch.utils.data import Dataset
+import torchvision.transforms as transforms
+
+import os.path as osp
+import os
+from PIL import Image
+import numpy as np
+import json
+import cv2
+
+from transform import *
+
+
+
+class FaceMask(Dataset):
+ def __init__(self, rootpth, cropsize=(640, 480), mode='scripts', *args, **kwargs):
+ super(FaceMask, self).__init__(*args, **kwargs)
+ assert mode in ('scripts', 'val', 'test')
+ self.mode = mode
+ self.ignore_lb = 255
+ self.rootpth = rootpth
+
+ self.imgs = os.listdir(os.path.join(self.rootpth, 'CelebA-HQ-img'))
+
+ # pre-processing
+ self.to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ])
+ self.trans_train = Compose([
+ ColorJitter(
+ brightness=0.5,
+ contrast=0.5,
+ saturation=0.5),
+ HorizontalFlip(),
+ RandomScale((0.75, 1.0, 1.25, 1.5, 1.75, 2.0)),
+ RandomCrop(cropsize)
+ ])
+
+ def __getitem__(self, idx):
+ impth = self.imgs[idx]
+ img = Image.open(osp.join(self.rootpth, 'CelebA-HQ-img', impth))
+ img = img.resize((512, 512), Image.BILINEAR)
+ label = Image.open(osp.join(self.rootpth, 'mask', impth[:-3]+'png')).convert('P')
+ # print(np.unique(np.array(label)))
+ if self.mode == 'scripts':
+ im_lb = dict(im=img, lb=label)
+ im_lb = self.trans_train(im_lb)
+ img, label = im_lb['im'], im_lb['lb']
+ img = self.to_tensor(img)
+ label = np.array(label).astype(np.int64)[np.newaxis, :]
+ return img, label
+
+ def __len__(self):
+ return len(self.imgs)
+
+
+if __name__ == "__main__":
+ face_data = '/home/zll/data/CelebAMask-HQ/CelebA-HQ-img'
+ face_sep_mask = '/home/zll/data/CelebAMask-HQ/CelebAMask-HQ-mask-anno'
+ mask_path = '/home/zll/data/CelebAMask-HQ/mask'
+ counter = 0
+ total = 0
+ for i in range(15):
+ # files = os.listdir(osp.join(face_sep_mask, str(i)))
+
+ atts = ['skin', 'l_brow', 'r_brow', 'l_eye', 'r_eye', 'eye_g', 'l_ear', 'r_ear', 'ear_r',
+ 'nose', 'mouth', 'u_lip', 'l_lip', 'neck', 'neck_l', 'cloth', 'hair', 'hat']
+
+ for j in range(i*2000, (i+1)*2000):
+
+ mask = np.zeros((512, 512))
+
+ for l, att in enumerate(atts, 1):
+ total += 1
+ file_name = ''.join([str(j).rjust(5, '0'), '_', att, '.png'])
+ path = osp.join(face_sep_mask, str(i), file_name)
+
+ if os.path.exists(path):
+ counter += 1
+ sep_mask = np.array(Image.open(path).convert('P'))
+ # print(np.unique(sep_mask))
+
+ mask[sep_mask == 225] = l
+ cv2.imwrite('{}/{}.png'.format(mask_path, j), mask)
+ print(j)
+
+ print(counter, total)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/models/CtrlHair/external_code/face_parsing/logger.py b/models/CtrlHair/external_code/face_parsing/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3f9ddcc2cae221b4dd881d02404e848b5396f7e
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/logger.py
@@ -0,0 +1,23 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+import os.path as osp
+import time
+import sys
+import logging
+
+import torch.distributed as dist
+
+
+def setup_logger(logpth):
+ logfile = 'BiSeNet-{}.log'.format(time.strftime('%Y-%m-%d-%H-%M-%S'))
+ logfile = osp.join(logpth, logfile)
+ FORMAT = '%(levelname)s %(filename)s(%(lineno)d): %(message)s'
+ log_level = logging.INFO
+ if dist.is_initialized() and not dist.get_rank()==0:
+ log_level = logging.ERROR
+ logging.basicConfig(level=log_level, format=FORMAT, filename=logfile)
+ logging.root.addHandler(logging.StreamHandler())
+
+
diff --git a/models/CtrlHair/external_code/face_parsing/loss.py b/models/CtrlHair/external_code/face_parsing/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8f65aa05566853cb87678d97926bd03b911e166
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/loss.py
@@ -0,0 +1,75 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+import numpy as np
+
+
+class OhemCELoss(nn.Module):
+ def __init__(self, thresh, n_min, ignore_lb=255, *args, **kwargs):
+ super(OhemCELoss, self).__init__()
+ self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float)).cuda()
+ self.n_min = n_min
+ self.ignore_lb = ignore_lb
+ self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
+
+ def forward(self, logits, labels):
+ N, C, H, W = logits.size()
+ loss = self.criteria(logits, labels).view(-1)
+ loss, _ = torch.sort(loss, descending=True)
+ if loss[self.n_min] > self.thresh:
+ loss = loss[loss>self.thresh]
+ else:
+ loss = loss[:self.n_min]
+ return torch.mean(loss)
+
+
+class SoftmaxFocalLoss(nn.Module):
+ def __init__(self, gamma, ignore_lb=255, *args, **kwargs):
+ super(SoftmaxFocalLoss, self).__init__()
+ self.gamma = gamma
+ self.nll = nn.NLLLoss(ignore_index=ignore_lb)
+
+ def forward(self, logits, labels):
+ scores = F.softmax(logits, dim=1)
+ factor = torch.pow(1.-scores, self.gamma)
+ log_score = F.log_softmax(logits, dim=1)
+ log_score = factor * log_score
+ loss = self.nll(log_score, labels)
+ return loss
+
+
+if __name__ == '__main__':
+ torch.manual_seed(15)
+ criteria1 = OhemCELoss(thresh=0.7, n_min=16*20*20//16).cuda()
+ criteria2 = OhemCELoss(thresh=0.7, n_min=16*20*20//16).cuda()
+ net1 = nn.Sequential(
+ nn.Conv2d(3, 19, kernel_size=3, stride=2, padding=1),
+ )
+ net1.cuda()
+ net1.train()
+ net2 = nn.Sequential(
+ nn.Conv2d(3, 19, kernel_size=3, stride=2, padding=1),
+ )
+ net2.cuda()
+ net2.train()
+
+ with torch.no_grad():
+ inten = torch.randn(16, 3, 20, 20).cuda()
+ lbs = torch.randint(0, 19, [16, 20, 20]).cuda()
+ lbs[1, :, :] = 255
+
+ logits1 = net1(inten)
+ logits1 = F.interpolate(logits1, inten.size()[2:], mode='bilinear')
+ logits2 = net2(inten)
+ logits2 = F.interpolate(logits2, inten.size()[2:], mode='bilinear')
+
+ loss1 = criteria1(logits1, lbs)
+ loss2 = criteria2(logits2, lbs)
+ loss = loss1 + loss2
+ print(loss.detach().cpu())
+ loss.backward()
diff --git a/models/CtrlHair/external_code/face_parsing/makeup.py b/models/CtrlHair/external_code/face_parsing/makeup.py
new file mode 100644
index 0000000000000000000000000000000000000000..13ae9c0167d7a389be2988ea2c486065c95964fb
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/makeup.py
@@ -0,0 +1,130 @@
+import cv2
+import os
+import numpy as np
+from skimage.filters import gaussian
+
+
+def sharpen(img):
+ img = img * 1.0
+ gauss_out = gaussian(img, sigma=5, multichannel=True)
+
+ alpha = 1.5
+ img_out = (img - gauss_out) * alpha + img
+
+ img_out = img_out / 255.0
+
+ mask_1 = img_out < 0
+ mask_2 = img_out > 1
+
+ img_out = img_out * (1 - mask_1)
+ img_out = img_out * (1 - mask_2) + mask_2
+ img_out = np.clip(img_out, 0, 1)
+ img_out = img_out * 255
+ return np.array(img_out, dtype=np.uint8)
+
+
+def hair(image, parsing, part=17, color=[230, 50, 20]):
+ b, g, r = color #[10, 50, 250] # [10, 250, 10]
+ tar_color = np.zeros_like(image)
+ tar_color[:, :, 0] = b
+ tar_color[:, :, 1] = g
+ tar_color[:, :, 2] = r
+
+ image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+ tar_hsv = cv2.cvtColor(tar_color, cv2.COLOR_BGR2HSV)
+
+ if part == 12 or part == 13:
+ image_hsv[:, :, 0:2] = tar_hsv[:, :, 0:2]
+ else:
+ image_hsv[:, :, 0:1] = tar_hsv[:, :, 0:1]
+
+ changed = cv2.cvtColor(image_hsv, cv2.COLOR_HSV2BGR)
+
+ if part == 17:
+ changed = sharpen(changed)
+
+ changed[parsing != part] = image[parsing != part]
+ # changed = cv2.resize(changed, (512, 512))
+ return changed
+
+#
+# def lip(image, parsing, part=17, color=[230, 50, 20]):
+# b, g, r = color #[10, 50, 250] # [10, 250, 10]
+# tar_color = np.zeros_like(image)
+# tar_color[:, :, 0] = b
+# tar_color[:, :, 1] = g
+# tar_color[:, :, 2] = r
+#
+# image_lab = cv2.cvtColor(image, cv2.COLOR_BGR2Lab)
+# il, ia, ib = cv2.split(image_lab)
+#
+# tar_lab = cv2.cvtColor(tar_color, cv2.COLOR_BGR2Lab)
+# tl, ta, tb = cv2.split(tar_lab)
+#
+# image_lab[:, :, 0] = np.clip(il - np.mean(il) + tl, 0, 100)
+# image_lab[:, :, 1] = np.clip(ia - np.mean(ia) + ta, -127, 128)
+# image_lab[:, :, 2] = np.clip(ib - np.mean(ib) + tb, -127, 128)
+#
+#
+# changed = cv2.cvtColor(image_lab, cv2.COLOR_Lab2BGR)
+#
+# if part == 17:
+# changed = sharpen(changed)
+#
+# changed[parsing != part] = image[parsing != part]
+# # changed = cv2.resize(changed, (512, 512))
+# return changed
+
+
+if __name__ == '__main__':
+ # 1 face
+ # 10 nose
+ # 11 teeth
+ # 12 upper lip
+ # 13 lower lip
+ # 17 hair
+ num = 116
+ table = {
+ 'hair': 17,
+ 'upper_lip': 12,
+ 'lower_lip': 13
+ }
+ image_path = '/home/zll/data/CelebAMask-HQ/test-img/{}.jpg'.format(num)
+ parsing_path = 'resources/test_res/{}.png'.format(num)
+
+ image = cv2.imread(image_path)
+ ori = image.copy()
+ parsing = np.array(cv2.imread(parsing_path, 0))
+ parsing = cv2.resize(parsing, image.shape[0:2], interpolation=cv2.INTER_NEAREST)
+
+ parts = [table['hair'], table['upper_lip'], table['lower_lip']]
+ # colors = [[20, 20, 200], [100, 100, 230], [100, 100, 230]]
+ colors = [[100, 200, 100]]
+ for part, color in zip(parts, colors):
+ image = hair(image, parsing, part, color)
+ cv2.imwrite('res/makeup/116_ori.png', cv2.resize(ori, (512, 512)))
+ cv2.imwrite('res/makeup/116_2.png', cv2.resize(image, (512, 512)))
+
+ cv2.imshow('image', cv2.resize(ori, (512, 512)))
+ cv2.imshow('color', cv2.resize(image, (512, 512)))
+
+ # cv2.imshow('image', ori)
+ # cv2.imshow('color', image)
+
+ cv2.waitKey(0)
+ cv2.destroyAllWindows()
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/models/CtrlHair/external_code/face_parsing/model.py b/models/CtrlHair/external_code/face_parsing/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..5119e751c3ae18e4dc1eecde7bfcb5bf9c62fb92
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/model.py
@@ -0,0 +1,283 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision
+
+from .resnet import Resnet18
+# from modules.bn import InPlaceABNSync as BatchNorm2d
+
+
+class ConvBNReLU(nn.Module):
+ def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
+ super(ConvBNReLU, self).__init__()
+ self.conv = nn.Conv2d(in_chan,
+ out_chan,
+ kernel_size = ks,
+ stride = stride,
+ padding = padding,
+ bias = False)
+ self.bn = nn.BatchNorm2d(out_chan)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = F.relu(self.bn(x))
+ return x
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+class BiSeNetOutput(nn.Module):
+ def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
+ super(BiSeNetOutput, self).__init__()
+ self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
+ self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.conv_out(x)
+ return x
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class AttentionRefinementModule(nn.Module):
+ def __init__(self, in_chan, out_chan, *args, **kwargs):
+ super(AttentionRefinementModule, self).__init__()
+ self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
+ self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
+ self.bn_atten = nn.BatchNorm2d(out_chan)
+ self.sigmoid_atten = nn.Sigmoid()
+ self.init_weight()
+
+ def forward(self, x):
+ feat = self.conv(x)
+ atten = F.avg_pool2d(feat, feat.size()[2:])
+ atten = self.conv_atten(atten)
+ atten = self.bn_atten(atten)
+ atten = self.sigmoid_atten(atten)
+ out = torch.mul(feat, atten)
+ return out
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+
+class ContextPath(nn.Module):
+ def __init__(self, *args, **kwargs):
+ super(ContextPath, self).__init__()
+ self.resnet = Resnet18()
+ self.arm16 = AttentionRefinementModule(256, 128)
+ self.arm32 = AttentionRefinementModule(512, 128)
+ self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
+ self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
+ self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
+
+ self.init_weight()
+
+ def forward(self, x):
+ H0, W0 = x.size()[2:]
+ feat8, feat16, feat32 = self.resnet(x)
+ H8, W8 = feat8.size()[2:]
+ H16, W16 = feat16.size()[2:]
+ H32, W32 = feat32.size()[2:]
+
+ avg = F.avg_pool2d(feat32, feat32.size()[2:])
+ avg = self.conv_avg(avg)
+ avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
+
+ feat32_arm = self.arm32(feat32)
+ feat32_sum = feat32_arm + avg_up
+ feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
+ feat32_up = self.conv_head32(feat32_up)
+
+ feat16_arm = self.arm16(feat16)
+ feat16_sum = feat16_arm + feat32_up
+ feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
+ feat16_up = self.conv_head16(feat16_up)
+
+ return feat8, feat16_up, feat32_up # x8, x8, x16
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+### This is not used, since I replace this with the resnet feature with the same size
+class SpatialPath(nn.Module):
+ def __init__(self, *args, **kwargs):
+ super(SpatialPath, self).__init__()
+ self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
+ self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
+ self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
+ self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
+ self.init_weight()
+
+ def forward(self, x):
+ feat = self.conv1(x)
+ feat = self.conv2(feat)
+ feat = self.conv3(feat)
+ feat = self.conv_out(feat)
+ return feat
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class FeatureFusionModule(nn.Module):
+ def __init__(self, in_chan, out_chan, *args, **kwargs):
+ super(FeatureFusionModule, self).__init__()
+ self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
+ self.conv1 = nn.Conv2d(out_chan,
+ out_chan//4,
+ kernel_size = 1,
+ stride = 1,
+ padding = 0,
+ bias = False)
+ self.conv2 = nn.Conv2d(out_chan//4,
+ out_chan,
+ kernel_size = 1,
+ stride = 1,
+ padding = 0,
+ bias = False)
+ self.relu = nn.ReLU(inplace=True)
+ self.sigmoid = nn.Sigmoid()
+ self.init_weight()
+
+ def forward(self, fsp, fcp):
+ fcat = torch.cat([fsp, fcp], dim=1)
+ feat = self.convblk(fcat)
+ atten = F.avg_pool2d(feat, feat.size()[2:])
+ atten = self.conv1(atten)
+ atten = self.relu(atten)
+ atten = self.conv2(atten)
+ atten = self.sigmoid(atten)
+ feat_atten = torch.mul(feat, atten)
+ feat_out = feat_atten + feat
+ return feat_out
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class BiSeNet(nn.Module):
+ def __init__(self, n_classes, *args, **kwargs):
+ super(BiSeNet, self).__init__()
+ self.cp = ContextPath()
+ ## here self.sp is deleted
+ self.ffm = FeatureFusionModule(256, 256)
+ self.conv_out = BiSeNetOutput(256, 256, n_classes)
+ self.conv_out16 = BiSeNetOutput(128, 64, n_classes)
+ self.conv_out32 = BiSeNetOutput(128, 64, n_classes)
+ self.init_weight()
+
+ def forward(self, x):
+ H, W = x.size()[2:]
+ feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
+ feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
+ feat_fuse = self.ffm(feat_sp, feat_cp8)
+
+ feat_out = self.conv_out(feat_fuse)
+ feat_out16 = self.conv_out16(feat_cp8)
+ feat_out32 = self.conv_out32(feat_cp16)
+
+ feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
+ feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
+ feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
+ return feat_out, feat_out16, feat_out32
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
+ for name, child in self.named_children():
+ child_wd_params, child_nowd_params = child.get_params()
+ if isinstance(child, FeatureFusionModule) or isinstance(child, BiSeNetOutput):
+ lr_mul_wd_params += child_wd_params
+ lr_mul_nowd_params += child_nowd_params
+ else:
+ wd_params += child_wd_params
+ nowd_params += child_nowd_params
+ return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
+
+
+if __name__ == "__main__":
+ net = BiSeNet(19)
+ net.cuda()
+ net.eval()
+ in_ten = torch.randn(16, 3, 640, 480).cuda()
+ out, out16, out32 = net(in_ten)
+ print(out.shape)
+
+ net.get_params()
diff --git a/models/CtrlHair/external_code/face_parsing/modules/__init__.py b/models/CtrlHair/external_code/face_parsing/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a098dee5911f3613d320d23db37bc401cf57fa4
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/__init__.py
@@ -0,0 +1,5 @@
+from .bn import ABN, InPlaceABN, InPlaceABNSync
+from .functions import ACT_RELU, ACT_LEAKY_RELU, ACT_ELU, ACT_NONE
+from .misc import GlobalAvgPool2d, SingleGPU
+from .residual import IdentityResidualBlock
+from .dense import DenseModule
diff --git a/models/CtrlHair/external_code/face_parsing/modules/bn.py b/models/CtrlHair/external_code/face_parsing/modules/bn.py
new file mode 100644
index 0000000000000000000000000000000000000000..da1f4b8a5df982c8407787af25a7def3809d6de3
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/bn.py
@@ -0,0 +1,130 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as functional
+
+try:
+ from queue import Queue
+except ImportError:
+ from Queue import Queue
+
+from .functions import *
+
+
+class ABN(nn.Module):
+ """Activated Batch Normalization
+
+ This gathers a `BatchNorm2d` and an activation function in a single module
+ """
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True, activation="leaky_relu", slope=0.01):
+ """Creates an Activated Batch Normalization module
+
+ Parameters
+ ----------
+ num_features : int
+ Number of feature channels in the input and color_texture.
+ eps : float
+ Small constant to prevent numerical issues.
+ momentum : float
+ Momentum factor applied to compute running statistics as.
+ affine : bool
+ If `True` apply learned scale and shift transformation after normalization.
+ activation : str
+ Name of the activation functions, one of: `leaky_relu`, `elu` or `none`.
+ slope : float
+ Negative slope for the `leaky_relu` activation.
+ """
+ super(ABN, self).__init__()
+ self.num_features = num_features
+ self.affine = affine
+ self.eps = eps
+ self.momentum = momentum
+ self.activation = activation
+ self.slope = slope
+ if self.affine:
+ self.weight = nn.Parameter(torch.ones(num_features))
+ self.bias = nn.Parameter(torch.zeros(num_features))
+ else:
+ self.register_parameter('weight', None)
+ self.register_parameter('bias', None)
+ self.register_buffer('running_mean', torch.zeros(num_features))
+ self.register_buffer('running_var', torch.ones(num_features))
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ nn.init.constant_(self.running_mean, 0)
+ nn.init.constant_(self.running_var, 1)
+ if self.affine:
+ nn.init.constant_(self.weight, 1)
+ nn.init.constant_(self.bias, 0)
+
+ def forward(self, x):
+ x = functional.batch_norm(x, self.running_mean, self.running_var, self.weight, self.bias,
+ self.training, self.momentum, self.eps)
+
+ if self.activation == ACT_RELU:
+ return functional.relu(x, inplace=True)
+ elif self.activation == ACT_LEAKY_RELU:
+ return functional.leaky_relu(x, negative_slope=self.slope, inplace=True)
+ elif self.activation == ACT_ELU:
+ return functional.elu(x, inplace=True)
+ else:
+ return x
+
+ def __repr__(self):
+ rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
+ ' affine={affine}, activation={activation}'
+ if self.activation == "leaky_relu":
+ rep += ', slope={slope})'
+ else:
+ rep += ')'
+ return rep.format(name=self.__class__.__name__, **self.__dict__)
+
+
+class InPlaceABN(ABN):
+ """InPlace Activated Batch Normalization"""
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True, activation="leaky_relu", slope=0.01):
+ """Creates an InPlace Activated Batch Normalization module
+
+ Parameters
+ ----------
+ num_features : int
+ Number of feature channels in the input and color_texture.
+ eps : float
+ Small constant to prevent numerical issues.
+ momentum : float
+ Momentum factor applied to compute running statistics as.
+ affine : bool
+ If `True` apply learned scale and shift transformation after normalization.
+ activation : str
+ Name of the activation functions, one of: `leaky_relu`, `elu` or `none`.
+ slope : float
+ Negative slope for the `leaky_relu` activation.
+ """
+ super(InPlaceABN, self).__init__(num_features, eps, momentum, affine, activation, slope)
+
+ def forward(self, x):
+ return inplace_abn(x, self.weight, self.bias, self.running_mean, self.running_var,
+ self.training, self.momentum, self.eps, self.activation, self.slope)
+
+
+class InPlaceABNSync(ABN):
+ """InPlace Activated Batch Normalization with cross-GPU synchronization
+ This assumes that it will be replicated across GPUs using the same mechanism as in `nn.DistributedDataParallel`.
+ """
+
+ def forward(self, x):
+ return inplace_abn_sync(x, self.weight, self.bias, self.running_mean, self.running_var,
+ self.training, self.momentum, self.eps, self.activation, self.slope)
+
+ def __repr__(self):
+ rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
+ ' affine={affine}, activation={activation}'
+ if self.activation == "leaky_relu":
+ rep += ', slope={slope})'
+ else:
+ rep += ')'
+ return rep.format(name=self.__class__.__name__, **self.__dict__)
+
+
diff --git a/models/CtrlHair/external_code/face_parsing/modules/deeplab.py b/models/CtrlHair/external_code/face_parsing/modules/deeplab.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd25b78369b27ef02c183a0b17b9bf8354c5f7c3
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/deeplab.py
@@ -0,0 +1,84 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as functional
+
+from models._util import try_index
+from .bn import ABN
+
+
+class DeeplabV3(nn.Module):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ hidden_channels=256,
+ dilations=(12, 24, 36),
+ norm_act=ABN,
+ pooling_size=None):
+ super(DeeplabV3, self).__init__()
+ self.pooling_size = pooling_size
+
+ self.map_convs = nn.ModuleList([
+ nn.Conv2d(in_channels, hidden_channels, 1, bias=False),
+ nn.Conv2d(in_channels, hidden_channels, 3, bias=False, dilation=dilations[0], padding=dilations[0]),
+ nn.Conv2d(in_channels, hidden_channels, 3, bias=False, dilation=dilations[1], padding=dilations[1]),
+ nn.Conv2d(in_channels, hidden_channels, 3, bias=False, dilation=dilations[2], padding=dilations[2])
+ ])
+ self.map_bn = norm_act(hidden_channels * 4)
+
+ self.global_pooling_conv = nn.Conv2d(in_channels, hidden_channels, 1, bias=False)
+ self.global_pooling_bn = norm_act(hidden_channels)
+
+ self.red_conv = nn.Conv2d(hidden_channels * 4, out_channels, 1, bias=False)
+ self.pool_red_conv = nn.Conv2d(hidden_channels, out_channels, 1, bias=False)
+ self.red_bn = norm_act(out_channels)
+
+ self.reset_parameters(self.map_bn.activation, self.map_bn.slope)
+
+ def reset_parameters(self, activation, slope):
+ gain = nn.init.calculate_gain(activation, slope)
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.xavier_normal_(m.weight.data, gain)
+ if hasattr(m, "bias") and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, ABN):
+ if hasattr(m, "weight") and m.weight is not None:
+ nn.init.constant_(m.weight, 1)
+ if hasattr(m, "bias") and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+
+ def forward(self, x):
+ # Map convolutions
+ out = torch.cat([m(x) for m in self.map_convs], dim=1)
+ out = self.map_bn(out)
+ out = self.red_conv(out)
+
+ # Global pooling
+ pool = self._global_pooling(x)
+ pool = self.global_pooling_conv(pool)
+ pool = self.global_pooling_bn(pool)
+ pool = self.pool_red_conv(pool)
+ if self.training or self.pooling_size is None:
+ pool = pool.repeat(1, 1, x.size(2), x.size(3))
+
+ out += pool
+ out = self.red_bn(out)
+ return out
+
+ def _global_pooling(self, x):
+ if self.training or self.pooling_size is None:
+ pool = x.view(x.size(0), x.size(1), -1).mean(dim=-1)
+ pool = pool.view(x.size(0), x.size(1), 1, 1)
+ else:
+ pooling_size = (min(try_index(self.pooling_size, 0), x.shape[2]),
+ min(try_index(self.pooling_size, 1), x.shape[3]))
+ padding = (
+ (pooling_size[1] - 1) // 2,
+ (pooling_size[1] - 1) // 2 if pooling_size[1] % 2 == 1 else (pooling_size[1] - 1) // 2 + 1,
+ (pooling_size[0] - 1) // 2,
+ (pooling_size[0] - 1) // 2 if pooling_size[0] % 2 == 1 else (pooling_size[0] - 1) // 2 + 1
+ )
+
+ pool = functional.avg_pool2d(x, pooling_size, stride=1)
+ pool = functional.pad(pool, pad=padding, mode="replicate")
+ return pool
diff --git a/models/CtrlHair/external_code/face_parsing/modules/dense.py b/models/CtrlHair/external_code/face_parsing/modules/dense.py
new file mode 100644
index 0000000000000000000000000000000000000000..9638d6e86d2ae838550fefa9002a984af52e6cc8
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/dense.py
@@ -0,0 +1,42 @@
+from collections import OrderedDict
+
+import torch
+import torch.nn as nn
+
+from .bn import ABN
+
+
+class DenseModule(nn.Module):
+ def __init__(self, in_channels, growth, layers, bottleneck_factor=4, norm_act=ABN, dilation=1):
+ super(DenseModule, self).__init__()
+ self.in_channels = in_channels
+ self.growth = growth
+ self.layers = layers
+
+ self.convs1 = nn.ModuleList()
+ self.convs3 = nn.ModuleList()
+ for i in range(self.layers):
+ self.convs1.append(nn.Sequential(OrderedDict([
+ ("bn", norm_act(in_channels)),
+ ("conv", nn.Conv2d(in_channels, self.growth * bottleneck_factor, 1, bias=False))
+ ])))
+ self.convs3.append(nn.Sequential(OrderedDict([
+ ("bn", norm_act(self.growth * bottleneck_factor)),
+ ("conv", nn.Conv2d(self.growth * bottleneck_factor, self.growth, 3, padding=dilation, bias=False,
+ dilation=dilation))
+ ])))
+ in_channels += self.growth
+
+ @property
+ def out_channels(self):
+ return self.in_channels + self.growth * self.layers
+
+ def forward(self, x):
+ inputs = [x]
+ for i in range(self.layers):
+ x = torch.cat(inputs, dim=1)
+ x = self.convs1[i](x)
+ x = self.convs3[i](x)
+ inputs += [x]
+
+ return torch.cat(inputs, dim=1)
diff --git a/models/CtrlHair/external_code/face_parsing/modules/functions.py b/models/CtrlHair/external_code/face_parsing/modules/functions.py
new file mode 100644
index 0000000000000000000000000000000000000000..093615ff4f383e95712c96b57286338ec3b28f3b
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/functions.py
@@ -0,0 +1,234 @@
+from os import path
+import torch
+import torch.distributed as dist
+import torch.autograd as autograd
+import torch.cuda.comm as comm
+from torch.autograd.function import once_differentiable
+from torch.utils.cpp_extension import load
+
+_src_path = path.join(path.dirname(path.abspath(__file__)), "src")
+_backend = load(name="inplace_abn",
+ extra_cflags=["-O3"],
+ sources=[path.join(_src_path, f) for f in [
+ "inplace_abn.cpp",
+ "inplace_abn_cpu.cpp",
+ "inplace_abn_cuda.cu",
+ "inplace_abn_cuda_half.cu"
+ ]],
+ extra_cuda_cflags=["--expt-extended-lambda"])
+
+# Activation names
+ACT_RELU = "relu"
+ACT_LEAKY_RELU = "leaky_relu"
+ACT_ELU = "elu"
+ACT_NONE = "none"
+
+
+def _check(fn, *args, **kwargs):
+ success = fn(*args, **kwargs)
+ if not success:
+ raise RuntimeError("CUDA Error encountered in {}".format(fn))
+
+
+def _broadcast_shape(x):
+ out_size = []
+ for i, s in enumerate(x.size()):
+ if i != 1:
+ out_size.append(1)
+ else:
+ out_size.append(s)
+ return out_size
+
+
+def _reduce(x):
+ if len(x.size()) == 2:
+ return x.sum(dim=0)
+ else:
+ n, c = x.size()[0:2]
+ return x.contiguous().view((n, c, -1)).sum(2).sum(0)
+
+
+def _count_samples(x):
+ count = 1
+ for i, s in enumerate(x.size()):
+ if i != 1:
+ count *= s
+ return count
+
+
+def _act_forward(ctx, x):
+ if ctx.activation == ACT_LEAKY_RELU:
+ _backend.leaky_relu_forward(x, ctx.slope)
+ elif ctx.activation == ACT_ELU:
+ _backend.elu_forward(x)
+ elif ctx.activation == ACT_NONE:
+ pass
+
+
+def _act_backward(ctx, x, dx):
+ if ctx.activation == ACT_LEAKY_RELU:
+ _backend.leaky_relu_backward(x, dx, ctx.slope)
+ elif ctx.activation == ACT_ELU:
+ _backend.elu_backward(x, dx)
+ elif ctx.activation == ACT_NONE:
+ pass
+
+
+class InPlaceABN(autograd.Function):
+ @staticmethod
+ def forward(ctx, x, weight, bias, running_mean, running_var,
+ training=True, momentum=0.1, eps=1e-05, activation=ACT_LEAKY_RELU, slope=0.01):
+ # Save context
+ ctx.training = training
+ ctx.momentum = momentum
+ ctx.eps = eps
+ ctx.activation = activation
+ ctx.slope = slope
+ ctx.affine = weight is not None and bias is not None
+
+ # Prepare inputs
+ count = _count_samples(x)
+ x = x.contiguous()
+ weight = weight.contiguous() if ctx.affine else x.new_empty(0)
+ bias = bias.contiguous() if ctx.affine else x.new_empty(0)
+
+ if ctx.training:
+ mean, var = _backend.mean_var(x)
+
+ # Update running stats
+ running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
+ running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * var * count / (count - 1))
+
+ # Mark in-place modified tensors
+ ctx.mark_dirty(x, running_mean, running_var)
+ else:
+ mean, var = running_mean.contiguous(), running_var.contiguous()
+ ctx.mark_dirty(x)
+
+ # BN forward + activation
+ _backend.forward(x, mean, var, weight, bias, ctx.affine, ctx.eps)
+ _act_forward(ctx, x)
+
+ # Output
+ ctx.var = var
+ ctx.save_for_backward(x, var, weight, bias)
+ return x
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, dz):
+ z, var, weight, bias = ctx.saved_tensors
+ dz = dz.contiguous()
+
+ # Undo activation
+ _act_backward(ctx, z, dz)
+
+ if ctx.training:
+ edz, eydz = _backend.edz_eydz(z, dz, weight, bias, ctx.affine, ctx.eps)
+ else:
+ # TODO: implement simplified CUDA backward for inference mode
+ edz = dz.new_zeros(dz.size(1))
+ eydz = dz.new_zeros(dz.size(1))
+
+ dx = _backend.backward(z, dz, var, weight, bias, edz, eydz, ctx.affine, ctx.eps)
+ dweight = eydz * weight.sign() if ctx.affine else None
+ dbias = edz if ctx.affine else None
+
+ return dx, dweight, dbias, None, None, None, None, None, None, None
+
+class InPlaceABNSync(autograd.Function):
+ @classmethod
+ def forward(cls, ctx, x, weight, bias, running_mean, running_var,
+ training=True, momentum=0.1, eps=1e-05, activation=ACT_LEAKY_RELU, slope=0.01, equal_batches=True):
+ # Save context
+ ctx.training = training
+ ctx.momentum = momentum
+ ctx.eps = eps
+ ctx.activation = activation
+ ctx.slope = slope
+ ctx.affine = weight is not None and bias is not None
+
+ # Prepare inputs
+ ctx.world_size = dist.get_world_size() if dist.is_initialized() else 1
+
+ #count = _count_samples(x)
+ batch_size = x.new_tensor([x.shape[0]],dtype=torch.long)
+
+ x = x.contiguous()
+ weight = weight.contiguous() if ctx.affine else x.new_empty(0)
+ bias = bias.contiguous() if ctx.affine else x.new_empty(0)
+
+ if ctx.training:
+ mean, var = _backend.mean_var(x)
+ if ctx.world_size>1:
+ # get global batch size
+ if equal_batches:
+ batch_size *= ctx.world_size
+ else:
+ dist.all_reduce(batch_size, dist.ReduceOp.SUM)
+
+ ctx.factor = x.shape[0]/float(batch_size.item())
+
+ mean_all = mean.clone() * ctx.factor
+ dist.all_reduce(mean_all, dist.ReduceOp.SUM)
+
+ var_all = (var + (mean - mean_all) ** 2) * ctx.factor
+ dist.all_reduce(var_all, dist.ReduceOp.SUM)
+
+ mean = mean_all
+ var = var_all
+
+ # Update running stats
+ running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
+ count = batch_size.item() * x.view(x.shape[0],x.shape[1],-1).shape[-1]
+ running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * var * (float(count) / (count - 1)))
+
+ # Mark in-place modified tensors
+ ctx.mark_dirty(x, running_mean, running_var)
+ else:
+ mean, var = running_mean.contiguous(), running_var.contiguous()
+ ctx.mark_dirty(x)
+
+ # BN forward + activation
+ _backend.forward(x, mean, var, weight, bias, ctx.affine, ctx.eps)
+ _act_forward(ctx, x)
+
+ # Output
+ ctx.var = var
+ ctx.save_for_backward(x, var, weight, bias)
+ return x
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, dz):
+ z, var, weight, bias = ctx.saved_tensors
+ dz = dz.contiguous()
+
+ # Undo activation
+ _act_backward(ctx, z, dz)
+
+ if ctx.training:
+ edz, eydz = _backend.edz_eydz(z, dz, weight, bias, ctx.affine, ctx.eps)
+ edz_local = edz.clone()
+ eydz_local = eydz.clone()
+
+ if ctx.world_size>1:
+ edz *= ctx.factor
+ dist.all_reduce(edz, dist.ReduceOp.SUM)
+
+ eydz *= ctx.factor
+ dist.all_reduce(eydz, dist.ReduceOp.SUM)
+ else:
+ edz_local = edz = dz.new_zeros(dz.size(1))
+ eydz_local = eydz = dz.new_zeros(dz.size(1))
+
+ dx = _backend.backward(z, dz, var, weight, bias, edz, eydz, ctx.affine, ctx.eps)
+ dweight = eydz_local * weight.sign() if ctx.affine else None
+ dbias = edz_local if ctx.affine else None
+
+ return dx, dweight, dbias, None, None, None, None, None, None, None
+
+inplace_abn = InPlaceABN.apply
+inplace_abn_sync = InPlaceABNSync.apply
+
+__all__ = ["inplace_abn", "inplace_abn_sync", "ACT_RELU", "ACT_LEAKY_RELU", "ACT_ELU", "ACT_NONE"]
diff --git a/models/CtrlHair/external_code/face_parsing/modules/misc.py b/models/CtrlHair/external_code/face_parsing/modules/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c50b69b38c950801baacba8b3684ffd23aef08b
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/misc.py
@@ -0,0 +1,21 @@
+import torch.nn as nn
+import torch
+import torch.distributed as dist
+
+class GlobalAvgPool2d(nn.Module):
+ def __init__(self):
+ """Global average pooling over the input's spatial dimensions"""
+ super(GlobalAvgPool2d, self).__init__()
+
+ def forward(self, inputs):
+ in_size = inputs.size()
+ return inputs.view((in_size[0], in_size[1], -1)).mean(dim=2)
+
+class SingleGPU(nn.Module):
+ def __init__(self, module):
+ super(SingleGPU, self).__init__()
+ self.module=module
+
+ def forward(self, input):
+ return self.module(input.cuda(non_blocking=True))
+
diff --git a/models/CtrlHair/external_code/face_parsing/modules/residual.py b/models/CtrlHair/external_code/face_parsing/modules/residual.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7d51ad274f3841813c1584a0ceb60ce58979d94
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/residual.py
@@ -0,0 +1,88 @@
+from collections import OrderedDict
+
+import torch.nn as nn
+
+from .bn import ABN
+
+
+class IdentityResidualBlock(nn.Module):
+ def __init__(self,
+ in_channels,
+ channels,
+ stride=1,
+ dilation=1,
+ groups=1,
+ norm_act=ABN,
+ dropout=None):
+ """Configurable identity-mapping residual block
+
+ Parameters
+ ----------
+ in_channels : int
+ Number of input channels.
+ channels : list of int
+ Number of channels in the internal feature maps. Can either have two or three elements: if three construct
+ a residual block with two `3 x 3` convolutions, otherwise construct a bottleneck block with `1 x 1`, then
+ `3 x 3` then `1 x 1` convolutions.
+ stride : int
+ Stride of the first `3 x 3` convolution
+ dilation : int
+ Dilation to apply to the `3 x 3` convolutions.
+ groups : int
+ Number of convolution groups. This is used to create ResNeXt-style blocks and is only compatible with
+ bottleneck blocks.
+ norm_act : callable
+ Function to create normalization / activation Module.
+ dropout: callable
+ Function to create Dropout Module.
+ """
+ super(IdentityResidualBlock, self).__init__()
+
+ # Check parameters for inconsistencies
+ if len(channels) != 2 and len(channels) != 3:
+ raise ValueError("channels must contain either two or three values")
+ if len(channels) == 2 and groups != 1:
+ raise ValueError("groups > 1 are only valid if len(channels) == 3")
+
+ is_bottleneck = len(channels) == 3
+ need_proj_conv = stride != 1 or in_channels != channels[-1]
+
+ self.bn1 = norm_act(in_channels)
+ if not is_bottleneck:
+ layers = [
+ ("conv1", nn.Conv2d(in_channels, channels[0], 3, stride=stride, padding=dilation, bias=False,
+ dilation=dilation)),
+ ("bn2", norm_act(channels[0])),
+ ("conv2", nn.Conv2d(channels[0], channels[1], 3, stride=1, padding=dilation, bias=False,
+ dilation=dilation))
+ ]
+ if dropout is not None:
+ layers = layers[0:2] + [("dropout", dropout())] + layers[2:]
+ else:
+ layers = [
+ ("conv1", nn.Conv2d(in_channels, channels[0], 1, stride=stride, padding=0, bias=False)),
+ ("bn2", norm_act(channels[0])),
+ ("conv2", nn.Conv2d(channels[0], channels[1], 3, stride=1, padding=dilation, bias=False,
+ groups=groups, dilation=dilation)),
+ ("bn3", norm_act(channels[1])),
+ ("conv3", nn.Conv2d(channels[1], channels[2], 1, stride=1, padding=0, bias=False))
+ ]
+ if dropout is not None:
+ layers = layers[0:4] + [("dropout", dropout())] + layers[4:]
+ self.convs = nn.Sequential(OrderedDict(layers))
+
+ if need_proj_conv:
+ self.proj_conv = nn.Conv2d(in_channels, channels[-1], 1, stride=stride, padding=0, bias=False)
+
+ def forward(self, x):
+ if hasattr(self, "proj_conv"):
+ bn1 = self.bn1(x)
+ shortcut = self.proj_conv(bn1)
+ else:
+ shortcut = x.clone()
+ bn1 = self.bn1(x)
+
+ out = self.convs(bn1)
+ out.add_(shortcut)
+
+ return out
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/checks.h b/models/CtrlHair/external_code/face_parsing/modules/src/checks.h
new file mode 100644
index 0000000000000000000000000000000000000000..e761a6fe34d0789815b588eba7e3726026e0e868
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/checks.h
@@ -0,0 +1,15 @@
+#pragma once
+
+#include
+
+// Define AT_CHECK for old version of ATen where the same function was called AT_ASSERT
+#ifndef AT_CHECK
+#define AT_CHECK AT_ASSERT
+#endif
+
+#define CHECK_CUDA(x) AT_CHECK((x).type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CPU(x) AT_CHECK(!(x).type().is_cuda(), #x " must be a CPU tensor")
+#define CHECK_CONTIGUOUS(x) AT_CHECK((x).is_contiguous(), #x " must be contiguous")
+
+#define CHECK_CUDA_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+#define CHECK_CPU_INPUT(x) CHECK_CPU(x); CHECK_CONTIGUOUS(x)
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.cpp b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..0a6b1128cc20cbfc476134154e23e5869a92b856
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.cpp
@@ -0,0 +1,95 @@
+#include
+
+#include
+
+#include "inplace_abn.h"
+
+std::vector mean_var(at::Tensor x) {
+ if (x.is_cuda()) {
+ if (x.type().scalarType() == at::ScalarType::Half) {
+ return mean_var_cuda_h(x);
+ } else {
+ return mean_var_cuda(x);
+ }
+ } else {
+ return mean_var_cpu(x);
+ }
+}
+
+at::Tensor forward(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ if (x.is_cuda()) {
+ if (x.type().scalarType() == at::ScalarType::Half) {
+ return forward_cuda_h(x, mean, var, weight, bias, affine, eps);
+ } else {
+ return forward_cuda(x, mean, var, weight, bias, affine, eps);
+ }
+ } else {
+ return forward_cpu(x, mean, var, weight, bias, affine, eps);
+ }
+}
+
+std::vector edz_eydz(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ if (z.is_cuda()) {
+ if (z.type().scalarType() == at::ScalarType::Half) {
+ return edz_eydz_cuda_h(z, dz, weight, bias, affine, eps);
+ } else {
+ return edz_eydz_cuda(z, dz, weight, bias, affine, eps);
+ }
+ } else {
+ return edz_eydz_cpu(z, dz, weight, bias, affine, eps);
+ }
+}
+
+at::Tensor backward(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps) {
+ if (z.is_cuda()) {
+ if (z.type().scalarType() == at::ScalarType::Half) {
+ return backward_cuda_h(z, dz, var, weight, bias, edz, eydz, affine, eps);
+ } else {
+ return backward_cuda(z, dz, var, weight, bias, edz, eydz, affine, eps);
+ }
+ } else {
+ return backward_cpu(z, dz, var, weight, bias, edz, eydz, affine, eps);
+ }
+}
+
+void leaky_relu_forward(at::Tensor z, float slope) {
+ at::leaky_relu_(z, slope);
+}
+
+void leaky_relu_backward(at::Tensor z, at::Tensor dz, float slope) {
+ if (z.is_cuda()) {
+ if (z.type().scalarType() == at::ScalarType::Half) {
+ return leaky_relu_backward_cuda_h(z, dz, slope);
+ } else {
+ return leaky_relu_backward_cuda(z, dz, slope);
+ }
+ } else {
+ return leaky_relu_backward_cpu(z, dz, slope);
+ }
+}
+
+void elu_forward(at::Tensor z) {
+ at::elu_(z);
+}
+
+void elu_backward(at::Tensor z, at::Tensor dz) {
+ if (z.is_cuda()) {
+ return elu_backward_cuda(z, dz);
+ } else {
+ return elu_backward_cpu(z, dz);
+ }
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("mean_var", &mean_var, "Mean and variance computation");
+ m.def("forward", &forward, "In-place forward computation");
+ m.def("edz_eydz", &edz_eydz, "First part of backward computation");
+ m.def("backward", &backward, "Second part of backward computation");
+ m.def("leaky_relu_forward", &leaky_relu_forward, "Leaky relu forward computation");
+ m.def("leaky_relu_backward", &leaky_relu_backward, "Leaky relu backward computation and inversion");
+ m.def("elu_forward", &elu_forward, "Elu forward computation");
+ m.def("elu_backward", &elu_backward, "Elu backward computation and inversion");
+}
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.h b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.h
new file mode 100644
index 0000000000000000000000000000000000000000..17afd1196449ecb6376f28961e54b55e1537492f
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn.h
@@ -0,0 +1,88 @@
+#pragma once
+
+#include
+
+#include
+
+std::vector mean_var_cpu(at::Tensor x);
+std::vector mean_var_cuda(at::Tensor x);
+std::vector mean_var_cuda_h(at::Tensor x);
+
+at::Tensor forward_cpu(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+at::Tensor forward_cuda(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+at::Tensor forward_cuda_h(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+
+std::vector edz_eydz_cpu(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+std::vector edz_eydz_cuda(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+std::vector edz_eydz_cuda_h(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps);
+
+at::Tensor backward_cpu(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps);
+at::Tensor backward_cuda(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps);
+at::Tensor backward_cuda_h(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps);
+
+void leaky_relu_backward_cpu(at::Tensor z, at::Tensor dz, float slope);
+void leaky_relu_backward_cuda(at::Tensor z, at::Tensor dz, float slope);
+void leaky_relu_backward_cuda_h(at::Tensor z, at::Tensor dz, float slope);
+
+void elu_backward_cpu(at::Tensor z, at::Tensor dz);
+void elu_backward_cuda(at::Tensor z, at::Tensor dz);
+
+static void get_dims(at::Tensor x, int64_t& num, int64_t& chn, int64_t& sp) {
+ num = x.size(0);
+ chn = x.size(1);
+ sp = 1;
+ for (int64_t i = 2; i < x.ndimension(); ++i)
+ sp *= x.size(i);
+}
+
+/*
+ * Specialized CUDA reduction functions for BN
+ */
+#ifdef __CUDACC__
+
+#include "utils/cuda.cuh"
+
+template
+__device__ T reduce(Op op, int plane, int N, int S) {
+ T sum = (T)0;
+ for (int batch = 0; batch < N; ++batch) {
+ for (int x = threadIdx.x; x < S; x += blockDim.x) {
+ sum += op(batch, plane, x);
+ }
+ }
+
+ // sum over NumThreads within a warp
+ sum = warpSum(sum);
+
+ // 'transpose', and reduce within warp again
+ __shared__ T shared[32];
+ __syncthreads();
+ if (threadIdx.x % WARP_SIZE == 0) {
+ shared[threadIdx.x / WARP_SIZE] = sum;
+ }
+ if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
+ // zero out the other entries in shared
+ shared[threadIdx.x] = (T)0;
+ }
+ __syncthreads();
+ if (threadIdx.x / WARP_SIZE == 0) {
+ sum = warpSum(shared[threadIdx.x]);
+ if (threadIdx.x == 0) {
+ shared[0] = sum;
+ }
+ }
+ __syncthreads();
+
+ // Everyone picks it up, should be broadcast into the whole gradInput
+ return shared[0];
+}
+#endif
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cpu.cpp b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cpu.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..ffc6d38c52ea31661b8dd438dc3fe1958f50b61e
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cpu.cpp
@@ -0,0 +1,119 @@
+#include
+
+#include
+
+#include "utils/checks.h"
+#include "inplace_abn.h"
+
+at::Tensor reduce_sum(at::Tensor x) {
+ if (x.ndimension() == 2) {
+ return x.sum(0);
+ } else {
+ auto x_view = x.view({x.size(0), x.size(1), -1});
+ return x_view.sum(-1).sum(0);
+ }
+}
+
+at::Tensor broadcast_to(at::Tensor v, at::Tensor x) {
+ if (x.ndimension() == 2) {
+ return v;
+ } else {
+ std::vector broadcast_size = {1, -1};
+ for (int64_t i = 2; i < x.ndimension(); ++i)
+ broadcast_size.push_back(1);
+
+ return v.view(broadcast_size);
+ }
+}
+
+int64_t count(at::Tensor x) {
+ int64_t count = x.size(0);
+ for (int64_t i = 2; i < x.ndimension(); ++i)
+ count *= x.size(i);
+
+ return count;
+}
+
+at::Tensor invert_affine(at::Tensor z, at::Tensor weight, at::Tensor bias, bool affine, float eps) {
+ if (affine) {
+ return (z - broadcast_to(bias, z)) / broadcast_to(at::abs(weight) + eps, z);
+ } else {
+ return z;
+ }
+}
+
+std::vector mean_var_cpu(at::Tensor x) {
+ auto num = count(x);
+ auto mean = reduce_sum(x) / num;
+ auto diff = x - broadcast_to(mean, x);
+ auto var = reduce_sum(diff.pow(2)) / num;
+
+ return {mean, var};
+}
+
+at::Tensor forward_cpu(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ auto gamma = affine ? at::abs(weight) + eps : at::ones_like(var);
+ auto mul = at::rsqrt(var + eps) * gamma;
+
+ x.sub_(broadcast_to(mean, x));
+ x.mul_(broadcast_to(mul, x));
+ if (affine) x.add_(broadcast_to(bias, x));
+
+ return x;
+}
+
+std::vector edz_eydz_cpu(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ auto edz = reduce_sum(dz);
+ auto y = invert_affine(z, weight, bias, affine, eps);
+ auto eydz = reduce_sum(y * dz);
+
+ return {edz, eydz};
+}
+
+at::Tensor backward_cpu(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps) {
+ auto y = invert_affine(z, weight, bias, affine, eps);
+ auto mul = affine ? at::rsqrt(var + eps) * (at::abs(weight) + eps) : at::rsqrt(var + eps);
+
+ auto num = count(z);
+ auto dx = (dz - broadcast_to(edz / num, dz) - y * broadcast_to(eydz / num, dz)) * broadcast_to(mul, dz);
+ return dx;
+}
+
+void leaky_relu_backward_cpu(at::Tensor z, at::Tensor dz, float slope) {
+ CHECK_CPU_INPUT(z);
+ CHECK_CPU_INPUT(dz);
+
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "leaky_relu_backward_cpu", ([&] {
+ int64_t count = z.numel();
+ auto *_z = z.data();
+ auto *_dz = dz.data();
+
+ for (int64_t i = 0; i < count; ++i) {
+ if (_z[i] < 0) {
+ _z[i] *= 1 / slope;
+ _dz[i] *= slope;
+ }
+ }
+ }));
+}
+
+void elu_backward_cpu(at::Tensor z, at::Tensor dz) {
+ CHECK_CPU_INPUT(z);
+ CHECK_CPU_INPUT(dz);
+
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "elu_backward_cpu", ([&] {
+ int64_t count = z.numel();
+ auto *_z = z.data();
+ auto *_dz = dz.data();
+
+ for (int64_t i = 0; i < count; ++i) {
+ if (_z[i] < 0) {
+ _z[i] = log1p(_z[i]);
+ _dz[i] *= (_z[i] + 1.f);
+ }
+ }
+ }));
+}
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda.cu b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda.cu
new file mode 100644
index 0000000000000000000000000000000000000000..b157b06d47173d1645c6a40c89f564b737e84d43
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda.cu
@@ -0,0 +1,333 @@
+#include
+
+#include
+#include
+
+#include
+
+#include "utils/checks.h"
+#include "utils/cuda.cuh"
+#include "inplace_abn.h"
+
+#include
+
+// Operations for reduce
+template
+struct SumOp {
+ __device__ SumOp(const T *t, int c, int s)
+ : tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ T operator()(int batch, int plane, int n) {
+ return tensor[(batch * chn + plane) * sp + n];
+ }
+ const T *tensor;
+ const int chn;
+ const int sp;
+};
+
+template
+struct VarOp {
+ __device__ VarOp(T m, const T *t, int c, int s)
+ : mean(m), tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ T operator()(int batch, int plane, int n) {
+ T val = tensor[(batch * chn + plane) * sp + n];
+ return (val - mean) * (val - mean);
+ }
+ const T mean;
+ const T *tensor;
+ const int chn;
+ const int sp;
+};
+
+template
+struct GradOp {
+ __device__ GradOp(T _weight, T _bias, const T *_z, const T *_dz, int c, int s)
+ : weight(_weight), bias(_bias), z(_z), dz(_dz), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ T _y = (z[(batch * chn + plane) * sp + n] - bias) / weight;
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ return Pair(_dz, _y * _dz);
+ }
+ const T weight;
+ const T bias;
+ const T *z;
+ const T *dz;
+ const int chn;
+ const int sp;
+};
+
+/***********
+ * mean_var
+ ***********/
+
+template
+__global__ void mean_var_kernel(const T *x, T *mean, T *var, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ T norm = T(1) / T(num * sp);
+
+ T _mean = reduce>(SumOp(x, chn, sp), plane, num, sp) * norm;
+ __syncthreads();
+ T _var = reduce>(VarOp(_mean, x, chn, sp), plane, num, sp) * norm;
+
+ if (threadIdx.x == 0) {
+ mean[plane] = _mean;
+ var[plane] = _var;
+ }
+}
+
+std::vector mean_var_cuda(at::Tensor x) {
+ CHECK_CUDA_INPUT(x);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto mean = at::empty({chn}, x.options());
+ auto var = at::empty({chn}, x.options());
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ AT_DISPATCH_FLOATING_TYPES(x.type(), "mean_var_cuda", ([&] {
+ mean_var_kernel<<>>(
+ x.data(),
+ mean.data(),
+ var.data(),
+ num, chn, sp);
+ }));
+
+ return {mean, var};
+}
+
+/**********
+ * forward
+ **********/
+
+template
+__global__ void forward_kernel(T *x, const T *mean, const T *var, const T *weight, const T *bias,
+ bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _weight = affine ? abs(weight[plane]) + eps : T(1);
+ T _bias = affine ? bias[plane] : T(0);
+
+ T mul = rsqrt(_var + eps) * _weight;
+
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _x = x[(batch * chn + plane) * sp + n];
+ T _y = (_x - _mean) * mul + _bias;
+
+ x[(batch * chn + plane) * sp + n] = _y;
+ }
+ }
+}
+
+at::Tensor forward_cuda(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ CHECK_CUDA_INPUT(x);
+ CHECK_CUDA_INPUT(mean);
+ CHECK_CUDA_INPUT(var);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ AT_DISPATCH_FLOATING_TYPES(x.type(), "forward_cuda", ([&] {
+ forward_kernel<<>>(
+ x.data(),
+ mean.data(),
+ var.data(),
+ weight.data(),
+ bias.data(),
+ affine, eps, num, chn, sp);
+ }));
+
+ return x;
+}
+
+/***********
+ * edz_eydz
+ ***********/
+
+template
+__global__ void edz_eydz_kernel(const T *z, const T *dz, const T *weight, const T *bias,
+ T *edz, T *eydz, bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ T _weight = affine ? abs(weight[plane]) + eps : 1.f;
+ T _bias = affine ? bias[plane] : 0.f;
+
+ Pair res = reduce, GradOp>(GradOp(_weight, _bias, z, dz, chn, sp), plane, num, sp);
+ __syncthreads();
+
+ if (threadIdx.x == 0) {
+ edz[plane] = res.v1;
+ eydz[plane] = res.v2;
+ }
+}
+
+std::vector edz_eydz_cuda(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(z, num, chn, sp);
+
+ auto edz = at::empty({chn}, z.options());
+ auto eydz = at::empty({chn}, z.options());
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "edz_eydz_cuda", ([&] {
+ edz_eydz_kernel<<>>(
+ z.data(),
+ dz.data(),
+ weight.data(),
+ bias.data(),
+ edz.data(),
+ eydz.data(),
+ affine, eps, num, chn, sp);
+ }));
+
+ return {edz, eydz};
+}
+
+/***********
+ * backward
+ ***********/
+
+template
+__global__ void backward_kernel(const T *z, const T *dz, const T *var, const T *weight, const T *bias, const T *edz,
+ const T *eydz, T *dx, bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ T _weight = affine ? abs(weight[plane]) + eps : 1.f;
+ T _bias = affine ? bias[plane] : 0.f;
+ T _var = var[plane];
+ T _edz = edz[plane];
+ T _eydz = eydz[plane];
+
+ T _mul = _weight * rsqrt(_var + eps);
+ T count = T(num * sp);
+
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ T _y = (z[(batch * chn + plane) * sp + n] - _bias) / _weight;
+
+ dx[(batch * chn + plane) * sp + n] = (_dz - _edz / count - _y * _eydz / count) * _mul;
+ }
+ }
+}
+
+at::Tensor backward_cuda(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+ CHECK_CUDA_INPUT(var);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+ CHECK_CUDA_INPUT(edz);
+ CHECK_CUDA_INPUT(eydz);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(z, num, chn, sp);
+
+ auto dx = at::zeros_like(z);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "backward_cuda", ([&] {
+ backward_kernel<<>>(
+ z.data(),
+ dz.data(),
+ var.data(),
+ weight.data(),
+ bias.data(),
+ edz.data(),
+ eydz.data(),
+ dx.data(),
+ affine, eps, num, chn, sp);
+ }));
+
+ return dx;
+}
+
+/**************
+ * activations
+ **************/
+
+template
+inline void leaky_relu_backward_impl(T *z, T *dz, float slope, int64_t count) {
+ // Create thrust pointers
+ thrust::device_ptr th_z = thrust::device_pointer_cast(z);
+ thrust::device_ptr th_dz = thrust::device_pointer_cast(dz);
+
+ auto stream = at::cuda::getCurrentCUDAStream();
+ thrust::transform_if(thrust::cuda::par.on(stream),
+ th_dz, th_dz + count, th_z, th_dz,
+ [slope] __device__ (const T& dz) { return dz * slope; },
+ [] __device__ (const T& z) { return z < 0; });
+ thrust::transform_if(thrust::cuda::par.on(stream),
+ th_z, th_z + count, th_z,
+ [slope] __device__ (const T& z) { return z / slope; },
+ [] __device__ (const T& z) { return z < 0; });
+}
+
+void leaky_relu_backward_cuda(at::Tensor z, at::Tensor dz, float slope) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+
+ int64_t count = z.numel();
+
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "leaky_relu_backward_cuda", ([&] {
+ leaky_relu_backward_impl(z.data(), dz.data(), slope, count);
+ }));
+}
+
+template
+inline void elu_backward_impl(T *z, T *dz, int64_t count) {
+ // Create thrust pointers
+ thrust::device_ptr th_z = thrust::device_pointer_cast(z);
+ thrust::device_ptr th_dz = thrust::device_pointer_cast(dz);
+
+ auto stream = at::cuda::getCurrentCUDAStream();
+ thrust::transform_if(thrust::cuda::par.on(stream),
+ th_dz, th_dz + count, th_z, th_z, th_dz,
+ [] __device__ (const T& dz, const T& z) { return dz * (z + 1.); },
+ [] __device__ (const T& z) { return z < 0; });
+ thrust::transform_if(thrust::cuda::par.on(stream),
+ th_z, th_z + count, th_z,
+ [] __device__ (const T& z) { return log1p(z); },
+ [] __device__ (const T& z) { return z < 0; });
+}
+
+void elu_backward_cuda(at::Tensor z, at::Tensor dz) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+
+ int64_t count = z.numel();
+
+ AT_DISPATCH_FLOATING_TYPES(z.type(), "leaky_relu_backward_cuda", ([&] {
+ elu_backward_impl(z.data(), dz.data(), count);
+ }));
+}
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda_half.cu b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda_half.cu
new file mode 100644
index 0000000000000000000000000000000000000000..bb63e73f9d90179e5bd5dae5579c4844da9c25e2
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/inplace_abn_cuda_half.cu
@@ -0,0 +1,275 @@
+#include
+
+#include
+
+#include
+
+#include "utils/checks.h"
+#include "utils/cuda.cuh"
+#include "inplace_abn.h"
+
+#include
+
+// Operations for reduce
+struct SumOpH {
+ __device__ SumOpH(const half *t, int c, int s)
+ : tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ float operator()(int batch, int plane, int n) {
+ return __half2float(tensor[(batch * chn + plane) * sp + n]);
+ }
+ const half *tensor;
+ const int chn;
+ const int sp;
+};
+
+struct VarOpH {
+ __device__ VarOpH(float m, const half *t, int c, int s)
+ : mean(m), tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ float operator()(int batch, int plane, int n) {
+ const auto t = __half2float(tensor[(batch * chn + plane) * sp + n]);
+ return (t - mean) * (t - mean);
+ }
+ const float mean;
+ const half *tensor;
+ const int chn;
+ const int sp;
+};
+
+struct GradOpH {
+ __device__ GradOpH(float _weight, float _bias, const half *_z, const half *_dz, int c, int s)
+ : weight(_weight), bias(_bias), z(_z), dz(_dz), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ float _y = (__half2float(z[(batch * chn + plane) * sp + n]) - bias) / weight;
+ float _dz = __half2float(dz[(batch * chn + plane) * sp + n]);
+ return Pair(_dz, _y * _dz);
+ }
+ const float weight;
+ const float bias;
+ const half *z;
+ const half *dz;
+ const int chn;
+ const int sp;
+};
+
+/***********
+ * mean_var
+ ***********/
+
+__global__ void mean_var_kernel_h(const half *x, float *mean, float *var, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ float norm = 1.f / static_cast(num * sp);
+
+ float _mean = reduce(SumOpH(x, chn, sp), plane, num, sp) * norm;
+ __syncthreads();
+ float _var = reduce(VarOpH(_mean, x, chn, sp), plane, num, sp) * norm;
+
+ if (threadIdx.x == 0) {
+ mean[plane] = _mean;
+ var[plane] = _var;
+ }
+}
+
+std::vector mean_var_cuda_h(at::Tensor x) {
+ CHECK_CUDA_INPUT(x);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto mean = at::empty({chn},x.options().dtype(at::kFloat));
+ auto var = at::empty({chn},x.options().dtype(at::kFloat));
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ mean_var_kernel_h<<>>(
+ reinterpret_cast(x.data()),
+ mean.data(),
+ var.data(),
+ num, chn, sp);
+
+ return {mean, var};
+}
+
+/**********
+ * forward
+ **********/
+
+__global__ void forward_kernel_h(half *x, const float *mean, const float *var, const float *weight, const float *bias,
+ bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ const float _mean = mean[plane];
+ const float _var = var[plane];
+ const float _weight = affine ? abs(weight[plane]) + eps : 1.f;
+ const float _bias = affine ? bias[plane] : 0.f;
+
+ const float mul = rsqrt(_var + eps) * _weight;
+
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ half *x_ptr = x + (batch * chn + plane) * sp + n;
+ float _x = __half2float(*x_ptr);
+ float _y = (_x - _mean) * mul + _bias;
+
+ *x_ptr = __float2half(_y);
+ }
+ }
+}
+
+at::Tensor forward_cuda_h(at::Tensor x, at::Tensor mean, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ CHECK_CUDA_INPUT(x);
+ CHECK_CUDA_INPUT(mean);
+ CHECK_CUDA_INPUT(var);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ forward_kernel_h<<>>(
+ reinterpret_cast(x.data()),
+ mean.data(),
+ var.data(),
+ weight.data(),
+ bias.data(),
+ affine, eps, num, chn, sp);
+
+ return x;
+}
+
+__global__ void edz_eydz_kernel_h(const half *z, const half *dz, const float *weight, const float *bias,
+ float *edz, float *eydz, bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ float _weight = affine ? abs(weight[plane]) + eps : 1.f;
+ float _bias = affine ? bias[plane] : 0.f;
+
+ Pair res = reduce, GradOpH>(GradOpH(_weight, _bias, z, dz, chn, sp), plane, num, sp);
+ __syncthreads();
+
+ if (threadIdx.x == 0) {
+ edz[plane] = res.v1;
+ eydz[plane] = res.v2;
+ }
+}
+
+std::vector edz_eydz_cuda_h(at::Tensor z, at::Tensor dz, at::Tensor weight, at::Tensor bias,
+ bool affine, float eps) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(z, num, chn, sp);
+
+ auto edz = at::empty({chn},z.options().dtype(at::kFloat));
+ auto eydz = at::empty({chn},z.options().dtype(at::kFloat));
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ edz_eydz_kernel_h<<>>(
+ reinterpret_cast(z.data()),
+ reinterpret_cast(dz.data()),
+ weight.data(),
+ bias.data(),
+ edz.data(),
+ eydz.data(),
+ affine, eps, num, chn, sp);
+
+ return {edz, eydz};
+}
+
+__global__ void backward_kernel_h(const half *z, const half *dz, const float *var, const float *weight, const float *bias, const float *edz,
+ const float *eydz, half *dx, bool affine, float eps, int num, int chn, int sp) {
+ int plane = blockIdx.x;
+
+ float _weight = affine ? abs(weight[plane]) + eps : 1.f;
+ float _bias = affine ? bias[plane] : 0.f;
+ float _var = var[plane];
+ float _edz = edz[plane];
+ float _eydz = eydz[plane];
+
+ float _mul = _weight * rsqrt(_var + eps);
+ float count = float(num * sp);
+
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ float _dz = __half2float(dz[(batch * chn + plane) * sp + n]);
+ float _y = (__half2float(z[(batch * chn + plane) * sp + n]) - _bias) / _weight;
+
+ dx[(batch * chn + plane) * sp + n] = __float2half((_dz - _edz / count - _y * _eydz / count) * _mul);
+ }
+ }
+}
+
+at::Tensor backward_cuda_h(at::Tensor z, at::Tensor dz, at::Tensor var, at::Tensor weight, at::Tensor bias,
+ at::Tensor edz, at::Tensor eydz, bool affine, float eps) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+ CHECK_CUDA_INPUT(var);
+ CHECK_CUDA_INPUT(weight);
+ CHECK_CUDA_INPUT(bias);
+ CHECK_CUDA_INPUT(edz);
+ CHECK_CUDA_INPUT(eydz);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(z, num, chn, sp);
+
+ auto dx = at::zeros_like(z);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ auto stream = at::cuda::getCurrentCUDAStream();
+ backward_kernel_h<<>>(
+ reinterpret_cast(z.data()),
+ reinterpret_cast(dz.data()),
+ var.data(),
+ weight.data(),
+ bias.data(),
+ edz.data(),
+ eydz.data(),
+ reinterpret_cast(dx.data()),
+ affine, eps, num, chn, sp);
+
+ return dx;
+}
+
+__global__ void leaky_relu_backward_impl_h(half *z, half *dz, float slope, int64_t count) {
+ for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < count; i += blockDim.x * gridDim.x){
+ float _z = __half2float(z[i]);
+ if (_z < 0) {
+ dz[i] = __float2half(__half2float(dz[i]) * slope);
+ z[i] = __float2half(_z / slope);
+ }
+ }
+}
+
+void leaky_relu_backward_cuda_h(at::Tensor z, at::Tensor dz, float slope) {
+ CHECK_CUDA_INPUT(z);
+ CHECK_CUDA_INPUT(dz);
+
+ int64_t count = z.numel();
+ dim3 threads(getNumThreads(count));
+ dim3 blocks = (count + threads.x - 1) / threads.x;
+ auto stream = at::cuda::getCurrentCUDAStream();
+ leaky_relu_backward_impl_h<<>>(
+ reinterpret_cast(z.data()),
+ reinterpret_cast(dz.data()),
+ slope, count);
+}
+
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/utils/checks.h b/models/CtrlHair/external_code/face_parsing/modules/src/utils/checks.h
new file mode 100644
index 0000000000000000000000000000000000000000..e761a6fe34d0789815b588eba7e3726026e0e868
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/utils/checks.h
@@ -0,0 +1,15 @@
+#pragma once
+
+#include
+
+// Define AT_CHECK for old version of ATen where the same function was called AT_ASSERT
+#ifndef AT_CHECK
+#define AT_CHECK AT_ASSERT
+#endif
+
+#define CHECK_CUDA(x) AT_CHECK((x).type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CPU(x) AT_CHECK(!(x).type().is_cuda(), #x " must be a CPU tensor")
+#define CHECK_CONTIGUOUS(x) AT_CHECK((x).is_contiguous(), #x " must be contiguous")
+
+#define CHECK_CUDA_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+#define CHECK_CPU_INPUT(x) CHECK_CPU(x); CHECK_CONTIGUOUS(x)
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/utils/common.h b/models/CtrlHair/external_code/face_parsing/modules/src/utils/common.h
new file mode 100644
index 0000000000000000000000000000000000000000..e8403eef8a233b75dd4bb353c16486fe1be2039a
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/utils/common.h
@@ -0,0 +1,49 @@
+#pragma once
+
+#include
+
+/*
+ * Functions to share code between CPU and GPU
+ */
+
+#ifdef __CUDACC__
+// CUDA versions
+
+#define HOST_DEVICE __host__ __device__
+#define INLINE_HOST_DEVICE __host__ __device__ inline
+#define FLOOR(x) floor(x)
+
+#if __CUDA_ARCH__ >= 600
+// Recent compute capabilities have block-level atomicAdd for all data types, so we use that
+#define ACCUM(x,y) atomicAdd_block(&(x),(y))
+#else
+// Older architectures don't have block-level atomicAdd, nor atomicAdd for doubles, so we defer to atomicAdd for float
+// and use the known atomicCAS-based implementation for double
+template
+__device__ inline data_t atomic_add(data_t *address, data_t val) {
+ return atomicAdd(address, val);
+}
+
+template<>
+__device__ inline double atomic_add(double *address, double val) {
+ unsigned long long int* address_as_ull = (unsigned long long int*)address;
+ unsigned long long int old = *address_as_ull, assumed;
+ do {
+ assumed = old;
+ old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val + __longlong_as_double(assumed)));
+ } while (assumed != old);
+ return __longlong_as_double(old);
+}
+
+#define ACCUM(x,y) atomic_add(&(x),(y))
+#endif // #if __CUDA_ARCH__ >= 600
+
+#else
+// CPU versions
+
+#define HOST_DEVICE
+#define INLINE_HOST_DEVICE inline
+#define FLOOR(x) std::floor(x)
+#define ACCUM(x,y) (x) += (y)
+
+#endif // #ifdef __CUDACC__
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/modules/src/utils/cuda.cuh b/models/CtrlHair/external_code/face_parsing/modules/src/utils/cuda.cuh
new file mode 100644
index 0000000000000000000000000000000000000000..60c0023835e02c5f7c539c28ac07b75b72df394b
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/modules/src/utils/cuda.cuh
@@ -0,0 +1,71 @@
+#pragma once
+
+/*
+ * General settings and functions
+ */
+const int WARP_SIZE = 32;
+const int MAX_BLOCK_SIZE = 1024;
+
+static int getNumThreads(int nElem) {
+ int threadSizes[6] = {32, 64, 128, 256, 512, MAX_BLOCK_SIZE};
+ for (int i = 0; i < 6; ++i) {
+ if (nElem <= threadSizes[i]) {
+ return threadSizes[i];
+ }
+ }
+ return MAX_BLOCK_SIZE;
+}
+
+/*
+ * Reduction utilities
+ */
+template
+__device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask, int width = warpSize,
+ unsigned int mask = 0xffffffff) {
+#if CUDART_VERSION >= 9000
+ return __shfl_xor_sync(mask, value, laneMask, width);
+#else
+ return __shfl_xor(value, laneMask, width);
+#endif
+}
+
+__device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
+
+template
+struct Pair {
+ T v1, v2;
+ __device__ Pair() {}
+ __device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
+ __device__ Pair(T v) : v1(v), v2(v) {}
+ __device__ Pair(int v) : v1(v), v2(v) {}
+ __device__ Pair &operator+=(const Pair &a) {
+ v1 += a.v1;
+ v2 += a.v2;
+ return *this;
+ }
+};
+
+template
+static __device__ __forceinline__ T warpSum(T val) {
+#if __CUDA_ARCH__ >= 300
+ for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
+ val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
+ }
+#else
+ __shared__ T values[MAX_BLOCK_SIZE];
+ values[threadIdx.x] = val;
+ __threadfence_block();
+ const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
+ for (int i = 1; i < WARP_SIZE; i++) {
+ val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
+ }
+#endif
+ return val;
+}
+
+template
+static __device__ __forceinline__ Pair warpSum(Pair value) {
+ value.v1 = warpSum(value.v1);
+ value.v2 = warpSum(value.v2);
+ return value;
+}
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/my_parsing_util.py b/models/CtrlHair/external_code/face_parsing/my_parsing_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..88cdff20a4ea6808d36686817df7ff0cf142217d
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/my_parsing_util.py
@@ -0,0 +1,95 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: my_parsing_util.py
+# Time : 2022/07/15
+# Author: xyguoo@163.com
+# Description:
+"""
+import sys
+
+import numpy as np
+import torch
+from PIL import Image
+
+from models.CtrlHair.external_code.face_parsing.model import BiSeNet
+from models.CtrlHair.global_value_utils import PARSING_LABEL_LIST
+import torchvision.transforms as transforms
+
+
+class FaceParsing:
+ label_list = {0: 'background', 1: 'skin_other', 2: 'l_brow', 3: 'r_brow', 4: 'l_eye',
+ 5: 'r_eye', 6: 'eye_g', 7: 'l_ear', 8: 'r_ear', 9: 'ear_r',
+ 10: 'nose', 11: 'mouth', 12: 'u_lip', 13: 'l_lip', 14: 'neck',
+ 15: 'neck_l', 16: 'cloth', 17: 'hair', 18: 'hat'}
+ skin_area = {1, 2, 3, 4, 5, 7, 8, 10, 11, 12, 13}
+ bise_net = None
+ to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ])
+
+ @staticmethod
+ def parsing_img(img):
+ pil_img = Image.fromarray(img)
+ with torch.no_grad():
+ image = pil_img.resize((512, 512), Image.BILINEAR)
+ img = FaceParsing.to_tensor(image)
+ img = torch.unsqueeze(img, 0)
+ # img = img.cuda()
+ if FaceParsing.bise_net is None:
+ n_classes = 19
+ FaceParsing.bise_net = BiSeNet(n_classes=n_classes)
+ # FaceParsing.bise_net.cuda()
+ save_pth = 'models/CtrlHair/external_model_params/face_parsing_79999_iter.pth'
+ FaceParsing.bise_net.load_state_dict(torch.load(save_pth))
+ FaceParsing.bise_net.eval()
+ out = FaceParsing.bise_net(img)[0]
+ parsing = out.squeeze(0).cpu().numpy().argmax(0)
+ return parsing, image
+
+ @staticmethod
+ def swap_parsing_label_to_celeba_mask(parsing):
+ celeba_parsing = np.zeros_like(parsing)
+ label_lists = list(FaceParsing.label_list.values())
+ for label_idx, label_name in enumerate(PARSING_LABEL_LIST):
+ celeba_parsing[label_lists.index(label_name) == parsing] = label_idx
+ return celeba_parsing
+
+
+class FaceParsing_tensor:
+ label_list = {0: 'background', 1: 'skin_other', 2: 'l_brow', 3: 'r_brow', 4: 'l_eye',
+ 5: 'r_eye', 6: 'eye_g', 7: 'l_ear', 8: 'r_ear', 9: 'ear_r',
+ 10: 'nose', 11: 'mouth', 12: 'u_lip', 13: 'l_lip', 14: 'neck',
+ 15: 'neck_l', 16: 'cloth', 17: 'hair', 18: 'hat'}
+ skin_area = {1, 2, 3, 4, 5, 7, 8, 10, 11, 12, 13}
+ bise_net = None
+ to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ])
+
+ @staticmethod
+ def parsing_img(img=None):
+ with torch.no_grad():
+ if FaceParsing.bise_net is None:
+ n_classes = 19
+ FaceParsing.bise_net = BiSeNet(n_classes=n_classes)
+ save_pth = 'pretrained_models/BiSeNet/face_parsing_79999_iter.pth'
+ FaceParsing.bise_net.load_state_dict(torch.load(save_pth))
+ FaceParsing.bise_net.eval()
+ FaceParsing.bise_net = FaceParsing.bise_net.cuda()
+
+ if img is None:
+ return
+ out = FaceParsing.bise_net(img)[0]
+ parsing = out.squeeze(0).argmax(0)
+ return parsing, None
+
+ @staticmethod
+ def swap_parsing_label_to_celeba_mask(parsing):
+ celeba_parsing = torch.zeros_like(parsing)
+ label_lists = list(FaceParsing.label_list.values())
+ for label_idx, label_name in enumerate(PARSING_LABEL_LIST):
+ celeba_parsing[label_lists.index(label_name) == parsing] = label_idx
+ return celeba_parsing
diff --git a/models/CtrlHair/external_code/face_parsing/optimizer.py b/models/CtrlHair/external_code/face_parsing/optimizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c99e0645164b22f1e743ee99daadadd26a1cd80
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/optimizer.py
@@ -0,0 +1,69 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+import torch
+import logging
+
+logger = logging.getLogger()
+
+class Optimizer(object):
+ def __init__(self,
+ model,
+ lr0,
+ momentum,
+ wd,
+ warmup_steps,
+ warmup_start_lr,
+ max_iter,
+ power,
+ *args, **kwargs):
+ self.warmup_steps = warmup_steps
+ self.warmup_start_lr = warmup_start_lr
+ self.lr0 = lr0
+ self.lr = self.lr0
+ self.max_iter = float(max_iter)
+ self.power = power
+ self.it = 0
+ wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = model.get_params()
+ param_list = [
+ {'params': wd_params},
+ {'params': nowd_params, 'weight_decay': 0},
+ {'params': lr_mul_wd_params, 'lr_mul': True},
+ {'params': lr_mul_nowd_params, 'weight_decay': 0, 'lr_mul': True}]
+ self.optim = torch.optim.SGD(
+ param_list,
+ lr = lr0,
+ momentum = momentum,
+ weight_decay = wd)
+ self.warmup_factor = (self.lr0/self.warmup_start_lr)**(1./self.warmup_steps)
+
+
+ def get_lr(self):
+ if self.it <= self.warmup_steps:
+ lr = self.warmup_start_lr*(self.warmup_factor**self.it)
+ else:
+ factor = (1-(self.it-self.warmup_steps)/(self.max_iter-self.warmup_steps))**self.power
+ lr = self.lr0 * factor
+ return lr
+
+
+ def step(self):
+ self.lr = self.get_lr()
+ for pg in self.optim.param_groups:
+ if pg.get('lr_mul', False):
+ pg['lr'] = self.lr * 10
+ else:
+ pg['lr'] = self.lr
+ if self.optim.defaults.get('lr_mul', False):
+ self.optim.defaults['lr'] = self.lr * 10
+ else:
+ self.optim.defaults['lr'] = self.lr
+ self.it += 1
+ self.optim.step()
+ if self.it == self.warmup_steps+2:
+ logger.info('==> warmup done, start to implement poly lr strategy')
+
+ def zero_grad(self):
+ self.optim.zero_grad()
+
diff --git a/models/CtrlHair/external_code/face_parsing/prepropess_data.py b/models/CtrlHair/external_code/face_parsing/prepropess_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee7ed56dd8c0372d482e6a53f323da17043bd521
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/prepropess_data.py
@@ -0,0 +1,38 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+import os.path as osp
+import os
+import cv2
+from transform import *
+from PIL import Image
+
+face_data = '/home/zll/data/CelebAMask-HQ/CelebA-HQ-img'
+face_sep_mask = '/home/zll/data/CelebAMask-HQ/CelebAMask-HQ-mask-anno'
+mask_path = '/home/zll/data/CelebAMask-HQ/mask'
+counter = 0
+total = 0
+for i in range(15):
+
+ atts = ['skin', 'l_brow', 'r_brow', 'l_eye', 'r_eye', 'eye_g', 'l_ear', 'r_ear', 'ear_r',
+ 'nose', 'mouth', 'u_lip', 'l_lip', 'neck', 'neck_l', 'cloth', 'hair', 'hat']
+
+ for j in range(i * 2000, (i + 1) * 2000):
+
+ mask = np.zeros((512, 512))
+
+ for l, att in enumerate(atts, 1):
+ total += 1
+ file_name = ''.join([str(j).rjust(5, '0'), '_', att, '.png'])
+ path = osp.join(face_sep_mask, str(i), file_name)
+
+ if os.path.exists(path):
+ counter += 1
+ sep_mask = np.array(Image.open(path).convert('P'))
+ # print(np.unique(sep_mask))
+
+ mask[sep_mask == 225] = l
+ cv2.imwrite('{}/{}.png'.format(mask_path, j), mask)
+ print(j)
+
+print(counter, total)
\ No newline at end of file
diff --git a/models/CtrlHair/external_code/face_parsing/resnet.py b/models/CtrlHair/external_code/face_parsing/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa2bf95130e9815ba378cb6f73207068b81a04b9
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/resnet.py
@@ -0,0 +1,109 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.model_zoo as modelzoo
+
+# from modules.bn import InPlaceABNSync as BatchNorm2d
+
+resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
+
+
+def conv3x3(in_planes, out_planes, stride=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=1, bias=False)
+
+
+class BasicBlock(nn.Module):
+ def __init__(self, in_chan, out_chan, stride=1):
+ super(BasicBlock, self).__init__()
+ self.conv1 = conv3x3(in_chan, out_chan, stride)
+ self.bn1 = nn.BatchNorm2d(out_chan)
+ self.conv2 = conv3x3(out_chan, out_chan)
+ self.bn2 = nn.BatchNorm2d(out_chan)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = None
+ if in_chan != out_chan or stride != 1:
+ self.downsample = nn.Sequential(
+ nn.Conv2d(in_chan, out_chan,
+ kernel_size=1, stride=stride, bias=False),
+ nn.BatchNorm2d(out_chan),
+ )
+
+ def forward(self, x):
+ residual = self.conv1(x)
+ residual = F.relu(self.bn1(residual))
+ residual = self.conv2(residual)
+ residual = self.bn2(residual)
+
+ shortcut = x
+ if self.downsample is not None:
+ shortcut = self.downsample(x)
+
+ out = shortcut + residual
+ out = self.relu(out)
+ return out
+
+
+def create_layer_basic(in_chan, out_chan, bnum, stride=1):
+ layers = [BasicBlock(in_chan, out_chan, stride=stride)]
+ for i in range(bnum-1):
+ layers.append(BasicBlock(out_chan, out_chan, stride=1))
+ return nn.Sequential(*layers)
+
+
+class Resnet18(nn.Module):
+ def __init__(self):
+ super(Resnet18, self).__init__()
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
+ bias=False)
+ self.bn1 = nn.BatchNorm2d(64)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
+ self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
+ self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
+ self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = F.relu(self.bn1(x))
+ x = self.maxpool(x)
+
+ x = self.layer1(x)
+ feat8 = self.layer2(x) # 1/8
+ feat16 = self.layer3(feat8) # 1/16
+ feat32 = self.layer4(feat16) # 1/32
+ return feat8, feat16, feat32
+
+ def init_weight(self):
+ state_dict = modelzoo.load_url(resnet18_url)
+ self_state_dict = self.state_dict()
+ for k, v in state_dict.items():
+ if 'fc' in k: continue
+ self_state_dict.update({k: v})
+ self.load_state_dict(self_state_dict)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+if __name__ == "__main__":
+ net = Resnet18()
+ x = torch.randn(16, 3, 224, 224)
+ out = net(x)
+ print(out[0].size())
+ print(out[1].size())
+ print(out[2].size())
+ net.get_params()
diff --git a/models/CtrlHair/external_code/face_parsing/train.py b/models/CtrlHair/external_code/face_parsing/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..e550289e66ca8398caf7f993aba76dce422fbc5b
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/train.py
@@ -0,0 +1,177 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+from logger import setup_logger
+from model import BiSeNet
+from face_dataset import FaceMask
+from loss import OhemCELoss
+from evaluate import evaluate
+from optimizer import Optimizer
+
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+import torch.distributed as dist
+
+import os
+import os.path as osp
+import logging
+import time
+import datetime
+import argparse
+
+import my_torchlib.train_utils
+
+respth = './resources'
+if not osp.exists(respth):
+ os.makedirs(respth)
+logger = logging.getLogger()
+
+
+def parse_args():
+ parse = argparse.ArgumentParser()
+ parse.add_argument(
+ '--local_rank',
+ dest = 'local_rank',
+ type = int,
+ default = -1,
+ )
+ return parse.parse_args()
+
+
+def train():
+ args = parse_args()
+ torch.cuda.set_device(args.local_rank)
+ dist.init_process_group(
+ backend = 'nccl',
+ init_method = 'tcp://127.0.0.1:33241',
+ world_size = torch.cuda.device_count(),
+ rank=args.local_rank
+ )
+ setup_logger(respth)
+
+ # dataset
+ n_classes = 19
+ n_img_per_gpu = 16
+ n_workers = 8
+ cropsize = [448, 448]
+ data_root = '/home/zll/data/CelebAMask-HQ/'
+
+ ds = FaceMask(data_root, cropsize=cropsize, mode='scripts')
+ sampler = torch.utils.data.distributed.DistributedSampler(ds)
+ dl = DataLoader(ds,
+ batch_size = n_img_per_gpu,
+ shuffle = False,
+ sampler = sampler,
+ num_workers = n_workers,
+ pin_memory = True,
+ drop_last = True)
+
+ # model
+ ignore_idx = -100
+ net = BiSeNet(n_classes=n_classes)
+ net.cuda()
+ my_torchlib.train_utils.train()
+ net = nn.parallel.DistributedDataParallel(net,
+ device_ids = [args.local_rank, ],
+ output_device = args.local_rank
+ )
+ score_thres = 0.7
+ n_min = n_img_per_gpu * cropsize[0] * cropsize[1]//16
+ LossP = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
+ Loss2 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
+ Loss3 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
+
+ ## optimizer
+ momentum = 0.9
+ weight_decay = 5e-4
+ lr_start = 1e-2
+ max_iter = 80000
+ power = 0.9
+ warmup_steps = 1000
+ warmup_start_lr = 1e-5
+ optim = Optimizer(
+ model = net.module,
+ lr0 = lr_start,
+ momentum = momentum,
+ wd = weight_decay,
+ warmup_steps = warmup_steps,
+ warmup_start_lr = warmup_start_lr,
+ max_iter = max_iter,
+ power = power)
+
+ ## scripts loop
+ msg_iter = 50
+ loss_avg = []
+ st = glob_st = time.time()
+ diter = iter(dl)
+ epoch = 0
+ for it in range(max_iter):
+ try:
+ im, lb = next(diter)
+ if not im.size()[0] == n_img_per_gpu:
+ raise StopIteration
+ except StopIteration:
+ epoch += 1
+ sampler.set_epoch(epoch)
+ diter = iter(dl)
+ im, lb = next(diter)
+ im = im.cuda()
+ lb = lb.cuda()
+ H, W = im.size()[2:]
+ lb = torch.squeeze(lb, 1)
+
+ optim.zero_grad()
+ out, out16, out32 = net(im)
+ lossp = LossP(out, lb)
+ loss2 = Loss2(out16, lb)
+ loss3 = Loss3(out32, lb)
+ loss = lossp + loss2 + loss3
+ loss.backward()
+ optim.step()
+
+ loss_avg.append(loss.item())
+
+ # print training log message
+ if (it+1) % msg_iter == 0:
+ loss_avg = sum(loss_avg) / len(loss_avg)
+ lr = optim.lr
+ ed = time.time()
+ t_intv, glob_t_intv = ed - st, ed - glob_st
+ eta = int((max_iter - it) * (glob_t_intv / it))
+ eta = str(datetime.timedelta(seconds=eta))
+ msg = ', '.join([
+ 'it: {it}/{max_it}',
+ 'lr: {lr:4f}',
+ 'loss: {loss:.4f}',
+ 'eta: {eta}',
+ 'time: {time:.4f}',
+ ]).format(
+ it = it+1,
+ max_it = max_iter,
+ lr = lr,
+ loss = loss_avg,
+ time = t_intv,
+ eta = eta
+ )
+ logger.info(msg)
+ loss_avg = []
+ st = ed
+ if dist.get_rank() == 0:
+ if (it+1) % 5000 == 0:
+ state = net.module.state_dict() if hasattr(net, 'module') else net.state_dict()
+ if dist.get_rank() == 0:
+ torch.save(state, './resources/cp/{}_iter.pth'.format(it))
+ evaluate(dspth='/home/zll/data/CelebAMask-HQ/test-img', cp='{}_iter.pth'.format(it))
+
+ # dump the final model
+ save_pth = osp.join(respth, 'model_final_diss.pth')
+ # net.cpu()
+ state = net.module.state_dict() if hasattr(net, 'module') else net.state_dict()
+ if dist.get_rank() == 0:
+ torch.save(state, save_pth)
+ logger.info('training done, model saved to: {}'.format(save_pth))
+
+
+if __name__ == "__main__":
+ train()
diff --git a/models/CtrlHair/external_code/face_parsing/transform.py b/models/CtrlHair/external_code/face_parsing/transform.py
new file mode 100644
index 0000000000000000000000000000000000000000..9479ae356a151f5da8eedf288abeae7458739d24
--- /dev/null
+++ b/models/CtrlHair/external_code/face_parsing/transform.py
@@ -0,0 +1,129 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+from PIL import Image
+import PIL.ImageEnhance as ImageEnhance
+import random
+import numpy as np
+
+class RandomCrop(object):
+ def __init__(self, size, *args, **kwargs):
+ self.size = size
+
+ def __call__(self, im_lb):
+ im = im_lb['im']
+ lb = im_lb['lb']
+ assert im.size == lb.size
+ W, H = self.size
+ w, h = im.size
+
+ if (W, H) == (w, h): return dict(im=im, lb=lb)
+ if w < W or h < H:
+ scale = float(W) / w if w < h else float(H) / h
+ w, h = int(scale * w + 1), int(scale * h + 1)
+ im = im.resize((w, h), Image.BILINEAR)
+ lb = lb.resize((w, h), Image.NEAREST)
+ sw, sh = random.random() * (w - W), random.random() * (h - H)
+ crop = int(sw), int(sh), int(sw) + W, int(sh) + H
+ return dict(
+ im = im.crop(crop),
+ lb = lb.crop(crop)
+ )
+
+
+class HorizontalFlip(object):
+ def __init__(self, p=0.5, *args, **kwargs):
+ self.p = p
+
+ def __call__(self, im_lb):
+ if random.random() > self.p:
+ return im_lb
+ else:
+ im = im_lb['im']
+ lb = im_lb['lb']
+
+ # atts = [1 'skin', 2 'l_brow', 3 'r_brow', 4 'l_eye', 5 'r_eye', 6 'eye_g', 7 'l_ear', 8 'r_ear', 9 'ear_r',
+ # 10 'nose', 11 'mouth', 12 'u_lip', 13 'l_lip', 14 'neck', 15 'neck_l', 16 'cloth', 17 'hair', 18 'hat']
+
+ flip_lb = np.array(lb)
+ flip_lb[lb == 2] = 3
+ flip_lb[lb == 3] = 2
+ flip_lb[lb == 4] = 5
+ flip_lb[lb == 5] = 4
+ flip_lb[lb == 7] = 8
+ flip_lb[lb == 8] = 7
+ flip_lb = Image.fromarray(flip_lb)
+ return dict(im = im.transpose(Image.FLIP_LEFT_RIGHT),
+ lb = flip_lb.transpose(Image.FLIP_LEFT_RIGHT),
+ )
+
+
+class RandomScale(object):
+ def __init__(self, scales=(1, ), *args, **kwargs):
+ self.scales = scales
+
+ def __call__(self, im_lb):
+ im = im_lb['im']
+ lb = im_lb['lb']
+ W, H = im.size
+ scale = random.choice(self.scales)
+ w, h = int(W * scale), int(H * scale)
+ return dict(im = im.resize((w, h), Image.BILINEAR),
+ lb = lb.resize((w, h), Image.NEAREST),
+ )
+
+
+class ColorJitter(object):
+ def __init__(self, brightness=None, contrast=None, saturation=None, *args, **kwargs):
+ if not brightness is None and brightness>0:
+ self.brightness = [max(1-brightness, 0), 1+brightness]
+ if not contrast is None and contrast>0:
+ self.contrast = [max(1-contrast, 0), 1+contrast]
+ if not saturation is None and saturation>0:
+ self.saturation = [max(1-saturation, 0), 1+saturation]
+
+ def __call__(self, im_lb):
+ im = im_lb['im']
+ lb = im_lb['lb']
+ r_brightness = random.uniform(self.brightness[0], self.brightness[1])
+ r_contrast = random.uniform(self.contrast[0], self.contrast[1])
+ r_saturation = random.uniform(self.saturation[0], self.saturation[1])
+ im = ImageEnhance.Brightness(im).enhance(r_brightness)
+ im = ImageEnhance.Contrast(im).enhance(r_contrast)
+ im = ImageEnhance.Color(im).enhance(r_saturation)
+ return dict(im = im,
+ lb = lb,
+ )
+
+
+class MultiScale(object):
+ def __init__(self, scales):
+ self.scales = scales
+
+ def __call__(self, img):
+ W, H = img.size
+ sizes = [(int(W*ratio), int(H*ratio)) for ratio in self.scales]
+ imgs = []
+ [imgs.append(img.resize(size, Image.BILINEAR)) for size in sizes]
+ return imgs
+
+
+class Compose(object):
+ def __init__(self, do_list):
+ self.do_list = do_list
+
+ def __call__(self, im_lb):
+ for comp in self.do_list:
+ im_lb = comp(im_lb)
+ return im_lb
+
+
+
+
+if __name__ == '__main__':
+ flip = HorizontalFlip(p = 1)
+ crop = RandomCrop((321, 321))
+ rscales = RandomScale((0.75, 1.0, 1.5, 1.75, 2.0))
+ img = Image.open('data/img.jpg')
+ lb = Image.open('data/label.png')
diff --git a/models/CtrlHair/external_code/landmarks_util.py b/models/CtrlHair/external_code/landmarks_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d490bde19c8a00343b417b12a1472a33bf0f4e4
--- /dev/null
+++ b/models/CtrlHair/external_code/landmarks_util.py
@@ -0,0 +1,55 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: landmarks_util.py
+# Time : 2022/07/15
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import pickle as pkl
+
+import dlib as dlib
+import numpy as np
+import tqdm
+import cv2
+
+detector = dlib.get_frontal_face_detector()
+predictor_dict = {68: dlib.shape_predictor('models/CtrlHair/external_model_params/shape_predictor_68_face_landmarks.dat'),
+ 81: dlib.shape_predictor('models/CtrlHair/external_model_params/shape_predictor_81_face_landmarks.dat')}
+
+
+def detect_landmarks(root_dir, dataset_name, landmark_output_file_path, output_dir=None, predictor=None):
+ result_dic = {}
+ for dn in dataset_name:
+ img_dir = os.path.join(root_dir, dn, 'images_256')
+ files = os.listdir(img_dir)
+ files.sort()
+
+ if output_dir and not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+
+ for f in tqdm.tqdm(files):
+ file_path = os.path.join(img_dir, f)
+ img_rd = cv2.imread(file_path)
+ img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
+
+ faces = detector(img_gray, 0)
+ font = cv2.FONT_HERSHEY_SIMPLEX
+
+ # annotate landmarks
+ if len(faces) != 0:
+ landmarks = np.array([[p.x, p.y] for p in predictor(img_rd, faces[0]).parts()])
+ result_dic['%s___%s' % (dn, f[:-4])] = landmarks / img_gray.shape[0]
+ if output_dir:
+ for idx, point in enumerate(landmarks):
+ pos = (point[0], point[1])
+ cv2.circle(img_rd, pos, 2, color=(139, 0, 0))
+ cv2.putText(img_rd, str(idx + 1), pos, font, 0.5, (0, 0, 255), 2, cv2.LINE_AA)
+ cv2.imwrite(os.path.join(output_dir, f), img_rd)
+ else:
+ # not detect face
+ print('no face for %s' % file_path)
+
+ with open(landmark_output_file_path, 'wb') as f:
+ pkl.dump(result_dic, f)
\ No newline at end of file
diff --git a/models/CtrlHair/global_value_utils.py b/models/CtrlHair/global_value_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..8355d7f7ffe2cac1fdcf720da646039103e5feb5
--- /dev/null
+++ b/models/CtrlHair/global_value_utils.py
@@ -0,0 +1,56 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: global_value_utils.py
+# Time : 2021/9/11 19:15
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+import pickle as pkl
+
+
+GLOBAL_DATA_ROOT = './dataset_info_ctrlhair'
+########################################################
+# Please change these setting if you scripts a new model`
+DATASET_NAME = ['ffhq', 'CelebaMask_HQ']
+DEFAULT_CONFIG_COLOR_TEXTURE_BRANCH = '045'
+DEFAULT_CONFIG_SHAPE_BRANCH = '054'
+########################################################
+
+TEMP_FOLDER = 'models/CtrlHair/temp_folder'
+
+PARSING_COLOR_LIST = [[0, 0, 0],
+ [204, 0, 0],
+ [76, 153, 0],
+ [204, 204, 0], ##
+ [51, 51, 255], ##
+ [204, 0, 204], ##
+ [0, 255, 255], ##
+ [51, 255, 255], ##
+ [102, 51, 0], ##
+ [255, 0, 0], ##
+ [102, 204, 0], ##
+ [255, 255, 0], ##
+ [0, 0, 153], ##
+ [0, 0, 204], ## hair
+ [255, 51, 153], ##
+ [0, 204, 204], ##
+ [0, 51, 0], ##
+ [255, 153, 51],
+ [0, 204, 0],
+ [255, 85, 255],
+ [255, 170, 255],
+ [0, 170, 255],
+ [85, 255, 255],
+ [170, 255, 255],
+ [255, 255, 255]]
+
+PARSING_LABEL_LIST = ['background', 'skin_other', 'nose', 'eye_g', 'l_eye', 'r_eye', 'l_brow', 'r_brow',
+ 'l_ear', 'r_ear', 'mouth', 'u_lip', 'l_lip', 'hair', 'hat',
+ 'ear_r', 'neck_l', 'neck', 'cloth']
+HAIR_IDX = PARSING_LABEL_LIST.index('hair')
+HAT_IDX = PARSING_LABEL_LIST.index('hat')
+UNKNOWN_IDX = len(PARSING_COLOR_LIST) - 1
+
+WRAP_TEMP_FOLDER = [os.path.join(TEMP_FOLDER, '/wrap_triangle/wrap_temp_result')]
diff --git a/models/CtrlHair/hair_editor.py b/models/CtrlHair/hair_editor.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2f4dd7964f4ca324ab9d936928c7f4ef979084b
--- /dev/null
+++ b/models/CtrlHair/hair_editor.py
@@ -0,0 +1,335 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: hair_editor.py
+# Time : 2021/11/18 17:21
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import os
+import pickle
+from glob import glob
+
+import cv2
+import numpy as np
+import torch
+
+import my_torchlib
+from color_texture_branch.solver import Solver as SolveFeature
+from external_code.face_parsing.my_parsing_util import FaceParsing
+from global_value_utils import HAIR_IDX, PARSING_LABEL_LIST
+from poisson_blending import poisson_blending
+from sean_codes.models.pix2pix_model import Pix2PixModel
+from sean_codes.options.test_options import TestOptions
+from shape_branch.solver import Solver as SolverMask
+from util.imutil import write_rgb
+
+
+# adaptor_root_dir = '/data1/guoxuyang/myWorkSpace/hair_editing'
+# sys.path.append(adaptor_root_dir)
+# sys.path.append(os.path.join(adaptor_root_dir, 'external_code/face_3DDFA'))
+
+
+def change_status(model, new_status):
+ for m in model.modules():
+ if hasattr(m, 'status'):
+ m.status = new_status
+
+
+class HairEditor:
+ """
+ This is the basic module, that could achieve many editing task. ui/hair_swap.py/Backend succeed this class.
+ """
+
+ def __init__(self, load_feature_model=True, load_mask_model=True):
+ self.opt = TestOptions().parse()
+ self.opt.status = 'test'
+ self.sean_model = Pix2PixModel(self.opt)
+ self.sean_model.eval()
+ self.img_size = 256
+ self.device = torch.device('cuda', 0)
+
+ if load_feature_model:
+ from color_texture_branch.config import cfg as cfg_feature
+ self.solver_feature = SolveFeature(cfg_feature, device=self.device, local_rank=-1, training=False)
+
+ self.feature_encoder = self.solver_feature.dis
+ self.feature_generator = self.solver_feature.gen
+ self.feature_rgb_predictor = self.solver_feature.rgb_model
+ # self.feature_curliness_predictor = self.solver_feature.curliness_model
+
+ # ckpt_dir = 'external_model_params/disentangle_checkpoints/' + cfg_app.experiment_name + '/checkpoints'
+ ckpt_dir = 'model_trained/color_texture/' + cfg_feature.experiment_name + '/checkpoints'
+ ckpt = my_torchlib.load_checkpoint(ckpt_dir)
+ for model_name in ['Model_G', 'Model_D']:
+ cur_model = ckpt[model_name]
+ if list(cur_model)[0].startswith('module'):
+ ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
+
+ self.feature_generator.load_state_dict(ckpt['Model_G'], strict=True)
+ self.feature_encoder.load_state_dict(ckpt['Model_D'], strict=True)
+
+ # if 'curliness' in cfg_feature.predictor:
+ # ckpt = my_torchlib.load_checkpoint(cfg_feature.predictor.curliness.root_dir + '/checkpoints')
+ # self.feature_curliness_predictor.load_state_dict(ckpt['Predictor'], strict=True)
+
+ if 'rgb' in cfg_feature.predictor:
+ ckpt = my_torchlib.load_checkpoint(cfg_feature.predictor.rgb.root_dir + '/checkpoints')
+ self.feature_rgb_predictor.load_state_dict(ckpt['Predictor'], strict=True)
+
+ # load unsupervised direction
+ existing_dirs_dir = os.path.join('model_trained/color_texture', cfg_feature.experiment_name,
+ 'texture_dir_used')
+ if os.path.exists(existing_dirs_dir):
+ existing_dirs_list = os.listdir(existing_dirs_dir)
+ existing_dirs_list.sort()
+ existing_dirs = []
+ for dd in existing_dirs_list:
+ with open(os.path.join(existing_dirs_dir, dd), 'rb') as f:
+ existing_dirs.append(pickle.load(f).to(self.device))
+ self.texture_dirs = existing_dirs
+
+ if load_mask_model:
+ from shape_branch.config import cfg as cfg_mask
+ self.solver_mask = SolverMask(cfg_mask, device=self.device, local_rank=-1, training=False)
+ self.mask_generator = self.solver_mask.gen
+
+ ##############################################
+ # change to your checkpoints dir #
+ ##############################################
+ ckpt_dir = 'model_trained/shape/' + cfg_mask.experiment_name + '/checkpoints'
+ ckpt = my_torchlib.load_checkpoint(ckpt_dir)
+ for model_name in ['Model_G', 'Model_D']:
+ cur_model = ckpt[model_name]
+ if list(cur_model)[0].startswith('module'):
+ ckpt[model_name] = {kk[7:]: cur_model[kk] for kk in cur_model}
+
+ self.mask_generator.load_state_dict(ckpt['Model_G'], strict=True)
+
+ # load unsupervised direction
+ existing_dirs_dir = os.path.join('model_trained/shape', cfg_mask.experiment_name, 'shape_dir_used')
+ if os.path.exists(existing_dirs_dir):
+ existing_dirs_list = os.listdir(existing_dirs_dir)
+ existing_dirs_list.sort()
+ existing_dirs = []
+ for dd in existing_dirs_list:
+ with open(os.path.join(existing_dirs_dir, dd), 'rb') as f:
+ existing_dirs.append(pickle.load(f).to(self.device))
+ self.shape_dirs = existing_dirs
+
+ def preprocess_img(self, img):
+ img = cv2.resize(img.astype('uint8'), (self.img_size, self.img_size))
+ return (np.transpose(img, [2, 0, 1]) / 127.5 - 1.0)[None, ...]
+
+ def preprocess_mask(self, mask_img):
+ mask_img = cv2.resize(mask_img.astype('uint8'), (self.img_size, self.img_size),
+ interpolation=cv2.INTER_NEAREST)
+ return mask_img[None, None, :, :]
+
+ @staticmethod
+ def load_average_feature():
+ ############### load average features
+ # average_style_code_folder = 'styles_test/mean_style_code/mean/'
+ average_style_code_folder = 'sean_codes/styles_test/mean_style_code/median/'
+ input_style_dic = {}
+
+ ############### hard coding for categories
+ for i in range(19):
+ input_style_dic[str(i)] = {}
+ average_category_folder_list = glob(os.path.join(average_style_code_folder, str(i), '*.npy'))
+ average_category_list = [os.path.splitext(os.path.basename(name))[0] for name in
+ average_category_folder_list]
+
+ for style_code_path in average_category_list:
+ input_style_dic[str(i)][style_code_path] = torch.from_numpy(
+ np.load(os.path.join(average_style_code_folder, str(i), style_code_path + '.npy'))).cuda()
+ return input_style_dic
+
+ def get_code(self, hair_img, hair_parsing):
+ # generate style code
+ data = {'label': torch.tensor(hair_parsing, dtype=torch.float32),
+ 'instance': torch.tensor(0),
+ 'image': torch.tensor(hair_img, dtype=torch.float32),
+ 'path': ['temp/temp_npy']}
+ change_status(self.sean_model, 'test')
+ hair_img_code = self.sean_model(data, mode='style_code')
+ return hair_img_code
+
+ def gen_img(self, code, parsing):
+ # load style code
+ if not isinstance(code, torch.Tensor):
+ code = torch.tensor(code)
+ obj_dic = self.load_average_feature()
+
+ for idx in range(19):
+ cur_code = code[0, idx]
+ if not torch.all(cur_code == 0):
+ obj_dic[str(idx)]['ACE'] = cur_code
+
+ temp_face_image = torch.zeros((0, 3, self.img_size, self.img_size)) # place holder
+
+ data = {'label': torch.tensor(parsing, dtype=torch.float32),
+ 'instance': torch.tensor(0),
+ 'image': torch.tensor(temp_face_image, dtype=torch.float32),
+ 'obj_dic': obj_dic}
+ change_status(self.sean_model, 'UI_mode')
+ # self.model = self.model.to(code.device)
+ generated = self.sean_model(data, mode='UI_mode')[0]
+ return generated
+
+ def generate_by_sean(self, face_img_code, hair_code, target_seg):
+ """
+ :param face_img_code: please input with the shape [19, 512]
+ :param hair_code: please input with the shape [512]
+ :param target_seg:
+ :return:
+ """
+ # load style code
+ obj_dic = self.load_average_feature()
+
+ for idx in range(19):
+ if idx == HAIR_IDX:
+ cur_code = hair_code
+ # cur_code = face_img_code[0, idx]
+ else:
+ cur_code = face_img_code[idx]
+ if not torch.all(face_img_code == 0):
+ obj_dic[str(idx)]['ACE'] = cur_code
+
+ data = {'label': torch.tensor(target_seg, dtype=torch.float32),
+ 'instance': torch.tensor(0),
+ 'obj_dic': obj_dic,
+ 'image': None}
+ change_status(self.sean_model, 'UI_mode')
+ generated = self.sean_model(data, mode='UI_mode')[0]
+ return generated
+
+ def generate_instance_transfer_img(self, face_img, face_parsing, hair_img, hair_parsing, target_seg, edit_data=None,
+ temp_path='temp'):
+ # generate style code
+ data = {'label': torch.tensor(face_parsing, dtype=torch.float32),
+ 'instance': torch.tensor(0),
+ 'image': torch.tensor(face_img, dtype=torch.float32),
+ 'path': ['temp/temp_npy']}
+ face_img_code = self.sean_model(data, mode='style_code')
+
+ if hair_img is None:
+ hair_img_code = face_img_code
+ else:
+ data = {'label': torch.tensor(hair_parsing, dtype=torch.float32),
+ 'instance': torch.tensor(0),
+ 'image': torch.tensor(hair_img, dtype=torch.float32),
+ 'path': ['temp/temp_npy']}
+ change_status(self.sean_model, 'test')
+ hair_img_code = self.sean_model(data, mode='style_code')
+ hair_code = hair_img_code[0, HAIR_IDX]
+
+ if edit_data is not None:
+ hair_code = self.solver_feature.edit_infer(hair_code[None, ...], edit_data)[0]
+
+ return self.generate_by_sean(face_img_code[0], hair_code, target_seg)
+
+ def get_hair_color(self, img):
+ parsing, _ = FaceParsing.parsing_img(img)
+ parsing = FaceParsing.swap_parsing_label_to_celeba_mask(parsing)
+ parsing = cv2.resize(parsing.astype('uint8'), (1024, 1024), interpolation=cv2.INTER_NEAREST)
+ img = cv2.resize(img.astype('uint8'), (1024, 1024))
+ hair_mask = (parsing == HAIR_IDX).astype('uint8')
+
+ kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(19, 19))
+ hair_mask = cv2.erode(hair_mask, kernel, iterations=1)
+ points = img[hair_mask.astype('bool')]
+ moment1 = points.mean(axis=0)
+ return moment1
+
+ @staticmethod
+ def draw_landmarks(img, lms):
+ lms = lms / 2
+ lms = lms.astype('int')
+ for idx, point in enumerate(lms):
+ font = cv2.FONT_HERSHEY_SIMPLEX
+ pos = (point[0], point[1])
+ cv2.circle(img, pos, 2, color=(139, 0, 0))
+ cv2.putText(img, str(idx + 1), pos, font, 0.18, (255, 0, 0), 1, cv2.LINE_AA)
+ return img
+
+ def postprocess_blending(self, face_img, res_img, face_parsing, target_parsing, verbose_print=False, blending=True):
+ """
+ Blend original face img and result image with poisson blending.
+ If not blend, the result image will look slightly different from original image in some details in
+ non-hair region, but the image quality will be better.
+ :param face_img:
+ :param res_img:
+ :param face_parsing:
+ :param target_parsing:
+ :param verbose_print:
+ :param blending: If `False`, the result image will do some trivial thing like transferring data type
+ :return:
+ """
+ if verbose_print:
+ print("Post process for the result image...")
+
+ def from_tensor_order_to_cv2(tensor_img, is_mask=False):
+ if isinstance(tensor_img, torch.Tensor):
+ tensor_img = tensor_img.detach().cpu().numpy()
+ if len(tensor_img.shape) == 4:
+ tensor_img = tensor_img[0]
+ if len(tensor_img.shape) == 2:
+ tensor_img = tensor_img[None, ...]
+ if tensor_img.shape[2] <= 3:
+ return tensor_img
+ res = np.transpose(tensor_img, [1, 2, 0])
+ if not is_mask:
+ res = res * 127.5 + 127.5
+ return res
+
+ res_img = from_tensor_order_to_cv2(res_img)
+ res_img = res_img.astype('uint8')
+ if blending:
+
+ target_parsing = from_tensor_order_to_cv2(target_parsing, is_mask=True)
+ face_img = from_tensor_order_to_cv2(face_img)
+ face_img = face_img.astype('uint8')
+
+ face_parsing = from_tensor_order_to_cv2(face_parsing, is_mask=True)
+
+ res_mask = np.logical_or(target_parsing == HAIR_IDX, face_parsing == HAIR_IDX).astype('uint8')
+ kernel13 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(13, 13))
+ kernel5 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(5, 5))
+ res_mask_dilated = cv2.dilate(res_mask, kernel13, iterations=1)[..., None]
+
+ res_mask_dilated5 = cv2.dilate(res_mask, kernel5, iterations=1)[..., None]
+
+ bg_mask = (target_parsing == PARSING_LABEL_LIST.index('background'))
+ res_mask_dilated = res_mask_dilated * (1 - bg_mask) + res_mask_dilated5 * bg_mask
+
+ face_to_hair = poisson_blending(face_img, res_img, 1 - res_mask_dilated, with_gamma=True)
+ return face_to_hair, res_mask_dilated
+ else:
+ return res_img, None
+
+ def crop_face(self, img_rgb, save_path=None):
+ """
+ crop the face part in the image to adapt the editing system
+ :param img_rgb:
+ :param save_path:
+ :return:
+ """
+ from external_code.crop import recreate_aligned_images
+ from external_code.landmarks_util import predictor_dict, detector
+
+ predictor_68 = predictor_dict[68]
+ bbox = detector(img_rgb, 0)[0]
+ lm_68 = np.array([[p.x, p.y] for p in predictor_68(img_rgb, bbox).parts()])
+ crop_img_pil, lm_68 = recreate_aligned_images(img_rgb, lm_68, output_size=self.img_size)
+ img_rgb = np.array(crop_img_pil)
+ if save_path is not None:
+ write_rgb(save_path, img_rgb)
+ return img_rgb
+
+ def get_mask(self, img_rgb):
+ parsing, _ = FaceParsing.parsing_img(img_rgb)
+ parsing = FaceParsing.swap_parsing_label_to_celeba_mask(parsing)
+ mask_img = cv2.resize(parsing.astype('uint8'), (self.img_size, self.img_size), interpolation=cv2.INTER_NEAREST)
+ return mask_img
diff --git a/models/CtrlHair/my_pylib/__init__.py b/models/CtrlHair/my_pylib/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ab90debbcbb649ee8c209509221f6397d25031c
--- /dev/null
+++ b/models/CtrlHair/my_pylib/__init__.py
@@ -0,0 +1,7 @@
+# from __future__ import absolute_import
+# from __future__ import division
+# from __future__ import print_function
+
+from .path import *
+from .timer import *
+from .utils import *
diff --git a/models/CtrlHair/my_pylib/path.py b/models/CtrlHair/my_pylib/path.py
new file mode 100644
index 0000000000000000000000000000000000000000..c373a2f9fbd7218069bde2ccdd55db4c1ba6997a
--- /dev/null
+++ b/models/CtrlHair/my_pylib/path.py
@@ -0,0 +1,62 @@
+"""Complementary functions for os.path."""
+
+import fnmatch
+import os
+import sys
+
+
+def add_path(paths):
+ if not isinstance(paths, (list, tuple)):
+ paths = [paths]
+ for path in paths:
+ if path not in sys.path:
+ sys.path.insert(0, path)
+
+
+def mkdir(paths):
+ if not isinstance(paths, (list, tuple)):
+ paths = [paths]
+ for path in paths:
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+
+def split(path):
+ dir, name_ext = os.path.split(path)
+ name, ext = os.path.splitext(name_ext)
+ return dir, name, ext
+
+
+def directory(path):
+ return split(path)[0]
+
+
+def name(path):
+ return split(path)[1]
+
+
+def ext(path):
+ return split(path)[2]
+
+
+def name_ext(path):
+ return ''.join(split(path)[1:])
+
+
+abspath = os.path.abspath
+join = os.path.join
+
+
+def match(dir, pat, recursive=False):
+ if recursive:
+ iterator = os.walk(dir)
+ else:
+ try:
+ iterator = [next(os.walk(dir))]
+ except:
+ return []
+ matches = []
+ for root, _, file_names in iterator:
+ for file_name in fnmatch.filter(file_names, pat):
+ matches.append(os.path.join(root, file_name))
+ return matches
diff --git a/models/CtrlHair/my_pylib/timer.py b/models/CtrlHair/my_pylib/timer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fffb1c0cf9614f4a520a4d0cd938cac8463e4b1d
--- /dev/null
+++ b/models/CtrlHair/my_pylib/timer.py
@@ -0,0 +1,124 @@
+import datetime
+import timeit
+
+
+class Timer(object):
+ """A timer as a context manager.
+
+ Modified from https://github.com/brouberol/contexttimer/blob/master/contexttimer/__init__.py.
+
+ Wraps around a timer. A custom timer can be passed
+ to the constructor. The default timer is timeit.default_timer.
+
+ Note that the latter measures wall clock time, not CPU time!
+ On Unix systems, it corresponds to time.time.
+ On Windows systems, it corresponds to time.clock.
+
+ Arguments:
+ print_at_exit : If True, print when exiting context.
+ format : 'ms', 's' or 'datetime'
+ """
+
+ def __init__(self, fmt='s', print_at_exit=True, timer=timeit.default_timer):
+ assert fmt in ['ms', 's', 'datetime'], "`fmt` should be 'ms', 's' or 'datetime'!"
+ self._fmt = fmt
+ self._print_at_exit = print_at_exit
+ self._timer = timer
+ self.start()
+
+ def __enter__(self):
+ """Start the timer in the context manager scope."""
+ self.restart()
+ return self
+
+ def __exit__(self, exc_type, exc_value, exc_traceback):
+ """Print the end time."""
+ if self._print_at_exit:
+ print(str(self))
+
+ def __str__(self):
+ return self.fmt(self.elapsed)[1]
+
+ def start(self):
+ self.start_time = self._timer()
+
+ restart = start
+
+ @property
+ def elapsed(self):
+ """Return the current elapsed time since last (re)start."""
+ return self._timer() - self.start_time
+
+ def fmt(self, second):
+ if self._fmt == 'ms':
+ time_fmt = second * 1000
+ time_str = '%s %s' % (time_fmt, self._fmt)
+ elif self._fmt == 's':
+ time_fmt = second
+ time_str = '%s %s' % (time_fmt, self._fmt)
+ elif self._fmt == 'datetime':
+ time_fmt = datetime.timedelta(seconds=second)
+ time_str = str(time_fmt)
+ return time_fmt, time_str
+
+
+def timer(run_times=1, **timer_kwargs):
+ """Function decorator displaying the function execution time.
+
+ All kwargs are the arguments taken by the Timer class constructor.
+ """
+
+ # store Timer kwargs in local variable so the namespace isn't polluted
+ # by different level args and kwargs
+
+ def wrapped_f(f):
+ def wrapped(*args, **kwargs):
+ timer_kwargs.update(print_at_exit=False)
+ with Timer(**timer_kwargs) as t:
+ for _ in range(run_times):
+ out = f(*args, **kwargs)
+ fmt = '[*] function "%(function_name)s" execution time for %(run_times)d runs: %(execution_time)s = %(' \
+ 'execution_time_each)s * %(run_times)d [*] '
+ context = {'function_name': f.__name__, 'run_times': run_times, 'execution_time': t,
+ 'execution_time_each': t.fmt(t.elapsed / run_times)[1]}
+ print(fmt % context)
+ return out
+
+ return wrapped
+
+ return wrapped_f
+
+
+if __name__ == "__main__":
+ import time
+
+ # 1
+ print(1)
+ with Timer() as t:
+ time.sleep(1)
+ print(t)
+ time.sleep(1)
+
+ with Timer(fmt='datetime') as t:
+ time.sleep(1)
+
+ # 2
+ print(2)
+ t = Timer(fmt='ms')
+ time.sleep(2)
+ print(t)
+
+ t = Timer(fmt='datetime')
+ time.sleep(1)
+ print(t)
+
+ # 3
+ print(3)
+
+
+ @timer(run_times=5, fmt='s')
+ def blah():
+ time.sleep(2)
+
+
+ blah()
diff --git a/models/CtrlHair/my_pylib/utils.py b/models/CtrlHair/my_pylib/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7e8580c1f06340729b1dc86a8a059ee96c90c83
--- /dev/null
+++ b/models/CtrlHair/my_pylib/utils.py
@@ -0,0 +1,19 @@
+import json
+import pprint
+
+import addict
+
+
+def save_json(path, obj, *args, **kw_args):
+ # wrap json.dumps
+ with open(path, 'w') as f:
+ f.write(json.dumps(obj, *args, **kw_args))
+
+
+def load_json(path, *args, **kw_args):
+ # wrap json.load
+ with open(path) as f:
+ return addict.Dict(json.load(f, *args, **kw_args))
+
+
+pp = pprint.pprint
diff --git a/models/CtrlHair/my_torchlib/__init__.py b/models/CtrlHair/my_torchlib/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff2ecaba7d8714a7f2ba626dc27ffb5ee8675404
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/__init__.py
@@ -0,0 +1,2 @@
+from .layers import *
+from .utils import *
diff --git a/models/CtrlHair/my_torchlib/layers/__init__.py b/models/CtrlHair/my_torchlib/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..69a388db1dea2d5699b716260dfa0902c27c0ab5
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/layers/__init__.py
@@ -0,0 +1 @@
+from .layers import *
diff --git a/models/CtrlHair/my_torchlib/layers/layers.py b/models/CtrlHair/my_torchlib/layers/layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b6a9a9ef98969866885281b76eaa1645cb43e5c
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/layers/layers.py
@@ -0,0 +1,33 @@
+from torch import nn
+
+
+# ==============================================================================
+# = layer =
+# ==============================================================================
+
+class NoOp(nn.Module):
+
+ def __init__(self, *args, **keyword_args):
+ super(NoOp, self).__init__()
+
+ def forward(self, x):
+ return x
+
+
+class Reshape(nn.Module): # 0表示保持当前大小
+
+ def __init__(self, *new_shape):
+ super(Reshape, self).__init__()
+ self._new_shape = new_shape
+
+ def forward(self, x):
+ new_shape = (x.size(i) if self._new_shape[i] == 0 else self._new_shape[i] for i in range(len(self._new_shape)))
+ return x.view(*new_shape)
+
+
+# ==============================================================================
+# = layer wrapper =
+# ==============================================================================
+
+def identity(x, *args, **keyword_args):
+ return x
diff --git a/models/CtrlHair/my_torchlib/module.py b/models/CtrlHair/my_torchlib/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a7787631eb1e62e75ec9851f6092149ac06550a
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/module.py
@@ -0,0 +1,283 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: module.py
+# Time : 2021/11/17 15:38
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch
+import torch.nn.functional as F
+
+from torch import nn
+
+
+class LinearBlock(nn.Module):
+
+ def __init__(self, input_dim, output_dim, norm, activation='relu', use_bias=True, leaky_slope=0.2, dropout=0):
+ super(LinearBlock, self).__init__()
+ # initialize fully connected layer
+ self.fc = nn.Linear(input_dim, output_dim, bias=use_bias)
+
+ # initialize normalization
+ norm_dim = output_dim
+ if norm == 'bn':
+ self.norm = nn.BatchNorm1d(norm_dim)
+ elif norm == 'in':
+ self.norm = nn.InstanceNorm1d(norm_dim)
+ elif norm == 'ln':
+ self.norm = nn.LayerNorm(norm_dim)
+ elif norm == 'none':
+ self.norm = None
+ else:
+ assert 0, "Unsupported normalization: {}".format(norm)
+
+ # initialize activation
+ if activation == 'relu':
+ self.activation = nn.ReLU(inplace=True)
+ elif activation == 'lrelu':
+ self.activation = nn.LeakyReLU(leaky_slope, inplace=True)
+ elif activation == 'prelu':
+ self.activation = nn.PReLU()
+ elif activation == 'selu':
+ self.activation = nn.SELU(inplace=True)
+ elif activation == 'tanh':
+ self.activation = nn.Tanh()
+ elif activation == 'none':
+ self.activation = None
+ else:
+ assert 0, "Unsupported activation: {}".format(activation)
+
+ self.dropout = dropout
+ if bool(self.dropout) and self.dropout > 0:
+ self.dropout_layer = nn.Dropout(p=self.dropout)
+
+ def forward(self, x):
+ out = self.fc(x)
+ if self.norm:
+ out = self.norm(out)
+ if self.activation:
+ out = self.activation(out)
+ if bool(self.dropout) and self.dropout > 0:
+ out = self.dropout_layer(out)
+ return out
+
+
+class Conv2dBlock(nn.Module):
+
+ def __init__(self, input_dim, output_dim, kernel_size, stride, padding=0, norm='none', activation='relu',
+ pad_type='zero', use_bias=True, norm_affine=False, transpose=False, leaky_slope=0.2):
+ super(Conv2dBlock, self).__init__()
+ # initialize padding
+ self.transpose = transpose
+
+ if not transpose:
+ if pad_type == 'reflect':
+ self.pad = nn.ReflectionPad2d(padding)
+ elif pad_type == 'replicate':
+ self.pad = nn.ReplicationPad2d(padding)
+ elif pad_type == 'zero':
+ self.pad = nn.ZeroPad2d(padding)
+ else:
+ assert 0, "Unsupported padding type: {}".format(pad_type)
+
+ # initialize convolution
+ if norm == 'sn':
+ self.conv = SpectralNorm(nn.Conv2d(input_dim, output_dim, kernel_size, stride, bias=use_bias))
+ elif transpose:
+ self.conv = nn.ConvTranspose2d(input_dim, output_dim, kernel_size, stride, padding, bias=use_bias)
+ else:
+ self.conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride, bias=use_bias)
+
+ # initialize normalization
+ norm_dim = output_dim
+ if norm == 'bn':
+ self.norm = nn.BatchNorm2d(norm_dim)
+ elif norm == 'in':
+ # self.norm = nn.InstanceNorm2d(norm_dim, track_running_stats=True)
+ self.norm = nn.InstanceNorm2d(norm_dim, norm_affine)
+ elif norm == 'myin':
+ self.norm = MyInstanceNorm2d(norm_dim)
+ elif norm == 'ln':
+ self.norm = LayerNorm(norm_dim)
+ elif norm == 'adain':
+ self.norm = AdaptiveInstanceNorm2d(norm_dim)
+ elif norm == 'none' or norm == 'sn':
+ self.norm = None
+ else:
+ assert 0, "Unsupported normalization: {}".format(norm)
+
+ # initialize activation
+ if activation == 'relu':
+ self.activation = nn.ReLU(inplace=True)
+ elif activation == 'lrelu':
+ self.activation = nn.LeakyReLU(leaky_slope, inplace=True)
+ elif activation == 'prelu':
+ self.activation = nn.PReLU()
+ elif activation == 'selu':
+ self.activation = nn.SELU(inplace=True)
+ elif activation == 'tanh':
+ self.activation = nn.Tanh()
+ elif activation == 'sigmoid':
+ self.activation = nn.Sigmoid()
+ elif activation == 'none':
+ self.activation = None
+ else:
+ assert 0, "Unsupported activation: {}".format(activation)
+
+ def forward(self, x):
+ if not self.transpose:
+ x = self.pad(x)
+ x = self.conv(x)
+ if self.norm:
+ x = self.norm(x)
+ if self.activation:
+ x = self.activation(x)
+ return x
+
+
+# ======================================
+# = normalization layers =
+# ======================================
+
+class AdaptiveInstanceNorm2d(nn.Module):
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1):
+ super(AdaptiveInstanceNorm2d, self).__init__()
+ self.num_features = num_features
+ self.eps = eps
+ self.momentum = momentum
+ # weight and bias are dynamically assigned
+ self.weight = None
+ self.bias = None
+ # just dummy buffers, not used
+ self.register_buffer('running_mean', torch.zeros(num_features))
+ self.register_buffer('running_var', torch.ones(num_features))
+
+ def forward(self, x):
+ assert self.weight is not None and self.bias is not None, "Please assign weight and bias before calling AdaIN!"
+ b, c = x.size(0), x.size(1)
+ running_mean = self.running_mean.repeat(b)
+ running_var = self.running_var.repeat(b)
+
+ # Apply instance norm
+ x_reshaped = x.contiguous().view(1, b * c, *x.size()[2:])
+
+ out = F.batch_norm(
+ x_reshaped, running_mean, running_var, self.weight, self.bias,
+ True, self.momentum, self.eps)
+
+ return out.view(b, c, *x.size()[2:])
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(' + str(self.num_features) + ')'
+
+
+class LayerNorm(nn.Module):
+
+ def __init__(self, num_features, eps=1e-5, affine=True):
+ super(LayerNorm, self).__init__()
+ self.num_features = num_features
+ self.affine = affine
+ self.eps = eps
+
+ if self.affine:
+ self.gamma = nn.Parameter(torch.Tensor(num_features).uniform_())
+ self.beta = nn.Parameter(torch.zeros(num_features))
+
+ def forward(self, x):
+ shape = [-1] + [1] * (x.dim() - 1)
+ # print(x.size())
+ if x.size(0) == 1:
+ # These two lines run much faster in pytorch 0.4 than the two lines listed below.
+ mean = x.view(-1).mean().view(*shape)
+ std = x.view(-1).std().view(*shape)
+ else:
+ mean = x.view(x.size(0), -1).mean(1).view(*shape)
+ std = x.view(x.size(0), -1).std(1).view(*shape)
+
+ x = (x - mean) / (std + self.eps)
+
+ if self.affine:
+ shape = [1, -1] + [1] * (x.dim() - 2)
+ x = x * self.gamma.view(*shape) + self.beta.view(*shape)
+ return x
+
+
+class MyInstanceNorm2d(nn.Module):
+
+ def __init__(self, num_features, eps=1e-5):
+ super(MyInstanceNorm2d, self).__init__()
+ self.num_features = num_features
+ self.eps = eps
+
+ def forward(self, x):
+ mean = x.view(x.size(0), x.size(1), -1).mean(2).view(x.size(0), x.size(1), 1, 1)
+ std = x.view(x.size(0), x.size(1), -1).std(2).view(x.size(0), x.size(1), 1, 1)
+ x = (x - mean) / (std + self.eps)
+ return x
+
+
+def l2normalize(v, eps=1e-12):
+ return v / (v.norm() + eps)
+
+
+class SpectralNorm(nn.Module):
+ """
+ Based on the paper "Spectral Normalization for Generative Adversarial Networks" by Takeru Miyato, Toshiki Kataoka, Masanori Koyama, Yuichi Yoshida
+ and the Pytorch implementation https://github.com/christiancosgrove/pytorch-spectral-normalization-gan
+ """
+
+ def __init__(self, module, name='weight', power_iterations=1):
+ super(SpectralNorm, self).__init__()
+ self.module = module
+ self.name = name
+ self.power_iterations = power_iterations
+ if not self._made_params():
+ self._make_params()
+
+ def _update_u_v(self):
+ u = getattr(self.module, self.name + "_u")
+ v = getattr(self.module, self.name + "_v")
+ w = getattr(self.module, self.name + "_bar")
+
+ height = w.data.shape[0]
+ for _ in range(self.power_iterations):
+ v.data = l2normalize(torch.mv(torch.t(w.view(height, -1).data), u.data))
+ u.data = l2normalize(torch.mv(w.view(height, -1).data, v.data))
+
+ # sigma = torch.dot(u.data, torch.mv(w.view(height,-1).data, v.data))
+ sigma = u.dot(w.view(height, -1).mv(v))
+ setattr(self.module, self.name, w / sigma.expand_as(w))
+
+ def _made_params(self):
+ try:
+ u = getattr(self.module, self.name + "_u")
+ v = getattr(self.module, self.name + "_v")
+ w = getattr(self.module, self.name + "_bar")
+ return True
+ except AttributeError:
+ return False
+
+ def _make_params(self):
+ w = getattr(self.module, self.name)
+
+ height = w.data.shape[0]
+ width = w.view(height, -1).data.shape[1]
+
+ u = nn.Parameter(w.data.new(height).normal_(0, 1), requires_grad=False)
+ v = nn.Parameter(w.data.new(width).normal_(0, 1), requires_grad=False)
+ u.data = l2normalize(u.data)
+ v.data = l2normalize(v.data)
+ w_bar = nn.Parameter(w.data)
+
+ del self.module._parameters[self.name]
+
+ self.module.register_parameter(self.name + "_u", u)
+ self.module.register_parameter(self.name + "_v", v)
+ self.module.register_parameter(self.name + "_bar", w_bar)
+
+ def forward(self, *args):
+ self._update_u_v()
+ return self.module.forward(*args)
diff --git a/models/CtrlHair/my_torchlib/train_utils.py b/models/CtrlHair/my_torchlib/train_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a9f6ee0dff505b9db942110423d34af2043b0ec
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/train_utils.py
@@ -0,0 +1,89 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: train_utils.py
+# Time : 2021/12/15 11:21
+# Author: xyguoo@163.com
+# Description:
+"""
+import numpy as np
+import torch
+from scipy import stats
+
+class LossUpdater:
+ def __init__(self, cfg):
+ self.cfg = cfg
+ self.register_list = {}
+ for ke in cfg:
+ if ke.startswith('lambda_') and isinstance(cfg[ke], dict):
+ self.register_list[ke] = cfg[ke]
+
+ def update(self, step):
+ for ke in self.register_list:
+ loss_dict = self.register_list[ke]
+ weight = None
+ for start_step in loss_dict:
+ if start_step > step:
+ break
+ weight = loss_dict[start_step]
+ if weight is None:
+ raise Exception()
+ self.cfg[ke] = weight
+
+
+def tensor2numpy(tensor):
+ return tensor.cpu().numpy().transpose(1, 2, 0)
+
+
+def to_device(dat, device):
+ for ke in dat:
+ if isinstance(dat[ke], torch.Tensor):
+ dat[ke] = dat[ke].to(device)
+
+
+def generate_noise(bs, dim, label=None):
+ # trunc = stats.truncnorm(-3, 3)
+ # noise = trunc.rvs(bs * dim).reshape(bs, dim)
+ # noise = torch.tensor(noise).float()
+ noise = torch.randn((bs, dim))
+ if label is not None:
+ noise = (noise.abs() * label).float()
+ return noise
+
+
+def train(cfg, loss_dict, optimizers, step, writer, flag, retain_graph=False, write_log=False):
+ """
+ :param loss_dict:
+ :param optimizers:
+ :param step:
+ :param writer:
+ :param flag:
+ :return:
+ """
+ if len(loss_dict) == 0:
+ return
+ loss_total = 0
+ for k, v in loss_dict.items():
+ if np.isnan(np.array(v.detach().cpu())):
+ print('!!!!!!!!! %s is nan' % k)
+ raise Exception()
+ if np.isinf(np.array(v.detach().cpu())):
+ print('!!!!!!!!! %s is inf' % k)
+ raise Exception()
+ if k not in cfg: # skip rgs_zp
+ continue
+ loss_total = loss_total + v * cfg[k]
+
+ for o in optimizers:
+ o.zero_grad()
+ loss_total.backward(retain_graph=retain_graph)
+ for o in optimizers:
+ o.step()
+
+ # summary
+ if write_log:
+ for k, v in loss_dict.items():
+ writer.add_scalar('%s/%s' % (flag, k), loss_dict[k].data.mean().cpu().numpy(),
+ global_step=step)
+ writer.add_scalar('%s/%s' % (flag, 'total'), loss_total.data.mean().cpu().numpy(),
+ global_step=step)
\ No newline at end of file
diff --git a/models/CtrlHair/my_torchlib/utils.py b/models/CtrlHair/my_torchlib/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..abb3cff17ebcc47fdcb68b36c42a7e1b71c60fe2
--- /dev/null
+++ b/models/CtrlHair/my_torchlib/utils.py
@@ -0,0 +1,85 @@
+import os
+import shutil
+import torch
+import torchvision.transforms as tform
+from PIL import Image
+
+
+def cpu(xs):
+ if not isinstance(xs, (list, tuple)):
+ return xs.cpu()
+ else:
+ return [x.cpu() for x in xs]
+
+
+def cuda(xs):
+ if torch.cuda.is_available():
+ if not isinstance(xs, (list, tuple)):
+ return xs.cuda()
+ else:
+ return [x.cuda() for x in xs]
+ else:
+ return xs
+
+
+def load_checkpoint(ckpt_dir_or_file, map_location=None, load_best=False):
+ if os.path.isdir(ckpt_dir_or_file):
+ if load_best:
+ ckpt_path = os.path.join(ckpt_dir_or_file, 'best_model.ckpt')
+ else:
+ with open(os.path.join(ckpt_dir_or_file, 'latest_checkpoint')) as f:
+ ckpt_path = os.path.join(ckpt_dir_or_file, f.readline()[:-1]) # -1去掉换行符
+ else:
+ ckpt_path = ckpt_dir_or_file
+ ckpt = torch.load(ckpt_path, map_location=map_location)
+ print(' [*] Loading checkpoint succeeds! Copy variables from % s!' % ckpt_path)
+ return ckpt
+
+
+def save_checkpoint(obj, save_path, is_best=False, max_keep=None):
+ # save checkpoint
+ torch.save(obj, save_path)
+
+ # deal with max_keep
+ save_dir = os.path.dirname(save_path)
+ list_path = os.path.join(save_dir, 'latest_checkpoint')
+
+ save_path = os.path.basename(save_path)
+ if os.path.exists(list_path):
+ with open(list_path) as f:
+ ckpt_list = f.readlines()
+ ckpt_list = [save_path + '\n'] + ckpt_list
+ else:
+ ckpt_list = [save_path + '\n']
+
+ if max_keep is not None:
+ for ckpt in ckpt_list[max_keep:]:
+ ckpt = os.path.join(save_dir, ckpt[:-1])
+ if os.path.exists(ckpt):
+ os.remove(ckpt)
+ ckpt_list[max_keep:] = []
+
+ with open(list_path, 'w') as f:
+ f.writelines(ckpt_list)
+
+ # copy best
+ if is_best:
+ shutil.copyfile(save_path, os.path.join(save_dir, 'best_model.ckpt'))
+
+
+def get_img_from_file(file_name, target_device, transform=False):
+ img = tform.ToTensor()(Image.open(file_name)) # [0, 1.0] tensor
+ if transform:
+ val_test_img_transform = tform.Compose([
+ # crop face area 190 * 178
+ # tform.Lambda(lambda x: x[:, 14:204, :]),
+ # center crop and resize on PLI image
+ tform.ToPILImage(),
+ tform.CenterCrop(170), # origin # elegant crop
+ # tform.CenterCrop(178),
+ tform.Resize(256, Image.BICUBIC), # elegant crop
+ # back to tensor
+ tform.ToTensor(),
+ ])
+ img = val_test_img_transform(img)
+ return (img * 2 - 1).to(target_device)
diff --git a/models/CtrlHair/poisson_blending.py b/models/CtrlHair/poisson_blending.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2bb103e218591d10e29776c5cff482af78aa9d3
--- /dev/null
+++ b/models/CtrlHair/poisson_blending.py
@@ -0,0 +1,87 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: poisson_blending.py
+# Time : 2021/11/5 15:22
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import numpy as np
+import scipy.sparse
+from scipy.sparse.linalg import spsolve
+
+
+def laplacian_matrix(n, m):
+ mat_D = scipy.sparse.lil_matrix((m, m))
+ mat_D.setdiag(-1, -1)
+ mat_D.setdiag(4)
+ mat_D.setdiag(-1, 1)
+
+ mat_A = scipy.sparse.block_diag([mat_D] * n).tolil()
+
+ mat_A.setdiag(-1, 1 * m)
+ mat_A.setdiag(-1, -1 * m)
+
+ return mat_A
+
+
+def poisson_blending(source, target, mask, with_gamma=True):
+ """
+ source: H * W * 3, cv2 image
+ target: H * W * 3, cv2 image
+ mask: H * W * 1
+ """
+ if with_gamma:
+ gamma_value = 2.2
+ else:
+ gamma_value = 1
+ source = source.astype('float')
+ target = target.astype('float')
+ source = np.power(source, 1 / gamma_value)
+ target = np.power(target, 1 / gamma_value)
+
+ res = target.copy()
+ y_range, x_range = source.shape[:2]
+ mat_A = laplacian_matrix(y_range, x_range)
+ laplacian = mat_A.tocsc()
+ mask[mask != 0] = 1
+
+ for y in range(1, y_range - 1):
+ for x in range(1, x_range - 1):
+ if mask[y, x] == 0:
+ k = x + y * x_range
+ mat_A[k, k] = 1
+ mat_A[k, k + 1] = 0
+ mat_A[k, k - 1] = 0
+ mat_A[k, k + x_range] = 0
+ mat_A[k, k - x_range] = 0
+ mat_A = mat_A.tocsc()
+
+ y_min, y_max = 0, y_range
+ x_min, x_max = 0, x_range
+
+ mask_flat = mask.flatten()
+ for channel in range(source.shape[2]):
+ source_flat = source[y_min:y_max, x_min:x_max, channel].flatten()
+ target_flat = target[y_min:y_max, x_min:x_max, channel].flatten()
+
+ # inside the mask:
+ # \Delta f = div v = \Delta g
+ alpha = 1
+ mat_b = laplacian.dot(source_flat) * alpha
+
+ # outside the mask:
+ # f = t
+ mat_b[mask_flat == 0] = target_flat[mask_flat == 0]
+
+ x = spsolve(mat_A, mat_b)
+ x = x.reshape((y_range, x_range))
+ res[:, :, channel] = x
+
+ res = np.power(res, gamma_value)
+
+ res[res > 255] = 255
+ res[res < 0] = 0
+ res = res.astype('uint8')
+ return res
diff --git a/models/CtrlHair/sean_codes/__init__.py b/models/CtrlHair/sean_codes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ee410e3c065678a2877bbb16cb2612c8c8a4c51
--- /dev/null
+++ b/models/CtrlHair/sean_codes/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py.py
+# Time : 2021/12/7 17:27
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/sean_codes/data/__init__.py b/models/CtrlHair/sean_codes/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7743f99330ba072b3a1773b7ba172c7c6540fb77
--- /dev/null
+++ b/models/CtrlHair/sean_codes/data/__init__.py
@@ -0,0 +1,55 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import importlib
+import torch.utils.data
+from .base_dataset import BaseDataset
+
+
+def find_dataset_using_name(dataset_name):
+ # Given the option --dataset [datasetname],
+ # the file "datasets/datasetname_dataset.py"
+ # will be imported.
+ dataset_filename = "sean_codes.data." + dataset_name + "_dataset"
+ datasetlib = importlib.import_module(dataset_filename)
+
+ # In the file, the class called DatasetNameDataset() will
+ # be instantiated. It has to be a subclass of BaseDataset,
+ # and it is case-insensitive.
+ dataset = None
+ target_dataset_name = dataset_name.replace('_', '') + 'dataset'
+ for name, cls in datasetlib.__dict__.items():
+ if name.lower() == target_dataset_name.lower() \
+ and issubclass(cls, BaseDataset):
+ dataset = cls
+
+ if dataset is None:
+ raise ValueError("In %s.py, there should be a subclass of BaseDataset "
+ "with class name that matches %s in lowercase." %
+ (dataset_filename, target_dataset_name))
+
+ return dataset
+
+
+def get_option_setter(dataset_name):
+ dataset_class = find_dataset_using_name(dataset_name)
+ return dataset_class.modify_commandline_options
+
+
+def create_dataloader(opt):
+ dataset = find_dataset_using_name(opt.dataset_mode)
+ instance = dataset()
+ instance.initialize(opt)
+ print("dataset [%s] of size %d was created" %
+ (type(instance).__name__, len(instance)))
+ dataloader = torch.utils.data.DataLoader(
+ instance,
+ batch_size=opt.batchSize,
+ shuffle=not opt.serial_batches,
+ num_workers=min(opt.batchSize, int(opt.nThreads)),
+ drop_last=opt.isTrain,
+ pin_memory=True
+ )
+ return dataloader
diff --git a/models/CtrlHair/sean_codes/data/base_dataset.py b/models/CtrlHair/sean_codes/data/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bb4b3cbf7d73e89eb53eeb14d8c5389a241fba2
--- /dev/null
+++ b/models/CtrlHair/sean_codes/data/base_dataset.py
@@ -0,0 +1,128 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch.utils.data as data
+from PIL import Image
+import torchvision.transforms as transforms
+import numpy as np
+import random
+
+
+class BaseDataset(data.Dataset):
+ def __init__(self):
+ super(BaseDataset, self).__init__()
+
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ return parser
+
+ def initialize(self, opt):
+ pass
+
+
+def get_params(opt, size):
+ w, h = size
+ new_h = h
+ new_w = w
+ if opt.preprocess_mode == 'resize_and_crop':
+ new_h = new_w = opt.load_size
+ elif opt.preprocess_mode == 'scale_width_and_crop':
+ new_w = opt.load_size
+ new_h = opt.load_size * h // w
+ elif opt.preprocess_mode == 'scale_shortside_and_crop':
+ ss, ls = min(w, h), max(w, h) # shortside and longside
+ width_is_shorter = w == ss
+ ls = int(opt.load_size * ls / ss)
+ new_w, new_h = (ss, ls) if width_is_shorter else (ls, ss)
+
+ x = random.randint(0, np.maximum(0, new_w - opt.crop_size))
+ y = random.randint(0, np.maximum(0, new_h - opt.crop_size))
+
+ flip = random.random() > 0.5
+ return {'crop_pos': (x, y), 'flip': flip}
+
+
+def get_transform(opt, params, method=Image.BICUBIC, normalize=True, toTensor=True):
+ transform_list = []
+ if 'resize' in opt.preprocess_mode:
+ osize = [opt.load_size, opt.load_size]
+ transform_list.append(transforms.Resize(osize, interpolation=method))
+ elif 'scale_width' in opt.preprocess_mode:
+ transform_list.append(transforms.Lambda(lambda img: __scale_width(img, opt.load_size, method)))
+ elif 'scale_shortside' in opt.preprocess_mode:
+ transform_list.append(transforms.Lambda(lambda img: __scale_shortside(img, opt.load_size, method)))
+
+ if 'crop' in opt.preprocess_mode:
+ transform_list.append(transforms.Lambda(lambda img: __crop(img, params['crop_pos'], opt.crop_size)))
+
+ if opt.preprocess_mode == 'none':
+ base = 32
+ transform_list.append(transforms.Lambda(lambda img: __make_power_2(img, base, method)))
+
+ if opt.preprocess_mode == 'fixed':
+ w = opt.crop_size
+ h = round(opt.crop_size / opt.aspect_ratio)
+ transform_list.append(transforms.Lambda(lambda img: __resize(img, w, h, method)))
+
+ if opt.isTrain and not opt.no_flip:
+ transform_list.append(transforms.Lambda(lambda img: __flip(img, params['flip'])))
+
+ if toTensor:
+ transform_list += [transforms.ToTensor()]
+
+ if normalize:
+ transform_list += [transforms.Normalize((0.5, 0.5, 0.5),
+ (0.5, 0.5, 0.5))]
+ return transforms.Compose(transform_list)
+
+
+def normalize():
+ return transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+
+
+def __resize(img, w, h, method=Image.BICUBIC):
+ return img.resize((w, h), method)
+
+
+def __make_power_2(img, base, method=Image.BICUBIC):
+ ow, oh = img.size
+ h = int(round(oh / base) * base)
+ w = int(round(ow / base) * base)
+ if (h == oh) and (w == ow):
+ return img
+ return img.resize((w, h), method)
+
+
+def __scale_width(img, target_width, method=Image.BICUBIC):
+ ow, oh = img.size
+ if (ow == target_width):
+ return img
+ w = target_width
+ h = int(target_width * oh / ow)
+ return img.resize((w, h), method)
+
+
+def __scale_shortside(img, target_width, method=Image.BICUBIC):
+ ow, oh = img.size
+ ss, ls = min(ow, oh), max(ow, oh) # shortside and longside
+ width_is_shorter = ow == ss
+ if (ss == target_width):
+ return img
+ ls = int(target_width * ls / ss)
+ nw, nh = (ss, ls) if width_is_shorter else (ls, ss)
+ return img.resize((nw, nh), method)
+
+
+def __crop(img, pos, size):
+ ow, oh = img.size
+ x1, y1 = pos
+ tw = th = size
+ return img.crop((x1, y1, x1 + tw, y1 + th))
+
+
+def __flip(img, flip):
+ if flip:
+ return img.transpose(Image.FLIP_LEFT_RIGHT)
+ return img
diff --git a/models/CtrlHair/sean_codes/data/custom_dataset.py b/models/CtrlHair/sean_codes/data/custom_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b0b4eca3d1dd647088a7060d1c4fcc1c1d10782
--- /dev/null
+++ b/models/CtrlHair/sean_codes/data/custom_dataset.py
@@ -0,0 +1,50 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+from .pix2pix_dataset import Pix2pixDataset
+from .image_folder import make_dataset
+
+
+class CustomDataset(Pix2pixDataset):
+ """ Dataset that loads images from directories
+ Use option --label_dir, --image_dir, --instance_dir to specify the directories.
+ The images in the directories are sorted in alphabetical order and paired in order.
+ """
+
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ parser = Pix2pixDataset.modify_commandline_options(parser, is_train)
+ parser.set_defaults(preprocess_mode='resize_and_crop')
+ load_size = 286 if is_train else 256
+ parser.set_defaults(load_size=load_size)
+ parser.set_defaults(crop_size=256)
+ parser.set_defaults(display_winsize=256)
+ parser.set_defaults(label_nc=19)
+ parser.set_defaults(contain_dontcare_label=False)
+
+ parser.add_argument('--label_dir', type=str, default='datasets/CelebA-HQ/test/labels',
+ help='path to the directory that contains label images')
+ parser.add_argument('--image_dir', type=str, default='datasets/CelebA-HQ/test/images',
+ help='path to the directory that contains photo images')
+ parser.add_argument('--instance_dir', type=str, default='',
+ help='path to the directory that contains instance maps. Leave black if not exists')
+ return parser
+
+ def get_paths(self, opt):
+ label_dir = opt.label_dir
+ label_paths = make_dataset(label_dir, recursive=False, read_cache=True)
+
+ image_dir = opt.image_dir
+ image_paths = make_dataset(image_dir, recursive=False, read_cache=True)
+
+ if len(opt.instance_dir) > 0:
+ instance_dir = opt.instance_dir
+ instance_paths = make_dataset(instance_dir, recursive=False, read_cache=True)
+ else:
+ instance_paths = []
+
+ assert len(label_paths) == len(image_paths), "The #images in %s and %s do not match. Is there something wrong?"
+
+ return label_paths, image_paths, instance_paths
diff --git a/models/CtrlHair/sean_codes/data/image_folder.py b/models/CtrlHair/sean_codes/data/image_folder.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd157935070526c823a831d4ad4e0b1970ccd14d
--- /dev/null
+++ b/models/CtrlHair/sean_codes/data/image_folder.py
@@ -0,0 +1,101 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+###############################################################################
+# Code from
+# https://github.com/pytorch/vision/blob/master/torchvision/datasets/folder.py
+# Modified the original code so that it also loads images from the current
+# directory as well as the subdirectories
+###############################################################################
+import torch.utils.data as data
+from PIL import Image
+import os
+
+IMG_EXTENSIONS = [
+ '.jpg', '.JPG', '.jpeg', '.JPEG',
+ '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tiff', '.webp'
+]
+
+
+def is_image_file(filename):
+ return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
+
+
+def make_dataset_rec(dir, images):
+ assert os.path.isdir(dir), '%s is not a valid directory' % dir
+
+ for root, dnames, fnames in sorted(os.walk(dir, followlinks=True)):
+ for fname in fnames:
+ if is_image_file(fname):
+ path = os.path.join(root, fname)
+ images.append(path)
+
+
+def make_dataset(dir, recursive=False, read_cache=False, write_cache=False):
+ """
+ xuyang: could get image path list
+ """
+ images = []
+
+ if read_cache:
+ possible_filelist = os.path.join(dir, 'files.list')
+ if os.path.isfile(possible_filelist):
+ with open(possible_filelist, 'r') as f:
+ images = f.read().splitlines()
+ return images
+
+ if recursive:
+ make_dataset_rec(dir, images)
+ else:
+ assert os.path.isdir(dir) or os.path.islink(dir), '%s is not a valid directory' % dir
+
+ for root, dnames, fnames in sorted(os.walk(dir)):
+ for fname in fnames:
+ if is_image_file(fname):
+ path = os.path.join(root, fname)
+ images.append(path)
+
+ if write_cache:
+ filelist_cache = os.path.join(dir, 'files.list')
+ with open(filelist_cache, 'w') as f:
+ for path in images:
+ f.write("%s\n" % path)
+ print('wrote filelist cache at %s' % filelist_cache)
+
+ return images
+
+
+def default_loader(path):
+ return Image.open(path).convert('RGB')
+
+
+class ImageFolder(data.Dataset):
+
+ def __init__(self, root, transform=None, return_paths=False,
+ loader=default_loader):
+ imgs = make_dataset(root)
+ if len(imgs) == 0:
+ raise(RuntimeError("Found 0 images in: " + root + "\n"
+ "Supported image extensions are: " +
+ ",".join(IMG_EXTENSIONS)))
+
+ self.root = root
+ self.imgs = imgs
+ self.transform = transform
+ self.return_paths = return_paths
+ self.loader = loader
+
+ def __getitem__(self, index):
+ path = self.imgs[index]
+ img = self.loader(path)
+ if self.transform is not None:
+ img = self.transform(img)
+ if self.return_paths:
+ return img, path
+ else:
+ return img
+
+ def __len__(self):
+ return len(self.imgs)
diff --git a/models/CtrlHair/sean_codes/data/pix2pix_dataset.py b/models/CtrlHair/sean_codes/data/pix2pix_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..7001596886d4f06554d926958f6de6ffe25155af
--- /dev/null
+++ b/models/CtrlHair/sean_codes/data/pix2pix_dataset.py
@@ -0,0 +1,139 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+from .base_dataset import BaseDataset, get_params, get_transform
+from PIL import Image
+import util.util as util
+import os
+import torch
+
+
+class Pix2pixDataset(BaseDataset):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ parser.add_argument('--no_pairing_check', action='store_true',
+ help='If specified, skip sanity check of correct label-image file pairing')
+ return parser
+
+ def initialize(self, opt):
+ self.opt = opt
+
+ label_paths, image_paths, instance_paths = self.get_paths(opt)
+
+ util.natural_sort(label_paths)
+ util.natural_sort(image_paths)
+ if not opt.no_instance:
+ util.natural_sort(instance_paths)
+
+ label_paths = label_paths[:opt.max_dataset_size]
+ image_paths = image_paths[:opt.max_dataset_size]
+ instance_paths = instance_paths[:opt.max_dataset_size]
+
+ if not opt.no_pairing_check:
+ for path1, path2 in zip(label_paths, image_paths):
+ assert self.paths_match(path1, path2), \
+ "The label-image pair (%s, %s) do not look like the right pair because the filenames are quite different. Are you sure about the pairing? Please see data/pix2pix_dataset.py to see what is going on, and use --no_pairing_check to bypass this." % (
+ path1, path2)
+
+ self.label_paths = label_paths
+ self.image_paths = image_paths
+ self.instance_paths = instance_paths
+
+ size = len(self.label_paths)
+ self.dataset_size = size
+
+ def get_paths(self, opt):
+ label_paths = []
+ image_paths = []
+ instance_paths = []
+ assert False, "A subclass of Pix2pixDataset must override self.get_paths(self, opt)"
+ return label_paths, image_paths, instance_paths
+
+ def paths_match(self, path1, path2):
+ filename1_without_ext = os.path.splitext(os.path.basename(path1))[0]
+ filename2_without_ext = os.path.splitext(os.path.basename(path2))[0]
+ return filename1_without_ext == filename2_without_ext
+
+ def __getitem__(self, index):
+ # Label Image
+ label_path = self.label_paths[index]
+ label = Image.open(label_path)
+ params = get_params(self.opt, label.size)
+ transform_label = get_transform(self.opt, params, method=Image.NEAREST, normalize=False)
+ label_tensor = transform_label(label) * 255.0
+ label_tensor[label_tensor == 255] = self.opt.label_nc # 'unknown' is opt.label_nc
+
+ # input image (real images)
+ image_path = self.image_paths[index]
+ assert self.paths_match(label_path, image_path), \
+ "The label_path %s and image_path %s don't match." % \
+ (label_path, image_path)
+ image = Image.open(image_path)
+ image = image.convert('RGB')
+
+ transform_image = get_transform(self.opt, params)
+ image_tensor = transform_image(image)
+
+ # if using instance maps
+ if self.opt.no_instance:
+ instance_tensor = 0
+ else:
+ instance_path = self.instance_paths[index]
+ instance = Image.open(instance_path)
+ if instance.mode == 'L':
+ instance_tensor = transform_label(instance) * 255
+ instance_tensor = instance_tensor.long()
+ else:
+ instance_tensor = transform_label(instance)
+
+ input_dict = {'label': label_tensor,
+ 'instance': instance_tensor,
+ 'image': image_tensor,
+ 'path': image_path,
+ }
+
+ # Give subclasses a chance to modify the final color_texture
+
+ self.postprocess(input_dict)
+
+ return input_dict
+
+ def postprocess(self, input_dict):
+ return input_dict
+
+ def __len__(self):
+ return self.dataset_size
+
+ # Our codes get input images and labels
+ def get_input_by_names(self, image_path, image, label_img):
+ label = Image.fromarray(label_img)
+ params = get_params(self.opt, label.size)
+ transform_label = get_transform(self.opt, params, method=Image.NEAREST, normalize=False)
+ label_tensor = transform_label(label) * 255.0
+ label_tensor[label_tensor == 255] = self.opt.label_nc # 'unknown' is opt.label_nc
+ label_tensor.unsqueeze_(0)
+
+ # input image (real images)]
+ # image = Image.open(image_path)
+ # image = image.convert('RGB')
+
+ transform_image = get_transform(self.opt, params)
+ image_tensor = transform_image(image)
+ image_tensor.unsqueeze_(0)
+
+ # if using instance maps
+ if self.opt.no_instance:
+ instance_tensor = torch.Tensor([0])
+
+ input_dict = {'label': label_tensor,
+ 'instance': instance_tensor,
+ 'image': image_tensor,
+ 'path': image_path,
+ }
+
+ # Give subclasses a chance to modify the final color_texture
+ self.postprocess(input_dict)
+
+ return input_dict
diff --git a/models/CtrlHair/sean_codes/get_mean_code.py b/models/CtrlHair/sean_codes/get_mean_code.py
new file mode 100644
index 0000000000000000000000000000000000000000..31f5dae9633b5aa20a42722113878f7b16c06990
--- /dev/null
+++ b/models/CtrlHair/sean_codes/get_mean_code.py
@@ -0,0 +1,45 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: get_mean_code.py
+# Time : 2022/2/22 17:22
+# Author: xyguoo@163.com
+# Description:
+"""
+
+from glob import glob
+
+import numpy as np
+import os
+
+layers_list = ['ACE.npy']
+
+style_list = []
+
+for cat_i in range(19):
+ for layer_j in layers_list:
+ tmp_list = glob('styles_test/style_codes/*/' + str(cat_i) + '/' + layer_j)
+ style_list = []
+
+ for k in tmp_list:
+ style_list.append(np.load(k))
+
+ if len(style_list) > 0:
+ style_list = np.array(style_list)
+
+ style_list_norm2 = np.linalg.norm(style_list, axis=1, keepdims=True) ** 2
+ dist_matrix = (style_list_norm2 + style_list_norm2.T -2 * style_list @ style_list.T)
+ dist_matrix[dist_matrix < 0] = 0
+ dist_matrix = dist_matrix ** 0.5
+ median_idx = dist_matrix.sum(axis=1).argmin()
+ feature = style_list[median_idx]
+
+ save_folder = os.path.join('styles_test/mean_style_code/median', str(cat_i))
+
+ if not os.path.exists(save_folder):
+ os.makedirs(save_folder)
+
+ save_name = os.path.join(save_folder, layer_j)
+ np.save(save_name, feature)
+
+print(100)
diff --git a/models/CtrlHair/sean_codes/models/__init__.py b/models/CtrlHair/sean_codes/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..810d272b2e64dbeb6c7b941221dba59d1a62df8a
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/__init__.py
@@ -0,0 +1,44 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import importlib
+import torch
+
+
+def find_model_using_name(model_name):
+ # Given the option --model [modelname],
+ # the file "models/modelname_model.py"
+ # will be imported.
+ model_filename = "sean_codes.models." + model_name + "_model"
+ modellib = importlib.import_module(model_filename)
+
+ # In the file, the class called ModelNameModel() will
+ # be instantiated. It has to be a subclass of torch.nn.Module,
+ # and it is case-insensitive.
+ model = None
+ target_model_name = model_name.replace('_', '') + 'model'
+ for name, cls in modellib.__dict__.items():
+ if name.lower() == target_model_name.lower() \
+ and issubclass(cls, torch.nn.Module):
+ model = cls
+
+ if model is None:
+ print("In %s.py, there should be a subclass of torch.nn.Module with class name that matches %s in lowercase." % (model_filename, target_model_name))
+ exit(0)
+
+ return model
+
+
+def get_option_setter(model_name):
+ model_class = find_model_using_name(model_name)
+ return model_class.modify_commandline_options
+
+
+def create_model(opt):
+ model = find_model_using_name(opt.sean_model)
+ instance = model(opt)
+ print("model [%s] was created" % (type(instance).__name__))
+
+ return instance
diff --git a/models/CtrlHair/sean_codes/models/networks/__init__.py b/models/CtrlHair/sean_codes/models/networks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0073164257fccadb1eaac9a67404df473241b7f1
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/__init__.py
@@ -0,0 +1,62 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+from .base_network import BaseNetwork
+from .loss import *
+# from sean_codes.models.networks import *
+from . import *
+from .encoder import *
+import util.util as util
+
+
+def find_network_using_name(target_network_name, filename):
+ target_class_name = target_network_name + filename
+ module_name = 'sean_codes.models.networks.' + filename
+ network = util.find_class_in_module(target_class_name, module_name)
+
+ assert issubclass(network, BaseNetwork), \
+ "Class %s should be a subclass of BaseNetwork" % network
+
+ return network
+
+
+def modify_commandline_options(parser, is_train):
+ opt, _ = parser.parse_known_args()
+
+ netG_cls = find_network_using_name(opt.netG, 'generator')
+ parser = netG_cls.modify_commandline_options(parser, is_train)
+ if is_train:
+ netD_cls = find_network_using_name(opt.netD, 'discriminator')
+ parser = netD_cls.modify_commandline_options(parser, is_train)
+ netE_cls = find_network_using_name('conv', 'encoder')
+ parser = netE_cls.modify_commandline_options(parser, is_train)
+
+ return parser
+
+
+def create_network(cls, opt):
+ net = cls(opt)
+ net.print_network()
+ if len(opt.gpu_ids) > 0:
+ assert(torch.cuda.is_available())
+ net.cuda()
+ net.init_weights(opt.init_type, opt.init_variance)
+ return net
+
+
+def define_G(opt):
+ netG_cls = find_network_using_name(opt.netG, 'generator')
+ return create_network(netG_cls, opt)
+
+
+def define_D(opt):
+ netD_cls = find_network_using_name(opt.netD, 'discriminator')
+ return create_network(netD_cls, opt)
+
+
+def define_E(opt):
+ # there exists only one encoder type
+ netE_cls = find_network_using_name('conv', 'encoder')
+ return create_network(netE_cls, opt)
diff --git a/models/CtrlHair/sean_codes/models/networks/architecture.py b/models/CtrlHair/sean_codes/models/networks/architecture.py
new file mode 100644
index 0000000000000000000000000000000000000000..75f713905dfd3d7b3e57903ea358382545a9be7c
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/architecture.py
@@ -0,0 +1,207 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision
+import torch.nn.utils.spectral_norm as spectral_norm
+from sean_codes.models.networks.normalization import ACE
+
+
+# ResNet block that uses SPADE.
+# It differs from the ResNet block of pix2pixHD in that
+# it takes in the segmentation map as input, learns the skip connection if necessary,
+# and applies normalization first and then convolution.
+# This architecture seemed like a standard architecture for unconditional or
+# class-conditional GAN architecture using residual block.
+# The code was inspired from https://github.com/LMescheder/GAN_stability.
+class SPADEResnetBlock(nn.Module):
+ def __init__(self, fin, fout, opt, Block_Name=None, use_rgb=True):
+ super().__init__()
+
+ self.use_rgb = use_rgb
+
+ self.Block_Name = Block_Name
+ self.status = opt.status
+
+ # Attributes
+ self.learned_shortcut = (fin != fout)
+ fmiddle = min(fin, fout)
+
+ # create conv layers
+ self.conv_0 = nn.Conv2d(fin, fmiddle, kernel_size=3, padding=1)
+ self.conv_1 = nn.Conv2d(fmiddle, fout, kernel_size=3, padding=1)
+ if self.learned_shortcut:
+ self.conv_s = nn.Conv2d(fin, fout, kernel_size=1, bias=False)
+
+ # apply spectral norm if specified
+ if 'spectral' in opt.norm_G:
+ self.conv_0 = spectral_norm(self.conv_0)
+ self.conv_1 = spectral_norm(self.conv_1)
+ if self.learned_shortcut:
+ self.conv_s = spectral_norm(self.conv_s)
+
+ # define normalization layers
+ spade_config_str = opt.norm_G.replace('spectral', '')
+
+ ########### Modifications 1
+ normtype_list = ['spadeinstance3x3', 'spadesyncbatch3x3', 'spadebatch3x3']
+ our_norm_type = 'spadesyncbatch3x3'
+
+ self.ace_0 = ACE(our_norm_type, fin, 3, ACE_Name=Block_Name + '_ACE_0', status=self.status,
+ spade_params=[spade_config_str, fin, opt.semantic_nc], use_rgb=use_rgb)
+ ########### Modifications 1
+
+ ########### Modifications 1
+ self.ace_1 = ACE(our_norm_type, fmiddle, 3, ACE_Name=Block_Name + '_ACE_1', status=self.status,
+ spade_params=[spade_config_str, fmiddle, opt.semantic_nc], use_rgb=use_rgb)
+ ########### Modifications 1
+
+ if self.learned_shortcut:
+ self.ace_s = ACE(our_norm_type, fin, 3, ACE_Name=Block_Name + '_ACE_s', status=self.status,
+ spade_params=[spade_config_str, fin, opt.semantic_nc], use_rgb=use_rgb)
+
+ # note the resnet block with SPADE also takes in |seg|,
+ # the semantic segmentation map as input
+ def forward(self, x, seg, style_codes, obj_dic=None):
+
+ x_s = self.shortcut(x, seg, style_codes, obj_dic)
+
+ ########### Modifications 1
+ dx = self.ace_0(x, seg, style_codes, obj_dic)
+
+ dx = self.conv_0(self.actvn(dx))
+
+ dx = self.ace_1(dx, seg, style_codes, obj_dic)
+
+ dx = self.conv_1(self.actvn(dx))
+ ########### Modifications 1
+
+ out = x_s + dx
+ return out
+
+ def shortcut(self, x, seg, style_codes, obj_dic):
+ if self.learned_shortcut:
+ x_s = self.ace_s(x, seg, style_codes, obj_dic)
+ x_s = self.conv_s(x_s)
+
+ else:
+ x_s = x
+ return x_s
+
+ def actvn(self, x):
+ return F.leaky_relu(x, 2e-1)
+
+
+# ResNet block used in pix2pixHD
+# We keep the same architecture as pix2pixHD.
+class ResnetBlock(nn.Module):
+ def __init__(self, dim, norm_layer, activation=nn.ReLU(False), kernel_size=3):
+ super().__init__()
+
+ pw = (kernel_size - 1) // 2
+ self.conv_block = nn.Sequential(
+ nn.ReflectionPad2d(pw),
+ norm_layer(nn.Conv2d(dim, dim, kernel_size=kernel_size)),
+ activation,
+ nn.ReflectionPad2d(pw),
+ norm_layer(nn.Conv2d(dim, dim, kernel_size=kernel_size))
+ )
+
+ def forward(self, x):
+ y = self.conv_block(x)
+ out = x + y
+ return out
+
+
+# VGG architecter, used for the perceptual loss using a pretrained VGG network
+class VGG19(torch.nn.Module):
+ def __init__(self, requires_grad=False):
+ super().__init__()
+ vgg_pretrained_features = torchvision.models.vgg19(pretrained=True).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ for x in range(2):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(2, 7):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(7, 12):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(12, 21):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(21, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h_relu1 = self.slice1(X)
+ h_relu2 = self.slice2(h_relu1)
+ h_relu3 = self.slice3(h_relu2)
+ h_relu4 = self.slice4(h_relu3)
+ h_relu5 = self.slice5(h_relu4)
+ out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
+ return out
+
+
+class Zencoder(torch.nn.Module):
+ def __init__(self, input_nc, output_nc, ngf=32, n_downsampling=2, norm_layer=nn.InstanceNorm2d):
+ super(Zencoder, self).__init__()
+ self.output_nc = output_nc
+
+ model = [nn.ReflectionPad2d(1), nn.Conv2d(input_nc, ngf, kernel_size=3, padding=0),
+ norm_layer(ngf), nn.LeakyReLU(0.2, False)]
+ ### downsample
+ for i in range(n_downsampling):
+ mult = 2 ** i
+ model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1),
+ norm_layer(ngf * mult * 2), nn.LeakyReLU(0.2, False)]
+
+ ### upsample
+ for i in range(1):
+ mult = 2 ** (n_downsampling - i)
+ model += [
+ nn.ConvTranspose2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, output_padding=1),
+ norm_layer(int(ngf * mult / 2)), nn.LeakyReLU(0.2, False)]
+
+ model += [nn.ReflectionPad2d(1), nn.Conv2d(256, output_nc, kernel_size=3, padding=0), nn.Tanh()]
+ self.model = nn.Sequential(*model)
+
+ def forward(self, input, segmap):
+
+ codes = self.model(input)
+ # codes shape: [N, 512, 128, 128]
+ segmap = F.interpolate(segmap, size=codes.size()[2:], mode='nearest')
+ # segmap shape: [N, 19, 128, 128]
+ # print(segmap.shape)
+ # print(codes.shape)
+
+ b_size = codes.shape[0]
+ # h_size = codes.shape[2]
+ # w_size = codes.shape[3]
+ f_size = codes.shape[1]
+
+ s_size = segmap.shape[1]
+
+ codes_vector = torch.zeros((b_size, s_size, f_size), dtype=codes.dtype, device=codes.device)
+
+ for i in range(b_size):
+ for j in range(s_size):
+ component_mask_area = torch.sum(segmap.bool()[i, j])
+
+ if component_mask_area > 0:
+ codes_component_feature = codes[i].masked_select(segmap.bool()[i, j]).reshape(f_size,
+ component_mask_area).mean(
+ 1)
+ codes_vector[i][j] = codes_component_feature
+
+ # codes_avg[i].masked_scatter_(segmap.bool()[i, j], codes_component_mu)
+
+ return codes_vector
diff --git a/models/CtrlHair/sean_codes/models/networks/base_network.py b/models/CtrlHair/sean_codes/models/networks/base_network.py
new file mode 100644
index 0000000000000000000000000000000000000000..f79189f3c4c9b0032ea5e8ec28c8915a9112a754
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/base_network.py
@@ -0,0 +1,59 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch.nn as nn
+from torch.nn import init
+
+
+class BaseNetwork(nn.Module):
+ def __init__(self):
+ super(BaseNetwork, self).__init__()
+
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ return parser
+
+ def print_network(self):
+ if isinstance(self, list):
+ self = self[0]
+ num_params = 0
+ for param in self.parameters():
+ num_params += param.numel()
+ print('Network [%s] was created. Total number of parameters: %.1f million. '
+ 'To see the architecture, do print(network).'
+ % (type(self).__name__, num_params / 1000000))
+
+ def init_weights(self, init_type='normal', gain=0.02):
+ def init_func(m):
+ classname = m.__class__.__name__
+ if classname.find('BatchNorm2d') != -1:
+ if hasattr(m, 'weight') and m.weight is not None:
+ init.normal_(m.weight.data, 1.0, gain)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+ elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0.0, gain)
+ elif init_type == 'xavier':
+ init.xavier_normal_(m.weight.data, gain=gain)
+ elif init_type == 'xavier_uniform':
+ init.xavier_uniform_(m.weight.data, gain=1.0)
+ elif init_type == 'kaiming':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=gain)
+ elif init_type == 'none': # uses pytorch's default init method
+ m.reset_parameters()
+ else:
+ raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+
+ self.apply(init_func)
+
+ # propagate to children
+ for m in self.children():
+ if hasattr(m, 'init_weights'):
+ m.init_weights(init_type, gain)
diff --git a/models/CtrlHair/sean_codes/models/networks/discriminator.py b/models/CtrlHair/sean_codes/models/networks/discriminator.py
new file mode 100644
index 0000000000000000000000000000000000000000..215f1bfae07d95d74c9c40799988e3ab5124c0bf
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/discriminator.py
@@ -0,0 +1,119 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch.nn as nn
+import numpy as np
+import torch.nn.functional as F
+from sean_codes.models.networks.base_network import BaseNetwork
+from sean_codes.models.networks.normalization import get_nonspade_norm_layer
+import util.util as util
+
+
+class MultiscaleDiscriminator(BaseNetwork):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ parser.add_argument('--netD_subarch', type=str, default='n_layer',
+ help='architecture of each discriminator')
+ parser.add_argument('--num_D', type=int, default=2,
+ help='number of discriminators to be used in multiscale')
+ opt, _ = parser.parse_known_args()
+
+ # define properties of each discriminator of the multiscale discriminator
+ subnetD = util.find_class_in_module(opt.netD_subarch + 'discriminator',
+ 'models.networks.discriminator')
+ subnetD.modify_commandline_options(parser, is_train)
+
+ return parser
+
+ def __init__(self, opt):
+ super().__init__()
+ self.opt = opt
+
+ for i in range(opt.num_D):
+ subnetD = self.create_single_discriminator(opt)
+ self.add_module('discriminator_%d' % i, subnetD)
+
+ def create_single_discriminator(self, opt):
+ subarch = opt.netD_subarch
+ if subarch == 'n_layer':
+ netD = NLayerDiscriminator(opt)
+ else:
+ raise ValueError('unrecognized discriminator subarchitecture %s' % subarch)
+ return netD
+
+ def downsample(self, input):
+ return F.avg_pool2d(input, kernel_size=3,
+ stride=2, padding=[1, 1],
+ count_include_pad=False)
+
+ # Returns list of lists of discriminator outputs.
+ # The final result is of size opt.num_D x opt.n_layers_D
+ def forward(self, input):
+ result = []
+ get_intermediate_features = not self.opt.no_ganFeat_loss
+ for name, D in self.named_children():
+ out = D(input)
+ if not get_intermediate_features:
+ out = [out]
+ result.append(out)
+ input = self.downsample(input)
+
+ return result
+
+
+# Defines the PatchGAN discriminator with the specified arguments.
+class NLayerDiscriminator(BaseNetwork):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ parser.add_argument('--n_layers_D', type=int, default=3,
+ help='# layers in each discriminator')
+ return parser
+
+ def __init__(self, opt):
+ super().__init__()
+ self.opt = opt
+
+ kw = 4
+ padw = int(np.ceil((kw - 1.0) / 2))
+ nf = opt.ndf
+ input_nc = self.compute_D_input_nc(opt)
+
+ norm_layer = get_nonspade_norm_layer(opt, opt.norm_D)
+ sequence = [[nn.Conv2d(input_nc, nf, kernel_size=kw, stride=2, padding=padw),
+ nn.LeakyReLU(0.2, False)]]
+
+ for n in range(1, opt.n_layers_D):
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ sequence += [[norm_layer(nn.Conv2d(nf_prev, nf, kernel_size=kw,
+ stride=2, padding=padw)),
+ nn.LeakyReLU(0.2, False)
+ ]]
+
+ sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
+
+ # We divide the layers into groups to extract intermediate layer outputs
+ for n in range(len(sequence)):
+ self.add_module('model' + str(n), nn.Sequential(*sequence[n]))
+
+ def compute_D_input_nc(self, opt):
+ input_nc = opt.label_nc + opt.output_nc
+ if opt.contain_dontcare_label:
+ input_nc += 1
+ if not opt.no_instance:
+ input_nc += 1
+ return input_nc
+
+ def forward(self, input):
+ results = [input]
+ for submodel in self.children():
+ intermediate_output = submodel(results[-1])
+ results.append(intermediate_output)
+
+ get_intermediate_features = not self.opt.no_ganFeat_loss
+ if get_intermediate_features:
+ return results[1:]
+ else:
+ return results[-1]
diff --git a/models/CtrlHair/sean_codes/models/networks/encoder.py b/models/CtrlHair/sean_codes/models/networks/encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..81d9bd542b2170588649b3fa6b6c76014b1ebbfc
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/encoder.py
@@ -0,0 +1,55 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch.nn as nn
+import numpy as np
+import torch.nn.functional as F
+from sean_codes.models.networks.base_network import BaseNetwork
+from sean_codes.models.networks.normalization import get_nonspade_norm_layer
+
+
+class ConvEncoder(BaseNetwork):
+ """ Same architecture as the image discriminator """
+
+ def __init__(self, opt):
+ super().__init__()
+
+ kw = 3
+ pw = int(np.ceil((kw - 1.0) / 2))
+ ndf = opt.ngf
+ norm_layer = get_nonspade_norm_layer(opt, opt.norm_E)
+ self.layer1 = norm_layer(nn.Conv2d(3, ndf, kw, stride=2, padding=pw))
+ self.layer2 = norm_layer(nn.Conv2d(ndf * 1, ndf * 2, kw, stride=2, padding=pw))
+ self.layer3 = norm_layer(nn.Conv2d(ndf * 2, ndf * 4, kw, stride=2, padding=pw))
+ self.layer4 = norm_layer(nn.Conv2d(ndf * 4, ndf * 8, kw, stride=2, padding=pw))
+ self.layer5 = norm_layer(nn.Conv2d(ndf * 8, ndf * 8, kw, stride=2, padding=pw))
+ if opt.crop_size >= 256:
+ self.layer6 = norm_layer(nn.Conv2d(ndf * 8, ndf * 8, kw, stride=2, padding=pw))
+
+ self.so = s0 = 4
+ self.fc_mu = nn.Linear(ndf * 8 * s0 * s0, 256)
+ self.fc_var = nn.Linear(ndf * 8 * s0 * s0, 256)
+
+ self.actvn = nn.LeakyReLU(0.2, False)
+ self.opt = opt
+
+ def forward(self, x):
+ if x.size(2) != 256 or x.size(3) != 256:
+ x = F.interpolate(x, size=(256, 256), mode='bilinear')
+
+ x = self.layer1(x)
+ x = self.layer2(self.actvn(x))
+ x = self.layer3(self.actvn(x))
+ x = self.layer4(self.actvn(x))
+ x = self.layer5(self.actvn(x))
+ if self.opt.crop_size >= 256:
+ x = self.layer6(self.actvn(x))
+ x = self.actvn(x)
+
+ x = x.view(x.size(0), -1)
+ mu = self.fc_mu(x)
+ logvar = self.fc_var(x)
+
+ return mu, logvar
diff --git a/models/CtrlHair/sean_codes/models/networks/generator.py b/models/CtrlHair/sean_codes/models/networks/generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..4600e6e15d352f183537756d737e6aac221de503
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/generator.py
@@ -0,0 +1,172 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch.nn as nn
+import torch.nn.functional as F
+from .base_network import BaseNetwork
+from .architecture import SPADEResnetBlock as SPADEResnetBlock
+from .architecture import Zencoder
+import torch
+
+
+class SPADEGenerator(BaseNetwork):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ parser.set_defaults(norm_G='spectralspadesyncbatch3x3')
+ parser.add_argument('--num_upsampling_layers',
+ choices=('normal', 'more', 'most'), default='normal',
+ help="If 'more', adds upsampling layer between the two middle resnet blocks. If 'most', also add one more upsampling + resnet layer at the end of the generator")
+
+ return parser
+
+ def __init__(self, opt):
+ super().__init__()
+ self.opt = opt
+ nf = opt.ngf
+
+ self.sw, self.sh = self.compute_latent_vector_size(opt)
+
+ self.Zencoder = Zencoder(3, 512)
+
+ self.fc = nn.Conv2d(self.opt.semantic_nc, 16 * nf, 3, padding=1)
+
+ self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt, Block_Name='head_0')
+
+ self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt, Block_Name='G_middle_0')
+ self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt, Block_Name='G_middle_1')
+
+ self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt, Block_Name='up_0')
+ self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt, Block_Name='up_1')
+ self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt, Block_Name='up_2')
+ self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt, Block_Name='up_3', use_rgb=False)
+
+ final_nc = nf
+
+ if opt.num_upsampling_layers == 'most':
+ self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt, Block_Name='up_4')
+ final_nc = nf // 2
+
+ self.conv_img = nn.Conv2d(final_nc, 3, 3, padding=1)
+
+ self.up = nn.Upsample(scale_factor=2)
+ # self.up = nn.Upsample(scale_factor=2, mode='bilinear')
+
+ def compute_latent_vector_size(self, opt):
+ if opt.num_upsampling_layers == 'normal':
+ num_up_layers = 5
+ elif opt.num_upsampling_layers == 'more':
+ num_up_layers = 6
+ elif opt.num_upsampling_layers == 'most':
+ num_up_layers = 7
+ else:
+ raise ValueError('opt.num_upsampling_layers [%s] not recognized' %
+ opt.num_upsampling_layers)
+
+ sw = opt.crop_size // (2 ** num_up_layers)
+ sh = round(sw / opt.aspect_ratio)
+
+ return sw, sh
+
+ def forward(self, input, rgb_img, obj_dic=None):
+ seg = input
+
+ x = F.interpolate(seg, size=(self.sh, self.sw))
+ x = self.fc(x)
+
+ if rgb_img is None:
+ style_codes = None
+ else:
+ style_codes = self.Zencoder(input=rgb_img, segmap=seg)
+
+ x = self.head_0(x, seg, style_codes, obj_dic=obj_dic)
+
+ x = self.up(x)
+ x = self.G_middle_0(x, seg, style_codes, obj_dic=obj_dic)
+
+ if self.opt.num_upsampling_layers == 'more' or \
+ self.opt.num_upsampling_layers == 'most':
+ x = self.up(x)
+
+ x = self.G_middle_1(x, seg, style_codes, obj_dic=obj_dic)
+
+ x = self.up(x)
+ x = self.up_0(x, seg, style_codes, obj_dic=obj_dic)
+ x = self.up(x)
+ x = self.up_1(x, seg, style_codes, obj_dic=obj_dic)
+ x = self.up(x)
+ x = self.up_2(x, seg, style_codes, obj_dic=obj_dic)
+ x = self.up(x)
+ x = self.up_3(x, seg, style_codes, obj_dic=obj_dic)
+
+ # if self.opt.num_upsampling_layers == 'most':
+ # x = self.up(x)
+ # x= self.up_4(x, seg, style_codes, obj_dic=obj_dic)
+
+ x = self.conv_img(F.leaky_relu(x, 2e-1))
+ x = torch.tanh(x)
+ return x
+
+# class Pix2PixHDGenerator(BaseNetwork):
+# @staticmethod
+# def modify_commandline_options(parser, is_train):
+# parser.add_argument('--resnet_n_downsample', type=int, default=4, help='number of downsampling layers in netG')
+# parser.add_argument('--resnet_n_blocks', type=int, default=9, help='number of residual blocks in the global generator network')
+# parser.add_argument('--resnet_kernel_size', type=int, default=3,
+# help='kernel size of the resnet block')
+# parser.add_argument('--resnet_initial_kernel_size', type=int, default=7,
+# help='kernel size of the first convolution')
+# parser.set_defaults(norm_G='instance')
+# return parser
+#
+# def __init__(self, opt):
+# super().__init__()
+# input_nc = opt.label_nc + (1 if opt.contain_dontcare_label else 0) + (0 if opt.no_instance else 1)
+#
+# norm_layer = get_nonspade_norm_layer(opt, opt.norm_G)
+# activation = nn.ReLU(False)
+#
+# model = []
+#
+# # initial conv
+# model += [nn.ReflectionPad2d(opt.resnet_initial_kernel_size // 2),
+# norm_layer(nn.Conv2d(input_nc, opt.ngf,
+# kernel_size=opt.resnet_initial_kernel_size,
+# padding=0)),
+# activation]
+#
+# # downsample
+# mult = 1
+# for i in range(opt.resnet_n_downsample):
+# model += [norm_layer(nn.Conv2d(opt.ngf * mult, opt.ngf * mult * 2,
+# kernel_size=3, stride=2, padding=1)),
+# activation]
+# mult *= 2
+#
+# # resnet blocks
+# for i in range(opt.resnet_n_blocks):
+# model += [ResnetBlock(opt.ngf * mult,
+# norm_layer=norm_layer,
+# activation=activation,
+# kernel_size=opt.resnet_kernel_size)]
+#
+# # upsample
+# for i in range(opt.resnet_n_downsample):
+# nc_in = int(opt.ngf * mult)
+# nc_out = int((opt.ngf * mult) / 2)
+# model += [norm_layer(nn.ConvTranspose2d(nc_in, nc_out,
+# kernel_size=3, stride=2,
+# padding=1, output_padding=1)),
+# activation]
+# mult = mult // 2
+#
+# # final color_texture conv
+# model += [nn.ReflectionPad2d(3),
+# nn.Conv2d(nc_out, opt.output_nc, kernel_size=7, padding=0),
+# nn.Tanh()]
+#
+# self.model = nn.Sequential(*model)
+#
+# def forward(self, input, z=None):
+# return self.model(input)
diff --git a/models/CtrlHair/sean_codes/models/networks/loss.py b/models/CtrlHair/sean_codes/models/networks/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..f443cd71ca22a087949e11285996a153307f19cf
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/loss.py
@@ -0,0 +1,120 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from .architecture import VGG19
+
+
+# Defines the GAN loss which uses either LSGAN or the regular GAN.
+# When LSGAN is used, it is basically same as MSELoss,
+# but it abstracts away the need to create the target label tensor
+# that has the same size as the input
+class GANLoss(nn.Module):
+ def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0,
+ tensor=torch.FloatTensor, opt=None):
+ super(GANLoss, self).__init__()
+ self.real_label = target_real_label
+ self.fake_label = target_fake_label
+ self.real_label_tensor = None
+ self.fake_label_tensor = None
+ self.zero_tensor = None
+ self.Tensor = tensor
+ self.gan_mode = gan_mode
+ self.opt = opt
+ if gan_mode == 'ls':
+ pass
+ elif gan_mode == 'original':
+ pass
+ elif gan_mode == 'w':
+ pass
+ elif gan_mode == 'hinge':
+ pass
+ else:
+ raise ValueError('Unexpected gan_mode {}'.format(gan_mode))
+
+ def get_target_tensor(self, input, target_is_real):
+ if target_is_real:
+ if self.real_label_tensor is None:
+ self.real_label_tensor = self.Tensor(1).fill_(self.real_label)
+ self.real_label_tensor.requires_grad_(False)
+ return self.real_label_tensor.expand_as(input)
+ else:
+ if self.fake_label_tensor is None:
+ self.fake_label_tensor = self.Tensor(1).fill_(self.fake_label)
+ self.fake_label_tensor.requires_grad_(False)
+ return self.fake_label_tensor.expand_as(input)
+
+ def get_zero_tensor(self, input):
+ if self.zero_tensor is None:
+ self.zero_tensor = self.Tensor(1).fill_(0)
+ self.zero_tensor.requires_grad_(False)
+ return self.zero_tensor.expand_as(input)
+
+ def loss(self, input, target_is_real, for_discriminator=True):
+ if self.gan_mode == 'original': # cross entropy loss
+ target_tensor = self.get_target_tensor(input, target_is_real)
+ loss = F.binary_cross_entropy_with_logits(input, target_tensor)
+ return loss
+ elif self.gan_mode == 'ls':
+ target_tensor = self.get_target_tensor(input, target_is_real)
+ return F.mse_loss(input, target_tensor)
+ elif self.gan_mode == 'hinge':
+ if for_discriminator:
+ if target_is_real:
+ minval = torch.min(input - 1, self.get_zero_tensor(input))
+ loss = -torch.mean(minval)
+ else:
+ minval = torch.min(-input - 1, self.get_zero_tensor(input))
+ loss = -torch.mean(minval)
+ else:
+ assert target_is_real, "The generator's hinge loss must be aiming for real"
+ loss = -torch.mean(input)
+ return loss
+ else:
+ # wgan
+ if target_is_real:
+ return -input.mean()
+ else:
+ return input.mean()
+
+ def __call__(self, input, target_is_real, for_discriminator=True):
+ # computing loss is a bit complicated because |input| may not be
+ # a tensor, but list of tensors in case of multiscale discriminator
+ if isinstance(input, list):
+ loss = 0
+ for pred_i in input:
+ if isinstance(pred_i, list):
+ pred_i = pred_i[-1]
+ loss_tensor = self.loss(pred_i, target_is_real, for_discriminator)
+ bs = 1 if len(loss_tensor.size()) == 0 else loss_tensor.size(0)
+ new_loss = torch.mean(loss_tensor.view(bs, -1), dim=1)
+ loss += new_loss
+ return loss / len(input)
+ else:
+ return self.loss(input, target_is_real, for_discriminator)
+
+
+# Perceptual loss that uses a pretrained VGG network
+class VGGLoss(nn.Module):
+ def __init__(self, gpu_ids):
+ super(VGGLoss, self).__init__()
+ self.vgg = VGG19().cuda()
+ self.criterion = nn.L1Loss()
+ self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
+
+ def forward(self, x, y):
+ x_vgg, y_vgg = self.vgg(x), self.vgg(y)
+ loss = 0
+ for i in range(len(x_vgg)):
+ loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach())
+ return loss
+
+
+# KL Divergence loss used in VAE with an image encoder
+# class KLDLoss(nn.Module):
+# def forward(self, mu, logvar):
+# return -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
diff --git a/models/CtrlHair/sean_codes/models/networks/normalization.py b/models/CtrlHair/sean_codes/models/networks/normalization.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab8ca20962bef200a32519418a9ce115a670017f
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/normalization.py
@@ -0,0 +1,257 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import re
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from sean_codes.models.networks.sync_batchnorm import SynchronizedBatchNorm2d
+import torch.nn.utils.spectral_norm as spectral_norm
+import os
+import numpy as np
+
+
+# Returns a function that creates a normalization function
+# that does not condition on semantic map
+def get_nonspade_norm_layer(opt, norm_type='instance'):
+ # helper function to get # color_texture channels of the previous layer
+ def get_out_channel(layer):
+ if hasattr(layer, 'out_channels'):
+ return getattr(layer, 'out_channels')
+ return layer.weight.size(0)
+
+ # this function will be returned
+ def add_norm_layer(layer):
+ nonlocal norm_type
+ if norm_type.startswith('spectral'):
+ layer = spectral_norm(layer)
+ subnorm_type = norm_type[len('spectral'):]
+
+ if subnorm_type == 'none' or len(subnorm_type) == 0:
+ return layer
+
+ # remove bias in the previous layer, which is meaningless
+ # since it has no effect after normalization
+ if getattr(layer, 'bias', None) is not None:
+ delattr(layer, 'bias')
+ layer.register_parameter('bias', None)
+
+ if subnorm_type == 'batch':
+ norm_layer = nn.BatchNorm2d(get_out_channel(layer), affine=True)
+ elif subnorm_type == 'sync_batch':
+ norm_layer = SynchronizedBatchNorm2d(get_out_channel(layer), affine=True)
+ elif subnorm_type == 'instance':
+ norm_layer = nn.InstanceNorm2d(get_out_channel(layer), affine=False)
+ else:
+ raise ValueError('normalization layer %s is not recognized' % subnorm_type)
+
+ return nn.Sequential(layer, norm_layer)
+
+ return add_norm_layer
+
+
+# Creates SPADE normalization layer based on the given configuration
+# SPADE consists of two steps. First, it normalizes the activations using
+# your favorite normalization method, such as Batch Norm or Instance Norm.
+# Second, it applies scale and bias to the normalized color_texture, conditioned on
+# the segmentation map.
+# The format of |config_text| is spade(norm)(ks), where
+# (norm) specifies the type of parameter-free normalization.
+# (e.g. syncbatch, batch, instance)
+# (ks) specifies the size of kernel in the SPADE module (e.g. 3x3)
+# Example |config_text| will be spadesyncbatch3x3, or spadeinstance5x5.
+# Also, the other arguments are
+# |norm_nc|: the #channels of the normalized activations, hence the color_texture dim of SPADE
+# |label_nc|: the #channels of the input semantic map, hence the input dim of SPADE
+
+
+class ACE(nn.Module):
+ def __init__(self, config_text, norm_nc, label_nc, ACE_Name=None, status='scripts', spade_params=None, use_rgb=True):
+ super().__init__()
+
+ self.ACE_Name = ACE_Name
+ self.status = status
+ self.save_npy = True
+ self.Spade = SPADE(*spade_params)
+ self.use_rgb = use_rgb
+ self.style_length = 512
+ self.blending_gamma = nn.Parameter(torch.zeros(1), requires_grad=True)
+ self.blending_beta = nn.Parameter(torch.zeros(1), requires_grad=True)
+ self.noise_var = nn.Parameter(torch.zeros(norm_nc), requires_grad=True)
+
+ assert config_text.startswith('spade')
+ parsed = re.search('spade(\D+)(\d)x\d', config_text)
+ param_free_norm_type = str(parsed.group(1))
+ ks = int(parsed.group(2))
+ pw = ks // 2
+
+ if param_free_norm_type == 'instance':
+ self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False)
+ elif param_free_norm_type == 'syncbatch':
+ self.param_free_norm = SynchronizedBatchNorm2d(norm_nc, affine=False)
+ elif param_free_norm_type == 'batch':
+ self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False)
+ else:
+ raise ValueError('%s is not a recognized param-free norm type in SPADE'
+ % param_free_norm_type)
+
+ # The dimension of the intermediate embedding space. Yes, hardcoded.
+
+ if self.use_rgb:
+ self.create_gamma_beta_fc_layers()
+
+ self.conv_gamma = nn.Conv2d(self.style_length, norm_nc, kernel_size=ks, padding=pw)
+ self.conv_beta = nn.Conv2d(self.style_length, norm_nc, kernel_size=ks, padding=pw)
+
+ def forward(self, x, segmap, style_codes=None, obj_dic=None):
+
+ # Part 1. generate parameter-free normalized activations
+ added_noise = (torch.randn(x.shape[0], x.shape[3], x.shape[2], 1).cuda() * self.noise_var).transpose(1, 3)
+ normalized = self.param_free_norm(x + added_noise)
+
+ # Part 2. produce scaling and bias conditioned on semantic map
+ segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
+
+ if self.use_rgb:
+ [b_size, f_size, h_size, w_size] = normalized.shape
+ middle_avg = torch.zeros((b_size, self.style_length, h_size, w_size), device=normalized.device)
+
+ if self.status == 'UI_mode':
+ ############## hard coding
+
+ for i in range(1):
+ for j in range(segmap.shape[1]):
+
+ component_mask_area = torch.sum(segmap.bool()[i, j])
+
+ if component_mask_area > 0:
+ if obj_dic is None:
+ print('wrong even it is the first input')
+ else:
+ style_code_tmp = obj_dic[str(j)]['ACE']
+
+ middle_mu = F.relu(self.__getattr__('fc_mu' + str(j))(style_code_tmp))
+ component_mu = middle_mu.reshape(self.style_length, 1).expand(self.style_length,
+ component_mask_area)
+
+ middle_avg[i].masked_scatter_(segmap.bool()[i, j], component_mu)
+
+ else:
+
+ for i in range(b_size):
+ for j in range(segmap.shape[1]):
+ component_mask_area = torch.sum(segmap.bool()[i, j])
+
+ if component_mask_area > 0:
+
+ middle_mu = F.relu(self.__getattr__('fc_mu' + str(j))(style_codes[i][j]))
+ component_mu = middle_mu.reshape(self.style_length, 1).expand(self.style_length,
+ component_mask_area)
+
+ middle_avg[i].masked_scatter_(segmap.bool()[i, j], component_mu)
+
+ if self.status == 'test' and self.save_npy and self.ACE_Name == 'up_2_ACE_0':
+ tmp = style_codes[i][j].cpu().numpy()
+ # gil
+ if obj_dic[i].find('temp_path') != -1:
+ dir_path = os.path.split(obj_dic[i])[0]
+ else:
+ dir_path = 'styles_test'
+ im_name = os.path.basename(obj_dic[i])
+ folder_path = os.path.join(dir_path, 'style_codes', im_name, str(j))
+ ############### some problem with obj_dic[i]
+
+ if not os.path.exists(folder_path):
+ os.makedirs(folder_path)
+
+ style_code_path = os.path.join(folder_path, 'ACE.npy')
+ np.save(style_code_path, tmp)
+
+ gamma_avg = self.conv_gamma(middle_avg)
+ beta_avg = self.conv_beta(middle_avg)
+
+ gamma_spade, beta_spade = self.Spade(segmap)
+
+ gamma_alpha = torch.sigmoid(self.blending_gamma)
+ beta_alpha = torch.sigmoid(self.blending_beta)
+
+ gamma_final = gamma_alpha * gamma_avg + (1 - gamma_alpha) * gamma_spade
+ beta_final = beta_alpha * beta_avg + (1 - beta_alpha) * beta_spade
+ out = normalized * (1 + gamma_final) + beta_final
+ else:
+ gamma_spade, beta_spade = self.Spade(segmap)
+ gamma_final = gamma_spade
+ beta_final = beta_spade
+ out = normalized * (1 + gamma_final) + beta_final
+
+ return out
+
+ def create_gamma_beta_fc_layers(self):
+
+ ################### These codes should be replaced with torch.nn.ModuleList
+
+ style_length = self.style_length
+
+ self.fc_mu0 = nn.Linear(style_length, style_length)
+ self.fc_mu1 = nn.Linear(style_length, style_length)
+ self.fc_mu2 = nn.Linear(style_length, style_length)
+ self.fc_mu3 = nn.Linear(style_length, style_length)
+ self.fc_mu4 = nn.Linear(style_length, style_length)
+ self.fc_mu5 = nn.Linear(style_length, style_length)
+ self.fc_mu6 = nn.Linear(style_length, style_length)
+ self.fc_mu7 = nn.Linear(style_length, style_length)
+ self.fc_mu8 = nn.Linear(style_length, style_length)
+ self.fc_mu9 = nn.Linear(style_length, style_length)
+ self.fc_mu10 = nn.Linear(style_length, style_length)
+ self.fc_mu11 = nn.Linear(style_length, style_length)
+ self.fc_mu12 = nn.Linear(style_length, style_length)
+ self.fc_mu13 = nn.Linear(style_length, style_length)
+ self.fc_mu14 = nn.Linear(style_length, style_length)
+ self.fc_mu15 = nn.Linear(style_length, style_length)
+ self.fc_mu16 = nn.Linear(style_length, style_length)
+ self.fc_mu17 = nn.Linear(style_length, style_length)
+ self.fc_mu18 = nn.Linear(style_length, style_length)
+
+
+class SPADE(nn.Module):
+ def __init__(self, config_text, norm_nc, label_nc):
+ super().__init__()
+
+ assert config_text.startswith('spade')
+ parsed = re.search('spade(\D+)(\d)x\d', config_text)
+ param_free_norm_type = str(parsed.group(1))
+ ks = int(parsed.group(2))
+
+ if param_free_norm_type == 'instance':
+ self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False)
+ elif param_free_norm_type == 'syncbatch':
+ self.param_free_norm = SynchronizedBatchNorm2d(norm_nc, affine=False)
+ elif param_free_norm_type == 'batch':
+ self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False)
+ else:
+ raise ValueError('%s is not a recognized param-free norm type in SPADE'
+ % param_free_norm_type)
+
+ # The dimension of the intermediate embedding space. Yes, hardcoded.
+ nhidden = 128
+
+ pw = ks // 2
+ self.mlp_shared = nn.Sequential(
+ nn.Conv2d(label_nc, nhidden, kernel_size=ks, padding=pw),
+ nn.ReLU()
+ )
+
+ self.mlp_gamma = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
+ self.mlp_beta = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw)
+
+ def forward(self, segmap):
+
+ inputmap = segmap
+
+ actv = self.mlp_shared(inputmap)
+ gamma = self.mlp_gamma(actv)
+ beta = self.mlp_beta(actv)
+
+ return gamma, beta
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/__init__.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..84ef0a02ec3d1649a62052c65ef1c75e2eaeb5bb
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/__init__.py
@@ -0,0 +1,13 @@
+# -*- coding: utf-8 -*-
+# File : __init__.py
+# Author : Jiayuan Mao
+# Email : maojiayuan@gmail.com
+# Date : 27/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+from .batchnorm import SynchronizedBatchNorm1d, SynchronizedBatchNorm2d, SynchronizedBatchNorm3d
+from .batchnorm import convert_model
+from .replicate import DataParallelWithCallback, patch_replication_callback
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm.py
new file mode 100644
index 0000000000000000000000000000000000000000..27f4b8bc7a24d19d5ab75e2d2bc2f5b23d2a95d2
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm.py
@@ -0,0 +1,361 @@
+# -*- coding: utf-8 -*-
+# File : batchnorm.py
+# Author : Jiayuan Mao
+# Email : maojiayuan@gmail.com
+# Date : 27/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+import collections
+
+import torch
+import torch.nn.functional as F
+
+from torch.nn.modules.batchnorm import _BatchNorm
+from torch.nn.parallel._functions import ReduceAddCoalesced, Broadcast
+
+from .comm import SyncMaster
+from .replicate import DataParallelWithCallback
+
+__all__ = ['SynchronizedBatchNorm1d', 'SynchronizedBatchNorm2d',
+ 'SynchronizedBatchNorm3d', 'convert_model']
+
+
+def _sum_ft(tensor):
+ """sum over the first and last dimention"""
+ return tensor.sum(dim=0).sum(dim=-1)
+
+
+def _unsqueeze_ft(tensor):
+ """add new dementions at the front and the tail"""
+ return tensor.unsqueeze(0).unsqueeze(-1)
+
+
+_ChildMessage = collections.namedtuple('_ChildMessage', ['sum', 'ssum', 'sum_size'])
+_MasterMessage = collections.namedtuple('_MasterMessage', ['sum', 'inv_std'])
+
+
+class _SynchronizedBatchNorm(_BatchNorm):
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True):
+ super(_SynchronizedBatchNorm, self).__init__(num_features, eps=eps, momentum=momentum, affine=affine)
+
+ self._sync_master = SyncMaster(self._data_parallel_master)
+
+ self._is_parallel = False
+ self._parallel_id = None
+ self._slave_pipe = None
+
+ def forward(self, input):
+ # If it is not parallel computation or is in evaluation mode, use PyTorch's implementation.
+ if not (self._is_parallel and self.training):
+ return F.batch_norm(
+ input, self.running_mean, self.running_var, self.weight, self.bias,
+ self.training, self.momentum, self.eps)
+
+ # Resize the input to (B, C, -1).
+ input_shape = input.size()
+ input = input.view(input.size(0), self.num_features, -1)
+
+ # Compute the sum and square-sum.
+ sum_size = input.size(0) * input.size(2)
+ input_sum = _sum_ft(input)
+ input_ssum = _sum_ft(input ** 2)
+
+ # Reduce-and-broadcast the statistics.
+ if self._parallel_id == 0:
+ mean, inv_std = self._sync_master.run_master(_ChildMessage(input_sum, input_ssum, sum_size))
+ else:
+ mean, inv_std = self._slave_pipe.run_slave(_ChildMessage(input_sum, input_ssum, sum_size))
+
+ # Compute the color_texture.
+ if self.affine:
+ # MJY:: Fuse the multiplication for speed.
+ output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std * self.weight) + _unsqueeze_ft(self.bias)
+ else:
+ output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std)
+
+ # Reshape it.
+ return output.view(input_shape)
+
+ def __data_parallel_replicate__(self, ctx, copy_id):
+ self._is_parallel = True
+ self._parallel_id = copy_id
+
+ # parallel_id == 0 means master device.
+ if self._parallel_id == 0:
+ ctx.sync_master = self._sync_master
+ else:
+ self._slave_pipe = ctx.sync_master.register_slave(copy_id)
+
+ def _data_parallel_master(self, intermediates):
+ """Reduce the sum and square-sum, compute the statistics, and broadcast it."""
+
+ # Always using same "device order" makes the ReduceAdd operation faster.
+ # Thanks to:: Tete Xiao (http://tetexiao.com/)
+ intermediates = sorted(intermediates, key=lambda i: i[1].sum.get_device())
+
+ to_reduce = [i[1][:2] for i in intermediates]
+ to_reduce = [j for i in to_reduce for j in i] # flatten
+ target_gpus = [i[1].sum.get_device() for i in intermediates]
+
+ sum_size = sum([i[1].sum_size for i in intermediates])
+ sum_, ssum = ReduceAddCoalesced.apply(target_gpus[0], 2, *to_reduce)
+ mean, inv_std = self._compute_mean_std(sum_, ssum, sum_size)
+
+ broadcasted = Broadcast.apply(target_gpus, mean, inv_std)
+
+ outputs = []
+ for i, rec in enumerate(intermediates):
+ outputs.append((rec[0], _MasterMessage(*broadcasted[i*2:i*2+2])))
+
+ return outputs
+
+ def _compute_mean_std(self, sum_, ssum, size):
+ """Compute the mean and standard-deviation with sum and square-sum. This method
+ also maintains the moving average on the master device."""
+ assert size > 1, 'BatchNorm computes unbiased standard-deviation, which requires size > 1.'
+ mean = sum_ / size
+ sumvar = ssum - sum_ * mean
+ unbias_var = sumvar / (size - 1)
+ bias_var = sumvar / size
+
+ self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.data
+ self.running_var = (1 - self.momentum) * self.running_var + self.momentum * unbias_var.data
+
+ return mean, bias_var.clamp(self.eps) ** -0.5
+
+
+class SynchronizedBatchNorm1d(_SynchronizedBatchNorm):
+ r"""Applies Synchronized Batch Normalization over a 2d or 3d input that is seen as a
+ mini-batch.
+
+ .. math::
+
+ y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
+
+ This module differs from the built-in PyTorch BatchNorm1d as the mean and
+ standard-deviation are reduced across all devices during training.
+
+ For example, when one uses `nn.DataParallel` to wrap the network during
+ training, PyTorch's implementation normalize the tensor on each device using
+ the statistics only on that device, which accelerated the computation and
+ is also easy to implement, but the statistics might be inaccurate.
+ Instead, in this synchronized version, the statistics will be computed
+ over all training samples distributed on multiple devices.
+
+ Note that, for one-GPU or CPU-only case, this module behaves exactly same
+ as the built-in PyTorch implementation.
+
+ The mean and standard-deviation are calculated per-dimension over
+ the mini-batches and gamma and beta are learnable parameter vectors
+ of size C (where C is the input size).
+
+ During training, this layer keeps a running estimate of its computed mean
+ and variance. The running sum is kept with a default momentum of 0.1.
+
+ During evaluation, this running mean/variance is used for normalization.
+
+ Because the BatchNorm is done over the `C` dimension, computing statistics
+ on `(N, L)` slices, it's common terminology to call this Temporal BatchNorm
+
+ Args:
+ num_features: num_features from an expected input of size
+ `batch_size x num_features [x width]`
+ eps: a value added to the denominator for numerical stability.
+ Default: 1e-5
+ momentum: the value used for the running_mean and running_var
+ computation. Default: 0.1
+ affine: a boolean value that when set to ``True``, gives the layer learnable
+ affine parameters. Default: ``True``
+
+ Shape:
+ - Input: :math:`(N, C)` or :math:`(N, C, L)`
+ - Output: :math:`(N, C)` or :math:`(N, C, L)` (same shape as input)
+
+ Examples:
+ >>> # With Learnable Parameters
+ >>> m = SynchronizedBatchNorm1d(100)
+ >>> # Without Learnable Parameters
+ >>> m = SynchronizedBatchNorm1d(100, affine=False)
+ >>> input = torch.autograd.Variable(torch.randn(20, 100))
+ >>> color_texture = m(input)
+ """
+
+ def _check_input_dim(self, input):
+ if input.dim() != 2 and input.dim() != 3:
+ raise ValueError('expected 2D or 3D input (got {}D input)'
+ .format(input.dim()))
+ super(SynchronizedBatchNorm1d, self)._check_input_dim(input)
+
+
+class SynchronizedBatchNorm2d(_SynchronizedBatchNorm):
+ r"""Applies Batch Normalization over a 4d input that is seen as a mini-batch
+ of 3d inputs
+
+ .. math::
+
+ y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
+
+ This module differs from the built-in PyTorch BatchNorm2d as the mean and
+ standard-deviation are reduced across all devices during training.
+
+ For example, when one uses `nn.DataParallel` to wrap the network during
+ training, PyTorch's implementation normalize the tensor on each device using
+ the statistics only on that device, which accelerated the computation and
+ is also easy to implement, but the statistics might be inaccurate.
+ Instead, in this synchronized version, the statistics will be computed
+ over all training samples distributed on multiple devices.
+
+ Note that, for one-GPU or CPU-only case, this module behaves exactly same
+ as the built-in PyTorch implementation.
+
+ The mean and standard-deviation are calculated per-dimension over
+ the mini-batches and gamma and beta are learnable parameter vectors
+ of size C (where C is the input size).
+
+ During training, this layer keeps a running estimate of its computed mean
+ and variance. The running sum is kept with a default momentum of 0.1.
+
+ During evaluation, this running mean/variance is used for normalization.
+
+ Because the BatchNorm is done over the `C` dimension, computing statistics
+ on `(N, H, W)` slices, it's common terminology to call this Spatial BatchNorm
+
+ Args:
+ num_features: num_features from an expected input of
+ size batch_size x num_features x height x width
+ eps: a value added to the denominator for numerical stability.
+ Default: 1e-5
+ momentum: the value used for the running_mean and running_var
+ computation. Default: 0.1
+ affine: a boolean value that when set to ``True``, gives the layer learnable
+ affine parameters. Default: ``True``
+
+ Shape:
+ - Input: :math:`(N, C, H, W)`
+ - Output: :math:`(N, C, H, W)` (same shape as input)
+
+ Examples:
+ >>> # With Learnable Parameters
+ >>> m = SynchronizedBatchNorm2d(100)
+ >>> # Without Learnable Parameters
+ >>> m = SynchronizedBatchNorm2d(100, affine=False)
+ >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45))
+ >>> color_texture = m(input)
+ """
+
+ def _check_input_dim(self, input):
+ if input.dim() != 4:
+ raise ValueError('expected 4D input (got {}D input)'
+ .format(input.dim()))
+ super(SynchronizedBatchNorm2d, self)._check_input_dim(input)
+
+
+class SynchronizedBatchNorm3d(_SynchronizedBatchNorm):
+ r"""Applies Batch Normalization over a 5d input that is seen as a mini-batch
+ of 4d inputs
+
+ .. math::
+
+ y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
+
+ This module differs from the built-in PyTorch BatchNorm3d as the mean and
+ standard-deviation are reduced across all devices during training.
+
+ For example, when one uses `nn.DataParallel` to wrap the network during
+ training, PyTorch's implementation normalize the tensor on each device using
+ the statistics only on that device, which accelerated the computation and
+ is also easy to implement, but the statistics might be inaccurate.
+ Instead, in this synchronized version, the statistics will be computed
+ over all training samples distributed on multiple devices.
+
+ Note that, for one-GPU or CPU-only case, this module behaves exactly same
+ as the built-in PyTorch implementation.
+
+ The mean and standard-deviation are calculated per-dimension over
+ the mini-batches and gamma and beta are learnable parameter vectors
+ of size C (where C is the input size).
+
+ During training, this layer keeps a running estimate of its computed mean
+ and variance. The running sum is kept with a default momentum of 0.1.
+
+ During evaluation, this running mean/variance is used for normalization.
+
+ Because the BatchNorm is done over the `C` dimension, computing statistics
+ on `(N, D, H, W)` slices, it's common terminology to call this Volumetric BatchNorm
+ or Spatio-temporal BatchNorm
+
+ Args:
+ num_features: num_features from an expected input of
+ size batch_size x num_features x depth x height x width
+ eps: a value added to the denominator for numerical stability.
+ Default: 1e-5
+ momentum: the value used for the running_mean and running_var
+ computation. Default: 0.1
+ affine: a boolean value that when set to ``True``, gives the layer learnable
+ affine parameters. Default: ``True``
+
+ Shape:
+ - Input: :math:`(N, C, D, H, W)`
+ - Output: :math:`(N, C, D, H, W)` (same shape as input)
+
+ Examples:
+ >>> # With Learnable Parameters
+ >>> m = SynchronizedBatchNorm3d(100)
+ >>> # Without Learnable Parameters
+ >>> m = SynchronizedBatchNorm3d(100, affine=False)
+ >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45, 10))
+ >>> color_texture = m(input)
+ """
+
+ def _check_input_dim(self, input):
+ if input.dim() != 5:
+ raise ValueError('expected 5D input (got {}D input)'
+ .format(input.dim()))
+ super(SynchronizedBatchNorm3d, self)._check_input_dim(input)
+
+
+def convert_model(module):
+ """Traverse the input module and its child recursively
+ and replace all instance of torch.nn.modules.batchnorm.BatchNorm*N*d
+ to SynchronizedBatchNorm*N*d
+
+ Args:
+ module: the input module needs to be convert to SyncBN model
+
+ Examples:
+ >>> import torch.nn as nn
+ >>> import torchvision
+ >>> # m is a standard pytorch model
+ >>> m = torchvision.models.resnet18(True)
+ >>> m = nn.DataParallel(m)
+ >>> # after convert, m is using SyncBN
+ >>> m = convert_model(m)
+ """
+ if isinstance(module, torch.nn.DataParallel):
+ mod = module.module
+ mod = convert_model(mod)
+ mod = DataParallelWithCallback(mod)
+ return mod
+
+ mod = module
+ for pth_module, sync_module in zip([torch.nn.modules.batchnorm.BatchNorm1d,
+ torch.nn.modules.batchnorm.BatchNorm2d,
+ torch.nn.modules.batchnorm.BatchNorm3d],
+ [SynchronizedBatchNorm1d,
+ SynchronizedBatchNorm2d,
+ SynchronizedBatchNorm3d]):
+ if isinstance(module, pth_module):
+ mod = sync_module(module.num_features, module.eps, module.momentum, module.affine)
+ mod.running_mean = module.running_mean
+ mod.running_var = module.running_var
+ if module.affine:
+ mod.weight.data = module.weight.data.clone().detach()
+ mod.bias.data = module.bias.data.clone().detach()
+
+ for name, child in module.named_children():
+ mod.add_module(name, convert_model(child))
+
+ return mod
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm_reimpl.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm_reimpl.py
new file mode 100644
index 0000000000000000000000000000000000000000..7afcdaff9c56d7ac9c487f2dbe61fe6cb9c353a0
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/batchnorm_reimpl.py
@@ -0,0 +1,74 @@
+#! /usr/bin/env python3
+# -*- coding: utf-8 -*-
+# File : batchnorm_reimpl.py
+# Author : acgtyrant
+# Date : 11/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+import torch
+import torch.nn as nn
+import torch.nn.init as init
+
+__all__ = ['BatchNormReimpl']
+
+
+class BatchNorm2dReimpl(nn.Module):
+ """
+ A re-implementation of batch normalization, used for testing the numerical
+ stability.
+
+ Author: acgtyrant
+ See also:
+ https://github.com/vacancy/Synchronized-BatchNorm-PyTorch/issues/14
+ """
+ def __init__(self, num_features, eps=1e-5, momentum=0.1):
+ super().__init__()
+
+ self.num_features = num_features
+ self.eps = eps
+ self.momentum = momentum
+ self.weight = nn.Parameter(torch.empty(num_features))
+ self.bias = nn.Parameter(torch.empty(num_features))
+ self.register_buffer('running_mean', torch.zeros(num_features))
+ self.register_buffer('running_var', torch.ones(num_features))
+ self.reset_parameters()
+
+ def reset_running_stats(self):
+ self.running_mean.zero_()
+ self.running_var.fill_(1)
+
+ def reset_parameters(self):
+ self.reset_running_stats()
+ init.uniform_(self.weight)
+ init.zeros_(self.bias)
+
+ def forward(self, input_):
+ batchsize, channels, height, width = input_.size()
+ numel = batchsize * height * width
+ input_ = input_.permute(1, 0, 2, 3).contiguous().view(channels, numel)
+ sum_ = input_.sum(1)
+ sum_of_square = input_.pow(2).sum(1)
+ mean = sum_ / numel
+ sumvar = sum_of_square - sum_ * mean
+
+ self.running_mean = (
+ (1 - self.momentum) * self.running_mean
+ + self.momentum * mean.detach()
+ )
+ unbias_var = sumvar / (numel - 1)
+ self.running_var = (
+ (1 - self.momentum) * self.running_var
+ + self.momentum * unbias_var.detach()
+ )
+
+ bias_var = sumvar / numel
+ inv_std = 1 / (bias_var + self.eps).pow(0.5)
+ output = (
+ (input_ - mean.unsqueeze(1)) * inv_std.unsqueeze(1) *
+ self.weight.unsqueeze(1) + self.bias.unsqueeze(1))
+
+ return output.view(channels, batchsize, height, width).permute(1, 0, 2, 3).contiguous()
+
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/comm.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/comm.py
new file mode 100644
index 0000000000000000000000000000000000000000..922f8c4a3adaa9b32fdcaef09583be03b0d7eb2b
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/comm.py
@@ -0,0 +1,137 @@
+# -*- coding: utf-8 -*-
+# File : comm.py
+# Author : Jiayuan Mao
+# Email : maojiayuan@gmail.com
+# Date : 27/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+import queue
+import collections
+import threading
+
+__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster']
+
+
+class FutureResult(object):
+ """A thread-safe future implementation. Used only as one-to-one pipe."""
+
+ def __init__(self):
+ self._result = None
+ self._lock = threading.Lock()
+ self._cond = threading.Condition(self._lock)
+
+ def put(self, result):
+ with self._lock:
+ assert self._result is None, 'Previous result has\'t been fetched.'
+ self._result = result
+ self._cond.notify()
+
+ def get(self):
+ with self._lock:
+ if self._result is None:
+ self._cond.wait()
+
+ res = self._result
+ self._result = None
+ return res
+
+
+_MasterRegistry = collections.namedtuple('MasterRegistry', ['result'])
+_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result'])
+
+
+class SlavePipe(_SlavePipeBase):
+ """Pipe for master-slave communication."""
+
+ def run_slave(self, msg):
+ self.queue.put((self.identifier, msg))
+ ret = self.result.get()
+ self.queue.put(True)
+ return ret
+
+
+class SyncMaster(object):
+ """An abstract `SyncMaster` object.
+
+ - During the replication, as the data parallel will trigger an callback of each module, all slave devices should
+ call `register(id)` and obtain an `SlavePipe` to communicate with the master.
+ - During the forward pass, master device invokes `run_master`, all messages from slave devices will be collected,
+ and passed to a registered callback.
+ - After receiving the messages, the master device should gather the information and determine to message passed
+ back to each slave devices.
+ """
+
+ def __init__(self, master_callback):
+ """
+
+ Args:
+ master_callback: a callback to be invoked after having collected messages from slave devices.
+ """
+ self._master_callback = master_callback
+ self._queue = queue.Queue()
+ self._registry = collections.OrderedDict()
+ self._activated = False
+
+ def __getstate__(self):
+ return {'master_callback': self._master_callback}
+
+ def __setstate__(self, state):
+ self.__init__(state['master_callback'])
+
+ def register_slave(self, identifier):
+ """
+ Register an slave device.
+
+ Args:
+ identifier: an identifier, usually is the device id.
+
+ Returns: a `SlavePipe` object which can be used to communicate with the master device.
+
+ """
+ if self._activated:
+ assert self._queue.empty(), 'Queue is not clean before next initialization.'
+ self._activated = False
+ self._registry.clear()
+ future = FutureResult()
+ self._registry[identifier] = _MasterRegistry(future)
+ return SlavePipe(identifier, self._queue, future)
+
+ def run_master(self, master_msg):
+ """
+ Main entry for the master device in each forward pass.
+ The messages were first collected from each devices (including the master device), and then
+ an callback will be invoked to compute the message to be sent back to each devices
+ (including the master device).
+
+ Args:
+ master_msg: the message that the master want to send to itself. This will be placed as the first
+ message when calling `master_callback`. For detailed usage, see `_SynchronizedBatchNorm` for an example.
+
+ Returns: the message to be sent back to the master device.
+
+ """
+ self._activated = True
+
+ intermediates = [(0, master_msg)]
+ for i in range(self.nr_slaves):
+ intermediates.append(self._queue.get())
+
+ results = self._master_callback(intermediates)
+ assert results[0][0] == 0, 'The first result should belongs to the master.'
+
+ for i, res in results:
+ if i == 0:
+ continue
+ self._registry[i].result.put(res)
+
+ for i in range(self.nr_slaves):
+ assert self._queue.get() is True
+
+ return results[0][1]
+
+ @property
+ def nr_slaves(self):
+ return len(self._registry)
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/replicate.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/replicate.py
new file mode 100644
index 0000000000000000000000000000000000000000..b71c7b8ed51a1d6c55b1f753bdd8d90bad79bd06
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/replicate.py
@@ -0,0 +1,94 @@
+# -*- coding: utf-8 -*-
+# File : replicate.py
+# Author : Jiayuan Mao
+# Email : maojiayuan@gmail.com
+# Date : 27/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+import functools
+
+from torch.nn.parallel.data_parallel import DataParallel
+
+__all__ = [
+ 'CallbackContext',
+ 'execute_replication_callbacks',
+ 'DataParallelWithCallback',
+ 'patch_replication_callback'
+]
+
+
+class CallbackContext(object):
+ pass
+
+
+def execute_replication_callbacks(modules):
+ """
+ Execute an replication callback `__data_parallel_replicate__` on each module created by original replication.
+
+ The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
+
+ Note that, as all modules are isomorphism, we assign each sub-module with a context
+ (shared among multiple copies of this module on different devices).
+ Through this context, different copies can share some information.
+
+ We guarantee that the callback on the master copy (the first copy) will be called ahead of calling the callback
+ of any slave copies.
+ """
+ master_copy = modules[0]
+ nr_modules = len(list(master_copy.modules()))
+ ctxs = [CallbackContext() for _ in range(nr_modules)]
+
+ for i, module in enumerate(modules):
+ for j, m in enumerate(module.modules()):
+ if hasattr(m, '__data_parallel_replicate__'):
+ m.__data_parallel_replicate__(ctxs[j], i)
+
+
+class DataParallelWithCallback(DataParallel):
+ """
+ Data Parallel with a replication callback.
+
+ An replication callback `__data_parallel_replicate__` of each module will be invoked after being created by
+ original `replicate` function.
+ The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
+
+ Examples:
+ > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
+ > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
+ # sync_bn.__data_parallel_replicate__ will be invoked.
+ """
+
+ def replicate(self, module, device_ids):
+ modules = super(DataParallelWithCallback, self).replicate(module, device_ids)
+ execute_replication_callbacks(modules)
+ return modules
+
+
+def patch_replication_callback(data_parallel):
+ """
+ Monkey-patch an existing `DataParallel` object. Add the replication callback.
+ Useful when you have customized `DataParallel` implementation.
+
+ Examples:
+ > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
+ > sync_bn = DataParallel(sync_bn, device_ids=[0, 1])
+ > patch_replication_callback(sync_bn)
+ # this is equivalent to
+ > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
+ > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
+ """
+
+ assert isinstance(data_parallel, DataParallel)
+
+ old_replicate = data_parallel.replicate
+
+ @functools.wraps(old_replicate)
+ def new_replicate(module, device_ids):
+ modules = old_replicate(module, device_ids)
+ execute_replication_callbacks(modules)
+ return modules
+
+ data_parallel.replicate = new_replicate
diff --git a/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/unittest.py b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/unittest.py
new file mode 100644
index 0000000000000000000000000000000000000000..bed56f1caa929ac3e9a57c583f8d3e42624f58be
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/networks/sync_batchnorm/unittest.py
@@ -0,0 +1,29 @@
+# -*- coding: utf-8 -*-
+# File : unittest.py
+# Author : Jiayuan Mao
+# Email : maojiayuan@gmail.com
+# Date : 27/01/2018
+#
+# This file is part of Synchronized-BatchNorm-PyTorch.
+# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
+# Distributed under MIT License.
+
+import unittest
+import torch
+
+
+class TorchTestCase(unittest.TestCase):
+ def assertTensorClose(self, x, y):
+ adiff = float((x - y).abs().max())
+ if (y == 0).all():
+ rdiff = 'NaN'
+ else:
+ rdiff = float((adiff / y).abs().max())
+
+ message = (
+ 'Tensor close check failed\n'
+ 'adiff={}\n'
+ 'rdiff={}\n'
+ ).format(adiff, rdiff)
+ self.assertTrue(torch.allclose(x, y), message)
+
diff --git a/models/CtrlHair/sean_codes/models/pix2pix_model.py b/models/CtrlHair/sean_codes/models/pix2pix_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..afeaf03994e5dab1b5fbe5b31587a8fe4931c99f
--- /dev/null
+++ b/models/CtrlHair/sean_codes/models/pix2pix_model.py
@@ -0,0 +1,266 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import torch
+import sean_codes.models.networks as networks
+import util.util as util
+
+
+class Pix2PixModel(torch.nn.Module):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ networks.modify_commandline_options(parser, is_train)
+ return parser
+
+ def __init__(self, opt):
+ super().__init__()
+ self.opt = opt
+ self.FloatTensor = torch.cuda.FloatTensor if self.use_gpu() \
+ else torch.FloatTensor
+ self.ByteTensor = torch.cuda.ByteTensor if self.use_gpu() \
+ else torch.ByteTensor
+
+ self.netG, self.netD, self.netE = self.initialize_networks(opt)
+
+ # set loss functions
+ if opt.isTrain:
+ self.criterionGAN = networks.GANLoss(
+ opt.gan_mode, tensor=self.FloatTensor, opt=self.opt)
+ self.criterionFeat = torch.nn.L1Loss()
+ if not opt.no_vgg_loss:
+ self.criterionVGG = networks.VGGLoss(self.opt.gpu_ids)
+
+ # Entry point for all calls involving forward pass
+ # of deep networks. We used this approach since DataParallel module
+ # can't parallelize custom functions, we branch to different
+ # routines based on |mode|.
+ def forward(self, data, mode):
+ input_semantics, real_image = self.preprocess_input(data)
+
+ if mode == 'generator':
+ g_loss, generated = self.compute_generator_loss(
+ input_semantics, real_image)
+ return g_loss, generated
+ elif mode == 'discriminator':
+ d_loss = self.compute_discriminator_loss(
+ input_semantics, real_image)
+ return d_loss
+ elif mode == 'encode_only':
+ z, mu, logvar = self.encode_z(real_image)
+ return mu, logvar
+ elif mode == 'inference':
+ with torch.no_grad():
+ # fake_image, _ = self.generate_fake(input_semantics, real_image)
+ obj_dic = data['path']
+ fake_image = self.save_style_codes(input_semantics, real_image, obj_dic)
+ return fake_image
+ elif mode == 'UI_mode':
+ with torch.no_grad():
+ # fake_image, _ = self.generate_fake(input_semantics, real_image)
+
+ ################### some problems here
+ obj_dic = data['obj_dic']
+ # if isinstance(obj_dic, str):
+ # obj_dic = [obj_dic]
+ fake_image = self.use_style_codes(input_semantics, real_image, obj_dic)
+ return fake_image
+ elif mode == 'style_code':
+ with torch.no_grad():
+ style_codes = self.netG.Zencoder(input=real_image, segmap=input_semantics)
+ return style_codes
+ else:
+ raise ValueError("|mode| is invalid")
+
+ def create_optimizers(self, opt):
+ G_params = list(self.netG.parameters())
+ if opt.use_vae:
+ G_params += list(self.netE.parameters())
+ if opt.isTrain:
+ D_params = list(self.netD.parameters())
+
+ if opt.no_TTUR:
+ beta1, beta2 = opt.beta1, opt.beta2
+ G_lr, D_lr = opt.lr, opt.lr
+ else:
+ beta1, beta2 = 0, 0.9
+ G_lr, D_lr = opt.lr / 2, opt.lr * 2
+
+ optimizer_G = torch.optim.Adam(G_params, lr=G_lr, betas=(beta1, beta2))
+ optimizer_D = torch.optim.Adam(D_params, lr=D_lr, betas=(beta1, beta2))
+
+ return optimizer_G, optimizer_D
+
+ def save(self, epoch):
+ util.save_network(self.netG, 'G', epoch, self.opt)
+ util.save_network(self.netD, 'D', epoch, self.opt)
+
+ ############################################################################
+ # Private helper methods
+ ############################################################################
+
+ def initialize_networks(self, opt):
+ netG = networks.define_G(opt)
+ netD = networks.define_D(opt) if opt.isTrain else None
+ netE = networks.define_E(opt) if opt.use_vae else None
+
+ if not opt.isTrain or opt.continue_train:
+ netG = util.load_network(netG, 'G', opt.which_epoch, opt)
+ if opt.isTrain:
+ netD = util.load_network(netD, 'D', opt.which_epoch, opt)
+
+ return netG, netD, netE
+
+ # preprocess the input, such as moving the tensors to GPUs and
+ # transforming the label map to one-hot encoding
+ # |data|: dictionary of the input data
+
+ def preprocess_input(self, data):
+ # move to GPU and change data types
+ data['label'] = data['label'].long()
+ if self.use_gpu():
+ for param in ['label', 'instance', 'image']:
+ if param in data and data[param] is not None:
+ data[param] = data[param].cuda(non_blocking=True)
+ if 'obj_dic' in data:
+ for idx in range(19):
+ if data['obj_dic'][str(idx)]['ACE'].device.type == 'cpu':
+ data['obj_dic'][str(idx)]['ACE'] = data['obj_dic'][str(idx)]['ACE'].cuda(non_blocking=True)
+ # create one-hot label map
+ label_map = data['label']
+ bs, _, h, w = label_map.size()
+ nc = self.opt.label_nc + 1 if self.opt.contain_dontcare_label \
+ else self.opt.label_nc
+ input_label = self.FloatTensor(bs, nc, h, w).zero_()
+ input_semantics = input_label.scatter_(1, label_map, 1.0)
+
+ # concatenate instance map if it exists
+ if not self.opt.no_instance:
+ inst_map = data['instance']
+ instance_edge_map = self.get_edges(inst_map)
+ input_semantics = torch.cat((input_semantics, instance_edge_map), dim=1)
+
+ return input_semantics, data['image']
+
+ def compute_generator_loss(self, input_semantics, real_image):
+ G_losses = {}
+
+ fake_image = self.generate_fake(
+ input_semantics, real_image, compute_kld_loss=self.opt.use_vae)
+
+ pred_fake, pred_real = self.discriminate(
+ input_semantics, fake_image, real_image)
+
+ G_losses['GAN'] = self.criterionGAN(pred_fake, True,
+ for_discriminator=False)
+
+ if not self.opt.no_ganFeat_loss:
+ num_D = len(pred_fake)
+ GAN_Feat_loss = self.FloatTensor(1).fill_(0)
+ for i in range(num_D): # for each discriminator
+ # last color_texture is the final prediction, so we exclude it
+ num_intermediate_outputs = len(pred_fake[i]) - 1
+ for j in range(num_intermediate_outputs): # for each layer color_texture
+ unweighted_loss = self.criterionFeat(
+ pred_fake[i][j], pred_real[i][j].detach())
+ GAN_Feat_loss += unweighted_loss * self.opt.lambda_feat / num_D
+ G_losses['GAN_Feat'] = GAN_Feat_loss
+
+ if not self.opt.no_vgg_loss:
+ G_losses['VGG'] = self.criterionVGG(fake_image, real_image) \
+ * self.opt.lambda_vgg
+
+ return G_losses, fake_image
+
+ def compute_discriminator_loss(self, input_semantics, real_image):
+ D_losses = {}
+ with torch.no_grad():
+ fake_image = self.generate_fake(input_semantics, real_image)
+ fake_image = fake_image.detach()
+ fake_image.requires_grad_()
+
+ pred_fake, pred_real = self.discriminate(
+ input_semantics, fake_image, real_image)
+
+ D_losses['D_Fake'] = self.criterionGAN(pred_fake, False,
+ for_discriminator=True)
+ D_losses['D_real'] = self.criterionGAN(pred_real, True,
+ for_discriminator=True)
+
+ return D_losses
+
+ def encode_z(self, real_image):
+ mu, logvar = self.netE(real_image)
+ z = self.reparameterize(mu, logvar)
+ return z, mu, logvar
+
+ def generate_fake(self, input_semantics, real_image, compute_kld_loss=False):
+
+ fake_image = self.netG(input_semantics, real_image)
+
+ return fake_image
+
+ ###############################################################
+
+ def save_style_codes(self, input_semantics, real_image, obj_dic):
+
+ fake_image = self.netG(input_semantics, real_image, obj_dic=obj_dic)
+
+ return fake_image
+
+ def use_style_codes(self, input_semantics, real_image, obj_dic):
+ fake_image = self.netG(input_semantics, real_image, obj_dic=obj_dic)
+
+ return fake_image
+
+ # Given fake and real image, return the prediction of discriminator
+ # for each fake and real image.
+
+ def discriminate(self, input_semantics, fake_image, real_image):
+ fake_concat = torch.cat([input_semantics, fake_image], dim=1)
+ real_concat = torch.cat([input_semantics, real_image], dim=1)
+
+ # In Batch Normalization, the fake and real images are
+ # recommended to be in the same batch to avoid disparate
+ # statistics in fake and real images.
+ # So both fake and real images are fed to D all at once.
+ fake_and_real = torch.cat([fake_concat, real_concat], dim=0)
+
+ discriminator_out = self.netD(fake_and_real)
+
+ pred_fake, pred_real = self.divide_pred(discriminator_out)
+
+ return pred_fake, pred_real
+
+ # Take the prediction of fake and real images from the combined batch
+ def divide_pred(self, pred):
+ # the prediction contains the intermediate outputs of multiscale GAN,
+ # so it's usually a list
+ if type(pred) == list:
+ fake = []
+ real = []
+ for p in pred:
+ fake.append([tensor[:tensor.size(0) // 2] for tensor in p])
+ real.append([tensor[tensor.size(0) // 2:] for tensor in p])
+ else:
+ fake = pred[:pred.size(0) // 2]
+ real = pred[pred.size(0) // 2:]
+
+ return fake, real
+
+ def get_edges(self, t):
+ edge = self.ByteTensor(t.size()).zero_()
+ edge[:, :, :, 1:] = edge[:, :, :, 1:] | (t[:, :, :, 1:] != t[:, :, :, :-1])
+ edge[:, :, :, :-1] = edge[:, :, :, :-1] | (t[:, :, :, 1:] != t[:, :, :, :-1])
+ edge[:, :, 1:, :] = edge[:, :, 1:, :] | (t[:, :, 1:, :] != t[:, :, :-1, :])
+ edge[:, :, :-1, :] = edge[:, :, :-1, :] | (t[:, :, 1:, :] != t[:, :, :-1, :])
+ return edge.float()
+
+ def reparameterize(self, mu, logvar):
+ std = torch.exp(0.5 * logvar)
+ eps = torch.randn_like(std)
+ return eps.mul(std) + mu
+
+ def use_gpu(self):
+ return len(self.opt.gpu_ids) > 0
diff --git a/models/CtrlHair/sean_codes/options/__init__.py b/models/CtrlHair/sean_codes/options/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba4ddb2d78be7bbf79bb0671eefd9296d3a168b7
--- /dev/null
+++ b/models/CtrlHair/sean_codes/options/__init__.py
@@ -0,0 +1,4 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
\ No newline at end of file
diff --git a/models/CtrlHair/sean_codes/options/base_options.py b/models/CtrlHair/sean_codes/options/base_options.py
new file mode 100644
index 0000000000000000000000000000000000000000..7764e869119caa27e736b9cb6294842bb540286b
--- /dev/null
+++ b/models/CtrlHair/sean_codes/options/base_options.py
@@ -0,0 +1,180 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+import sys
+import argparse
+import os
+from util import util
+import torch
+from sean_codes import models, data
+import pickle
+
+
+class BaseOptions():
+ def __init__(self):
+ self.initialized = False
+
+ def initialize(self, parser):
+ # experiment specifics
+ parser.add_argument('--name', type=str, default='CelebA-HQ_pretrained',
+ help='name of the experiment. It decides where to store samples and models')
+
+ parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
+ parser.add_argument('--checkpoints_dir', type=str, default='external_model_params/sean_checkpoints',
+ help='models are saved here')
+ parser.add_argument('--model', type=str, default='pix2pix', help='which model to use')
+ parser.add_argument('--norm_G', type=str, default='spectralinstance', help='instance normalization or batch normalization')
+ parser.add_argument('--norm_D', type=str, default='spectralinstance', help='instance normalization or batch normalization')
+ parser.add_argument('--norm_E', type=str, default='spectralinstance', help='instance normalization or batch normalization')
+ parser.add_argument('--phase', type=str, default='scripts', help='scripts, val, test, etc')
+
+ # input/color_texture sizes
+ parser.add_argument('--batchSize', type=int, default=1, help='input batch size')
+ parser.add_argument('--preprocess_mode', type=str, default='scale_width_and_crop', help='scaling and cropping of images at load time.', choices=("resize_and_crop", "crop", "scale_width", "scale_width_and_crop", "scale_shortside", "scale_shortside_and_crop", "fixed", "none"))
+ parser.add_argument('--load_size', type=int, default=256, help='Scale images to this size. The final image will be cropped to --crop_size.')
+ parser.add_argument('--crop_size', type=int, default=256, help='Crop to the width of crop_size (after initially scaling the images to load_size.)')
+ parser.add_argument('--aspect_ratio', type=float, default=1.0, help='The ratio width/height. The final height of the load image will be crop_size/aspect_ratio')
+ parser.add_argument('--label_nc', type=int, default=19, help='# of input label classes without unknown class. If you have unknown class as class label, specify --contain_dopntcare_label.')
+ parser.add_argument('--contain_dontcare_label', action='store_true', help='if the label map contains dontcare label (dontcare=255)')
+ parser.add_argument('--output_nc', type=int, default=3, help='# of color_texture image channels')
+
+ # for setting inputs
+ parser.add_argument('--dataroot', type=str, default='./datasets/cityscapes/')
+ parser.add_argument('--dataset_mode', type=str, default='custom')
+ parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
+ parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data argumentation')
+ parser.add_argument('--nThreads', default=28, type=int, help='# threads for loading data')
+ parser.add_argument('--max_dataset_size', type=int, default=sys.maxsize, help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
+ parser.add_argument('--load_from_opt_file', action='store_true', help='load the options from sean_checkpoints and use that as default')
+ parser.add_argument('--cache_filelist_write', action='store_true', help='saves the current filelist into a text file, so that it loads faster')
+ parser.add_argument('--cache_filelist_read', action='store_true', help='reads from the file list cache')
+
+ # for displays
+ parser.add_argument('--display_winsize', type=int, default=400, help='display window size')
+
+ # for generator
+ parser.add_argument('--netG', type=str, default='spade', help='selects model to use for netG (pix2pixhd | spade)')
+ parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in first conv layer')
+ parser.add_argument('--init_type', type=str, default='xavier', help='network initialization [normal|xavier|kaiming|orthogonal]')
+ parser.add_argument('--init_variance', type=float, default=0.02, help='variance of the initialization distribution')
+ parser.add_argument('--z_dim', type=int, default=256,
+ help="dimension of the latent z vector")
+
+ # for instance-wise features
+ parser.add_argument('--no_instance', type=bool, default=True,
+ help='if specified, do *not* add instance map as input')
+ parser.add_argument('--nef', type=int, default=16, help='# of encoder filters in the first conv layer')
+ parser.add_argument('--use_vae', action='store_true', help='enable training with an image encoder.')
+
+ self.initialized = True
+ return parser
+
+ def gather_options(self):
+ # initialize parser with basic options
+ if not self.initialized:
+ parser = argparse.ArgumentParser(
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser = self.initialize(parser)
+
+ # get the basic options
+ opt, unknown = parser.parse_known_args()
+
+ # modify model-related parser options
+ model_name = opt.model
+ model_option_setter = models.get_option_setter(model_name)
+ parser = model_option_setter(parser, self.isTrain)
+
+ # modify dataset-related parser options
+ dataset_mode = opt.dataset_mode
+ dataset_option_setter = data.get_option_setter(dataset_mode)
+ parser = dataset_option_setter(parser, self.isTrain)
+
+ opt, unknown = parser.parse_known_args()
+
+ # if there is opt_file, load it.
+ # The previous default options will be overwritten
+ if opt.load_from_opt_file:
+ parser = self.update_options_from_file(parser, opt)
+
+ opt = parser.parse_args()
+ self.parser = parser
+ return opt
+
+ def print_options(self, opt):
+ message = ''
+ message += '----------------- Options ---------------\n'
+ for k, v in sorted(vars(opt).items()):
+ comment = ''
+ default = self.parser.get_default(k)
+ if v != default:
+ comment = '\t[default: %s]' % str(default)
+ message += '{:>25}: {:<30}{}\n'.format(str(k), str(v), comment)
+ message += '----------------- End -------------------'
+ print(message)
+
+ def option_file_path(self, opt, makedir=False):
+ expr_dir = os.path.join(opt.checkpoints_dir, opt.name)
+ if makedir:
+ util.mkdirs(expr_dir)
+ file_name = os.path.join(expr_dir, 'opt')
+ return file_name
+
+ def save_options(self, opt):
+ file_name = self.option_file_path(opt, makedir=True)
+ with open(file_name + '.txt', 'wt') as opt_file:
+ for k, v in sorted(vars(opt).items()):
+ comment = ''
+ default = self.parser.get_default(k)
+ if v != default:
+ comment = '\t[default: %s]' % str(default)
+ opt_file.write('{:>25}: {:<30}{}\n'.format(str(k), str(v), comment))
+
+ with open(file_name + '.pkl', 'wb') as opt_file:
+ pickle.dump(opt, opt_file)
+
+ def update_options_from_file(self, parser, opt):
+ new_opt = self.load_options(opt)
+ for k, v in sorted(vars(opt).items()):
+ if hasattr(new_opt, k) and v != getattr(new_opt, k):
+ new_val = getattr(new_opt, k)
+ parser.set_defaults(**{k: new_val})
+ return parser
+
+ def load_options(self, opt):
+ file_name = self.option_file_path(opt, makedir=False)
+ new_opt = pickle.load(open(file_name + '.pkl', 'rb'))
+ return new_opt
+
+ def parse(self, save=False):
+
+ opt = self.gather_options()
+ opt.isTrain = self.isTrain # scripts or test
+
+ # self.print_options(opt)
+ if opt.isTrain:
+ self.save_options(opt)
+
+ # Set semantic_nc based on the option.
+ # This will be convenient in many places
+ opt.semantic_nc = opt.label_nc + \
+ (1 if opt.contain_dontcare_label else 0) + \
+ (0 if opt.no_instance else 1)
+
+ # set gpu ids
+ str_ids = opt.gpu_ids.split(',')
+ opt.gpu_ids = []
+ for str_id in str_ids:
+ id = int(str_id)
+ if id >= 0:
+ opt.gpu_ids.append(id)
+ if len(opt.gpu_ids) > 0:
+ torch.cuda.set_device(opt.gpu_ids[0])
+
+ assert len(opt.gpu_ids) == 0 or opt.batchSize % len(opt.gpu_ids) == 0, \
+ "Batch size %d is wrong. It must be a multiple of # GPUs %d." \
+ % (opt.batchSize, len(opt.gpu_ids))
+
+ self.opt = opt
+ return self.opt
diff --git a/models/CtrlHair/sean_codes/options/test_options.py b/models/CtrlHair/sean_codes/options/test_options.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7e06df9ac5e17c875623c9c54cfeb1d6c54616e
--- /dev/null
+++ b/models/CtrlHair/sean_codes/options/test_options.py
@@ -0,0 +1,27 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+from util.common_options import ctrl_hair_parser_options
+from .base_options import BaseOptions
+
+
+class TestOptions(BaseOptions):
+ def initialize(self, parser):
+ BaseOptions.initialize(self, parser)
+ parser.add_argument('--results_dir', type=str, default='./results/', help='saves results here.')
+ parser.add_argument('--which_epoch', type=str, default='latest',
+ help='which epoch to load? set to latest to use latest cached model')
+ parser.add_argument('--how_many', type=int, default=float("inf"), help='how many test images to run')
+
+ parser.set_defaults(preprocess_mode='scale_width_and_crop', crop_size=256, load_size=256, display_winsize=256)
+ parser.set_defaults(serial_batches=True)
+ parser.set_defaults(no_flip=True)
+ parser.set_defaults(phase='test')
+
+ parser.add_argument('--status', type=str, default='test')
+
+ ctrl_hair_parser_options(parser)
+
+ self.isTrain = False
+ return parser
diff --git a/models/CtrlHair/sean_codes/options/train_options.py b/models/CtrlHair/sean_codes/options/train_options.py
new file mode 100644
index 0000000000000000000000000000000000000000..1eb1496ab13f5d57eac9460583d82a931fd9a68c
--- /dev/null
+++ b/models/CtrlHair/sean_codes/options/train_options.py
@@ -0,0 +1,46 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+from .base_options import BaseOptions
+
+
+class TrainOptions(BaseOptions):
+ def initialize(self, parser):
+ BaseOptions.initialize(self, parser)
+ # for displays
+ parser.add_argument('--display_freq', type=int, default=100, help='frequency of showing training results on screen')
+ parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
+ parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
+ parser.add_argument('--save_epoch_freq', type=int, default=10, help='frequency of saving sean_checkpoints at the end of epochs')
+ parser.add_argument('--no_html', default=False, help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
+ parser.add_argument('--debug', action='store_true', help='only do one epoch and displays at each iteration')
+ parser.add_argument('--tf_log', action='store_true', help='if specified, use tensorboard logging. Requires tensorflow installed')
+
+ # for training
+ parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
+ parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
+ parser.add_argument('--niter', type=int, default=50, help='# of iter at starting learning rate. This is NOT the total #epochs. Totla #epochs is niter + niter_decay')
+ parser.add_argument('--niter_decay', type=int, default=50, help='# of iter to linearly decay learning rate to zero')
+ parser.add_argument('--optimizer', type=str, default='adam')
+ parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
+ parser.add_argument('--beta2', type=float, default=0.999, help='momentum term of adam')
+ parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
+ parser.add_argument('--D_steps_per_G', type=int, default=1, help='number of discriminator iterations per generator iterations.')
+
+ # for discriminators
+ parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in first conv layer')
+ parser.add_argument('--lambda_feat', type=float, default=10.0, help='weight for feature matching loss')
+ parser.add_argument('--lambda_vgg', type=float, default=10.0, help='weight for vgg loss')
+ parser.add_argument('--no_ganFeat_loss', action='store_true', help='if specified, do *not* use discriminator feature matching loss')
+ parser.add_argument('--no_vgg_loss', action='store_true', help='if specified, do *not* use VGG feature matching loss')
+ parser.add_argument('--gan_mode', type=str, default='hinge', help='(ls|original|hinge)')
+ parser.add_argument('--netD', type=str, default='multiscale', help='(n_layers|multiscale|image)')
+ parser.add_argument('--no_TTUR', action='store_true', help='Use TTUR training scheme')
+ parser.add_argument('--lambda_kld', type=float, default=0.005)
+
+ parser.add_argument('--status', type=str, default='scripts')
+
+ self.isTrain = True
+ return parser
diff --git a/models/CtrlHair/sean_codes/trainers/__init__.py b/models/CtrlHair/sean_codes/trainers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c23f2831952e1a35fd8f170760c627f7fb20ed9
--- /dev/null
+++ b/models/CtrlHair/sean_codes/trainers/__init__.py
@@ -0,0 +1,4 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
diff --git a/models/CtrlHair/sean_codes/trainers/pix2pix_trainer.py b/models/CtrlHair/sean_codes/trainers/pix2pix_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..988f3244fe6d5152b0e51561635066432dfd0b77
--- /dev/null
+++ b/models/CtrlHair/sean_codes/trainers/pix2pix_trainer.py
@@ -0,0 +1,86 @@
+"""
+Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
+Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
+"""
+
+from sean_codes.models.networks.sync_batchnorm import DataParallelWithCallback
+from sean_codes.models.pix2pix_model import Pix2PixModel
+
+
+class Pix2PixTrainer():
+ """
+ Trainer creates the model and optimizers, and uses them to
+ updates the weights of the network while reporting losses
+ and the latest visuals to visualize the progress in training.
+ """
+
+ def __init__(self, opt):
+ self.opt = opt
+ self.pix2pix_model = Pix2PixModel(opt)
+ if len(opt.gpu_ids) > 0:
+ self.pix2pix_model = DataParallelWithCallback(self.pix2pix_model,
+ device_ids=opt.gpu_ids)
+ self.pix2pix_model_on_one_gpu = self.pix2pix_model.module
+ else:
+ self.pix2pix_model_on_one_gpu = self.pix2pix_model
+
+ self.generated = None
+ if opt.isTrain:
+ self.optimizer_G, self.optimizer_D = \
+ self.pix2pix_model_on_one_gpu.create_optimizers(opt)
+ self.old_lr = opt.lr
+
+ def run_generator_one_step(self, data):
+ self.optimizer_G.zero_grad()
+ g_losses, generated = self.pix2pix_model(data, mode='generator')
+ g_loss = sum(g_losses.values()).mean()
+ g_loss.backward()
+ self.optimizer_G.step()
+ self.g_losses = g_losses
+ self.generated = generated
+
+ def run_discriminator_one_step(self, data):
+ self.optimizer_D.zero_grad()
+ d_losses = self.pix2pix_model(data, mode='discriminator')
+ d_loss = sum(d_losses.values()).mean()
+ d_loss.backward()
+ self.optimizer_D.step()
+ self.d_losses = d_losses
+
+ def get_latest_losses(self):
+ return {**self.g_losses, **self.d_losses}
+
+ def get_latest_generated(self):
+ return self.generated
+
+ def update_learning_rate(self, epoch):
+ self.update_learning_rate(epoch)
+
+ def save(self, epoch):
+ self.pix2pix_model_on_one_gpu.save(epoch)
+
+ ##################################################################
+ # Helper functions
+ ##################################################################
+
+ def update_learning_rate(self, epoch):
+ if epoch > self.opt.niter:
+ lrd = self.opt.lr / self.opt.niter_decay
+ new_lr = self.old_lr - lrd
+ else:
+ new_lr = self.old_lr
+
+ if new_lr != self.old_lr:
+ if self.opt.no_TTUR:
+ new_lr_G = new_lr
+ new_lr_D = new_lr
+ else:
+ new_lr_G = new_lr / 2
+ new_lr_D = new_lr * 2
+
+ for param_group in self.optimizer_D.param_groups:
+ param_group['lr'] = new_lr_D
+ for param_group in self.optimizer_G.param_groups:
+ param_group['lr'] = new_lr_G
+ print('update learning rate: %f -> %f' % (self.old_lr, new_lr))
+ self.old_lr = new_lr
diff --git a/models/CtrlHair/shape_branch/__init__.py b/models/CtrlHair/shape_branch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f414ceb4ca3fb00e06f3d1bd91786d4f1b0b3dd
--- /dev/null
+++ b/models/CtrlHair/shape_branch/__init__.py
@@ -0,0 +1,8 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py.py
+# Time : 2021/12/31 15:28
+# Author: xyguoo@163.com
+# Description:
+"""
diff --git a/models/CtrlHair/shape_branch/adaptor_generation.py b/models/CtrlHair/shape_branch/adaptor_generation.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6fb7208561e7c7d9b338a6eb6c62181ec5befa1
--- /dev/null
+++ b/models/CtrlHair/shape_branch/adaptor_generation.py
@@ -0,0 +1,114 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: adaptor_generation.py
+# Time : 2021/12/31 19:35
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+import os
+
+pp = os.path.abspath(os.path.join(os.path.abspath(__file__), '../..'))
+sys.path.append(pp)
+
+import os
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+from wrap_codes.mask_adaptor import wrap_for_image_with_idx
+from common_dataset import DataFilter
+from shape_branch.config import cfg
+from global_value_utils import HAIR_IDX, TEMP_FOLDER
+from util.util import path_join_abs
+import cv2
+import threading
+import random
+import time
+import glob
+import tqdm
+
+def generate_mask_to_pool(root_dir, hair_dir, face_dir, hair_base_path, face_base_path, pool_dir, temp_wrap_dir,
+ thread_id, find_repeat, only_hair):
+ face_num = face_base_path[-9:-4]
+ hair_num = hair_base_path[-9:-4]
+ output_name = os.path.join(pool_dir, '%s___%s___%s___%s___%02d.png') % (
+ hair_dir, hair_num, face_dir, face_num, thread_id)
+ find_res = []
+ if find_repeat:
+ find_res = glob.glob(os.path.join(pool_dir, '%s___%s___%s___%s___*.png') % (
+ hair_dir, hair_num, face_dir, face_num))
+ if len(find_res) == 0:
+ print('Generate thread %d: %s %s to %s %s' % (thread_id, hair_dir, hair_num, face_dir, face_num))
+ align_mask = wrap_for_image_with_idx(root_dir, hair_dir, face_dir,
+ hair_base_path, face_base_path,
+ wrap_temp_folder=temp_wrap_dir)[0]
+ if only_hair:
+ output_img = (align_mask == HAIR_IDX) * 255
+ else:
+ output_img = align_mask
+ cv2.imwrite(output_name, output_img)
+ else:
+ print('Hit for %s' % output_name)
+
+
+class AdaptorPoolGeneration:
+ def __init__(self, only_hair, dir_name, test_dir_name, thread_num=10, max_file=1e7):
+ self.data_filter = DataFilter(cfg)
+ self.pool_dir = os.path.join(cfg.data_root, dir_name)
+ self.pool_test_dir = os.path.join(cfg.data_root, test_dir_name)
+ self.max_file = max_file
+ self.only_hair = only_hair
+ for p in [self.pool_dir, self.pool_test_dir]:
+ if not os.path.exists(p):
+ os.makedirs(p)
+ self.thread_num = thread_num
+
+ def generate_test_set(self, img_num=100):
+ temp_wrap_dir = os.path.join(TEMP_FOLDER, 'wrap_triangle/temp_wrap_test')
+
+ for hair in tqdm.tqdm(self.data_filter.test_hair_list[:img_num]):
+ for face in self.data_filter.test_face_list[:img_num]:
+ hair_dir = hair.split('/')[-3]
+ face_dir = face.split('/')[-3]
+ base_hair = os.path.split(hair)[-1]
+ base_face = os.path.split(face)[-1]
+ generate_mask_to_pool(cfg.data_root, hair_dir, face_dir, base_hair, base_face,
+ self.pool_test_dir, temp_wrap_dir, 0, find_repeat=False, only_hair=self.only_hair)
+
+ def run(self):
+ self.threads = []
+ for idx in range(self.thread_num):
+ t = threading.Thread(target=self.generate_thread, args=[idx])
+ self.threads.append(t)
+ for thread in self.threads:
+ thread.start()
+
+ def generate_thread(self, thread_idx):
+ temp_wrap_dir = os.path.join(TEMP_FOLDER, 'wrap_triangle/temp_wrap_%d' % thread_idx)
+ random.seed(time.time())
+ while True:
+ if len(os.listdir(self.pool_dir)) < self.max_file:
+ for _ in range(100):
+ while True:
+ hair_path = random.choice(self.data_filter.train_list)
+ hair_num = hair_path[-9:-4]
+ hair_dir = hair_path.split('/')[-3]
+ if self.data_filter.valid_hair(path_join_abs(hair_path, '../..'), hair_num):
+ break
+ while True:
+ face_path = random.choice(self.data_filter.train_list)
+ face_num = face_path[-9:-4]
+ face_dir = face_path.split('/')[-3]
+ if self.data_filter.valid_face(path_join_abs(face_path, '../..'), face_num):
+ break
+ try:
+ generate_mask_to_pool(cfg.data_root, hair_dir, face_dir,
+ os.path.basename(hair_path), os.path.basename(face_path),
+ self.pool_dir, temp_wrap_dir,
+ thread_idx, find_repeat=False, only_hair=self.only_hair)
+ except Exception as e:
+ print(repr(e))
+ else:
+ print('Full, so sleep in thread %d' % thread_idx)
+ time.sleep(3.0)
diff --git a/models/CtrlHair/shape_branch/config.py b/models/CtrlHair/shape_branch/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca6f79c7fbe9e71f83b1d4b3cf30d1b934cf58ed
--- /dev/null
+++ b/models/CtrlHair/shape_branch/config.py
@@ -0,0 +1,129 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: config.py
+# Time : 2021/11/17 13:10
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import addict # nesting dict
+import os
+import argparse
+
+from models.CtrlHair.global_value_utils import GLOBAL_DATA_ROOT, DEFAULT_CONFIG_SHAPE_BRANCH
+
+configs = [
+ addict.Dict({
+ "experiment_name": "054__succeed__049__gan_fake_0.5_from_noise",
+ 'hair_dim': 16,
+ 'pos_encoding_order': 10,
+ 'lambda_hair': 100,
+ 'lambda_non_hair': 100,
+ 'lambda_face': 20,
+ 'lambda_self_rec': 5,
+ 'lambda_kl': 0.1,
+ 'regular_method': 'ce',
+ 'full_dataset': True,
+ 'only_celeba_as_real': True,
+ 'g_norm': 'ln',
+ 'd_norm': 'none',
+ 'lr_g': 0.0002,
+ 'lambda_adv_noise': 1,
+ 'lambda_gp_0_noise': 10,
+ 'total_batch_size': 4,
+ 'random_ae_prob': 0.5,
+ 'lr_dz': 0.00005,
+ 'adaptor_test_pool_dir': 'shape_testing_wrap_pool',
+ 'adaptor_pool_dir': 'shape_training_wrap_pool'
+ }),
+]
+
+
+def get_config(configs, config_id):
+ for c in configs:
+ if c.experiment_name.startswith(config_id):
+ check_add_default_value_to_base_cfg(c)
+ return c
+
+
+def check_add_default_value_to_base_cfg(cfg):
+ add_default_value_to_cfg(cfg, 'lr_d', 0.0001)
+ add_default_value_to_cfg(cfg, 'lr_g', 0.0002)
+ add_default_value_to_cfg(cfg, 'lr_dz', 0.0001)
+ add_default_value_to_cfg(cfg, 'beta1', 0.5)
+ add_default_value_to_cfg(cfg, 'beta2', 0.999)
+
+ add_default_value_to_cfg(cfg, 'total_step', 380002)
+ add_default_value_to_cfg(cfg, 'log_step', 10)
+ add_default_value_to_cfg(cfg, 'sample_step', 10000)
+ add_default_value_to_cfg(cfg, 'model_save_step', 10000)
+ add_default_value_to_cfg(cfg, 'sample_batch_size', 16)
+ add_default_value_to_cfg(cfg, 'max_save', 1)
+ add_default_value_to_cfg(cfg, 'vae_var_output', 'var')
+ add_default_value_to_cfg(cfg, 'SEAN_code', 512)
+ add_default_value_to_cfg(cfg, 'd_hidden_in_channel', 16)
+
+ # Model configuration
+ add_default_value_to_cfg(cfg, 'total_batch_size', 4)
+ add_default_value_to_cfg(cfg, 'gan_type', 'hinge2')
+ add_default_value_to_cfg(cfg, 'lambda_gp_0', 10.0)
+ add_default_value_to_cfg(cfg, 'lambda_adv', 1.0)
+
+ add_default_value_to_cfg(cfg, 'g_norm', 'bn')
+ add_default_value_to_cfg(cfg, 'd_norm', 'bn')
+ add_default_value_to_cfg(cfg, 'init_type', 'normal')
+ add_default_value_to_cfg(cfg, 'G_D_train_num', {'G': 1, 'D': 1}, )
+ add_default_value_to_cfg(cfg, 'vae_hair_mode', True)
+
+ output_root_dir = 'model_trained/shape/%s' % cfg['experiment_name']
+ add_default_value_to_cfg(cfg, 'root_dir', output_root_dir)
+ add_default_value_to_cfg(cfg, 'log_dir', output_root_dir + '/summaries')
+ add_default_value_to_cfg(cfg, 'checkpoints_dir', output_root_dir + '/checkpoints')
+ add_default_value_to_cfg(cfg, 'sample_dir', output_root_dir + '/sample_training')
+
+ try:
+ add_default_value_to_cfg(cfg, 'gpu_num', len(args.gpu.split(',')))
+ except:
+ add_default_value_to_cfg(cfg, 'gpu_num', 1)
+ add_default_value_to_cfg(cfg, 'img_size', 256)
+ add_default_value_to_cfg(cfg, 'data_root', GLOBAL_DATA_ROOT)
+
+ # dz discriminator
+ add_default_value_to_cfg(cfg, 'd_hidden_dim', 256)
+ add_default_value_to_cfg(cfg, 'd_noise_hidden_layer_num', 3)
+
+
+def add_default_value_to_cfg(cfg, key, value):
+ if key not in cfg:
+ cfg[key] = value
+
+
+def merge_config_in_place(ori_cfg, new_cfg):
+ for k in new_cfg:
+ ori_cfg[k] = new_cfg[k]
+
+
+def back_process(cfg):
+ cfg.batch_size = cfg.total_batch_size // cfg.gpu_num
+
+
+def get_basic_arg_parser():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, help='Specify config number', default=DEFAULT_CONFIG_SHAPE_BRANCH)
+ parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
+ parser.add_argument('--local_rank', type=int, default=-1)
+ return parser
+
+
+import sys
+
+if sys.argv[0].endswith('shape_branch/scripts.py') or sys.argv[0].endswith('shape_branch/script_find_direction.py'):
+ parser = get_basic_arg_parser()
+ args = parser.parse_args()
+ cfg = get_config(configs, args.config)
+ os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
+ back_process(cfg)
+else:
+ cfg = get_config(configs, DEFAULT_CONFIG_SHAPE_BRANCH)
+ back_process(cfg)
diff --git a/models/CtrlHair/shape_branch/dataset.py b/models/CtrlHair/shape_branch/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..8530fa42615057a9cbfeae43ff153ad6fd24a584
--- /dev/null
+++ b/models/CtrlHair/shape_branch/dataset.py
@@ -0,0 +1,192 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: dataset.py
+# Time : 2021/11/16 21:24
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+
+import cv2
+
+from common_dataset import DataFilter
+import random
+import pickle
+import torch
+from torchvision import transforms as tform
+from PIL import Image
+
+from global_value_utils import GLOBAL_DATA_ROOT
+from util.util import path_join_abs
+
+
+class Dataset(DataFilter):
+
+ def __init__(self, cfg, rank=0):
+ super().__init__(cfg)
+ self.cfg = cfg
+
+ img_size = 256
+ self.__setattr__('mask_transform_%d' % img_size,
+ tform.Compose([tform.Resize(img_size, interpolation=Image.NEAREST),
+ tform.ToTensor(),
+ tform.Lambda(lambda x: 255 * x)]))
+ self.__setattr__('mask_transform_mirror_%d' % img_size,
+ tform.Compose([tform.Resize(img_size, interpolation=Image.NEAREST),
+ tform.Lambda(lambda x: tform.functional.hflip(x)),
+ tform.ToTensor(),
+ tform.Lambda(lambda x: 255 * x)]))
+
+ self.mask_pool_dir = os.path.join(cfg.data_root, cfg.adaptor_pool_dir)
+ self.mask_test_pool_dir = os.path.join(cfg.data_root, cfg.adaptor_test_pool_dir)
+ self.mask_buffer = []
+ self.local_rank = rank
+ random.seed(self.random_seed + self.local_rank + 1)
+
+ if self.cfg.only_celeba_as_real: # CelebA Mask is the manual mask, which has strong realism
+ self.dis_real_list = [st for st in self.train_list if 'CelebaMask' in st]
+
+ self.data_root = GLOBAL_DATA_ROOT
+ with open(os.path.join(self.data_root, 'sean_code_dict.pkl'), 'rb') as f:
+ self.sean_code_dict = pickle.load(f)
+
+ def get_by_file_name(self, size, img_path=None, validate_func=None, mirror=False, data_list=None, need_img=False):
+ if data_list is None:
+ data_list = self.train_list
+
+ if img_path is None:
+ while True:
+ random_idx = random.randint(0, len(data_list) - 1)
+ img_path = data_list[random_idx]
+ if validate_func is None or validate_func(path_join_abs(img_path, '../..'), img_path[-9:-4]):
+ break
+ if data_list is self.train_list:
+ self.train_list = self.train_list[:random_idx] + self.train_list[random_idx + 1:]
+ else:
+ data_list = data_list[:random_idx] + data_list[random_idx + 1:]
+
+ if mirror:
+ mask_transform = self.__getattribute__('mask_transform_mirror_%d' % size)
+ else:
+ mask_transform = self.__getattribute__('mask_transform_%d' % size)
+
+ base_num = img_path[-9:-4]
+ mask_path = path_join_abs(img_path, '../../label', base_num + '.png')
+ mask = mask_transform(Image.open(mask_path))
+
+ if need_img:
+ img = cv2.imread(img_path)
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ return mask, img
+ return mask
+
+ def get_pair_file_randomly_from_buffer(self):
+ if len(self.mask_buffer) == 0:
+ self.mask_buffer = os.listdir(self.mask_pool_dir)
+ random.shuffle(self.mask_buffer)
+ return self.mask_buffer.pop()
+
+ def get_pair_randomly_from_pool(self, img_size):
+ mask_file = self.get_pair_file_randomly_from_buffer()
+ file_parts = mask_file.split('___')
+ hair_dir, hair, face_dir, face = file_parts[:4]
+ images_dir = 'label'
+ mirror = (random.random() > 0.5)
+ face_img, target_hair_mask, hair_img = self.get_adaptor_pair_mask(
+ path_join_abs(self.cfg.data_root, face_dir, images_dir, '%s.png' % face),
+ path_join_abs(self.cfg.data_root, hair_dir, images_dir, '%s.png' % hair),
+ img_size, self.mask_pool_dir, mirror=mirror, mask_thread_num=file_parts[-1][:2])
+ return face_img, target_hair_mask, hair_img
+
+ def get_adaptor_pair_mask(self, face_path, hair_path, img_size, mask_pool_dir, mirror=False, mask_thread_num='00',
+ need_img=False):
+ if need_img:
+ face_mask, face_img = self.get_by_file_name(img_size, face_path, mirror=mirror, need_img=need_img)
+ hair_mask, hair_img = self.get_by_file_name(img_size, hair_path, mirror=mirror, need_img=need_img)
+ else:
+ face_mask = self.get_by_file_name(img_size, face_path, mirror=mirror, need_img=need_img)
+ hair_mask = self.get_by_file_name(img_size, hair_path, mirror=mirror, need_img=need_img)
+ face_base_path = os.path.basename(face_path)[:-4]
+ hair_base_path = os.path.basename(hair_path)[:-4]
+ face_dir = face_path.split('/')[-3]
+ hair_dir = hair_path.split('/')[-3]
+ target_mask_path = os.path.join(mask_pool_dir, '%s___%s___%s___%s___%s.png' % (
+ hair_dir, hair_base_path, face_dir, face_base_path, mask_thread_num))
+ if mirror:
+ transform_func = self.__getattribute__('mask_transform_mirror_%d' % img_size)
+ else:
+ transform_func = self.__getattribute__('mask_transform_%d' % img_size)
+
+ target_hair_mask = transform_func(Image.open(target_mask_path))
+ if need_img:
+ return face_mask, target_hair_mask, hair_mask, face_img, hair_img
+ else:
+ return face_mask, target_hair_mask, hair_mask
+
+ def get_random_pair_batch(self, batch_size, img_size=None):
+ if not img_size:
+ img_size = self.cfg.img_size
+ face_imgs, target_hair_masks, hair_imgs = [], [], []
+ while len(face_imgs) < batch_size:
+ face_img, target_hair_mask, hair_img = \
+ self.get_pair_randomly_from_pool(img_size)
+ face_imgs.append(face_img)
+ target_hair_masks.append(target_hair_mask)
+ hair_imgs.append(hair_img)
+ results = [face_imgs, target_hair_masks, hair_imgs]
+ for idx in range(len(results)):
+ results[idx] = torch.stack(results[idx], dim=0)
+ return {'face': results[0], 'target': results[1], 'hair': results[2]}
+
+ def get_random_single_batch(self, batch_size):
+ face_imgs = []
+ while len(face_imgs) < batch_size:
+ if self.cfg.only_celeba_as_real:
+ face_img = self.get_by_file_name(256, validate_func=self.valid_hair, mirror=(random.random() > 0.5),
+ data_list=self.dis_real_list)
+ else:
+ face_img = self.get_by_file_name(256, validate_func=self.valid_hair, mirror=(random.random() > 0.5))
+ face_imgs.append(face_img)
+ face_imgs = torch.stack(face_imgs, dim=0)
+ return face_imgs
+
+ def get_test_batch(self, batch_size=32, img_size=None):
+ if not img_size:
+ img_size = self.cfg.img_size
+ face_masks, target_hair_masks, hair_masks, sean_codes, face_imgs, hair_imgs = [], [], [], [], [], []
+
+ idx = 0
+ while len(face_masks) < batch_size:
+ face_maks_path = self.test_face_list[idx]
+ hair_mask_path = self.test_hair_list[idx]
+ idx += 1
+ face_mask, target_hair_mask, hair_mask, face_img, hair_img = \
+ self.get_adaptor_pair_mask(face_maks_path, hair_mask_path, img_size, self.mask_test_pool_dir,
+ need_img=True)
+ face_masks.append(face_mask)
+ target_hair_masks.append(target_hair_mask)
+ hair_masks.append(hair_mask)
+
+ face_path_parts = face_maks_path.split('/')
+ sean_codes.append(torch.tensor(
+ self.sean_code_dict['___'.join([face_path_parts[-3], face_path_parts[-1][:-4]])]))
+
+ face_imgs.append(torch.tensor(face_img))
+ hair_imgs.append(torch.tensor(hair_img))
+
+ face_masks = torch.stack(face_masks, dim=0)
+ hair_masks = torch.stack(hair_masks, dim=0)
+ target_hair_masks = torch.stack(target_hair_masks, dim=0)
+
+ return {'face': face_masks, 'target': target_hair_masks, 'hair': hair_masks, 'sean_code': sean_codes,
+ 'face_imgs': face_imgs, 'hair_imgs': hair_imgs}
+
+
+if __name__ == '__main__':
+ from shape_branch.config import cfg
+
+ ds = Dataset(cfg)
+ # resources = ds.get_training_batch(8)
+ res = ds.get_random_inpainting_batch(9)
+ pass
diff --git a/models/CtrlHair/shape_branch/model.py b/models/CtrlHair/shape_branch/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddcaac120222e6b27639f8b16e4b3ce65ad5f9fe
--- /dev/null
+++ b/models/CtrlHair/shape_branch/model.py
@@ -0,0 +1,232 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: model.py
+# Time : 2021/11/17 15:37
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import torch.nn as nn
+from models.CtrlHair.my_torchlib.module import LinearBlock, Conv2dBlock
+import torch
+from torch.nn import init
+import numpy as np
+from models.CtrlHair.global_value_utils import HAIR_IDX
+
+
+def generate_pos_embedding(img_size, order=10):
+ coordinators = np.linspace(0, 1, img_size, endpoint=False)
+ bi_coordinators = np.stack(np.meshgrid(coordinators, coordinators), 0)
+ bi_coordinators = bi_coordinators[None, ...]
+ nums = np.arange(0, order)
+ nums = 2 ** nums * np.pi
+ nums = nums[:, None, None, None]
+ gamma1 = np.sin(nums * bi_coordinators)
+ gamma2 = np.cos(nums * bi_coordinators)
+ gamma = np.concatenate([gamma1, gamma2], axis=0)
+ gamma = gamma.reshape([-1, img_size, img_size])
+ gamma = torch.tensor(gamma, requires_grad=False).float()
+ return gamma
+
+
+def init_weights(net, init_type='normal', init_gain=0.02):
+ """Initialize network weights.
+
+ Parameters:
+ net (network) -- network to be initialized
+ init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
+ init_gain (float) -- scaling factor for normal, xavier and orthogonal.
+
+ We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
+ work better for some applications. Feel free to try yourself.
+ """
+
+ def init_func(m): # define the initialization function
+ classname = m.__class__.__name__
+ if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0.0, init_gain)
+ elif init_type == 'xavier':
+ init.xavier_normal_(m.weight.data, gain=init_gain)
+ elif init_type == 'kaiming':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=init_gain)
+ else:
+ raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+ elif classname.find(
+ 'BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
+ init.normal_(m.weight.data, 1.0, init_gain)
+ init.constant_(m.bias.data, 0.0)
+
+ print('initialize network with %s' % init_type)
+ net.apply(init_func) # apply the initialization function
+
+
+class MaskEncoder(nn.Module):
+
+ def __init__(self, input_channel, output_dim, norm, layer_num, input_size=256, vae_mode=False,
+ pos_encoding_order=10, max_batch_size=1, hidden_in_channel=32):
+ super(MaskEncoder, self).__init__()
+ self.vae_mode = vae_mode
+ layers = []
+
+ in_channel = input_channel + pos_encoding_order * 4
+ for cur_num in range(layer_num):
+ out_channel = min(2048, 2 ** cur_num * hidden_in_channel)
+ cur_conv = Conv2dBlock(
+ in_channel, out_channel, kernel_size=4, stride=2, padding=1, norm=norm, activation='lrelu')
+ layers.append(cur_conv)
+ in_channel = out_channel
+
+ out_size = input_size // (2 ** layer_num)
+ self.layers = nn.Sequential(*layers)
+
+ fc_in_dim = out_size ** 2 * out_channel
+ self.out_layer = LinearBlock(fc_in_dim, output_dim, norm='none', activation='none')
+ if self.vae_mode:
+ self.std_out_layer = LinearBlock(fc_in_dim, output_dim, norm='none', activation='none')
+
+ self.input_embedding = generate_pos_embedding(img_size=input_size, order=pos_encoding_order)
+ self.input_embedding = self.input_embedding.repeat((max_batch_size, 1, 1, 1))
+
+ def forward(self, input_mask: torch.Tensor):
+ batch_size = input_mask.shape[0]
+ if self.input_embedding.device != input_mask.device:
+ self.input_embedding = self.input_embedding.to(input_mask.device)
+ input_with_pos = torch.cat([input_mask, self.input_embedding[:batch_size]], axis=1)
+ feature = self.layers(input_with_pos)
+ feature = feature.flatten(1)
+ out_mean = self.out_layer(feature)
+ if self.vae_mode:
+ out_std = self.std_out_layer(feature).abs()
+ return self.vae_resampling(out_mean, out_std), out_mean, out_std
+ else:
+ return out_mean, out_mean, None
+
+ def vae_resampling(self, mean, std):
+ z = torch.randn(mean.shape).to(mean.device)
+ res = z * std + mean
+ return res
+
+
+class MaskDecoder(nn.Module):
+ def __init__(self, input_dim, output_channel, norm, layer_num, output_size=256):
+ super(MaskDecoder, self).__init__()
+
+ self.in_channel = min(32 * 2 ** layer_num, 2048)
+ self.input_size = output_size // (2 ** layer_num)
+ self.in_layer = LinearBlock(input_dim, self.in_channel * self.input_size ** 2, norm='none', activation='none')
+
+ layers = []
+ in_channel = self.in_channel
+ for cur_num in range(layer_num):
+ up = nn.Upsample(scale_factor=2, mode='nearest')
+ out_channel = min(32 * 2 ** (layer_num - 1 - cur_num), 2048)
+ cur_conv = Conv2dBlock(in_channel, out_channel, kernel_size=3, stride=1, padding=1, norm=norm,
+ activation='lrelu')
+ layers.append(up)
+ layers.append(cur_conv)
+ in_channel = out_channel
+ self.layers = nn.Sequential(*layers)
+ self.out_layer = Conv2dBlock(in_channel, output_channel, kernel_size=3, stride=1, padding=1, norm='none',
+ activation='none')
+
+ def forward(self, input_vector):
+ feature = self.in_layer(input_vector)
+ feature = feature.reshape(-1, self.in_channel, self.input_size, self.input_size)
+ feature = self.layers(feature)
+ feature = self.out_layer(feature)
+ return feature
+
+
+class Generator(nn.Module):
+ """Generator network."""
+
+ def __init__(self, cfg):
+ super(Generator, self).__init__()
+ self.cfg = cfg
+
+ self.hair_encoder = MaskEncoder(1, cfg.hair_dim, norm=cfg.g_norm, layer_num=7, vae_mode=cfg.vae_hair_mode,
+ # self.hair_encoder = MaskEncoder(1, cfg.hair_dim, norm='none', layer_num=7, vae_mode=cfg.vae_hair_mode,
+ pos_encoding_order=cfg.pos_encoding_order,
+ max_batch_size=max(cfg.total_batch_size, cfg.sample_batch_size))
+ self.face_encoder = MaskEncoder(18, 1024, norm=cfg.g_norm, layer_num=7, vae_mode=False,
+ # self.face_encoder = MaskEncoder(18, 1024, norm='none', layer_num=7, vae_mode=False,
+ pos_encoding_order=cfg.pos_encoding_order,
+ max_batch_size=max(cfg.total_batch_size, cfg.sample_batch_size))
+ self.hair_decoder = MaskDecoder(1024 + cfg.hair_dim, output_channel=1, norm=cfg.g_norm, layer_num=7)
+ self.face_decoder = MaskDecoder(1024, output_channel=18, norm=cfg.g_norm, layer_num=7)
+
+ def forward_hair_encoder(self, hair, testing=False):
+ code, mean, std = self.hair_encoder(hair)
+ if testing:
+ return mean
+ else:
+ return code, mean, std
+
+ def forward_face_encoder(self, face):
+ code, _, _ = self.face_encoder(face)
+ return code
+
+ def forward_hair_decoder(self, hair_code, face_code):
+ code = torch.cat([face_code, hair_code], dim=1)
+ hair = self.hair_decoder(code)
+ return hair
+
+ def forward_face_decoder(self, face_code):
+ face = self.face_decoder(face_code)
+ return face
+
+ def forward_decoder(self, hair_logit, face_logit):
+ logit = torch.cat([face_logit[:, :HAIR_IDX], hair_logit, face_logit[:, HAIR_IDX:]], dim=1)
+ mask = torch.softmax(logit, dim=1)
+ return mask
+
+ def forward_edit_directly_in_test(self, hair, face):
+ _, hair_code, _ = self.forward_hair_encoder(hair)
+ face_code = self.forward_face_encoder(face)
+ mask = self.forward_decode_by_code(hair_code, face_code)
+ return mask
+
+ def forward_decode_by_code(self, hair_code, face_code):
+ hair_logit = self.forward_hair_decoder(hair_code, face_code)
+ face_logit = self.forward_face_decoder(face_code)
+ mask = self.forward_decoder(hair_logit, face_logit)
+ return mask
+
+
+class Discriminator(nn.Module):
+ """Discriminator network."""
+
+ def __init__(self, cfg):
+ super(Discriminator, self).__init__()
+ self.cfg = cfg
+ self.dis = MaskEncoder(19, 1, norm=cfg.d_norm, layer_num=7, vae_mode=False,
+ pos_encoding_order=cfg.pos_encoding_order, max_batch_size=cfg.total_batch_size,
+ hidden_in_channel=cfg.d_hidden_in_channel)
+
+ def forward(self, mask):
+ dis_res, _, _ = self.dis(mask)
+ return dis_res
+
+
+class DiscriminatorNoise(nn.Module):
+ """Discriminator network."""
+
+ def __init__(self, cfg):
+ super(DiscriminatorNoise, self).__init__()
+ self.cfg = cfg
+ input_dim = cfg.hair_dim
+ layers = [LinearBlock(input_dim, cfg.d_hidden_dim, cfg.d_norm, activation='lrelu')]
+ for _ in range(cfg.d_noise_hidden_layer_num - 1):
+ layers.append(LinearBlock(cfg.d_hidden_dim, cfg.d_hidden_dim, cfg.d_norm, activation='lrelu'))
+ output_dim = 1
+ layers.append(LinearBlock(cfg.d_hidden_dim, output_dim, 'none', 'none'))
+ self.net = nn.Sequential(*layers)
+
+ def forward(self, x):
+ return self.net(x)[:, [0]]
diff --git a/models/CtrlHair/shape_branch/script_adaptor_test_pool.py b/models/CtrlHair/shape_branch/script_adaptor_test_pool.py
new file mode 100644
index 0000000000000000000000000000000000000000..87cef04fa7804a68bf9fec7da76b5f0212636317
--- /dev/null
+++ b/models/CtrlHair/shape_branch/script_adaptor_test_pool.py
@@ -0,0 +1,24 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_adaptor_test_pool.py
+# Time : 2022/07/14
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+sys.path.append('.')
+
+from shape_branch.adaptor_generation import AdaptorPoolGeneration
+from shape_branch.config import cfg
+
+if __name__ == '__main__':
+ pp = AdaptorPoolGeneration(only_hair=False,
+ dir_name=cfg.adaptor_pool_dir,
+ test_dir_name=cfg.adaptor_test_pool_dir, thread_num=10)
+
+ ######################################################
+ # Run this for generating wrap pool for testing
+ ######################################################
+ pp.generate_test_set(cfg.sample_batch_size)
diff --git a/models/CtrlHair/shape_branch/script_adaptor_train_pool.py b/models/CtrlHair/shape_branch/script_adaptor_train_pool.py
new file mode 100644
index 0000000000000000000000000000000000000000..132f498c536dc6e4e13d894e8b3c4e8c1fbaf035
--- /dev/null
+++ b/models/CtrlHair/shape_branch/script_adaptor_train_pool.py
@@ -0,0 +1,26 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_adaptor_train_pool.py
+# Time : 2022/07/14
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+sys.path.append('.')
+
+from shape_branch.adaptor_generation import AdaptorPoolGeneration
+from shape_branch.config import cfg
+
+if __name__ == '__main__':
+ pp = AdaptorPoolGeneration(only_hair=False,
+ dir_name=cfg.adaptor_pool_dir,
+ test_dir_name=cfg.adaptor_test_pool_dir, thread_num=10)
+
+ #####################################################
+ # Run this for generating wrap pool for training dataset,
+ # which is a multi-thread procedure for speeding
+ #####################################################
+ pp.run()
+
diff --git a/models/CtrlHair/shape_branch/script_find_direction.py b/models/CtrlHair/shape_branch/script_find_direction.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6a7d302497b7ecd333f35e4af4fc355b0112081
--- /dev/null
+++ b/models/CtrlHair/shape_branch/script_find_direction.py
@@ -0,0 +1,76 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: script_find_direction.py
+# Time : 2022/2/28
+# Author: xyguoo@163.com
+# Description:
+"""
+import sys
+
+sys.path.append('.')
+
+import os
+import tqdm
+
+from ui.backend import Backend
+from util.canvas_grid import Canvas
+import numpy as np
+
+import pickle
+from util.mask_color_util import mask_to_rgb
+from common_dataset import DataFilter
+from util.imutil import read_rgb, write_rgb
+from shape_branch.config import cfg
+from util.find_semantic_direction import get_random_direction
+
+df = DataFilter(cfg)
+be = Backend(2.5, blending=False)
+
+exist_direction = 'model_trained/shape/%s' % cfg.experiment_name
+code_dim = cfg.hair_dim
+att_name = 'shape'
+interpolate_num = 6
+max_val = 2.5
+batch = 10
+
+interpolate_values = np.linspace(-max_val, max_val, interpolate_num)
+
+existing_dirs_dir = os.path.join(exist_direction, '%s_dir_used' % att_name)
+
+existing_dirs_list = os.listdir(existing_dirs_dir)
+existing_dirs = []
+for dd in existing_dirs_list:
+ with open(os.path.join(existing_dirs_dir, dd), 'rb') as f:
+ existing_dirs.append(pickle.load(f))
+
+direction_dir = '%s/direction_find/%s_dir_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
+img_gen_dir = '%s/direction_find/%s_%d' % (exist_direction, att_name, len(existing_dirs) + 1)
+for dd in [direction_dir, img_gen_dir]:
+ if not os.path.exists(dd):
+ os.makedirs(dd)
+
+img_list = df.train_list
+
+for dir_idx in tqdm.tqdm(range(0, 300)):
+ rand_dir = get_random_direction(code_dim, existing_dirs)
+ with open('%s/%d.pkl' % (direction_dir, dir_idx,), 'wb') as f:
+ pickle.dump(rand_dir, f)
+ rand_dir = rand_dir.to(be.device)
+
+ canvas = Canvas(batch * 2, interpolate_num + 1)
+ for img_idx, img_file in tqdm.tqdm(enumerate(img_list[:batch])):
+ img = read_rgb(img_file)
+ _, img_parsing = be.set_input_img(img)
+
+ canvas.process_draw_image(img, img_idx * 2, 0)
+ canvas.process_draw_image(img_parsing, img_idx * 2 + 1, 0)
+
+ for inter_idx in range(interpolate_num):
+ inter_val = interpolate_values[inter_idx]
+ be.continue_change_with_direction(att_name, rand_dir, inter_val)
+
+ out_img = be.output()
+ canvas.process_draw_image(out_img, img_idx * 2, inter_idx + 1)
+ canvas.process_draw_image(mask_to_rgb(be.cur_mask), img_idx * 2 + 1, inter_idx + 1)
+ write_rgb('%s/%d.png' % (img_gen_dir, dir_idx), canvas.canvas)
diff --git a/models/CtrlHair/shape_branch/shape_util.py b/models/CtrlHair/shape_branch/shape_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..82c7e43733248dc9c1f9402f4625baeb0783e624
--- /dev/null
+++ b/models/CtrlHair/shape_branch/shape_util.py
@@ -0,0 +1,26 @@
+import torch
+
+from models.CtrlHair.global_value_utils import HAIR_IDX
+
+
+def mask_label_to_one_hot(img):
+ # img = img * 255
+ img[img == 255] = 19
+ bs, _, h, w = img.size()
+ nc = 19
+ input_label = torch.FloatTensor(bs, nc + 1, h, w).zero_().to(img.device)
+ input_semantics = input_label.scatter_(1, img.long(), 1.0)
+ input_semantics = input_semantics[:, :-1, :, :]
+ return input_semantics
+
+
+def mask_one_hot_to_label(one_hot):
+ mask = torch.argmax(one_hot, dim=1)
+ mask[one_hot.max(dim=1)[0] == 0] = 255
+ return mask
+
+
+def split_hair_face(mask):
+ hair = mask[:, [HAIR_IDX], :, :]
+ face = torch.cat([mask[:, :HAIR_IDX, :, :], mask[:, HAIR_IDX + 1:, :, :]], dim=1)
+ return hair, face
diff --git a/models/CtrlHair/shape_branch/solver.py b/models/CtrlHair/shape_branch/solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b4c929472fc130ccc91578c1abb06470a5037f7
--- /dev/null
+++ b/models/CtrlHair/shape_branch/solver.py
@@ -0,0 +1,262 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: solver.py
+# Time : 2021/11/17 16:24
+# Author: xyguoo@163.com
+# Description:
+"""
+import random
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torchvision.transforms as T
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from models.CtrlHair.my_torchlib.train_utils import generate_noise
+from .config import cfg
+from .model import Generator, Discriminator, DiscriminatorNoise
+# solver
+from .shape_util import mask_label_to_one_hot, mask_one_hot_to_label, split_hair_face
+
+
+class Solver:
+
+ def __init__(self, cfg, device, local_rank, training=True):
+
+ self.ce_loss = torch.nn.CrossEntropyLoss()
+ self.mse_loss = torch.nn.MSELoss()
+
+ self.cfg = cfg
+ self.gen = Generator(cfg)
+ self.dis = Discriminator(cfg)
+
+ self.gen.to(device)
+ self.dis.to(device)
+
+ if training:
+ self.G_optimizer = torch.optim.Adam(self.gen.parameters(), lr=cfg.lr_d, betas=(cfg.beta1, cfg.beta2),
+ weight_decay=0.00)
+ self.D_optimizer = torch.optim.Adam(self.dis.parameters(), lr=cfg.lr_g, betas=(cfg.beta1, cfg.beta2),
+ weight_decay=0.00)
+ if cfg.lambda_adv_noise:
+ self.dis_noise = DiscriminatorNoise(cfg)
+ self.dis_noise.to(device)
+ self.D_noise_optimizer = torch.optim.Adam(self.dis_noise.parameters(), lr=cfg.lr_g,
+ betas=(cfg.beta1, cfg.beta2), weight_decay=0.00)
+ else:
+ self.dis_noise = None
+ else:
+ self.gen.eval()
+ self.dis.eval()
+
+ if local_rank >= 0:
+ pDDP = lambda m, find_unused: DDP(m, device_ids=[local_rank], output_device=local_rank,
+ find_unused_parameters=False)
+ self.gen = pDDP(self.gen, find_unused=True)
+ self.dis = pDDP(self.dis, find_unused=True)
+ self.local_rank = local_rank
+ self.device = device
+
+ @staticmethod
+ def kl_loss(mean, std):
+ var = std ** 2
+ var_log = torch.log(var + 1e-4)
+ kl_loss = 0.5 * (mean ** 2 + 1.0 * (var - 1 - var_log)).mean()
+ return kl_loss
+
+ def forward(self, data):
+ self.data_target_mask = data['target']
+ self.data_face_mask = data['face']
+ self.data_hair_mask = data['hair']
+
+ if cfg.disturb_real_batch_mask:
+ data_target_disturb = self.disturb_real(data['target'])
+ self.ae_in_hair, self.ae_in_target_face = split_hair_face(data_target_disturb)
+ data_face_disturb = self.disturb_real(data['face'])
+ _, self.ae_in_face = split_hair_face(data_face_disturb)
+ else:
+ self.ae_in_hair, self.ae_in_target_face = split_hair_face(data['target'])
+ _, self.ae_in_face = split_hair_face(data['face'])
+
+ self.ae_mid_hair_code, self.ae_mid_hair_mean, self.ae_mid_hair_std = self.gen.forward_hair_encoder(
+ self.ae_in_hair)
+ self.ae_mid_face_code = self.gen.forward_face_encoder(self.ae_in_face)
+ self.ae_out_hair_logit = self.gen.forward_hair_decoder(self.ae_mid_hair_code, self.ae_mid_face_code)
+ self.ae_out_face_logit = self.gen.forward_face_decoder(self.ae_mid_face_code)
+
+ self.ae_out_mask = self.gen.forward_decoder(self.ae_out_hair_logit, self.ae_out_face_logit)
+
+ if 'lambda_adv_noise' in cfg or 'lambda_info' in cfg:
+ self.real_noise = generate_noise(cfg.batch_size, cfg.hair_dim).to(
+ self.ae_mid_face_code.device).type_as(self.ae_mid_face_code)
+
+ if 'lambda_info' in cfg:
+ self.gan_in_hair_code = self.real_noise
+ self.gan_in_face_code = self.ae_mid_face_code
+ self.gan_mid_hair_logit = self.gen.forward_hair_decoder(self.gan_in_hair_code, self.gan_in_face_code)
+ self.gan_mid_face_logit = self.gen.forward_face_decoder(self.gan_in_face_code)
+ self.gan_mid_mask = self.gen.forward_decoder(self.gan_mid_hair_logit, self.gan_mid_face_logit)
+
+ self.gan_mid_hair, _ = split_hair_face(self.gan_mid_mask)
+ self.gan_out_hair_code, _, _ = self.gen.forward_hair_encoder(self.gan_mid_hair)
+
+ if random.random() < 0.5:
+ self.dis_out_fake = self.dis.forward(self.ae_out_mask)
+ else:
+ self.dis_out_fake = self.dis.forward(self.gan_mid_mask)
+ else:
+ if random.random() < cfg.random_ae_prob:
+ self.dis_out_fake = self.dis.forward(self.ae_out_mask)
+ else:
+ self.gan_in_hair_code = self.real_noise
+ self.gan_mid_hair_logit = self.gen.forward_hair_decoder(self.gan_in_hair_code,
+ self.ae_mid_face_code)
+ self.gan_mid_face_logit = self.ae_out_face_logit
+ self.gan_mid_mask = self.gen.forward_decoder(self.gan_mid_hair_logit, self.gan_mid_face_logit)
+ self.dis_out_fake = self.dis.forward(self.gan_mid_mask)
+
+ def forward_g(self, loss_dict):
+ self.forward_general_gen(self.dis_out_fake, loss_dict)
+ hair, face = split_hair_face(self.ae_out_mask)
+
+ if cfg.regular_method == 'ce':
+ loss_dict['lambda_hair'] = -torch.log(hair + 1e-5)[(self.ae_in_hair > 0.5)].mean()
+ loss_dict['lambda_non_hair'] = -torch.log(1 - hair + 1e-5)[(self.ae_in_hair < 0.5)].mean()
+ loss_dict['lambda_face'] = -torch.log(face + 1e-5)[(self.ae_in_target_face > 0.5)].mean()
+
+ hair_hair, hair_face = split_hair_face(self.data_hair_mask)
+ mask = self.gen.forward_edit_directly_in_test(hair_hair, hair_face)
+ if 'lambda_self_rec' in cfg:
+ if cfg.regular_method == 'ce':
+ loss_dict['lambda_self_rec'] = -torch.log(mask + 1e-5)[self.data_hair_mask > 0.5].mean()
+
+ if 'lambda_kl' in cfg and cfg.lambda_kl > 0:
+ loss_dict['lambda_kl'] = self.kl_loss(self.ae_mid_hair_mean, self.ae_mid_hair_std)
+ if cfg.lambda_moment_1 or cfg.lambda_moment_2:
+ noise_mid = self.ae_mid_hair_code
+ if cfg.lambda_moment_1:
+ loss_dict['lambda_moment_1'] = (noise_mid.mean(dim=0) ** 2).mean()
+ if cfg.lambda_moment_2:
+ loss_dict['lambda_moment_2'] = (((noise_mid ** 2).mean(dim=0) - 0.973) ** 2).mean()
+
+ if 'lambda_info' in cfg:
+ loss_dict['lambda_info'] = self.mse_loss(self.gan_out_hair_code, self.gan_in_hair_code)
+
+ if cfg.lambda_adv_noise:
+ self.d_noise_res = self.dis_noise(self.ae_mid_hair_code)
+ self.forward_general_gen(self.d_noise_res, loss_dict, loss_name_suffix='_noise')
+
+ for loss_d in [loss_dict]:
+ for ke in loss_d:
+ if np.isnan(np.array(loss_d[ke].detach().cpu())):
+ print('!!!!!!!!! %s is nan' % ke)
+ print(loss_d)
+ raise Exception()
+
+ @staticmethod
+ def forward_general_gen(dis_res, loss_dict, loss_name_suffix=''):
+ if cfg.gan_type == 'lsgan':
+ loss_dis = torch.mean((dis_res - 1) ** 2)
+ elif cfg.gan_type == 'nsgan':
+ all1 = torch.ones_like(dis_res.data).cuda()
+ loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis_res), all1))
+ elif cfg.gan_type == 'wgan_gp':
+ loss_dis = - torch.mean(dis_res)
+ elif cfg.gan_type == 'hinge':
+ loss_dis = -torch.mean(dis_res)
+ elif cfg.gan_type == 'hinge2':
+ loss_dis = torch.mean(torch.max(1 - dis_res, torch.zeros_like(dis_res)))
+ else:
+ raise NotImplementedError()
+ loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
+
+ @staticmethod
+ def forward_general_dis(dis1, dis0, loss_dict,
+ dis_model=None, input_real=None, input_fake=None, loss_name_suffix=''):
+ if cfg.gan_type == 'lsgan':
+ loss_dis = torch.mean((dis0 - 0) ** 2) + torch.mean((dis1 - 1) ** 2)
+ elif cfg.gan_type == 'nsgan':
+ all0 = torch.zeros_like(dis0.data).cuda()
+ all1 = torch.ones_like(dis1.data).cuda()
+ loss_dis = torch.mean(F.binary_cross_entropy(torch.sigmoid(dis0), all0) +
+ F.binary_cross_entropy(torch.sigmoid(dis1), all1))
+ elif cfg.gan_type == 'wgan_gp':
+ loss_dis = torch.mean(dis0) - torch.mean(dis1)
+ elif cfg.gan_type == 'hinge' or cfg.gan_type == 'hinge2':
+ loss_dis = torch.mean(torch.max(1 - dis1, torch.zeros_like(dis1)))
+ loss_dis += torch.mean(torch.max(1 + dis0, torch.zeros_like(dis0)))
+ else:
+ assert 0, "Unsupported GAN type: {}".format(cfg.gan_type)
+ loss_dict['lambda_adv' + loss_name_suffix] = loss_dis
+
+ if cfg.gan_type == 'wgan_gp':
+ loss_gp = 0
+ alpha_gp = torch.rand(input_real.size(0), *([1] * (len(input_real.shape) - 1))).type_as(input_real)
+ x_hat = (alpha_gp * input_real + (1 - alpha_gp) * input_fake).requires_grad_(True)
+ out_hat = dis_model.forward(x_hat)
+ # gradient penalty
+ weight = torch.ones(out_hat.size()).type_as(out_hat)
+ dydx = torch.autograd.grad(outputs=out_hat, inputs=x_hat, grad_outputs=weight, retain_graph=True,
+ create_graph=True, only_inputs=True)[0]
+ dydx = dydx.contiguous().view(dydx.size(0), -1)
+ dydx_l2norm = torch.sqrt(torch.sum(dydx ** 2, dim=1))
+ loss_gp += torch.mean((dydx_l2norm - 1) ** 2)
+ loss_dict['lambda_gp' + loss_name_suffix] = loss_gp
+
+ if cfg.lambda_gp_0 and cfg.lambda_gp_0 > 0:
+ # ii = input_real.requires_grad_(True)
+ dydx = torch.autograd.grad(outputs=dis1.sum(), inputs=input_real, retain_graph=True, create_graph=True,
+ only_inputs=True, allow_unused=True)[0]
+ dydx2 = dydx.pow(2)
+ dydx_l2norm = dydx2.view(dydx.size(0), -1).sum(1)
+ loss_gp = dydx_l2norm.mean()
+ loss_dict['lambda_gp_0' + loss_name_suffix] = loss_gp
+
+ def forward_d(self, loss_dict, real_batch):
+ if cfg.disturb_real_batch_mask:
+ real_batch = self.disturb_real(real_batch)
+
+ if 'lambda_gp_0' in cfg and cfg.lambda_gp_0 > 0:
+ real_batch = real_batch.requires_grad_()
+ dis_out_real = self.dis.forward(real_batch)
+ self.forward_general_dis(dis_out_real, self.dis_out_fake,
+ loss_dict, self.dis, input_real=real_batch,
+ input_fake=self.ae_out_mask)
+
+ def disturb_real(self, real_batch):
+ cur = (torch.rand(real_batch.shape).to(real_batch.device) * 0.03 + real_batch)
+ cur = cur / cur.sum(dim=(1), keepdim=True)
+ return cur
+
+ def forward_adv_noise(self, loss_dict):
+
+ input_real = self.real_noise
+ if 'lambda_gp_0' in cfg and cfg.lambda_gp_0 > 0:
+ input_real = input_real.requires_grad_()
+
+ input_fake = self.ae_mid_hair_code.detach()
+
+ dis1 = self.dis_noise(input_real)
+ dis0 = self.dis_noise(input_fake)
+
+ self.forward_general_dis(dis1, dis0, loss_dict, self.dis_noise, input_real=input_real,
+ input_fake=input_fake, loss_name_suffix='_noise')
+
+
+def get_hair_face_code(mask_generator, mask):
+ mask_batch = mask[None, None, :, :]
+ mask_batch = T.functional.resize(mask_batch.long(), (256, 256),
+ interpolation=T.InterpolationMode.NEAREST)
+ mask_one_hot = mask_label_to_one_hot(mask_batch)
+ hair, face = split_hair_face(mask_one_hot)
+ hair_code = mask_generator.forward_hair_encoder(hair, testing=True)
+ face_code = mask_generator.forward_face_encoder(face)
+ return face_code, hair_code
+
+
+def get_new_shape(mask_generator, face_code, new_hair_code):
+ out_mask = mask_generator.forward_decode_by_code(new_hair_code, face_code)
+ out_mask = mask_one_hot_to_label(out_mask)[0]
+ return out_mask
diff --git a/models/CtrlHair/shape_branch/train.py b/models/CtrlHair/shape_branch/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..64423f479a791a7ea5eea61db44ecde3104df6c3
--- /dev/null
+++ b/models/CtrlHair/shape_branch/train.py
@@ -0,0 +1,135 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: scripts.py.py
+# Time : 2021/11/17 15:24
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import sys
+sys.path.append('.')
+
+import tensorboardX
+import torch
+import tqdm
+from shape_branch.config import cfg, args
+from shape_branch.dataset import Dataset
+import my_pylib
+from shape_branch.validation_in_train import print_val_save_model
+# distributed training
+import torch.distributed as dist
+from shape_branch.solver import Solver
+from my_torchlib.train_utils import LossUpdater, to_device, generate_noise, train
+import my_torchlib
+from shape_branch.model import init_weights
+from shape_branch.shape_util import mask_label_to_one_hot
+
+
+def get_total_step():
+ total = 0
+ for key in cfg.iter:
+ total += cfg.iter[key]
+ return total
+
+
+def worker(proc, nprocs, args):
+ local_rank = args.local_rank
+ if local_rank >= 0:
+ torch.cuda.set_device(local_rank)
+ dist.init_process_group(backend='nccl',
+ init_method='tcp://localhost:%d' % (6030 + int(cfg.experiment_name[:3])),
+ rank=args.local_rank,
+ world_size=cfg.gpu_num)
+ print('setup rank %d' % local_rank)
+ device = torch.device('cuda', max(0, local_rank))
+
+ # config
+ out_dir = cfg.root_dir
+
+ # data
+ ds = Dataset(cfg)
+
+ loss_updater = LossUpdater(cfg)
+ loss_updater.update(0)
+
+ # Loss class
+ solver = Solver(cfg, device, local_rank=local_rank)
+
+ # load checkpoint
+ ckpt_dir = cfg.checkpoints_dir
+ if local_rank <= 0:
+ my_pylib.mkdir(out_dir)
+ my_pylib.save_json(out_dir + '/setting_hair.json', cfg, indent=4, separators=(',', ': '))
+ my_pylib.mkdir(ckpt_dir)
+ my_pylib.mkdir(cfg.sample_dir)
+
+ try:
+ ckpt = my_torchlib.load_checkpoint(ckpt_dir)
+ start_step = ckpt['step'] + 1
+ solver.gen.load_state_dict(ckpt['Model_G'], strict=True)
+ solver.dis.load_state_dict(ckpt['Model_D'], strict=True)
+ solver.D_optimizer.load_state_dict(ckpt['D_optimizer'])
+ solver.G_optimizer.load_state_dict(ckpt['G_optimizer'])
+ if cfg.lambda_adv_noise:
+ solver.dis_noise.load_state_dict(ckpt['Model_D_noise'], strict=True)
+ solver.D_noise_optimizer.load_state_dict(ckpt['D_noise_optimizer'])
+ print('Load succeed!')
+ except:
+ print(' [*] No checkpoint!')
+ init_weights(solver.gen, init_type=cfg.init_type)
+ init_weights(solver.dis, init_type=cfg.init_type)
+ start_step = 1
+
+ # writer
+ if local_rank <= 0:
+ writer = tensorboardX.SummaryWriter(cfg.log_dir)
+ else:
+ writer = None
+
+ # start training
+ test_batch = ds.get_test_batch(cfg.sample_batch_size)
+ for ke in ['face', 'target', 'hair']:
+ test_batch[ke] = mask_label_to_one_hot(test_batch[ke])
+ to_device(test_batch, device)
+
+ if local_rank >= 0:
+ dist.barrier()
+
+ total_step = cfg.total_step + 2
+ for step in tqdm.tqdm(range(start_step, total_step), total=total_step, initial=start_step, desc='step'):
+ loss_updater.update(step)
+ write_log = (writer and step % 23 == 0)
+
+ for i in range(sum(cfg.G_D_train_num.values())):
+ data = ds.get_random_pair_batch(cfg.batch_size)
+ for ke in data:
+ data[ke] = mask_label_to_one_hot(data[ke])
+ to_device(data, device)
+ loss_dict = {}
+ solver.forward(data)
+ if i < cfg.G_D_train_num['D']:
+ real_batch = ds.get_random_single_batch(cfg.batch_size)
+ real_batch = mask_label_to_one_hot(real_batch)
+ real_batch = real_batch.to(device)
+ solver.forward_d(loss_dict, real_batch)
+ train(cfg, loss_dict, optimizers=[solver.D_optimizer],
+ step=step, writer=writer, flag='D', write_log=write_log)
+ else:
+ solver.forward_g(loss_dict)
+ train(cfg, loss_dict, optimizers=[solver.G_optimizer],
+ step=step, writer=writer, flag='G', write_log=write_log)
+
+ if cfg.lambda_adv_noise:
+ loss_dict = {}
+ solver.forward_adv_noise(loss_dict)
+ train(cfg, loss_dict, optimizers=[solver.D_noise_optimizer], step=step, writer=writer, flag='D_noise',
+ write_log=write_log)
+
+ print_val_save_model(step, cfg.sample_dir, solver, test_batch, ckpt_dir, local_rank)
+
+
+if __name__ == '__main__':
+ # with torch.autograd.set_detect_anomaly(True):
+ # mp.spawn(worker, nprocs=cfg.gpu_num, args=(cfg.gpu_num, args))
+ worker(proc=None, nprocs=None, args=args)
diff --git a/models/CtrlHair/shape_branch/validation_in_train.py b/models/CtrlHair/shape_branch/validation_in_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9a46ad6c759ba46b227e64e873a35c854f1811f
--- /dev/null
+++ b/models/CtrlHair/shape_branch/validation_in_train.py
@@ -0,0 +1,165 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: validation_in_train.py
+# Time : 2021/12/10 12:55
+# Author: xyguoo@163.com
+# Description:
+"""
+import os
+
+import copy
+
+import cv2
+
+from hair_editor import HairEditor
+from my_torchlib.train_utils import generate_noise
+from util.canvas_grid import Canvas
+from util.imutil import write_rgb
+from util.mask_color_util import mask_to_rgb
+from .config import cfg
+import my_pylib
+import torch
+import torch.distributed as dist
+import my_torchlib
+from .shape_util import split_hair_face, mask_one_hot_to_label
+import numpy as np
+
+he = HairEditor(load_feature_model=False, load_mask_model=False)
+
+
+def save_model(step, solver, ckpt_dir):
+ save_dic = {'step': step,
+ 'Model_G': solver.gen.state_dict(), 'Model_D': solver.dis.state_dict(),
+ 'D_optimizer': solver.D_optimizer.state_dict(), 'G_optimizer': solver.G_optimizer.state_dict()}
+ if cfg.lambda_adv_noise:
+ save_dic['Model_D_noise'] = solver.dis_noise.state_dict()
+ save_dic['D_noise_optimizer'] = solver.D_noise_optimizer.state_dict()
+ my_torchlib.save_checkpoint(save_dic, '%s/%07d.ckpt' % (ckpt_dir, step), max_keep=cfg.max_save)
+
+
+def print_val_save_model(step, out_dir, solver, test_batch, ckpt_dir, local_rank):
+ """
+ :param step:
+ :param validation_data:
+ :param img_size:
+ :param alpha:
+ :return:
+ """
+ if step > 0 and step % cfg.sample_step == 0:
+ gen = solver.gen
+ dis = solver.dis
+ local_rank = solver.local_rank
+ device = solver.device
+
+ gen.eval()
+ # dis.eval()
+
+ with torch.no_grad():
+ target_hair_part, _ = split_hair_face(test_batch['target'])
+ face_hair_part, face_part = split_hair_face(test_batch['face'])
+ hair_hair_part, hair_face_part = split_hair_face(test_batch['hair'])
+
+ face_face_code = solver.gen.forward_face_encoder(face_part)
+ _, target_hair_code, _ = solver.gen.forward_hair_encoder(target_hair_part)
+ hair_face_code = solver.gen.forward_face_encoder(hair_face_part)
+ _, hair_hair_code, _ = solver.gen.forward_hair_encoder(hair_hair_part)
+
+ hair_mask_label = mask_one_hot_to_label(test_batch['hair']).cpu().numpy()
+ hair_mask_vis = [mask_to_rgb(ii, draw_type=0) for ii in hair_mask_label]
+
+ face_mask_label = mask_one_hot_to_label(test_batch['face']).cpu().numpy()
+ face_mask_vis = [mask_to_rgb(ii, draw_type=0) for ii in face_mask_label]
+
+ target_mask_label = mask_one_hot_to_label(test_batch['target']).cpu().numpy()
+ target_mask_vis = [mask_to_rgb(ii, draw_type=0) for ii in target_mask_label]
+
+ # ---------
+ # rec and edit random
+ # ---------
+ grid_count = 10
+ # generate each noise dim
+ canvas = Canvas(cfg.sample_batch_size, grid_count + 2, margin=3)
+
+ rec_masks = solver.gen.forward_decode_by_code(hair_hair_code, hair_face_code)
+ rec_masks_label = mask_one_hot_to_label(rec_masks).cpu().numpy()
+ rec_masks_vis = [mask_to_rgb(ii, draw_type=0) for ii in rec_masks_label]
+ for draw_idx, idx in enumerate(range(cfg.sample_batch_size)):
+ canvas.process_draw_image(hair_mask_vis[draw_idx], draw_idx, 0)
+ canvas.process_draw_image(rec_masks_vis[draw_idx], draw_idx, 1)
+
+ temp_noise = generate_noise(grid_count, cfg.hair_dim).to(device)
+ for grid_idx in range(grid_count):
+ cur_hair_code = torch.tile(temp_noise[grid_idx, :], (cfg.sample_batch_size, 1))
+ res_masks = solver.gen.forward_decode_by_code(cur_hair_code, hair_face_code)
+ res_masks_label = mask_one_hot_to_label(res_masks).cpu().numpy()
+ for draw_idx, idx in enumerate(range(cfg.sample_batch_size)):
+ canvas.process_draw_image(mask_to_rgb(res_masks_label[draw_idx], draw_type=0),
+ draw_idx, grid_idx + 2)
+
+ if local_rank <= 0:
+ canvas.write_(os.path.join(out_dir, '%07d_random.png' % step))
+
+ # ---------
+ # transfer
+ # ---------
+ res_mask = solver.gen.forward_decode_by_code(target_hair_code, face_face_code)
+ res_mask_label = mask_one_hot_to_label(res_mask).cpu().numpy()
+ res_mask_vis = [mask_to_rgb(ii, draw_type=0) for ii in res_mask_label]
+ vacant_column = np.ones([cfg.sample_batch_size * cfg.img_size, 3, 3], dtype='uint8') * 255
+
+ face_imgs = np.concatenate(test_batch['face_imgs'], axis=0)
+ hair_imgs = np.concatenate(test_batch['hair_imgs'], axis=0)
+ target_imgs = []
+ for idx in range(cfg.sample_batch_size):
+ cur_img = he.gen_img(test_batch['sean_code'][idx][None, ...],
+ res_mask_label[idx][None, None, ...]).cpu().numpy() * 127.5 + 127.5
+ cur_img = np.transpose(cur_img, [1, 2, 0])
+ cur_img, _ = he.postprocess_blending(test_batch['face_imgs'][idx], cur_img,
+ face_mask_label[idx][None, ...],
+ res_mask_label[idx][None, ...])
+ target_imgs.append(cur_img)
+ target_imgs = np.concatenate(target_imgs, axis=0)
+ canvas = np.concatenate([np.concatenate(hair_mask_vis, axis=0), vacant_column,
+ hair_imgs, vacant_column,
+ np.concatenate(face_mask_vis, axis=0), vacant_column,
+ face_imgs, vacant_column,
+ np.concatenate(target_mask_vis, axis=0), vacant_column,
+ np.concatenate(res_mask_vis, axis=0), vacant_column,
+ target_imgs], axis=1)
+ write_rgb(os.path.join(out_dir, '%07d__transfer.png' % step), canvas)
+
+ # ---------
+ # edit code
+ # ---------
+ grid_count = 6
+ lin_space = np.linspace(-2.5, 2.5, grid_count)
+
+ for dim_idx in range(cfg.hair_dim):
+ canvas = Canvas(cfg.sample_batch_size, grid_count + 1, margin=3)
+
+ for draw_idx, idx in enumerate(range(cfg.sample_batch_size)):
+ canvas.process_draw_image(hair_mask_vis[draw_idx], draw_idx, 0)
+
+ for grid_idx in range(grid_count):
+ hair_hair_code_copy = copy.deepcopy(hair_hair_code)
+ hair_hair_code_copy[:, dim_idx] = lin_space[grid_idx]
+ res_mask = solver.gen.forward_decode_by_code(hair_hair_code_copy, hair_face_code)
+ res_mask = mask_one_hot_to_label(res_mask).cpu().numpy()
+
+ for draw_idx, idx in enumerate(range(cfg.sample_batch_size)):
+ draw_mask = mask_to_rgb(res_mask[draw_idx], draw_type=0)
+ canvas.process_draw_image(draw_mask, draw_idx, grid_idx + 1)
+ if local_rank <= 0:
+ canvas.write_(os.path.join(out_dir, '%07d_noise_%02d.png' % (step, dim_idx)))
+
+ gen.train()
+ # dis.scripts()
+ if local_rank >= 0:
+ dist.barrier()
+
+ if step > 0 and step % cfg.model_save_step == 0:
+ if local_rank <= 0:
+ save_model(step, solver, ckpt_dir)
+ if local_rank >= 0:
+ dist.barrier()
diff --git a/models/CtrlHair/ui/__init__.py b/models/CtrlHair/ui/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a533a6a830fd861255e4c037ede85835b76c6629
--- /dev/null
+++ b/models/CtrlHair/ui/__init__.py
@@ -0,0 +1,7 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: __init__.py.py
+# Time : 2022/2/20 15:45
+# Author: xyguoo@163.com
+"""
diff --git a/models/CtrlHair/ui/backend.py b/models/CtrlHair/ui/backend.py
new file mode 100644
index 0000000000000000000000000000000000000000..5996f00d3f050e9d4d1d8efeee16a09b3c5a4dd5
--- /dev/null
+++ b/models/CtrlHair/ui/backend.py
@@ -0,0 +1,504 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: hair_swap.py
+# Time : 2022/2/20 17:06
+# Author: xyguoo@163.com
+# Description: This is the backend interface for editing. When you want to customize custom editing and
+ modification functions (such as replacing mask), it is recommended to call these interfaces directly.
+ In the finally main section of this file, there is an example of using Backend
+"""
+
+import sys
+sys.path.append('.')
+
+import copy
+import os
+
+import cv2
+import torch
+
+from global_value_utils import HAIR_IDX, TEMP_FOLDER
+from my_torchlib.train_utils import generate_noise
+from shape_branch.shape_util import mask_label_to_one_hot, mask_one_hot_to_label, split_hair_face
+from util.mask_color_util import mask_to_rgb
+from wrap_codes.mask_adaptor import wrap_by_imgs
+
+from hair_editor import HairEditor
+from util.color_from_hsv_to_gaussian import DistTranslation
+
+
+class LatentRepresentation:
+ def __init__(self):
+ self.color = None
+ self.curliness = None
+ self.shape = None
+ self.texture = None
+ self.face = None
+
+
+class Backend(HairEditor):
+ """
+ This is the main interface set, please call these interfaces directly to customize custom editing
+ """
+
+ def __init__(self, maximum_value_fe, blending=True, temp_path=os.path.join(TEMP_FOLDER, 'demo_output')):
+ """
+ :param maximum_value_fe: The max value in sliding bar of the frontend ui. If you just use the backend,
+ but not use the frontend, this value is
+ :param blending: Whether use poisson blending between hair region and others region
+ :param temp_path: the dir that save temp content, which can be removed after execution
+ """
+ super().__init__(True, True)
+ self.target_img = None
+ self.input_img = None
+ self.target_mask = None
+ self.input_mask = None
+ self.cur_latent = None
+ self.target_latent = None
+ self.cur_mask = None
+ self.input_sean_code = None
+ self.target_size = 256
+ self.maximum_value_fe = maximum_value_fe
+ self.temp_path = temp_path
+ self.blending = blending
+ self.dist_translation = DistTranslation()
+
+ def parse_img(self, img_rgb, target_img=False):
+ """
+ mask the input image
+ :param img_rgb: with channel order rgb
+ :param target_img: is the target image?
+ """
+ img_ts = cv2.resize(img_rgb, (self.target_size, self.target_size))
+ mask = self.get_mask(img_rgb)
+ lr = LatentRepresentation()
+
+ # infer shape
+ if target_img:
+ out_mask = None
+ else:
+ mask_batch = self.preprocess_mask(mask)
+ mask_tensor = torch.tensor(mask_batch, dtype=torch.uint8, device=self.device)
+ mask_one_hot = mask_label_to_one_hot(mask_tensor)
+ hair, face = split_hair_face(mask_one_hot)
+ hair_code = self.mask_generator.forward_hair_encoder(hair, testing=True)
+ face_code = self.mask_generator.forward_face_encoder(face)
+ lr.shape = hair_code
+ lr.face = face_code
+ out_mask = self.mask_generator.forward_decode_by_code(hair_code, face_code)
+ out_mask = mask_one_hot_to_label(out_mask).cpu().numpy()[0]
+
+ # infer feature
+ input_code = self.get_code(self.preprocess_img(img_rgb), mask_batch)
+ hair_feature = input_code[:, HAIR_IDX]
+
+ out_color = self.feature_rgb_predictor({'code': hair_feature})
+
+ c = out_color['rgb_mean'].detach().cpu().numpy()
+ c_hsv = cv2.cvtColor(c[None, ...].astype('uint8'), cv2.COLOR_RGB2HSV)
+ c_hsv = torch.tensor(c_hsv).to(self.device)[0]
+ lr.color = {'hsv': c_hsv, 'pca_std': out_color['pca_std']}
+
+ out_enc = self.feature_encoder({'code': hair_feature})
+ lr.curliness = out_enc['noise_curliness']
+ lr.texture = out_enc['noise']
+ return img_ts, out_mask, lr, mask, input_code, hair_feature
+
+ def tensor_hsv_to_rgb(self, hsv):
+ """
+ input tensor with hsv and convert to rgb
+ """
+ c = hsv.detach().cpu().numpy()
+ c_rgb = cv2.cvtColor(c[None, ...].astype('uint8'), cv2.COLOR_HSV2RGB)
+ c_rgb = torch.tensor(c_rgb).to(self.device)[0]
+ return c_rgb
+
+ def tensor_rgb_to_hsv(self, rgb):
+ """
+ input tensor with rgb and convert to hsv
+ """
+
+ c = rgb.detach().cpu().numpy()
+ c_hsv = cv2.cvtColor(c[None, ...].astype('uint8'), cv2.COLOR_RGB2HSV)
+ c_hsv = torch.tensor(c_hsv).to(self.device)[0]
+ return c_hsv
+
+ def set_input_img(self, img_rgb):
+ """
+ set and parse the input image
+ :param img_rgb:
+ """
+ self.input_img, self.cur_mask, self.cur_latent, \
+ self.input_mask, self.input_sean_code, self.input_hair_feature = self.parse_img(img_rgb)
+ input_mask_show = mask_to_rgb(self.cur_mask, draw_type=1)
+ return self.input_img, input_mask_show
+
+ def set_target_img(self, img_rgb):
+ """
+ set and parse the target image
+ :param img_rgb:
+ """
+ self.target_img, _, self.target_latent, \
+ self.target_mask, _, self.target_hair_feature = self.parse_img(img_rgb)
+ input_maks_show = mask_to_rgb(self.target_mask, draw_type=1)
+ return self.target_img, input_maks_show
+
+ def output(self, target_latent=None, feature=None):
+ """
+ generate an color_texture image
+ :param target_latent: if the latent representation of target is not provided,
+ `self.cur_latent` and `self.cur_mask` will be used
+ :param feature: if edited hair feature X is not provided, it will be generated with color and texture branch
+ :return: color_texture image
+ """
+ if target_latent is None:
+ target_latent = self.cur_latent
+ target_mask = self.cur_mask
+ else:
+ target_mask = self.refresh_cur_mask(target_latent)[0]
+
+ if 'rgb_mean' in target_latent.color:
+ target_color_rgb = self.target_latent.color['rgb_mean']
+ else:
+ target_color_rgb = self.tensor_hsv_to_rgb(target_latent.color['hsv'])
+
+ if feature is None:
+ data = {'noise': target_latent.texture, 'noise_curliness': target_latent.curliness,
+ 'rgb_mean': target_color_rgb, 'pca_std': target_latent.color['pca_std']}
+ feature = self.feature_generator(data)['code']
+ self.input_sean_code[:, HAIR_IDX] = feature
+ edit_img = self.gen_img(self.input_sean_code, target_mask[None, None, ...])
+ output_img, _ = self.postprocess_blending(self.input_img, edit_img, self.input_mask, target_mask,
+ blending=self.blending)
+
+ return output_img
+
+ def change_curliness(self, val):
+ """
+ change the latent representation of curliness of texture
+ """
+ self.cur_latent.curliness[0] = val
+
+ # def change_color(self, val, idx):
+ # val = (val + self.maximum_value_fe) / 2 / self.maximum_value_fe
+ # if idx == 3:
+ # self.cur_latent.color['pca_std'][0] = val * 100 + 20
+ # else:
+ # if idx == 0:
+ # val *= 179
+ # if idx == 1:
+ # val *= 255
+ # if idx == 2:
+ # val *= 255
+ # self.cur_latent.color['hsv'][0][idx] = val
+
+ def change_color(self, val, idx):
+ """
+ change the latent representation of color
+ idx=0 is hue, idx=1 is saturation, idx=2 is brightness, idx=3 is variance
+
+ please note that when idx=3, the variance is not obey gaussian,
+ the value range is in [-self.maximum_value_fe, self.maximum_value_fe]
+ """
+ if idx == 3:
+ val = (val + self.maximum_value_fe) / 2 / self.maximum_value_fe
+ self.cur_latent.color['pca_std'][0] = val * 100 + 20
+ else:
+ val = self.dist_translation.gaussian_to_val(idx, val)
+ self.cur_latent.color['hsv'][0][idx] = val
+
+ def change_shape(self, val, idx):
+ """
+ change the latent representation of shape
+ :param val: latent value
+ :param idx: for current checkpoint, idx=0 is length, idx=1 is volumn, idx=2 is bangs_direction, idx=3 is bangs
+ """
+ self.continue_change_with_direction('shape', self.shape_dirs[idx], val)
+ self.refresh_cur_mask()
+
+ def change_texture(self, val, idx):
+ """
+ change the latent representation of texture
+ :param val: latent value
+ :param idx: for current checkpoint, idx=0 is smoothness, idx=1 is thickness
+ """
+ self.continue_change_with_direction('texture', self.texture_dirs[idx], val)
+
+ def get_curliness_be2fe(self):
+ """
+ convert the latent representation to the value of sliding bar in the frontend of Pyqt ui, and return it
+ """
+ return self.cur_latent.curliness[0]
+
+ def get_color_be2fe(self):
+ """
+ convert the latent representation to the value of sliding bar in the frontend of Pyqt ui, and return it
+ """
+ c_hsv = self.cur_latent.color['hsv'].detach().cpu().numpy()[0]
+ # color0 = c_hsv[0] / 179 * 2 * self.maximum_value_fe - self.maximum_value_fe
+ # color1 = c_hsv[1] / 255 * 2 * self.maximum_value_fe - self.maximum_value_fe
+ # color2 = c_hsv[2] / 255 * 2 * self.maximum_value_fe - self.maximum_value_fe
+ color0 = self.dist_translation.val_to_gaussian(0, c_hsv[0])
+ color1 = self.dist_translation.val_to_gaussian(1, c_hsv[1])
+ color2 = self.dist_translation.val_to_gaussian(2, c_hsv[2])
+ var_fe = (self.cur_latent.color['pca_std'][0] - 20) / 100 * 2 * self.maximum_value_fe - self.maximum_value_fe
+ return color0, color1, color2, var_fe
+
+ def get_shape_be2fe(self):
+ """
+ convert the latent representation to the value of sliding bar in the frontend of Pyqt ui, and return it
+ """
+ res = []
+ for idx in range(4):
+ res.append(torch.dot(self.cur_latent.shape[0], self.shape_dirs[idx]))
+ return res
+
+ def get_texture_be2fe(self):
+ """
+ convert the latent representation to the value of sliding bar in the frontend of Pyqt ui, and return it
+ """
+ res = []
+ for idx in range(2):
+ res.append(torch.dot(self.cur_latent.texture[0], self.texture_dirs[idx]))
+ return res
+
+ def transfer_latent_representation(self, flag, refresh=True):
+ """
+ transfer the latent representation of target image to input image.
+ i.e., transfer from self.target_latent to self.cur_latent
+ :param flag: 'color', 'texture' or 'shape'
+ :param refresh: whether refresh mask
+ :return:
+ """
+ if flag == 'shape':
+ wt, _ = wrap_by_imgs(self.target_img, self.input_img, wrap_temp_folder=self.temp_path,
+ need_crop=False)
+ wt = self.preprocess_mask(wt)
+ self.warp_target = wt[0, 0]
+ mask_tensor = torch.tensor(wt, dtype=torch.uint8, device=self.device)
+ mask_one_hot = mask_label_to_one_hot(mask_tensor)
+ hair, face = split_hair_face(mask_one_hot)
+ hair_code = self.mask_generator.forward_hair_encoder(hair, testing=True)
+ face_code = self.mask_generator.forward_face_encoder(face)
+ self.target_latent.shape = hair_code
+ self.target_latent.face = face_code
+
+ self.refresh_cur_mask()
+
+ target_att = self.target_latent.__getattribute__(flag)
+ if isinstance(target_att, torch.Tensor):
+ self.cur_latent.__setattr__(flag, target_att.clone())
+ else:
+ cp_dict = copy.copy(target_att)
+ for ke in cp_dict:
+ cp_dict[ke] = cp_dict[ke].clone()
+ self.cur_latent.__setattr__(flag, cp_dict)
+
+ if flag == 'shape' and refresh:
+ self.refresh_cur_mask()
+
+ if flag == 'texture':
+ self.transfer_latent_representation('curliness')
+
+ def refresh_cur_mask(self, target_latent=None):
+ """
+ refresh and generate current mask
+ :param target_latent: if no target latent is given, self.cur_mask will be used
+ :return:
+ """
+ if target_latent is None:
+ target_latent = self.cur_latent
+ out_mask = self.mask_generator.forward_decode_by_code(target_latent.shape, target_latent.face)
+ out_mask = mask_one_hot_to_label(out_mask).cpu().numpy()[0]
+ self.cur_mask = out_mask
+ return out_mask, mask_to_rgb(out_mask, draw_type=1)
+
+ def get_cur_mask(self):
+ """
+ get the mask, which can be visited
+ """
+ return mask_to_rgb(self.cur_mask, draw_type=1)
+
+ def interpolate_hsv(self, hsv1, hsv2, alpha):
+ """
+ final hsv = hsv1 * (1 - alpha) + hsv2 * alpha
+ return: final hsv
+ """
+ rgb1 = self.tensor_hsv_to_rgb(hsv1)
+ rgb2 = self.tensor_hsv_to_rgb(hsv2)
+ rgb = rgb1 * (1 - alpha) + rgb2 * alpha
+ inter_hsv = self.tensor_rgb_to_hsv(rgb)
+ return inter_hsv
+
+ def interpolate_triple(self, latent1, latent2, latent3, alpha1, alpha2, alpha3):
+ """
+ (latent1 * alpha1 + latent2 * alpha2 + latent3 * alpha3) / (alpha1 + alpha2 + alpha3)
+ :return: final latent
+ """
+ latent12 = self.interpolate(latent1, latent2, alpha2 / (alpha1 + alpha2))
+ latent_res = self.interpolate(latent12, latent3, alpha3)
+ return latent_res
+
+ def interpolate(self, latent1, latent2, alpha):
+ """
+ final latent = latent1 * (1 - alpha) + latent2 * alpha
+ :return: final latent
+ """
+ result_latent = LatentRepresentation()
+ for att in ['curliness', 'shape', 'texture']:
+ result_latent.__setattr__(att, latent1.__getattribute__(att) * (1 - alpha) +
+ latent2.__getattribute__(att) * alpha)
+ color_dic = {}
+ color_dic['pca_std'] = latent1.color['pca_std'] * (1 - alpha) + latent2.color['pca_std'] * alpha
+ color_dic['hsv'] = self.interpolate_hsv(latent1.color['hsv'], latent2.color['hsv'], alpha)
+
+ result_latent.color = color_dic
+ result_latent.face = self.cur_latent.face
+ return result_latent
+
+ def interpolate_each_att(self, latent1, latent2, alpha, att_name):
+ """
+ interpolate a certain latent
+ :param att_name: curliness, shape, texture, color
+ :return: final full latent
+ """
+ result_latent = LatentRepresentation()
+ for att in ['curliness', 'shape', 'texture']:
+ result_latent.__setattr__(att, self.cur_latent.__getattribute__(att).clone())
+
+ if att_name == 'shape':
+ # keep color
+ color_dic = {}
+ for semantic in ['hsv', 'pca_std']:
+ color_dic[semantic] = self.cur_latent.color[semantic].clone()
+ result_latent.__setattr__(att_name, latent1.__getattribute__(att_name) * (1 - alpha) +
+ latent2.__getattribute__(att_name) * alpha)
+ elif att_name in ['curliness', 'texture']:
+ # keep color
+ color_dic = {}
+ for semantic in ['hsv', 'pca_std']:
+ color_dic[semantic] = self.cur_latent.color[semantic].clone()
+ result_latent.__setattr__('curliness', latent1.__getattribute__('curliness') * (1 - alpha) +
+ latent2.__getattribute__('curliness') * alpha)
+ result_latent.__setattr__('texture', latent1.__getattribute__('texture') * (1 - alpha) +
+ latent2.__getattribute__('texture') * alpha)
+ else:
+ color_dic = {}
+ # for semantic in ['hsv', 'pca_std']:
+ color_dic['pca_std'] = latent1.color['pca_std'] * (1 - alpha) + latent2.color['pca_std'] * alpha
+ color_dic['hsv'] = self.interpolate_hsv(latent1.color['hsv'], latent2.color['hsv'], alpha)
+
+ result_latent.color = color_dic
+ result_latent.face = self.cur_latent.face
+
+ return result_latent
+
+ @staticmethod
+ def show_hair_region(mask, non_hair_value=0):
+ """
+ Get hair region, and full none hair region as `non_hair_value`
+ :param mask:
+ :param non_hair_value:
+ :return:
+ """
+ mask_rgb = mask_to_rgb(mask, draw_type=1)
+ mask_rgb[mask != HAIR_IDX] = non_hair_value
+ return mask_rgb
+
+ def directly_change_hair_mask(self, hair_mask):
+ """
+ Directly replace hair region with a hair_mask. This is a recommend method to imply mask transfer.
+ :param hair_mask:
+ :return:
+ """
+ hair_mask = hair_mask == HAIR_IDX
+ face_logit = self.mask_generator.forward_face_decoder(self.cur_latent.face)
+ hair_logit = torch.tensor(hair_mask)[None, None, ...].type_as(face_logit).to(self.device)
+ hair_logit = hair_logit * (face_logit.max() - face_logit.min() + 2) + face_logit.min() - 1
+ mask = self.mask_generator.forward_decoder(hair_logit, face_logit)
+ self.cur_mask = mask_one_hot_to_label(mask).cpu().numpy()[0]
+
+ def get_random_texture(self):
+ """
+ sample a texture latent code randomly
+ :return:
+ """
+ random_latent = generate_noise(1, 8)
+ random_latent = random_latent.to(self.device)
+ self.cur_latent.texture = random_latent
+
+ def get_random_shape(self):
+ """
+ sample a shape latent code randomly
+ :return:
+ """
+ random_latent = generate_noise(1, 16)
+ random_latent = random_latent.to(self.device)
+ self.cur_latent.shape = random_latent
+ self.refresh_cur_mask()
+
+ def get_random_curliness(self):
+ """
+ sample a curliness latent code randomly
+ :return:
+ """
+ random_latent = generate_noise(1, 1)
+ random_latent = random_latent.to(self.device)
+ self.cur_latent.curliness = random_latent
+
+ def continue_change_with_direction(self, att_name, direction, val):
+ """
+ change the latent code value on a projection direction
+ :param att_name: shape or texture
+ :param direction: projection direction
+ :param val: coordinate on this projection direction
+ :return:
+ """
+ att = self.cur_latent.__getattribute__(att_name)
+ att = att + (val - torch.dot(att[0], direction)) * direction
+ self.cur_latent.__setattr__(att_name, att)
+ if att_name == 'shape':
+ self.refresh_cur_mask()
+
+
+"""
+This is a example of using Backend for costume editing
+"""
+if __name__ == '__main__':
+ be = Backend(2.5)
+ from util.imutil import read_rgb, write_rgb
+
+ input_image = read_rgb('imgs/00079.png')
+ target_image = read_rgb('imgs/00001.png')
+
+ """
+ If the image need crop
+ """
+ # input_image = be.crop_face(input_image)
+ # target_image = be.crop_face(target_image)
+
+ input_image = cv2.resize(input_image, (256, 256))
+
+ be.set_input_img(input_image)
+ be.set_target_img(target_image)
+
+ # transfer all latent code from target image to input image
+ be.transfer_latent_representation('texture')
+ be.transfer_latent_representation('color')
+ be.transfer_latent_representation('shape')
+
+ # change the variance manually
+ be.change_color(1.0, 2)
+
+ out_mask = be.get_mask(input_image)
+ output_img = be.output()
+ write_rgb('temp.png', output_img)
+ # above is the output image
+
+ im2 = read_rgb('imgs/00037.png')
+ im2 = cv2.resize(im2, (256, 256))
+ be.set_target_img(im2)
+ be.transfer_latent_representation('shape')
+ output_img2 = be.output()
+ # above is the output image 2
diff --git a/models/CtrlHair/ui/frontend_demo.py b/models/CtrlHair/ui/frontend_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..610880ee28302cf605f4a31df1a604606fb856a1
--- /dev/null
+++ b/models/CtrlHair/ui/frontend_demo.py
@@ -0,0 +1,269 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: frontend.py
+# Time : 2022/2/20 15:58
+# Author: xyguoo@163.com
+# Description: This is the demo frontend
+"""
+
+import sys
+sys.path.append('.')
+
+from global_value_utils import TEMP_FOLDER
+import argparse
+import os
+
+from util.common_options import ctrl_hair_parser_options
+
+parser = argparse.ArgumentParser()
+ctrl_hair_parser_options(parser)
+
+args = parser.parse_args()
+os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
+from ui.backend import Backend
+from util.imutil import read_rgb, write_rgb
+
+from PyQt5.QtWidgets import QWidget, QPushButton, QVBoxLayout, QApplication, QLabel, QGridLayout, \
+ QSlider, QFileDialog
+from PyQt5.QtGui import QPixmap, QFont
+from PyQt5.QtCore import Qt
+
+
+class Example(QWidget):
+ def __init__(self):
+ super().__init__()
+ self.temp_path = os.path.join(TEMP_FOLDER, 'demo_output')
+ self.maximum_value = 2.0
+ self.blending = not args.no_blending
+ self.backend = Backend(self.maximum_value, blending=self.blending)
+ self.initUI()
+ self.target_size = 256
+ self.need_crop = args.need_crop
+ if not os.path.exists(self.temp_path):
+ os.makedirs(self.temp_path)
+ self.font = QFont()
+ self.font.setPointSize(15)
+ self.setFont(self.font)
+
+ self.input_name = None
+ self.target_name = None
+
+ def initUI(self):
+ self.lbl_target_img = QLabel(self)
+ self.lbl_input_img = QLabel(self)
+ self.lbl_input_seg = QLabel(self)
+ self.lbl_out_img = QLabel(self)
+
+ self.labels = [self.lbl_target_img, self.lbl_input_img,
+ self.lbl_input_seg, self.lbl_out_img]
+
+ self.grid1 = QGridLayout()
+ # tags = ['target image', 'input image', 'hair shape', 'color_texture']
+ # for idx in range(len(self.labels)):
+ # self.grid1.addWidget(QLabel(tags[idx]), 0, idx)
+ for idx in range(len(self.labels)):
+ self.grid1.addWidget(self.labels[idx], 1, idx, alignment=Qt.AlignTop)
+ self.labels[idx].setFixedSize(256, 256)
+
+ self.btn_open_target = QPushButton('Target Image', self)
+ self.btn_open_target.clicked[bool].connect(self.evt_open_target)
+ self.grid1.addWidget(self.btn_open_target, 0, 0)
+
+ self.btn_open_input = QPushButton('Input Image', self)
+ self.btn_open_input.clicked[bool].connect(self.evt_open_input)
+ self.grid1.addWidget(self.btn_open_input, 0, 1)
+
+ self.grid1.addWidget(QLabel('Hair Shape'), 0, 2, alignment=Qt.AlignCenter)
+
+ self.btn_output = QPushButton('Output', self)
+ self.btn_output.clicked[bool].connect(self.evt_output)
+ self.grid1.addWidget(self.btn_output, 0, 3)
+ self.btn_output.setEnabled(False)
+
+ self.grid2 = QGridLayout()
+
+ self.btn_trans_color = QPushButton('Transfer Color', self)
+ self.btn_trans_color.clicked[bool].connect(self.evt_trans_color)
+ self.grid2.addWidget(self.btn_trans_color, 10, 0)
+ self.btn_trans_color.setEnabled(False)
+
+ self.btn_trans_texture = QPushButton('Transfer Texture', self)
+ self.btn_trans_texture.clicked[bool].connect(self.evt_trans_texture)
+ self.grid2.addWidget(self.btn_trans_texture, 10, 1)
+ self.btn_trans_texture.setEnabled(False)
+
+ self.btn_trans_shape = QPushButton('Transfer Shape', self)
+ self.btn_trans_shape.clicked[bool].connect(self.evt_trans_shape)
+ self.grid2.addWidget(self.btn_trans_shape, 10, 2)
+ self.btn_trans_shape.setEnabled(False)
+
+ self.sld2val = {}
+ self.val2sld = {}
+
+ self.label_color = ['Color: Hue', 'Color: Saturation', 'Color: Brightness',
+ 'Color: Variance']
+ self.label_shape = ['Shape: Volume', 'Shape: Bangs', 'Shape: Length', 'Shape: Direction']
+ self.label_curliness = ['Texture: Curliness']
+ self.label_app = ['Texture: Smoothness', 'Texture: Thickness']
+ self.label_total = self.label_color + self.label_shape + self.label_curliness + self.label_app
+
+ col_num = 4
+ row_num = 3
+ for row in range(row_num):
+ for col in range(col_num):
+ if col == 3 and row == 2:
+ continue
+ num = col_num * row + col
+ sld = QSlider(Qt.Horizontal, self)
+ sld.setMinimum(-self.maximum_value * 100)
+ sld.setMaximum(self.maximum_value * 100)
+ sld.sliderMoved[int].connect(self.evt_change_value)
+ self.sld2val[sld] = num
+ self.val2sld[num] = sld
+ self.grid2.addWidget(QLabel(self.label_total[num]), row * 2 + 2, col)
+ self.grid2.addWidget(sld, row * 2 + 2 + 1, col)
+ sld.setEnabled(False)
+
+ self.grid2.addWidget(QLabel(), 10, 3)
+
+ whole_vbox = QVBoxLayout(self)
+ whole_vbox.addLayout(self.grid1)
+ whole_vbox.addLayout(self.grid2)
+
+ self.setLayout(whole_vbox)
+ self.setGeometry(100, 100, 900, 600)
+ self.setWindowTitle('CtrlHair')
+ self.show()
+
+ def evt_open_target(self):
+ fname = QFileDialog.getOpenFileName(self, 'Open image file')
+ if fname[0]:
+ self.target_name = fname[0]
+ self.load_target_image(fname[0])
+ if self.input_name is not None:
+ self.btn_trans_color.setEnabled(True)
+ self.btn_trans_shape.setEnabled(True)
+ self.btn_trans_texture.setEnabled(True)
+
+ def evt_open_input(self):
+ fname = QFileDialog.getOpenFileName(self, 'Open image file')
+ if fname[0]:
+ input_name = fname[0]
+ self.input_name = input_name
+ self.load_input_image(input_name)
+ self.btn_output.setEnabled(True)
+ if self.target_name is not None:
+ self.btn_trans_color.setEnabled(True)
+ self.btn_trans_shape.setEnabled(True)
+ self.btn_trans_texture.setEnabled(True)
+
+ for kk in self.sld2val:
+ kk.setEnabled(True)
+
+ def evt_output(self):
+ output_img = self.backend.output()
+ img_path = os.path.join(self.temp_path, 'out_img.png')
+ write_rgb(img_path, output_img)
+ self.lbl_out_img.setPixmap((QPixmap(img_path)))
+
+ def evt_trans_color(self):
+ self.backend.transfer_latent_representation('color')
+ self.refresh_slider()
+
+ def evt_trans_texture(self):
+ self.backend.transfer_latent_representation('texture')
+ self.refresh_slider()
+
+ def evt_trans_shape(self):
+ self.backend.transfer_latent_representation('shape', refresh=True)
+ self.refresh_slider()
+ input_parsing_show = self.backend.get_cur_mask()
+ input_parsing_path = os.path.join(self.temp_path, 'input_parsing.png')
+ write_rgb(input_parsing_path, input_parsing_show)
+ self.lbl_input_seg.setPixmap((QPixmap(input_parsing_path)))
+
+ def load_input_image(self, img_path):
+ img = read_rgb(img_path)
+ if self.need_crop:
+ img = self.backend.crop_face(img)
+ input_img, input_parsing_show = self.backend.set_input_img(img_rgb=img)
+ input_path = os.path.join(self.temp_path, 'input_img.png')
+ write_rgb(input_path, input_img)
+ self.lbl_input_img.setPixmap((QPixmap(input_path)))
+
+ input_parsing_path = os.path.join(self.temp_path, 'input_parsing.png')
+ write_rgb(input_parsing_path, input_parsing_show)
+ self.lbl_input_seg.setPixmap((QPixmap(input_parsing_path)))
+ self.refresh_slider()
+
+ self.lbl_out_img.setPixmap(QPixmap(None))
+
+ def load_target_image(self, img_path):
+ img = read_rgb(img_path)
+ if self.need_crop:
+ img = self.backend.crop_face(img)
+ input_img, input_parsing_show = self.backend.set_target_img(img_rgb=img)
+ input_path = os.path.join(self.temp_path, 'target_img.png')
+ write_rgb(input_path, input_img)
+ self.lbl_target_img.setPixmap((QPixmap(input_path)))
+
+ def refresh_slider(self):
+ idx = 0
+ # color
+ color_val = self.backend.get_color_be2fe()
+ for ii in range(4):
+ self.val2sld[idx + ii].setValue(int(color_val[ii] * 100))
+
+ # shape
+ idx += len(self.label_color)
+ shape_val = self.backend.get_shape_be2fe()
+ for ii in range(4):
+ self.val2sld[idx + ii].setValue(int(shape_val[ii] * 100))
+
+ # curliness
+ idx += len(self.label_shape)
+ self.val2sld[idx].setValue(self.backend.get_curliness_be2fe() * 100)
+ # texture
+ idx += len(self.label_curliness)
+ app_val = self.backend.get_texture_be2fe()
+ for ii in range(2):
+ self.val2sld[idx + ii].setValue(int(app_val[ii] * 100))
+
+ def evt_change_value(self, sld_v):
+ """
+ change all sliders value
+ :param v: 0-100
+ :return:
+ """
+ v = sld_v / 100.0
+ sld_idx = self.sld2val[self.sender()]
+ if sld_idx < len(self.label_color):
+ self.backend.change_color(v, sld_idx)
+ return
+ sld_idx -= len(self.label_color)
+ if sld_idx < len(self.label_shape):
+ self.backend.change_shape(v, sld_idx)
+ input_parsing_show = self.backend.get_cur_mask()
+ input_parsing_path = os.path.join(self.temp_path, 'input_parsing.png')
+ write_rgb(input_parsing_path, input_parsing_show)
+ self.lbl_input_seg.setPixmap((QPixmap(input_parsing_path)))
+ return
+ sld_idx -= len(self.label_shape)
+ if sld_idx < len(self.label_curliness):
+ self.backend.change_curliness(v)
+ return
+ sld_idx -= len(self.label_curliness)
+ if sld_idx < len(self.label_app):
+ self.backend.change_texture(v, sld_idx)
+ return
+
+
+def main():
+ app = QApplication(sys.argv)
+ ex = Example()
+ sys.exit(app.exec_())
+
+
+if __name__ == '__main__':
+ main()
diff --git a/models/CtrlHair/util/__init__.py b/models/CtrlHair/util/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/CtrlHair/util/canvas_grid.py b/models/CtrlHair/util/canvas_grid.py
new file mode 100644
index 0000000000000000000000000000000000000000..65a200854f842ce8d83876be58bc401c2c24bcc9
--- /dev/null
+++ b/models/CtrlHair/util/canvas_grid.py
@@ -0,0 +1,34 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: canvas_grid.py
+# Time : 2021/11/18 16:40
+# Author: xyguoo@163.com
+# Description: This is the util that generating image in a big grid picture
+"""
+
+import numpy as np
+
+from util.imutil import write_rgb
+
+
+class Canvas:
+ def __init__(self, row, col, img_size=256, margin=0):
+ self.row = row
+ self.col = col
+ self.img_size = img_size
+ self.margin = margin
+ self.canvas = np.ones((row * img_size, col * img_size + margin * (col - 1), 3), dtype='uint8') * 255
+
+ def process_draw_image(self, img, i, j):
+ if img.dtype in [np.float32, np.float, np.float64]:
+ if img.min() < 0:
+ img = img * 127.5 + 127.5
+ elif img.max() <= 1:
+ img = img * 255
+ img = img.astype('uint8')
+ i_start, j_start = int(i * self.img_size), int(j * self.img_size) + int(j * self.margin)
+ self.canvas[i_start: i_start + img.shape[0], j_start: j_start + img.shape[1], :] = img
+
+ def write_(self, file):
+ write_rgb(file, self.canvas)
diff --git a/models/CtrlHair/util/color_from_hsv_to_gaussian.py b/models/CtrlHair/util/color_from_hsv_to_gaussian.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a45b8bacc231d6430eaf971288bd859a5a8d55d
--- /dev/null
+++ b/models/CtrlHair/util/color_from_hsv_to_gaussian.py
@@ -0,0 +1,40 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: color_from_hsv_to_gaussian.py
+# Time : 2022/3/6 16:00
+# Author: xyguoo@163.com
+# Description: transfer HSV value to Gaussian latent value according to the distribution of the dataset
+"""
+import os
+import pickle as pkl
+from bisect import bisect_left, bisect_right
+
+import scipy.stats as st
+
+
+class DistTranslation:
+ def __init__(self):
+ hair_root = 'dataset_info_ctrlhair'
+ with open(os.path.join(hair_root, 'hsv_stat_dict_ordered.pkl'), 'rb') as f:
+ self.cols_hsv = pkl.load(f)
+
+ def gaussian_to_val(self, dim, val):
+ # if dim == 0:
+ # return (val + 2.) / 4 * 179
+ return self.cols_hsv[int((st.norm.cdf(val)) * self.cols_hsv.shape[0])][dim]
+
+ def val_to_gaussian(self, dim, val):
+ # if dim == 0:
+ # return val / 179 * 2 * 2. - 2.
+
+ left_v = bisect_left(self.cols_hsv[:, dim], val)
+ right_v = bisect_right(self.cols_hsv[:, dim], val)
+ return st.norm.ppf((left_v + right_v) / 2 / self.cols_hsv.shape[0])
+
+#
+# if __name__ == '__main__':
+# dt = DistTranslation()
+#
+# with open('hsv_stat_dict_ordered.pkl', 'wb') as f:
+# pkl.dump(dt.cols_hsv, f)
diff --git a/models/CtrlHair/util/common_options.py b/models/CtrlHair/util/common_options.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f54b7f53ca743e0da96d2a2c05aad5cd234d569
--- /dev/null
+++ b/models/CtrlHair/util/common_options.py
@@ -0,0 +1,15 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: common_options.py
+# Time : 2022/7/12
+# Author: xyguoo@163.com
+# Description:
+"""
+
+def ctrl_hair_parser_options(parser):
+ parser.add_argument('-c', '--config', type=str, default='001')
+ parser.add_argument('-g', '--gpu', type=str, help='Specify GPU number', default='0')
+ parser.add_argument('-n', '--need_crop', type=bool, help='whether images need crop', default=True)
+ parser.add_argument('--no_blending', action='store_true',
+ help='whether using poisson blending as post processing', default=False)
\ No newline at end of file
diff --git a/models/CtrlHair/util/find_semantic_direction.py b/models/CtrlHair/util/find_semantic_direction.py
new file mode 100644
index 0000000000000000000000000000000000000000..e2f8b06abc4cd0906825404cfeb2639a3ac82b31
--- /dev/null
+++ b/models/CtrlHair/util/find_semantic_direction.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: find_semantic_direction.py
+# Time : 2022/07/17
+# Author: xyguoo@163.com
+# Description:
+"""
+import torch
+
+
+def get_random_direction(dim, existing_dirs):
+ dir = torch.randn(dim)
+
+ for dd in existing_dirs:
+ dir = dir - torch.dot(dir, dd) * dd
+
+ if dir[0] < 0:
+ dir = -dir
+ dir = dir / dir.norm()
+ return dir
diff --git a/models/CtrlHair/util/imutil.py b/models/CtrlHair/util/imutil.py
new file mode 100644
index 0000000000000000000000000000000000000000..539fa8c449eb192a8c84d5c01588f029a5ecd93d
--- /dev/null
+++ b/models/CtrlHair/util/imutil.py
@@ -0,0 +1,24 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: imutil.py
+# Time : 2021/12/7 14:55
+# Author: xyguoo@163.com
+# Description:
+"""
+import cv2
+import numpy as np
+
+
+def read_rgb(img_path):
+ im = cv2.imread(img_path)
+ im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
+ return im
+
+
+def write_rgb(file_name, img):
+ if len(img.shape) == 2:
+ img = np.stack([img] * 3, axis=2)
+ elif img.shape[2] == 1:
+ img = np.tile(img, [1, 1, 3])
+ cv2.imwrite(file_name, cv2.cvtColor(img, cv2.COLOR_RGB2BGR))
diff --git a/models/CtrlHair/util/mask_color_util.py b/models/CtrlHair/util/mask_color_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..8751567c07bd3abad70f7a6bf0257fecda80bf5c
--- /dev/null
+++ b/models/CtrlHair/util/mask_color_util.py
@@ -0,0 +1,64 @@
+# -*- coding: utf-8 -*-
+
+"""
+# File name: mask_color_util.py
+# Time : 2021/12/7 11:13
+# Author: xyguoo@163.com
+# Description:
+"""
+
+import numpy as np
+
+from models.CtrlHair.global_value_utils import HAIR_IDX
+
+
+def mask_to_rgb(pred, draw_type=2):
+ """
+ generate visual mask image
+ :param pred: pred is the label image with pixel vale in {0, 1, 2, ..., 20}
+ :param draw_type: 0: all part; 1: {bg, face, hair}; 2: {hair, others}
+ :return:
+ """
+ if len(pred.shape) == 3 and pred.shape[0] == 1:
+ pred = pred[0]
+ num_labels = 19
+ color = np.array([[0, 128, 64],
+ [204, 0, 0],
+ [76, 153, 0],
+ [204, 204, 0], ##
+ [51, 51, 255], ##
+ [204, 0, 204], ##
+ [0, 255, 255], ##
+ [51, 255, 255], ##
+ [102, 51, 0], ##
+ [255, 0, 0], ##
+ [102, 204, 0], ##
+ [255, 255, 0], ##
+ [0, 0, 153], ##
+ [0, 0, 204], ##
+ [255, 51, 153], ##
+ [0, 204, 204], ##
+ [0, 51, 0], ##
+ [255, 153, 51],
+ [0, 204, 0],
+ ])
+
+ for cc in range(len(color)):
+ if draw_type == 2:
+ if cc != HAIR_IDX:
+ color[cc] = [255, 255, 255]
+ elif draw_type == 1:
+ if cc != HAIR_IDX and cc != 0:
+ color[cc] = [237, 28, 36]
+
+ h, w = np.shape(pred)
+ rgb = np.zeros((h, w, 3), dtype=np.uint8)
+ # print(color.shape)
+ for ii in range(num_labels):
+ # print(ii)
+ mask = pred == ii
+ rgb[mask, None] = color[ii, :]
+ # Correct unk
+ unk = pred == 255
+ rgb[unk, None] = 255
+ return rgb
diff --git a/models/CtrlHair/util/util.py b/models/CtrlHair/util/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3eb65e92ea5963f3df4e6ed4c9018e870cd0181
--- /dev/null
+++ b/models/CtrlHair/util/util.py
@@ -0,0 +1,281 @@
+"""
+These interfaces are most based on SEAN. But we modify some of them, and add some new interface for our CtrlHair.
+"""
+
+import argparse
+import importlib
+import os
+import re
+
+import cv2
+import dill as pickle
+import numpy as np
+import torch
+from PIL import Image
+
+
+def save_obj(obj, name):
+ with open(name, 'wb') as f:
+ pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
+
+
+def load_obj(name):
+ with open(name, 'rb') as f:
+ return pickle.load(f)
+
+# returns a configuration for creating a generator
+# |default_opt| should be the opt of the current experiment
+# |**kwargs|: if any configuration should be overriden, it can be specified here
+
+
+def copyconf(default_opt, **kwargs):
+ conf = argparse.Namespace(**vars(default_opt))
+ for key in kwargs:
+ print(key, kwargs[key])
+ setattr(conf, key, kwargs[key])
+ return conf
+
+
+def tile_images(imgs, picturesPerRow=4):
+ """ Code borrowed from
+ https://stackoverflow.com/questions/26521365/cleanly-tile-numpy-array-of-images-stored-in-a-flattened-1d-format/26521997
+ """
+
+ # Padding
+ if imgs.shape[0] % picturesPerRow == 0:
+ rowPadding = 0
+ else:
+ rowPadding = picturesPerRow - imgs.shape[0] % picturesPerRow
+ if rowPadding > 0:
+ imgs = np.concatenate([imgs, np.zeros((rowPadding, *imgs.shape[1:]), dtype=imgs.dtype)], axis=0)
+
+ # Tiling Loop (The conditionals are not necessary anymore)
+ tiled = []
+ for i in range(0, imgs.shape[0], picturesPerRow):
+ tiled.append(np.concatenate([imgs[j] for j in range(i, i + picturesPerRow)], axis=1))
+
+ tiled = np.concatenate(tiled, axis=0)
+ return tiled
+
+
+# Converts a Tensor into a Numpy array
+# |imtype|: the desired type of the converted numpy array
+def tensor2im(image_tensor, imtype=np.uint8, normalize=True, tile=False):
+ if isinstance(image_tensor, list):
+ image_numpy = []
+ for i in range(len(image_tensor)):
+ image_numpy.append(tensor2im(image_tensor[i], imtype, normalize))
+ return image_numpy
+
+ if image_tensor.dim() == 4:
+ # transform each image in the batch
+ images_np = []
+ for b in range(image_tensor.size(0)):
+ one_image = image_tensor[b]
+ one_image_np = tensor2im(one_image)
+ images_np.append(one_image_np.reshape(1, *one_image_np.shape))
+ images_np = np.concatenate(images_np, axis=0)
+ if tile:
+ images_tiled = tile_images(images_np)
+ return images_tiled
+ else:
+ return images_np
+
+ if image_tensor.dim() == 2:
+ image_tensor = image_tensor.unsqueeze(0)
+ image_numpy = image_tensor.detach().cpu().float().numpy()
+ if normalize:
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0
+ else:
+ image_numpy = np.transpose(image_numpy, (1, 2, 0)) * 255.0
+ image_numpy = np.clip(image_numpy, 0, 255)
+ if image_numpy.shape[2] == 1:
+ image_numpy = image_numpy[:, :, 0]
+ return image_numpy.astype(imtype)
+
+
+# Converts a one-hot tensor into a colorful label map
+def tensor2label(label_tensor, n_label, imtype=np.uint8, tile=False):
+ if label_tensor.dim() == 4:
+ # transform each image in the batch
+ images_np = []
+ for b in range(label_tensor.size(0)):
+ one_image = label_tensor[b]
+ one_image_np = tensor2label(one_image, n_label, imtype)
+ images_np.append(one_image_np.reshape(1, *one_image_np.shape))
+ images_np = np.concatenate(images_np, axis=0)
+ if tile:
+ images_tiled = tile_images(images_np)
+ return images_tiled
+ else:
+ images_np = images_np[0]
+ return images_np
+
+ if label_tensor.dim() == 1:
+ return np.zeros((64, 64, 3), dtype=np.uint8)
+ if n_label == 0:
+ return tensor2im(label_tensor, imtype)
+ label_tensor = label_tensor.cpu().float()
+ if label_tensor.size()[0] > 1:
+ label_tensor = label_tensor.max(0, keepdim=True)[1]
+ label_tensor = Colorize(n_label)(label_tensor)
+ label_numpy = np.transpose(label_tensor.numpy(), (1, 2, 0))
+ result = label_numpy.astype(imtype)
+ return result
+
+
+def save_image(image_numpy, image_path, create_dir=False):
+ if create_dir:
+ os.makedirs(os.path.dirname(image_path), exist_ok=True)
+ if len(image_numpy.shape) == 2:
+ image_numpy = np.expand_dims(image_numpy, axis=2)
+ if image_numpy.shape[2] == 1:
+ image_numpy = np.repeat(image_numpy, 3, 2)
+ image_pil = Image.fromarray(image_numpy)
+
+ # save to png
+ image_pil.save(image_path.replace('.jpg', '.png'))
+
+
+def mkdirs(paths):
+ if isinstance(paths, list) and not isinstance(paths, str):
+ for path in paths:
+ mkdir(path)
+ else:
+ mkdir(paths)
+
+
+def mkdir(path):
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+
+def atoi(text):
+ return int(text) if text.isdigit() else text
+
+
+def natural_keys(text):
+ '''
+ alist.sort(key=natural_keys) sorts in human order
+ http://nedbatchelder.com/blog/200712/human_sorting.html
+ (See Toothy's implementation in the comments)
+ '''
+ return [atoi(c) for c in re.split('(\d+)', text)]
+
+
+def natural_sort(items):
+ items.sort(key=natural_keys)
+
+
+def str2bool(v):
+ if v.lower() in ('yes', 'true', 't', 'y', '1'):
+ return True
+ elif v.lower() in ('no', 'false', 'f', 'n', '0'):
+ return False
+ else:
+ raise argparse.ArgumentTypeError('Boolean value expected.')
+
+
+def find_class_in_module(target_cls_name, module):
+ target_cls_name = target_cls_name.replace('_', '').lower()
+ clslib = importlib.import_module(module)
+ cls = None
+ for name, clsobj in clslib.__dict__.items():
+ if name.lower() == target_cls_name:
+ cls = clsobj
+
+ if cls is None:
+ print("In %s, there should be a class whose name matches %s in lowercase without underscore(_)" % (module, target_cls_name))
+ exit(0)
+
+ return cls
+
+
+def save_network(net, label, epoch, opt):
+ save_filename = '%s_net_%s.pth' % (epoch, label)
+ save_path = os.path.join(opt.checkpoints_dir, opt.name, save_filename)
+ torch.save(net.cpu().state_dict(), save_path)
+ if len(opt.gpu_ids) and torch.cuda.is_available():
+ net.cuda()
+
+
+def load_network(net, label, epoch, opt):
+ save_filename = '%s_net_%s.pth' % (epoch, label)
+ save_dir = os.path.join(opt.checkpoints_dir, opt.name)
+ save_path = os.path.join(save_dir, save_filename)
+ weights = torch.load(save_path)
+ net.load_state_dict(weights)
+ return net
+
+
+###############################################################################
+# Code from
+# https://github.com/ycszen/pytorch-seg/blob/master/transform.py
+# Modified so it complies with the Citscape label map colors
+###############################################################################
+def uint82bin(n, count=8):
+ """returns the binary of integer n, count refers to amount of bits"""
+ return ''.join([str((n >> y) & 1) for y in range(count - 1, -1, -1)])
+
+
+def labelcolormap(N):
+ if N == 35: # cityscape
+ cmap = np.array([(0, 0, 0), (0, 0, 0), (0, 0, 0), (0, 0, 0), (0, 0, 0), (111, 74, 0), (81, 0, 81),
+ (128, 64, 128), (244, 35, 232), (250, 170, 160), (230, 150, 140), (70, 70, 70), (102, 102, 156), (190, 153, 153),
+ (180, 165, 180), (150, 100, 100), (150, 120, 90), (153, 153, 153), (153, 153, 153), (250, 170, 30), (220, 220, 0),
+ (107, 142, 35), (152, 251, 152), (70, 130, 180), (220, 20, 60), (255, 0, 0), (0, 0, 142), (0, 0, 70),
+ (0, 60, 100), (0, 0, 90), (0, 0, 110), (0, 80, 100), (0, 0, 230), (119, 11, 32), (0, 0, 142)],
+ dtype=np.uint8)
+ else:
+ cmap = np.zeros((N, 3), dtype=np.uint8)
+ for i in range(N):
+ r, g, b = 0, 0, 0
+ id = i + 1 # let's give 0 a color
+ for j in range(7):
+ str_id = uint82bin(id)
+ r = r ^ (np.uint8(str_id[-1]) << (7 - j))
+ g = g ^ (np.uint8(str_id[-2]) << (7 - j))
+ b = b ^ (np.uint8(str_id[-3]) << (7 - j))
+ id = id >> 3
+ cmap[i, 0] = r
+ cmap[i, 1] = g
+ cmap[i, 2] = b
+
+ return cmap
+
+
+class Colorize(object):
+ def __init__(self, n=35):
+ self.cmap = labelcolormap(n)
+ self.cmap = torch.from_numpy(self.cmap[:n])
+
+ def __call__(self, gray_image):
+ size = gray_image.size()
+ color_image = torch.ByteTensor(3, size[1], size[2]).fill_(0)
+
+ for label in range(0, len(self.cmap)):
+ mask = (label == gray_image[0]).cpu()
+ color_image[0][mask] = self.cmap[label][0]
+ color_image[1][mask] = self.cmap[label][1]
+ color_image[2][mask] = self.cmap[label][2]
+
+ return color_image
+
+
+def make_folder(path):
+ if not os.path.exists(os.path.join(path)):
+ os.makedirs(os.path.join(path))
+
+
+def path_join_abs(*paths):
+ return os.path.abspath(os.path.join(*paths))
+
+
+def draw_landmark(landmarks, img_rd):
+ landmarks = landmarks.astype('int')
+ img_rd = img_rd.copy()
+ for idx, point in enumerate(landmarks):
+ pos = (point[0], point[1])
+ cv2.circle(img_rd, pos, 2, color=(139, 0, 0))
+ cv2.putText(img_rd, str(idx + 1), pos, cv2.FONT_HERSHEY_SIMPLEX, 0.3, (0, 0, 255), 1, cv2.LINE_AA)
+ return img_rd
\ No newline at end of file
diff --git a/models/Embedding.py b/models/Embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f90b53c66a84bdd8940bf48d7d1e7b4746f4eea
--- /dev/null
+++ b/models/Embedding.py
@@ -0,0 +1,118 @@
+from collections import defaultdict
+
+import torch
+import torch.nn.functional as F
+import torchvision.transforms as T
+from torch import nn
+from torch.utils.data import DataLoader
+
+from datasets.image_dataset import ImagesDataset, image_collate
+from models.FeatureStyleEncoder import FSencoder
+from models.Net import Net, get_segmentation
+from models.encoder4editing.utils.model_utils import setup_model, get_latents
+from utils.bicubic import BicubicDownSample
+from utils.save_utils import save_gen_image, save_latents
+
+
+class Embedding(nn.Module):
+ """
+ Module for image embedding
+ """
+
+ def __init__(self, opts, net=None):
+ super().__init__()
+ self.opts = opts
+ if net is None:
+ self.net = Net(self.opts)
+ else:
+ self.net = net
+
+ self.encoder = FSencoder.get_trainer(self.opts.device)
+ self.e4e, _ = setup_model('pretrained_models/encoder4editing/e4e_ffhq_encode.pt', self.opts.device)
+
+ self.normalize = T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+ self.to_bisenet = T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
+
+ self.downsample_512 = BicubicDownSample(factor=2)
+ self.downsample_256 = BicubicDownSample(factor=4)
+
+ def setup_dataloader(self, images: dict[torch.Tensor, list[str]] | list[torch.Tensor], batch_size=None):
+ self.dataset = ImagesDataset(images)
+ self.dataloader = DataLoader(self.dataset, collate_fn=image_collate, shuffle=False,
+ batch_size=batch_size or self.opts.batch_size)
+
+ @torch.inference_mode()
+ def get_e4e_embed(self, images: list[torch.Tensor]) -> dict[str, torch.Tensor]:
+ device = self.opts.device
+ self.setup_dataloader(images, batch_size=len(images))
+
+ for image, _ in self.dataloader:
+ image = image.to(device)
+ latent_W = get_latents(self.e4e, image)
+ latent_F, _ = self.net.generator([latent_W], input_is_latent=True, return_latents=False,
+ start_layer=0, end_layer=3)
+ return {"F": latent_F, "W": latent_W}
+
+ @torch.inference_mode()
+ def embedding_images(self, images_to_name: dict[torch.Tensor, list[str]], **kwargs) -> dict[
+ str, dict[str, torch.Tensor]]:
+ device = self.opts.device
+ self.setup_dataloader(images_to_name)
+
+ name_to_embed = defaultdict(dict)
+ for image, names in self.dataloader:
+ image = image.to(device)
+
+ im_512 = self.downsample_512(image)
+ im_256 = self.downsample_256(image)
+ im_256_norm = self.normalize(im_256)
+
+ # E4E
+ latent_W = get_latents(self.e4e, im_256_norm)
+
+ # FS encoder
+ output = self.encoder.test(img=self.normalize(image), return_latent=True)
+ latent = output.pop() # [bs, 512, 16, 16]
+ latent_S = output.pop() # [bs, 18, 512]
+
+ latent_F, _ = self.net.generator([latent_S], input_is_latent=True, return_latents=False,
+ start_layer=3, end_layer=3, layer_in=latent) # [bs, 512, 32, 32]
+
+ # BiSeNet
+ masks = torch.cat([get_segmentation(image.unsqueeze(0)) for image in self.to_bisenet(im_512)])
+
+ # Mixing if we change the color or shape
+ if len(images_to_name) > 1:
+ hair_mask = torch.where(masks == 13, torch.ones_like(masks, device=device),
+ torch.zeros_like(masks, device=device))
+ hair_mask = F.interpolate(hair_mask.float(), size=(32, 32), mode='bicubic')
+
+ latent_F_from_W = self.net.generator([latent_W], input_is_latent=True, return_latents=False,
+ start_layer=0, end_layer=3)[0]
+ latent_F = latent_F + self.opts.mixing * hair_mask * (latent_F_from_W - latent_F)
+
+ for k, names in enumerate(names):
+ for name in names:
+ name_to_embed[name]['W'] = latent_W[k].unsqueeze(0)
+ name_to_embed[name]['F'] = latent_F[k].unsqueeze(0)
+ name_to_embed[name]['S'] = latent_S[k].unsqueeze(0)
+ name_to_embed[name]['mask'] = masks[k].unsqueeze(0)
+ name_to_embed[name]['image_256'] = im_256[k].unsqueeze(0)
+ name_to_embed[name]['image_norm_256'] = im_256_norm[k].unsqueeze(0)
+
+ if self.opts.save_all:
+ gen_W_im, _ = self.net.generator([latent_W], input_is_latent=True, return_latents=False)
+ gen_FS_im, _ = self.net.generator([latent_S], input_is_latent=True, return_latents=False,
+ start_layer=4, end_layer=8, layer_in=latent_F)
+
+ exp_name = exp_name if (exp_name := kwargs.get('exp_name')) is not None else ""
+ output_dir = self.opts.save_all_dir / exp_name
+ for name, im_W, lat_W in zip(names, gen_W_im, latent_W):
+ save_gen_image(output_dir, 'W+', f'{name}.png', im_W)
+ save_latents(output_dir, 'W+', f'{name}.npz', latent_W=lat_W)
+
+ for name, im_F, lat_S, lat_F in zip(names, gen_FS_im, latent_S, latent_F):
+ save_gen_image(output_dir, 'FS', f'{name}.png', im_F)
+ save_latents(output_dir, 'FS', f'{name}.npz', latent_S=lat_S, latent_F=lat_F)
+
+ return name_to_embed
diff --git a/models/Encoders.py b/models/Encoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fe25686776a73cb782b13691efcce37e3373669
--- /dev/null
+++ b/models/Encoders.py
@@ -0,0 +1,160 @@
+import argparse
+
+import clip
+import torch
+import torch.nn as nn
+from torch.nn import Linear, LayerNorm, LeakyReLU, Sequential
+from torchvision import transforms as T
+
+from models.Net import FeatureEncoderMult, IBasicBlock, conv1x1
+from models.stylegan2.model import PixelNorm
+
+
+class ModulationModule(nn.Module):
+ def __init__(self, layernum, last=False, inp=512, middle=512):
+ super().__init__()
+ self.layernum = layernum
+ self.last = last
+ self.fc = Linear(512, 512)
+ self.norm = LayerNorm([self.layernum, 512], elementwise_affine=False)
+ self.gamma_function = Sequential(Linear(inp, middle), LayerNorm([middle]), LeakyReLU(), Linear(middle, 512))
+ self.beta_function = Sequential(Linear(inp, middle), LayerNorm([middle]), LeakyReLU(), Linear(middle, 512))
+ self.leakyrelu = LeakyReLU()
+
+ def forward(self, x, embedding):
+ x = self.fc(x)
+ x = self.norm(x)
+ gamma = self.gamma_function(embedding)
+ beta = self.beta_function(embedding)
+ out = x * (1 + gamma) + beta
+ if not self.last:
+ out = self.leakyrelu(out)
+ return out
+
+
+class FeatureiResnet(nn.Module):
+ def __init__(self, blocks, inplanes=1024):
+ super().__init__()
+
+ self.res_blocks = {}
+
+ for n, block in enumerate(blocks, start=1):
+ planes, num_blocks = block
+
+ for k in range(1, num_blocks + 1):
+ downsample = None
+ if inplanes != planes:
+ downsample = nn.Sequential(conv1x1(inplanes, planes, 1), nn.BatchNorm2d(planes, eps=1e-05, ), )
+
+ self.res_blocks[f'res_block_{n}_{k}'] = IBasicBlock(inplanes, planes, 1, downsample, 1, 64, 1)
+ inplanes = planes
+
+ self.res_blocks = nn.ModuleDict(self.res_blocks)
+
+ def forward(self, x):
+ for module in self.res_blocks.values():
+ x = module(x)
+ return x
+
+
+class RotateModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.pixelnorm = PixelNorm()
+ self.modulation_module_list = nn.ModuleList([ModulationModule(6, i == 4) for i in range(5)])
+
+ def forward(self, latent_from, latent_to):
+ dt_latent = self.pixelnorm(latent_from)
+ for modulation_module in self.modulation_module_list:
+ dt_latent = modulation_module(dt_latent, latent_to)
+ output = latent_from + 0.1 * dt_latent
+ return output
+
+
+class ClipBlendingModel(nn.Module):
+ def __init__(self, clip_model="ViT-B/32"):
+ super().__init__()
+ self.pixelnorm = PixelNorm()
+ self.clip_model, _ = clip.load(clip_model, device="cuda")
+ self.transform = T.Compose(
+ [T.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))])
+ self.face_pool = torch.nn.AdaptiveAvgPool2d((224, 224))
+ self.modulation_module_list = nn.ModuleList(
+ [ModulationModule(12, i == 4, inp=512 * 3, middle=1024) for i in range(5)]
+ )
+
+ for param in self.clip_model.parameters():
+ param.requires_grad = False
+
+ def get_image_embed(self, image_tensor):
+ resized_tensor = self.face_pool(image_tensor)
+ renormed_tensor = self.transform(resized_tensor * 0.5 + 0.5)
+ return self.clip_model.encode_image(renormed_tensor)
+
+ def forward(self, latent_face, latent_color, target_face, hair_color):
+ embed_face = self.get_image_embed(target_face).unsqueeze(1).expand(-1, 12, -1)
+ embed_color = self.get_image_embed(hair_color).unsqueeze(1).expand(-1, 12, -1)
+ latent_in = torch.cat((latent_color, embed_face, embed_color), dim=-1)
+
+ dt_latent = self.pixelnorm(latent_face)
+ for modulation_module in self.modulation_module_list:
+ dt_latent = modulation_module(dt_latent, latent_in)
+ output = latent_face + 0.1 * dt_latent
+ return output
+
+
+class PostProcessModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.encoder_face = FeatureEncoderMult(fs_layers=[9], opts=argparse.Namespace(
+ **{'arcface_model_path': "pretrained_models/ArcFace/backbone_ir50.pth"}))
+
+ self.latent_avg = torch.load('pretrained_models/PostProcess/latent_avg.pt', map_location=torch.device('cuda'))
+ self.to_feature = FeatureiResnet([[1024, 2], [768, 2], [512, 2]])
+
+ self.to_latent_1 = nn.ModuleList([ModulationModule(18, i == 4) for i in range(5)])
+ self.to_latent_2 = nn.ModuleList([ModulationModule(18, i == 4) for i in range(5)])
+ self.pixelnorm = PixelNorm()
+
+ def forward(self, source, target):
+ s_face, [f_face] = self.encoder_face(source)
+ s_hair, [f_hair] = self.encoder_face(target)
+
+ dt_latent_face = self.pixelnorm(s_face)
+ dt_latent_hair = self.pixelnorm(s_hair)
+
+ for mod_module in self.to_latent_1:
+ dt_latent_face = mod_module(dt_latent_face, s_hair)
+
+ for mod_module in self.to_latent_2:
+ dt_latent_hair = mod_module(dt_latent_hair, s_face)
+
+ finall_s = self.latent_avg + 0.1 * (dt_latent_face + dt_latent_hair)
+
+ cat_f = torch.cat((f_face, f_hair), dim=1)
+ finall_f = self.to_feature(cat_f)
+
+ return finall_s, finall_f
+
+
+class ClipModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.clip_model, _ = clip.load("ViT-B/32", device="cuda")
+ self.transform = T.Compose(
+ [T.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))]
+ )
+ self.face_pool = torch.nn.AdaptiveAvgPool2d((224, 224))
+
+ for param in self.clip_model.parameters():
+ param.requires_grad = False
+
+ def forward(self, image_tensor):
+ if not image_tensor.is_cuda:
+ image_tensor = image_tensor.to("cuda")
+ if image_tensor.dtype == torch.uint8:
+ image_tensor = image_tensor / 255
+
+ resized_tensor = self.face_pool(image_tensor)
+ renormed_tensor = self.transform(resized_tensor)
+ return self.clip_model.encode_image(renormed_tensor)
diff --git a/models/FeatureStyleEncoder/.DS_Store b/models/FeatureStyleEncoder/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..24d931501c51af3fb84693dba0fd8b2afa221ab9
Binary files /dev/null and b/models/FeatureStyleEncoder/.DS_Store differ
diff --git a/models/FeatureStyleEncoder/.gitignore b/models/FeatureStyleEncoder/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..e5c5a4e8085394da550fb2da14170ba8c1ba0a49
--- /dev/null
+++ b/models/FeatureStyleEncoder/.gitignore
@@ -0,0 +1,6 @@
+logs/
+__pycache__/
+matshow/
+.ipynb_checkpoints/
+tmp/
+RAFT/
diff --git a/models/FeatureStyleEncoder/FSencoder.py b/models/FeatureStyleEncoder/FSencoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef93b00821569a381113695405d09c2adf3d7df1
--- /dev/null
+++ b/models/FeatureStyleEncoder/FSencoder.py
@@ -0,0 +1,41 @@
+from argparse import Namespace
+import glob
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+import yaml
+import sys
+
+current_dir = os.path.abspath(os.path.dirname(__file__))
+sys.path.insert(0, current_dir)
+
+from PIL import Image
+from tqdm import tqdm
+from torchvision import transforms, utils
+
+from trainer import *
+
+torch.backends.cudnn.enabled = True
+torch.backends.cudnn.deterministic = True
+torch.backends.cudnn.benchmark = True
+# torch.autograd.set_detect_anomaly(True)
+Image.MAX_IMAGE_PIXELS = None
+
+opts = Namespace(config='001', pretrained_model_path='pretrained_models/FeatureStyleEncoder/143_enc.pth', stylegan_model_path=f'pretrained_models/FeatureStyleEncoder/psp_ffhq_encode.pt', arcface_model_path=f'pretrained_models/FeatureStyleEncoder/backbone.pth', parsing_model_path=f'pretrained_models/FeatureStyleEncoder/79999_iter.pth', log_path='./logs/', resume=False, checkpoint='', checkpoint_noiser='', multigpu=False, input_path='./test/', save_path='./')
+
+config = yaml.load(open(f'{current_dir}/configs/' + opts.config + '.yaml', 'r'), Loader=yaml.FullLoader)
+
+def get_trainer(device):
+ # Initialize trainer
+ trainer = Trainer(config, opts)
+ trainer.initialize(opts.stylegan_model_path, opts.arcface_model_path, opts.parsing_model_path)
+ trainer.to(device)
+
+ # state_dict = torch.load(opts.pretrained_model_path)#os.path.join(opts.log_path, opts.config + '/checkpoint.pth'))
+ trainer.enc.load_state_dict(torch.load(opts.pretrained_model_path))
+ trainer.enc.eval()
+
+ return trainer
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/LICENSE.md b/models/FeatureStyleEncoder/LICENSE.md
new file mode 100644
index 0000000000000000000000000000000000000000..846612a6045a350bb13c23a278ed25a857d0b494
--- /dev/null
+++ b/models/FeatureStyleEncoder/LICENSE.md
@@ -0,0 +1,60 @@
+## LIMITED SOFTWARE EVALUATION LICENSE AGREEMENT
+
+The following Limited Software Evaluation License (the “License”) constitutes an agreement between you (the “Licensee”) and InterDigital Communications, Inc, a company organized and existing under the laws of the State of Delaware, USA, with its registered offices located at 200 Bellevue Parkway, Suite 300, Wilmington, DE 19809, USA (hereinafter “InterDigital”).
+This License governs the download and use of the Software (as defined below). Your use of the Software is subject to the terms and conditions set forth in this License. By installing, using, accessing or copying the Software, you hereby irrevocably accept the terms and conditions of this License. If you do not accept all parts of the terms and conditions of this License, you cannot install, use, access nor copy the Software.
+
+# Article 1. Definitions
+“Affiliate” as used herein shall mean any entity that, directly or indirectly, through one or more intermediates, is controlled by, controls, or is under common control with InterDigital or The Licensee, as the case may be. For purposes of this definition only, the term “control” means the possession of the power to direct or cause the direction of the management and policies of an entity, whether by ownership of voting stock or partnership interest, by contract, or otherwise, including direct or indirect ownership of more than fifty percent (50%) of the voting interest in the entity in question.
+“Authorized Purpose” means any use of the Software for fundamental research work with the exclusion of any commercial use. A commercial use includes, without limitation, any sublicense granted on the Software against a fee whatever its nature, any use of the Software in a product that is offered (either free or for a price) to any third party, any use of the Software to provide a service to a third party and/or any use of the Software to create a competing product of the Software ("Purpose")
+“Documentation” means textual materials delivered by InterDigital to the Licensee pursuant to this License relating to the Software, in written or electronic format, including but not limited to, technical reference manuals, technical notes, user manuals, and application guides.
+“Effective Date” means the date Licensee first installs a copy of the Software on any computer.
+
+“Limited Period” means the life of the copyright owned by InterDigital on the Software in each and every country where such copyright would exist.
+“Intellectual Property Rights” means all copyrights, trademarks, trade secrets, patents and any other intellectual property rights recognized in any jurisdiction worldwide, including all applications and registrations with respect thereto.
+"Open Source Software" shall mean any software, including where appropriate, any and all modifications, derivative works, enhancements, upgrades, improvements, fixed bugs, and/or statically linked to the source code of such software, released under a free or open source software license that requires, as a condition of usage, copy, modification and/or redistribution of such software, that the party:
+• Redistribute the Open Source Software royalty-free; and/or
+• Redistribute the Open Source Software under the same license/distribution terms as those contained in the open source or free software license under which it was originally released; and/or
+• Release to the public, disclose or otherwise make available the source code of the Open Source Software.
+For purposes of this License, by means of example and without limitation, any software that is released or distributed under any of the following licenses shall be qualified as Open Source Software: (i) GNU General Public License (GPL); (ii) GNU Lesser/Library GPL (LGPL); (iii) the Artistic License; (iv) the Mozilla Public License; (v) the Common Public License; (vi) the Sun Community Source License (SCSL); (vii) the Sun Industry Standards Source License (SISSL); (viii) BSD License; (ix) MIT License; (x) Apache Software License; (xi) Open SSL License; (xii) IBM Public License; and (xiii) Open Software License.
+“Software” means the Software with which this license was downloaded, namely FeatureStyleEncoder in object code.
+# Article 2. License
+InterDigital grants Licensee a free, worldwide, non-exclusive, license to InterDigital’s copyright on the Software to download, use and reproduce solely for the Authorized Purpose for the Limited Period.
+Licensee shall not pay any royalty, license fee or maintenance fee, or other fee of any nature under this License.
+# Article 3. Restrictions on use of the Software
+Licensee shall not have the right to correct, adapt, modify, reverse engineer, disassemble, decompile or/and otherwise perform or conduct any action leading to the transformation of the Software.
+Licensee shall not remove, obscure or modify any copyright, trademark or other proprietary rights notices, marks or labels contained on or within the Software, falsify or delete any author attributions, legal notices or other labels of the origin or source of the material.
+Licensee may reproduce and distribute copies of the Software in any medium provided that Licensee gives any other recipients of the Software a copy of this License.
+
+# Article 4. Ownership
+Title to and ownership of the Software, the Documentation, and/or any Intellectual Property Right protecting the Software and/or the Documentation shall at all times remain with InterDigital. Licensee agrees that except for the limited rights granted to the Software as set forth in Section 2 above, in no event shall anything in this License grant, provide, or convey any other rights, privileges, immunities, or interest in or to any Intellectual Property Rights (including but not limited to patent rights) of InterDigital or any of its Affiliates, whether by implication, estoppel, or otherwise.
+
+# Article 5. Publication/Communication
+Any publication or oral communication resulting from the use of the Software shall be elaborated in good faith and shall not be driven by a deliberate will to denigrate InterDigital or any of its products. In any publication and on any support joined to an oral communication (e.g., a PowerPoint presentation) relating to the Software, the following statement shall be inserted:
+“FeatureStyleEncoder” is an InterDigital product”
+In any publication, the latest publication about the software shall be properly cited. The latest publication currently is:
+A Style-Based GAN Encoder for High Fidelity Reconstruction of Images and Videos, Xu Yao, Alasdair Newson, Yann Gousseau, Pierre Hellier, ECCV European Conference on Computer Vision, 2022 (https://arxiv.org/pdf/2202.02183.pdf).
+In any oral communication relating to the Software and/or its use, the Licensee shall orally indicate that the Software is InterDigital’s property.
+
+# Article 6. No Warranty - Disclaimer
+THE SOFTWARE AND DOCUMENTATION ARE PROVIDED TO LICENSEE ON AN “AS IS” BASIS. INTERDIGITAL MAKES NO WARRANTY THAT THE SOFTWARE WILL OPERATE ON ANY PARTICULAR HARDWARE, PLATFORM, OR ENVIRONMENT. THERE IS NO WARRANTY THAT THE OPERATION OF THE SOFTWARE SHALL BE UNINTERRUPTED, WITHOUT BUGS OR ERROR FREE. THE SOFTWARE AND DOCUMENTATION ARE PROVIDED HEREUNDER WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY IMPLIED LIABILITIES AND WARRANTIES OF NONINFRINGEMENT OF INTELLECTUAL PROPERTY, FREEDOM FROM INHERENT DEFECTS, CONFORMITY TO A SAMPLE OR MODEL, MERCHANTABILITY, FITNESS AND/OR SUITABILITY FOR A SPECIFIC OR GENERAL PURPOSE AND THOSE ARISING BY STATUTE OR BY LAW, OR FROM A CAUSE OF DEALING OR USAGE OF TRADE. ANY AND ALL SUCH IMPLIED WARRANTIES ARE FULLY DISCLAIMED BY INTERDIGITAL TO THE MAXIMUM EXTENT ALLOWED BY LAW, AND LICENSEE ACKNOWLEDGES THAT THIS DISCLAIMER OF ALL EXPRESS AND IMPLIED WARRANTIES BY INTERDIGITAL, AS WELL AS LICENSEE’S ACCEPTANCE AND ACKNOWLEDGEMENT OF THE SAME, IS A MATERIAL PART OF THE CONSIDERATION FOR THIS LICENSE.
+InterDigital shall not be obligated to perform or provide any modifications, derivative works, enhancements, upgrades, updates or improvements of the Software or Documentation, or to fix any bug that could arise.
+Licensee at all times uses the Software at its own cost, risk and responsibility. InterDigital shall not be liable for any damages that could accrue by or to Licensee as a result of its use of the Software, either in accordance with this License or not.
+InterDigital shall not be liable for any consequential or indirect losses, including any indirect loss of profits, revenues, business, and/or anticipated savings, whether or not in the contemplation of the Parties at the time of entering into this License unless expressly set out in this License, or arising from gross negligence, willful misconduct or fraud.
+Licensee agrees that it will defend, indemnify and hold harmless InterDigital and its Affiliates against any and all losses, damages, costs and expenses arising from a breach by the Licensee of any of its obligations or representations hereunder, including, without limitation, any third party claims, and/or any claims in connection with any such breach and/or any use of the Software, including any claim from third party arising from access, use, or any other activity in relation to this Software.
+Licensee shall not make any warranty, representation, or commitment on behalf of InterDigital to any other third party.
+
+# Article 7. Open Source Software
+Licensee hereby represents, warrants, and covenants to InterDigital that Licensee’s use of the Software shall not result in the Contamination of all or any part of the Software, directly or indirectly, or of any Intellectual Property of InterDigital or its Affiliates.
+As used herein, “Contamination” shall mean that the licensing terms under which any Open Source Software, distinct from the Software, is released would also apply to the Software herein, by virtue of such Open Source Software being linked to, combined with, or otherwise connected to the Software.
+Licensee agree that some Open Source Software are included in the distribution. A list of such is provided in exhibit A with the relevant licenses applicable. For the avoidance of doubt, regarding such open source parts, the relevant license will apply exclusively.
+
+# Article 8. No Future Contract Obligation
+Neither this License nor the furnishing of the Software, nor any other InterDigital information provided to Licensee, shall be construed to obligate either party to: (a) enter into any further agreement or negotiation concerning the deployment of the Software; (b) refrain from entering into any agreement or negotiation with any other third party regarding the same or any other subject matter; or (c) refrain from pursuing its business in whatever manner it elects even if this involves competing with the other party.
+
+# Article 9. General Provisions
+9.1 Severability. If any provision of this License shall be held to be in contravention of applicable law, this License shall be construed as if such provision were not a part thereof, and in all other respects the terms hereof shall remain in full force and effect.
+9.2 Governing Law. Regardless of the place of execution, delivery, performance or any other aspect of this License, this License and all of the rights of the parties under this License shall be governed by, construed under and enforced in accordance with the substantive law of the State of Delaware, USA, without regard to conflicts of law principles. In case of a dispute that cannot be settled amicably, the state and federal courts located in New Castle County, Delaware, USA, shall have exclusive jurisdiction over such dispute, and each party hereby irrevocably waives any objection to the jurisdiction of such courts, including but not limited to objections of lack of in personam jurisdiction or based on principles of forum non conveniens.
+9.3 Survival. The provisions of articles 1, 3, 4, 6, 7, 8, 9.1, 9.2 and 9.5 shall survive termination of this License.
+9.4 Assignment. InterDigital may assign this license to any third Party. Licensee may not assign this agreement to any third party without InterDigital’s prior written approval.
+9.5 Entire Agreement. This License constitutes the entire agreement between the parties hereto with respect to the subject matter hereof and supersedes any prior agreements or understanding.
+
diff --git a/models/FeatureStyleEncoder/README.md b/models/FeatureStyleEncoder/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..625d4cd00adc82e19cebebe0faf093a064e0018d
--- /dev/null
+++ b/models/FeatureStyleEncoder/README.md
@@ -0,0 +1,92 @@
+## A Style-Based GAN Encoder for High Fidelity Reconstruction of Images and Videos
+
+Official implementation for paper: A Style-Based GAN Encoder for High Fidelity Reconstruction of Images and Videos.
+
+[[Video Editing Results]](https://drive.google.com/file/d/1ebih6TZxb2eLKxJdbO8GnsInDKSegfYL/view?usp=sharing)
+
+
+
+> **Abstract** We propose a novel architecture for GAN inversion, which we call Feature-Style encoder. The style encoder is key for the manipulation of the obtained latent codes, while the feature encoder is crucial for optimal image reconstruction. Our model achieves accurate inversion of real images from the latent space of a pre-trained style-based GAN model, obtaining better perceptual quality and lower reconstruction error than existing methods. Thanks to its encoder structure, the model allows fast and accurate image editing. Additionally, we demonstrate that the proposed encoder is especially well-suited for inversion and editing on videos. We conduct extensive experiments for several style-based generators pre-trained on different data domains. Our proposed method yields state-of-the-art results for style-based GAN inversion, significantly outperforming competing approaches.
+
+
+## Requirements
+
+### Dependencies
+
+- Python 3.6
+- PyTorch 1.8
+- Opencv
+
+You can install a new environment for this repo by running
+```
+conda env create -f environment.yml
+conda activate feature_style
+```
+
+### Prepare StyleGAN2 model and other necessary models
+
+* We adapt the StyleGAN2 model implemented by paper [Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation](https://arxiv.org/pdf/2008.00951.pdf). Here is their [official implementation](https://github.com/eladrich/pixel2style2pixel.git).
+
+* Download and save the pretrained models running
+ ```
+ sh download_models.sh
+ ```
+
+
+## Training
+
+* Prepare the training data
+
+ To train the encoder for StyleGAN, we use the synthetic images generated by StyleGAN and also the real images [ffhq dataset](https://github.com/NVlabs/ffhq-dataset).
+ You can generate the synthetic images by running
+ ```
+ python generate_imgs.py
+ ```
+ and download the ffhq dataset (aligned faces) to `data/ffhq-dataset/images/`.
+
+* Training
+
+ You can modify the training options of the config file in the directory `configs/`.
+ ```
+ python train.py --config 001
+ ```
+
+## Testing
+
+* Inversion
+
+ You can test the encoder on the images in `test/`. The output images are saved in `output/image/`.
+ ```
+ python test.py --pretrained_model_path './pretrained_models/143_enc.pth' --input_path './test/'
+ ```
+* Inversion and editing in notebook
+
+ You can explore the encoder and the attribute editing code in notebook `inference.ipynb`. You can also open it in Google Colab [here](https://colab.research.google.com/github/InterDigitalInc/FeatureStyleEncoder/blob/master/inference.ipynb).
+
+
+## Video Manipulation
+
+We provide a script to achieve inversion and attribute manipulation for the videos in the test directory `data/video/`. You can upload your own video and modify the options in `run_video_inversion_editing.sh`.
+
+```
+sh run_video_inversion_editing.sh
+```
+
+## Citation
+```
+@article{xuyao2022,
+ title={A Style-Based GAN Encoder for High Fidelity Reconstruction of Images and Videos},
+ author={Yao, Xu and Newson, Alasdair and Gousseau, Yann and Hellier, Pierre},
+ journal={European conference on computer vision},
+ year={2022}
+}
+```
+## License
+
+Copyright © 2022, InterDigital R&D France. All rights reserved.
+
+This source code is made available under the license found in the LICENSE.txt in the root directory of this source tree.
+
+
+
+
diff --git a/models/FeatureStyleEncoder/arcface/__init__.py b/models/FeatureStyleEncoder/arcface/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a0bcbf8ecdb946bb6f72e93922006fd6b48dba2
--- /dev/null
+++ b/models/FeatureStyleEncoder/arcface/__init__.py
@@ -0,0 +1 @@
+from .iresnet import iresnet18, iresnet34, iresnet50, iresnet100, iresnet200
diff --git a/models/FeatureStyleEncoder/arcface/iresnet.py b/models/FeatureStyleEncoder/arcface/iresnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..96ec43e32d5fc11871d0b85e34134c7fc6335577
--- /dev/null
+++ b/models/FeatureStyleEncoder/arcface/iresnet.py
@@ -0,0 +1,195 @@
+import torch
+from torch import nn
+
+__all__ = ['iresnet18', 'iresnet34', 'iresnet50', 'iresnet100', 'iresnet200']
+
+
+def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=stride,
+ padding=dilation,
+ groups=groups,
+ bias=False,
+ dilation=dilation)
+
+
+def conv1x1(in_planes, out_planes, stride=1):
+ """1x1 convolution"""
+ return nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size=1,
+ stride=stride,
+ bias=False)
+
+
+class IBasicBlock(nn.Module):
+ expansion = 1
+ def __init__(self, inplanes, planes, stride=1, downsample=None,
+ groups=1, base_width=64, dilation=1):
+ super(IBasicBlock, self).__init__()
+ if groups != 1 or base_width != 64:
+ raise ValueError('BasicBlock only supports groups=1 and base_width=64')
+ if dilation > 1:
+ raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
+ self.bn1 = nn.BatchNorm2d(inplanes, eps=1e-05,)
+ self.conv1 = conv3x3(inplanes, planes)
+ self.bn2 = nn.BatchNorm2d(planes, eps=1e-05,)
+ self.prelu = nn.PReLU(planes)
+ self.conv2 = conv3x3(planes, planes, stride)
+ self.bn3 = nn.BatchNorm2d(planes, eps=1e-05,)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ identity = x
+ out = self.bn1(x)
+ out = self.conv1(out)
+ out = self.bn2(out)
+ out = self.prelu(out)
+ out = self.conv2(out)
+ out = self.bn3(out)
+ if self.downsample is not None:
+ identity = self.downsample(x)
+ out += identity
+ return out
+
+
+class IResNet(nn.Module):
+ fc_scale = 7 * 7
+ def __init__(self,
+ block, layers, dropout=0, num_features=512, zero_init_residual=False,
+ groups=1, width_per_group=64, replace_stride_with_dilation=None, fp16=False):
+ super(IResNet, self).__init__()
+ self.fp16 = fp16
+ self.inplanes = 64
+ self.dilation = 1
+ if replace_stride_with_dilation is None:
+ replace_stride_with_dilation = [False, False, False]
+ if len(replace_stride_with_dilation) != 3:
+ raise ValueError("replace_stride_with_dilation should be None "
+ "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
+ self.groups = groups
+ self.base_width = width_per_group
+ self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(self.inplanes, eps=1e-05)
+ self.prelu = nn.PReLU(self.inplanes)
+ self.layer1 = self._make_layer(block, 64, layers[0], stride=2)
+ self.layer2 = self._make_layer(block,
+ 128,
+ layers[1],
+ stride=2,
+ dilate=replace_stride_with_dilation[0])
+ self.layer3 = self._make_layer(block,
+ 256,
+ layers[2],
+ stride=2,
+ dilate=replace_stride_with_dilation[1])
+ self.layer4 = self._make_layer(block,
+ 512,
+ layers[3],
+ stride=2,
+ dilate=replace_stride_with_dilation[2])
+ self.bn2 = nn.BatchNorm2d(512 * block.expansion, eps=1e-05,)
+ self.dropout = nn.Dropout(p=dropout, inplace=True)
+ self.fc = nn.Linear(512 * block.expansion * self.fc_scale, num_features)
+ self.features = nn.BatchNorm1d(num_features, eps=1e-05)
+ nn.init.constant_(self.features.weight, 1.0)
+ self.features.weight.requires_grad = False
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.normal_(m.weight, 0, 0.1)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+ if zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, IBasicBlock):
+ nn.init.constant_(m.bn2.weight, 0)
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
+ downsample = None
+ previous_dilation = self.dilation
+ if dilate:
+ self.dilation *= stride
+ stride = 1
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ conv1x1(self.inplanes, planes * block.expansion, stride),
+ nn.BatchNorm2d(planes * block.expansion, eps=1e-05, ),
+ )
+ layers = []
+ layers.append(
+ block(self.inplanes, planes, stride, downsample, self.groups,
+ self.base_width, previous_dilation))
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(
+ block(self.inplanes,
+ planes,
+ groups=self.groups,
+ base_width=self.base_width,
+ dilation=self.dilation))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x, return_features=False):
+ out = []
+ with torch.cuda.amp.autocast(self.fp16):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.prelu(x)
+ x = self.layer1(x)
+ out.append(x)
+ x = self.layer2(x)
+ out.append(x)
+ x = self.layer3(x)
+ out.append(x)
+ x = self.layer4(x)
+ out.append(x)
+ x = self.bn2(x)
+ x = torch.flatten(x, 1)
+ x = self.dropout(x)
+ x = self.fc(x.float() if self.fp16 else x)
+ x = self.features(x)
+
+ if return_features:
+ out.append(x)
+ return out
+ return x
+
+
+def _iresnet(arch, block, layers, pretrained, progress, **kwargs):
+ model = IResNet(block, layers, **kwargs)
+ if pretrained:
+ raise ValueError()
+ return model
+
+
+def iresnet18(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet18', IBasicBlock, [2, 2, 2, 2], pretrained,
+ progress, **kwargs)
+
+
+def iresnet34(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet34', IBasicBlock, [3, 4, 6, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet50(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet50', IBasicBlock, [3, 4, 14, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet100(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet100', IBasicBlock, [3, 13, 30, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet200(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet200', IBasicBlock, [6, 26, 60, 6], pretrained,
+ progress, **kwargs)
diff --git a/models/FeatureStyleEncoder/configs/001.yaml b/models/FeatureStyleEncoder/configs/001.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..6292278ccf34bafcdb2efd437fe31b161c5a0916
--- /dev/null
+++ b/models/FeatureStyleEncoder/configs/001.yaml
@@ -0,0 +1,49 @@
+# Input data
+resolution: 1024
+age_min: 20
+age_max: 70
+use_realimg: True
+# Training hyperparameters
+batch_size: 1
+epochs: 12
+iter_per_epoch: 10000
+device: 'cuda'
+# Optimizer parameters
+optimizer: 'ranger'
+lr: 0.0001
+beta_1: 0.95
+beta_2: 0.999
+weight_decay: 0
+# Learning rate scheduler
+step_size: 10
+gamma: 0.1
+# Tensorboard log options
+image_save_iter: 100
+log_iter: 10
+# Network setting
+use_fs_encoder: True
+use_fs_encoder_v2: True
+fs_stride: 2
+pretrained_weight_for_fs: False
+enc_resolution: 256
+enc_residual: False
+truncation_psi: 1
+use_noise: True
+randomize_noise: False # If generator use a different random noise at each time of generating a image from z
+# Loss setting
+use_parsing_net: True
+multi_layer_idloss: True
+real_image_as_image_loss: False
+feature_match_loss: False
+feature_match_loss_G: False
+use_random_noise: True
+optimize_on_z: False
+multiscale_lpips: True
+# Loss weight
+w:
+ l1: 0
+ l2: 1
+ lpips: 0.2
+ id: 0.1
+ landmark: 0.1
+ f_recon: 0.01
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/download_models.sh b/models/FeatureStyleEncoder/download_models.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a554f924dcdda5a372d14187431f9655331a7e74
--- /dev/null
+++ b/models/FeatureStyleEncoder/download_models.sh
@@ -0,0 +1,22 @@
+#!/bin/sh
+pip install gdown
+mkdir pretrained_models
+cd pretrained_models
+
+# download pretrained encoder
+gdown --fuzzy https://drive.google.com/file/d/1RnnBL77j_Can0dY1KOiXHvG224MxjvzC/view?usp=sharing
+
+# download ArcFace pretrained model
+gdown --fuzzy https://drive.google.com/file/d/1coFTz-Kkgvoc_gRT8JFzqCgeC3lAFWQp/view?usp=sharing
+
+# download face parsing model from https://github.com/zllrunning/face-parsing.PyTorch
+gdown --fuzzy https://drive.google.com/open?id=154JgKpzCPW82qINcVieuPH3fZ2e0P812
+
+# download pSp pretrained model from https://github.com/eladrich/pixel2style2pixel.git
+cd ../pixel2style2pixel
+mkdir pretrained_models
+cd pretrained_models
+gdown --fuzzy https://drive.google.com/file/d/1bMTNWkh5LArlaWSc_wa8VKyq2V42T2z0/view?usp=sharing
+cd ..
+cd ..
+
diff --git a/models/FeatureStyleEncoder/environment.yml b/models/FeatureStyleEncoder/environment.yml
new file mode 100644
index 0000000000000000000000000000000000000000..08e5b22047207f73625a58bbf9ce881c43fa7712
--- /dev/null
+++ b/models/FeatureStyleEncoder/environment.yml
@@ -0,0 +1,159 @@
+name: feature_style
+channels:
+ - pytorch
+ - 1adrianb
+ - conda-forge
+ - defaults
+dependencies:
+ - _libgcc_mutex=0.1
+ - argon2-cffi=20.1.0
+ - async_generator=1.10
+ - attrs=20.3.0
+ - backcall=0.2.0
+ - blas=1.0
+ - bleach=3.3.0
+ - bzip2=1.0.8
+ - ca-certificates=2021.10.8
+ - certifi=2021.5.30
+ - cffi=1.14.5
+ - cloudpickle=1.6.0
+ - cudatoolkit=10.2.89
+ - cycler=0.10.0
+ - cytoolz=0.11.0
+ - dask-core=1.1.4
+ - dataclasses=0.8
+ - decorator=5.0.6
+ - defusedxml=0.7.1
+ - entrypoints=0.3
+ - face_alignment=1.3.4
+ - ffmpeg=4.3
+ - freetype=2.10.4
+ - gmp=6.2.1
+ - gnutls=3.6.15
+ - hdf5=1.10.2
+ - imageio=2.9.0
+ - importlib-metadata=3.10.0
+ - importlib_metadata=3.10.0
+ - intel-openmp=2020.2
+ - ipykernel=5.3.4
+ - ipython=7.16.1
+ - ipython_genutils=0.2.0
+ - ipywidgets=7.6.3
+ - jedi=0.17.0
+ - jinja2=2.11.3
+ - jpeg=9b
+ - jsonschema=3.2.0
+ - jupyter_client=6.1.12
+ - jupyter_core=4.7.1
+ - jupyterlab_pygments=0.1.2
+ - jupyterlab_widgets=1.0.0
+ - kiwisolver=1.3.1
+ - lame=3.100
+ - lcms2=2.12
+ - ld_impl_linux-64=2.33.1
+ - libffi=3.3
+ - libgcc-ng=9.1.0
+ - libgfortran=3.0.0
+ - libgfortran-ng=7.3.0
+ - libiconv=1.15
+ - libidn2=2.3.0
+ - libllvm10=10.0.1
+ - libpng=1.6.37
+ - libsodium=1.0.18
+ - libstdcxx-ng=9.1.0
+ - libtasn1=4.16.0
+ - libtiff=4.1.0
+ - libunistring=0.9.10
+ - libuv=1.40.0
+ - llvmlite=0.36.0
+ - lz4-c=1.9.3
+ - markupsafe=1.1.1
+ - matplotlib-base=3.3.4
+ - mistune=0.8.4
+ - mkl=2020.2
+ - mkl-service=2.3.0
+ - mkl_fft=1.3.0
+ - mkl_random=1.1.1
+ - nbclient=0.5.3
+ - nbconvert=6.0.7
+ - nbformat=5.1.3
+ - ncurses=6.2
+ - nest-asyncio=1.5.1
+ - nettle=3.7.2
+ - networkx=2.2
+ - notebook=6.3.0
+ - numba=0.53.1
+ - numpy=1.19.2
+ - numpy-base=1.19.2
+ - olefile=0.46
+ - opencv=3.4.1
+ - openh264=2.1.0
+ - openssl=1.1.1l
+ - packaging=20.9
+ - pandoc=2.12
+ - pandocfilters=1.4.3
+ - parso=0.8.2
+ - pexpect=4.8.0
+ - pickleshare=0.7.5
+ - pillow=8.2.0
+ - pip=21.0.1
+ - prometheus_client=0.10.1
+ - prompt-toolkit=3.0.17
+ - ptyprocess=0.7.0
+ - pycparser=2.20
+ - pygments=2.8.1
+ - pyparsing=2.4.7
+ - pyrsistent=0.17.3
+ - python=3.6.13
+ - python-dateutil=2.8.1
+ - python_abi=3.6
+ - pytorch=1.8.1
+ - pywavelets=1.1.1
+ - pyzmq=20.0.0
+ - readline=8.1
+ - scikit-image=0.17.2
+ - scipy=1.5.2
+ - send2trash=1.5.0
+ - setuptools=52.0.0
+ - six=1.15.0
+ - sqlite=3.35.4
+ - tbb=2020.3
+ - terminado=0.9.4
+ - testpath=0.4.4
+ - tifffile=2020.10.1
+ - tk=8.6.10
+ - toolz=0.11.1
+ - torchvision=0.9.1
+ - tornado=6.1
+ - tqdm=4.59.0
+ - traitlets=4.3.3
+ - typing_extensions=3.7.4.3
+ - wcwidth=0.2.5
+ - webencodings=0.5.1
+ - wheel=0.36.2
+ - widgetsnbextension=3.5.1
+ - xz=5.2.5
+ - yaml=0.2.5
+ - zeromq=4.3.4
+ - zipp=3.4.1
+ - zlib=1.2.11
+ - zstd=1.4.9
+ - pip:
+ - charset-normalizer==2.0.7
+ - click==8.0.3
+ - cython==0.29.23
+ - dlib==19.22.1
+ - idna==3.2
+ - joblib==1.1.0
+ - ninja==1.10.2.2
+ - onnxruntime==1.7.0
+ - opencv-python==4.5.1.48
+ - protobuf==3.15.8
+ - pytorch-msssim==0.2.1
+ - pyyaml==5.4.1
+ - requests==2.26.0
+ - scikit-learn==0.22
+ - sklearn==0.0
+ - tensorboard-logger==0.1.0
+ - threadpoolctl==3.0.0
+ - urllib3==1.26.7
diff --git a/models/FeatureStyleEncoder/face_parsing/model.py b/models/FeatureStyleEncoder/face_parsing/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f649917a85676ec3ef36fa1e262ddcfaaca12e20
--- /dev/null
+++ b/models/FeatureStyleEncoder/face_parsing/model.py
@@ -0,0 +1,292 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision
+
+import sys
+sys.path.append('..')
+from face_parsing.resnet import Resnet18
+# from modules.bn import InPlaceABNSync as BatchNorm2d
+
+
+class ConvBNReLU(nn.Module):
+ def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
+ super(ConvBNReLU, self).__init__()
+ self.conv = nn.Conv2d(in_chan,
+ out_chan,
+ kernel_size = ks,
+ stride = stride,
+ padding = padding,
+ bias = False)
+ self.bn = nn.BatchNorm2d(out_chan)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = F.relu(self.bn(x))
+ return x
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+class BiSeNetOutput(nn.Module):
+ def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
+ super(BiSeNetOutput, self).__init__()
+ self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
+ self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.conv_out(x)
+ return x
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class AttentionRefinementModule(nn.Module):
+ def __init__(self, in_chan, out_chan, *args, **kwargs):
+ super(AttentionRefinementModule, self).__init__()
+ self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
+ self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
+ self.bn_atten = nn.BatchNorm2d(out_chan)
+ self.sigmoid_atten = nn.Sigmoid()
+ self.init_weight()
+
+ def forward(self, x):
+ feat = self.conv(x)
+ atten = F.avg_pool2d(feat, feat.size()[2:])
+ atten = self.conv_atten(atten)
+ atten = self.bn_atten(atten)
+ atten = self.sigmoid_atten(atten)
+ out = torch.mul(feat, atten)
+ return out
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+
+class ContextPath(nn.Module):
+ def __init__(self, *args, **kwargs):
+ super(ContextPath, self).__init__()
+ self.resnet = Resnet18()
+ self.arm16 = AttentionRefinementModule(256, 128)
+ self.arm32 = AttentionRefinementModule(512, 128)
+ self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
+ self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
+ self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
+
+ self.init_weight()
+
+ def forward(self, x):
+ H0, W0 = x.size()[2:]
+ feat8, feat16, feat32 = self.resnet(x)
+ H8, W8 = feat8.size()[2:]
+ H16, W16 = feat16.size()[2:]
+ H32, W32 = feat32.size()[2:]
+
+ avg = F.avg_pool2d(feat32, feat32.size()[2:])
+ avg = self.conv_avg(avg)
+ avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
+
+ feat32_arm = self.arm32(feat32)
+ feat32_sum = feat32_arm + avg_up
+ feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
+ feat32_up = self.conv_head32(feat32_up)
+
+ feat16_arm = self.arm16(feat16)
+ feat16_sum = feat16_arm + feat32_up
+ feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
+ feat16_up = self.conv_head16(feat16_up)
+
+ return feat8, feat16_up, feat32_up # x8, x8, x16
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+### This is not used, since I replace this with the resnet feature with the same size
+class SpatialPath(nn.Module):
+ def __init__(self, *args, **kwargs):
+ super(SpatialPath, self).__init__()
+ self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
+ self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
+ self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
+ self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
+ self.init_weight()
+
+ def forward(self, x):
+ feat = self.conv1(x)
+ feat = self.conv2(feat)
+ feat = self.conv3(feat)
+ feat = self.conv_out(feat)
+ return feat
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class FeatureFusionModule(nn.Module):
+ def __init__(self, in_chan, out_chan, *args, **kwargs):
+ super(FeatureFusionModule, self).__init__()
+ self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
+ self.conv1 = nn.Conv2d(out_chan,
+ out_chan//4,
+ kernel_size = 1,
+ stride = 1,
+ padding = 0,
+ bias = False)
+ self.conv2 = nn.Conv2d(out_chan//4,
+ out_chan,
+ kernel_size = 1,
+ stride = 1,
+ padding = 0,
+ bias = False)
+ self.relu = nn.ReLU(inplace=True)
+ self.sigmoid = nn.Sigmoid()
+ self.init_weight()
+
+ def forward(self, fsp, fcp):
+ fcat = torch.cat([fsp, fcp], dim=1)
+ feat = self.convblk(fcat)
+ atten = F.avg_pool2d(feat, feat.size()[2:])
+ atten = self.conv1(atten)
+ atten = self.relu(atten)
+ atten = self.conv2(atten)
+ atten = self.sigmoid(atten)
+ feat_atten = torch.mul(feat, atten)
+ feat_out = feat_atten + feat
+ return feat_out
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+class BiSeNet(nn.Module):
+ def __init__(self, n_classes, *args, **kwargs):
+ super(BiSeNet, self).__init__()
+ self.cp = ContextPath()
+ ## here self.sp is deleted
+ self.ffm = FeatureFusionModule(256, 256)
+ self.conv_out = BiSeNetOutput(256, 256, n_classes)
+ self.conv_out16 = BiSeNetOutput(128, 64, n_classes)
+ self.conv_out32 = BiSeNetOutput(128, 64, n_classes)
+ self.init_weight()
+
+ def forward(self, x):
+ H, W = x.size()[2:]
+ feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
+ feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
+ feat_fuse = self.ffm(feat_sp, feat_cp8)
+
+ feat_out = self.conv_out(feat_fuse)
+ feat_out16 = self.conv_out16(feat_cp8)
+ feat_out32 = self.conv_out32(feat_cp16)
+
+ feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
+ feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
+ feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
+ return feat_out, feat_out16, feat_out32
+
+ def extract_fuse_layer(self, x):
+ H, W = x.size()[2:]
+ feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
+ feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
+ feat_fuse = self.ffm(feat_sp, feat_cp8)
+ return [feat_fuse]
+
+ def init_weight(self):
+ for ly in self.children():
+ if isinstance(ly, nn.Conv2d):
+ nn.init.kaiming_normal_(ly.weight, a=1)
+ if not ly.bias is None: nn.init.constant_(ly.bias, 0)
+
+ def get_params(self):
+ wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
+ for name, child in self.named_children():
+ child_wd_params, child_nowd_params = child.get_params()
+ if isinstance(child, FeatureFusionModule) or isinstance(child, BiSeNetOutput):
+ lr_mul_wd_params += child_wd_params
+ lr_mul_nowd_params += child_nowd_params
+ else:
+ wd_params += child_wd_params
+ nowd_params += child_nowd_params
+ return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
+
+
+if __name__ == "__main__":
+ net = BiSeNet(19)
+ net.cuda()
+ net.eval()
+ in_ten = torch.randn(16, 3, 640, 480).cuda()
+ out, out16, out32 = net(in_ten)
+ print(out.shape)
+
+ net.get_params()
diff --git a/models/FeatureStyleEncoder/face_parsing/resnet.py b/models/FeatureStyleEncoder/face_parsing/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa4c308aa46c5d592844cb626d9544a769455b0
--- /dev/null
+++ b/models/FeatureStyleEncoder/face_parsing/resnet.py
@@ -0,0 +1,112 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.model_zoo as modelzoo
+
+import os
+
+
+# from modules.bn import InPlaceABNSync as BatchNorm2d
+
+resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
+
+
+def conv3x3(in_planes, out_planes, stride=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=1, bias=False)
+
+
+class BasicBlock(nn.Module):
+ def __init__(self, in_chan, out_chan, stride=1):
+ super(BasicBlock, self).__init__()
+ self.conv1 = conv3x3(in_chan, out_chan, stride)
+ self.bn1 = nn.BatchNorm2d(out_chan)
+ self.conv2 = conv3x3(out_chan, out_chan)
+ self.bn2 = nn.BatchNorm2d(out_chan)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = None
+ if in_chan != out_chan or stride != 1:
+ self.downsample = nn.Sequential(
+ nn.Conv2d(in_chan, out_chan,
+ kernel_size=1, stride=stride, bias=False),
+ nn.BatchNorm2d(out_chan),
+ )
+
+ def forward(self, x):
+ residual = self.conv1(x)
+ residual = F.relu(self.bn1(residual))
+ residual = self.conv2(residual)
+ residual = self.bn2(residual)
+
+ shortcut = x
+ if self.downsample is not None:
+ shortcut = self.downsample(x)
+
+ out = shortcut + residual
+ out = self.relu(out)
+ return out
+
+
+def create_layer_basic(in_chan, out_chan, bnum, stride=1):
+ layers = [BasicBlock(in_chan, out_chan, stride=stride)]
+ for i in range(bnum-1):
+ layers.append(BasicBlock(out_chan, out_chan, stride=1))
+ return nn.Sequential(*layers)
+
+
+class Resnet18(nn.Module):
+ def __init__(self):
+ super(Resnet18, self).__init__()
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
+ bias=False)
+ self.bn1 = nn.BatchNorm2d(64)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
+ self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
+ self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
+ self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
+ self.init_weight()
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = F.relu(self.bn1(x))
+ x = self.maxpool(x)
+
+ x = self.layer1(x)
+ feat8 = self.layer2(x) # 1/8
+ feat16 = self.layer3(feat8) # 1/16
+ feat32 = self.layer4(feat16) # 1/32
+ return feat8, feat16, feat32
+
+ def init_weight(self):
+ state_dict = modelzoo.load_url(resnet18_url)
+ self_state_dict = self.state_dict()
+ for k, v in state_dict.items():
+ if 'fc' in k: continue
+ self_state_dict.update({k: v})
+ self.load_state_dict(self_state_dict)
+
+ def get_params(self):
+ wd_params, nowd_params = [], []
+ for name, module in self.named_modules():
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ wd_params.append(module.weight)
+ if not module.bias is None:
+ nowd_params.append(module.bias)
+ elif isinstance(module, nn.BatchNorm2d):
+ nowd_params += list(module.parameters())
+ return wd_params, nowd_params
+
+
+if __name__ == "__main__":
+ net = Resnet18()
+ x = torch.randn(16, 3, 224, 224)
+ out = net(x)
+ print(out[0].size())
+ print(out[1].size())
+ print(out[2].size())
+ net.get_params()
diff --git a/models/FeatureStyleEncoder/face_parsing/test.py b/models/FeatureStyleEncoder/face_parsing/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad94fe9b62f724b2d3957984840699b317657c44
--- /dev/null
+++ b/models/FeatureStyleEncoder/face_parsing/test.py
@@ -0,0 +1,87 @@
+#!/usr/bin/python
+# -*- encoding: utf-8 -*-
+
+from model import BiSeNet
+
+import torch
+
+import os
+import os.path as osp
+import numpy as np
+from PIL import Image
+import torchvision.transforms as transforms
+import cv2
+
+def vis_parsing_maps(im, parsing_anno, stride, save_im=False, save_path='vis_results/parsing_map_on_im.jpg'):
+ # Colors for all 20 parts
+ part_colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0],
+ [255, 0, 85], [255, 0, 170],
+ [0, 255, 0], [85, 255, 0], [170, 255, 0],
+ [0, 255, 85], [0, 255, 170],
+ [0, 0, 255], [85, 0, 255], [170, 0, 255],
+ [0, 85, 255], [0, 170, 255],
+ [255, 255, 0], [255, 255, 85], [255, 255, 170],
+ [255, 0, 255], [255, 85, 255], [255, 170, 255],
+ [0, 255, 255], [85, 255, 255], [170, 255, 255]]
+
+ im = np.array(im)
+ vis_im = im.copy().astype(np.uint8)
+ vis_parsing_anno = parsing_anno.copy().astype(np.uint8)
+ vis_parsing_anno = cv2.resize(vis_parsing_anno, None, fx=stride, fy=stride, interpolation=cv2.INTER_NEAREST)
+ vis_parsing_anno_color = np.zeros((vis_parsing_anno.shape[0], vis_parsing_anno.shape[1], 3)) + 255
+
+ num_of_class = np.max(vis_parsing_anno)
+
+ for pi in range(1, num_of_class + 1):
+ index = np.where(vis_parsing_anno == pi)
+ vis_parsing_anno_color[index[0], index[1], :] = part_colors[pi]
+
+ vis_parsing_anno_color = vis_parsing_anno_color.astype(np.uint8)
+ # print(vis_parsing_anno_color.shape, vis_im.shape)
+ vis_im = cv2.addWeighted(cv2.cvtColor(vis_im, cv2.COLOR_RGB2BGR), 0.4, vis_parsing_anno_color, 0.6, 0)
+
+ # Save result or not
+ if save_im:
+ cv2.imwrite(save_path[:-4] +'.png', vis_parsing_anno)
+ cv2.imwrite(save_path, vis_im, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
+
+ # return vis_im
+
+def evaluate(respth='./res/test_res', dspth='./data', cp='model_final_diss.pth'):
+
+ if not os.path.exists(respth):
+ os.makedirs(respth)
+
+ n_classes = 19
+ net = BiSeNet(n_classes=n_classes)
+ net.cuda()
+ save_pth = osp.join('', cp)
+ net.load_state_dict(torch.load(save_pth))
+ net.eval()
+
+ to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
+ ])
+ with torch.no_grad():
+ for image_path in os.listdir(dspth):
+ img = Image.open(osp.join(dspth, image_path))
+ image = img.resize((512, 512), Image.BILINEAR)
+ img = to_tensor(image)
+ img = torch.unsqueeze(img, 0)
+ img = img.cuda()
+ out = net(img)
+ out = out[0]
+ parsing = out.squeeze(0).cpu().numpy().argmax(0)
+ # print(parsing)
+ print(np.unique(parsing))
+
+ vis_parsing_maps(image, parsing, stride=1, save_im=True, save_path=osp.join(respth, image_path))
+
+
+
+
+if __name__ == "__main__":
+ evaluate(dspth='../face-parsing/imgs/', cp='./pretrained_models/79999_iter.pth')
+
+
diff --git a/models/FeatureStyleEncoder/generate_imgs.py b/models/FeatureStyleEncoder/generate_imgs.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1e0975401a3ecaa4c536f1fbcdcb8bde031700e
--- /dev/null
+++ b/models/FeatureStyleEncoder/generate_imgs.py
@@ -0,0 +1,52 @@
+import argparse
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+import yaml
+
+from PIL import Image
+from torchvision import transforms, utils
+from tensorboard_logger import Logger
+from tqdm import tqdm
+from utils.functions import *
+
+import sys
+sys.path.append('pixel2style2pixel/')
+from pixel2style2pixel.models.stylegan2.model import Generator, get_keys
+
+torch.backends.cudnn.enabled = True
+torch.backends.cudnn.deterministic = True
+torch.backends.cudnn.benchmark = True
+torch.autograd.set_detect_anomaly(True)
+Image.MAX_IMAGE_PIXELS = None
+device = torch.device('cuda')
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--config', type=str, default='002', help='Path to the config file.')
+parser.add_argument('--dataset_path', type=str, default='./data/stylegan2-generate-images/', help='dataset path')
+parser.add_argument('--stylegan_model_path', type=str, default='./pixel2style2pixel/pretrained_models/psp_ffhq_encode.pt', help='pretrained stylegan model')
+opts = parser.parse_args()
+
+
+StyleGAN = Generator(1024, 512, 8)
+state_dict = torch.load(opts.stylegan_model_path, map_location='cpu')
+StyleGAN.load_state_dict(get_keys(state_dict, 'decoder'), strict=True)
+StyleGAN.to(device)
+
+#seeds = np.array([torch.random.seed() for i in range(100000)])
+seeds = np.load(opts.dataset_path + 'seeds_pytorch_1.8.1.npy')
+
+with torch.no_grad():
+ os.makedirs(opts.dataset_path + 'ims/', exist_ok=True)
+
+ for i, seed in enumerate(tqdm(seeds)):
+
+ torch.manual_seed(seed)
+ z = torch.randn(1, 512).to(device)
+ n = StyleGAN.make_noise()
+ w = StyleGAN.get_latent(z)
+ x, _ = StyleGAN([w], input_is_latent=True, noise=n)
+ utils.save_image(clip_img(x), opts.dataset_path + 'ims/%06d.jpg'%i)
diff --git a/models/FeatureStyleEncoder/lpips/__init__.py b/models/FeatureStyleEncoder/lpips/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..98a780ff8576cfe4d0486388bd0028a980c1aa81
--- /dev/null
+++ b/models/FeatureStyleEncoder/lpips/__init__.py
@@ -0,0 +1,178 @@
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import numpy as np
+import torch
+# from torch.autograd import Variable
+
+from lpips.trainer import *
+from lpips.lpips import *
+
+# class PerceptualLoss(torch.nn.Module):
+# def __init__(self, model='lpips', net='alex', spatial=False, use_gpu=False, gpu_ids=[0], version='0.1'): # VGG using our perceptually-learned weights (LPIPS metric)
+# # def __init__(self, model='net', net='vgg', use_gpu=True): # "default" way of using VGG as a perceptual loss
+# super(PerceptualLoss, self).__init__()
+# print('Setting up Perceptual loss...')
+# self.use_gpu = use_gpu
+# self.spatial = spatial
+# self.gpu_ids = gpu_ids
+# self.model = dist_model.DistModel()
+# self.model.initialize(model=model, net=net, use_gpu=use_gpu, spatial=self.spatial, gpu_ids=gpu_ids, version=version)
+# print('...[%s] initialized'%self.model.name())
+# print('...Done')
+
+# def forward(self, pred, target, normalize=False):
+# """
+# Pred and target are Variables.
+# If normalize is True, assumes the images are between [0,1] and then scales them between [-1,+1]
+# If normalize is False, assumes the images are already between [-1,+1]
+
+# Inputs pred and target are Nx3xHxW
+# Output pytorch Variable N long
+# """
+
+# if normalize:
+# target = 2 * target - 1
+# pred = 2 * pred - 1
+
+# return self.model.forward(target, pred)
+
+def normalize_tensor(in_feat,eps=1e-10):
+ norm_factor = torch.sqrt(torch.sum(in_feat**2+1e-8,dim=1,keepdim=True))
+ return in_feat/(norm_factor+eps)
+
+def l2(p0, p1, range=255.):
+ return .5*np.mean((p0 / range - p1 / range)**2)
+
+def psnr(p0, p1, peak=255.):
+ return 10*np.log10(peak**2/np.mean((1.*p0-1.*p1)**2))
+
+def dssim(p0, p1, range=255.):
+ from skimage.measure import compare_ssim
+ return (1 - compare_ssim(p0, p1, data_range=range, multichannel=True)) / 2.
+
+def rgb2lab(in_img,mean_cent=False):
+ from skimage import color
+ img_lab = color.rgb2lab(in_img)
+ if(mean_cent):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ return img_lab
+
+def tensor2np(tensor_obj):
+ # change dimension of a tensor object into a numpy array
+ return tensor_obj[0].cpu().float().numpy().transpose((1,2,0))
+
+def np2tensor(np_obj):
+ # change dimenion of np array into tensor array
+ return torch.Tensor(np_obj[:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
+
+def tensor2tensorlab(image_tensor,to_norm=True,mc_only=False):
+ # image tensor to lab tensor
+ from skimage import color
+
+ img = tensor2im(image_tensor)
+ img_lab = color.rgb2lab(img)
+ if(mc_only):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ if(to_norm and not mc_only):
+ img_lab[:,:,0] = img_lab[:,:,0]-50
+ img_lab = img_lab/100.
+
+ return np2tensor(img_lab)
+
+def tensorlab2tensor(lab_tensor,return_inbnd=False):
+ from skimage import color
+ import warnings
+ warnings.filterwarnings("ignore")
+
+ lab = tensor2np(lab_tensor)*100.
+ lab[:,:,0] = lab[:,:,0]+50
+
+ rgb_back = 255.*np.clip(color.lab2rgb(lab.astype('float')),0,1)
+ if(return_inbnd):
+ # convert back to lab, see if we match
+ lab_back = color.rgb2lab(rgb_back.astype('uint8'))
+ mask = 1.*np.isclose(lab_back,lab,atol=2.)
+ mask = np2tensor(np.prod(mask,axis=2)[:,:,np.newaxis])
+ return (im2tensor(rgb_back),mask)
+ else:
+ return im2tensor(rgb_back)
+
+def load_image(path):
+ if(path[-3:] == 'dng'):
+ import rawpy
+ with rawpy.imread(path) as raw:
+ img = raw.postprocess()
+ elif(path[-3:]=='bmp' or path[-3:]=='jpg' or path[-3:]=='png' or path[-4:]=='jpeg'):
+ import cv2
+ return cv2.imread(path)[:,:,::-1]
+ else:
+ img = (255*plt.imread(path)[:,:,:3]).astype('uint8')
+
+ return img
+
+def rgb2lab(input):
+ from skimage import color
+ return color.rgb2lab(input / 255.)
+
+def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
+ image_numpy = image_tensor[0].cpu().float().numpy()
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
+ return image_numpy.astype(imtype)
+
+def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
+ return torch.Tensor((image / factor - cent)
+ [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
+
+def tensor2vec(vector_tensor):
+ return vector_tensor.data.cpu().numpy()[:, :, 0, 0]
+
+
+def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=255./2.):
+# def tensor2im(image_tensor, imtype=np.uint8, cent=1., factor=1.):
+ image_numpy = image_tensor[0].cpu().float().numpy()
+ image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + cent) * factor
+ return image_numpy.astype(imtype)
+
+def im2tensor(image, imtype=np.uint8, cent=1., factor=255./2.):
+# def im2tensor(image, imtype=np.uint8, cent=1., factor=1.):
+ return torch.Tensor((image / factor - cent)
+ [:, :, :, np.newaxis].transpose((3, 2, 0, 1)))
+
+
+
+def voc_ap(rec, prec, use_07_metric=False):
+ """ ap = voc_ap(rec, prec, [use_07_metric])
+ Compute VOC AP given precision and recall.
+ If use_07_metric is true, uses the
+ VOC 07 11 point method (default:False).
+ """
+ if use_07_metric:
+ # 11 point metric
+ ap = 0.
+ for t in np.arange(0., 1.1, 0.1):
+ if np.sum(rec >= t) == 0:
+ p = 0
+ else:
+ p = np.max(prec[rec >= t])
+ ap = ap + p / 11.
+ else:
+ # correct AP calculation
+ # first append sentinel values at the end
+ mrec = np.concatenate(([0.], rec, [1.]))
+ mpre = np.concatenate(([0.], prec, [0.]))
+
+ # compute the precision envelope
+ for i in range(mpre.size - 1, 0, -1):
+ mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
+
+ # to calculate area under PR curve, look for points
+ # where X axis (recall) changes value
+ i = np.where(mrec[1:] != mrec[:-1])[0]
+
+ # and sum (\Delta recall) * prec
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
+ return ap
+
diff --git a/models/FeatureStyleEncoder/lpips/lpips.py b/models/FeatureStyleEncoder/lpips/lpips.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b979c082fdc45092e4669c52179339e16fa9d1f
--- /dev/null
+++ b/models/FeatureStyleEncoder/lpips/lpips.py
@@ -0,0 +1,219 @@
+
+from __future__ import absolute_import
+
+import torch
+import torch.nn as nn
+import torch.nn.init as init
+from torch.autograd import Variable
+import numpy as np
+from . import pretrained_networks as pn
+import torch.nn
+
+import lpips
+
+def spatial_average(in_tens, keepdim=True):
+ return in_tens.mean([2,3],keepdim=keepdim)
+
+def upsample(in_tens, out_HW=(64,64)): # assumes scale factor is same for H and W
+ in_H, in_W = in_tens.shape[2], in_tens.shape[3]
+ return nn.Upsample(size=out_HW, mode='bilinear', align_corners=False)(in_tens)
+
+# Learned perceptual metric
+class LPIPS(nn.Module):
+ def __init__(self, pretrained=True, net='alex', version='0.1', lpips=True, spatial=False,
+ pnet_rand=False, pnet_tune=False, use_dropout=True, model_path=None, eval_mode=True, verbose=True):
+ # lpips - [True] means with linear calibration on top of base network
+ # pretrained - [True] means load linear weights
+
+ super(LPIPS, self).__init__()
+ if(verbose):
+ print('Setting up [%s] perceptual loss: trunk [%s], v[%s], spatial [%s]'%
+ ('LPIPS' if lpips else 'baseline', net, version, 'on' if spatial else 'off'))
+
+ self.pnet_type = net
+ self.pnet_tune = pnet_tune
+ self.pnet_rand = pnet_rand
+ self.spatial = spatial
+ self.lpips = lpips # false means baseline of just averaging all layers
+ self.version = version
+ self.scaling_layer = ScalingLayer()
+
+ if(self.pnet_type in ['vgg','vgg16']):
+ net_type = pn.vgg16
+ self.chns = [64,128,256,512,512]
+ elif(self.pnet_type=='alex'):
+ net_type = pn.alexnet
+ self.chns = [64,192,384,256,256]
+ elif(self.pnet_type=='squeeze'):
+ net_type = pn.squeezenet
+ self.chns = [64,128,256,384,384,512,512]
+ self.L = len(self.chns)
+
+ self.net = net_type(pretrained=not self.pnet_rand, requires_grad=self.pnet_tune)
+
+ if(lpips):
+ self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
+ self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
+ self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
+ self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
+ self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
+ self.lins = [self.lin0,self.lin1,self.lin2,self.lin3,self.lin4]
+ if(self.pnet_type=='squeeze'): # 7 layers for squeezenet
+ self.lin5 = NetLinLayer(self.chns[5], use_dropout=use_dropout)
+ self.lin6 = NetLinLayer(self.chns[6], use_dropout=use_dropout)
+ self.lins+=[self.lin5,self.lin6]
+ self.lins = nn.ModuleList(self.lins)
+
+ if(pretrained):
+ if(model_path is None):
+ import inspect
+ import os
+ model_path = os.path.abspath(os.path.join(inspect.getfile(self.__init__), '..', 'weights/v%s/%s.pth'%(version,net)))
+
+ if(verbose):
+ print('Loading model from: %s'%model_path)
+ self.load_state_dict(torch.load(model_path, map_location='cpu'), strict=False)
+
+ if(eval_mode):
+ self.eval()
+
+ def forward(self, in0, in1, retPerLayer=False, normalize=False):
+ if normalize: # turn on this flag if input is [0,1] so it can be adjusted to [-1, +1]
+ in0 = 2 * in0 - 1
+ in1 = 2 * in1 - 1
+
+ # v0.0 - original release had a bug, where input was not scaled
+ in0_input, in1_input = (self.scaling_layer(in0), self.scaling_layer(in1)) if self.version=='0.1' else (in0, in1)
+ outs0, outs1 = self.net.forward(in0_input), self.net.forward(in1_input)
+ feats0, feats1, diffs = {}, {}, {}
+
+ for kk in range(self.L):
+ feats0[kk], feats1[kk] = lpips.normalize_tensor(outs0[kk]), lpips.normalize_tensor(outs1[kk])
+ diffs[kk] = (feats0[kk]-feats1[kk])**2
+
+ if(self.lpips):
+ if(self.spatial):
+ res = [upsample(self.lins[kk](diffs[kk]), out_HW=in0.shape[2:]) for kk in range(self.L)]
+ else:
+ res = [spatial_average(self.lins[kk](diffs[kk]), keepdim=True) for kk in range(self.L)]
+ else:
+ if(self.spatial):
+ res = [upsample(diffs[kk].sum(dim=1,keepdim=True), out_HW=in0.shape[2:]) for kk in range(self.L)]
+ else:
+ res = [spatial_average(diffs[kk].sum(dim=1,keepdim=True), keepdim=True) for kk in range(self.L)]
+
+ val = res[0]
+ for l in range(1,self.L):
+ val += res[l]
+
+ # a = spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
+ # b = torch.max(self.lins[kk](feats0[kk]**2))
+ # for kk in range(self.L):
+ # a += spatial_average(self.lins[kk](diffs[kk]), keepdim=True)
+ # b = torch.max(b,torch.max(self.lins[kk](feats0[kk]**2)))
+ # a = a/self.L
+ # from IPython import embed
+ # embed()
+ # return 10*torch.log10(b/a)
+
+ if(retPerLayer):
+ return (val, res)
+ else:
+ return val
+
+
+class ScalingLayer(nn.Module):
+ def __init__(self):
+ super(ScalingLayer, self).__init__()
+ self.register_buffer('shift', torch.Tensor([-.030,-.088,-.188])[None,:,None,None])
+ self.register_buffer('scale', torch.Tensor([.458,.448,.450])[None,:,None,None])
+
+ def forward(self, inp):
+ return (inp - self.shift) / self.scale
+
+
+class NetLinLayer(nn.Module):
+ ''' A single linear layer which does a 1x1 conv '''
+ def __init__(self, chn_in, chn_out=1, use_dropout=False):
+ super(NetLinLayer, self).__init__()
+
+ layers = [nn.Dropout(),] if(use_dropout) else []
+ layers += [nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),]
+ self.model = nn.Sequential(*layers)
+
+ def forward(self, x):
+ return self.model(x)
+
+class Dist2LogitLayer(nn.Module):
+ ''' takes 2 distances, puts through fc layers, spits out value between [0,1] (if use_sigmoid is True) '''
+ def __init__(self, chn_mid=32, use_sigmoid=True):
+ super(Dist2LogitLayer, self).__init__()
+
+ layers = [nn.Conv2d(5, chn_mid, 1, stride=1, padding=0, bias=True),]
+ layers += [nn.LeakyReLU(0.2,True),]
+ layers += [nn.Conv2d(chn_mid, chn_mid, 1, stride=1, padding=0, bias=True),]
+ layers += [nn.LeakyReLU(0.2,True),]
+ layers += [nn.Conv2d(chn_mid, 1, 1, stride=1, padding=0, bias=True),]
+ if(use_sigmoid):
+ layers += [nn.Sigmoid(),]
+ self.model = nn.Sequential(*layers)
+
+ def forward(self,d0,d1,eps=0.1):
+ return self.model.forward(torch.cat((d0,d1,d0-d1,d0/(d1+eps),d1/(d0+eps)),dim=1))
+
+class BCERankingLoss(nn.Module):
+ def __init__(self, chn_mid=32):
+ super(BCERankingLoss, self).__init__()
+ self.net = Dist2LogitLayer(chn_mid=chn_mid)
+ # self.parameters = list(self.net.parameters())
+ self.loss = torch.nn.BCELoss()
+
+ def forward(self, d0, d1, judge):
+ per = (judge+1.)/2.
+ self.logit = self.net.forward(d0,d1)
+ return self.loss(self.logit, per)
+
+# L2, DSSIM metrics
+class FakeNet(nn.Module):
+ def __init__(self, use_gpu=True, colorspace='Lab'):
+ super(FakeNet, self).__init__()
+ self.use_gpu = use_gpu
+ self.colorspace = colorspace
+
+class L2(FakeNet):
+ def forward(self, in0, in1, retPerLayer=None):
+ assert(in0.size()[0]==1) # currently only supports batchSize 1
+
+ if(self.colorspace=='RGB'):
+ (N,C,X,Y) = in0.size()
+ value = torch.mean(torch.mean(torch.mean((in0-in1)**2,dim=1).view(N,1,X,Y),dim=2).view(N,1,1,Y),dim=3).view(N)
+ return value
+ elif(self.colorspace=='Lab'):
+ value = lpips.l2(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
+ lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
+ ret_var = Variable( torch.Tensor((value,) ) )
+ if(self.use_gpu):
+ ret_var = ret_var.cuda()
+ return ret_var
+
+class DSSIM(FakeNet):
+
+ def forward(self, in0, in1, retPerLayer=None):
+ assert(in0.size()[0]==1) # currently only supports batchSize 1
+
+ if(self.colorspace=='RGB'):
+ value = lpips.dssim(1.*lpips.tensor2im(in0.data), 1.*lpips.tensor2im(in1.data), range=255.).astype('float')
+ elif(self.colorspace=='Lab'):
+ value = lpips.dssim(lpips.tensor2np(lpips.tensor2tensorlab(in0.data,to_norm=False)),
+ lpips.tensor2np(lpips.tensor2tensorlab(in1.data,to_norm=False)), range=100.).astype('float')
+ ret_var = Variable( torch.Tensor((value,) ) )
+ if(self.use_gpu):
+ ret_var = ret_var.cuda()
+ return ret_var
+
+def print_network(net):
+ num_params = 0
+ for param in net.parameters():
+ num_params += param.numel()
+ print('Network',net)
+ print('Total number of parameters: %d' % num_params)
diff --git a/models/FeatureStyleEncoder/lpips/pretrained_networks.py b/models/FeatureStyleEncoder/lpips/pretrained_networks.py
new file mode 100644
index 0000000000000000000000000000000000000000..054dba7f4f7fa94bcd41df0aaaba52b4dd852f93
--- /dev/null
+++ b/models/FeatureStyleEncoder/lpips/pretrained_networks.py
@@ -0,0 +1,182 @@
+from collections import namedtuple
+import torch
+from torchvision import models as tv
+
+import os
+
+class squeezenet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(squeezenet, self).__init__()
+ pretrained_features = tv.squeezenet1_1(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.slice6 = torch.nn.Sequential()
+ self.slice7 = torch.nn.Sequential()
+ self.N_slices = 7
+ for x in range(2):
+ self.slice1.add_module(str(x), pretrained_features[x])
+ for x in range(2,5):
+ self.slice2.add_module(str(x), pretrained_features[x])
+ for x in range(5, 8):
+ self.slice3.add_module(str(x), pretrained_features[x])
+ for x in range(8, 10):
+ self.slice4.add_module(str(x), pretrained_features[x])
+ for x in range(10, 11):
+ self.slice5.add_module(str(x), pretrained_features[x])
+ for x in range(11, 12):
+ self.slice6.add_module(str(x), pretrained_features[x])
+ for x in range(12, 13):
+ self.slice7.add_module(str(x), pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1 = h
+ h = self.slice2(h)
+ h_relu2 = h
+ h = self.slice3(h)
+ h_relu3 = h
+ h = self.slice4(h)
+ h_relu4 = h
+ h = self.slice5(h)
+ h_relu5 = h
+ h = self.slice6(h)
+ h_relu6 = h
+ h = self.slice7(h)
+ h_relu7 = h
+ vgg_outputs = namedtuple("SqueezeOutputs", ['relu1','relu2','relu3','relu4','relu5','relu6','relu7'])
+ out = vgg_outputs(h_relu1,h_relu2,h_relu3,h_relu4,h_relu5,h_relu6,h_relu7)
+
+ return out
+
+
+class alexnet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(alexnet, self).__init__()
+ alexnet_pretrained_features = tv.alexnet(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.N_slices = 5
+ for x in range(2):
+ self.slice1.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(2, 5):
+ self.slice2.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(5, 8):
+ self.slice3.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(8, 10):
+ self.slice4.add_module(str(x), alexnet_pretrained_features[x])
+ for x in range(10, 12):
+ self.slice5.add_module(str(x), alexnet_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1 = h
+ h = self.slice2(h)
+ h_relu2 = h
+ h = self.slice3(h)
+ h_relu3 = h
+ h = self.slice4(h)
+ h_relu4 = h
+ h = self.slice5(h)
+ h_relu5 = h
+ alexnet_outputs = namedtuple("AlexnetOutputs", ['relu1', 'relu2', 'relu3', 'relu4', 'relu5'])
+ out = alexnet_outputs(h_relu1, h_relu2, h_relu3, h_relu4, h_relu5)
+
+ return out
+
+class vgg16(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(vgg16, self).__init__()
+ vgg_pretrained_features = tv.vgg16(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.N_slices = 5
+ for x in range(4):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(4, 9):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(9, 16):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(16, 23):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(23, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1_2 = h
+ h = self.slice2(h)
+ h_relu2_2 = h
+ h = self.slice3(h)
+ h_relu3_3 = h
+ h = self.slice4(h)
+ h_relu4_3 = h
+ h = self.slice5(h)
+ h_relu5_3 = h
+ vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3', 'relu5_3'])
+ out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
+
+ return out
+
+
+
+class resnet(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True, num=18):
+ super(resnet, self).__init__()
+ if(num==18):
+ self.net = tv.resnet18(pretrained=pretrained)
+ elif(num==34):
+ self.net = tv.resnet34(pretrained=pretrained)
+ elif(num==50):
+ self.net = tv.resnet50(pretrained=pretrained)
+ elif(num==101):
+ self.net = tv.resnet101(pretrained=pretrained)
+ elif(num==152):
+ self.net = tv.resnet152(pretrained=pretrained)
+ self.N_slices = 5
+
+ self.conv1 = self.net.conv1
+ self.bn1 = self.net.bn1
+ self.relu = self.net.relu
+ self.maxpool = self.net.maxpool
+ self.layer1 = self.net.layer1
+ self.layer2 = self.net.layer2
+ self.layer3 = self.net.layer3
+ self.layer4 = self.net.layer4
+
+ def forward(self, X):
+ h = self.conv1(X)
+ h = self.bn1(h)
+ h = self.relu(h)
+ h_relu1 = h
+ h = self.maxpool(h)
+ h = self.layer1(h)
+ h_conv2 = h
+ h = self.layer2(h)
+ h_conv3 = h
+ h = self.layer3(h)
+ h_conv4 = h
+ h = self.layer4(h)
+ h_conv5 = h
+
+ outputs = namedtuple("Outputs", ['relu1','conv2','conv3','conv4','conv5'])
+ out = outputs(h_relu1, h_conv2, h_conv3, h_conv4, h_conv5)
+
+ return out
diff --git a/models/FeatureStyleEncoder/lpips/trainer.py b/models/FeatureStyleEncoder/lpips/trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..52b6112cdc79db7a429ec52e60fcefdb756f776b
--- /dev/null
+++ b/models/FeatureStyleEncoder/lpips/trainer.py
@@ -0,0 +1,280 @@
+
+from __future__ import absolute_import
+
+import numpy as np
+import torch
+from torch import nn
+from collections import OrderedDict
+from torch.autograd import Variable
+from scipy.ndimage import zoom
+from tqdm import tqdm
+import lpips
+import os
+
+
+class Trainer():
+ def name(self):
+ return self.model_name
+
+ def initialize(self, model='lpips', net='alex', colorspace='Lab', pnet_rand=False, pnet_tune=False, model_path=None,
+ use_gpu=True, printNet=False, spatial=False,
+ is_train=False, lr=.0001, beta1=0.5, version='0.1', gpu_ids=[0]):
+ '''
+ INPUTS
+ model - ['lpips'] for linearly calibrated network
+ ['baseline'] for off-the-shelf network
+ ['L2'] for L2 distance in Lab colorspace
+ ['SSIM'] for ssim in RGB colorspace
+ net - ['squeeze','alex','vgg']
+ model_path - if None, will look in weights/[NET_NAME].pth
+ colorspace - ['Lab','RGB'] colorspace to use for L2 and SSIM
+ use_gpu - bool - whether or not to use a GPU
+ printNet - bool - whether or not to print network architecture out
+ spatial - bool - whether to output an array containing varying distances across spatial dimensions
+ is_train - bool - [True] for training mode
+ lr - float - initial learning rate
+ beta1 - float - initial momentum term for adam
+ version - 0.1 for latest, 0.0 was original (with a bug)
+ gpu_ids - int array - [0] by default, gpus to use
+ '''
+ self.use_gpu = use_gpu
+ self.gpu_ids = gpu_ids
+ self.model = model
+ self.net = net
+ self.is_train = is_train
+ self.spatial = spatial
+ self.model_name = '%s [%s]'%(model,net)
+
+ if(self.model == 'lpips'): # pretrained net + linear layer
+ self.net = lpips.LPIPS(pretrained=not is_train, net=net, version=version, lpips=True, spatial=spatial,
+ pnet_rand=pnet_rand, pnet_tune=pnet_tune,
+ use_dropout=True, model_path=model_path, eval_mode=False)
+ elif(self.model=='baseline'): # pretrained network
+ self.net = lpips.LPIPS(pnet_rand=pnet_rand, net=net, lpips=False)
+ elif(self.model in ['L2','l2']):
+ self.net = lpips.L2(use_gpu=use_gpu,colorspace=colorspace) # not really a network, only for testing
+ self.model_name = 'L2'
+ elif(self.model in ['DSSIM','dssim','SSIM','ssim']):
+ self.net = lpips.DSSIM(use_gpu=use_gpu,colorspace=colorspace)
+ self.model_name = 'SSIM'
+ else:
+ raise ValueError("Model [%s] not recognized." % self.model)
+
+ self.parameters = list(self.net.parameters())
+
+ if self.is_train: # training mode
+ # extra network on top to go from distances (d0,d1) => predicted human judgment (h*)
+ self.rankLoss = lpips.BCERankingLoss()
+ self.parameters += list(self.rankLoss.net.parameters())
+ self.lr = lr
+ self.old_lr = lr
+ self.optimizer_net = torch.optim.Adam(self.parameters, lr=lr, betas=(beta1, 0.999))
+ else: # test mode
+ self.net.eval()
+
+ if(use_gpu):
+ self.net.to(gpu_ids[0])
+ self.net = torch.nn.DataParallel(self.net, device_ids=gpu_ids)
+ if(self.is_train):
+ self.rankLoss = self.rankLoss.to(device=gpu_ids[0]) # just put this on GPU0
+
+ if(printNet):
+ print('---------- Networks initialized -------------')
+ networks.print_network(self.net)
+ print('-----------------------------------------------')
+
+ def forward(self, in0, in1, retPerLayer=False):
+ ''' Function computes the distance between image patches in0 and in1
+ INPUTS
+ in0, in1 - torch.Tensor object of shape Nx3xXxY - image patch scaled to [-1,1]
+ OUTPUT
+ computed distances between in0 and in1
+ '''
+
+ return self.net.forward(in0, in1, retPerLayer=retPerLayer)
+
+ # ***** TRAINING FUNCTIONS *****
+ def optimize_parameters(self):
+ self.forward_train()
+ self.optimizer_net.zero_grad()
+ self.backward_train()
+ self.optimizer_net.step()
+ self.clamp_weights()
+
+ def clamp_weights(self):
+ for module in self.net.modules():
+ if(hasattr(module, 'weight') and module.kernel_size==(1,1)):
+ module.weight.data = torch.clamp(module.weight.data,min=0)
+
+ def set_input(self, data):
+ self.input_ref = data['ref']
+ self.input_p0 = data['p0']
+ self.input_p1 = data['p1']
+ self.input_judge = data['judge']
+
+ if(self.use_gpu):
+ self.input_ref = self.input_ref.to(device=self.gpu_ids[0])
+ self.input_p0 = self.input_p0.to(device=self.gpu_ids[0])
+ self.input_p1 = self.input_p1.to(device=self.gpu_ids[0])
+ self.input_judge = self.input_judge.to(device=self.gpu_ids[0])
+
+ self.var_ref = Variable(self.input_ref,requires_grad=True)
+ self.var_p0 = Variable(self.input_p0,requires_grad=True)
+ self.var_p1 = Variable(self.input_p1,requires_grad=True)
+
+ def forward_train(self): # run forward pass
+ self.d0 = self.forward(self.var_ref, self.var_p0)
+ self.d1 = self.forward(self.var_ref, self.var_p1)
+ self.acc_r = self.compute_accuracy(self.d0,self.d1,self.input_judge)
+
+ self.var_judge = Variable(1.*self.input_judge).view(self.d0.size())
+
+ self.loss_total = self.rankLoss.forward(self.d0, self.d1, self.var_judge*2.-1.)
+
+ return self.loss_total
+
+ def backward_train(self):
+ torch.mean(self.loss_total).backward()
+
+ def compute_accuracy(self,d0,d1,judge):
+ ''' d0, d1 are Variables, judge is a Tensor '''
+ d1_lt_d0 = (d1 %f' % (type,self.old_lr, lr))
+ self.old_lr = lr
+
+
+ def get_image_paths(self):
+ return self.image_paths
+
+ def save_done(self, flag=False):
+ np.save(os.path.join(self.save_dir, 'done_flag'),flag)
+ np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i')
+
+
+def score_2afc_dataset(data_loader, func, name=''):
+ ''' Function computes Two Alternative Forced Choice (2AFC) score using
+ distance function 'func' in dataset 'data_loader'
+ INPUTS
+ data_loader - CustomDatasetDataLoader object - contains a TwoAFCDataset inside
+ func - callable distance function - calling d=func(in0,in1) should take 2
+ pytorch tensors with shape Nx3xXxY, and return numpy array of length N
+ OUTPUTS
+ [0] - 2AFC score in [0,1], fraction of time func agrees with human evaluators
+ [1] - dictionary with following elements
+ d0s,d1s - N arrays containing distances between reference patch to perturbed patches
+ gts - N array in [0,1], preferred patch selected by human evaluators
+ (closer to "0" for left patch p0, "1" for right patch p1,
+ "0.6" means 60pct people preferred right patch, 40pct preferred left)
+ scores - N array in [0,1], corresponding to what percentage function agreed with humans
+ CONSTS
+ N - number of test triplets in data_loader
+ '''
+
+ d0s = []
+ d1s = []
+ gts = []
+
+ for data in tqdm(data_loader.load_data(), desc=name):
+ d0s+=func(data['ref'],data['p0']).data.cpu().numpy().flatten().tolist()
+ d1s+=func(data['ref'],data['p1']).data.cpu().numpy().flatten().tolist()
+ gts+=data['judge'].cpu().numpy().flatten().tolist()
+
+ d0s = np.array(d0s)
+ d1s = np.array(d1s)
+ gts = np.array(gts)
+ scores = (d0s 1:
+ kernel = kernel * (upsample_factor ** 2)
+
+ self.register_buffer('kernel', kernel)
+
+ self.pad = pad
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, pad=self.pad)
+
+ return out
+
+
+class EqualConv2d(nn.Module):
+ def __init__(
+ self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(
+ torch.randn(out_channel, in_channel, kernel_size, kernel_size)
+ )
+ self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
+
+ self.stride = stride
+ self.padding = padding
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channel))
+
+ else:
+ self.bias = None
+
+ def forward(self, input):
+ out = F.conv2d(
+ input,
+ self.weight * self.scale,
+ bias=self.bias,
+ stride=self.stride,
+ padding=self.padding,
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
+ f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
+ )
+
+
+class EqualLinear(nn.Module):
+ def __init__(
+ self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
+
+ else:
+ self.bias = None
+
+ self.activation = activation
+
+ self.scale = (1 / math.sqrt(in_dim)) * lr_mul
+ self.lr_mul = lr_mul
+
+ def forward(self, input):
+ if self.activation:
+ out = F.linear(input, self.weight * self.scale)
+ out = fused_leaky_relu(out, self.bias * self.lr_mul)
+
+ else:
+ out = F.linear(
+ input, self.weight * self.scale, bias=self.bias * self.lr_mul
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
+ )
+
+
+class ScaledLeakyReLU(nn.Module):
+ def __init__(self, negative_slope=0.2):
+ super().__init__()
+
+ self.negative_slope = negative_slope
+
+ def forward(self, input):
+ out = F.leaky_relu(input, negative_slope=self.negative_slope)
+
+ return out * math.sqrt(2)
+
+
+class ModulatedConv2d(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ demodulate=True,
+ upsample=False,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ ):
+ super().__init__()
+
+ self.eps = 1e-8
+ self.kernel_size = kernel_size
+ self.in_channel = in_channel
+ self.out_channel = out_channel
+ self.upsample = upsample
+ self.downsample = downsample
+
+ if upsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) - (kernel_size - 1)
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2 + 1
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1))
+
+ fan_in = in_channel * kernel_size ** 2
+ self.scale = 1 / math.sqrt(fan_in)
+ self.padding = kernel_size // 2
+
+ self.weight = nn.Parameter(
+ torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
+ )
+
+ self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
+
+ self.demodulate = demodulate
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
+ f'upsample={self.upsample}, downsample={self.downsample})'
+ )
+
+ def forward(self, input, style):
+ batch, in_channel, height, width = input.shape
+
+ style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
+ weight = self.scale * self.weight * style
+
+ if self.demodulate:
+ demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
+ weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
+
+ weight = weight.view(
+ batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+
+ if self.upsample:
+ input = input.view(1, batch * in_channel, height, width)
+ weight = weight.view(
+ batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+ weight = weight.transpose(1, 2).reshape(
+ batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
+ )
+ out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+ out = self.blur(out)
+
+ elif self.downsample:
+ input = self.blur(input)
+ _, _, height, width = input.shape
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ else:
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=self.padding, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ return out
+
+
+class NoiseInjection(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.zeros(1))
+
+ def forward(self, image, noise=None):
+ if noise is None:
+ batch, _, height, width = image.shape
+ noise = image.new_empty(batch, 1, height, width).normal_()
+
+ return image + self.weight * noise
+
+
+class ConstantInput(nn.Module):
+ def __init__(self, channel, size=4):
+ super().__init__()
+
+ self.input = nn.Parameter(torch.randn(1, channel, size, size))
+
+ def forward(self, input):
+ batch = input.shape[0]
+ out = self.input.repeat(batch, 1, 1, 1)
+
+ return out
+
+
+class StyledConv(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ demodulate=True,
+ ):
+ super().__init__()
+
+ self.conv = ModulatedConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=upsample,
+ blur_kernel=blur_kernel,
+ demodulate=demodulate,
+ )
+
+ self.noise = NoiseInjection()
+ # self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
+ # self.activate = ScaledLeakyReLU(0.2)
+ self.activate = FusedLeakyReLU(out_channel)
+
+ def forward(self, input, style, noise=None):
+ out = self.conv(input, style)
+ out = self.noise(out, noise=noise)
+ # out = out + self.bias
+ out = self.activate(out)
+
+ return out
+
+
+class ToRGB(nn.Module):
+ def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ if upsample:
+ self.upsample = Upsample(blur_kernel)
+
+ self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
+ self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
+
+ def forward(self, input, style, skip=None):
+ out = self.conv(input, style)
+ out = out + self.bias
+
+ if skip is not None:
+ skip = self.upsample(skip)
+
+ out = out + skip
+
+ return out
+
+
+class Generator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+
+ self.size = size
+
+ self.style_dim = style_dim
+
+ layers = [PixelNorm()]
+
+ for i in range(n_mlp):
+ layers.append(
+ EqualLinear(
+ style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
+ )
+ )
+
+ self.style = nn.Sequential(*layers)
+
+ self.channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.input = ConstantInput(self.channels[4])
+ self.conv1 = StyledConv(
+ self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
+ )
+ self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
+
+ self.log_size = int(math.log(size, 2))
+ self.num_layers = (self.log_size - 2) * 2 + 1
+
+ self.convs = nn.ModuleList()
+ self.upsamples = nn.ModuleList()
+ self.to_rgbs = nn.ModuleList()
+ self.noises = nn.Module()
+
+ in_channel = self.channels[4]
+
+ for layer_idx in range(self.num_layers):
+ res = (layer_idx + 5) // 2
+ shape = [1, 1, 2 ** res, 2 ** res]
+ self.noises.register_buffer(f'noise_{layer_idx}', torch.randn(*shape))
+
+ for i in range(3, self.log_size + 1):
+ out_channel = self.channels[2 ** i]
+
+ self.convs.append(
+ StyledConv(
+ in_channel,
+ out_channel,
+ 3,
+ style_dim,
+ upsample=True,
+ blur_kernel=blur_kernel,
+ )
+ )
+
+ self.convs.append(
+ StyledConv(
+ out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
+ )
+ )
+
+ self.to_rgbs.append(ToRGB(out_channel, style_dim))
+
+ in_channel = out_channel
+
+ self.n_latent = self.log_size * 2 - 2
+
+ def make_noise(self):
+ device = self.input.input.device
+
+ noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
+
+ for i in range(3, self.log_size + 1):
+ for _ in range(2):
+ noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
+
+ return noises
+
+ def mean_latent(self, n_latent):
+ latent_in = torch.randn(
+ n_latent, self.style_dim, device=self.input.input.device
+ )
+ latent = self.style(latent_in).mean(0, keepdim=True)
+
+ return latent
+
+ def get_latent(self, input):
+ return self.style(input)
+
+ def forward(
+ self,
+ styles,
+ return_latents=False,
+ return_features=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ noise=None,
+ randomize_noise=True,
+ features_in=None,
+ feature_scale=1.0
+ ):
+ if not input_is_latent:
+ styles = [self.style(s) for s in styles]
+
+ if noise is None:
+ if randomize_noise:
+ noise = [None] * self.num_layers
+ else:
+ noise = [
+ getattr(self.noises, f'noise_{i}') for i in range(self.num_layers)
+ ]
+
+ if truncation < 1:
+ style_t = []
+
+ for style in styles:
+ style_t.append(
+ truncation_latent + truncation * (style - truncation_latent)
+ )
+
+ styles = style_t
+
+ if len(styles) < 2:
+ inject_index = self.n_latent
+
+ if styles[0].ndim < 3:
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ else:
+ latent = styles[0]
+
+ else:
+ if inject_index is None:
+ inject_index = random.randint(1, self.n_latent - 1)
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
+
+ latent = torch.cat([latent, latent2], 1)
+
+ def insert_feature(x, layer_idx):
+ if features_in is not None and features_in[layer_idx] is not None:
+ x = (1 - feature_scale) * x + feature_scale * features_in[layer_idx].type_as(x)
+ return x
+
+ outs = []
+ out = self.input(latent)
+ outs.append(out)
+ out = self.conv1(out, latent[:, 0], noise=noise[0])
+ outs.append(out)
+
+ skip = self.to_rgb1(out, latent[:, 1])
+
+ i = 1
+ for conv1, conv2, noise1, noise2, to_rgb in zip(
+ self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
+ ):
+ out = insert_feature(out, i)
+ out = conv1(out, latent[:, i], noise=noise1)
+ outs.append(out)
+ out = insert_feature(out, i + 1)
+ out = conv2(out, latent[:, i + 1], noise=noise2)
+ outs.append(out)
+ skip = to_rgb(out, latent[:, i + 2], skip)
+
+ i += 2
+
+ image = skip
+
+ if return_latents:
+ return image, latent
+ elif return_features:
+ return image, outs
+ else:
+ return image, None
+
+
+class ConvLayer(nn.Sequential):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ bias=True,
+ activate=True,
+ ):
+ layers = []
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
+
+ stride = 2
+ self.padding = 0
+
+ else:
+ stride = 1
+ self.padding = kernel_size // 2
+
+ layers.append(
+ EqualConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ padding=self.padding,
+ stride=stride,
+ bias=bias and not activate,
+ )
+ )
+
+ if activate:
+ if bias:
+ layers.append(FusedLeakyReLU(out_channel))
+
+ else:
+ layers.append(ScaledLeakyReLU(0.2))
+
+ super().__init__(*layers)
+
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ self.conv1 = ConvLayer(in_channel, in_channel, 3)
+ self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
+
+ self.skip = ConvLayer(
+ in_channel, out_channel, 1, downsample=True, activate=False, bias=False
+ )
+
+ def forward(self, input):
+ out = self.conv1(input)
+ out = self.conv2(out)
+
+ skip = self.skip(input)
+ out = (out + skip) / math.sqrt(2)
+
+ return out
+
+
+class Discriminator(nn.Module):
+ def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ convs = [ConvLayer(3, channels[size], 1)]
+
+ log_size = int(math.log(size, 2))
+
+ in_channel = channels[size]
+
+ for i in range(log_size, 2, -1):
+ out_channel = channels[2 ** (i - 1)]
+
+ convs.append(ResBlock(in_channel, out_channel, blur_kernel))
+
+ in_channel = out_channel
+
+ self.convs = nn.Sequential(*convs)
+
+ self.stddev_group = 4
+ self.stddev_feat = 1
+
+ self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
+ self.final_linear = nn.Sequential(
+ EqualLinear(channels[4] * 4 * 4, channels[4], activation='fused_lrelu'),
+ EqualLinear(channels[4], 1),
+ )
+
+ def forward(self, input):
+ out = self.convs(input)
+
+ batch, channel, height, width = out.shape
+ group = min(batch, self.stddev_group)
+ stddev = out.view(
+ group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
+ )
+ stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
+ stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
+ stddev = stddev.repeat(group, 1, height, width)
+ out = torch.cat([out, stddev], 1)
+
+ out = self.final_conv(out)
+
+ out = out.view(batch, -1)
+ out = self.final_linear(out)
+
+ return out
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/__init__.py b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0918d92285955855be89f00096b888ee5597ce3
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/__init__.py
@@ -0,0 +1,2 @@
+from .fused_act import FusedLeakyReLU, fused_leaky_relu
+from .upfirdn2d import upfirdn2d
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_act.py b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_act.py
new file mode 100644
index 0000000000000000000000000000000000000000..973a84fffde53668d31397da5fb993bbc95f7be0
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_act.py
@@ -0,0 +1,85 @@
+import os
+
+import torch
+from torch import nn
+from torch.autograd import Function
+from torch.utils.cpp_extension import load
+
+module_path = os.path.dirname(__file__)
+fused = load(
+ 'fused',
+ sources=[
+ os.path.join(module_path, 'fused_bias_act.cpp'),
+ os.path.join(module_path, 'fused_bias_act_kernel.cu'),
+ ],
+)
+
+
+class FusedLeakyReLUFunctionBackward(Function):
+ @staticmethod
+ def forward(ctx, grad_output, out, negative_slope, scale):
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ empty = grad_output.new_empty(0)
+
+ grad_input = fused.fused_bias_act(
+ grad_output, empty, out, 3, 1, negative_slope, scale
+ )
+
+ dim = [0]
+
+ if grad_input.ndim > 2:
+ dim += list(range(2, grad_input.ndim))
+
+ grad_bias = grad_input.sum(dim).detach()
+
+ return grad_input, grad_bias
+
+ @staticmethod
+ def backward(ctx, gradgrad_input, gradgrad_bias):
+ out, = ctx.saved_tensors
+ gradgrad_out = fused.fused_bias_act(
+ gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale
+ )
+
+ return gradgrad_out, None, None, None
+
+
+class FusedLeakyReLUFunction(Function):
+ @staticmethod
+ def forward(ctx, input, bias, negative_slope, scale):
+ empty = input.new_empty(0)
+ out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ out, = ctx.saved_tensors
+
+ grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
+ grad_output, out, ctx.negative_slope, ctx.scale
+ )
+
+ return grad_input, grad_bias, None, None
+
+
+class FusedLeakyReLU(nn.Module):
+ def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5):
+ super().__init__()
+
+ self.bias = nn.Parameter(torch.zeros(channel))
+ self.negative_slope = negative_slope
+ self.scale = scale
+
+ def forward(self, input):
+ return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
+
+
+def fused_leaky_relu(input, bias, negative_slope=0.2, scale=2 ** 0.5):
+ return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act.cpp b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..02be898f970bcc8ea297867fcaa4e71b24b3d949
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act.cpp
@@ -0,0 +1,21 @@
+#include
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(bias);
+
+ return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
+}
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act_kernel.cu b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..c9fa56fea7ede7072dc8925cfb0148f136eb85b8
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/fused_bias_act_kernel.cu
@@ -0,0 +1,99 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+template
+static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
+ int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
+ int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
+
+ scalar_t zero = 0.0;
+
+ for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
+ scalar_t x = p_x[xi];
+
+ if (use_bias) {
+ x += p_b[(xi / step_b) % size_b];
+ }
+
+ scalar_t ref = use_ref ? p_ref[xi] : zero;
+
+ scalar_t y;
+
+ switch (act * 10 + grad) {
+ default:
+ case 10: y = x; break;
+ case 11: y = x; break;
+ case 12: y = 0.0; break;
+
+ case 30: y = (x > 0.0) ? x : x * alpha; break;
+ case 31: y = (ref > 0.0) ? x : x * alpha; break;
+ case 32: y = 0.0; break;
+ }
+
+ out[xi] = y * scale;
+ }
+}
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ auto x = input.contiguous();
+ auto b = bias.contiguous();
+ auto ref = refer.contiguous();
+
+ int use_bias = b.numel() ? 1 : 0;
+ int use_ref = ref.numel() ? 1 : 0;
+
+ int size_x = x.numel();
+ int size_b = b.numel();
+ int step_b = 1;
+
+ for (int i = 1 + 1; i < x.dim(); i++) {
+ step_b *= x.size(i);
+ }
+
+ int loop_x = 4;
+ int block_size = 4 * 32;
+ int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
+
+ auto y = torch::empty_like(x);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
+ fused_bias_act_kernel<<>>(
+ y.data_ptr(),
+ x.data_ptr(),
+ b.data_ptr(),
+ ref.data_ptr(),
+ act,
+ grad,
+ alpha,
+ scale,
+ loop_x,
+ size_x,
+ step_b,
+ size_b,
+ use_bias,
+ use_ref
+ );
+ });
+
+ return y;
+}
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.cpp b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..d2e633dc896433c205e18bc3e455539192ff968e
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.cpp
@@ -0,0 +1,23 @@
+#include
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(kernel);
+
+ return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
+}
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.py b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..e43c7eeddbc143ea313454e5b64d083c27dafc5b
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d.py
@@ -0,0 +1,185 @@
+import os
+
+import torch
+from torch.autograd import Function
+from torch.utils.cpp_extension import load
+
+
+module_path = os.path.dirname(__file__)
+upfirdn2d_op = load(
+ 'upfirdn2d',
+ sources=[
+ os.path.join(module_path, 'upfirdn2d.cpp'),
+ os.path.join(module_path, 'upfirdn2d_kernel.cu'),
+ ],
+)
+
+
+class UpFirDn2dBackward(Function):
+ @staticmethod
+ def forward(
+ ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
+ ):
+ up_x, up_y = up
+ down_x, down_y = down
+ g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
+
+ grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
+
+ grad_input = upfirdn2d_op.upfirdn2d(
+ grad_output,
+ grad_kernel,
+ down_x,
+ down_y,
+ up_x,
+ up_y,
+ g_pad_x0,
+ g_pad_x1,
+ g_pad_y0,
+ g_pad_y1,
+ )
+ grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
+
+ ctx.save_for_backward(kernel)
+
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ ctx.up_x = up_x
+ ctx.up_y = up_y
+ ctx.down_x = down_x
+ ctx.down_y = down_y
+ ctx.pad_x0 = pad_x0
+ ctx.pad_x1 = pad_x1
+ ctx.pad_y0 = pad_y0
+ ctx.pad_y1 = pad_y1
+ ctx.in_size = in_size
+ ctx.out_size = out_size
+
+ return grad_input
+
+ @staticmethod
+ def backward(ctx, gradgrad_input):
+ kernel, = ctx.saved_tensors
+
+ gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
+
+ gradgrad_out = upfirdn2d_op.upfirdn2d(
+ gradgrad_input,
+ kernel,
+ ctx.up_x,
+ ctx.up_y,
+ ctx.down_x,
+ ctx.down_y,
+ ctx.pad_x0,
+ ctx.pad_x1,
+ ctx.pad_y0,
+ ctx.pad_y1,
+ )
+ # gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
+ gradgrad_out = gradgrad_out.view(
+ ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
+ )
+
+ return gradgrad_out, None, None, None, None, None, None, None, None
+
+
+class UpFirDn2d(Function):
+ @staticmethod
+ def forward(ctx, input, kernel, up, down, pad):
+ up_x, up_y = up
+ down_x, down_y = down
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ kernel_h, kernel_w = kernel.shape
+ batch, channel, in_h, in_w = input.shape
+ ctx.in_size = input.shape
+
+ input = input.reshape(-1, in_h, in_w, 1)
+
+ ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+ ctx.out_size = (out_h, out_w)
+
+ ctx.up = (up_x, up_y)
+ ctx.down = (down_x, down_y)
+ ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
+
+ g_pad_x0 = kernel_w - pad_x0 - 1
+ g_pad_y0 = kernel_h - pad_y0 - 1
+ g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
+ g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
+
+ ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
+
+ out = upfirdn2d_op.upfirdn2d(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+ )
+ # out = out.view(major, out_h, out_w, minor)
+ out = out.view(-1, channel, out_h, out_w)
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ kernel, grad_kernel = ctx.saved_tensors
+
+ grad_input = UpFirDn2dBackward.apply(
+ grad_output,
+ kernel,
+ grad_kernel,
+ ctx.up,
+ ctx.down,
+ ctx.pad,
+ ctx.g_pad,
+ ctx.in_size,
+ ctx.out_size,
+ )
+
+ return grad_input, None, None, None, None
+
+
+def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
+ out = UpFirDn2d.apply(
+ input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
+ )
+
+ return out
+
+
+def upfirdn2d_native(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+):
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.view(-1, in_h, 1, in_w, 1, minor)
+ out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.view(-1, in_h * up_y, in_w * up_x, minor)
+
+ out = F.pad(
+ out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
+ )
+ out = out[
+ :,
+ max(-pad_y0, 0): out.shape[1] - max(-pad_y1, 0),
+ max(-pad_x0, 0): out.shape[2] - max(-pad_x1, 0),
+ :,
+ ]
+
+ out = out.permute(0, 3, 1, 2)
+ out = out.reshape(
+ [-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
+ )
+ w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ -1,
+ minor,
+ in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
+ in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
+ )
+ out = out.permute(0, 2, 3, 1)
+
+ return out[:, ::down_y, ::down_x, :]
diff --git a/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d_kernel.cu b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..2a710aa6adc3d43ac93136a1814e3c39970e1c7e
--- /dev/null
+++ b/models/FeatureStyleEncoder/pixel2style2pixel/models/stylegan2/op/upfirdn2d_kernel.cu
@@ -0,0 +1,272 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
+ int c = a / b;
+
+ if (c * b > a) {
+ c--;
+ }
+
+ return c;
+}
+
+
+struct UpFirDn2DKernelParams {
+ int up_x;
+ int up_y;
+ int down_x;
+ int down_y;
+ int pad_x0;
+ int pad_x1;
+ int pad_y0;
+ int pad_y1;
+
+ int major_dim;
+ int in_h;
+ int in_w;
+ int minor_dim;
+ int kernel_h;
+ int kernel_w;
+ int out_h;
+ int out_w;
+ int loop_major;
+ int loop_x;
+};
+
+
+template
+__global__ void upfirdn2d_kernel(scalar_t* out, const scalar_t* input, const scalar_t* kernel, const UpFirDn2DKernelParams p) {
+ const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
+ const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
+
+ __shared__ volatile float sk[kernel_h][kernel_w];
+ __shared__ volatile float sx[tile_in_h][tile_in_w];
+
+ int minor_idx = blockIdx.x;
+ int tile_out_y = minor_idx / p.minor_dim;
+ minor_idx -= tile_out_y * p.minor_dim;
+ tile_out_y *= tile_out_h;
+ int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
+ int major_idx_base = blockIdx.z * p.loop_major;
+
+ if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h | major_idx_base >= p.major_dim) {
+ return;
+ }
+
+ for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w; tap_idx += blockDim.x) {
+ int ky = tap_idx / kernel_w;
+ int kx = tap_idx - ky * kernel_w;
+ scalar_t v = 0.0;
+
+ if (kx < p.kernel_w & ky < p.kernel_h) {
+ v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
+ }
+
+ sk[ky][kx] = v;
+ }
+
+ for (int loop_major = 0, major_idx = major_idx_base; loop_major < p.loop_major & major_idx < p.major_dim; loop_major++, major_idx++) {
+ for (int loop_x = 0, tile_out_x = tile_out_x_base; loop_x < p.loop_x & tile_out_x < p.out_w; loop_x++, tile_out_x += tile_out_w) {
+ int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
+ int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
+ int tile_in_x = floor_div(tile_mid_x, up_x);
+ int tile_in_y = floor_div(tile_mid_y, up_y);
+
+ __syncthreads();
+
+ for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w; in_idx += blockDim.x) {
+ int rel_in_y = in_idx / tile_in_w;
+ int rel_in_x = in_idx - rel_in_y * tile_in_w;
+ int in_x = rel_in_x + tile_in_x;
+ int in_y = rel_in_y + tile_in_y;
+
+ scalar_t v = 0.0;
+
+ if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
+ v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim + minor_idx];
+ }
+
+ sx[rel_in_y][rel_in_x] = v;
+ }
+
+ __syncthreads();
+ for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w; out_idx += blockDim.x) {
+ int rel_out_y = out_idx / tile_out_w;
+ int rel_out_x = out_idx - rel_out_y * tile_out_w;
+ int out_x = rel_out_x + tile_out_x;
+ int out_y = rel_out_y + tile_out_y;
+
+ int mid_x = tile_mid_x + rel_out_x * down_x;
+ int mid_y = tile_mid_y + rel_out_y * down_y;
+ int in_x = floor_div(mid_x, up_x);
+ int in_y = floor_div(mid_y, up_y);
+ int rel_in_x = in_x - tile_in_x;
+ int rel_in_y = in_y - tile_in_y;
+ int kernel_x = (in_x + 1) * up_x - mid_x - 1;
+ int kernel_y = (in_y + 1) * up_y - mid_y - 1;
+
+ scalar_t v = 0.0;
+
+ #pragma unroll
+ for (int y = 0; y < kernel_h / up_y; y++)
+ #pragma unroll
+ for (int x = 0; x < kernel_w / up_x; x++)
+ v += sx[rel_in_y + y][rel_in_x + x] * sk[kernel_y + y * up_y][kernel_x + x * up_x];
+
+ if (out_x < p.out_w & out_y < p.out_h) {
+ out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim + minor_idx] = v;
+ }
+ }
+ }
+ }
+}
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ UpFirDn2DKernelParams p;
+
+ auto x = input.contiguous();
+ auto k = kernel.contiguous();
+
+ p.major_dim = x.size(0);
+ p.in_h = x.size(1);
+ p.in_w = x.size(2);
+ p.minor_dim = x.size(3);
+ p.kernel_h = k.size(0);
+ p.kernel_w = k.size(1);
+ p.up_x = up_x;
+ p.up_y = up_y;
+ p.down_x = down_x;
+ p.down_y = down_y;
+ p.pad_x0 = pad_x0;
+ p.pad_x1 = pad_x1;
+ p.pad_y0 = pad_y0;
+ p.pad_y1 = pad_y1;
+
+ p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) / p.down_y;
+ p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) / p.down_x;
+
+ auto out = at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
+
+ int mode = -1;
+
+ int tile_out_h;
+ int tile_out_w;
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 1;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 3 && p.kernel_w <= 3) {
+ mode = 2;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 3;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 4;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 5;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 6;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ dim3 block_size;
+ dim3 grid_size;
+
+ if (tile_out_h > 0 && tile_out_w) {
+ p.loop_major = (p.major_dim - 1) / 16384 + 1;
+ p.loop_x = 1;
+ block_size = dim3(32 * 8, 1, 1);
+ grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
+ (p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
+ (p.major_dim - 1) / p.loop_major + 1);
+ }
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
+ switch (mode) {
+ case 1:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 2:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 3:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 4:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 5:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 6:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+ }
+ });
+
+ return out;
+}
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/ranger.py b/models/FeatureStyleEncoder/ranger.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d63264dda6df0ee40cac143440f0b5f8977a9ad
--- /dev/null
+++ b/models/FeatureStyleEncoder/ranger.py
@@ -0,0 +1,164 @@
+# Ranger deep learning optimizer - RAdam + Lookahead + Gradient Centralization, combined into one optimizer.
+
+# https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
+# and/or
+# https://github.com/lessw2020/Best-Deep-Learning-Optimizers
+
+# Ranger has now been used to capture 12 records on the FastAI leaderboard.
+
+# This version = 20.4.11
+
+# Credits:
+# Gradient Centralization --> https://arxiv.org/abs/2004.01461v2 (a new optimization technique for DNNs), github: https://github.com/Yonghongwei/Gradient-Centralization
+# RAdam --> https://github.com/LiyuanLucasLiu/RAdam
+# Lookahead --> rewritten by lessw2020, but big thanks to Github @LonePatient and @RWightman for ideas from their code.
+# Lookahead paper --> MZhang,G Hinton https://arxiv.org/abs/1907.08610
+
+# summary of changes:
+# 4/11/20 - add gradient centralization option. Set new testing benchmark for accuracy with it, toggle with use_gc flag at init.
+# full code integration with all updates at param level instead of group, moves slow weights into state dict (from generic weights),
+# supports group learning rates (thanks @SHolderbach), fixes sporadic load from saved model issues.
+# changes 8/31/19 - fix references to *self*.N_sma_threshold;
+# changed eps to 1e-5 as better default than 1e-8.
+
+import math
+import torch
+from torch.optim.optimizer import Optimizer
+
+
+class Ranger(Optimizer):
+
+ def __init__(self, params, lr=1e-3, # lr
+ alpha=0.5, k=6, N_sma_threshhold=5, # Ranger options
+ betas=(.95, 0.999), eps=1e-5, weight_decay=0, # Adam options
+ use_gc=True, gc_conv_only=False
+ # Gradient centralization on or off, applied to conv layers only or conv + fc layers
+ ):
+
+ # parameter checks
+ if not 0.0 <= alpha <= 1.0:
+ raise ValueError(f'Invalid slow update rate: {alpha}')
+ if not 1 <= k:
+ raise ValueError(f'Invalid lookahead steps: {k}')
+ if not lr > 0:
+ raise ValueError(f'Invalid Learning Rate: {lr}')
+ if not eps > 0:
+ raise ValueError(f'Invalid eps: {eps}')
+
+ # parameter comments:
+ # beta1 (momentum) of .95 seems to work better than .90...
+ # N_sma_threshold of 5 seems better in testing than 4.
+ # In both cases, worth testing on your dataset (.90 vs .95, 4 vs 5) to make sure which works best for you.
+
+ # prep defaults and init torch.optim base
+ defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas, N_sma_threshhold=N_sma_threshhold,
+ eps=eps, weight_decay=weight_decay)
+ super().__init__(params, defaults)
+
+ # adjustable threshold
+ self.N_sma_threshhold = N_sma_threshhold
+
+ # look ahead params
+
+ self.alpha = alpha
+ self.k = k
+
+ # radam buffer for state
+ self.radam_buffer = [[None, None, None] for ind in range(10)]
+
+ # gc on or off
+ self.use_gc = use_gc
+
+ # level of gradient centralization
+ self.gc_gradient_threshold = 3 if gc_conv_only else 1
+
+ def __setstate__(self, state):
+ super(Ranger, self).__setstate__(state)
+
+ def step(self, closure=None):
+ loss = None
+
+ # Evaluate averages and grad, update param tensors
+ for group in self.param_groups:
+
+ for p in group['params']:
+ if p.grad is None:
+ continue
+ grad = p.grad.data.float()
+
+ if grad.is_sparse:
+ raise RuntimeError('Ranger optimizer does not support sparse gradients')
+
+ p_data_fp32 = p.data.float()
+
+ state = self.state[p] # get state dict for this param
+
+ if len(state) == 0: # if first time to run...init dictionary with our desired entries
+ # if self.first_run_check==0:
+ # self.first_run_check=1
+ # print("Initializing slow buffer...should not see this at load from saved model!")
+ state['step'] = 0
+ state['exp_avg'] = torch.zeros_like(p_data_fp32)
+ state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
+
+ # look ahead weight storage now in state dict
+ state['slow_buffer'] = torch.empty_like(p.data)
+ state['slow_buffer'].copy_(p.data)
+
+ else:
+ state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
+ state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
+
+ # begin computations
+ exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
+ beta1, beta2 = group['betas']
+
+ # GC operation for Conv layers and FC layers
+ if grad.dim() > self.gc_gradient_threshold:
+ grad.add_(-grad.mean(dim=tuple(range(1, grad.dim())), keepdim=True))
+
+ state['step'] += 1
+
+ # compute variance mov avg
+ exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
+ # compute mean moving avg
+ exp_avg.mul_(beta1).add_(1 - beta1, grad)
+
+ buffered = self.radam_buffer[int(state['step'] % 10)]
+
+ if state['step'] == buffered[0]:
+ N_sma, step_size = buffered[1], buffered[2]
+ else:
+ buffered[0] = state['step']
+ beta2_t = beta2 ** state['step']
+ N_sma_max = 2 / (1 - beta2) - 1
+ N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
+ buffered[1] = N_sma
+ if N_sma > self.N_sma_threshhold:
+ step_size = math.sqrt(
+ (1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (
+ N_sma_max - 2)) / (1 - beta1 ** state['step'])
+ else:
+ step_size = 1.0 / (1 - beta1 ** state['step'])
+ buffered[2] = step_size
+
+ if group['weight_decay'] != 0:
+ p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
+
+ # apply lr
+ if N_sma > self.N_sma_threshhold:
+ denom = exp_avg_sq.sqrt().add_(group['eps'])
+ p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
+ else:
+ p_data_fp32.add_(-step_size * group['lr'], exp_avg)
+
+ p.data.copy_(p_data_fp32)
+
+ # integrated look ahead...
+ # we do it at the param level instead of group level
+ if state['step'] % group['k'] == 0:
+ slow_p = state['slow_buffer'] # get access to slow param tensor
+ slow_p.add_(self.alpha, p.data - slow_p) # (fast weights - slow weights) * alpha
+ p.data.copy_(slow_p) # copy interpolated weights to RAdam param tensor
+
+ return loss
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/run_video_inversion_editing.sh b/models/FeatureStyleEncoder/run_video_inversion_editing.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8a221a3b8d44e10b0622bec175818ca8c173b901
--- /dev/null
+++ b/models/FeatureStyleEncoder/run_video_inversion_editing.sh
@@ -0,0 +1,24 @@
+VideoName='FP010363HD03'
+Attribute='Heavy_Makeup'
+Scale='1'
+Sigma='3' # Choose appropriate gaussian filter size
+VideoDir='./data/video/'
+OutputDir='./output/video/'
+
+
+# Cut video to frames
+python video_processing.py --function 'video_to_frames' --video_path ${VideoDir}/${VideoName}.mp4 --output_path ${OutputDir} #--resize
+
+# Crop and align the faces in each frame
+python video_processing.py --function 'align_frames' --video_path ${VideoDir}/${VideoName}.mp4 --output_path ${OutputDir} --filter_size=${Sigma} --optical_flow
+
+# Inversion
+python test.py --config 143 --input_path ${OutputDir}/${VideoName}/${VideoName}_crop_align/ --save_path ${OutputDir}/${VideoName}/${VideoName}_inversion/
+
+# Achieve latent manipulation
+python video_processing.py --function 'latent_manipulation' --video_path ${VideoDir}/${VideoName}.mp4 --attr ${Attribute} --alpha=${Scale}
+
+# Reproject the manipulated frames to the original video
+python video_processing.py --function 'reproject_origin' --video_path ${VideoDir}/${VideoName}.mp4 --seamless
+python video_processing.py --function 'reproject_manipulate' --video_path ${VideoDir}/${VideoName}.mp4 --attr ${Attribute} --seamless
+python video_processing.py --function 'compare_frames' --video_path ${VideoDir}/${VideoName}.mp4 --attr ${Attribute} --strs 'Original,Projected,Manipulated'
diff --git a/models/FeatureStyleEncoder/test.py b/models/FeatureStyleEncoder/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..618bb00474c297b47700906755d26dec46b395d2
--- /dev/null
+++ b/models/FeatureStyleEncoder/test.py
@@ -0,0 +1,78 @@
+import argparse
+import glob
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+import yaml
+
+from PIL import Image
+from tqdm import tqdm
+from torchvision import transforms, utils
+
+from utils.datasets import *
+from utils.functions import *
+from trainer import *
+
+torch.backends.cudnn.enabled = True
+torch.backends.cudnn.deterministic = True
+torch.backends.cudnn.benchmark = True
+torch.autograd.set_detect_anomaly(True)
+Image.MAX_IMAGE_PIXELS = None
+device = torch.device('cuda')
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--config', type=str, default='001', help='Path to the config file.')
+parser.add_argument('--pretrained_model_path', type=str, default='./pretrained_models/143_enc.pth', help='pretrained stylegan2 model')
+parser.add_argument('--stylegan_model_path', type=str, default='./pixel2style2pixel/pretrained_models/psp_ffhq_encode.pt', help='pretrained stylegan2 model')
+parser.add_argument('--arcface_model_path', type=str, default='./pretrained_models/backbone.pth', help='pretrained ArcFace model')
+parser.add_argument('--parsing_model_path', type=str, default='./pretrained_models/79999_iter.pth', help='pretrained parsing model')
+parser.add_argument('--log_path', type=str, default='./logs/', help='log file path')
+parser.add_argument('--resume', action='store_true', help='resume from checkpoint')
+parser.add_argument('--checkpoint', type=str, default='', help='checkpoint file path')
+parser.add_argument('--checkpoint_noiser', type=str, default='', help='checkpoint file path')
+parser.add_argument('--multigpu', type=bool, default=False, help='use multiple gpus')
+parser.add_argument('--input_path', type=str, default='./test/', help='evaluation data file path')
+parser.add_argument('--save_path', type=str, default='./output/image/', help='output data save path')
+
+opts = parser.parse_args()
+
+log_dir = os.path.join(opts.log_path, opts.config) + '/'
+config = yaml.load(open('./configs/' + opts.config + '.yaml', 'r'), Loader=yaml.FullLoader)
+
+# Initialize trainer
+trainer = Trainer(config, opts)
+trainer.initialize(opts.stylegan_model_path, opts.arcface_model_path, opts.parsing_model_path)
+trainer.to(device)
+
+state_dict = torch.load(opts.pretrained_model_path)#os.path.join(opts.log_path, opts.config + '/checkpoint.pth'))
+trainer.enc.load_state_dict(torch.load(opts.pretrained_model_path))
+trainer.enc.eval()
+
+img_to_tensor = transforms.Compose([
+ transforms.Resize((1024, 1024)),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+])
+
+# simple inference
+image_dir = opts.input_path
+save_dir = opts.save_path
+os.makedirs(save_dir, exist_ok=True)
+
+with torch.no_grad():
+ img_list = [glob.glob1(image_dir, ext) for ext in ['*jpg','*png']]
+ img_list = [item for sublist in img_list for item in sublist]
+ img_list.sort()
+ for i, img_name in enumerate(img_list):
+ #print(i, img_name)
+ image_A = img_to_tensor(Image.open(image_dir + img_name)).unsqueeze(0).to(device)
+ output = trainer.test(img=image_A, return_latent=True)
+ feature = output.pop()
+ latent = output.pop()
+ #np.save(save_dir + 'latent_code_%d.npy'%i, latent.cpu().numpy())
+ utils.save_image(clip_img(output[1]), save_dir + img_name)
+ if i > 1000:
+ break
diff --git a/models/FeatureStyleEncoder/train.py b/models/FeatureStyleEncoder/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba582aca6615a981e8b0a6b1a51bf4f3c0a3f913
--- /dev/null
+++ b/models/FeatureStyleEncoder/train.py
@@ -0,0 +1,149 @@
+import argparse
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+import yaml
+
+from PIL import Image
+from tqdm import tqdm
+from torchvision import transforms, utils
+from tensorboard_logger import Logger
+
+from utils.datasets import *
+from utils.functions import *
+from trainer import *
+
+torch.backends.cudnn.enabled = True
+torch.backends.cudnn.deterministic = True
+torch.backends.cudnn.benchmark = True
+torch.autograd.set_detect_anomaly(True)
+Image.MAX_IMAGE_PIXELS = None
+device = torch.device('cuda')
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--config', type=str, default='001', help='Path to the config file.')
+parser.add_argument('--real_dataset_path', type=str, default='./data/ffhq-dataset/images/', help='dataset path')
+parser.add_argument('--dataset_path', type=str, default='./data/stylegan2-generate-images/ims/', help='dataset path')
+parser.add_argument('--label_path', type=str, default='./data/stylegan2-generate-images/seeds_pytorch_1.8.1.npy', help='laebl path')
+parser.add_argument('--stylegan_model_path', type=str, default='./pixel2style2pixel/pretrained_models/psp_ffhq_encode.pt', help='pretrained stylegan2 model')
+parser.add_argument('--arcface_model_path', type=str, default='./pretrained_models/backbone.pth', help='pretrained ArcFace model')
+parser.add_argument('--parsing_model_path', type=str, default='./pretrained_models/79999_iter.pth', help='pretrained parsing model')
+parser.add_argument('--log_path', type=str, default='./logs/', help='log file path')
+parser.add_argument('--resume', action='store_true', help='resume from checkpoint')
+parser.add_argument('--checkpoint', type=str, default='', help='checkpoint file path')
+opts = parser.parse_args()
+
+log_dir = os.path.join(opts.log_path, opts.config) + '/'
+os.makedirs(log_dir, exist_ok=True)
+logger = Logger(log_dir)
+
+config = yaml.load(open('./configs/' + opts.config + '.yaml', 'r'), Loader=yaml.FullLoader)
+
+batch_size = config['batch_size']
+epochs = config['epochs']
+iter_per_epoch = config['iter_per_epoch']
+img_size = (config['resolution'], config['resolution'])
+video_data_input = False
+
+
+img_to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+])
+img_to_tensor_car = transforms.Compose([
+ transforms.Resize((384, 512)),
+ transforms.Pad(padding=(0, 64, 0, 64)),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+])
+
+# Initialize trainer
+trainer = Trainer(config, opts)
+trainer.initialize(opts.stylegan_model_path, opts.arcface_model_path, opts.parsing_model_path)
+trainer.to(device)
+
+noise_exemple = trainer.noise_inputs
+train_data_split = 0.9 if 'train_split' not in config else config['train_split']
+
+# Load synthetic dataset
+dataset_A = MyDataSet(image_dir=opts.dataset_path, label_dir=opts.label_path, output_size=img_size, noise_in=noise_exemple, training_set=True, train_split=train_data_split)
+loader_A = data.DataLoader(dataset_A, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
+# Load real dataset
+dataset_B = MyDataSet(image_dir=opts.real_dataset_path, label_dir=None, output_size=img_size, noise_in=noise_exemple, training_set=True, train_split=train_data_split)
+loader_B = data.DataLoader(dataset_B, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
+
+# Start Training
+epoch_0 = 0
+
+# check if checkpoint exist
+if 'checkpoint.pth' in os.listdir(log_dir):
+ epoch_0 = trainer.load_checkpoint(os.path.join(log_dir, 'checkpoint.pth'))
+
+if opts.resume:
+ epoch_0 = trainer.load_checkpoint(os.path.join(opts.log_path, opts.checkpoint))
+
+torch.manual_seed(0)
+os.makedirs(log_dir + 'validation/', exist_ok=True)
+
+print("Start!")
+
+for n_epoch in tqdm(range(epoch_0, epochs)):
+
+ iter_A = iter(loader_A)
+ iter_B = iter(loader_B)
+ iter_0 = n_epoch*iter_per_epoch
+
+ trainer.enc_opt.zero_grad()
+
+ for n_iter in range(iter_0, iter_0 + iter_per_epoch):
+
+ if opts.dataset_path is None:
+ z, noise = next(iter_A)
+ img_A = None
+ else:
+ z, img_A, noise = next(iter_A)
+ img_A = img_A.to(device)
+
+ z = z.to(device)
+ noise = [ee.to(device) for ee in noise]
+ w = trainer.mapping(z)
+ if 'fixed_noise' in config and config['fixed_noise']:
+ img_A, noise = None, None
+
+ img_B = None
+ if 'use_realimg' in config and config['use_realimg']:
+ try:
+ img_B = next(iter_B)
+ if img_B.size(0) != batch_size:
+ iter_B = iter(loader_B)
+ img_B = next(iter_B)
+ except StopIteration:
+ iter_B = iter(loader_B)
+ img_B = next(iter_B)
+ img_B = img_B.to(device)
+
+ trainer.update(w=w, img=img_A, noise=noise, real_img=img_B, n_iter=n_iter)
+ if (n_iter+1) % config['log_iter'] == 0:
+ trainer.log_loss(logger, n_iter, prefix='scripts')
+ if (n_iter+1) % config['image_save_iter'] == 0:
+ trainer.save_image(log_dir, n_epoch, n_iter, prefix='/scripts/', w=w, img=img_A, noise=noise)
+ trainer.save_image(log_dir, n_epoch, n_iter+1, prefix='/scripts/', w=w, img=img_B, noise=noise, training_mode=False)
+
+ trainer.enc_scheduler.step()
+ trainer.save_checkpoint(n_epoch, log_dir)
+
+ # Test the model on celeba hq dataset
+ with torch.no_grad():
+ trainer.enc.eval()
+ for i in range(10):
+ image_A = img_to_tensor(Image.open('./data/celeba_hq/%d.jpg' % i)).unsqueeze(0).to(device)
+ output = trainer.test(img=image_A)
+ out_img = torch.cat(output, 3)
+ utils.save_image(clip_img(out_img[:1]), log_dir + 'validation/' + 'epoch_' +str(n_epoch+1) + '_' + str(i) + '.jpg')
+ trainer.compute_loss(w=w, img=img_A, noise=noise, real_img=img_B)
+ trainer.log_loss(logger, n_iter, prefix='validation')
+
+trainer.save_model(log_dir)
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/trainer.py b/models/FeatureStyleEncoder/trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69cacf142a968a5be010c5ca4286c7348c3a2c4
--- /dev/null
+++ b/models/FeatureStyleEncoder/trainer.py
@@ -0,0 +1,431 @@
+import sys
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+
+from PIL import Image
+from torch.autograd import grad
+from torchvision import transforms, utils
+
+import face_alignment
+import lpips
+
+current_dir = os.path.abspath(os.path.dirname(__file__))
+sys.path.insert(0, current_dir)
+from pixel2style2pixel.models.stylegan2.model import Generator, get_keys
+
+from nets.feature_style_encoder import *
+from arcface.iresnet import *
+from face_parsing.model import BiSeNet
+from ranger import Ranger
+
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+
+from PIL import Image
+from torch.autograd import grad
+
+
+def clip_img(x):
+ """Clip stylegan generated image to range(0,1)"""
+ img_tmp = x.clone()[0]
+ img_tmp = (img_tmp + 1) / 2
+ img_tmp = torch.clamp(img_tmp, 0, 1)
+ return [img_tmp.detach().cpu()]
+
+def tensor_byte(x):
+ return x.element_size()*x.nelement()
+
+def count_parameters(net):
+ s = sum([np.prod(list(mm.size())) for mm in net.parameters()])
+ print(s)
+
+def stylegan_to_classifier(x, out_size=(224, 224)):
+ """Clip image to range(0,1)"""
+ img_tmp = x.clone()
+ img_tmp = torch.clamp((0.5*img_tmp + 0.5), 0, 1)
+ img_tmp = F.interpolate(img_tmp, size=out_size, mode='bilinear')
+ img_tmp[:,0] = (img_tmp[:,0] - 0.485)/0.229
+ img_tmp[:,1] = (img_tmp[:,1] - 0.456)/0.224
+ img_tmp[:,2] = (img_tmp[:,2] - 0.406)/0.225
+ #img_tmp = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])(img_tmp)
+ return img_tmp
+
+def downscale(x, scale_times=1, mode='bilinear'):
+ for i in range(scale_times):
+ x = F.interpolate(x, scale_factor=0.5, mode=mode)
+ return x
+
+def upscale(x, scale_times=1, mode='bilinear'):
+ for i in range(scale_times):
+ x = F.interpolate(x, scale_factor=2, mode=mode)
+ return x
+
+def hist_transform(source_tensor, target_tensor):
+ """Histogram transformation"""
+ c, h, w = source_tensor.size()
+ s_t = source_tensor.view(c, -1)
+ t_t = target_tensor.view(c, -1)
+ s_t_sorted, s_t_indices = torch.sort(s_t)
+ t_t_sorted, t_t_indices = torch.sort(t_t)
+ for i in range(c):
+ s_t[i, s_t_indices[i]] = t_t_sorted[i]
+ return s_t.view(c, h, w)
+
+def init_weights(m):
+ """Initialize layers with Xavier uniform distribution"""
+ if type(m) == nn.Conv2d:
+ nn.init.xavier_uniform_(m.weight)
+ elif type(m) == nn.Linear:
+ nn.init.uniform_(m.weight, 0.0, 1.0)
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0.01)
+
+def total_variation(x, delta=1):
+ """Total variation, x: tensor of size (B, C, H, W)"""
+ out = torch.mean(torch.abs(x[:, :, :, :-delta] - x[:, :, :, delta:]))\
+ + torch.mean(torch.abs(x[:, :, :-delta, :] - x[:, :, delta:, :]))
+ return out
+
+def vgg_transform(x):
+ """Adapt image for vgg network, x: image of range(0,1) subtracting ImageNet mean"""
+ r, g, b = torch.split(x, 1, 1)
+ out = torch.cat((b, g, r), dim = 1)
+ out = F.interpolate(out, size=(224, 224), mode='bilinear')
+ out = out*255.
+ return out
+
+# warp image with flow
+def normalize_axis(x,L):
+ return (x-1-(L-1)/2)*2/(L-1)
+
+def unnormalize_axis(x,L):
+ return x*(L-1)/2+1+(L-1)/2
+
+def torch_flow_to_th_sampling_grid(flow,h_src,w_src,use_cuda=False):
+ b,c,h_tgt,w_tgt=flow.size()
+ grid_y, grid_x = torch.meshgrid(torch.tensor(range(1,w_tgt+1)),torch.tensor(range(1,h_tgt+1)))
+ disp_x=flow[:,0,:,:]
+ disp_y=flow[:,1,:,:]
+ source_x=grid_x.unsqueeze(0).repeat(b,1,1).type_as(flow)+disp_x
+ source_y=grid_y.unsqueeze(0).repeat(b,1,1).type_as(flow)+disp_y
+ source_x_norm=normalize_axis(source_x,w_src)
+ source_y_norm=normalize_axis(source_y,h_src)
+ sampling_grid=torch.cat((source_x_norm.unsqueeze(3), source_y_norm.unsqueeze(3)), dim=3)
+ if use_cuda:
+ sampling_grid = sampling_grid.cuda()
+ return sampling_grid
+
+def warp_image_torch(image, flow):
+ """
+ Warp image (tensor, shape=[b, 3, h_src, w_src]) with flow (tensor, shape=[b, h_tgt, w_tgt, 2])
+ """
+ b,c,h_src,w_src=image.size()
+ sampling_grid_torch = torch_flow_to_th_sampling_grid(flow, h_src, w_src)
+ warped_image_torch = F.grid_sample(image, sampling_grid_torch)
+ return warped_image_torch
+
+class Trainer(nn.Module):
+ def __init__(self, config, opts):
+ super(Trainer, self).__init__()
+ # Load Hyperparameters
+ self.config = config
+ self.device = torch.device(self.config['device'])
+ self.scale = int(np.log2(config['resolution']/config['enc_resolution']))
+ self.scale_mode = 'bilinear'
+ self.opts = opts
+ self.n_styles = 2 * int(np.log2(config['resolution'])) - 2
+ self.idx_k = 5
+ if 'idx_k' in self.config:
+ self.idx_k = self.config['idx_k']
+ if 'stylegan_version' in self.config and self.config['stylegan_version'] == 3:
+ self.n_styles = 16
+ # Networks
+ in_channels = 256
+ if 'in_c' in self.config:
+ in_channels = config['in_c']
+ enc_residual = False
+ if 'enc_residual' in self.config:
+ enc_residual = self.config['enc_residual']
+ enc_residual_coeff = False
+ if 'enc_residual_coeff' in self.config:
+ enc_residual_coeff = self.config['enc_residual_coeff']
+ resnet_layers = [4,5,6]
+ if 'enc_start_layer' in self.config:
+ st_l = self.config['enc_start_layer']
+ resnet_layers = [st_l, st_l+1, st_l+2]
+ if 'scale_mode' in self.config:
+ self.scale_mode = self.config['scale_mode']
+ # Load encoder
+ self.stride = (self.config['fs_stride'], self.config['fs_stride'])
+ self.enc = fs_encoder_v2(n_styles=self.n_styles, opts=opts, residual=enc_residual, use_coeff=enc_residual_coeff, resnet_layer=resnet_layers, stride=self.stride)
+
+ ##########################
+ # Other nets
+ self.StyleGAN = self.init_stylegan(config)
+ self.Arcface = iresnet50()
+ self.parsing_net = BiSeNet(n_classes=19)
+ # Optimizers
+ # Latent encoder
+ self.enc_params = list(self.enc.parameters())
+ if 'freeze_iresnet' in self.config and self.config['freeze_iresnet']:
+ self.enc_params = list(self.enc.styles.parameters())
+ if 'optimizer' in self.config and self.config['optimizer'] == 'ranger':
+ self.enc_opt = Ranger(self.enc_params, lr=config['lr'], betas=(config['beta_1'], config['beta_2']), weight_decay=config['weight_decay'])
+ else:
+ self.enc_opt = torch.optim.Adam(self.enc_params, lr=config['lr'], betas=(config['beta_1'], config['beta_2']), weight_decay=config['weight_decay'])
+ self.enc_scheduler = torch.optim.lr_scheduler.StepLR(self.enc_opt, step_size=config['step_size'], gamma=config['gamma'])
+
+ self.fea_avg = None
+
+ def initialize(self, stylegan_model_path, arcface_model_path, parsing_model_path):
+ # load StyleGAN model
+ stylegan_state_dict = torch.load(stylegan_model_path, map_location='cpu')
+ self.StyleGAN.load_state_dict(get_keys(stylegan_state_dict, 'decoder'), strict=True)
+ self.StyleGAN.to(self.device)
+ # get StyleGAN average latent in w space and the noise inputs
+ self.dlatent_avg = stylegan_state_dict['latent_avg'].to(self.device)
+ self.noise_inputs = [getattr(self.StyleGAN.noises, f'noise_{i}').to(self.device) for i in range(self.StyleGAN.num_layers)]
+ # load Arcface weight
+ self.Arcface.load_state_dict(torch.load(self.opts.arcface_model_path))
+ self.Arcface.eval()
+ # load face parsing net weight
+ self.parsing_net.load_state_dict(torch.load(self.opts.parsing_model_path))
+ self.parsing_net.eval()
+ # load lpips net weight
+ # self.loss_fn = lpips.LPIPS(net='alex', spatial=False)
+ # self.loss_fn.to(self.device)
+
+ def init_stylegan(self, config):
+ """StyleGAN = G_main(
+ truncation_psi=config['truncation_psi'],
+ resolution=config['resolution'],
+ use_noise=config['use_noise'],
+ randomize_noise=config['randomize_noise']
+ )"""
+ StyleGAN = Generator(1024, 512, 8)
+ return StyleGAN
+
+ def mapping(self, z):
+ return self.StyleGAN.get_latent(z).detach()
+
+ def L1loss(self, input, target):
+ return nn.L1Loss()(input,target)
+
+ def L2loss(self, input, target):
+ return nn.MSELoss()(input,target)
+
+ def CEloss(self, x, target_age):
+ return nn.CrossEntropyLoss()(x, target_age)
+
+ def LPIPS(self, input, target, multi_scale=False):
+ if multi_scale:
+ out = 0
+ for k in range(3):
+ out += self.loss_fn.forward(downscale(input, k, self.scale_mode), downscale(target, k, self.scale_mode)).mean()
+ else:
+ out = self.loss_fn.forward(downscale(input, self.scale, self.scale_mode), downscale(target, self.scale, self.scale_mode)).mean()
+ return out
+
+ def IDloss(self, input, target):
+ x_1 = F.interpolate(input, (112,112))
+ x_2 = F.interpolate(target, (112,112))
+ cos = nn.CosineSimilarity(dim=1, eps=1e-6)
+ if 'multi_layer_idloss' in self.config and self.config['multi_layer_idloss']:
+ id_1 = self.Arcface(x_1, return_features=True)
+ id_2 = self.Arcface(x_2, return_features=True)
+ return sum([1 - cos(id_1[i].flatten(start_dim=1), id_2[i].flatten(start_dim=1)) for i in range(len(id_1))])
+ else:
+ id_1 = self.Arcface(x_1)
+ id_2 = self.Arcface(x_2)
+ return 1 - cos(id_1, id_2)
+
+ def landmarkloss(self, input, target):
+ cos = nn.CosineSimilarity(dim=1, eps=1e-6)
+ x_1 = stylegan_to_classifier(input, out_size=(512, 512))
+ x_2 = stylegan_to_classifier(target, out_size=(512,512))
+ out_1 = self.parsing_net(x_1)
+ out_2 = self.parsing_net(x_2)
+ parsing_loss = sum([1 - cos(out_1[i].flatten(start_dim=1), out_2[i].flatten(start_dim=1)) for i in range(len(out_1))])
+ return parsing_loss.mean()
+
+
+ def feature_match(self, enc_feat, dec_feat, layer_idx=None):
+ loss = []
+ if layer_idx is None:
+ layer_idx = [i for i in range(len(enc_feat))]
+ for i in layer_idx:
+ loss.append(self.L1loss(enc_feat[i], dec_feat[i]))
+ return loss
+
+ def encode(self, img):
+ w_recon, fea = self.enc(downscale(img, self.scale, self.scale_mode))
+ w_recon = w_recon + self.dlatent_avg
+ return w_recon, fea
+
+ def get_image(self, w=None, img=None, noise=None, zero_noise_input=True, training_mode=True):
+
+ x_1, n_1 = img, noise
+ if x_1 is None:
+ x_1, _ = self.StyleGAN([w], input_is_latent=True, noise = n_1)
+
+ w_delta = None
+ fea = None
+ features = None
+ return_features = False
+ # Reconstruction
+ k = 0
+ if 'use_fs_encoder' in self.config and self.config['use_fs_encoder']:
+ return_features = True
+ k = self.idx_k
+ w_recon, fea = self.enc(downscale(x_1, self.scale, self.scale_mode))
+ w_recon = w_recon + self.dlatent_avg
+ features = [None]*k + [fea] + [None]*(17-k)
+ else:
+ w_recon = self.enc(downscale(x_1, self.scale, self.scale_mode)) + self.dlatent_avg
+
+ # generate image
+ x_1_recon, fea_recon = self.StyleGAN([w_recon], input_is_latent=True, return_features=True, features_in=features, feature_scale=min(1.0, 0.0001*self.n_iter))
+ fea_recon = fea_recon[k].detach()
+ return [x_1_recon, x_1[:,:3,:,:], w_recon, w_delta, n_1, fea, fea_recon]
+
+ def compute_loss(self, w=None, img=None, noise=None, real_img=None):
+ return self.compute_loss_stylegan2(w=w, img=img, noise=noise, real_img=real_img)
+
+ def compute_loss_stylegan2(self, w=None, img=None, noise=None, real_img=None):
+
+ if img is None:
+ # generate synthetic images
+ if noise is None:
+ noise = [torch.randn(w.size()[:1] + ee.size()[1:]).to(self.device) for ee in self.noise_inputs]
+ img, _ = self.StyleGAN([w], input_is_latent=True, noise = noise)
+ img = img.detach()
+
+ if img is not None and real_img is not None:
+ # concat synthetic and real data
+ img = torch.cat([img, real_img], dim=0)
+ noise = [torch.cat([ee, ee], dim=0) for ee in noise]
+
+ out = self.get_image(w=w, img=img, noise=noise)
+ x_1_recon, x_1, w_recon, w_delta, n_1, fea_1, fea_recon = out
+
+ # Loss setting
+ w_l2, w_lpips, w_id = self.config['w']['l2'], self.config['w']['lpips'], self.config['w']['id']
+ b = x_1.size(0)//2
+ if 'l2loss_on_real_image' in self.config and self.config['l2loss_on_real_image']:
+ b = x_1.size(0)
+ self.l2_loss = self.L2loss(x_1_recon[:b], x_1[:b]) if w_l2 > 0 else torch.tensor(0) # l2 loss only on synthetic data
+ # LPIPS
+ multiscale_lpips=False if 'multiscale_lpips' not in self.config else self.config['multiscale_lpips']
+ self.lpips_loss = self.LPIPS(x_1_recon, x_1, multi_scale=multiscale_lpips).mean() if w_lpips > 0 else torch.tensor(0)
+ self.id_loss = self.IDloss(x_1_recon, x_1).mean() if w_id > 0 else torch.tensor(0)
+ self.landmark_loss = self.landmarkloss(x_1_recon, x_1) if self.config['w']['landmark'] > 0 else torch.tensor(0)
+
+ if 'use_fs_encoder' in self.config and self.config['use_fs_encoder']:
+ k = self.idx_k
+ features = [None]*k + [fea_1] + [None]*(17-k)
+ x_1_recon_2, _ = self.StyleGAN([w_recon], noise=n_1, input_is_latent=True, features_in=features, feature_scale=min(1.0, 0.0001*self.n_iter))
+ self.lpips_loss += self.LPIPS(x_1_recon_2, x_1, multi_scale=multiscale_lpips).mean() if w_lpips > 0 else torch.tensor(0)
+ self.id_loss += self.IDloss(x_1_recon_2, x_1).mean() if w_id > 0 else torch.tensor(0)
+ self.landmark_loss += self.landmarkloss(x_1_recon_2, x_1) if self.config['w']['landmark'] > 0 else torch.tensor(0)
+
+ # downscale image
+ x_1 = downscale(x_1, self.scale, self.scale_mode)
+ x_1_recon = downscale(x_1_recon, self.scale, self.scale_mode)
+
+ # Total loss
+ w_l2, w_lpips, w_id = self.config['w']['l2'], self.config['w']['lpips'], self.config['w']['id']
+ self.loss = w_l2*self.l2_loss + w_lpips*self.lpips_loss + w_id*self.id_loss
+
+ if 'f_recon' in self.config['w']:
+ self.feature_recon_loss = self.L2loss(fea_1, fea_recon)
+ self.loss += self.config['w']['f_recon']*self.feature_recon_loss
+ if 'l1' in self.config['w'] and self.config['w']['l1']>0:
+ self.l1_loss = self.L1loss(x_1_recon, x_1)
+ self.loss += self.config['w']['l1']*self.l1_loss
+ if 'landmark' in self.config['w']:
+ self.loss += self.config['w']['landmark']*self.landmark_loss
+ return self.loss
+
+ def test(self, w=None, img=None, noise=None, zero_noise_input=True, return_latent=False, training_mode=False):
+ if 'n_iter' not in self.__dict__.keys():
+ self.n_iter = 1e5
+ out = self.get_image(w=w, img=img, noise=noise, training_mode=training_mode)
+ x_1_recon, x_1, w_recon, w_delta, n_1, fea_1 = out[:6]
+ output = [x_1, x_1_recon]
+ if return_latent:
+ output += [w_recon, fea_1]
+ return output
+
+ def log_loss(self, logger, n_iter, prefix='scripts'):
+ logger.log_value(prefix + '/l2_loss', self.l2_loss.item(), n_iter + 1)
+ logger.log_value(prefix + '/lpips_loss', self.lpips_loss.item(), n_iter + 1)
+ logger.log_value(prefix + '/id_loss', self.id_loss.item(), n_iter + 1)
+ logger.log_value(prefix + '/total_loss', self.loss.item(), n_iter + 1)
+ if 'f_recon' in self.config['w']:
+ logger.log_value(prefix + '/feature_recon_loss', self.feature_recon_loss.item(), n_iter + 1)
+ if 'l1' in self.config['w'] and self.config['w']['l1']>0:
+ logger.log_value(prefix + '/l1_loss', self.l1_loss.item(), n_iter + 1)
+ if 'landmark' in self.config['w']:
+ logger.log_value(prefix + '/landmark_loss', self.landmark_loss.item(), n_iter + 1)
+
+ def save_image(self, log_dir, n_epoch, n_iter, prefix='/scripts/', w=None, img=None, noise=None, training_mode=True):
+ return self.save_image_stylegan2(log_dir=log_dir, n_epoch=n_epoch, n_iter=n_iter, prefix=prefix, w=w, img=img, noise=noise, training_mode=training_mode)
+
+ def save_image_stylegan2(self, log_dir, n_epoch, n_iter, prefix='/scripts/', w=None, img=None, noise=None, training_mode=True):
+ os.makedirs(log_dir + prefix, exist_ok=True)
+ with torch.no_grad():
+ out = self.get_image(w=w, img=img, noise=noise, training_mode=training_mode)
+ x_1_recon, x_1, w_recon, w_delta, n_1, fea_1 = out[:6]
+ x_1 = downscale(x_1, self.scale, self.scale_mode)
+ x_1_recon = downscale(x_1_recon, self.scale, self.scale_mode)
+ out_img = torch.cat((x_1, x_1_recon), dim=3)
+ #fs
+ if 'use_fs_encoder' in self.config and self.config['use_fs_encoder']:
+ k = self.idx_k
+ features = [None]*k + [fea_1] + [None]*(17-k)
+ x_1_recon_2, _ = self.StyleGAN([w_recon], noise=n_1, input_is_latent=True, features_in=features, feature_scale=min(1.0, 0.0001*self.n_iter))
+ x_1_recon_2 = downscale(x_1_recon_2, self.scale, self.scale_mode)
+ out_img = torch.cat((x_1, x_1_recon, x_1_recon_2), dim=3)
+ utils.save_image(clip_img(out_img[:1]), log_dir + prefix + 'epoch_' +str(n_epoch+1) + '_iter_' + str(n_iter+1) + '_0.jpg')
+ if out_img.size(0)>1:
+ utils.save_image(clip_img(out_img[1:]), log_dir + prefix + 'epoch_' +str(n_epoch+1) + '_iter_' + str(n_iter+1) + '_1.jpg')
+
+ def save_model(self, log_dir):
+ torch.save(self.enc.state_dict(),'{:s}/enc.pth.tar'.format(log_dir))
+
+ def save_checkpoint(self, n_epoch, log_dir):
+ checkpoint_state = {
+ 'n_epoch': n_epoch,
+ 'enc_state_dict': self.enc.state_dict(),
+ 'enc_opt_state_dict': self.enc_opt.state_dict(),
+ 'enc_scheduler_state_dict': self.enc_scheduler.state_dict()
+ }
+ torch.save(checkpoint_state, '{:s}/checkpoint.pth'.format(log_dir))
+ if (n_epoch+1)%10 == 0 :
+ torch.save(checkpoint_state, '{:s}/checkpoint'.format(log_dir)+'_'+str(n_epoch+1)+'.pth')
+
+ def load_model(self, log_dir):
+ self.enc.load_state_dict(torch.load('{:s}/enc.pth.tar'.format(log_dir)))
+
+ def load_checkpoint(self, checkpoint_path):
+ state_dict = torch.load(checkpoint_path)
+ self.enc.load_state_dict(state_dict['enc_state_dict'])
+ self.enc_opt.load_state_dict(state_dict['enc_opt_state_dict'])
+ self.enc_scheduler.load_state_dict(state_dict['enc_scheduler_state_dict'])
+ return state_dict['n_epoch'] + 1
+
+ def update(self, w=None, img=None, noise=None, real_img=None, n_iter=0):
+ self.n_iter = n_iter
+ self.enc_opt.zero_grad()
+ self.compute_loss(w=w, img=img, noise=noise, real_img=real_img).backward()
+ self.enc_opt.step()
+
+
diff --git a/models/FeatureStyleEncoder/utils/.DS_Store b/models/FeatureStyleEncoder/utils/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..f9853bccefe6d4cf619b94db2b287e29ebd0dc06
Binary files /dev/null and b/models/FeatureStyleEncoder/utils/.DS_Store differ
diff --git a/models/FeatureStyleEncoder/utils/datasets.py b/models/FeatureStyleEncoder/utils/datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1cbb377efe9eea031123431ff31f1c6a7aab497
--- /dev/null
+++ b/models/FeatureStyleEncoder/utils/datasets.py
@@ -0,0 +1,158 @@
+import os
+import glob
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+
+from PIL import Image
+from torchvision import transforms, utils
+
+class MyDataSet(data.Dataset):
+ def __init__(self, image_dir=None, label_dir=None, output_size=(256, 256), noise_in=None, training_set=True, video_data=False, train_split=0.9):
+ self.image_dir = image_dir
+ self.normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+ self.resize = transforms.Compose([
+ transforms.Resize(output_size),
+ transforms.ToTensor()
+ ])
+ self.noise_in = noise_in
+ self.video_data = video_data
+ self.random_rotation = transforms.Compose([
+ transforms.Resize(output_size),
+ transforms.RandomPerspective(distortion_scale=0.05, p=1.0),
+ transforms.ToTensor()
+ ])
+
+ # load image file
+ train_len = None
+ self.length = 0
+ self.image_dir = image_dir
+ if image_dir is not None:
+ img_list = [glob.glob1(self.image_dir, ext) for ext in ['*jpg','*png']]
+ image_list = [item for sublist in img_list for item in sublist]
+ image_list.sort()
+ train_len = int(train_split*len(image_list))
+ if training_set:
+ self.image_list = image_list[:train_len]
+ else:
+ self.image_list = image_list[train_len:]
+ self.length = len(self.image_list)
+
+ # load label file
+ self.label_dir = label_dir
+ if label_dir is not None:
+ self.seeds = np.load(label_dir)
+ if train_len is None:
+ train_len = int(train_split*len(self.seeds))
+ if training_set:
+ self.seeds = self.seeds[:train_len]
+ else:
+ self.seeds = self.seeds[train_len:]
+ if self.length == 0:
+ self.length = len(self.seeds)
+
+ def __len__(self):
+ return self.length
+
+ def __getitem__(self, idx):
+ img = None
+ if self.image_dir is not None:
+ img_name = os.path.join(self.image_dir, self.image_list[idx])
+ image = Image.open(img_name)
+ img = self.resize(image)
+ if img.size(0) == 1:
+ img = torch.cat((img, img, img), dim=0)
+ img = self.normalize(img)
+
+ # generate image
+ if self.label_dir is not None:
+ torch.manual_seed(self.seeds[idx])
+ z = torch.randn(1, 512)[0]
+ if self.noise_in is None:
+ n = [torch.randn(1, 1)]
+ else:
+ n = [torch.randn(noise.size())[0] for noise in self.noise_in]
+ if img is None:
+ return z, n
+ else:
+ return z, img, n
+ else:
+ return img
+
+class Car_DataSet(data.Dataset):
+ def __init__(self, image_dir=None, label_dir=None, output_size=(512, 512), noise_in=None, training_set=True, video_data=False, train_split=0.9):
+ self.image_dir = image_dir
+ self.normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+ self.resize = transforms.Compose([
+ transforms.Resize((384, 512)),
+ transforms.Pad(padding=(0, 64, 0, 64)),
+ transforms.ToTensor()
+ ])
+ self.noise_in = noise_in
+ self.video_data = video_data
+ self.random_rotation = transforms.Compose([
+ transforms.Resize(output_size),
+ transforms.RandomPerspective(distortion_scale=0.05, p=1.0),
+ transforms.ToTensor()
+ ])
+
+ # load image file
+ train_len = None
+ self.length = 0
+ self.image_dir = image_dir
+ if image_dir is not None:
+ img_list = [glob.glob1(self.image_dir, ext) for ext in ['*jpg','*png']]
+ image_list = [item for sublist in img_list for item in sublist]
+ image_list.sort()
+ train_len = int(train_split*len(image_list))
+ if training_set:
+ self.image_list = image_list[:train_len]
+ else:
+ self.image_list = image_list[train_len:]
+ self.length = len(self.image_list)
+
+ # load label file
+ self.label_dir = label_dir
+ if label_dir is not None:
+ self.seeds = np.load(label_dir)
+ if train_len is None:
+ train_len = int(train_split*len(self.seeds))
+ if training_set:
+ self.seeds = self.seeds[:train_len]
+ else:
+ self.seeds = self.seeds[train_len:]
+ if self.length == 0:
+ self.length = len(self.seeds)
+
+ def __len__(self):
+ return self.length
+
+ def __getitem__(self, idx):
+ img = None
+ if self.image_dir is not None:
+ img_name = os.path.join(self.image_dir, self.image_list[idx])
+ image = Image.open(img_name)
+ img = self.resize(image)
+ if img.size(0) == 1:
+ img = torch.cat((img, img, img), dim=0)
+ img = self.normalize(img)
+ if self.video_data:
+ img_2 = self.random_rotation(image)
+ img_2 = self.normalize(img_2)
+ img_2 = torch.where(img_2 > -1, img_2, img)
+ img = torch.cat([img, img_2], dim=0)
+
+ # generate image
+ if self.label_dir is not None:
+ torch.manual_seed(self.seeds[idx])
+ z = torch.randn(1, 512)[0]
+ n = [torch.randn_like(noise[0]) for noise in self.noise_in]
+ if img is None:
+ return z, n
+ else:
+ return z, img, n
+ else:
+ return img
+
diff --git a/models/FeatureStyleEncoder/utils/functions.py b/models/FeatureStyleEncoder/utils/functions.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e3fa0ee305302762763830fe7f70d175ad84d59
--- /dev/null
+++ b/models/FeatureStyleEncoder/utils/functions.py
@@ -0,0 +1,109 @@
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.data as data
+
+from PIL import Image
+from torch.autograd import grad
+
+
+def clip_img(x):
+ """Clip stylegan generated image to range(0,1)"""
+ img_tmp = x.clone()[0]
+ img_tmp = (img_tmp + 1) / 2
+ img_tmp = torch.clamp(img_tmp, 0, 1)
+ return [img_tmp.detach().cpu()]
+
+def tensor_byte(x):
+ return x.element_size()*x.nelement()
+
+def count_parameters(net):
+ s = sum([np.prod(list(mm.size())) for mm in net.parameters()])
+ print(s)
+
+def stylegan_to_classifier(x, out_size=(224, 224)):
+ """Clip image to range(0,1)"""
+ img_tmp = x.clone()
+ img_tmp = torch.clamp((0.5*img_tmp + 0.5), 0, 1)
+ img_tmp = F.interpolate(img_tmp, size=out_size, mode='bilinear')
+ img_tmp[:,0] = (img_tmp[:,0] - 0.485)/0.229
+ img_tmp[:,1] = (img_tmp[:,1] - 0.456)/0.224
+ img_tmp[:,2] = (img_tmp[:,2] - 0.406)/0.225
+ #img_tmp = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])(img_tmp)
+ return img_tmp
+
+def downscale(x, scale_times=1, mode='bilinear'):
+ for i in range(scale_times):
+ x = F.interpolate(x, scale_factor=0.5, mode=mode)
+ return x
+
+def upscale(x, scale_times=1, mode='bilinear'):
+ for i in range(scale_times):
+ x = F.interpolate(x, scale_factor=2, mode=mode)
+ return x
+
+def hist_transform(source_tensor, target_tensor):
+ """Histogram transformation"""
+ c, h, w = source_tensor.size()
+ s_t = source_tensor.view(c, -1)
+ t_t = target_tensor.view(c, -1)
+ s_t_sorted, s_t_indices = torch.sort(s_t)
+ t_t_sorted, t_t_indices = torch.sort(t_t)
+ for i in range(c):
+ s_t[i, s_t_indices[i]] = t_t_sorted[i]
+ return s_t.view(c, h, w)
+
+def init_weights(m):
+ """Initialize layers with Xavier uniform distribution"""
+ if type(m) == nn.Conv2d:
+ nn.init.xavier_uniform_(m.weight)
+ elif type(m) == nn.Linear:
+ nn.init.uniform_(m.weight, 0.0, 1.0)
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0.01)
+
+def total_variation(x, delta=1):
+ """Total variation, x: tensor of size (B, C, H, W)"""
+ out = torch.mean(torch.abs(x[:, :, :, :-delta] - x[:, :, :, delta:]))\
+ + torch.mean(torch.abs(x[:, :, :-delta, :] - x[:, :, delta:, :]))
+ return out
+
+def vgg_transform(x):
+ """Adapt image for vgg network, x: image of range(0,1) subtracting ImageNet mean"""
+ r, g, b = torch.split(x, 1, 1)
+ out = torch.cat((b, g, r), dim = 1)
+ out = F.interpolate(out, size=(224, 224), mode='bilinear')
+ out = out*255.
+ return out
+
+# warp image with flow
+def normalize_axis(x,L):
+ return (x-1-(L-1)/2)*2/(L-1)
+
+def unnormalize_axis(x,L):
+ return x*(L-1)/2+1+(L-1)/2
+
+def torch_flow_to_th_sampling_grid(flow,h_src,w_src,use_cuda=False):
+ b,c,h_tgt,w_tgt=flow.size()
+ grid_y, grid_x = torch.meshgrid(torch.tensor(range(1,w_tgt+1)),torch.tensor(range(1,h_tgt+1)))
+ disp_x=flow[:,0,:,:]
+ disp_y=flow[:,1,:,:]
+ source_x=grid_x.unsqueeze(0).repeat(b,1,1).type_as(flow)+disp_x
+ source_y=grid_y.unsqueeze(0).repeat(b,1,1).type_as(flow)+disp_y
+ source_x_norm=normalize_axis(source_x,w_src)
+ source_y_norm=normalize_axis(source_y,h_src)
+ sampling_grid=torch.cat((source_x_norm.unsqueeze(3), source_y_norm.unsqueeze(3)), dim=3)
+ if use_cuda:
+ sampling_grid = sampling_grid.cuda()
+ return sampling_grid
+
+def warp_image_torch(image, flow):
+ """
+ Warp image (tensor, shape=[b, 3, h_src, w_src]) with flow (tensor, shape=[b, h_tgt, w_tgt, 2])
+ """
+ b,c,h_src,w_src=image.size()
+ sampling_grid_torch = torch_flow_to_th_sampling_grid(flow, h_src, w_src)
+ warped_image_torch = F.grid_sample(image, sampling_grid_torch)
+ return warped_image_torch
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/utils/video_utils.py b/models/FeatureStyleEncoder/utils/video_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..01f0874a0e88dec0c8404dfdaab92a761f2323bf
--- /dev/null
+++ b/models/FeatureStyleEncoder/utils/video_utils.py
@@ -0,0 +1,454 @@
+# Copyright (c) 2021, InterDigital R&D France. All rights reserved.
+#
+# This source code is made available under the license found in the
+# LICENSE.txt in the root directory of this source tree.
+
+import cv2
+import glob
+import numpy as np
+import os
+import face_alignment
+import torch
+
+from PIL import Image, ImageFilter
+from scipy import ndimage
+from scipy.ndimage import gaussian_filter1d
+from skimage import io
+from torchvision import transforms, utils
+
+
+def pil_to_cv2(pil_image):
+ open_cv_image = np.array(pil_image)
+ return open_cv_image[:, :, ::-1].copy()
+
+
+def cv2_to_pil(open_cv_image):
+ return Image.fromarray(open_cv_image[:, :, ::-1].copy())
+
+
+def put_text(img, text):
+ font = cv2.FONT_HERSHEY_SIMPLEX
+ bottomLeftCornerOfText = (10,50)
+ fontScale = 1.5
+ fontColor = (255,255,0)
+ lineType = 2
+ return cv2.putText(img, text,
+ bottomLeftCornerOfText,
+ font,
+ fontScale,
+ fontColor,
+ lineType)
+
+
+# Compare frames in two directory
+def compare_frames(save_dir, origin_dir, target_dir, strs='Original,Projected,Manipulated', dim=None):
+
+ os.makedirs(save_dir, exist_ok=True)
+ try:
+ if not isinstance(target_dir, list):
+ target_dir = [target_dir]
+ image_list = glob.glob1(origin_dir,'frame*')
+ image_list.sort()
+ for name in image_list:
+ img_l = []
+ for idx, dir_path in enumerate([origin_dir] + list(target_dir)):
+ img_1 = cv2.imread(dir_path + name)
+ img_1 = put_text(img_1, strs.split(',')[idx])
+ img_l.append(img_1)
+ img = np.concatenate(img_l, axis=1)
+ cv2.imwrite(save_dir + name, img)
+ except FileNotFoundError:
+ pass
+
+
+# Save frames into video
+def create_video(image_folder, fps=24, video_format='.mp4', resize_ratio=1):
+
+ video_name = os.path.dirname(image_folder) + video_format
+ img_list = glob.glob1(image_folder,'frame*')
+ img_list.sort()
+ frame = cv2.imread(os.path.join(image_folder, img_list[0]))
+ frame = cv2.resize(frame, (0,0), fx=resize_ratio, fy=resize_ratio)
+ height, width, layers = frame.shape
+ if video_format == '.mp4':
+ fourcc = cv2.VideoWriter_fourcc(*'mp4v')
+ elif video_format == '.avi':
+ fourcc = cv2.VideoWriter_fourcc(*'XVID')
+ video = cv2.VideoWriter(video_name, fourcc, fps, (width,height))
+ for image_name in img_list:
+ frame = cv2.imread(os.path.join(image_folder, image_name))
+ frame = cv2.resize(frame, (0,0), fx=resize_ratio, fy=resize_ratio)
+ video.write(frame)
+
+
+# Split video into frames
+def video_to_frames(video_path, frame_path, img_format='.jpg', count_num=1000, resize=False):
+
+ os.makedirs(frame_path, exist_ok=True)
+ vidcap = cv2.VideoCapture(video_path)
+ success,image = vidcap.read()
+ count = 0
+ while success:
+ if resize:
+ image = cv2.resize(image, (0,0), fx=0.5, fy=0.5)
+ cv2.imwrite(frame_path + '/frame%04d' % count + img_format, image)
+ success,image = vidcap.read()
+ count += 1
+ if count >= count_num:
+ break
+
+# Align faces
+def align_frames(img_dir, save_dir, output_size=1024, transform_size=1024, optical_flow=True, gaussian=True, filter_size=3):
+
+ os.makedirs(save_dir, exist_ok=True)
+
+ # load face landmark detector
+ fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=False, device='cuda')
+
+ # list images in the directory
+ img_list = glob.glob1(img_dir, 'frame*')
+ img_list.sort()
+
+ # save align statistics
+ stat_dict = {'quad':[], 'qsize':[], 'coord':[], 'crop':[]}
+ lms = []
+ for idx, img_name in enumerate(img_list):
+
+ img_path = os.path.join(img_dir, img_name)
+ img = io.imread(img_path)
+ lm = []
+
+ preds = fa.get_landmarks(img)
+ for kk in range(68):
+ lm.append((preds[0][kk][0], preds[0][kk][1]))
+
+ # Eye distance
+ lm_eye_left = lm[36 : 42] # left-clockwise
+ lm_eye_right = lm[42 : 48] # left-clockwise
+ eye_left = np.mean(lm_eye_left, axis=0)
+ eye_right = np.mean(lm_eye_right, axis=0)
+ eye_to_eye = eye_right - eye_left
+
+ if optical_flow:
+ if idx > 0:
+ s = int(np.hypot(*eye_to_eye)/4)
+ lk_params = dict(winSize=(s, s), maxLevel=5, criteria = (cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS, 10, 0.03))
+ points_arr = np.array(lm, np.float32)
+ points_prevarr = np.array(prev_lm, np.float32)
+ points_arr,status, err = cv2.calcOpticalFlowPyrLK(prev_img, img, points_prevarr, points_arr, **lk_params)
+ sigma =100
+ points_arr_float = np.array(points_arr,np.float32)
+ points = points_arr_float.tolist()
+ for k in range(0, len(lm)):
+ d = cv2.norm(np.array(prev_lm[k]) - np.array(lm[k]))
+ alpha = np.exp(-d*d/sigma)
+ lm[k] = (1 - alpha) * np.array(lm[k]) + alpha * np.array(points[k])
+ prev_img = img
+ prev_lm = lm
+
+ lms.append(lm)
+
+ # Apply gaussian filter on landmarks
+ if gaussian:
+ lm_filtered = np.array(lms)
+ for kk in range(68):
+ lm_filtered[:, kk, 0] = gaussian_filter1d(lm_filtered[:, kk, 0], filter_size)
+ lm_filtered[:, kk, 1] = gaussian_filter1d(lm_filtered[:, kk, 1], filter_size)
+ lms = lm_filtered.tolist()
+
+ # save landmarks
+ landmark_out_dir = os.path.dirname(img_dir) + '_landmark/'
+ os.makedirs(landmark_out_dir, exist_ok=True)
+
+ for idx, img_name in enumerate(img_list):
+
+ img_path = os.path.join(img_dir, img_name)
+ img = io.imread(img_path)
+
+ lm = lms[idx]
+ img_lm = img.copy()
+ for kk in range(68):
+ img_lm = cv2.circle(img_lm, (int(lm[kk][0]),int(lm[kk][1])), radius=3, color=(255, 0, 255), thickness=-1)
+ # Save landmark images
+ cv2.imwrite(landmark_out_dir + img_name, img_lm[:,:,::-1])
+
+ # Save mask images
+ """
+ seg_mask = np.zeros(img.shape, img.dtype)
+ poly = np.array(lm[0:17] + lm[17:27][::-1], np.int32)
+ cv2.fillPoly(seg_mask, [poly], (255, 255, 255))
+ cv2.imwrite(img_dir + "mask%04d.jpg"%idx, seg_mask);
+ """
+
+ # Parse landmarks.
+ lm_eye_left = lm[36 : 42] # left-clockwise
+ lm_eye_right = lm[42 : 48] # left-clockwise
+ lm_mouth_outer = lm[48 : 60] # left-clockwise
+
+ # Calculate auxiliary vectors.
+ eye_left = np.mean([lm_eye_left[0], lm_eye_left[3]], axis=0)
+ eye_right = np.mean([lm_eye_right[0], lm_eye_right[3]], axis=0)
+ eye_avg = (eye_left + eye_right) * 0.5
+ eye_to_eye = eye_right - eye_left
+ mouth_left = np.array(lm_mouth_outer[0])
+ mouth_right = np.array(lm_mouth_outer[6])
+ mouth_avg = (mouth_left + mouth_right) * 0.5
+ eye_to_mouth = mouth_avg - eye_avg
+
+ # Choose oriented crop rectangle.
+ x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1]
+ x /= np.hypot(*x)
+ x *= max(np.hypot(*eye_to_eye) * 2.0, np.hypot(*eye_to_mouth) * 1.8)
+ y = np.flipud(x) * [-1, 1]
+ c = eye_avg + eye_to_mouth * 0.1
+ quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y])
+ qsize = np.hypot(*x) * 2
+
+ stat_dict['coord'].append(quad)
+ stat_dict['qsize'].append(qsize)
+
+ # Apply gaussian filter on crops
+ if gaussian:
+ quads = np.array(stat_dict['coord'])
+ quads = gaussian_filter1d(quads, 2*filter_size, axis=0)
+ stat_dict['coord'] = quads.tolist()
+ qsize = np.array(stat_dict['qsize'])
+ qsize = gaussian_filter1d(qsize, 2*filter_size, axis=0)
+ stat_dict['qsize'] = qsize.tolist()
+
+ for idx, img_name in enumerate(img_list):
+
+ img_path = os.path.join(img_dir, img_name)
+ img = Image.open(img_path)
+
+ qsize = stat_dict['qsize'][idx]
+ quad = np.array(stat_dict['coord'][idx])
+
+ # Crop.
+ border = max(int(np.rint(qsize * 0.1)), 3)
+ crop = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
+ crop = (max(crop[0] - border, 0), max(crop[1] - border, 0), min(crop[2] + border, img.size[0]), min(crop[3] + border, img.size[1]))
+ if crop[2] - crop[0] < img.size[0] or crop[3] - crop[1] < img.size[1]:
+ img = img.crop(crop)
+ quad -= crop[0:2]
+
+ stat_dict['crop'].append(crop)
+ stat_dict['quad'].append((quad + 0.5).flatten())
+
+ # Pad.
+ pad = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
+ pad = (max(-pad[0] + border, 0), max(-pad[1] + border, 0), max(pad[2] - img.size[0] + border, 0), max(pad[3] - img.size[1] + border, 0))
+ if max(pad) > border - 4:
+ pad = np.maximum(pad, int(np.rint(qsize * 0.3)))
+ img = np.pad(np.float32(img), ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect')
+ h, w, _ = img.shape
+ y, x, _ = np.ogrid[:h, :w, :1]
+ img = Image.fromarray(np.uint8(np.clip(np.rint(img), 0, 255)), 'RGB')
+ quad += pad[:2]
+ # Transform.
+ img = img.transform((transform_size, transform_size), Image.QUAD, (quad + 0.5).flatten(), Image.BILINEAR)
+
+ # resizing
+ img_pil = img.resize((output_size, output_size), Image.LANCZOS)
+ img_pil.save(save_dir+img_name)
+
+ create_video(landmark_out_dir)
+ np.save(save_dir+'stat_dict.npy', stat_dict)
+
+
+def find_coeffs(pa, pb):
+
+ matrix = []
+ for p1, p2 in zip(pa, pb):
+ matrix.append([p1[0], p1[1], 1, 0, 0, 0, -p2[0]*p1[0], -p2[0]*p1[1]])
+ matrix.append([0, 0, 0, p1[0], p1[1], 1, -p2[1]*p1[0], -p2[1]*p1[1]])
+ A = np.matrix(matrix, dtype=np.float)
+ B = np.array(pb).reshape(8)
+ res = np.dot(np.linalg.inv(A.T * A) * A.T, B)
+ return np.array(res).reshape(8)
+
+# reproject aligned frames to the original video
+def video_reproject(orig_dir_path, recon_dir_path, save_dir_path, state_dir_path, mask_dir_path, seamless=False):
+
+ if not os.path.exists(save_dir_path):
+ os.makedirs(save_dir_path)
+
+ img_list_0 = glob.glob1(orig_dir_path,'frame*')
+ img_list_2 = glob.glob1(recon_dir_path,'frame*')
+ img_list_0.sort()
+ img_list_2.sort()
+ stat_dict = np.load(state_dir_path + 'stat_dict.npy', allow_pickle=True).item()
+ counter = len(img_list_2)
+
+ for idx in range(counter):
+
+ img_0 = Image.open(orig_dir_path + img_list_0[idx])
+ img_2 = Image.open(recon_dir_path + img_list_2[idx])
+
+ quad_f = stat_dict['quad'][idx]
+ quad_0 = stat_dict['crop'][idx]
+
+ coeffs = find_coeffs(
+ [(quad_f[0], quad_f[1]), (quad_f[2] , quad_f[3]), (quad_f[4], quad_f[5]), (quad_f[6], quad_f[7])],
+ [(0, 0), (0, 1024), (1024, 1024), (1024, 0)])
+ crop_size = (quad_0[2] - quad_0[0], quad_0[3] - quad_0[1])
+ img_2 = img_2.transform(crop_size, Image.PERSPECTIVE, coeffs, Image.BICUBIC)
+ output = img_0.copy()
+ output.paste(img_2, (int(quad_0[0]), int(quad_0[1])))
+
+ """
+ mask = cv2.imread(orig_dir_path + 'mask%04d.jpg'%idx)
+ kernel = np.ones((10,10), np.uint8)
+ mask = cv2.dilate(mask, kernel, iterations=5)
+ """
+ crop_mask = Image.open(mask_dir_path + img_list_0[idx])
+ crop_mask = crop_mask.transform(crop_size, Image.PERSPECTIVE, coeffs, Image.BICUBIC)
+ mask = Image.fromarray(np.zeros(np.array(img_0).shape, np.array(img_0).dtype))
+ mask.paste(crop_mask, (int(quad_0[0]), int(quad_0[1])))
+ mask = pil_to_cv2(mask)
+ # Apply mask
+ if not seamless:
+ mask = cv2_to_pil(mask).filter(ImageFilter.GaussianBlur(radius=10)).convert('L')
+ mask = np.array(mask)[:, :, np.newaxis]/255.
+ output = np.array(img_0)*(1-mask) + np.array(output)*mask
+ output = Image.fromarray(output.astype(np.uint8))
+ output.save(save_dir_path + img_list_2[idx])
+ else:
+ src = pil_to_cv2(output)
+ dst = pil_to_cv2(img_0)
+ # clone
+ br = cv2.boundingRect(cv2.split(mask)[0]) # bounding rect (x,y,width,height)
+ center = (br[0] + br[2] // 2, br[1] + br[3] // 2)
+ output = cv2.seamlessClone(src, dst, mask, center, cv2.NORMAL_CLONE)
+ cv2.imwrite(save_dir_path + img_list_2[idx], output)
+
+
+
+
+# Align faces
+def align_image(img_dir, save_dir, output_size=1024, transform_size=1024, format='*.png'):
+ os.makedirs(save_dir, exist_ok=True)
+
+ # load face landmark detector
+ fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=False, device='cuda')
+ # list images in the directory
+ img_list = glob.glob1(img_dir, format)
+ #img_list = os.listdir(img_dir)
+ img_list.sort()
+
+ # save align statistics
+ stat_dict = {'quad':[], 'qsize':[], 'coord':[], 'crop':[]}
+
+ for idx, img_name in enumerate(img_list):
+
+ img_path = os.path.join(img_dir, img_name)
+ img = Image.open(img_path).convert('RGB')
+ img_np = np.array(img)
+ lm = []
+
+ preds = fa.get_landmarks(img_np)
+ for kk in range(68):
+ lm.append((preds[0][kk][0], preds[0][kk][1]))
+ if len(lm)==0:
+ continue
+
+ # Parse landmarks. Code extracted from ffhq-dataset
+ # pylint: disable=unused-variable
+ lm_chin = lm[0 : 17] # left-right
+ lm_eyebrow_left = lm[17 : 22] # left-right
+ lm_eyebrow_right = lm[22 : 27] # left-right
+ lm_nose = lm[27 : 31] # top-down
+ lm_nostrils = lm[31 : 36] # top-down
+ lm_eye_left = lm[36 : 42] # left-clockwise
+ lm_eye_right = lm[42 : 48] # left-clockwise
+ lm_mouth_outer = lm[48 : 60] # left-clockwise
+ lm_mouth_inner = lm[60 : 68] # left-clockwise
+
+ # Calculate auxiliary vectors.
+ eye_left = np.mean([lm_eye_left[0], lm_eye_left[3]], axis=0)
+ eye_right = np.mean([lm_eye_right[0], lm_eye_right[3]], axis=0)
+ eye_avg = (eye_left + eye_right) * 0.5
+ eye_to_eye = eye_right - eye_left
+ mouth_left = np.array(lm_mouth_outer[0])
+ mouth_right = np.array(lm_mouth_outer[6])
+ mouth_avg = (mouth_left + mouth_right) * 0.5
+ eye_to_mouth = mouth_avg - eye_avg
+
+ # Choose oriented crop rectangle.
+ x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1]
+ x /= np.hypot(*x)
+ x *= np.hypot(*eye_to_eye) * 2.0#max(np.hypot(*eye_to_eye) * 2.0, np.hypot(*eye_to_mouth) * 1.8)
+
+ y = np.flipud(x) * [-1, 1]
+ c = eye_avg + eye_to_mouth * 0.1
+ quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y])
+ qsize = np.hypot(*x) * 2
+
+ stat_dict['coord'].append(quad)
+ stat_dict['qsize'].append(qsize)
+
+ qsize = stat_dict['qsize'][idx]
+ quad = np.array(stat_dict['coord'][idx])
+ """
+ # Shrink.
+ shrink = int(np.floor(qsize / output_size * 0.5))
+ if shrink > 1:
+ print('shrink!')
+ rsize = (int(np.rint(float(img.size[0]) / shrink)), int(np.rint(float(img.size[1]) / shrink)))
+ img = img.resize(rsize, Image.ANTIALIAS)
+ quad /= shrink
+ qsize /= shrink
+ """
+ # Crop.
+ border = max(int(np.rint(qsize * 0.1)), 3)
+ crop = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
+ crop = (max(crop[0] - border, 0), max(crop[1] - border, 0), min(crop[2] + border, img.size[0]), min(crop[3] + border, img.size[1]))
+ if crop[2] - crop[0] < img.size[0] or crop[3] - crop[1] < img.size[1]:
+ img = img.crop(crop)
+ quad -= crop[0:2]
+
+ stat_dict['crop'].append(crop)
+ stat_dict['quad'].append((quad + 0.5).flatten())
+ #img = img.crop(crop)
+ # Pad.
+ pad = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1]))))
+ pad = (max(-pad[0] + border, 0), max(-pad[1] + border, 0), max(pad[2] - img.size[0] + border, 0), max(pad[3] - img.size[1] + border, 0))
+ if max(pad) > border - 4:
+ pad = np.maximum(pad, int(np.rint(qsize * 0.3)))
+ img = np.pad(np.float32(img), ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'edge')
+ h, w, _ = img.shape
+ y, x, _ = np.ogrid[:h, :w, :1]
+ img = Image.fromarray(np.uint8(np.clip(np.rint(img), 0, 255)), 'RGB')
+ quad += pad[:2]
+ # Transform.
+ img = img.transform((transform_size, transform_size), Image.QUAD, (quad + 0.5).flatten(), Image.BILINEAR)
+ img_pil = img.resize((output_size, output_size), Image.LANCZOS)
+
+ # resizing
+ img_pil.save(save_dir+img_name)
+
+ np.save(save_dir+'stat_dict.npy', stat_dict)
+
+img_to_tensor = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+])
+
+def generate_mask(img_dir, save_dir, parsing_net, labels=[1,2,3,4,5,6,9,10,11,12,13], output_size=(1024, 1024), device=torch.device('cuda')):
+ os.makedirs(save_dir, exist_ok=True)
+ img_list = glob.glob1(img_dir, 'frame*')
+ img_list.sort()
+
+ for img_name in img_list:
+ img_path = os.path.join(img_dir, img_name)
+ img = Image.open(img_path).resize((512, 512), Image.LANCZOS)
+ x_1 = img_to_tensor(img).unsqueeze(0).to(device)
+ out_1 = parsing_net(x_1)
+ parsing = out_1[0].squeeze(0).detach().cpu().numpy().argmax(0)
+ mask = np.uint8(parsing)
+ for j in labels:
+ mask = np.where(mask==j, 255, mask)
+ mask = np.where(mask==255, 255, 0)
+ mask_pil = Image.fromarray(np.uint8(mask)).resize(output_size, Image.LANCZOS)
+ save_path = os.path.join(save_dir, img_name)
+ mask_pil.save(save_path)
\ No newline at end of file
diff --git a/models/FeatureStyleEncoder/video_processing.py b/models/FeatureStyleEncoder/video_processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0fd231e87501d37ba9ba74899a1790731fff4aa
--- /dev/null
+++ b/models/FeatureStyleEncoder/video_processing.py
@@ -0,0 +1,174 @@
+# Copyright (c) 2021, InterDigital R&D France. All rights reserved.
+#
+# This source code is made available under the license found in the
+# LICENSE.txt in the root directory of this source tree.
+
+import argparse
+import copy
+import glob
+import numpy as np
+import os
+import torch
+import yaml
+import time
+
+from PIL import Image
+from torchvision import transforms, utils, models
+
+from utils.video_utils import *
+from face_parsing.model import BiSeNet
+from trainer import *
+
+
+torch.backends.cudnn.enabled = True
+torch.backends.cudnn.deterministic = True
+torch.backends.cudnn.benchmark = True
+torch.autograd.set_detect_anomaly(True)
+Image.MAX_IMAGE_PIXELS = None
+device = torch.device('cuda')
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--config', type=str, default='001', help='Path to the config file.')
+parser.add_argument('--attr', type=str, default='Eyeglasses', help='attribute for manipulation.')
+parser.add_argument('--alpha', type=str, default='1.', help='scale for manipulation.')
+parser.add_argument('--label_file', type=str, default='./data/celebahq_anno.npy', help='label file path')
+parser.add_argument('--pretrained_model_path', type=str, default='./pretrained_models/143_enc.pth', help='pretrained stylegan2 model')
+parser.add_argument('--stylegan_model_path', type=str, default='./pixel2style2pixel/pretrained_models/psp_ffhq_encode.pt', help='pretrained stylegan2 model')
+parser.add_argument('--arcface_model_path', type=str, default='./pretrained_models/backbone.pth', help='pretrained ArcFace model')
+parser.add_argument('--parsing_model_path', type=str, default='./pretrained_models/79999_iter.pth', help='pretrained parsing model')
+parser.add_argument('--log_path', type=str, default='./logs/', help='log file path')
+parser.add_argument('--function', type=str, default='', help='Calling function by name.')
+parser.add_argument('--video_path', type=str, default='./data/video/FP006911MD02.mp4', help='video file path')
+parser.add_argument('--output_path', type=str, default='./output/video/', help='output video file path')
+parser.add_argument('--boundary_path', type=str, default='./boundaries_ours/', help='output video file path')
+parser.add_argument('--optical_flow', action='store_true', help='use optical flow')
+parser.add_argument('--resize', action='store_true', help='downscale image size')
+parser.add_argument('--seamless', action='store_true', help='seamless cloning')
+parser.add_argument('--filter_size', type=float, default=3, help='filter size')
+parser.add_argument('--strs', type=str, default='Original,Projected,Manipulated', help='strs to be added on video')
+opts = parser.parse_args()
+
+# Celeba attribute list
+attr_dict = {'5_o_Clock_Shadow': 0, 'Arched_Eyebrows': 1, 'Attractive': 2, 'Bags_Under_Eyes': 3, \
+ 'Bald': 4, 'Bangs': 5, 'Big_Lips': 6, 'Big_Nose': 7, 'Black_Hair': 8, 'Blond_Hair': 9, \
+ 'Brown_Hair': 11, 'Bushy_Eyebrows': 12, 'Chubby': 13, 'Double_Chin': 14, \
+ 'Eyeglasses': 15, 'Goatee': 16, 'Gray_Hair': 17, 'Heavy_Makeup': 18, 'High_Cheekbones': 19, \
+ 'Male': 20, 'Mouth_Slightly_Open': 21, 'Mustache': 22, 'Narrow_Eyes': 23, 'No_Beard': 24, \
+ 'Oval_Face': 25, 'Pale_Skin': 26, 'Pointy_Nose': 27, 'Receding_Hairline': 28, 'Rosy_Cheeks': 29, \
+ 'Sideburns': 30, 'Smiling': 31, 'Straight_Hair': 32, 'Wavy_Hair': 33, 'Wearing_Earrings': 34, \
+ 'Wearing_Hat': 35, 'Wearing_Lipstick': 36, 'Wearing_Necklace': 37, 'Wearing_Necktie': 38, 'Young': 39}
+
+img_to_tensor = transforms.Compose([
+ transforms.Resize((1024, 1024)),
+ transforms.ToTensor(),
+ transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+])
+
+# linear interpolation
+def linear_interpolate(latent_code,
+ boundary,
+ start_distance=-3.0,
+ end_distance=3.0,
+ steps=10):
+ assert (latent_code.shape[0] == 1 and boundary.shape[0] == 1 and
+ len(boundary.shape) == 2 and
+ boundary.shape[1] == latent_code.shape[-1])
+
+ linspace = np.linspace(start_distance, end_distance, steps)
+ if len(latent_code.shape) == 2:
+ linspace = linspace.reshape(-1, 1).astype(np.float32)
+ return latent_code + linspace * boundary
+ if len(latent_code.shape) == 3:
+ linspace = linspace.reshape(-1, 1, 1).astype(np.float32)
+ return latent_code + linspace * boundary.reshape(1, 1, -1)
+
+# Latent code manipulation
+def latent_manipulation(opts, align_dir_path, process_dir_path):
+
+ os.makedirs(process_dir_path, exist_ok=True)
+ #attrs = opts.attr.split(',')
+ #alphas = opts.alpha.split(',')
+ step_scale = 15 * int(opts.alpha)
+ n_steps = 5
+
+ boundary = np.load(opts.boundary_path +'%s_boundary.npy'%opts.attr)
+
+ # Initialize trainer
+ config = yaml.load(open('./configs/' + opts.config + '.yaml', 'r'), Loader=yaml.FullLoader)
+ trainer = Trainer(config, opts)
+ trainer.initialize(opts.stylegan_model_path, opts.arcface_model_path, opts.parsing_model_path)
+ trainer.to(device)
+
+ state_dict = torch.load(opts.pretrained_model_path)#os.path.join(opts.log_path, opts.config + '/checkpoint.pth'))
+ trainer.enc.load_state_dict(torch.load(opts.pretrained_model_path))
+ trainer.enc.eval()
+
+ with torch.no_grad():
+ img_list = [glob.glob1(align_dir_path, ext) for ext in ['*jpg','*png']]
+ img_list = [item for sublist in img_list for item in sublist]
+ img_list.sort()
+ n_1 = trainer.StyleGAN.make_noise()
+
+ for i, img_name in enumerate(img_list):
+ #print(i, img_name)
+ image_A = img_to_tensor(Image.open(align_dir_path + img_name)).unsqueeze(0).to(device)
+ w_0, f_0 = trainer.encode(image_A)
+
+ w_0_np = w_0.cpu().numpy().reshape(1, -1)
+ out = linear_interpolate(w_0_np, boundary, start_distance=-step_scale, end_distance=step_scale, steps=n_steps)
+ w_1 = torch.tensor(out[-1]).view(1, -1, 512).to(device)
+
+ _, fea_0 = trainer.StyleGAN([w_0], noise=n_1, input_is_latent=True, return_features=True)
+ _, fea_1 = trainer.StyleGAN([w_1], noise=n_1, input_is_latent=True, return_features=True)
+
+ features = [None]*5 + [f_0 + fea_1[5] - fea_0[5]] + [None]*(17-5)
+ x_1, _ = trainer.StyleGAN([w_1], noise=n_1, input_is_latent=True, features_in=features, feature_scale=1.0)
+ utils.save_image(clip_img(x_1), process_dir_path + 'frame%04d'%i+'.jpg')
+
+
+video_path = opts.video_path
+video_name = video_path.split('/')[-1]
+orig_dir_path = opts.output_path + video_name.split('.')[0] + '/' + video_name.split('.')[0] + '/'
+align_dir_path = os.path.dirname(orig_dir_path) + '_crop_align/'
+mask_dir_path = os.path.dirname(orig_dir_path) + '_crop_align_mask/'
+latent_dir_path = os.path.dirname(orig_dir_path) + '_crop_align_latent/'
+process_dir_path = os.path.dirname(orig_dir_path) + '_crop_align_' + opts.attr.replace(',','_') + '/'
+reproject_dir_path = os.path.dirname(orig_dir_path) + '_crop_align_' + opts.attr.replace(',','_') + '_reproject/'
+
+
+print(opts.function)
+start_time = time.perf_counter()
+
+if opts.function == 'video_to_frames':
+ video_to_frames(video_path, orig_dir_path, count_num=120, resize=opts.resize)
+ create_video(orig_dir_path)
+elif opts.function == 'align_frames':
+ align_frames(orig_dir_path, align_dir_path, output_size=1024, optical_flow=opts.optical_flow, filter_size=opts.filter_size)
+ # parsing mask
+ parsing_net = BiSeNet(n_classes=19)
+ parsing_net.load_state_dict(torch.load(opts.parsing_model_path))
+ parsing_net.eval()
+ parsing_net.to(device)
+ generate_mask(align_dir_path, mask_dir_path, parsing_net)
+elif opts.function == 'latent_manipulation':
+ latent_manipulation(opts, align_dir_path, process_dir_path)
+elif opts.function == 'reproject_origin':
+ process_dir_path = os.path.dirname(orig_dir_path) + '_inversion/'
+ reproject_dir_path = os.path.dirname(orig_dir_path) + '_inversion_reproject/'
+ video_reproject(orig_dir_path, process_dir_path, reproject_dir_path, align_dir_path, mask_dir_path, seamless=opts.seamless)
+ create_video(reproject_dir_path)
+elif opts.function == 'reproject_manipulate':
+ video_reproject(orig_dir_path, process_dir_path, reproject_dir_path, align_dir_path, mask_dir_path, seamless=opts.seamless)
+ create_video(reproject_dir_path)
+elif opts.function == 'compare_frames':
+ process_dir_paths = []
+ process_dir_paths.append(os.path.dirname(orig_dir_path) + '_inversion_reproject/')
+ if len(opts.attr.split(','))>0:
+ process_dir_paths.append(reproject_dir_path)
+ save_dir = os.path.dirname(orig_dir_path) + '_crop_align_' + opts.attr.replace(',','_') + '_compare/'
+ compare_frames(save_dir, orig_dir_path, process_dir_paths, strs=opts.strs, dim=1)
+ create_video(save_dir, video_format='.avi', resize_ratio=1)
+
+
+count_time = time.perf_counter() - start_time
+print("Elapsed time: %0.4f seconds"%count_time)
\ No newline at end of file
diff --git a/models/Net.py b/models/Net.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bd1684d5ea1f751735817cccbc78129823c8eed
--- /dev/null
+++ b/models/Net.py
@@ -0,0 +1,484 @@
+import os
+
+import numpy as np
+import torch
+from torch import nn
+from torchvision import transforms
+
+from models.CtrlHair.external_code.face_parsing.my_parsing_util import FaceParsing_tensor
+from models.stylegan2.model import Generator
+from utils.drive import download_weight
+
+transform_to_256 = transforms.Compose([
+ transforms.Resize((256, 256)),
+])
+
+__all__ = ['Net', 'iresnet18', 'iresnet34', 'iresnet50', 'iresnet100', 'iresnet200', 'FeatureEncoderMult',
+ 'IBasicBlock', 'conv1x1', 'get_segmentation']
+
+
+class Net(nn.Module):
+
+ def __init__(self, opts):
+ super(Net, self).__init__()
+ self.opts = opts
+ self.generator = Generator(opts.size, opts.latent, opts.n_mlp, channel_multiplier=opts.channel_multiplier)
+ self.cal_layer_num()
+ self.load_weights()
+ self.load_PCA_model()
+ FaceParsing_tensor.parsing_img()
+
+ def load_weights(self):
+ if not os.path.exists(self.opts.ckpt):
+ print('Downloading StyleGAN2 checkpoint: {}'.format(self.opts.ckpt))
+ download_weight(self.opts.ckpt)
+
+ print('Loading StyleGAN2 from checkpoint: {}'.format(self.opts.ckpt))
+ checkpoint = torch.load(self.opts.ckpt)
+ device = self.opts.device
+ self.generator.load_state_dict(checkpoint['g_ema'])
+ self.latent_avg = checkpoint['latent_avg']
+ self.generator.to(device)
+ self.latent_avg = self.latent_avg.to(device)
+
+ for param in self.generator.parameters():
+ param.requires_grad = False
+ self.generator.eval()
+
+ def build_PCA_model(self, PCA_path):
+
+ with torch.no_grad():
+ latent = torch.randn((1000000, 512), dtype=torch.float32)
+ # latent = torch.randn((10000, 512), dtype=torch.float32)
+ self.generator.style.cpu()
+ pulse_space = torch.nn.LeakyReLU(5)(self.generator.style(latent)).numpy()
+ self.generator.style.to(self.opts.device)
+
+ from utils.PCA_utils import IPCAEstimator
+
+ transformer = IPCAEstimator(512)
+ X_mean = pulse_space.mean(0)
+ transformer.fit(pulse_space - X_mean)
+ X_comp, X_stdev, X_var_ratio = transformer.get_components()
+ np.savez(PCA_path, X_mean=X_mean, X_comp=X_comp, X_stdev=X_stdev, X_var_ratio=X_var_ratio)
+
+ def load_PCA_model(self):
+ device = self.opts.device
+
+ PCA_path = self.opts.ckpt[:-3] + '_PCA.npz'
+
+ if not os.path.isfile(PCA_path):
+ self.build_PCA_model(PCA_path)
+
+ PCA_model = np.load(PCA_path)
+ self.X_mean = torch.from_numpy(PCA_model['X_mean']).float().to(device)
+ self.X_comp = torch.from_numpy(PCA_model['X_comp']).float().to(device)
+ self.X_stdev = torch.from_numpy(PCA_model['X_stdev']).float().to(device)
+
+ # def make_noise(self):
+ # noises_single = self.generator.make_noise()
+ # noises = []
+ # for noise in noises_single:
+ # noises.append(noise.repeat(1, 1, 1, 1).normal_())
+ #
+ # return noises
+
+ def cal_layer_num(self):
+ if self.opts.size == 1024:
+ self.layer_num = 18
+ elif self.opts.size == 512:
+ self.layer_num = 16
+ elif self.opts.size == 256:
+ self.layer_num = 14
+
+ self.S_index = self.layer_num - 11
+
+ return
+
+ def cal_p_norm_loss(self, latent_in):
+ latent_p_norm = (torch.nn.LeakyReLU(negative_slope=5)(latent_in) - self.X_mean).bmm(
+ self.X_comp.T.unsqueeze(0)) / self.X_stdev
+ p_norm_loss = self.opts.p_norm_lambda * (latent_p_norm.pow(2).mean())
+ return p_norm_loss
+
+ def cal_l_F(self, latent_F, F_init):
+ return self.opts.l_F_lambda * (latent_F - F_init).pow(2).mean()
+
+
+def get_segmentation(img_rgb, resize=True):
+ parsing, _ = FaceParsing_tensor.parsing_img(img_rgb)
+ parsing = FaceParsing_tensor.swap_parsing_label_to_celeba_mask(parsing)
+ mask_img = parsing.long()[None, None, ...]
+ if resize:
+ mask_img = transforms.functional.resize(mask_img, (256, 256),
+ interpolation=transforms.InterpolationMode.NEAREST)
+ return mask_img
+
+
+fs_kernals = {
+ 0: (12, 12),
+ 1: (12, 12),
+ 2: (6, 6),
+ 3: (6, 6),
+ 4: (3, 3),
+ 5: (3, 3),
+ 6: (3, 3),
+ 7: (3, 3),
+}
+
+fs_strides = {
+ 0: (7, 7),
+ 1: (7, 7),
+ 2: (4, 4),
+ 3: (4, 4),
+ 4: (2, 2),
+ 5: (2, 2),
+ 6: (1, 1),
+ 7: (1, 1),
+}
+
+
+def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=stride,
+ padding=dilation,
+ groups=groups,
+ bias=False,
+ dilation=dilation)
+
+
+def conv1x1(in_planes, out_planes, stride=1):
+ """1x1 convolution"""
+ return nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size=1,
+ stride=stride,
+ bias=False)
+
+
+class IBasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None,
+ groups=1, base_width=64, dilation=1):
+ super(IBasicBlock, self).__init__()
+ if groups != 1 or base_width != 64:
+ raise ValueError('BasicBlock only supports groups=1 and base_width=64')
+ if dilation > 1:
+ raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
+ self.bn1 = nn.BatchNorm2d(inplanes, eps=1e-05, )
+ self.conv1 = conv3x3(inplanes, planes)
+ self.bn2 = nn.BatchNorm2d(planes, eps=1e-05, )
+ self.prelu = nn.PReLU(planes)
+ self.conv2 = conv3x3(planes, planes, stride)
+ self.bn3 = nn.BatchNorm2d(planes, eps=1e-05, )
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ identity = x
+ out = self.bn1(x)
+ out = self.conv1(out)
+ out = self.bn2(out)
+ out = self.prelu(out)
+ out = self.conv2(out)
+ out = self.bn3(out)
+ if self.downsample is not None:
+ identity = self.downsample(x)
+ out += identity
+ return out
+
+
+class IResNet(nn.Module):
+ fc_scale = 7 * 7
+
+ def __init__(self,
+ block, layers, dropout=0, num_features=512, zero_init_residual=False,
+ groups=1, width_per_group=64, replace_stride_with_dilation=None, fp16=False):
+ super(IResNet, self).__init__()
+ self.fp16 = fp16
+ self.inplanes = 64
+ self.dilation = 1
+ if replace_stride_with_dilation is None:
+ replace_stride_with_dilation = [False, False, False]
+ if len(replace_stride_with_dilation) != 3:
+ raise ValueError("replace_stride_with_dilation should be None "
+ "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
+ self.groups = groups
+ self.base_width = width_per_group
+ self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(self.inplanes, eps=1e-05)
+ self.prelu = nn.PReLU(self.inplanes)
+ self.layer1 = self._make_layer(block, 64, layers[0], stride=2)
+ self.layer2 = self._make_layer(block,
+ 128,
+ layers[1],
+ stride=2,
+ dilate=replace_stride_with_dilation[0])
+ self.layer3 = self._make_layer(block,
+ 256,
+ layers[2],
+ stride=2,
+ dilate=replace_stride_with_dilation[1])
+ self.layer4 = self._make_layer(block,
+ 512,
+ layers[3],
+ stride=2,
+ dilate=replace_stride_with_dilation[2])
+ self.bn2 = nn.BatchNorm2d(512 * block.expansion, eps=1e-05, )
+ self.dropout = nn.Dropout(p=dropout, inplace=True)
+ self.fc = nn.Linear(512 * block.expansion * self.fc_scale, num_features)
+ self.features = nn.BatchNorm1d(num_features, eps=1e-05)
+ nn.init.constant_(self.features.weight, 1.0)
+ self.features.weight.requires_grad = False
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.normal_(m.weight, 0, 0.1)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+ if zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, IBasicBlock):
+ nn.init.constant_(m.bn2.weight, 0)
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
+ downsample = None
+ previous_dilation = self.dilation
+ if dilate:
+ self.dilation *= stride
+ stride = 1
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ conv1x1(self.inplanes, planes * block.expansion, stride),
+ nn.BatchNorm2d(planes * block.expansion, eps=1e-05, ),
+ )
+ layers = []
+ layers.append(
+ block(self.inplanes, planes, stride, downsample, self.groups,
+ self.base_width, previous_dilation))
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(
+ block(self.inplanes,
+ planes,
+ groups=self.groups,
+ base_width=self.base_width,
+ dilation=self.dilation))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x, return_features=False):
+ out = []
+ with torch.cuda.amp.autocast(self.fp16):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.prelu(x)
+ x = self.layer1(x)
+ out.append(x)
+ x = self.layer2(x)
+ out.append(x)
+ x = self.layer3(x)
+ out.append(x)
+ x = self.layer4(x)
+ out.append(x)
+ x = self.bn2(x)
+ x = torch.flatten(x, 1)
+ x = self.dropout(x)
+ x = self.fc(x.float() if self.fp16 else x)
+ x = self.features(x)
+
+ if return_features:
+ out.append(x)
+ return out
+ return x
+
+
+def _iresnet(arch, block, layers, pretrained, progress, **kwargs):
+ model = IResNet(block, layers, **kwargs)
+ if pretrained:
+ raise ValueError()
+ return model
+
+
+def iresnet18(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet18', IBasicBlock, [2, 2, 2, 2], pretrained,
+ progress, **kwargs)
+
+
+def iresnet34(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet34', IBasicBlock, [3, 4, 6, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet50(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet50', IBasicBlock, [3, 4, 14, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet100(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet100', IBasicBlock, [3, 13, 30, 3], pretrained,
+ progress, **kwargs)
+
+
+def iresnet200(pretrained=False, progress=True, **kwargs):
+ return _iresnet('iresnet200', IBasicBlock, [6, 26, 60, 6], pretrained,
+ progress, **kwargs)
+
+
+class FeatureEncoder(nn.Module):
+ def __init__(self, n_styles=18, opts=None, residual=False,
+ use_coeff=False, resnet_layer=None,
+ video_input=False, f_maps=512, stride=(1, 1)):
+ super(FeatureEncoder, self).__init__()
+
+ resnet50 = iresnet50()
+ resnet50.load_state_dict(torch.load(opts.arcface_model_path))
+
+ # input conv layer
+ if video_input:
+ self.conv = nn.Sequential(
+ nn.Conv2d(6, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
+ *list(resnet50.children())[1:3]
+ )
+ else:
+ self.conv = nn.Sequential(*list(resnet50.children())[:3])
+
+ # define layers
+ self.block_1 = list(resnet50.children())[3] # 15-18
+ self.block_2 = list(resnet50.children())[4] # 10-14
+ self.block_3 = list(resnet50.children())[5] # 5-9
+ self.block_4 = list(resnet50.children())[6] # 1-4
+ self.content_layer = nn.Sequential(
+ nn.BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.PReLU(num_parameters=512),
+ nn.Conv2d(512, 512, kernel_size=(3, 3), stride=stride, padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
+ )
+
+ self.avg_pool = nn.AdaptiveAvgPool2d((3, 3))
+ self.styles = nn.ModuleList()
+ for i in range(n_styles):
+ self.styles.append(nn.Linear(960 * 9, 512))
+
+ def apply_head(self, x):
+ latents = []
+ for i in range(len(self.styles)):
+ latents.append(self.styles[i](x))
+ out = torch.stack(latents, dim=1)
+ return out
+
+ def forward(self, x):
+ latents = []
+ features = []
+ x = self.conv(x)
+ x = self.block_1(x)
+ features.append(self.avg_pool(x))
+ x = self.block_2(x)
+ features.append(self.avg_pool(x))
+ x = self.block_3(x)
+ content = self.content_layer(x)
+ features.append(self.avg_pool(x))
+ x = self.block_4(x)
+ features.append(self.avg_pool(x))
+ x = torch.cat(features, dim=1)
+ x = x.view(x.size(0), -1)
+ return self.apply_head(x), content
+
+
+class FeatureEncoderMult(FeatureEncoder):
+ def __init__(self, fs_layers=(5,), ranks=None, **kwargs):
+ super().__init__(**kwargs)
+
+ self.fs_layers = fs_layers
+ self.content_layer = nn.ModuleList()
+ self.ranks = ranks
+ shift = 0 if max(fs_layers) <= 7 else 2
+ scale = 1 if max(fs_layers) <= 7 else 2
+ for i in range(len(fs_layers)):
+ if ranks is not None:
+ stride, kern = ranks_data[ranks[i] - shift]
+ layer1 = nn.Sequential(
+ nn.BatchNorm2d(256 // scale, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.Conv2d(256 // scale, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.PReLU(num_parameters=512),
+ nn.Conv2d(512, 512, kernel_size=(fs_kernals[fs_layers[i] - shift][0], kern),
+ stride=(fs_strides[fs_layers[i] - shift][0], stride),
+ padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
+ )
+ layer2 = nn.Sequential(
+ nn.BatchNorm2d(256 // scale, eps=1e-05, momentum=0.1, affine=True,
+ track_running_stats=True),
+ nn.Conv2d(256 // scale, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1),
+ bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
+ track_running_stats=True),
+ nn.PReLU(num_parameters=512),
+ nn.Conv2d(512, 512, kernel_size=(kern, fs_kernals[fs_layers[i] - shift][1]),
+ stride=(stride, fs_strides[fs_layers[i] - shift][1]),
+ padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True,
+ track_running_stats=True)
+ )
+ layer = nn.ModuleList([layer1, layer2])
+ else:
+ layer = nn.Sequential(
+ nn.BatchNorm2d(256 // scale, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.Conv2d(256 // scale, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
+ nn.PReLU(num_parameters=512),
+ nn.Conv2d(512, 512, kernel_size=fs_kernals[fs_layers[i] - shift],
+ stride=fs_strides[fs_layers[i] - shift],
+ padding=(1, 1), bias=False),
+ nn.BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
+ )
+ self.content_layer.append(layer)
+
+ def forward(self, x):
+ x = transform_to_256(x)
+ features = []
+ content = []
+ x = self.conv(x)
+ x = self.block_1(x)
+ features.append(self.avg_pool(x))
+ x = self.block_2(x)
+ if max(self.fs_layers) > 7:
+ for layer in self.content_layer:
+ if self.ranks is not None:
+ mat1 = layer[0](x)
+ mat2 = layer[1](x)
+ content.append(torch.matmul(mat1, mat2))
+ else:
+ content.append(layer(x))
+ features.append(self.avg_pool(x))
+ x = self.block_3(x)
+ if len(content) == 0:
+ for layer in self.content_layer:
+ if self.ranks is not None:
+ mat1 = layer[0](x)
+ mat2 = layer[1](x)
+ content.append(torch.matmul(mat1, mat2))
+ else:
+ content.append(layer(x))
+ features.append(self.avg_pool(x))
+ x = self.block_4(x)
+ features.append(self.avg_pool(x))
+ x = torch.cat(features, dim=1)
+ x = x.view(x.size(0), -1)
+ return self.apply_head(x), content
+
+
+def get_keys(d, name, key="state_dict"):
+ if key in d:
+ d = d[key]
+ d_filt = {k[len(name) + 1:]: v for k, v in d.items() if k[: len(name) + 1] == name + '.'}
+ return d_filt
diff --git a/models/STAR/.DS_Store b/models/STAR/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..4f0e9920a4ea9e5ab371e5d28a21d90745a36d19
Binary files /dev/null and b/models/STAR/.DS_Store differ
diff --git a/models/STAR/README.md b/models/STAR/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..68abf0f118dd6641b30e820f1e25b21be3c538f1
--- /dev/null
+++ b/models/STAR/README.md
@@ -0,0 +1,110 @@
+# STAR Loss: Reducing Semantic Ambiguity in Facial Landmark Detection.
+
+Paper Link: [arxiv](https://arxiv.org/abs/2306.02763) | [CVPR 2023](https://openaccess.thecvf.com/content/CVPR2023/papers/Zhou_STAR_Loss_Reducing_Semantic_Ambiguity_in_Facial_Landmark_Detection_CVPR_2023_paper.pdf)
+
+
+- Pytorch implementation of **S**elf-adap**T**ive **A**mbiguity **R**eduction (**STAR**) loss.
+- STAR loss is a self-adaptive anisotropic direction loss, which can be used in heatmap regression-based methods for facial landmark detection.
+- Specifically, we find that semantic ambiguity results in the anisotropic predicted distribution, which inspires us to use predicted distribution to represent semantic ambiguity. So, we use PCA to indicate the character of the predicted distribution and indirectly formulate the direction and intensity of semantic ambiguity. Based on this, STAR loss adaptively suppresses the prediction error in the ambiguity direction to mitigate the impact of ambiguity annotation in training. More details can be found in our paper.
+
+  +
+
+
+
+
+
+## Dependencies
+
+* python==3.7.3
+* PyTorch=1.6.0
+* requirements.txt
+
+## Dataset Preparation
+
+ - Step1: Download the raw images from [COFW](http://www.vision.caltech.edu/xpburgos/ICCV13/#dataset), [300W](https://ibug.doc.ic.ac.uk/resources/300-W/), and [WFLW](https://wywu.github.io/projects/LAB/WFLW.html).
+ - Step2: We follow the data preprocess in [ADNet](https://openaccess.thecvf.com/content/ICCV2021/papers/Huang_ADNet_Leveraging_Error-Bias_Towards_Normal_Direction_in_Face_Alignment_ICCV_2021_paper.pdf), and the metadata can be download from [the corresponding repository](https://github.com/huangyangyu/ADNet).
+ - Step3: Make them look like this:
+```script
+# the dataset directory:
+|-- ${image_dir}
+ |-- WFLW
+ | -- WFLW_images
+ |-- 300W
+ | -- afw
+ | -- helen
+ | -- ibug
+ | -- lfpw
+ |-- COFW
+ | -- train
+ | -- test
+|-- ${annot_dir}
+ |-- WFLW
+ |-- train.tsv, test.tsv
+ |-- 300W
+ |-- train.tsv, test.tsv
+ |--COFW
+ |-- train.tsv, test.tsv
+```
+
+## Usage
+* Work directory: set the ${ckpt_dir} in ./conf/alignment.py.
+* Pretrained model:
+
+| Dataset | Model |
+|:-----------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| WFLW | [google](https://drive.google.com/file/d/1aOx0wYEZUfBndYy_8IYszLPG_D2fhxrT/view?usp=sharing) / [baidu](https://pan.baidu.com/s/10vvI-ovs3x9NrdmpnXK6sg?pwd=u0yu) |
+| 300W | [google](https://drive.google.com/file/d/1Fiu3hjjkQRdKsWE9IgyNPdiJSz9_MzA5/view?usp=sharing) / [baidu](https://pan.baidu.com/s/1bjUhLq1zS1XSl1nX78fU7A?pwd=yb2s) |
+| COFW | [google](https://drive.google.com/file/d/1NFcZ9jzql_jnn3ulaSzUlyhS05HWB9n_/view?usp=drive_link) / [baidu](https://pan.baidu.com/s/1XO6hDZ8siJLTgFcpyu1Tzw?pwd=m57n) |
+
+
+### Training
+```shell
+python main.py --mode=train --device_ids=0,1,2,3 \
+ --image_dir=${image_dir} --annot_dir=${annot_dir} \
+ --data_definition={WFLW, 300W, COFW}
+```
+
+### Testing
+```shell
+python main.py --mode=test --device_ids=0 \
+ --image_dir=${image_dir} --annot_dir=${annot_dir} \
+ --data_definition={WFLW, 300W, COFW} \
+ --pretrained_weight=${model_path} \
+```
+
+### Evaluation
+```shell
+python evaluate.py --device_ids=0 \
+ --model_path=${model_path} --metadata_path=${metadata_path} \
+ --image_dir=${image_dir} --data_definition={WFLW, 300W, COFW} \
+```
+
+To test on your own image, the following code could be considered:
+```shell
+python demo.py
+```
+
+
+## Results
+The models trained by STAR Loss achieved **SOTA** performance in all of COFW, 300W and WFLW datasets.
+
+
+  +
+
+
+## BibTeX Citation
+Please consider citing our papers in your publications if the project helps your research. BibTeX reference is as follows.
+```
+@inproceedings{Zhou_2023_CVPR,
+ author = {Zhou, Zhenglin and Li, Huaxia and Liu, Hong and Wang, Nanyang and Yu, Gang and Ji, Rongrong},
+ title = {STAR Loss: Reducing Semantic Ambiguity in Facial Landmark Detection},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2023},
+ pages = {15475-15484}
+}
+```
+
+## Acknowledgments
+This repository is built on top of [ADNet](https://github.com/huangyangyu/ADNet).
+Thanks for this strong baseline.
diff --git a/models/STAR/conf/__init__.py b/models/STAR/conf/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f92d0e82f402d1599c16deb5d1f0c3bb568bfb3
--- /dev/null
+++ b/models/STAR/conf/__init__.py
@@ -0,0 +1 @@
+from .alignment import Alignment
\ No newline at end of file
diff --git a/models/STAR/conf/alignment.py b/models/STAR/conf/alignment.py
new file mode 100644
index 0000000000000000000000000000000000000000..34adf12a2ab7d14f189cac4b842cf81e19b65938
--- /dev/null
+++ b/models/STAR/conf/alignment.py
@@ -0,0 +1,228 @@
+import os.path as osp
+from .base import Base
+
+
+class Alignment(Base):
+ """
+ Alignment configure file, which contains training parameters of alignment.
+ """
+
+ def __init__(self, args):
+ super(Alignment, self).__init__('alignment')
+ self.ckpt_dir = '/apdcephfs_cq3/share_1134483/charlinzhou/ckpts/STAR/'
+ self.net = "stackedHGnet_v1"
+ self.nstack = 4
+ self.loader_type = "alignment"
+ self.data_definition = "WFLW" # COFW, 300W, WFLW
+ self.test_file = "test.tsv"
+
+ # image
+ self.channels = 3
+ self.width = 256
+ self.height = 256
+ self.means = (127.5, 127.5, 127.5)
+ self.scale = 1 / 127.5
+ self.aug_prob = 1.0
+
+ self.display_iteration = 10
+ self.val_epoch = 1
+ self.valset = "test.tsv"
+ self.norm_type = 'default'
+ self.encoder_type = 'default'
+ self.decoder_type = 'default'
+
+ # scheduler & optimizer
+ self.milestones = [200, 350, 450]
+ self.max_epoch = 500
+ self.optimizer = "adam"
+ self.learn_rate = 0.001
+ self.weight_decay = 0.00001
+ self.betas = [0.9, 0.999]
+ self.gamma = 0.1
+
+ # batch_size & workers
+ self.batch_size = 32
+ self.train_num_workers = 16
+ self.val_batch_size = 32
+ self.val_num_workers = 16
+ self.test_batch_size = 16
+ self.test_num_workers = 0
+
+ # tricks
+ self.ema = True
+ self.add_coord = True
+ self.use_AAM = True
+
+ # loss
+ self.loss_func = "STARLoss_v2"
+
+ # STAR Loss paras
+ self.star_w = 1
+ self.star_dist = 'smoothl1'
+
+ self.init_from_args(args)
+
+ # COFW
+ if self.data_definition == "COFW":
+ self.edge_info = (
+ (True, (0, 4, 2, 5)), # RightEyebrow
+ (True, (1, 6, 3, 7)), # LeftEyebrow
+ (True, (8, 12, 10, 13)), # RightEye
+ (False, (9, 14, 11, 15)), # LeftEye
+ (True, (18, 20, 19, 21)), # Nose
+ (True, (22, 26, 23, 27)), # LowerLip
+ (True, (22, 24, 23, 25)), # UpperLip
+ )
+ if self.norm_type == 'ocular':
+ self.nme_left_index = 8 # ocular
+ self.nme_right_index = 9 # ocular
+ elif self.norm_type in ['pupil', 'default']:
+ self.nme_left_index = 16 # pupil
+ self.nme_right_index = 17 # pupil
+ else:
+ raise NotImplementedError
+ self.classes_num = [29, 7, 29]
+ self.crop_op = True
+ self.flip_mapping = (
+ [0, 1], [4, 6], [2, 3], [5, 7], [8, 9], [10, 11], [12, 14], [16, 17], [13, 15], [18, 19], [22, 23],
+ )
+ self.image_dir = osp.join(self.image_dir, 'COFW')
+ # 300W
+ elif self.data_definition == "300W":
+ self.edge_info = (
+ (False, (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)), # FaceContour
+ (False, (17, 18, 19, 20, 21)), # RightEyebrow
+ (False, (22, 23, 24, 25, 26)), # LeftEyebrow
+ (False, (27, 28, 29, 30)), # NoseLine
+ (False, (31, 32, 33, 34, 35)), # Nose
+ (True, (36, 37, 38, 39, 40, 41)), # RightEye
+ (True, (42, 43, 44, 45, 46, 47)), # LeftEye
+ (True, (48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59)), # OuterLip
+ (True, (60, 61, 62, 63, 64, 65, 66, 67)), # InnerLip
+ )
+ if self.norm_type in ['ocular', 'default']:
+ self.nme_left_index = 36 # ocular
+ self.nme_right_index = 45 # ocular
+ elif self.norm_type == 'pupil':
+ self.nme_left_index = [36, 37, 38, 39, 40, 41] # pupil
+ self.nme_right_index = [42, 43, 44, 45, 46, 47] # pupil
+ else:
+ raise NotImplementedError
+ self.classes_num = [68, 9, 68]
+ self.crop_op = True
+ self.flip_mapping = (
+ [0, 16], [1, 15], [2, 14], [3, 13], [4, 12], [5, 11], [6, 10], [7, 9],
+ [17, 26], [18, 25], [19, 24], [20, 23], [21, 22],
+ [31, 35], [32, 34],
+ [36, 45], [37, 44], [38, 43], [39, 42], [40, 47], [41, 46],
+ [48, 54], [49, 53], [50, 52], [61, 63], [60, 64], [67, 65], [58, 56], [59, 55],
+ )
+ self.image_dir = osp.join(self.image_dir, '300W')
+ # 300VW
+ elif self.data_definition == "300VW":
+ self.edge_info = (
+ (False, (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)), # FaceContour
+ (False, (17, 18, 19, 20, 21)), # RightEyebrow
+ (False, (22, 23, 24, 25, 26)), # LeftEyebrow
+ (False, (27, 28, 29, 30)), # NoseLine
+ (False, (31, 32, 33, 34, 35)), # Nose
+ (True, (36, 37, 38, 39, 40, 41)), # RightEye
+ (True, (42, 43, 44, 45, 46, 47)), # LeftEye
+ (True, (48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59)), # OuterLip
+ (True, (60, 61, 62, 63, 64, 65, 66, 67)), # InnerLip
+ )
+ if self.norm_type in ['ocular', 'default']:
+ self.nme_left_index = 36 # ocular
+ self.nme_right_index = 45 # ocular
+ elif self.norm_type == 'pupil':
+ self.nme_left_index = [36, 37, 38, 39, 40, 41] # pupil
+ self.nme_right_index = [42, 43, 44, 45, 46, 47] # pupil
+ else:
+ raise NotImplementedError
+ self.classes_num = [68, 9, 68]
+ self.crop_op = True
+ self.flip_mapping = (
+ [0, 16], [1, 15], [2, 14], [3, 13], [4, 12], [5, 11], [6, 10], [7, 9],
+ [17, 26], [18, 25], [19, 24], [20, 23], [21, 22],
+ [31, 35], [32, 34],
+ [36, 45], [37, 44], [38, 43], [39, 42], [40, 47], [41, 46],
+ [48, 54], [49, 53], [50, 52], [61, 63], [60, 64], [67, 65], [58, 56], [59, 55],
+ )
+ self.image_dir = osp.join(self.image_dir, '300VW_Dataset_2015_12_14')
+ # WFLW
+ elif self.data_definition == "WFLW":
+ self.edge_info = (
+ (False, (
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
+ 27,
+ 28, 29, 30, 31, 32)), # FaceContour
+ (True, (33, 34, 35, 36, 37, 38, 39, 40, 41)), # RightEyebrow
+ (True, (42, 43, 44, 45, 46, 47, 48, 49, 50)), # LeftEyebrow
+ (False, (51, 52, 53, 54)), # NoseLine
+ (False, (55, 56, 57, 58, 59)), # Nose
+ (True, (60, 61, 62, 63, 64, 65, 66, 67)), # RightEye
+ (True, (68, 69, 70, 71, 72, 73, 74, 75)), # LeftEye
+ (True, (76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87)), # OuterLip
+ (True, (88, 89, 90, 91, 92, 93, 94, 95)), # InnerLip
+ )
+ if self.norm_type in ['ocular', 'default']:
+ self.nme_left_index = 60 # ocular
+ self.nme_right_index = 72 # ocular
+ elif self.norm_type == 'pupil':
+ self.nme_left_index = 96 # pupils
+ self.nme_right_index = 97 # pupils
+ else:
+ raise NotImplementedError
+ self.classes_num = [98, 9, 98]
+ self.crop_op = True
+ self.flip_mapping = (
+ [0, 32], [1, 31], [2, 30], [3, 29], [4, 28], [5, 27], [6, 26], [7, 25], [8, 24], [9, 23], [10, 22],
+ [11, 21], [12, 20], [13, 19], [14, 18], [15, 17], # cheek
+ [33, 46], [34, 45], [35, 44], [36, 43], [37, 42], [38, 50], [39, 49], [40, 48], [41, 47], # elbrow
+ [60, 72], [61, 71], [62, 70], [63, 69], [64, 68], [65, 75], [66, 74], [67, 73],
+ [55, 59], [56, 58],
+ [76, 82], [77, 81], [78, 80], [87, 83], [86, 84],
+ [88, 92], [89, 91], [95, 93], [96, 97]
+ )
+ self.image_dir = osp.join(self.image_dir, 'WFLW', 'WFLW_images')
+
+ self.label_num = self.nstack * 3 if self.use_AAM else self.nstack
+ self.loss_weights, self.criterions, self.metrics = [], [], []
+ for i in range(self.nstack):
+ factor = (2 ** i) / (2 ** (self.nstack - 1))
+ if self.use_AAM:
+ self.loss_weights += [factor * weight for weight in [1.0, 10.0, 10.0]]
+ self.criterions += [self.loss_func, "AWingLoss", "AWingLoss"]
+ self.metrics += ["NME", None, None]
+ else:
+ self.loss_weights += [factor * weight for weight in [1.0]]
+ self.criterions += [self.loss_func, ]
+ self.metrics += ["NME", ]
+
+ self.key_metric_index = (self.nstack - 1) * 3 if self.use_AAM else (self.nstack - 1)
+
+ # data
+ self.folder = self.get_foldername()
+ self.work_dir = osp.join(self.ckpt_dir, self.data_definition, self.folder)
+ self.model_dir = osp.join(self.work_dir, 'model')
+ self.log_dir = osp.join(self.work_dir, 'log')
+
+ self.train_tsv_file = osp.join(self.annot_dir, self.data_definition, "train.tsv")
+ self.train_pic_dir = self.image_dir
+
+ self.val_tsv_file = osp.join(self.annot_dir, self.data_definition, self.valset)
+ self.val_pic_dir = self.image_dir
+
+ self.test_tsv_file = osp.join(self.annot_dir, self.data_definition, self.test_file)
+ self.test_pic_dir = self.image_dir
+
+ def get_foldername(self):
+ str = ''
+ str += '{}_{}x{}_{}_ep{}_lr{}_bs{}'.format(self.data_definition, self.height, self.width,
+ self.optimizer, self.max_epoch, self.learn_rate, self.batch_size)
+ str += '_{}'.format(self.loss_func)
+ str += '_{}_{}'.format(self.star_dist, self.star_w) if self.loss_func == 'STARLoss' else ''
+ str += '_AAM' if self.use_AAM else ''
+ str += '_{}'.format(self.valset[:-4]) if self.valset != 'test.tsv' else ''
+ str += '_{}'.format(self.id)
+ return str
diff --git a/models/STAR/conf/base.py b/models/STAR/conf/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2545649666ba3dbc60ad50a542374b3bff2bbbe
--- /dev/null
+++ b/models/STAR/conf/base.py
@@ -0,0 +1,95 @@
+import uuid
+import logging
+import os.path as osp
+from argparse import Namespace
+# from tensorboardX import SummaryWriter
+
+
+class Base:
+ """
+ Base configure file, which contains the basic training parameters and should be inherited by other attribute configure file.
+ """
+
+ def __init__(self, config_name, ckpt_dir='./', image_dir='./', annot_dir='./'):
+ self.type = config_name
+ self.id = str(uuid.uuid4())
+ self.note = ""
+
+ self.ckpt_dir = ckpt_dir
+ self.image_dir = image_dir
+ self.annot_dir = annot_dir
+
+ self.loader_type = "alignment"
+ self.loss_func = "STARLoss"
+
+ # train
+ self.batch_size = 128
+ self.val_batch_size = 1
+ self.test_batch_size = 32
+ self.channels = 3
+ self.width = 256
+ self.height = 256
+
+ # mean values in r, g, b channel.
+ self.means = (127, 127, 127)
+ self.scale = 0.0078125
+
+ self.display_iteration = 100
+ self.milestones = [50, 80]
+ self.max_epoch = 100
+
+ self.net = "stackedHGnet_v1"
+ self.nstack = 4
+
+ # ["adam", "sgd"]
+ self.optimizer = "adam"
+ self.learn_rate = 0.1
+ self.momentum = 0.01 # caffe: 0.99
+ self.weight_decay = 0.0
+ self.nesterov = False
+ self.scheduler = "MultiStepLR"
+ self.gamma = 0.1
+
+ self.loss_weights = [1.0]
+ self.criterions = ["SoftmaxWithLoss"]
+ self.metrics = ["Accuracy"]
+ self.key_metric_index = 0
+ self.classes_num = [1000]
+ self.label_num = len(self.classes_num)
+
+ # model
+ self.ema = False
+ self.use_AAM = True
+
+ # visualization
+ self.writer = None
+
+ # log file
+ self.logger = None
+
+ def init_instance(self):
+ self.writer = SummaryWriter(logdir=self.log_dir, comment=self.type)
+ log_formatter = logging.Formatter("%(asctime)s %(levelname)-8s: %(message)s")
+ root_logger = logging.getLogger()
+ file_handler = logging.FileHandler(osp.join(self.log_dir, "log.txt"))
+ file_handler.setFormatter(log_formatter)
+ file_handler.setLevel(logging.NOTSET)
+ root_logger.addHandler(file_handler)
+ console_handler = logging.StreamHandler()
+ console_handler.setFormatter(log_formatter)
+ console_handler.setLevel(logging.NOTSET)
+ root_logger.addHandler(console_handler)
+ root_logger.setLevel(logging.NOTSET)
+ self.logger = root_logger
+
+ def __del__(self):
+ # tensorboard --logdir self.log_dir
+ if self.writer is not None:
+ # self.writer.export_scalars_to_json(self.log_dir + "visual.json")
+ self.writer.close()
+
+ def init_from_args(self, args: Namespace):
+ args_vars = vars(args)
+ for key, value in args_vars.items():
+ if hasattr(self, key) and value is not None:
+ setattr(self, key, value)
diff --git a/models/STAR/config.json b/models/STAR/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..35831f0d94065ba9b748dfeab3a3bf1aa25f1de3
--- /dev/null
+++ b/models/STAR/config.json
@@ -0,0 +1,15 @@
+{
+ "Token":"bpt4JPotFA6bpdknR9ZDCw",
+ "business_flag": "shadow_cv_face",
+ "model_local_file_path": "/apdcephfs_cq3/share_1134483/charlinzhou/Documents/awesome-tools/jizhi/",
+ "host_num": 1,
+ "host_gpu_num": 1,
+ "GPUName": "V100",
+ "is_elasticity": true,
+ "enable_evicted_pulled_up": true,
+ "task_name": "20230312_slpt_star_bb_init_eigen_box_align_smoothl1-1",
+ "task_flag": "20230312_slpt_star_bb_init_eigen_box_align_smoothl1-1",
+ "model_name": "20230312_slpt_star_bb_init_eigen_box_align_smoothl1-1",
+ "image_full_name": "mirrors.tencent.com/haroldzcli/py36-pytorch1.7.1-torchvision0.8.2-cuda10.1-cudnn7.6",
+ "start_cmd": "./start_slpt.sh /apdcephfs_cq3/share_1134483/charlinzhou/Documents/SLPT_Training train.py --loss_func=star --bb_init --eigen_box --dist_func=align_smoothl1"
+}
diff --git a/models/STAR/demo.py b/models/STAR/demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0025275bf8030b646b0fdd7a6a282f14535d14c
--- /dev/null
+++ b/models/STAR/demo.py
@@ -0,0 +1,267 @@
+import os
+import cv2
+import copy
+import dlib
+import math
+import argparse
+import numpy as np
+import gradio as gr
+from matplotlib import pyplot as plt
+import torch
+# private package
+from lib import utility
+
+
+class GetCropMatrix():
+ """
+ from_shape -> transform_matrix
+ """
+
+ def __init__(self, image_size, target_face_scale, align_corners=False):
+ self.image_size = image_size
+ self.target_face_scale = target_face_scale
+ self.align_corners = align_corners
+
+ def _compose_rotate_and_scale(self, angle, scale, shift_xy, from_center, to_center):
+ cosv = math.cos(angle)
+ sinv = math.sin(angle)
+
+ fx, fy = from_center
+ tx, ty = to_center
+
+ acos = scale * cosv
+ asin = scale * sinv
+
+ a0 = acos
+ a1 = -asin
+ a2 = tx - acos * fx + asin * fy + shift_xy[0]
+
+ b0 = asin
+ b1 = acos
+ b2 = ty - asin * fx - acos * fy + shift_xy[1]
+
+ rot_scale_m = np.array([
+ [a0, a1, a2],
+ [b0, b1, b2],
+ [0.0, 0.0, 1.0]
+ ], np.float32)
+ return rot_scale_m
+
+ def process(self, scale, center_w, center_h):
+ if self.align_corners:
+ to_w, to_h = self.image_size - 1, self.image_size - 1
+ else:
+ to_w, to_h = self.image_size, self.image_size
+
+ rot_mu = 0
+ scale_mu = self.image_size / (scale * self.target_face_scale * 200.0)
+ shift_xy_mu = (0, 0)
+ matrix = self._compose_rotate_and_scale(
+ rot_mu, scale_mu, shift_xy_mu,
+ from_center=[center_w, center_h],
+ to_center=[to_w / 2.0, to_h / 2.0])
+ return matrix
+
+
+class TransformPerspective():
+ """
+ image, matrix3x3 -> transformed_image
+ """
+
+ def __init__(self, image_size):
+ self.image_size = image_size
+
+ def process(self, image, matrix):
+ return cv2.warpPerspective(
+ image, matrix, dsize=(self.image_size, self.image_size),
+ flags=cv2.INTER_LINEAR, borderValue=0)
+
+
+class TransformPoints2D():
+ """
+ points (nx2), matrix (3x3) -> points (nx2)
+ """
+
+ def process(self, srcPoints, matrix):
+ # nx3
+ desPoints = np.concatenate([srcPoints, np.ones_like(srcPoints[:, [0]])], axis=1)
+ desPoints = desPoints @ np.transpose(matrix) # nx3
+ desPoints = desPoints[:, :2] / desPoints[:, [2, 2]]
+ return desPoints.astype(srcPoints.dtype)
+
+
+class Alignment:
+ def __init__(self, args, model_path, dl_framework, device_ids):
+ self.input_size = 256
+ self.target_face_scale = 1.0
+ self.dl_framework = dl_framework
+
+ # model
+ if self.dl_framework == "pytorch":
+ # conf
+ self.config = utility.get_config(args)
+ self.config.device_id = device_ids[0]
+ # set environment
+ utility.set_environment(self.config)
+ self.config.init_instance()
+ if self.config.logger is not None:
+ self.config.logger.info("Loaded configure file %s: %s" % (args.config_name, self.config.id))
+ self.config.logger.info("\n" + "\n".join(["%s: %s" % item for item in self.config.__dict__.items()]))
+
+ net = utility.get_net(self.config)
+ if device_ids == [-1]:
+ checkpoint = torch.load(model_path, map_location="cpu")
+ else:
+ checkpoint = torch.load(model_path)
+ net.load_state_dict(checkpoint["net"])
+ net = net.to(self.config.device_id)
+ net.eval()
+ self.alignment = net
+ else:
+ assert False
+
+ self.getCropMatrix = GetCropMatrix(image_size=self.input_size, target_face_scale=self.target_face_scale,
+ align_corners=True)
+ self.transformPerspective = TransformPerspective(image_size=self.input_size)
+ self.transformPoints2D = TransformPoints2D()
+
+ def norm_points(self, points, align_corners=False):
+ if align_corners:
+ # [0, SIZE-1] -> [-1, +1]
+ return points / torch.tensor([self.input_size - 1, self.input_size - 1]).to(points).view(1, 1, 2) * 2 - 1
+ else:
+ # [-0.5, SIZE-0.5] -> [-1, +1]
+ return (points * 2 + 1) / torch.tensor([self.input_size, self.input_size]).to(points).view(1, 1, 2) - 1
+
+ def denorm_points(self, points, align_corners=False):
+ if align_corners:
+ # [-1, +1] -> [0, SIZE-1]
+ return (points + 1) / 2 * torch.tensor([self.input_size - 1, self.input_size - 1]).to(points).view(1, 1, 2)
+ else:
+ # [-1, +1] -> [-0.5, SIZE-0.5]
+ return ((points + 1) * torch.tensor([self.input_size, self.input_size]).to(points).view(1, 1, 2) - 1) / 2
+
+ def preprocess(self, image, scale, center_w, center_h):
+ matrix = self.getCropMatrix.process(scale, center_w, center_h)
+ input_tensor = self.transformPerspective.process(image, matrix)
+ input_tensor = input_tensor[np.newaxis, :]
+
+ input_tensor = torch.from_numpy(input_tensor)
+ input_tensor = input_tensor.float().permute(0, 3, 1, 2)
+ input_tensor = input_tensor / 255.0 * 2.0 - 1.0
+ input_tensor = input_tensor.to(self.config.device_id)
+ return input_tensor, matrix
+
+ def postprocess(self, srcPoints, coeff):
+ # dstPoints = self.transformPoints2D.process(srcPoints, coeff)
+ # matrix^(-1) * src = dst
+ # src = matrix * dst
+ dstPoints = np.zeros(srcPoints.shape, dtype=np.float32)
+ for i in range(srcPoints.shape[0]):
+ dstPoints[i][0] = coeff[0][0] * srcPoints[i][0] + coeff[0][1] * srcPoints[i][1] + coeff[0][2]
+ dstPoints[i][1] = coeff[1][0] * srcPoints[i][0] + coeff[1][1] * srcPoints[i][1] + coeff[1][2]
+ return dstPoints
+
+ def analyze(self, image, scale, center_w, center_h):
+ input_tensor, matrix = self.preprocess(image, scale, center_w, center_h)
+
+ if self.dl_framework == "pytorch":
+ with torch.no_grad():
+ output = self.alignment(input_tensor)
+ landmarks = output[-1][0]
+ else:
+ assert False
+
+ landmarks = self.denorm_points(landmarks)
+ landmarks = landmarks.data.cpu().numpy()[0]
+ landmarks = self.postprocess(landmarks, np.linalg.inv(matrix))
+
+ return landmarks
+
+
+def draw_pts(img, pts, mode="pts", shift=4, color=(0, 255, 0), radius=1, thickness=1, save_path=None, dif=0,
+ scale=0.3, concat=False, ):
+ img_draw = copy.deepcopy(img)
+ for cnt, p in enumerate(pts):
+ if mode == "index":
+ cv2.putText(img_draw, str(cnt), (int(float(p[0] + dif)), int(float(p[1] + dif))), cv2.FONT_HERSHEY_SIMPLEX,
+ scale, color, thickness)
+ elif mode == 'pts':
+ if len(img_draw.shape) > 2:
+ # 此处来回切换是因为opencv的bug
+ img_draw = cv2.cvtColor(img_draw, cv2.COLOR_BGR2RGB)
+ img_draw = cv2.cvtColor(img_draw, cv2.COLOR_RGB2BGR)
+ cv2.circle(img_draw, (int(p[0] * (1 << shift)), int(p[1] * (1 << shift))), radius << shift, color, -1,
+ cv2.LINE_AA, shift=shift)
+ else:
+ raise NotImplementedError
+ if concat:
+ img_draw = np.concatenate((img, img_draw), axis=1)
+ if save_path is not None:
+ cv2.imwrite(save_path, img_draw)
+ return img_draw
+
+
+def process(input_image):
+ image_draw = copy.deepcopy(input_image)
+ dets = detector(input_image, 1)
+
+ num_faces = len(dets)
+ if num_faces == 0:
+ print("Sorry, there were no faces found in '{}'".format(face_file_path))
+ exit()
+
+ results = []
+ for detection in dets:
+ face = sp(input_image, detection)
+ shape = []
+ for i in range(68):
+ x = face.part(i).x
+ y = face.part(i).y
+ shape.append((x, y))
+ shape = np.array(shape)
+ # image_draw = draw_pts(image_draw, shape)
+ x1, x2 = shape[:, 0].min(), shape[:, 0].max()
+ y1, y2 = shape[:, 1].min(), shape[:, 1].max()
+ scale = min(x2 - x1, y2 - y1) / 200 * 1.05
+ center_w = (x2 + x1) / 2
+ center_h = (y2 + y1) / 2
+
+ scale, center_w, center_h = float(scale), float(center_w), float(center_h)
+ landmarks_pv = alignment.analyze(input_image, scale, center_w, center_h)
+ results.append(landmarks_pv)
+ image_draw = draw_pts(image_draw, landmarks_pv)
+ return image_draw, results
+
+
+if __name__ == '__main__':
+ # face detector
+ # could be downloaded in this repo: https://github.com/italojs/facial-landmarks-recognition/tree/master
+ predictor_path = '/path/to/shape_predictor_68_face_landmarks.dat'
+ detector = dlib.get_frontal_face_detector()
+ sp = dlib.shape_predictor(predictor_path)
+
+ # facial landmark detector
+ args = argparse.Namespace()
+ args.config_name = 'alignment'
+ # could be downloaded here: https://drive.google.com/file/d/1aOx0wYEZUfBndYy_8IYszLPG_D2fhxrT/view
+ model_path = '/path/to/WFLW_STARLoss_NME_4_02_FR_2_32_AUC_0_605.pkl'
+ device_ids = '0'
+ device_ids = list(map(int, device_ids.split(",")))
+ alignment = Alignment(args, model_path, dl_framework="pytorch", device_ids=device_ids)
+
+ # image: input image
+ # image_draw: draw the detected facial landmarks on image
+ # results: a list of detected facial landmarks
+ face_file_path = '/path/to/face/image/bald_guys.jpg'
+ image = cv2.imread(face_file_path)
+ image_draw, results = process(image)
+
+ # visualize
+ img = cv2.cvtColor(image_draw, cv2.COLOR_BGR2RGB)
+ plt.imshow(img)
+ plt.show()
+
+ # demo
+ # interface = gr.Interface(fn=process, inputs="image", outputs="image")
+ # interface.launch(share=True)
diff --git a/models/STAR/evaluate.py b/models/STAR/evaluate.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c9b759381559cf32f9e461dc2e3c26b92d8dda0
--- /dev/null
+++ b/models/STAR/evaluate.py
@@ -0,0 +1,258 @@
+import os
+import cv2
+import math
+import argparse
+import numpy as np
+from tqdm import tqdm
+
+import torch
+
+# private package
+from lib import utility
+
+
+
+class GetCropMatrix():
+ """
+ from_shape -> transform_matrix
+ """
+
+ def __init__(self, image_size, target_face_scale, align_corners=False):
+ self.image_size = image_size
+ self.target_face_scale = target_face_scale
+ self.align_corners = align_corners
+
+ def _compose_rotate_and_scale(self, angle, scale, shift_xy, from_center, to_center):
+ cosv = math.cos(angle)
+ sinv = math.sin(angle)
+
+ fx, fy = from_center
+ tx, ty = to_center
+
+ acos = scale * cosv
+ asin = scale * sinv
+
+ a0 = acos
+ a1 = -asin
+ a2 = tx - acos * fx + asin * fy + shift_xy[0]
+
+ b0 = asin
+ b1 = acos
+ b2 = ty - asin * fx - acos * fy + shift_xy[1]
+
+ rot_scale_m = np.array([
+ [a0, a1, a2],
+ [b0, b1, b2],
+ [0.0, 0.0, 1.0]
+ ], np.float32)
+ return rot_scale_m
+
+ def process(self, scale, center_w, center_h):
+ if self.align_corners:
+ to_w, to_h = self.image_size - 1, self.image_size - 1
+ else:
+ to_w, to_h = self.image_size, self.image_size
+
+ rot_mu = 0
+ scale_mu = self.image_size / (scale * self.target_face_scale * 200.0)
+ shift_xy_mu = (0, 0)
+ matrix = self._compose_rotate_and_scale(
+ rot_mu, scale_mu, shift_xy_mu,
+ from_center=[center_w, center_h],
+ to_center=[to_w / 2.0, to_h / 2.0])
+ return matrix
+
+
+class TransformPerspective():
+ """
+ image, matrix3x3 -> transformed_image
+ """
+
+ def __init__(self, image_size):
+ self.image_size = image_size
+
+ def process(self, image, matrix):
+ return cv2.warpPerspective(
+ image, matrix, dsize=(self.image_size, self.image_size),
+ flags=cv2.INTER_LINEAR, borderValue=0)
+
+
+class TransformPoints2D():
+ """
+ points (nx2), matrix (3x3) -> points (nx2)
+ """
+
+ def process(self, srcPoints, matrix):
+ # nx3
+ desPoints = np.concatenate([srcPoints, np.ones_like(srcPoints[:, [0]])], axis=1)
+ desPoints = desPoints @ np.transpose(matrix) # nx3
+ desPoints = desPoints[:, :2] / desPoints[:, [2, 2]]
+ return desPoints.astype(srcPoints.dtype)
+
+
+class Alignment:
+ def __init__(self, args, model_path, dl_framework, device_ids):
+ self.input_size = 256
+ self.target_face_scale = 1.0
+ self.dl_framework = dl_framework
+
+ # model
+ if self.dl_framework == "pytorch":
+ # conf
+ self.config = utility.get_config(args)
+ self.config.device_id = device_ids[0]
+ # set environment
+ utility.set_environment(self.config)
+ self.config.init_instance()
+ if self.config.logger is not None:
+ self.config.logger.info("Loaded configure file %s: %s" % (args.config_name, self.config.id))
+ self.config.logger.info("\n" + "\n".join(["%s: %s" % item for item in self.config.__dict__.items()]))
+
+ net = utility.get_net(self.config)
+ if device_ids == [-1]:
+ checkpoint = torch.load(model_path, map_location="cpu")
+ else:
+ checkpoint = torch.load(model_path)
+ net.load_state_dict(checkpoint["net"])
+ net = net.to(self.config.device_id)
+ net.eval()
+ self.alignment = net
+ else:
+ assert False
+
+ self.getCropMatrix = GetCropMatrix(image_size=self.input_size, target_face_scale=self.target_face_scale,
+ align_corners=True)
+ self.transformPerspective = TransformPerspective(image_size=self.input_size)
+ self.transformPoints2D = TransformPoints2D()
+
+ def norm_points(self, points, align_corners=False):
+ if align_corners:
+ # [0, SIZE-1] -> [-1, +1]
+ return points / torch.tensor([self.input_size - 1, self.input_size - 1]).to(points).view(1, 1, 2) * 2 - 1
+ else:
+ # [-0.5, SIZE-0.5] -> [-1, +1]
+ return (points * 2 + 1) / torch.tensor([self.input_size, self.input_size]).to(points).view(1, 1, 2) - 1
+
+ def denorm_points(self, points, align_corners=False):
+ if align_corners:
+ # [-1, +1] -> [0, SIZE-1]
+ return (points + 1) / 2 * torch.tensor([self.input_size - 1, self.input_size - 1]).to(points).view(1, 1, 2)
+ else:
+ # [-1, +1] -> [-0.5, SIZE-0.5]
+ return ((points + 1) * torch.tensor([self.input_size, self.input_size]).to(points).view(1, 1, 2) - 1) / 2
+
+ def preprocess(self, image, scale, center_w, center_h):
+ matrix = self.getCropMatrix.process(scale, center_w, center_h)
+ input_tensor = self.transformPerspective.process(image, matrix)
+ input_tensor = input_tensor[np.newaxis, :]
+
+ input_tensor = torch.from_numpy(input_tensor)
+ input_tensor = input_tensor.float().permute(0, 3, 1, 2)
+ input_tensor = input_tensor / 255.0 * 2.0 - 1.0
+ input_tensor = input_tensor.to(self.config.device_id)
+ return input_tensor, matrix
+
+ def postprocess(self, srcPoints, coeff):
+ # dstPoints = self.transformPoints2D.process(srcPoints, coeff)
+ # matrix^(-1) * src = dst
+ # src = matrix * dst
+ dstPoints = np.zeros(srcPoints.shape, dtype=np.float32)
+ for i in range(srcPoints.shape[0]):
+ dstPoints[i][0] = coeff[0][0] * srcPoints[i][0] + coeff[0][1] * srcPoints[i][1] + coeff[0][2]
+ dstPoints[i][1] = coeff[1][0] * srcPoints[i][0] + coeff[1][1] * srcPoints[i][1] + coeff[1][2]
+ return dstPoints
+
+ def analyze(self, image, scale, center_w, center_h):
+ input_tensor, matrix = self.preprocess(image, scale, center_w, center_h)
+
+ if self.dl_framework == "pytorch":
+ with torch.no_grad():
+ output = self.alignment(input_tensor)
+ landmarks = output[-1][0]
+ else:
+ assert False
+
+ landmarks = self.denorm_points(landmarks)
+ landmarks = landmarks.data.cpu().numpy()[0]
+ landmarks = self.postprocess(landmarks, np.linalg.inv(matrix))
+
+ return landmarks
+
+
+def L2(p1, p2):
+ return np.linalg.norm(p1 - p2)
+
+
+def NME(landmarks_gt, landmarks_pv):
+ pts_num = landmarks_gt.shape[0]
+ if pts_num == 29:
+ left_index = 16
+ right_index = 17
+ elif pts_num == 68:
+ left_index = 36
+ right_index = 45
+ elif pts_num == 98:
+ left_index = 60
+ right_index = 72
+
+ nme = 0
+ eye_span = L2(landmarks_gt[left_index], landmarks_gt[right_index])
+ for i in range(pts_num):
+ error = L2(landmarks_pv[i], landmarks_gt[i])
+ nme += error / eye_span
+ nme /= pts_num
+ return nme
+
+
+def evaluate(args, model_path, metadata_path, device_ids, mode):
+ alignment = Alignment(args, model_path, dl_framework="pytorch", device_ids=device_ids)
+ config = alignment.config
+ nme_sum = 0
+ with open(metadata_path, 'r') as f:
+ lines = f.readlines()
+ for k, line in enumerate(tqdm(lines)):
+ item = line.strip().split("\t")
+ image_name, landmarks_5pts, landmarks_gt, scale, center_w, center_h = item[:6]
+ # image & keypoints alignment
+ image_name = image_name.replace('\\', '/')
+ image_name = image_name.replace('//msr-facestore/Workspace/MSRA_EP_Allergan/users/yanghuan/training_data/wflw/rawImages/', '')
+ image_name = image_name.replace('./rawImages/', '')
+ image_path = os.path.join(config.image_dir, image_name)
+ landmarks_gt = np.array(list(map(float, landmarks_gt.split(","))), dtype=np.float32).reshape(-1, 2)
+ scale, center_w, center_h = float(scale), float(center_w), float(center_h)
+
+ image = cv2.imread(image_path)
+ landmarks_pv = alignment.analyze(image, scale, center_w, center_h)
+
+ # NME
+ if mode == "nme":
+ nme = NME(landmarks_gt, landmarks_pv)
+ nme_sum += nme
+ # print("Current NME(%d): %f" % (k + 1, (nme_sum / (k + 1))))
+ else:
+ pass
+
+ if mode == "nme":
+ print("Final NME: %f" % (nme_sum / (k + 1)))
+ else:
+ pass
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Evaluation script")
+ parser.add_argument("--config_name", type=str, default="alignment", help="set configure file name")
+ parser.add_argument("--model_path", type=str, default="./train.pkl", help="the path of model")
+ parser.add_argument("--data_definition", type=str, default='WFLW', help="COFW/300W/WFLW")
+ parser.add_argument("--metadata_path", type=str, default="", help="the path of metadata")
+ parser.add_argument("--image_dir", type=str, default="", help="the path of image")
+ parser.add_argument("--device_ids", type=str, default="0", help="set device ids, -1 means use cpu device, >= 0 means use gpu device")
+ parser.add_argument("--mode", type=str, default="nme", help="set the evaluate mode: nme")
+ args = parser.parse_args()
+
+ device_ids = list(map(int, args.device_ids.split(",")))
+ evaluate(
+ args,
+ model_path=args.model_path,
+ metadata_path=args.metadata_path,
+ device_ids=device_ids,
+ mode=args.mode)
diff --git a/models/STAR/lib/.DS_Store b/models/STAR/lib/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..0a46003cbfa5d371dab2d128e02e050380ec0cec
Binary files /dev/null and b/models/STAR/lib/.DS_Store differ
diff --git a/models/STAR/lib/__init__.py b/models/STAR/lib/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff08a78fc3315c65bc061eb1a42a3e8cc90b9b8d
--- /dev/null
+++ b/models/STAR/lib/__init__.py
@@ -0,0 +1,9 @@
+from .dataset import get_encoder, get_decoder
+from .dataset import AlignmentDataset, Augmentation
+from .backbone import StackedHGNetV1
+from .metric import NME, Accuracy
+from .utils import time_print, time_string, time_for_file, time_string_short
+from .utils import convert_secs2time, convert_size2str
+
+from .utility import get_dataloader, get_config, get_net, get_criterions
+from .utility import get_optimizer, get_scheduler
diff --git a/models/STAR/lib/backbone/__init__.py b/models/STAR/lib/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b967103849100c921d4ecceb7a25142fa5ded6f6
--- /dev/null
+++ b/models/STAR/lib/backbone/__init__.py
@@ -0,0 +1,5 @@
+from .stackedHGNetV1 import StackedHGNetV1
+
+__all__ = [
+ "StackedHGNetV1",
+]
\ No newline at end of file
diff --git a/models/STAR/lib/backbone/core/coord_conv.py b/models/STAR/lib/backbone/core/coord_conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..0eb8e2d6ec574b77576970b6e6aef20c62887228
--- /dev/null
+++ b/models/STAR/lib/backbone/core/coord_conv.py
@@ -0,0 +1,157 @@
+import torch
+import torch.nn as nn
+
+
+class AddCoordsTh(nn.Module):
+ def __init__(self, x_dim, y_dim, with_r=False, with_boundary=False):
+ super(AddCoordsTh, self).__init__()
+ self.x_dim = x_dim
+ self.y_dim = y_dim
+ self.with_r = with_r
+ self.with_boundary = with_boundary
+
+ def forward(self, input_tensor, heatmap=None):
+ """
+ input_tensor: (batch, c, x_dim, y_dim)
+ """
+ batch_size_tensor = input_tensor.shape[0]
+
+ xx_ones = torch.ones([1, self.y_dim], dtype=torch.int32).to(input_tensor)
+ xx_ones = xx_ones.unsqueeze(-1)
+
+ xx_range = torch.arange(self.x_dim, dtype=torch.int32).unsqueeze(0).to(input_tensor)
+ xx_range = xx_range.unsqueeze(1)
+
+ xx_channel = torch.matmul(xx_ones.float(), xx_range.float())
+ xx_channel = xx_channel.unsqueeze(-1)
+
+ yy_ones = torch.ones([1, self.x_dim], dtype=torch.int32).to(input_tensor)
+ yy_ones = yy_ones.unsqueeze(1)
+
+ yy_range = torch.arange(self.y_dim, dtype=torch.int32).unsqueeze(0).to(input_tensor)
+ yy_range = yy_range.unsqueeze(-1)
+
+ yy_channel = torch.matmul(yy_range.float(), yy_ones.float())
+ yy_channel = yy_channel.unsqueeze(-1)
+
+ xx_channel = xx_channel.permute(0, 3, 2, 1)
+ yy_channel = yy_channel.permute(0, 3, 2, 1)
+
+ xx_channel = xx_channel / (self.x_dim - 1)
+ yy_channel = yy_channel / (self.y_dim - 1)
+
+ xx_channel = xx_channel * 2 - 1
+ yy_channel = yy_channel * 2 - 1
+
+ xx_channel = xx_channel.repeat(batch_size_tensor, 1, 1, 1)
+ yy_channel = yy_channel.repeat(batch_size_tensor, 1, 1, 1)
+
+ if self.with_boundary and type(heatmap) != type(None):
+ boundary_channel = torch.clamp(heatmap[:, -1:, :, :],
+ 0.0, 1.0)
+
+ zero_tensor = torch.zeros_like(xx_channel).to(xx_channel)
+ xx_boundary_channel = torch.where(boundary_channel>0.05,
+ xx_channel, zero_tensor)
+ yy_boundary_channel = torch.where(boundary_channel>0.05,
+ yy_channel, zero_tensor)
+ ret = torch.cat([input_tensor, xx_channel, yy_channel], dim=1)
+
+
+ if self.with_r:
+ rr = torch.sqrt(torch.pow(xx_channel, 2) + torch.pow(yy_channel, 2))
+ rr = rr / torch.max(rr)
+ ret = torch.cat([ret, rr], dim=1)
+
+ if self.with_boundary and type(heatmap) != type(None):
+ ret = torch.cat([ret, xx_boundary_channel,
+ yy_boundary_channel], dim=1)
+ return ret
+
+
+class CoordConvTh(nn.Module):
+ """CoordConv layer as in the paper."""
+ def __init__(self, x_dim, y_dim, with_r, with_boundary,
+ in_channels, out_channels, first_one=False, relu=False, bn=False, *args, **kwargs):
+ super(CoordConvTh, self).__init__()
+ self.addcoords = AddCoordsTh(x_dim=x_dim, y_dim=y_dim, with_r=with_r,
+ with_boundary=with_boundary)
+ in_channels += 2
+ if with_r:
+ in_channels += 1
+ if with_boundary and not first_one:
+ in_channels += 2
+ self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, *args, **kwargs)
+ self.relu = nn.ReLU() if relu else None
+ self.bn = nn.BatchNorm2d(out_channels) if bn else None
+
+ self.with_boundary = with_boundary
+ self.first_one = first_one
+
+
+ def forward(self, input_tensor, heatmap=None):
+ assert (self.with_boundary and not self.first_one) == (heatmap is not None)
+ ret = self.addcoords(input_tensor, heatmap)
+ ret = self.conv(ret)
+ if self.bn is not None:
+ ret = self.bn(ret)
+ if self.relu is not None:
+ ret = self.relu(ret)
+
+ return ret
+
+
+'''
+An alternative implementation for PyTorch with auto-infering the x-y dimensions.
+'''
+class AddCoords(nn.Module):
+
+ def __init__(self, with_r=False):
+ super().__init__()
+ self.with_r = with_r
+
+ def forward(self, input_tensor):
+ """
+ Args:
+ input_tensor: shape(batch, channel, x_dim, y_dim)
+ """
+ batch_size, _, x_dim, y_dim = input_tensor.size()
+
+ xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1).to(input_tensor)
+ yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2).to(input_tensor)
+
+ xx_channel = xx_channel / (x_dim - 1)
+ yy_channel = yy_channel / (y_dim - 1)
+
+ xx_channel = xx_channel * 2 - 1
+ yy_channel = yy_channel * 2 - 1
+
+ xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
+ yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
+
+ ret = torch.cat([
+ input_tensor,
+ xx_channel.type_as(input_tensor),
+ yy_channel.type_as(input_tensor)], dim=1)
+
+ if self.with_r:
+ rr = torch.sqrt(torch.pow(xx_channel - 0.5, 2) + torch.pow(yy_channel - 0.5, 2))
+ ret = torch.cat([ret, rr], dim=1)
+
+ return ret
+
+
+class CoordConv(nn.Module):
+
+ def __init__(self, in_channels, out_channels, with_r=False, **kwargs):
+ super().__init__()
+ self.addcoords = AddCoords(with_r=with_r)
+ in_channels += 2
+ if with_r:
+ in_channels += 1
+ self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
+
+ def forward(self, x):
+ ret = self.addcoords(x)
+ ret = self.conv(ret)
+ return ret
diff --git a/models/STAR/lib/backbone/stackedHGNetV1.py b/models/STAR/lib/backbone/stackedHGNetV1.py
new file mode 100644
index 0000000000000000000000000000000000000000..471f8faadc534e8805dc1a072dfcf59d185f3117
--- /dev/null
+++ b/models/STAR/lib/backbone/stackedHGNetV1.py
@@ -0,0 +1,307 @@
+import numpy as np
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .core.coord_conv import CoordConvTh
+from models.STAR.lib.dataset import get_decoder
+
+
+
+class Activation(nn.Module):
+ def __init__(self, kind: str = 'relu', channel=None):
+ super().__init__()
+ self.kind = kind
+
+ if '+' in kind:
+ norm_str, act_str = kind.split('+')
+ else:
+ norm_str, act_str = 'none', kind
+
+ self.norm_fn = {
+ 'in': F.instance_norm,
+ 'bn': nn.BatchNorm2d(channel),
+ 'bn_noaffine': nn.BatchNorm2d(channel, affine=False, track_running_stats=True),
+ 'none': None
+ }[norm_str]
+
+ self.act_fn = {
+ 'relu': F.relu,
+ 'softplus': nn.Softplus(),
+ 'exp': torch.exp,
+ 'sigmoid': torch.sigmoid,
+ 'tanh': torch.tanh,
+ 'none': None
+ }[act_str]
+
+ self.channel = channel
+
+ def forward(self, x):
+ if self.norm_fn is not None:
+ x = self.norm_fn(x)
+ if self.act_fn is not None:
+ x = self.act_fn(x)
+ return x
+
+ def extra_repr(self):
+ return f'kind={self.kind}, channel={self.channel}'
+
+
+class ConvBlock(nn.Module):
+ def __init__(self, inp_dim, out_dim, kernel_size=3, stride=1, bn=False, relu=True, groups=1):
+ super(ConvBlock, self).__init__()
+ self.inp_dim = inp_dim
+ self.conv = nn.Conv2d(inp_dim, out_dim, kernel_size,
+ stride, padding=(kernel_size - 1) // 2, groups=groups, bias=True)
+ self.relu = None
+ self.bn = None
+ if relu:
+ self.relu = nn.ReLU()
+ if bn:
+ self.bn = nn.BatchNorm2d(out_dim)
+
+ def forward(self, x):
+ x = self.conv(x)
+ if self.bn is not None:
+ x = self.bn(x)
+ if self.relu is not None:
+ x = self.relu(x)
+ return x
+
+
+class ResBlock(nn.Module):
+ def __init__(self, inp_dim, out_dim, mid_dim=None):
+ super(ResBlock, self).__init__()
+ if mid_dim is None:
+ mid_dim = out_dim // 2
+ self.relu = nn.ReLU()
+ self.bn1 = nn.BatchNorm2d(inp_dim)
+ self.conv1 = ConvBlock(inp_dim, mid_dim, 1, relu=False)
+ self.bn2 = nn.BatchNorm2d(mid_dim)
+ self.conv2 = ConvBlock(mid_dim, mid_dim, 3, relu=False)
+ self.bn3 = nn.BatchNorm2d(mid_dim)
+ self.conv3 = ConvBlock(mid_dim, out_dim, 1, relu=False)
+ self.skip_layer = ConvBlock(inp_dim, out_dim, 1, relu=False)
+ if inp_dim == out_dim:
+ self.need_skip = False
+ else:
+ self.need_skip = True
+
+ def forward(self, x):
+ if self.need_skip:
+ residual = self.skip_layer(x)
+ else:
+ residual = x
+ out = self.bn1(x)
+ out = self.relu(out)
+ out = self.conv1(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+ out = self.conv2(out)
+ out = self.bn3(out)
+ out = self.relu(out)
+ out = self.conv3(out)
+ out += residual
+ return out
+
+
+class Hourglass(nn.Module):
+ def __init__(self, n, f, increase=0, up_mode='nearest',
+ add_coord=False, first_one=False, x_dim=64, y_dim=64):
+ super(Hourglass, self).__init__()
+ nf = f + increase
+
+ Block = ResBlock
+
+ if add_coord:
+ self.coordconv = CoordConvTh(x_dim=x_dim, y_dim=y_dim,
+ with_r=True, with_boundary=True,
+ relu=False, bn=False,
+ in_channels=f, out_channels=f,
+ first_one=first_one,
+ kernel_size=1,
+ stride=1, padding=0)
+ else:
+ self.coordconv = None
+ self.up1 = Block(f, f)
+
+ # Lower branch
+ self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
+
+ self.low1 = Block(f, nf)
+ self.n = n
+ # Recursive hourglass
+ if self.n > 1:
+ self.low2 = Hourglass(n=n - 1, f=nf, increase=increase, up_mode=up_mode, add_coord=False)
+ else:
+ self.low2 = Block(nf, nf)
+ self.low3 = Block(nf, f)
+ self.up2 = nn.Upsample(scale_factor=2, mode=up_mode)
+
+ def forward(self, x, heatmap=None):
+ if self.coordconv is not None:
+ x = self.coordconv(x, heatmap)
+ up1 = self.up1(x)
+ pool1 = self.pool1(x)
+ low1 = self.low1(pool1)
+ low2 = self.low2(low1)
+ low3 = self.low3(low2)
+ up2 = self.up2(low3)
+ return up1 + up2
+
+
+class E2HTransform(nn.Module):
+ def __init__(self, edge_info, num_points, num_edges):
+ super().__init__()
+
+ e2h_matrix = np.zeros([num_points, num_edges])
+ for edge_id, isclosed_indices in enumerate(edge_info):
+ is_closed, indices = isclosed_indices
+ for point_id in indices:
+ e2h_matrix[point_id, edge_id] = 1
+ e2h_matrix = torch.from_numpy(e2h_matrix).float()
+
+ # pn x en x 1 x 1.
+ self.register_buffer('weight', e2h_matrix.view(
+ e2h_matrix.size(0), e2h_matrix.size(1), 1, 1))
+
+ # some keypoints are not coverred by any edges,
+ # in these cases, we must add a constant bias to their heatmap weights.
+ bias = ((e2h_matrix @ torch.ones(e2h_matrix.size(1)).to(
+ e2h_matrix)) < 0.5).to(e2h_matrix)
+ # pn x 1.
+ self.register_buffer('bias', bias)
+
+ def forward(self, edgemaps):
+ # input: batch_size x en x hw x hh.
+ # output: batch_size x pn x hw x hh.
+ return F.conv2d(edgemaps, weight=self.weight, bias=self.bias)
+
+
+class StackedHGNetV1(nn.Module):
+ def __init__(self, config, classes_num, edge_info,
+ nstack=4, nlevels=4, in_channel=256, increase=0,
+ add_coord=True, decoder_type='default'):
+ super(StackedHGNetV1, self).__init__()
+
+ self.cfg = config
+ self.coder_type = decoder_type
+ self.decoder = get_decoder(decoder_type=decoder_type)
+ self.nstack = nstack
+ self.add_coord = add_coord
+
+ self.num_heats = classes_num[0]
+
+ if self.add_coord:
+ convBlock = CoordConvTh(x_dim=self.cfg.width, y_dim=self.cfg.height,
+ with_r=True, with_boundary=False,
+ relu=True, bn=True,
+ in_channels=3, out_channels=64,
+ kernel_size=7,
+ stride=2, padding=3)
+ else:
+ convBlock = ConvBlock(3, 64, 7, 2, bn=True, relu=True)
+
+ pool = nn.MaxPool2d(kernel_size=2, stride=2)
+
+ Block = ResBlock
+
+ self.pre = nn.Sequential(
+ convBlock,
+ Block(64, 128),
+ pool,
+ Block(128, 128),
+ Block(128, in_channel)
+ )
+
+ self.hgs = nn.ModuleList(
+ [Hourglass(n=nlevels, f=in_channel, increase=increase, add_coord=self.add_coord, first_one=(_ == 0),
+ x_dim=int(self.cfg.width / self.nstack), y_dim=int(self.cfg.height / self.nstack))
+ for _ in range(nstack)])
+
+ self.features = nn.ModuleList([
+ nn.Sequential(
+ Block(in_channel, in_channel),
+ ConvBlock(in_channel, in_channel, 1, bn=True, relu=True)
+ ) for _ in range(nstack)])
+
+ self.out_heatmaps = nn.ModuleList(
+ [ConvBlock(in_channel, self.num_heats, 1, relu=False, bn=False)
+ for _ in range(nstack)])
+
+ if self.cfg.use_AAM:
+ self.num_edges = classes_num[1]
+ self.num_points = classes_num[2]
+
+ self.e2h_transform = E2HTransform(edge_info, self.num_points, self.num_edges)
+ self.out_edgemaps = nn.ModuleList(
+ [ConvBlock(in_channel, self.num_edges, 1, relu=False, bn=False)
+ for _ in range(nstack)])
+ self.out_pointmaps = nn.ModuleList(
+ [ConvBlock(in_channel, self.num_points, 1, relu=False, bn=False)
+ for _ in range(nstack)])
+ self.merge_edgemaps = nn.ModuleList(
+ [ConvBlock(self.num_edges, in_channel, 1, relu=False, bn=False)
+ for _ in range(nstack - 1)])
+ self.merge_pointmaps = nn.ModuleList(
+ [ConvBlock(self.num_points, in_channel, 1, relu=False, bn=False)
+ for _ in range(nstack - 1)])
+ self.edgemap_act = Activation("sigmoid", self.num_edges)
+ self.pointmap_act = Activation("sigmoid", self.num_points)
+
+ self.merge_features = nn.ModuleList(
+ [ConvBlock(in_channel, in_channel, 1, relu=False, bn=False)
+ for _ in range(nstack - 1)])
+ self.merge_heatmaps = nn.ModuleList(
+ [ConvBlock(self.num_heats, in_channel, 1, relu=False, bn=False)
+ for _ in range(nstack - 1)])
+
+ self.nstack = nstack
+
+ self.heatmap_act = Activation("in+relu", self.num_heats)
+
+ self.inference = False
+
+ def set_inference(self, inference):
+ self.inference = inference
+
+ def forward(self, x):
+ x = self.pre(x)
+
+ y, fusionmaps = [], []
+ heatmaps = None
+ for i in range(self.nstack):
+ hg = self.hgs[i](x, heatmap=heatmaps)
+ feature = self.features[i](hg)
+
+ heatmaps0 = self.out_heatmaps[i](feature)
+ heatmaps = self.heatmap_act(heatmaps0)
+
+ if self.cfg.use_AAM:
+ pointmaps0 = self.out_pointmaps[i](feature)
+ pointmaps = self.pointmap_act(pointmaps0)
+ edgemaps0 = self.out_edgemaps[i](feature)
+ edgemaps = self.edgemap_act(edgemaps0)
+ mask = self.e2h_transform(edgemaps) * pointmaps
+ fusion_heatmaps = mask * heatmaps
+ else:
+ fusion_heatmaps = heatmaps
+
+ landmarks = self.decoder.get_coords_from_heatmap(fusion_heatmaps)
+
+ if i < self.nstack - 1:
+ x = x + self.merge_features[i](feature) + \
+ self.merge_heatmaps[i](heatmaps)
+ if self.cfg.use_AAM:
+ x += self.merge_pointmaps[i](pointmaps)
+ x += self.merge_edgemaps[i](edgemaps)
+
+ y.append(landmarks)
+ if self.cfg.use_AAM:
+ y.append(pointmaps)
+ y.append(edgemaps)
+
+ fusionmaps.append(fusion_heatmaps)
+
+ return y, fusionmaps, landmarks
\ No newline at end of file
diff --git a/models/STAR/lib/dataset/__init__.py b/models/STAR/lib/dataset/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3380c4b601721c79c2076538d8e675badd05b5a2
--- /dev/null
+++ b/models/STAR/lib/dataset/__init__.py
@@ -0,0 +1,11 @@
+from .encoder import get_encoder
+from .decoder import get_decoder
+from .augmentation import Augmentation
+from .alignmentDataset import AlignmentDataset
+
+__all__ = [
+ "Augmentation",
+ "AlignmentDataset",
+ "get_encoder",
+ "get_decoder"
+]
diff --git a/models/STAR/lib/dataset/alignmentDataset.py b/models/STAR/lib/dataset/alignmentDataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ba888feae477174a98685e0d07eeadeadfaf6d7
--- /dev/null
+++ b/models/STAR/lib/dataset/alignmentDataset.py
@@ -0,0 +1,316 @@
+import os
+import sys
+import cv2
+import math
+import copy
+import hashlib
+import imageio
+import numpy as np
+import pandas as pd
+from scipy import interpolate
+from PIL import Image, ImageEnhance, ImageFile
+
+import torch
+import torch.nn.functional as F
+from torch.utils.data import Dataset
+
+ImageFile.LOAD_TRUNCATED_IMAGES = True
+
+sys.path.append("./")
+from models.STAR.lib.dataset.augmentation import Augmentation
+from models.STAR.lib.dataset.encoder import get_encoder
+
+
+class AlignmentDataset(Dataset):
+
+ def __init__(self, tsv_flie, image_dir="", transform=None,
+ width=256, height=256, channels=3,
+ means=(127.5, 127.5, 127.5), scale=1 / 127.5,
+ classes_num=None, crop_op=True, aug_prob=0.0, edge_info=None, flip_mapping=None, is_train=True,
+ encoder_type='default',
+ ):
+ super(AlignmentDataset, self).__init__()
+ self.use_AAM = True
+ self.encoder_type = encoder_type
+ self.encoder = get_encoder(height, width, encoder_type=encoder_type)
+ self.items = pd.read_csv(tsv_flie, sep="\t")
+ self.image_dir = image_dir
+ self.landmark_num = classes_num[0]
+ self.transform = transform
+
+ self.image_width = width
+ self.image_height = height
+ self.channels = channels
+ assert self.image_width == self.image_height
+
+ self.means = means
+ self.scale = scale
+
+ self.aug_prob = aug_prob
+ self.edge_info = edge_info
+ self.is_train = is_train
+ std_lmk_5pts = np.array([
+ 196.0, 226.0,
+ 316.0, 226.0,
+ 256.0, 286.0,
+ 220.0, 360.4,
+ 292.0, 360.4], np.float32) / 256.0 - 1.0
+ std_lmk_5pts = np.reshape(std_lmk_5pts, (5, 2)) # [-1 1]
+ target_face_scale = 1.0 if crop_op else 1.25
+
+ self.augmentation = Augmentation(
+ is_train=self.is_train,
+ aug_prob=self.aug_prob,
+ image_size=self.image_width,
+ crop_op=crop_op,
+ std_lmk_5pts=std_lmk_5pts,
+ target_face_scale=target_face_scale,
+ flip_rate=0.5,
+ flip_mapping=flip_mapping,
+ random_shift_sigma=0.05,
+ random_rot_sigma=math.pi / 180 * 18,
+ random_scale_sigma=0.1,
+ random_gray_rate=0.2,
+ random_occ_rate=0.4,
+ random_blur_rate=0.3,
+ random_gamma_rate=0.2,
+ random_nose_fusion_rate=0.2)
+
+ def _circle(self, img, pt, sigma=1.0, label_type='Gaussian'):
+ # Check that any part of the gaussian is in-bounds
+ tmp_size = sigma * 3
+ ul = [int(pt[0] - tmp_size), int(pt[1] - tmp_size)]
+ br = [int(pt[0] + tmp_size + 1), int(pt[1] + tmp_size + 1)]
+ if (ul[0] > img.shape[1] - 1 or ul[1] > img.shape[0] - 1 or
+ br[0] - 1 < 0 or br[1] - 1 < 0):
+ # If not, just return the image as is
+ return img
+
+ # Generate gaussian
+ size = 2 * tmp_size + 1
+ x = np.arange(0, size, 1, np.float32)
+ y = x[:, np.newaxis]
+ x0 = y0 = size // 2
+ # The gaussian is not normalized, we want the center value to equal 1
+ if label_type == 'Gaussian':
+ g = np.exp(- ((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2))
+ else:
+ g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)
+
+ # Usable gaussian range
+ g_x = max(0, -ul[0]), min(br[0], img.shape[1]) - ul[0]
+ g_y = max(0, -ul[1]), min(br[1], img.shape[0]) - ul[1]
+ # Image range
+ img_x = max(0, ul[0]), min(br[0], img.shape[1])
+ img_y = max(0, ul[1]), min(br[1], img.shape[0])
+
+ img[img_y[0]:img_y[1], img_x[0]:img_x[1]] = 255 * g[g_y[0]:g_y[1], g_x[0]:g_x[1]]
+ return img
+
+ def _polylines(self, img, lmks, is_closed, color=255, thickness=1, draw_mode=cv2.LINE_AA,
+ interpolate_mode=cv2.INTER_AREA, scale=4):
+ h, w = img.shape
+ img_scale = cv2.resize(img, (w * scale, h * scale), interpolation=interpolate_mode)
+ lmks_scale = (lmks * scale + 0.5).astype(np.int32)
+ cv2.polylines(img_scale, [lmks_scale], is_closed, color, thickness * scale, draw_mode)
+ img = cv2.resize(img_scale, (w, h), interpolation=interpolate_mode)
+ return img
+
+ def _generate_edgemap(self, points, scale=0.25, thickness=1):
+ h, w = self.image_height, self.image_width
+ edgemaps = []
+ for is_closed, indices in self.edge_info:
+ edgemap = np.zeros([h, w], dtype=np.float32)
+ # align_corners: False.
+ part = copy.deepcopy(points[np.array(indices)])
+
+ part = self._fit_curve(part, is_closed)
+ part[:, 0] = np.clip(part[:, 0], 0, w - 1)
+ part[:, 1] = np.clip(part[:, 1], 0, h - 1)
+ edgemap = self._polylines(edgemap, part, is_closed, 255, thickness)
+
+ edgemaps.append(edgemap)
+ edgemaps = np.stack(edgemaps, axis=0) / 255.0
+ edgemaps = torch.from_numpy(edgemaps).float().unsqueeze(0)
+ edgemaps = F.interpolate(edgemaps, size=(int(w * scale), int(h * scale)), mode='bilinear',
+ align_corners=False).squeeze()
+ return edgemaps
+
+ def _fit_curve(self, lmks, is_closed=False, density=5):
+ try:
+ x = lmks[:, 0].copy()
+ y = lmks[:, 1].copy()
+ if is_closed:
+ x = np.append(x, x[0])
+ y = np.append(y, y[0])
+ tck, u = interpolate.splprep([x, y], s=0, per=is_closed, k=3)
+ # bins = (x.shape[0] - 1) * density + 1
+ # lmk_x, lmk_y = interpolate.splev(np.linspace(0, 1, bins), f)
+ intervals = np.array([])
+ for i in range(len(u) - 1):
+ intervals = np.concatenate((intervals, np.linspace(u[i], u[i + 1], density, endpoint=False)))
+ if not is_closed:
+ intervals = np.concatenate((intervals, [u[-1]]))
+ lmk_x, lmk_y = interpolate.splev(intervals, tck, der=0)
+ # der_x, der_y = interpolate.splev(intervals, tck, der=1)
+ curve_lmks = np.stack([lmk_x, lmk_y], axis=-1)
+ # curve_ders = np.stack([der_x, der_y], axis=-1)
+ # origin_indices = np.arange(0, curve_lmks.shape[0], density)
+
+ return curve_lmks
+ except:
+ return lmks
+
+ def _image_id(self, image_path):
+ if not os.path.exists(image_path):
+ image_path = os.path.join(self.image_dir, image_path)
+ return hashlib.md5(open(image_path, "rb").read()).hexdigest()
+
+ def _load_image(self, image_path):
+ if not os.path.exists(image_path):
+ image_path = os.path.join(self.image_dir, image_path)
+
+ try:
+ # img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)#HWC, BGR, [0-255]
+ img = cv2.imread(image_path, cv2.IMREAD_COLOR) # HWC, BGR, [0-255]
+ assert img is not None and len(img.shape) == 3 and img.shape[2] == 3
+ except:
+ try:
+ img = imageio.imread(image_path) # HWC, RGB, [0-255]
+ img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # HWC, BGR, [0-255]
+ assert img is not None and len(img.shape) == 3 and img.shape[2] == 3
+ except:
+ try:
+ gifImg = imageio.mimread(image_path) # BHWC, RGB, [0-255]
+ img = gifImg[0] # HWC, RGB, [0-255]
+ img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # HWC, BGR, [0-255]
+ assert img is not None and len(img.shape) == 3 and img.shape[2] == 3
+ except:
+ img = None
+ return img
+
+ def _compose_rotate_and_scale(self, angle, scale, shift_xy, from_center, to_center):
+ cosv = math.cos(angle)
+ sinv = math.sin(angle)
+
+ fx, fy = from_center
+ tx, ty = to_center
+
+ acos = scale * cosv
+ asin = scale * sinv
+
+ a0 = acos
+ a1 = -asin
+ a2 = tx - acos * fx + asin * fy + shift_xy[0]
+
+ b0 = asin
+ b1 = acos
+ b2 = ty - asin * fx - acos * fy + shift_xy[1]
+
+ rot_scale_m = np.array([
+ [a0, a1, a2],
+ [b0, b1, b2],
+ [0.0, 0.0, 1.0]
+ ], np.float32)
+ return rot_scale_m
+
+ def _transformPoints2D(self, points, matrix):
+ """
+ points (nx2), matrix (3x3) -> points (nx2)
+ """
+ dtype = points.dtype
+
+ # nx3
+ points = np.concatenate([points, np.ones_like(points[:, [0]])], axis=1)
+ points = points @ np.transpose(matrix) # nx3
+ points = points[:, :2] / points[:, [2, 2]]
+ return points.astype(dtype)
+
+ def _transformPerspective(self, image, matrix, target_shape):
+ """
+ image, matrix3x3 -> transformed_image
+ """
+ return cv2.warpPerspective(
+ image, matrix,
+ dsize=(target_shape[1], target_shape[0]),
+ flags=cv2.INTER_LINEAR, borderValue=0)
+
+ def _norm_points(self, points, h, w, align_corners=False):
+ if align_corners:
+ # [0, SIZE-1] -> [-1, +1]
+ des_points = points / torch.tensor([w - 1, h - 1]).to(points).view(1, 2) * 2 - 1
+ else:
+ # [-0.5, SIZE-0.5] -> [-1, +1]
+ des_points = (points * 2 + 1) / torch.tensor([w, h]).to(points).view(1, 2) - 1
+ des_points = torch.clamp(des_points, -1, 1)
+ return des_points
+
+ def _denorm_points(self, points, h, w, align_corners=False):
+ if align_corners:
+ # [-1, +1] -> [0, SIZE-1]
+ des_points = (points + 1) / 2 * torch.tensor([w - 1, h - 1]).to(points).view(1, 1, 2)
+ else:
+ # [-1, +1] -> [-0.5, SIZE-0.5]
+ des_points = ((points + 1) * torch.tensor([w, h]).to(points).view(1, 1, 2) - 1) / 2
+ return des_points
+
+ def __len__(self):
+ return len(self.items)
+
+ def __getitem__(self, index):
+ sample = dict()
+
+ image_path = self.items.iloc[index, 0]
+ landmarks_5pts = self.items.iloc[index, 1]
+ landmarks_5pts = np.array(list(map(float, landmarks_5pts.split(","))), dtype=np.float32).reshape(5, 2)
+ landmarks_target = self.items.iloc[index, 2]
+ landmarks_target = np.array(list(map(float, landmarks_target.split(","))), dtype=np.float32).reshape(
+ self.landmark_num, 2)
+ scale = float(self.items.iloc[index, 3])
+ center_w, center_h = float(self.items.iloc[index, 4]), float(self.items.iloc[index, 5])
+ if len(self.items.iloc[index]) > 6:
+ tags = np.array(list(map(lambda x: int(float(x)), self.items.iloc[index, 6].split(","))))
+ else:
+ tags = np.array([])
+
+ # image & keypoints alignment
+ image_path = image_path.replace('\\', '/')
+ # wflw testset
+ image_path = image_path.replace(
+ '//msr-facestore/Workspace/MSRA_EP_Allergan/users/yanghuan/training_data/wflw/rawImages/', '')
+ # trainset
+ image_path = image_path.replace('./rawImages/', '')
+ image_path = os.path.join(self.image_dir, image_path)
+
+ # image path
+ sample["image_path"] = image_path
+
+ img = self._load_image(image_path) # HWC, BGR, [0, 255]
+ assert img is not None
+
+ # augmentation
+ # landmarks_target = [-0.5, edge-0.5]
+ img, landmarks_target, matrix = \
+ self.augmentation.process(img, landmarks_target, landmarks_5pts, scale, center_w, center_h)
+
+ landmarks = self._norm_points(torch.from_numpy(landmarks_target), self.image_height, self.image_width)
+
+ sample["label"] = [landmarks, ]
+
+ if self.use_AAM:
+ pointmap = self.encoder.generate_heatmap(landmarks_target)
+ edgemap = self._generate_edgemap(landmarks_target)
+ sample["label"] += [pointmap, edgemap]
+
+ sample['matrix'] = matrix
+
+ # image normalization
+ img = img.transpose(2, 0, 1).astype(np.float32) # CHW, BGR, [0, 255]
+ img[0, :, :] = (img[0, :, :] - self.means[0]) * self.scale
+ img[1, :, :] = (img[1, :, :] - self.means[1]) * self.scale
+ img[2, :, :] = (img[2, :, :] - self.means[2]) * self.scale
+ sample["data"] = torch.from_numpy(img) # CHW, BGR, [-1, 1]
+
+ sample["tags"] = tags
+
+ return sample
diff --git a/models/STAR/lib/dataset/augmentation.py b/models/STAR/lib/dataset/augmentation.py
new file mode 100644
index 0000000000000000000000000000000000000000..0694d316b8d20ccbb6fda6f4b9750c851f83995a
--- /dev/null
+++ b/models/STAR/lib/dataset/augmentation.py
@@ -0,0 +1,355 @@
+import os
+import cv2
+import math
+import random
+import numpy as np
+from skimage import transform
+
+
+class Augmentation:
+ def __init__(self,
+ is_train=True,
+ aug_prob=1.0,
+ image_size=256,
+ crop_op=True,
+ std_lmk_5pts=None,
+ target_face_scale=1.0,
+ flip_rate=0.5,
+ flip_mapping=None,
+ random_shift_sigma=0.05,
+ random_rot_sigma=math.pi/180*18,
+ random_scale_sigma=0.1,
+ random_gray_rate=0.2,
+ random_occ_rate=0.4,
+ random_blur_rate=0.3,
+ random_gamma_rate=0.2,
+ random_nose_fusion_rate=0.2):
+ self.is_train = is_train
+ self.aug_prob = aug_prob
+ self.crop_op = crop_op
+ self._flip = Flip(flip_mapping, flip_rate)
+ if self.crop_op:
+ self._cropMatrix = GetCropMatrix(
+ image_size=image_size,
+ target_face_scale=target_face_scale,
+ align_corners=True)
+ else:
+ self._alignMatrix = GetAlignMatrix(
+ image_size=image_size,
+ target_face_scale=target_face_scale,
+ std_lmk_5pts=std_lmk_5pts)
+ self._randomGeometryMatrix = GetRandomGeometryMatrix(
+ target_shape=(image_size, image_size),
+ from_shape=(image_size, image_size),
+ shift_sigma=random_shift_sigma,
+ rot_sigma=random_rot_sigma,
+ scale_sigma=random_scale_sigma,
+ align_corners=True)
+ self._transform = Transform(image_size=image_size)
+ self._randomTexture = RandomTexture(
+ random_gray_rate=random_gray_rate,
+ random_occ_rate=random_occ_rate,
+ random_blur_rate=random_blur_rate,
+ random_gamma_rate=random_gamma_rate,
+ random_nose_fusion_rate=random_nose_fusion_rate)
+
+ def process(self, img, lmk, lmk_5pts=None, scale=1.0, center_w=0, center_h=0, is_train=True):
+ if self.is_train and random.random() < self.aug_prob:
+ img, lmk, lmk_5pts, center_w, center_h = self._flip.process(img, lmk, lmk_5pts, center_w, center_h)
+ matrix_geoaug = self._randomGeometryMatrix.process()
+ if self.crop_op:
+ matrix_pre = self._cropMatrix.process(scale, center_w, center_h)
+ else:
+ matrix_pre = self._alignMatrix.process(lmk_5pts)
+ matrix = matrix_geoaug @ matrix_pre
+ aug_img, aug_lmk = self._transform.process(img, lmk, matrix)
+ aug_img = self._randomTexture.process(aug_img)
+ else:
+ if self.crop_op:
+ matrix = self._cropMatrix.process(scale, center_w, center_h)
+ else:
+ matrix = self._alignMatrix.process(lmk_5pts)
+ aug_img, aug_lmk = self._transform.process(img, lmk, matrix)
+ return aug_img, aug_lmk, matrix
+
+
+class GetCropMatrix:
+ def __init__(self, image_size, target_face_scale, align_corners=False):
+ self.image_size = image_size
+ self.target_face_scale = target_face_scale
+ self.align_corners = align_corners
+
+ def _compose_rotate_and_scale(self, angle, scale, shift_xy, from_center, to_center):
+ cosv = math.cos(angle)
+ sinv = math.sin(angle)
+
+ fx, fy = from_center
+ tx, ty = to_center
+
+ acos = scale * cosv
+ asin = scale * sinv
+
+ a0 = acos
+ a1 = -asin
+ a2 = tx - acos * fx + asin * fy + shift_xy[0]
+
+ b0 = asin
+ b1 = acos
+ b2 = ty - asin * fx - acos * fy + shift_xy[1]
+
+ rot_scale_m = np.array([
+ [a0, a1, a2],
+ [b0, b1, b2],
+ [0.0, 0.0, 1.0]
+ ], np.float32)
+ return rot_scale_m
+
+ def process(self, scale, center_w, center_h):
+ if self.align_corners:
+ to_w, to_h = self.image_size-1, self.image_size-1
+ else:
+ to_w, to_h = self.image_size, self.image_size
+
+ rot_mu = 0
+ scale_mu = self.image_size / (scale * self.target_face_scale * 200.0)
+ shift_xy_mu = (0, 0)
+ matrix = self._compose_rotate_and_scale(
+ rot_mu, scale_mu, shift_xy_mu,
+ from_center=[center_w, center_h],
+ to_center=[to_w/2.0, to_h/2.0])
+ return matrix
+
+
+class GetAlignMatrix:
+ def __init__(self, image_size, target_face_scale, std_lmk_5pts):
+ """
+ points in std_lmk_5pts range from -1 to 1.
+ """
+ self.std_lmk_5pts = (std_lmk_5pts * target_face_scale + 1) * \
+ np.array([image_size, image_size], np.float32) / 2.0
+
+ def process(self, lmk_5pts):
+ assert lmk_5pts.shape[-2:] == (5, 2)
+ tform = transform.SimilarityTransform()
+ tform.estimate(lmk_5pts, self.std_lmk_5pts)
+ return tform.params
+
+
+class GetRandomGeometryMatrix:
+ def __init__(self, target_shape, from_shape,
+ shift_sigma=0.1, rot_sigma=18*math.pi/180, scale_sigma=0.1,
+ shift_mu=0.0, rot_mu=0.0, scale_mu=1.0,
+ shift_normal=True, rot_normal=True, scale_normal=True,
+ align_corners=False):
+ self.target_shape = target_shape
+ self.from_shape = from_shape
+ self.shift_config = (shift_mu, shift_sigma, shift_normal)
+ self.rot_config = (rot_mu, rot_sigma, rot_normal)
+ self.scale_config = (scale_mu, scale_sigma, scale_normal)
+ self.align_corners = align_corners
+
+ def _compose_rotate_and_scale(self, angle, scale, shift_xy, from_center, to_center):
+ cosv = math.cos(angle)
+ sinv = math.sin(angle)
+
+ fx, fy = from_center
+ tx, ty = to_center
+
+ acos = scale * cosv
+ asin = scale * sinv
+
+ a0 = acos
+ a1 = -asin
+ a2 = tx - acos * fx + asin * fy + shift_xy[0]
+
+ b0 = asin
+ b1 = acos
+ b2 = ty - asin * fx - acos * fy + shift_xy[1]
+
+ rot_scale_m = np.array([
+ [a0, a1, a2],
+ [b0, b1, b2],
+ [0.0, 0.0, 1.0]
+ ], np.float32)
+ return rot_scale_m
+
+ def _random(self, mu_sigma_normal, size=None):
+ mu, sigma, is_normal = mu_sigma_normal
+ if is_normal:
+ return np.random.normal(mu, sigma, size=size)
+ else:
+ return np.random.uniform(low=mu-sigma, high=mu+sigma, size=size)
+
+ def process(self):
+ if self.align_corners:
+ from_w, from_h = self.from_shape[1]-1, self.from_shape[0]-1
+ to_w, to_h = self.target_shape[1]-1, self.target_shape[0]-1
+ else:
+ from_w, from_h = self.from_shape[1], self.from_shape[0]
+ to_w, to_h = self.target_shape[1], self.target_shape[0]
+
+ if self.shift_config[:2] != (0.0, 0.0) or \
+ self.rot_config[:2] != (0.0, 0.0) or \
+ self.scale_config[:2] != (1.0, 0.0):
+ shift_xy = self._random(self.shift_config, size=[2]) * \
+ min(to_h, to_w)
+ rot_angle = self._random(self.rot_config)
+ scale = self._random(self.scale_config)
+ matrix_geoaug = self._compose_rotate_and_scale(
+ rot_angle, scale, shift_xy,
+ from_center=[from_w/2.0, from_h/2.0],
+ to_center=[to_w/2.0, to_h/2.0])
+
+ return matrix_geoaug
+
+
+class Transform:
+ def __init__(self, image_size):
+ self.image_size = image_size
+
+ def _transformPoints2D(self, points, matrix):
+ """
+ points (nx2), matrix (3x3) -> points (nx2)
+ """
+ dtype = points.dtype
+
+ # nx3
+ points = np.concatenate([points, np.ones_like(points[:, [0]])], axis=1)
+ points = points @ np.transpose(matrix)
+ points = points[:, :2] / points[:, [2, 2]]
+ return points.astype(dtype)
+
+ def _transformPerspective(self, image, matrix):
+ """
+ image, matrix3x3 -> transformed_image
+ """
+ return cv2.warpPerspective(
+ image, matrix,
+ dsize=(self.image_size, self.image_size),
+ flags=cv2.INTER_LINEAR, borderValue=0)
+
+ def process(self, image, landmarks, matrix):
+ t_landmarks = self._transformPoints2D(landmarks, matrix)
+ t_image = self._transformPerspective(image, matrix)
+ return t_image, t_landmarks
+
+
+class RandomTexture:
+ def __init__(self, random_gray_rate=0, random_occ_rate=0, random_blur_rate=0, random_gamma_rate=0, random_nose_fusion_rate=0):
+ self.random_gray_rate = random_gray_rate
+ self.random_occ_rate = random_occ_rate
+ self.random_blur_rate = random_blur_rate
+ self.random_gamma_rate = random_gamma_rate
+ self.random_nose_fusion_rate = random_nose_fusion_rate
+ self.texture_augs = (
+ (self.add_occ, self.random_occ_rate),
+ (self.add_blur, self.random_blur_rate),
+ (self.add_gamma, self.random_gamma_rate),
+ (self.add_nose_fusion, self.random_nose_fusion_rate)
+ )
+
+ def add_gray(self, image):
+ assert image.ndim == 3 and image.shape[-1] == 3
+ image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
+ image = np.tile(np.expand_dims(image, -1), [1, 1, 3])
+ return image
+
+ def add_occ(self, image):
+ h, w, c = image.shape
+ rh = 0.2 + 0.6 * random.random() # [0.2, 0.8]
+ rw = rh - 0.2 + 0.4 * random.random()
+ cx = int((h - 1) * random.random())
+ cy = int((w - 1) * random.random())
+ dh = int(h / 2 * rh)
+ dw = int(w / 2 * rw)
+ x0 = max(0, cx - dw // 2)
+ y0 = max(0, cy - dh // 2)
+ x1 = min(w - 1, cx + dw // 2)
+ y1 = min(h - 1, cy + dh // 2)
+ image[y0:y1+1, x0:x1+1] = 0
+ return image
+
+ def add_blur(self, image):
+ blur_kratio = 0.05 * random.random()
+ blur_ksize = int((image.shape[0] + image.shape[1]) / 2 * blur_kratio)
+ if blur_ksize > 1:
+ image = cv2.blur(image, (blur_ksize, blur_ksize))
+ return image
+
+ def add_gamma(self, image):
+ if random.random() < 0.5:
+ gamma = 0.25 + 0.75 * random.random()
+ else:
+ gamma = 1.0 + 3.0 * random.random()
+ image = (((image / 255.0) ** gamma) * 255).astype("uint8")
+ return image
+
+ def add_nose_fusion(self, image):
+ h, w, c = image.shape
+ nose = np.array(bytearray(os.urandom(h * w * c)), dtype=image.dtype).reshape(h, w, c)
+ alpha = 0.5 * random.random()
+ image = (1 - alpha) * image + alpha * nose
+ return image.astype(np.uint8)
+
+ def process(self, image):
+ image = image.copy()
+ if random.random() < self.random_occ_rate:
+ image = self.add_occ(image)
+ if random.random() < self.random_blur_rate:
+ image = self.add_blur(image)
+ if random.random() < self.random_gamma_rate:
+ image = self.add_gamma(image)
+ if random.random() < self.random_nose_fusion_rate:
+ image = self.add_nose_fusion(image)
+ """
+ orders = list(range(len(self.texture_augs)))
+ random.shuffle(orders)
+ for order in orders:
+ if random.random() < self.texture_augs[order][1]:
+ image = self.texture_augs[order][0](image)
+ """
+
+ if random.random() < self.random_gray_rate:
+ image = self.add_gray(image)
+
+ return image
+
+
+class Flip:
+ def __init__(self, flip_mapping, random_rate):
+ self.flip_mapping = flip_mapping
+ self.random_rate = random_rate
+
+ def process(self, image, landmarks, landmarks_5pts, center_w, center_h):
+ if random.random() >= self.random_rate or self.flip_mapping is None:
+ return image, landmarks, landmarks_5pts, center_w, center_h
+
+ # COFW
+ if landmarks.shape[0] == 29:
+ flip_offset = 0
+ # 300W, WFLW
+ elif landmarks.shape[0] in (68, 98):
+ flip_offset = -1
+ else:
+ flip_offset = -1
+
+ h, w, _ = image.shape
+ #image_flip = cv2.flip(image, 1)
+ image_flip = np.fliplr(image).copy()
+ landmarks_flip = landmarks.copy()
+ for i, j in self.flip_mapping:
+ landmarks_flip[i] = landmarks[j]
+ landmarks_flip[j] = landmarks[i]
+ landmarks_flip[:, 0] = w + flip_offset - landmarks_flip[:, 0]
+ if landmarks_5pts is not None:
+ flip_mapping = ([0, 1], [3, 4])
+ landmarks_5pts_flip = landmarks_5pts.copy()
+ for i, j in flip_mapping:
+ landmarks_5pts_flip[i] = landmarks_5pts[j]
+ landmarks_5pts_flip[j] = landmarks_5pts[i]
+ landmarks_5pts_flip[:, 0] = w + flip_offset - landmarks_5pts_flip[:, 0]
+ else:
+ landmarks_5pts_flip = None
+
+ center_w = w + flip_offset - center_w
+ return image_flip, landmarks_flip, landmarks_5pts_flip, center_w, center_h
diff --git a/models/STAR/lib/dataset/decoder/__init__.py b/models/STAR/lib/dataset/decoder/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2315040c50fbccacc9cff3e0b8e92c1691a4600b
--- /dev/null
+++ b/models/STAR/lib/dataset/decoder/__init__.py
@@ -0,0 +1,8 @@
+from .decoder_default import decoder_default
+
+def get_decoder(decoder_type='default'):
+ if decoder_type == 'default':
+ decoder = decoder_default()
+ else:
+ raise NotImplementedError
+ return decoder
\ No newline at end of file
diff --git a/models/STAR/lib/dataset/decoder/decoder_default.py b/models/STAR/lib/dataset/decoder/decoder_default.py
new file mode 100644
index 0000000000000000000000000000000000000000..19b981e3392e17b065a12a96861c64e600d790bd
--- /dev/null
+++ b/models/STAR/lib/dataset/decoder/decoder_default.py
@@ -0,0 +1,38 @@
+import torch
+
+
+class decoder_default:
+ def __init__(self, weight=1, use_weight_map=False):
+ self.weight = weight
+ self.use_weight_map = use_weight_map
+
+ def _make_grid(self, h, w):
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float() / (h - 1) * 2 - 1,
+ torch.arange(w).float() / (w - 1) * 2 - 1)
+ return yy, xx
+
+ def get_coords_from_heatmap(self, heatmap):
+ """
+ inputs:
+ - heatmap: batch x npoints x h x w
+
+ outputs:
+ - coords: batch x npoints x 2 (x,y), [-1, +1]
+ - radius_sq: batch x npoints
+ """
+ batch, npoints, h, w = heatmap.shape
+ if self.use_weight_map:
+ heatmap = heatmap * self.weight
+
+ yy, xx = self._make_grid(h, w)
+ yy = yy.view(1, 1, h, w).to(heatmap)
+ xx = xx.view(1, 1, h, w).to(heatmap)
+
+ heatmap_sum = torch.clamp(heatmap.sum([2, 3]), min=1e-6)
+
+ yy_coord = (yy * heatmap).sum([2, 3]) / heatmap_sum # batch x npoints
+ xx_coord = (xx * heatmap).sum([2, 3]) / heatmap_sum # batch x npoints
+ coords = torch.stack([xx_coord, yy_coord], dim=-1)
+
+ return coords
diff --git a/models/STAR/lib/dataset/encoder/__init__.py b/models/STAR/lib/dataset/encoder/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b80fe999ee83928d6abde95c51ef03c6bd052098
--- /dev/null
+++ b/models/STAR/lib/dataset/encoder/__init__.py
@@ -0,0 +1,8 @@
+from .encoder_default import encoder_default
+
+def get_encoder(image_height, image_width, scale=0.25, sigma=1.5, encoder_type='default'):
+ if encoder_type == 'default':
+ encoder = encoder_default(image_height, image_width, scale, sigma)
+ else:
+ raise NotImplementedError
+ return encoder
diff --git a/models/STAR/lib/dataset/encoder/encoder_default.py b/models/STAR/lib/dataset/encoder/encoder_default.py
new file mode 100644
index 0000000000000000000000000000000000000000..6662a94bdc5788ebb00cc2eb0c4103ba5a10d653
--- /dev/null
+++ b/models/STAR/lib/dataset/encoder/encoder_default.py
@@ -0,0 +1,63 @@
+import copy
+import numpy as np
+
+import torch
+import torch.nn.functional as F
+
+
+class encoder_default:
+ def __init__(self, image_height, image_width, scale=0.25, sigma=1.5):
+ self.image_height = image_height
+ self.image_width = image_width
+ self.scale = scale
+ self.sigma = sigma
+
+ def generate_heatmap(self, points):
+ # points = (num_pts, 2)
+ h, w = self.image_height, self.image_width
+ pointmaps = []
+ for i in range(len(points)):
+ pointmap = np.zeros([h, w], dtype=np.float32)
+ # align_corners: False.
+ point = copy.deepcopy(points[i])
+ point[0] = max(0, min(w - 1, point[0]))
+ point[1] = max(0, min(h - 1, point[1]))
+ pointmap = self._circle(pointmap, point, sigma=self.sigma)
+
+ pointmaps.append(pointmap)
+ pointmaps = np.stack(pointmaps, axis=0) / 255.0
+ pointmaps = torch.from_numpy(pointmaps).float().unsqueeze(0)
+ pointmaps = F.interpolate(pointmaps, size=(int(w * self.scale), int(h * self.scale)), mode='bilinear',
+ align_corners=False).squeeze()
+ return pointmaps
+
+ def _circle(self, img, pt, sigma=1.0, label_type='Gaussian'):
+ # Check that any part of the gaussian is in-bounds
+ tmp_size = sigma * 3
+ ul = [int(pt[0] - tmp_size), int(pt[1] - tmp_size)]
+ br = [int(pt[0] + tmp_size + 1), int(pt[1] + tmp_size + 1)]
+ if (ul[0] > img.shape[1] - 1 or ul[1] > img.shape[0] - 1 or
+ br[0] - 1 < 0 or br[1] - 1 < 0):
+ # If not, just return the image as is
+ return img
+
+ # Generate gaussian
+ size = 2 * tmp_size + 1
+ x = np.arange(0, size, 1, np.float32)
+ y = x[:, np.newaxis]
+ x0 = y0 = size // 2
+ # The gaussian is not normalized, we want the center value to equal 1
+ if label_type == 'Gaussian':
+ g = np.exp(- ((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2))
+ else:
+ g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)
+
+ # Usable gaussian range
+ g_x = max(0, -ul[0]), min(br[0], img.shape[1]) - ul[0]
+ g_y = max(0, -ul[1]), min(br[1], img.shape[0]) - ul[1]
+ # Image range
+ img_x = max(0, ul[0]), min(br[0], img.shape[1])
+ img_y = max(0, ul[1]), min(br[1], img.shape[0])
+
+ img[img_y[0]:img_y[1], img_x[0]:img_x[1]] = 255 * g[g_y[0]:g_y[1], g_x[0]:g_x[1]]
+ return img
diff --git a/models/STAR/lib/loss/__init__.py b/models/STAR/lib/loss/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f71a33bddba049b10a2a94ee5e51342f50878637
--- /dev/null
+++ b/models/STAR/lib/loss/__init__.py
@@ -0,0 +1,14 @@
+from .awingLoss import AWingLoss
+from .smoothL1Loss import SmoothL1Loss
+from .wingLoss import WingLoss
+from .starLoss import STARLoss
+from .starLoss_v2 import STARLoss_v2
+
+__all__ = [
+ "AWingLoss",
+ "SmoothL1Loss",
+ "WingLoss",
+ "STARLoss",
+
+ "STARLoss_v2",
+]
diff --git a/models/STAR/lib/loss/awingLoss.py b/models/STAR/lib/loss/awingLoss.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5bfc579bd52702506e0dd0c4a6f2932d0698586
--- /dev/null
+++ b/models/STAR/lib/loss/awingLoss.py
@@ -0,0 +1,39 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class AWingLoss(nn.Module):
+ def __init__(self, omega=14, theta=0.5, epsilon=1, alpha=2.1, use_weight_map=True):
+ super(AWingLoss, self).__init__()
+ self.omega = omega
+ self.theta = theta
+ self.epsilon = epsilon
+ self.alpha = alpha
+ self.use_weight_map = use_weight_map
+
+ def __repr__(self):
+ return "AWingLoss()"
+
+ def generate_weight_map(self, heatmap, k_size=3, w=10):
+ dilate = F.max_pool2d(heatmap, kernel_size=k_size, stride=1, padding=1)
+ weight_map = torch.where(dilate < 0.2, torch.zeros_like(heatmap), torch.ones_like(heatmap))
+ return w * weight_map + 1
+
+ def forward(self, output, groundtruth):
+ """
+ input: b x n x h x w
+ output: b x n x h x w => 1
+ """
+ delta = (output - groundtruth).abs()
+ A = self.omega * (1 / (1 + torch.pow(self.theta / self.epsilon, self.alpha - groundtruth))) * (self.alpha - groundtruth) * \
+ (torch.pow(self.theta / self.epsilon, self.alpha - groundtruth - 1)) * (1 / self.epsilon)
+ C = self.theta * A - self.omega * \
+ torch.log(1 + torch.pow(self.theta / self.epsilon, self.alpha - groundtruth))
+ loss = torch.where(delta < self.theta,
+ self.omega * torch.log(1 + torch.pow(delta / self.epsilon, self.alpha - groundtruth)),
+ (A * delta - C))
+ if self.use_weight_map:
+ weight = self.generate_weight_map(groundtruth)
+ loss = loss * weight
+ return loss.mean()
diff --git a/models/STAR/lib/loss/smoothL1Loss.py b/models/STAR/lib/loss/smoothL1Loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e81104da2f7a3134103bea6a1463a924f4f6ce20
--- /dev/null
+++ b/models/STAR/lib/loss/smoothL1Loss.py
@@ -0,0 +1,36 @@
+import torch
+import torch.nn as nn
+
+
+class SmoothL1Loss(nn.Module):
+ def __init__(self, scale=0.01):
+ super(SmoothL1Loss, self).__init__()
+ self.scale = scale
+ self.EPSILON = 1e-10
+
+ def __repr__(self):
+ return "SmoothL1Loss()"
+
+ def forward(self, output: torch.Tensor, groundtruth: torch.Tensor, reduction='mean'):
+ """
+ input: b x n x 2
+ output: b x n x 1 => 1
+ """
+ if output.dim() == 4:
+ shape = output.shape
+ groundtruth = groundtruth.reshape(shape[0], shape[1], 1, shape[3])
+
+ delta_2 = (output - groundtruth).pow(2).sum(dim=-1, keepdim=False)
+ delta = delta_2.clamp(min=1e-6).sqrt()
+ # delta = torch.sqrt(delta_2 + self.EPSILON)
+ loss = torch.where( \
+ delta_2 < self.scale * self.scale, \
+ 0.5 / self.scale * delta_2, \
+ delta - 0.5 * self.scale)
+
+ if reduction == 'mean':
+ loss = loss.mean()
+ elif reduction == 'sum':
+ loss = loss.sum()
+
+ return loss
diff --git a/models/STAR/lib/loss/starLoss.py b/models/STAR/lib/loss/starLoss.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfd43782daba6f01d7d5ad9647c7028de111dd13
--- /dev/null
+++ b/models/STAR/lib/loss/starLoss.py
@@ -0,0 +1,140 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.autograd import Variable
+
+from .smoothL1Loss import SmoothL1Loss
+from .wingLoss import WingLoss
+
+
+def get_channel_sum(input):
+ temp = torch.sum(input, dim=3)
+ output = torch.sum(temp, dim=2)
+ return output
+
+
+def expand_two_dimensions_at_end(input, dim1, dim2):
+ input = input.unsqueeze(-1).unsqueeze(-1)
+ input = input.expand(-1, -1, dim1, dim2)
+ return input
+
+
+class STARLoss(nn.Module):
+ def __init__(self, w=1, dist='smoothl1', num_dim_image=2, EPSILON=1e-5):
+ super(STARLoss, self).__init__()
+ self.w = w
+ self.num_dim_image = num_dim_image
+ self.EPSILON = EPSILON
+ self.dist = dist
+ if self.dist == 'smoothl1':
+ self.dist_func = SmoothL1Loss()
+ elif self.dist == 'l1':
+ self.dist_func = F.l1_loss
+ elif self.dist == 'l2':
+ self.dist_func = F.mse_loss
+ elif self.dist == 'wing':
+ self.dist_func = WingLoss()
+ else:
+ raise NotImplementedError
+
+ def __repr__(self):
+ return "STARLoss()"
+
+ def _make_grid(self, h, w):
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float() / (h - 1) * 2 - 1,
+ torch.arange(w).float() / (w - 1) * 2 - 1)
+ return yy, xx
+
+ def weighted_mean(self, heatmap):
+ batch, npoints, h, w = heatmap.shape
+
+ yy, xx = self._make_grid(h, w)
+ yy = yy.view(1, 1, h, w).to(heatmap)
+ xx = xx.view(1, 1, h, w).to(heatmap)
+
+ yy_coord = (yy * heatmap).sum([2, 3]) # batch x npoints
+ xx_coord = (xx * heatmap).sum([2, 3]) # batch x npoints
+ coords = torch.stack([xx_coord, yy_coord], dim=-1)
+ return coords
+
+ def unbiased_weighted_covariance(self, htp, means, num_dim_image=2, EPSILON=1e-5):
+ batch_size, num_points, height, width = htp.shape
+
+ yv, xv = self._make_grid(height, width)
+ xv = Variable(xv)
+ yv = Variable(yv)
+
+ if htp.is_cuda:
+ xv = xv.cuda()
+ yv = yv.cuda()
+
+ xmean = means[:, :, 0]
+ xv_minus_mean = xv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(xmean, height,
+ width) # [batch_size, 68, 64, 64]
+ ymean = means[:, :, 1]
+ yv_minus_mean = yv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(ymean, height,
+ width) # [batch_size, 68, 64, 64]
+ wt_xv_minus_mean = xv_minus_mean
+ wt_yv_minus_mean = yv_minus_mean
+
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ vec_concat = torch.cat((wt_xv_minus_mean, wt_yv_minus_mean), 1) # [batch_size*68, 2, 4096]
+
+ htp_vec = htp.view(batch_size * num_points, 1, height * width)
+ htp_vec = htp_vec.expand(-1, 2, -1)
+
+ covariance = torch.bmm(htp_vec * vec_concat, vec_concat.transpose(1, 2)) # [batch_size*68, 2, 2]
+ covariance = covariance.view(batch_size, num_points, num_dim_image, num_dim_image) # [batch_size, 68, 2, 2]
+
+ V_1 = htp.sum([2, 3]) + EPSILON # [batch_size, 68]
+ V_2 = torch.pow(htp, 2).sum([2, 3]) + EPSILON # [batch_size, 68]
+
+ denominator = V_1 - (V_2 / V_1)
+ covariance = covariance / expand_two_dimensions_at_end(denominator, num_dim_image, num_dim_image)
+
+ return covariance
+
+ def ambiguity_guided_decompose(self, pts, eigenvalues, eigenvectors):
+ batch_size, npoints = pts.shape[:2]
+ rotate = torch.matmul(pts.view(batch_size, npoints, 1, 2), eigenvectors.transpose(-1, -2))
+ scale = rotate.view(batch_size, npoints, 2) / torch.sqrt(eigenvalues + self.EPSILON)
+ return scale
+
+ def eigenvalue_restriction(self, evalues, batch, npoints):
+ eigen_loss = torch.abs(evalues.view(batch * npoints, 2)).sum(-1)
+ return eigen_loss.mean()
+
+ def forward(self, heatmap, groundtruth):
+ """
+ heatmap: b x n x 64 x 64
+ groundtruth: b x n x 2
+ output: b x n x 1 => 1
+ """
+ # normalize
+ bs, npoints, h, w = heatmap.shape
+ heatmap_sum = torch.clamp(heatmap.sum([2, 3]), min=1e-6)
+ heatmap = heatmap / heatmap_sum.view(bs, npoints, 1, 1)
+
+ means = self.weighted_mean(heatmap) # [bs, 68, 2]
+ covars = self.unbiased_weighted_covariance(heatmap, means) # covars [bs, 68, 2, 2]
+
+ # TODO: GPU-based eigen-decomposition
+ # https://github.com/pytorch/pytorch/issues/60537
+ _covars = covars.view(bs * npoints, 2, 2).cpu()
+ evalues, evectors = _covars.symeig(eigenvectors=True) # evalues [bs * 68, 2], evectors [bs * 68, 2, 2]
+ evalues = evalues.view(bs, npoints, 2).to(heatmap)
+ evectors = evectors.view(bs, npoints, 2, 2).to(heatmap)
+
+ # STAR Loss
+ # Ambiguity-guided Decomposition
+ error = self.ambiguity_guided_decompose(groundtruth - means, evalues, evectors)
+ loss_trans = self.dist_func(torch.zeros_like(error).to(error), error)
+ # Eigenvalue Restriction
+ loss_eigen = self.eigenvalue_restriction(evalues, bs, npoints)
+ star_loss = loss_trans + self.w * loss_eigen
+
+ return star_loss
diff --git a/models/STAR/lib/loss/starLoss_v2.py b/models/STAR/lib/loss/starLoss_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..c182ff81b24eb0f46130485ef16baff57632810d
--- /dev/null
+++ b/models/STAR/lib/loss/starLoss_v2.py
@@ -0,0 +1,150 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.autograd import Variable
+
+from .smoothL1Loss import SmoothL1Loss
+from .wingLoss import WingLoss
+
+
+def get_channel_sum(input):
+ temp = torch.sum(input, dim=3)
+ output = torch.sum(temp, dim=2)
+ return output
+
+
+def expand_two_dimensions_at_end(input, dim1, dim2):
+ input = input.unsqueeze(-1).unsqueeze(-1)
+ input = input.expand(-1, -1, dim1, dim2)
+ return input
+
+
+class STARLoss_v2(nn.Module):
+ def __init__(self, w=1, dist='smoothl1', num_dim_image=2, EPSILON=1e-5):
+ super(STARLoss_v2, self).__init__()
+ self.w = w
+ self.num_dim_image = num_dim_image
+ self.EPSILON = EPSILON
+ self.dist = dist
+ if self.dist == 'smoothl1':
+ self.dist_func = SmoothL1Loss()
+ elif self.dist == 'l1':
+ self.dist_func = F.l1_loss
+ elif self.dist == 'l2':
+ self.dist_func = F.mse_loss
+ elif self.dist == 'wing':
+ self.dist_func = WingLoss()
+ else:
+ raise NotImplementedError
+
+ def __repr__(self):
+ return "STARLoss()"
+
+ def _make_grid(self, h, w):
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float() / (h - 1) * 2 - 1,
+ torch.arange(w).float() / (w - 1) * 2 - 1)
+ return yy, xx
+
+ def weighted_mean(self, heatmap):
+ batch, npoints, h, w = heatmap.shape
+
+ yy, xx = self._make_grid(h, w)
+ yy = yy.view(1, 1, h, w).to(heatmap)
+ xx = xx.view(1, 1, h, w).to(heatmap)
+
+ yy_coord = (yy * heatmap).sum([2, 3]) # batch x npoints
+ xx_coord = (xx * heatmap).sum([2, 3]) # batch x npoints
+ coords = torch.stack([xx_coord, yy_coord], dim=-1)
+ return coords
+
+ def unbiased_weighted_covariance(self, htp, means, num_dim_image=2, EPSILON=1e-5):
+ batch_size, num_points, height, width = htp.shape
+
+ yv, xv = self._make_grid(height, width)
+ xv = Variable(xv)
+ yv = Variable(yv)
+
+ if htp.is_cuda:
+ xv = xv.cuda()
+ yv = yv.cuda()
+
+ xmean = means[:, :, 0]
+ xv_minus_mean = xv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(xmean, height,
+ width) # [batch_size, 68, 64, 64]
+ ymean = means[:, :, 1]
+ yv_minus_mean = yv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(ymean, height,
+ width) # [batch_size, 68, 64, 64]
+ wt_xv_minus_mean = xv_minus_mean
+ wt_yv_minus_mean = yv_minus_mean
+
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ vec_concat = torch.cat((wt_xv_minus_mean, wt_yv_minus_mean), 1) # [batch_size*68, 2, 4096]
+
+ htp_vec = htp.view(batch_size * num_points, 1, height * width)
+ htp_vec = htp_vec.expand(-1, 2, -1)
+
+ covariance = torch.bmm(htp_vec * vec_concat, vec_concat.transpose(1, 2)) # [batch_size*68, 2, 2]
+ covariance = covariance.view(batch_size, num_points, num_dim_image, num_dim_image) # [batch_size, 68, 2, 2]
+
+ V_1 = htp.sum([2, 3]) + EPSILON # [batch_size, 68]
+ V_2 = torch.pow(htp, 2).sum([2, 3]) + EPSILON # [batch_size, 68]
+
+ denominator = V_1 - (V_2 / V_1)
+ covariance = covariance / expand_two_dimensions_at_end(denominator, num_dim_image, num_dim_image)
+
+ return covariance
+
+ def ambiguity_guided_decompose(self, error, evalues, evectors):
+ bs, npoints = error.shape[:2]
+ normal_vector = evectors[:, :, 0]
+ tangent_vector = evectors[:, :, 1]
+ normal_error = torch.matmul(normal_vector.unsqueeze(-2), error.unsqueeze(-1))
+ tangent_error = torch.matmul(tangent_vector.unsqueeze(-2), error.unsqueeze(-1))
+ normal_error = normal_error.squeeze(dim=-1)
+ tangent_error = tangent_error.squeeze(dim=-1)
+ normal_dist = self.dist_func(normal_error, torch.zeros_like(normal_error).to(normal_error), reduction='none')
+ tangent_dist = self.dist_func(tangent_error, torch.zeros_like(tangent_error).to(tangent_error), reduction='none')
+ normal_dist = normal_dist.reshape(bs, npoints, 1)
+ tangent_dist = tangent_dist.reshape(bs, npoints, 1)
+ dist = torch.cat((normal_dist, tangent_dist), dim=-1)
+ scale_dist = dist / torch.sqrt(evalues + self.EPSILON)
+ scale_dist = scale_dist.sum(-1)
+ return scale_dist
+
+ def eigenvalue_restriction(self, evalues, batch, npoints):
+ eigen_loss = torch.abs(evalues.view(batch, npoints, 2)).sum(-1)
+ return eigen_loss
+
+ def forward(self, heatmap, groundtruth):
+ """
+ heatmap: b x n x 64 x 64
+ groundtruth: b x n x 2
+ output: b x n x 1 => 1
+ """
+ # normalize
+ bs, npoints, h, w = heatmap.shape
+ heatmap_sum = torch.clamp(heatmap.sum([2, 3]), min=1e-6)
+ heatmap = heatmap / heatmap_sum.view(bs, npoints, 1, 1)
+
+ means = self.weighted_mean(heatmap) # [bs, 68, 2]
+ covars = self.unbiased_weighted_covariance(heatmap, means) # covars [bs, 68, 2, 2]
+
+ # TODO: GPU-based eigen-decomposition
+ # https://github.com/pytorch/pytorch/issues/60537
+ _covars = covars.view(bs * npoints, 2, 2).cpu()
+ evalues, evectors = _covars.symeig(eigenvectors=True) # evalues [bs * 68, 2], evectors [bs * 68, 2, 2]
+ evalues = evalues.view(bs, npoints, 2).to(heatmap)
+ evectors = evectors.view(bs, npoints, 2, 2).to(heatmap)
+
+ # STAR Loss
+ # Ambiguity-guided Decomposition
+ loss_trans = self.ambiguity_guided_decompose(groundtruth - means, evalues, evectors)
+ # Eigenvalue Restriction
+ loss_eigen = self.eigenvalue_restriction(evalues, bs, npoints)
+ star_loss = loss_trans + self.w * loss_eigen
+
+ return star_loss.mean()
diff --git a/models/STAR/lib/loss/wingLoss.py b/models/STAR/lib/loss/wingLoss.py
new file mode 100644
index 0000000000000000000000000000000000000000..578f71cbf9947ce585b2aef6c060a78f1f90993f
--- /dev/null
+++ b/models/STAR/lib/loss/wingLoss.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+
+import math
+import torch
+from torch import nn
+
+
+# torch.log and math.log is e based
+class WingLoss(nn.Module):
+ def __init__(self, omega=0.01, epsilon=2):
+ super(WingLoss, self).__init__()
+ self.omega = omega
+ self.epsilon = epsilon
+
+ def forward(self, pred, target):
+ y = target
+ y_hat = pred
+ delta_2 = (y - y_hat).pow(2).sum(dim=-1, keepdim=False)
+ # delta = delta_2.sqrt()
+ delta = delta_2.clamp(min=1e-6).sqrt()
+ C = self.omega - self.omega * math.log(1 + self.omega / self.epsilon)
+ loss = torch.where(
+ delta < self.omega,
+ self.omega * torch.log(1 + delta / self.epsilon),
+ delta - C
+ )
+ return loss.mean()
diff --git a/models/STAR/lib/metric/__init__.py b/models/STAR/lib/metric/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e843d42131dbd60a09f8951ddb652f9ce358b3f9
--- /dev/null
+++ b/models/STAR/lib/metric/__init__.py
@@ -0,0 +1,11 @@
+from .nme import NME
+from .accuracy import Accuracy
+from .fr_and_auc import FR_AUC
+from .params import count_parameters_in_MB
+
+__all__ = [
+ "NME",
+ "Accuracy",
+ "FR_AUC",
+ 'count_parameters_in_MB',
+]
diff --git a/models/STAR/lib/metric/accuracy.py b/models/STAR/lib/metric/accuracy.py
new file mode 100644
index 0000000000000000000000000000000000000000..d007da207bdd203ad4dbff24cfa5d5e0733c7b76
--- /dev/null
+++ b/models/STAR/lib/metric/accuracy.py
@@ -0,0 +1,21 @@
+import torch
+import torch.nn.functional as F
+
+class Accuracy:
+ def __init__(self):
+ pass
+
+ def __repr__(self):
+ return "Accuracy()"
+
+ def test(self, label_pd, label_gt, ignore_label=-1):
+ correct_cnt = 0
+ total_cnt = 0
+ with torch.no_grad():
+ label_pd = F.softmax(label_pd, dim=1)
+ label_pd = torch.max(label_pd, 1)[1]
+ label_gt = label_gt.long()
+ c = (label_pd == label_gt)
+ correct_cnt = torch.sum(c).item()
+ total_cnt = c.size(0) - torch.sum(label_gt==ignore_label).item()
+ return correct_cnt, total_cnt
diff --git a/models/STAR/lib/metric/fr_and_auc.py b/models/STAR/lib/metric/fr_and_auc.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4ceec47500a04eb1e42aa02ba9b67aeaf44e46b
--- /dev/null
+++ b/models/STAR/lib/metric/fr_and_auc.py
@@ -0,0 +1,25 @@
+import numpy as np
+from scipy.integrate import simps
+
+
+class FR_AUC:
+ def __init__(self, data_definition):
+ self.data_definition = data_definition
+ if data_definition == '300W':
+ self.thresh = 0.05
+ else:
+ self.thresh = 0.1
+
+ def __repr__(self):
+ return "FR_AUC()"
+
+ def test(self, nmes, thres=None, step=0.0001):
+ if thres is None:
+ thres = self.thresh
+
+ num_data = len(nmes)
+ xs = np.arange(0, thres + step, step)
+ ys = np.array([np.count_nonzero(nmes <= x) for x in xs]) / float(num_data)
+ fr = 1.0 - ys[-1]
+ auc = simps(ys, x=xs) / thres
+ return [round(fr, 4), round(auc, 6)]
diff --git a/models/STAR/lib/metric/nme.py b/models/STAR/lib/metric/nme.py
new file mode 100644
index 0000000000000000000000000000000000000000..2da6b07dc48bd1863bbc6d8365fe0e821f6f8783
--- /dev/null
+++ b/models/STAR/lib/metric/nme.py
@@ -0,0 +1,39 @@
+import torch
+import numpy as np
+
+class NME:
+ def __init__(self, nme_left_index, nme_right_index):
+ self.nme_left_index = nme_left_index
+ self.nme_right_index = nme_right_index
+
+ def __repr__(self):
+ return "NME()"
+
+ def get_norm_distance(self, landmarks):
+ assert isinstance(self.nme_right_index, list), 'the nme_right_index is not list.'
+ assert isinstance(self.nme_left_index, list), 'the nme_left, index is not list.'
+ right_pupil = landmarks[self.nme_right_index, :].mean(0)
+ left_pupil = landmarks[self.nme_left_index, :].mean(0)
+ norm_distance = np.linalg.norm(right_pupil - left_pupil)
+ return norm_distance
+
+ def test(self, label_pd, label_gt):
+ nme_list = []
+ label_pd = label_pd.data.cpu().numpy()
+ label_gt = label_gt.data.cpu().numpy()
+
+ for i in range(label_gt.shape[0]):
+ landmarks_gt = label_gt[i]
+ landmarks_pv = label_pd[i]
+ if isinstance(self.nme_right_index, list):
+ norm_distance = self.get_norm_distance(landmarks_gt)
+ elif isinstance(self.nme_right_index, int):
+ norm_distance = np.linalg.norm(landmarks_gt[self.nme_left_index] - landmarks_gt[self.nme_right_index])
+ else:
+ raise NotImplementedError
+ landmarks_delta = landmarks_pv - landmarks_gt
+ nme = (np.linalg.norm(landmarks_delta, axis=1) / norm_distance).mean()
+ nme_list.append(nme)
+ # sum_nme += nme
+ # total_cnt += 1
+ return nme_list
diff --git a/models/STAR/lib/metric/params.py b/models/STAR/lib/metric/params.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b5552085951f85279bf386242a235063f9f77ea
--- /dev/null
+++ b/models/STAR/lib/metric/params.py
@@ -0,0 +1,7 @@
+import torch.nn as nn
+
+def count_parameters_in_MB(model):
+ if isinstance(model, nn.Module):
+ return sum(v.numel() for v in model.parameters()) / 1e6
+ else:
+ return sum(v.numel() for v in model) / 1e6
\ No newline at end of file
diff --git a/models/STAR/lib/utility.py b/models/STAR/lib/utility.py
new file mode 100644
index 0000000000000000000000000000000000000000..46fb27e32c0fffd25708117220462b8ffa6e9765
--- /dev/null
+++ b/models/STAR/lib/utility.py
@@ -0,0 +1,364 @@
+import json
+import os.path as osp
+import time
+import torch
+import numpy as np
+from tqdm import tqdm
+
+import torchvision.transforms as transforms
+from torch.utils.data import DataLoader, DistributedSampler
+import torch.optim as optim
+import torch.optim.lr_scheduler as lr_scheduler
+import torch.nn.functional as F
+
+# private package
+from models.STAR.conf import *
+from models.STAR.lib.dataset import AlignmentDataset
+from models.STAR.lib.backbone import StackedHGNetV1
+from models.STAR.lib.loss import *
+from models.STAR.lib.metric import NME, FR_AUC
+from models.STAR.lib.utils import convert_secs2time
+from models.STAR.lib.utils import AverageMeter
+
+
+def get_config(args):
+ config = None
+ config_name = args.config_name
+ if config_name == "alignment":
+ config = Alignment(args)
+ else:
+ assert NotImplementedError
+
+ return config
+
+
+def get_dataset(config, tsv_file, image_dir, loader_type, is_train):
+ dataset = None
+ if loader_type == "alignment":
+ dataset = AlignmentDataset(
+ tsv_file,
+ image_dir,
+ transforms.Compose([transforms.ToTensor()]),
+ config.width,
+ config.height,
+ config.channels,
+ config.means,
+ config.scale,
+ config.classes_num,
+ config.crop_op,
+ config.aug_prob,
+ config.edge_info,
+ config.flip_mapping,
+ is_train,
+ encoder_type=config.encoder_type
+ )
+ else:
+ assert False
+ return dataset
+
+
+def get_dataloader(config, data_type, world_rank=0, world_size=1):
+ loader = None
+ if data_type == "train":
+ dataset = get_dataset(
+ config,
+ config.train_tsv_file,
+ config.train_pic_dir,
+ config.loader_type,
+ is_train=True)
+ if world_size > 1:
+ sampler = DistributedSampler(dataset, rank=world_rank, num_replicas=world_size, shuffle=True)
+ loader = DataLoader(dataset, sampler=sampler, batch_size=config.batch_size // world_size,
+ num_workers=config.train_num_workers, pin_memory=True, drop_last=True)
+ else:
+ loader = DataLoader(dataset, batch_size=config.batch_size, shuffle=True,
+ num_workers=config.train_num_workers)
+ elif data_type == "val":
+ dataset = get_dataset(
+ config,
+ config.val_tsv_file,
+ config.val_pic_dir,
+ config.loader_type,
+ is_train=False)
+ loader = DataLoader(dataset, shuffle=False, batch_size=config.val_batch_size,
+ num_workers=config.val_num_workers)
+ elif data_type == "test":
+ dataset = get_dataset(
+ config,
+ config.test_tsv_file,
+ config.test_pic_dir,
+ config.loader_type,
+ is_train=False)
+ loader = DataLoader(dataset, shuffle=False, batch_size=config.test_batch_size,
+ num_workers=config.test_num_workers)
+ else:
+ assert False
+ return loader
+
+
+def get_optimizer(config, net):
+ params = net.parameters()
+
+ optimizer = None
+ if config.optimizer == "sgd":
+ optimizer = optim.SGD(
+ params,
+ lr=config.learn_rate,
+ momentum=config.momentum,
+ weight_decay=config.weight_decay,
+ nesterov=config.nesterov)
+ elif config.optimizer == "adam":
+ optimizer = optim.Adam(
+ params,
+ lr=config.learn_rate)
+ elif config.optimizer == "rmsprop":
+ optimizer = optim.RMSprop(
+ params,
+ lr=config.learn_rate,
+ momentum=config.momentum,
+ alpha=config.alpha,
+ eps=config.epsilon,
+ weight_decay=config.weight_decay
+ )
+ else:
+ assert False
+ return optimizer
+
+
+def get_scheduler(config, optimizer):
+ if config.scheduler == "MultiStepLR":
+ scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=config.milestones, gamma=config.gamma)
+ else:
+ assert False
+ return scheduler
+
+
+def get_net(config):
+ net = None
+ if config.net == "stackedHGnet_v1":
+ net = StackedHGNetV1(config=config,
+ classes_num=config.classes_num,
+ edge_info=config.edge_info,
+ nstack=config.nstack,
+ add_coord=config.add_coord,
+ decoder_type=config.decoder_type)
+ else:
+ assert False
+ return net
+
+
+def get_criterions(config):
+ criterions = list()
+ for k in range(config.label_num):
+ if config.criterions[k] == "AWingLoss":
+ criterion = AWingLoss()
+ elif config.criterions[k] == "smoothl1":
+ criterion = SmoothL1Loss()
+ elif config.criterions[k] == "l1":
+ criterion = F.l1_loss
+ elif config.criterions[k] == 'l2':
+ criterion = F.mse_loss
+ elif config.criterions[k] == "STARLoss":
+ criterion = STARLoss(dist=config.star_dist, w=config.star_w)
+ elif config.criterions[k] == "STARLoss_v2":
+ criterion = STARLoss_v2(dist=config.star_dist, w=config.star_w)
+ else:
+ assert False
+ criterions.append(criterion)
+ return criterions
+
+
+def set_environment(config):
+ if config.device_id >= 0:
+ assert torch.cuda.is_available() and torch.cuda.device_count() > config.device_id
+ torch.cuda.empty_cache()
+ config.device = torch.device("cuda", config.device_id)
+ config.use_gpu = True
+ else:
+ config.device = torch.device("cpu")
+ config.use_gpu = False
+
+ torch.set_default_dtype(torch.float32)
+ torch.set_default_tensor_type(torch.FloatTensor)
+ torch.set_flush_denormal(True) # ignore extremely small value
+ torch.backends.cudnn.benchmark = True # This flag allows you to enable the inbuilt cudnn auto-tuner to find the best algorithm to use for your hardware.
+ torch.autograd.set_detect_anomaly(True)
+
+
+def forward(config, test_loader, net):
+ # ave_metrics = [[0, 0] for i in range(config.label_num)]
+ list_nmes = [[] for i in range(config.label_num)]
+ metric_nme = NME(nme_left_index=config.nme_left_index, nme_right_index=config.nme_right_index)
+ metric_fr_auc = FR_AUC(data_definition=config.data_definition)
+
+ output_pd = None
+
+ net = net.float().to(config.device)
+ net.eval()
+ dataset_size = len(test_loader.dataset)
+ batch_size = test_loader.batch_size
+ if config.logger is not None:
+ config.logger.info("Forward process, Dataset size: %d, Batch size: %d" % (dataset_size, batch_size))
+ for i, sample in enumerate(tqdm(test_loader)):
+ input = sample["data"].float().to(config.device, non_blocking=True)
+ labels = list()
+ if isinstance(sample["label"], list):
+ for label in sample["label"]:
+ label = label.float().to(config.device, non_blocking=True)
+ labels.append(label)
+ else:
+ label = sample["label"].float().to(config.device, non_blocking=True)
+ for k in range(label.shape[1]):
+ labels.append(label[:, k])
+ labels = config.nstack * labels
+
+ with torch.no_grad():
+ output, heatmap, landmarks = net(input)
+
+ # metrics
+ for k in range(config.label_num):
+ if config.metrics[k] is not None:
+ list_nmes[k] += metric_nme.test(output[k], labels[k])
+
+ metrics = [[np.mean(nmes), ] + metric_fr_auc.test(nmes) for nmes in list_nmes]
+
+ return output_pd, metrics
+
+
+def compute_loss(config, criterions, output, labels, heatmap=None, landmarks=None):
+ batch_weight = 1.0
+ sum_loss = 0
+ losses = list()
+ for k in range(config.label_num):
+ if config.criterions[k] in ['smoothl1', 'l1', 'l2', 'WingLoss', 'AWingLoss']:
+ loss = criterions[k](output[k], labels[k])
+ elif config.criterions[k] in ["STARLoss", "STARLoss_v2"]:
+ _k = int(k / 3) if config.use_AAM else k
+ loss = criterions[k](heatmap[_k], labels[k])
+ else:
+ assert NotImplementedError
+ loss = batch_weight * loss
+ sum_loss += config.loss_weights[k] * loss
+ loss = float(loss.data.cpu().item())
+ losses.append(loss)
+ return losses, sum_loss
+
+
+def forward_backward(config, train_loader, net_module, net, net_ema, criterions, optimizer, epoch):
+ train_model_time = AverageMeter()
+ ave_losses = [0] * config.label_num
+
+ net_module = net_module.float().to(config.device)
+ net_module.train(True)
+ dataset_size = len(train_loader.dataset)
+ batch_size = config.batch_size # train_loader.batch_size
+ batch_num = max(dataset_size / max(batch_size, 1), 1)
+ if config.logger is not None:
+ config.logger.info(config.note)
+ config.logger.info("Forward Backward process, Dataset size: %d, Batch size: %d" % (dataset_size, batch_size))
+
+ iter_num = len(train_loader)
+ epoch_start_time = time.time()
+ if net_module != net:
+ train_loader.sampler.set_epoch(epoch)
+ for iter, sample in enumerate(train_loader):
+ iter_start_time = time.time()
+ # input
+ input = sample["data"].float().to(config.device, non_blocking=True)
+ # labels
+ labels = list()
+ if isinstance(sample["label"], list):
+ for label in sample["label"]:
+ label = label.float().to(config.device, non_blocking=True)
+ labels.append(label)
+ else:
+ label = sample["label"].float().to(config.device, non_blocking=True)
+ for k in range(label.shape[1]):
+ labels.append(label[:, k])
+ labels = config.nstack * labels
+ # forward
+ output, heatmaps, landmarks = net_module(input)
+
+ # loss
+ losses, sum_loss = compute_loss(config, criterions, output, labels, heatmaps, landmarks)
+ ave_losses = list(map(sum, zip(ave_losses, losses)))
+
+ # backward
+ optimizer.zero_grad()
+ with torch.autograd.detect_anomaly():
+ sum_loss.backward()
+ # torch.nn.utils.clip_grad_norm_(net_module.parameters(), 128.0)
+ optimizer.step()
+
+ if net_ema is not None:
+ accumulate_net(net_ema, net, 0.5 ** (config.batch_size / 10000.0))
+ # accumulate_net(net_ema, net, 0.5 ** (8 / 10000.0))
+
+ # output
+ train_model_time.update(time.time() - iter_start_time)
+ last_time = convert_secs2time(train_model_time.avg * (iter_num - iter - 1), True)
+ if iter % config.display_iteration == 0 or iter + 1 == len(train_loader):
+ if config.logger is not None:
+ losses_str = ' Average Loss: {:.6f}'.format(sum(losses) / len(losses))
+ for k, loss in enumerate(losses):
+ losses_str += ', L{}: {:.3f}'.format(k, loss)
+ config.logger.info(
+ ' -->>[{:03d}/{:03d}][{:03d}/{:03d}]'.format(epoch, config.max_epoch, iter, iter_num) \
+ + last_time + losses_str)
+
+ epoch_end_time = time.time()
+ epoch_total_time = epoch_end_time - epoch_start_time
+ epoch_load_data_time = epoch_total_time - train_model_time.sum
+ if config.logger is not None:
+ config.logger.info("Train/Epoch: %d/%d, Average total time cost per iteration in this epoch: %.6f" % (
+ epoch, config.max_epoch, epoch_total_time / iter_num))
+ config.logger.info("Train/Epoch: %d/%d, Average loading data time cost per iteration in this epoch: %.6f" % (
+ epoch, config.max_epoch, epoch_load_data_time / iter_num))
+ config.logger.info("Train/Epoch: %d/%d, Average training model time cost per iteration in this epoch: %.6f" % (
+ epoch, config.max_epoch, train_model_time.avg))
+
+ ave_losses = [loss / iter_num for loss in ave_losses]
+ if config.logger is not None:
+ config.logger.info("Train/Epoch: %d/%d, Average Loss in this epoch: %.6f" % (
+ epoch, config.max_epoch, sum(ave_losses) / len(ave_losses)))
+ for k, ave_loss in enumerate(ave_losses):
+ if config.logger is not None:
+ config.logger.info("Train/Loss%03d in this epoch: %.6f" % (k, ave_loss))
+
+
+def accumulate_net(model1, model2, decay):
+ """
+ operation: model1 = model1 * decay + model2 * (1 - decay)
+ """
+ par1 = dict(model1.named_parameters())
+ par2 = dict(model2.named_parameters())
+ for k in par1.keys():
+ par1[k].data.mul_(decay).add_(
+ other=par2[k].data.to(par1[k].data.device),
+ alpha=1 - decay)
+
+ par1 = dict(model1.named_buffers())
+ par2 = dict(model2.named_buffers())
+ for k in par1.keys():
+ if par1[k].data.is_floating_point():
+ par1[k].data.mul_(decay).add_(
+ other=par2[k].data.to(par1[k].data.device),
+ alpha=1 - decay)
+ else:
+ par1[k].data = par2[k].data.to(par1[k].data.device)
+
+
+def save_model(config, epoch, net, net_ema, optimizer, scheduler, pytorch_model_path):
+ # save pytorch model
+ state = {
+ "net": net.state_dict(),
+ "optimizer": optimizer.state_dict(),
+ "scheduler": scheduler.state_dict(),
+ "epoch": epoch
+ }
+ if config.ema:
+ state["net_ema"] = net_ema.state_dict()
+
+ torch.save(state, pytorch_model_path)
+ if config.logger is not None:
+ config.logger.info("Epoch: %d/%d, model saved in this epoch" % (epoch, config.max_epoch))
diff --git a/models/STAR/lib/utils/__init__.py b/models/STAR/lib/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8cf0cbd5b0bf523d300e6f35167eadf85a1e1a46
--- /dev/null
+++ b/models/STAR/lib/utils/__init__.py
@@ -0,0 +1,16 @@
+from .meter import AverageMeter
+from .time_utils import time_print, time_string, time_string_short, time_for_file
+from .time_utils import convert_secs2time, convert_size2str
+from .vis_utils import plot_points
+
+__all__ = [
+ "AverageMeter",
+ "time_print",
+ "time_string",
+ "time_string_short",
+ "time_for_file",
+ "convert_size2str",
+ "convert_secs2time",
+
+ "plot_points",
+]
diff --git a/models/STAR/lib/utils/dist_utils.py b/models/STAR/lib/utils/dist_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed54cab62100d985509ec1070257a790fdffac9c
--- /dev/null
+++ b/models/STAR/lib/utils/dist_utils.py
@@ -0,0 +1,183 @@
+import torch
+from torch.autograd import Variable
+import matplotlib.pyplot as plt
+import seaborn as sns
+
+
+def get_channel_sum(input):
+ """
+ Generates the sum of each channel of the input
+ input = batch_size x 68 x 64 x 64
+ output = batch_size x 68
+ """
+ temp = torch.sum(input, dim=3)
+ output = torch.sum(temp, dim=2)
+
+ return output
+
+
+def expand_two_dimensions_at_end(input, dim1, dim2):
+ """
+ Adds two more dimensions to the end of the input
+ input = batch_size x 68
+ output= batch_size x 68 x dim1 x dim2
+ """
+ input = input.unsqueeze(-1).unsqueeze(-1)
+ input = input.expand(-1, -1, dim1, dim2)
+
+ return input
+
+
+class Distribution(object):
+ def __init__(self, heatmaps, num_dim_dist=2, EPSILON=1e-5, is_normalize=True):
+ self.heatmaps = heatmaps
+ self.num_dim_dist = num_dim_dist
+ self.EPSILON = EPSILON
+ self.is_normalize = is_normalize
+ batch, npoints, h, w = heatmaps.shape
+ # normalize
+ heatmap_sum = torch.clamp(heatmaps.sum([2, 3]), min=1e-6)
+ self.heatmaps = heatmaps / heatmap_sum.view(batch, npoints, 1, 1)
+
+ # means [batch_size x 68 x 2]
+ self.mean = self.get_spatial_mean(self.heatmaps)
+ # covars [batch_size x 68 x 2 x 2]
+ self.covars = self.get_covariance_matrix(self.heatmaps, self.mean)
+
+ _covars = self.covars.view(batch * npoints, 2, 2).cpu()
+ evalues, evectors = _covars.symeig(eigenvectors=True)
+ # eigenvalues [batch_size x 68 x 2]
+ self.evalues = evalues.view(batch, npoints, 2).to(heatmaps)
+ # eignvectors [batch_size x 68 x 2 x 2]
+ self.evectors = evectors.view(batch, npoints, 2, 2).to(heatmaps)
+
+ def __repr__(self):
+ return "Distribution()"
+
+ def plot(self, heatmap, mean, evalues, evectors):
+ # heatmap is not normalized
+ plt.figure(0)
+ if heatmap.is_cuda:
+ heatmap, mean = heatmap.cpu(), mean.cpu()
+ evalues, evectors = evalues.cpu(), evectors.cpu()
+ sns.heatmap(heatmap, cmap="RdBu_r")
+ for evalue, evector in zip(evalues, evectors):
+ plt.arrow(mean[0], mean[1], evalue * evector[0], evalue * evector[1],
+ width=0.2, shape="full")
+ plt.show()
+
+ def easy_plot(self, index):
+ # index = (num of batch_size, num of num_points)
+ num_bs, num_p = index
+ heatmap = self.heatmaps[num_bs, num_p]
+ mean = self.mean[num_bs, num_p]
+ evalues = self.evalues[num_bs, num_p]
+ evectors = self.evectors[num_bs, num_p]
+ self.plot(heatmap, mean, evalues, evectors)
+
+ def project_and_scale(self, pts, eigenvalues, eigenvectors):
+ batch_size, npoints, _ = pts.shape
+ proj_pts = torch.matmul(pts.view(batch_size, npoints, 1, 2), eigenvectors)
+ scale_proj_pts = proj_pts.view(batch_size, npoints, 2) / torch.sqrt(eigenvalues)
+ return scale_proj_pts
+
+ def _make_grid(self, h, w):
+ if self.is_normalize:
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float() / (h - 1) * 2 - 1,
+ torch.arange(w).float() / (w - 1) * 2 - 1)
+ else:
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float(),
+ torch.arange(w).float()
+ )
+
+ return yy, xx
+
+ def get_spatial_mean(self, heatmap):
+ batch, npoints, h, w = heatmap.shape
+
+ yy, xx = self._make_grid(h, w)
+ yy = yy.view(1, 1, h, w).to(heatmap)
+ xx = xx.view(1, 1, h, w).to(heatmap)
+
+ yy_coord = (yy * heatmap).sum([2, 3]) # batch x npoints
+ xx_coord = (xx * heatmap).sum([2, 3]) # batch x npoints
+ coords = torch.stack([xx_coord, yy_coord], dim=-1)
+ return coords
+
+ def get_covariance_matrix(self, htp, means):
+ """
+ Covariance calculation from the normalized heatmaps
+ Reference https://en.wikipedia.org/wiki/Weighted_arithmetic_mean#Weighted_sample_covariance
+ The unbiased estimate is given by
+ Unbiased covariance =
+ ___
+ \
+ /__ w_i (x_i - \mu_i)^T (x_i - \mu_i)
+
+ ___________________________________________
+
+ V_1 - (V_2/V_1)
+
+ ___ ___
+ \ \
+ where V_1 = /__ w_i and V_2 = /__ w_i^2
+
+
+ Input:
+ htp = batch_size x 68 x 64 x 64
+ means = batch_size x 68 x 2
+
+ Output:
+ covariance = batch_size x 68 x 2 x 2
+ """
+ batch_size = htp.shape[0]
+ num_points = htp.shape[1]
+ height = htp.shape[2]
+ width = htp.shape[3]
+
+ yv, xv = self._make_grid(height, width)
+ xv = Variable(xv)
+ yv = Variable(yv)
+
+ if htp.is_cuda:
+ xv = xv.cuda()
+ yv = yv.cuda()
+
+ xmean = means[:, :, 0]
+ xv_minus_mean = xv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(xmean, height,
+ width) # batch_size x 68 x 64 x 64
+ ymean = means[:, :, 1]
+ yv_minus_mean = yv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(ymean, height,
+ width) # batch_size x 68 x 64 x 64
+
+ # These are the unweighted versions
+ wt_xv_minus_mean = xv_minus_mean
+ wt_yv_minus_mean = yv_minus_mean
+
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, height * width) # batch_size*68 x 4096
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, 1,
+ height * width) # batch_size*68 x 1 x 4096
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, height * width) # batch_size*68 x 4096
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, 1,
+ height * width) # batch_size*68 x 1 x 4096
+ vec_concat = torch.cat((wt_xv_minus_mean, wt_yv_minus_mean), 1) # batch_size*68 x 2 x 4096
+
+ htp_vec = htp.view(batch_size * num_points, 1, height * width)
+ htp_vec = htp_vec.expand(-1, 2, -1)
+
+ # Torch batch matrix multiplication
+ # https://pytorch.org/docs/stable/torch.html#torch.bmm
+ # Also use the heatmap as the weights at one place now
+ covariance = torch.bmm(htp_vec * vec_concat, vec_concat.transpose(1, 2)) # batch_size*68 x 2 x 2
+ covariance = covariance.view(batch_size, num_points, self.num_dim_dist,
+ self.num_dim_dist) # batch_size x 68 x 2 x 2
+
+ V_1 = get_channel_sum(htp) + self.EPSILON # batch_size x 68
+ V_2 = get_channel_sum(torch.pow(htp, 2)) # batch_size x 68
+ denominator = V_1 - (V_2 / V_1)
+
+ covariance = covariance / expand_two_dimensions_at_end(denominator, self.num_dim_dist, self.num_dim_dist)
+
+ return (covariance)
diff --git a/models/STAR/lib/utils/meter.py b/models/STAR/lib/utils/meter.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ba5f27e79f85b02fd7dffad665cdf826731d462
--- /dev/null
+++ b/models/STAR/lib/utils/meter.py
@@ -0,0 +1,20 @@
+class AverageMeter(object):
+ """Computes and stores the average and current value"""
+
+ def __init__(self):
+ self.reset()
+
+ def reset(self):
+ self.val = 0.0
+ self.avg = 0.0
+ self.sum = 0.0
+ self.count = 0.0
+
+ def update(self, val, n=1):
+ self.val = val
+ self.sum += val
+ self.count += n
+ self.avg = self.sum / self.count
+
+ def __repr__(self):
+ return ('{name}(val={val}, avg={avg}, count={count})'.format(name=self.__class__.__name__, **self.__dict__))
\ No newline at end of file
diff --git a/models/STAR/lib/utils/time_utils.py b/models/STAR/lib/utils/time_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d177aafea369fbd5e006a3a6fdbe01fe51207e6f
--- /dev/null
+++ b/models/STAR/lib/utils/time_utils.py
@@ -0,0 +1,49 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+# All rights reserved.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+import time, sys
+import numpy as np
+
+
+def time_for_file():
+ ISOTIMEFORMAT = '%d-%h-at-%H-%M-%S'
+ return '{}'.format(time.strftime(ISOTIMEFORMAT, time.gmtime(time.time())))
+
+
+def time_string():
+ ISOTIMEFORMAT = '%Y-%m-%d %X'
+ string = '[{}]'.format(time.strftime(ISOTIMEFORMAT, time.gmtime(time.time())))
+ return string
+
+
+def time_string_short():
+ ISOTIMEFORMAT = '%Y%m%d'
+ string = '{}'.format(time.strftime(ISOTIMEFORMAT, time.gmtime(time.time())))
+ return string
+
+
+def time_print(string, is_print=True):
+ if (is_print):
+ print('{} : {}'.format(time_string(), string))
+
+
+def convert_size2str(torch_size):
+ dims = len(torch_size)
+ string = '['
+ for idim in range(dims):
+ string = string + ' {}'.format(torch_size[idim])
+ return string + ']'
+
+
+def convert_secs2time(epoch_time, return_str=False):
+ need_hour = int(epoch_time / 3600)
+ need_mins = int((epoch_time - 3600 * need_hour) / 60)
+ need_secs = int(epoch_time - 3600 * need_hour - 60 * need_mins)
+ if return_str:
+ str = '[Time Left: {:02d}:{:02d}:{:02d}]'.format(need_hour, need_mins, need_secs)
+ return str
+ else:
+ return need_hour, need_mins, need_secs
diff --git a/models/STAR/lib/utils/vis_utils.py b/models/STAR/lib/utils/vis_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..99b5ed1471d9eb75328bf4ae4396d4e3b2544b4e
--- /dev/null
+++ b/models/STAR/lib/utils/vis_utils.py
@@ -0,0 +1,31 @@
+import cv2
+import numpy as np
+import numbers
+
+
+def plot_points(vis, points, radius=1, color=(255, 255, 0), shift=4, indexes=0, is_index=False):
+ if isinstance(points, list):
+ num_point = len(points)
+ elif isinstance(points, np.numarray):
+ num_point = points.shape[0]
+ else:
+ raise NotImplementedError
+ if isinstance(radius, numbers.Number):
+ radius = np.zeros((num_point)) + radius
+
+ if isinstance(indexes, numbers.Number):
+ indexes = [indexes + i for i in range(num_point)]
+ elif isinstance(indexes, list):
+ pass
+ else:
+ raise NotImplementedError
+
+ factor = (1 << shift)
+ for (index, p, s) in zip(indexes, points, radius):
+ cv2.circle(vis, (int(p[0] * factor + 0.5), int(p[1] * factor + 0.5)),
+ int(s * factor), color, 1, cv2.LINE_AA, shift=shift)
+ if is_index:
+ vis = cv2.putText(vis, str(index), (int(p[0]), int(p[1])), cv2.FONT_HERSHEY_SIMPLEX, 0.2,
+ (255, 255, 255), 1)
+
+ return vis
diff --git a/models/STAR/main.py b/models/STAR/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5147d7a77e98a0a15720a54557f40524caf4c27
--- /dev/null
+++ b/models/STAR/main.py
@@ -0,0 +1,67 @@
+import argparse
+from trainer import train
+from tester import test
+
+
+def add_data_options(parser):
+ group = parser.add_argument_group("dataset")
+ group.add_argument("--image_dir", type=str, default=None, help="the directory of image")
+ group.add_argument("--annot_dir", type=str, default=None, help="the directory of annot")
+
+
+def add_base_options(parser):
+ group = parser.add_argument_group("base")
+ group.add_argument("--mode", type=str, default="train", help="train or test")
+ group.add_argument("--config_name", type=str, default="alignment", help="set configure file name")
+ group.add_argument('--device_ids', type=str, default="0,1,2,3",
+ help="set device ids, -1 means use cpu device, >= 0 means use gpu device")
+ group.add_argument('--data_definition', type=str, default='WFLW', help="COFW, 300W, WFLW")
+ group.add_argument('--learn_rate', type=float, default=0.001, help='learning rate')
+ group.add_argument("--batch_size", type=int, default=128, help="the batch size in train process")
+ group.add_argument('--width', type=int, default=256, help='the width of input image')
+ group.add_argument('--height', type=int, default=256, help='the height of input image')
+
+
+def add_train_options(parser):
+ group = parser.add_argument_group('train')
+ group.add_argument("--train_num_workers", type=int, default=None, help="the num of workers in train process")
+ group.add_argument('--loss_func', type=str, default='STARLoss_v2', help="loss function")
+ group.add_argument("--val_batch_size", type=int, default=None, help="the batch size in val process")
+ group.add_argument("--val_num_workers", type=int, default=None, help="the num of workers in val process")
+
+
+def add_eval_options(parser):
+ group = parser.add_argument_group("eval")
+ group.add_argument("--pretrained_weight", type=str, default=None,
+ help="set pretrained model file name, if ignored then train the network without pretrain model")
+ group.add_argument('--norm_type', type=str, default='default', help='default, ocular, pupil')
+ group.add_argument('--test_file', type=str, default="test.tsv", help='for wflw, test.tsv/test_xx_metadata.tsv')
+
+
+def add_starloss_options(parser):
+ group = parser.add_argument_group('starloss')
+ group.add_argument('--star_w', type=float, default=1, help="regular loss ratio")
+ group.add_argument('--star_dist', type=str, default='smoothl1', help='STARLoss distance function')
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Entry Function")
+ add_base_options(parser)
+ add_data_options(parser)
+ add_train_options(parser)
+ add_eval_options(parser)
+ add_starloss_options(parser)
+
+ args = parser.parse_args()
+ print(args)
+
+ print(
+ "mode is %s, config_name is %s, pretrained_weight is %s, image_dir is %s, annot_dir is %s, device_ids is %s" % (
+ args.mode, args.config_name, args.pretrained_weight, args.image_dir, args.annot_dir, args.device_ids))
+ args.device_ids = list(map(int, args.device_ids.split(",")))
+ if args.mode == "train":
+ train(args)
+ elif args.mode == "test":
+ test(args)
+ else:
+ print("unknown running mode")
diff --git a/models/STAR/requirements.txt b/models/STAR/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2e61114224b460979bc877eff7a0d96571831199
--- /dev/null
+++ b/models/STAR/requirements.txt
@@ -0,0 +1,19 @@
+tqdm
+torch==1.6.0
+torchvision==0.7.0
+python-gflags==3.1.2
+pandas==0.24.2
+pillow==6.0.0
+numpy==1.16.4
+opencv-python==4.1.0.25
+imageio==2.5.0
+imgaug==0.2.9
+lmdb==0.98
+lxml==4.5.0
+tensorboard==2.4.1
+protobuf==3.20
+tensorboardX==1.8
+# pyarrow==0.17.1
+# wandb==0.10.25
+# https://pytorch.org/get-started/previous-versions/
+# pip install torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
diff --git a/models/STAR/tester.py b/models/STAR/tester.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b79b2c2b7da39b28ed4572fe3861e84903b661b
--- /dev/null
+++ b/models/STAR/tester.py
@@ -0,0 +1,49 @@
+import os
+import torch
+from lib import utility
+
+
+def test(args):
+ # conf
+ config = utility.get_config(args)
+ config.device_id = args.device_ids[0]
+
+ # set environment
+ utility.set_environment(config)
+ config.init_instance()
+ if config.logger is not None:
+ config.logger.info("Loaded configure file %s: %s" % (args.config_name, config.id))
+ config.logger.info("\n" + "\n".join(["%s: %s" % item for item in config.__dict__.items()]))
+
+ # model
+ net = utility.get_net(config)
+ model_path = os.path.join(config.model_dir,
+ "train.pkl") if args.pretrained_weight is None else args.pretrained_weight
+ if args.device_ids == [-1]:
+ checkpoint = torch.load(model_path, map_location="cpu")
+ else:
+ checkpoint = torch.load(model_path)
+
+ net.load_state_dict(checkpoint["net"])
+
+ if config.logger is not None:
+ config.logger.info("Loaded network")
+ # config.logger.info('Net flops: {} G, params: {} MB'.format(flops/1e9, params/1e6))
+
+ # data - test
+ test_loader = utility.get_dataloader(config, "test")
+
+ if config.logger is not None:
+ config.logger.info("Loaded data from {:}".format(config.test_tsv_file))
+
+ # inference
+ result, metrics = utility.forward(config, test_loader, net)
+ if config.logger is not None:
+ config.logger.info("Finished inference")
+
+ # output
+ for k, metric in enumerate(metrics):
+ if config.logger is not None and len(metric) != 0:
+ config.logger.info(
+ "Tested {} dataset, the Size is {}, Metric: [NME {:.6f}, FR {:.6f}, AUC {:.6f}]".format(
+ config.type, len(test_loader.dataset), metric[0], metric[1], metric[2]))
diff --git a/models/STAR/tools/analysis_motivation.py b/models/STAR/tools/analysis_motivation.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbcbdd3a30510c07c3571675e0452eba70de442f
--- /dev/null
+++ b/models/STAR/tools/analysis_motivation.py
@@ -0,0 +1,220 @@
+import glob
+import json
+import os.path as osp
+import numpy as np
+from tqdm import tqdm
+import matplotlib.pyplot as plt
+import seaborn as sns
+from pandas import DataFrame
+import pandas as pd
+
+
+def L2(p1, p2):
+ return np.linalg.norm(p1 - p2)
+
+
+def NME(landmarks_gt, landmarks_pv):
+ pts_num = landmarks_gt.shape[0]
+ if pts_num == 29:
+ left_index = 16
+ right_index = 17
+ elif pts_num == 68:
+ left_index = 36
+ right_index = 45
+ elif pts_num == 98:
+ left_index = 60
+ right_index = 72
+
+ nme = 0
+ eye_span = L2(landmarks_gt[left_index], landmarks_gt[right_index])
+ nmeList = []
+ for i in range(pts_num):
+ error = L2(landmarks_pv[i], landmarks_gt[i])
+ _nme = error / eye_span
+ nmeList.append(_nme)
+ nme += _nme
+ nme /= pts_num
+ return nme, nmeList
+
+
+def NME_analysis(listA):
+ for jsonA in listA:
+ pred = np.array(jsonA['pred'])
+ gt = np.array(jsonA['gt'])
+ nme, nmeList = NME(gt, pred)
+ jsonA['nme'] = nme
+ jsonA['nmeList'] = nmeList
+ return listA
+
+
+def nme_analysis(listA):
+ bdy_nmeList = []
+ scene_nmeList = []
+ for jsonA in tqdm(listA):
+ nme = jsonA['nmeList']
+ nme = np.array(nme)
+ bdy_nme = np.mean(nme[:33])
+ scene_nme = np.mean(nme[33:])
+ # scene_nme = np.mean(nme[[33, 35, 40, 38,
+ # 60, 62, 96, 66, 64,
+ # 50, 44, 48, 46,
+ # 68, 70, 97, 74, 72,
+ # 54, 55, 57, 59,
+ # 76, 82, 79, 90, 94, 85, 16]])
+ bdy_nmeList.append(bdy_nme)
+ scene_nmeList.append(scene_nme)
+ print('bdy nme: {:.4f}'.format(np.mean(bdy_nmeList)))
+ print('scene_nmeList: {:.4f}'.format(np.mean(scene_nmeList)))
+
+
+def Energy_analysis(listA, easyThresh=0.02, easyNum=10, hardThresh=0.07, hardNum=10):
+ easyDict = {'energy': [], 'nme': []}
+ hardDict = {'energy': [], 'nme': []}
+
+ _easyNum, _hardNum = 0, 0
+
+ def cal_energy(evalues):
+ evalues = np.array(evalues)
+ # _energy = _energy.max(1)
+ eccentricity = evalues.max(1) / evalues.min(1)
+ # _energy = _energy.sum() / 2
+ _energy = np.mean(eccentricity)
+ return _energy
+
+ for jsonA in tqdm(listA):
+ nme = jsonA['nme']
+ evalues = jsonA['evalues']
+
+ if _easyNum == easyNum and _hardNum == hardNum:
+ break
+
+ if nme < easyThresh and _easyNum < easyNum:
+ energy = cal_energy(evalues)
+ easyDict['energy'].append(energy)
+ easyDict['nme'].append(nme)
+ _easyNum += 1
+ elif nme > hardThresh and _hardNum < hardNum:
+ energy = cal_energy(evalues)
+ hardDict['energy'].append(energy)
+ hardDict['nme'].append(nme)
+ _hardNum += 1
+
+ print('easyThresh: < {}; hardThresh > {}'.format(easyThresh, hardThresh))
+ print(' |nme |energy |num |')
+ print('easy samples: |{:.4f} |{:.4f} |{} |'.format(np.mean(easyDict['nme']),
+ np.mean(easyDict['energy']),
+ len(easyDict['energy'])))
+ print('hard samples: |{:.4f} |{:.4f} |{} |'.format(np.mean(hardDict['nme']),
+ np.mean(hardDict['energy']),
+ len(hardDict['energy'])))
+
+ return easyDict, hardDict
+
+
+def Eccentricity_analysis(listA):
+ eyecornerList = []
+ boundaryList = []
+ for jsonA in listA:
+ evalues = np.array(jsonA['evalues'])
+ eccentricity = evalues.max(1) / evalues.min(1)
+
+ eyecorner = np.mean(eccentricity[[60, 64, 68, 72]])
+ boundary = np.mean(eccentricity[0:33])
+ eyecornerList.append(eyecorner)
+ boundaryList.append(boundary)
+
+ print('eyecorner: {:.4f}'.format(np.mean(eyecornerList)))
+ print('boundary: {:.4f}'.format(np.mean(boundaryList)))
+ return eyecornerList, boundaryList
+
+
+def plot_bar(dataList):
+ x = list(range(98))
+ assert len(x) == len(dataList)
+ _x = 'Landmark Index'
+ # _y = 'elliptical eccentricity (λ1/λ2)'
+ _y = 'PCA Analyze (λ1/λ2)'
+ data = {
+ _x: x,
+ _y: dataList
+ }
+ df = DataFrame(data)
+ plt.figure(figsize=(10, 4))
+ sns.barplot(x=_x, y=_y, data=df)
+ plt.show()
+
+
+def Eccentricity_analysis2(listA, is_vis=False):
+ landmarksList = [[] for i in range(98)]
+ for jsonA in listA:
+ evalues = np.array(jsonA['evalues'])
+ eccentricity = evalues.max(1) / evalues.min(1)
+ for i, e in enumerate(eccentricity):
+ landmarksList[i].append(e)
+ print('Mean value: {:.4f}'.format(np.mean(np.array(landmarksList))))
+ landmarksList = [np.mean(l) for l in landmarksList]
+ if is_vis:
+ plot_bar(landmarksList)
+ return landmarksList
+
+
+def std_analysis2():
+ save_dir = '/apdcephfs/share_1134483/charlinzhou/experiment/cvpr-23/wflw_results'
+ # l2_npy = glob.glob(osp.join(save_dir, '*DSNT*.npy'))
+ l2_npy = glob.glob(osp.join(save_dir, '*MHNLoss_v2_l2*.npy'))
+
+ def npy2std(npyList):
+ datas = [np.load(npy)[np.newaxis, :] for npy in npyList]
+ datas = np.concatenate(datas, axis=0)
+ # denormalization
+ datas = (datas + 1) * 256 / 2
+ mean = datas.mean(axis=0)[np.newaxis, :]
+ dist = np.linalg.norm(datas - mean, axis=-1)
+ std = np.std(dist, 0)
+ print('min: {}, max:{}, mean:{}'.format(std.min(), std.max(), std.mean()))
+ return std
+
+ std1 = npy2std(l2_npy)
+ std1 = std1.mean(0)
+ # plot_bar(std1)
+ bdy_std = np.mean(std1[:33])
+ cofw_std = np.mean(std1[[33, 35, 40, 38,
+ 60, 62, 96, 66, 64,
+ 50, 44, 48, 46,
+ 68, 70, 97, 74, 72,
+ 54, 55, 57, 59,
+ 76, 82, 79, 90, 94, 85, 16]])
+ print('bdy_std: {:.4f}, cofw_std: {:.4f}'.format(bdy_std, cofw_std))
+ print('the ratio of Boundary std and ALL std: {:.4f} / {:.4f}'.format(np.sum(std1[:33]), np.sum(std1)))
+
+
+if __name__ == '__main__':
+ # 4.29模型
+ json_path = '/apdcephfs/share_1134483/charlinzhou/ckpts/STAR/WFLW/WFLW_256x256_adam_ep500_lr0.001_bs128_STARLoss_smoothl1_1_b0183746-161a-4b76-9cb9-8a2059090233/results.json'
+ # 无初始化
+ # json_path = '/apdcephfs/share_1134483/charlinzhou/ckpts/STAR/WFLW/WFLW_256x256_adam_ep500_lr0.001_bs128_STARLoss_smoothl1_1_9cff3656-8ca8-4c3d-a95d-da76f9f76ea5/results.json'
+ # 4.02模型
+ # json_path = '/apdcephfs/share_1134483/charlinzhou/ckpts/STAR/WFLW/WFLW_256x256_adam_ep500_lr0.001_bs128_STARLoss_smoothl1_1_AAM_2d2bb70e-6fdb-459c-baf7-18c89e7a165f/results.json'
+ listA = json.load(open(json_path, 'r'))
+ print('Load Done!')
+ listA = NME_analysis(listA)
+ print('NME analysis Done!')
+ # Exp1: 分析简单样本和困难样本的能量差异
+ easyDict, hardDict = Energy_analysis(listA, easyNum=2500, hardNum=2500, easyThresh=0.03, hardThresh=0.08)
+
+ # Exp2.1: 分析眼角点和轮廓点的斜率差异
+ # eyecornerList, boundaryList = Eccentricity_analysis(listA)
+
+ # Exp2.2: 可视化所有点的斜率分布
+ # landmarksList = Eccentricity_analysis2(listA, is_vis=True)
+
+ # Exp2.3: 可视化所有点的方差分布
+ # std_analysis2()
+
+ # Exp3: 五官和轮廓NME分析
+ # nme_analysis(listA)
+ # print(easyDict)
+ # print(hardDict)
+
+ # nmeList = [jsonA['nme'] for jsonA in listA]
+ # print(len(nmeList))
diff --git a/models/STAR/tools/infinite_loop.py b/models/STAR/tools/infinite_loop.py
new file mode 100644
index 0000000000000000000000000000000000000000..510011e4ddcbef5c6b67dce38edce3e2236b694d
--- /dev/null
+++ b/models/STAR/tools/infinite_loop.py
@@ -0,0 +1,4 @@
+import time
+
+while True:
+ time.sleep(1)
diff --git a/models/STAR/tools/infinite_loop_gpu.py b/models/STAR/tools/infinite_loop_gpu.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bfc2a50fede08ce1412f03aee5db9132ca285ff
--- /dev/null
+++ b/models/STAR/tools/infinite_loop_gpu.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+
+import os
+import time
+import torch
+import argparse
+
+parser = argparse.ArgumentParser(description='inf')
+parser.add_argument('--gpu', default='1', type=str, help='index of gpu to use')
+args = parser.parse_args()
+
+os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
+
+n = 1000
+
+x = torch.zeros(4, n, n).cuda()
+rest_time = 0.0000000000001
+while True:
+ y = x * x
+ time.sleep(rest_time)
+ y1 = x * x
diff --git a/models/STAR/tools/split_wflw.py b/models/STAR/tools/split_wflw.py
new file mode 100644
index 0000000000000000000000000000000000000000..0337f4236e43c48dd8ccd0f3041f274448d712f1
--- /dev/null
+++ b/models/STAR/tools/split_wflw.py
@@ -0,0 +1,38 @@
+import csv
+import os.path as osp
+import numpy as np
+import pandas as pd
+from tqdm import tqdm
+
+tsv_file = '/apdcephfs/share_1134483/charlinzhou/datas/ADNet/WFLW/test.tsv'
+save_folder = '/apdcephfs/share_1134483/charlinzhou/datas/ADNet/_WFLW/'
+
+save_tags = ['largepose', 'expression', 'illumination', 'makeup', 'occlusion', 'blur']
+save_tags = ['test_{}_metadata.tsv'.format(t) for t in save_tags]
+save_files = [osp.join(save_folder, t) for t in save_tags]
+save_files = [open(f, 'w', newline='') for f in save_files]
+
+landmark_num = 98
+items = pd.read_csv(tsv_file, sep="\t")
+
+items_num = len(items)
+for index in tqdm(range(items_num)):
+ image_path = items.iloc[index, 0]
+ landmarks_5pts = items.iloc[index, 1]
+ # landmarks_5pts = np.array(list(map(float, landmarks_5pts.split(","))), dtype=np.float32).reshape(5, 2)
+ landmarks_target = items.iloc[index, 2]
+ # landmarks_target = np.array(list(map(float, landmarks_target.split(","))), dtype=np.float32).reshape(landmark_num, 2)
+ scale = items.iloc[index, 3]
+ center_w, center_h = items.iloc[index, 4], items.iloc[index, 5]
+ if len(items.iloc[index]) > 6:
+ tags = np.array(list(map(lambda x: int(float(x)), items.iloc[index, 6].split(","))))
+ else:
+ tags = np.array([])
+ assert len(tags) == 6, '{} v.s. 6'.format(len(tags))
+ for k, tag in enumerate(tags):
+ if tag == 1:
+ save_file = save_files[k]
+ tsv_w = csv.writer(save_file, delimiter='\t')
+ tsv_w.writerow([image_path, landmarks_5pts, landmarks_target, scale, center_w, center_h])
+
+print('Done!')
diff --git a/models/STAR/tools/testtime_pca.py b/models/STAR/tools/testtime_pca.py
new file mode 100644
index 0000000000000000000000000000000000000000..c231a96719b986354b9e60d783eacc0467a413f2
--- /dev/null
+++ b/models/STAR/tools/testtime_pca.py
@@ -0,0 +1,107 @@
+import torch
+import torch.nn as nn
+from torch.autograd import Variable
+
+
+def get_channel_sum(input):
+ temp = torch.sum(input, dim=3)
+ output = torch.sum(temp, dim=2)
+ return output
+
+
+def expand_two_dimensions_at_end(input, dim1, dim2):
+ input = input.unsqueeze(-1).unsqueeze(-1)
+ input = input.expand(-1, -1, dim1, dim2)
+ return input
+
+
+class TestTimePCA(nn.Module):
+ def __init__(self):
+ super(TestTimePCA, self).__init__()
+
+ def _make_grid(self, h, w):
+ yy, xx = torch.meshgrid(
+ torch.arange(h).float() / (h - 1) * 2 - 1,
+ torch.arange(w).float() / (w - 1) * 2 - 1)
+ return yy, xx
+
+ def weighted_mean(self, heatmap):
+ batch, npoints, h, w = heatmap.shape
+
+ yy, xx = self._make_grid(h, w)
+ yy = yy.view(1, 1, h, w).to(heatmap)
+ xx = xx.view(1, 1, h, w).to(heatmap)
+
+ yy_coord = (yy * heatmap).sum([2, 3]) # batch x npoints
+ xx_coord = (xx * heatmap).sum([2, 3]) # batch x npoints
+ coords = torch.stack([xx_coord, yy_coord], dim=-1)
+ return coords
+
+ def unbiased_weighted_covariance(self, htp, means, num_dim_image=2, EPSILON=1e-5):
+ batch_size, num_points, height, width = htp.shape
+
+ yv, xv = self._make_grid(height, width)
+ xv = Variable(xv)
+ yv = Variable(yv)
+
+ if htp.is_cuda:
+ xv = xv.cuda()
+ yv = yv.cuda()
+
+ xmean = means[:, :, 0]
+ xv_minus_mean = xv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(xmean, height,
+ width) # [batch_size, 68, 64, 64]
+ ymean = means[:, :, 1]
+ yv_minus_mean = yv.expand(batch_size, num_points, -1, -1) - expand_two_dimensions_at_end(ymean, height,
+ width) # [batch_size, 68, 64, 64]
+ wt_xv_minus_mean = xv_minus_mean
+ wt_yv_minus_mean = yv_minus_mean
+
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_xv_minus_mean = wt_xv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, height * width) # [batch_size*68, 4096]
+ wt_yv_minus_mean = wt_yv_minus_mean.view(batch_size * num_points, 1, height * width) # [batch_size*68, 1, 4096]
+ vec_concat = torch.cat((wt_xv_minus_mean, wt_yv_minus_mean), 1) # [batch_size*68, 2, 4096]
+
+ htp_vec = htp.view(batch_size * num_points, 1, height * width)
+ htp_vec = htp_vec.expand(-1, 2, -1)
+
+ covariance = torch.bmm(htp_vec * vec_concat, vec_concat.transpose(1, 2)) # [batch_size*68, 2, 2]
+ covariance = covariance.view(batch_size, num_points, num_dim_image, num_dim_image) # [batch_size, 68, 2, 2]
+
+ V_1 = htp.sum([2, 3]) + EPSILON # [batch_size, 68]
+ V_2 = torch.pow(htp, 2).sum([2, 3]) + EPSILON # [batch_size, 68]
+
+ denominator = V_1 - (V_2 / V_1)
+ covariance = covariance / expand_two_dimensions_at_end(denominator, num_dim_image, num_dim_image)
+
+ return covariance
+
+ def forward(self, heatmap, groudtruth):
+
+ batch, npoints, h, w = heatmap.shape
+
+ heatmap_sum = torch.clamp(heatmap.sum([2, 3]), min=1e-6)
+ heatmap = heatmap / heatmap_sum.view(batch, npoints, 1, 1)
+
+ # means [batch_size, 68, 2]
+ means = self.weighted_mean(heatmap)
+
+ # covars [batch_size, 68, 2, 2]
+ covars = self.unbiased_weighted_covariance(heatmap, means)
+
+ # eigenvalues [batch_size * 68, 2] , eigenvectors [batch_size * 68, 2, 2]
+ covars = covars.view(batch * npoints, 2, 2).cpu()
+ evalues, evectors = covars.symeig(eigenvectors=True)
+ evalues = evalues.view(batch, npoints, 2)
+ evectors = evectors.view(batch, npoints, 2, 2)
+ means = means.cpu()
+
+ results = [dict() for _ in range(batch)]
+ for i in range(batch):
+ results[i]['pred'] = means[i].numpy().tolist()
+ results[i]['gt'] = groudtruth[i].cpu().numpy().tolist()
+ results[i]['evalues'] = evalues[i].numpy().tolist()
+ results[i]['evectors'] = evectors[i].numpy().tolist()
+
+ return results
diff --git a/models/STAR/trainer.py b/models/STAR/trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff7bce92c866521643715ca22236d0b94b5f860e
--- /dev/null
+++ b/models/STAR/trainer.py
@@ -0,0 +1,209 @@
+import os
+import sys
+import time
+import argparse
+import traceback
+import torch
+import torch.nn as nn
+from lib import utility
+from lib.utils import AverageMeter, convert_secs2time
+
+os.environ["MKL_THREADING_LAYER"] = "GNU"
+
+
+# os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3"
+
+def train(args):
+ device_ids = args.device_ids
+ nprocs = len(device_ids)
+ if nprocs > 1:
+ torch.multiprocessing.spawn(
+ train_worker, args=(nprocs, 1, args), nprocs=nprocs,
+ join=True)
+ elif nprocs == 1:
+ train_worker(device_ids[0], nprocs, 1, args)
+ else:
+ assert False
+
+
+def train_worker(world_rank, world_size, nodes_size, args):
+ # initialize config.
+ config = utility.get_config(args)
+ config.device_id = world_rank if nodes_size == 1 else world_rank % torch.cuda.device_count()
+ # set environment
+ utility.set_environment(config)
+ # initialize instances, such as writer, logger and wandb.
+ if world_rank == 0:
+ config.init_instance()
+
+ if config.logger is not None:
+ config.logger.info("\n" + "\n".join(["%s: %s" % item for item in config.__dict__.items()]))
+ config.logger.info("Loaded configure file %s: %s" % (config.type, config.id))
+
+ # worker communication
+ if world_size > 1:
+ torch.distributed.init_process_group(
+ backend="nccl", init_method="tcp://localhost:23456" if nodes_size == 1 else "env://",
+ rank=world_rank, world_size=world_size)
+ torch.cuda.set_device(config.device)
+
+ # model
+ net = utility.get_net(config)
+ if world_size > 1:
+ net = torch.nn.SyncBatchNorm.convert_sync_batchnorm(net)
+ net = net.float().to(config.device)
+ net.train(True)
+ if config.ema and world_rank == 0:
+ net_ema = utility.get_net(config)
+ if world_size > 1:
+ net_ema = torch.nn.SyncBatchNorm.convert_sync_batchnorm(net_ema)
+ net_ema = net_ema.float().to(config.device)
+ net_ema.eval()
+ utility.accumulate_net(net_ema, net, 0)
+ else:
+ net_ema = None
+
+ # multi-GPU training
+ if world_size > 1:
+ net_module = nn.parallel.DistributedDataParallel(net, device_ids=[config.device_id],
+ output_device=config.device_id, find_unused_parameters=True)
+ else:
+ net_module = net
+
+ criterions = utility.get_criterions(config)
+ optimizer = utility.get_optimizer(config, net_module)
+ scheduler = utility.get_scheduler(config, optimizer)
+
+ # load pretrain model
+ if args.pretrained_weight is not None:
+ if not os.path.exists(args.pretrained_weight):
+ pretrained_weight = os.path.join(config.work_dir, args.pretrained_weight)
+ else:
+ pretrained_weight = args.pretrained_weight
+
+ try:
+ checkpoint = torch.load(pretrained_weight)
+ net.load_state_dict(checkpoint["net"], strict=False)
+ if net_ema is not None:
+ net_ema.load_state_dict(checkpoint["net_ema"], strict=False)
+ if config.logger is not None:
+ config.logger.warn("Successed to load pretrain model %s." % pretrained_weight)
+ start_epoch = checkpoint["epoch"]
+ optimizer.load_state_dict(checkpoint["optimizer"])
+ scheduler.load_state_dict(checkpoint["scheduler"])
+ except:
+ start_epoch = 0
+ if config.logger is not None:
+ config.logger.warn("Failed to load pretrain model %s." % pretrained_weight)
+ else:
+ start_epoch = 0
+
+ if config.logger is not None:
+ config.logger.info("Loaded network")
+
+ # data - train, val
+ train_loader = utility.get_dataloader(config, "train", world_rank, world_size)
+ if world_rank == 0:
+ val_loader = utility.get_dataloader(config, "val")
+ if config.logger is not None:
+ config.logger.info("Loaded data")
+
+ # forward & backward
+ if config.logger is not None:
+ config.logger.info("Optimizer type %s. Start training..." % (config.optimizer))
+ if not os.path.exists(config.model_dir) and world_rank == 0:
+ os.makedirs(config.model_dir)
+
+ # training
+ best_metric, best_net = None, None
+ epoch_time, eval_time = AverageMeter(), AverageMeter()
+ for i_epoch, epoch in enumerate(range(config.max_epoch + 1)):
+ try:
+ epoch_start_time = time.time()
+ if epoch >= start_epoch:
+ # forward and backward
+ if epoch != start_epoch:
+ utility.forward_backward(config, train_loader, net_module, net, net_ema, criterions, optimizer,
+ epoch)
+
+ if world_size > 1:
+ torch.distributed.barrier()
+
+ # validating
+ if epoch % config.val_epoch == 0 and epoch != 0 and world_rank == 0:
+ eval_start_time = time.time()
+ epoch_nets = {"net": net, "net_ema": net_ema}
+ for net_name, epoch_net in epoch_nets.items():
+ if epoch_net is None:
+ continue
+ result, metrics = utility.forward(config, val_loader, epoch_net)
+ for k, metric in enumerate(metrics):
+ if config.logger is not None and len(metric) != 0:
+ config.logger.info(
+ "Val_{}/Metric{:3d} in this epoch: [NME {:.6f}, FR {:.6f}, AUC {:.6f}]".format(
+ net_name, k, metric[0], metric[1], metric[2]))
+
+ # update best model.
+ cur_metric = metrics[config.key_metric_index][0]
+ if best_metric is None or best_metric > cur_metric:
+ best_metric = cur_metric
+ best_net = epoch_net
+ current_pytorch_model_path = os.path.join(config.model_dir, "best_model.pkl")
+ # current_onnx_model_path = os.path.join(config.model_dir, "train.onnx")
+ utility.save_model(
+ config,
+ epoch,
+ best_net,
+ net_ema,
+ optimizer,
+ scheduler,
+ current_pytorch_model_path)
+ if best_metric is not None:
+ config.logger.info(
+ "Val/Best_Metric%03d in this epoch: %.6f" % (config.key_metric_index, best_metric))
+ eval_time.update(time.time() - eval_start_time)
+
+ # saving model
+ if epoch == config.max_epoch and world_rank == 0:
+ current_pytorch_model_path = os.path.join(config.model_dir, "last_model.pkl")
+ # current_onnx_model_path = os.path.join(config.model_dir, "model_epoch_%s.onnx" % epoch)
+ utility.save_model(
+ config,
+ epoch,
+ net,
+ net_ema,
+ optimizer,
+ scheduler,
+ current_pytorch_model_path)
+
+ if world_size > 1:
+ torch.distributed.barrier()
+
+ # adjusting learning rate
+ if epoch > 0:
+ scheduler.step()
+ epoch_time.update(time.time() - epoch_start_time)
+ last_time = convert_secs2time(epoch_time.avg * (config.max_epoch - i_epoch), True)
+ if config.logger is not None:
+ config.logger.info(
+ "Train/Epoch: %d/%d, Learning rate decays to %s, " % (
+ epoch, config.max_epoch, str(scheduler.get_last_lr())) \
+ + last_time + 'eval_time: {:4.2f}, '.format(eval_time.avg) + '\n\n')
+
+ except:
+ traceback.print_exc()
+ config.logger.error("Exception happened in training steps")
+
+ if config.logger is not None:
+ config.logger.info("Training finished")
+
+ try:
+ if config.logger is not None and best_metric is not None:
+ new_folder_name = config.folder + '-fin-{:.4f}'.format(best_metric)
+ new_work_dir = os.path.join(config.ckpt_dir, config.data_definition, new_folder_name)
+ os.system('mv {} {}'.format(config.work_dir, new_work_dir))
+ except:
+ traceback.print_exc()
+
+ if world_size > 1:
+ torch.distributed.destroy_process_group()
diff --git a/models/__init__.py b/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/.DS_Store b/models/encoder4editing/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..eaef0e7fe24cc28841e2843076297d8c7fdb582e
Binary files /dev/null and b/models/encoder4editing/.DS_Store differ
diff --git a/models/encoder4editing/LICENSE b/models/encoder4editing/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..88ba9d421ea8acea9b4e3937535e72c282b3d4e6
--- /dev/null
+++ b/models/encoder4editing/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2021 omertov
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/models/encoder4editing/README.md b/models/encoder4editing/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..639e7347a730fea1e1fbf595cbbaa0e03d79ac6b
--- /dev/null
+++ b/models/encoder4editing/README.md
@@ -0,0 +1,143 @@
+# Designing an Encoder for StyleGAN Image Manipulation (SIGGRAPH 2021)
+  +
+  + [](http://colab.research.google.com/github/omertov/encoder4editing/blob/main/notebooks/inference_playground.ipynb)
+
+> Recently, there has been a surge of diverse methods for performing image editing by employing pre-trained unconditional generators. Applying these methods on real images, however, remains a challenge, as it necessarily requires the inversion of the images into their latent space. To successfully invert a real image, one needs to find a latent code that reconstructs the input image accurately, and more importantly, allows for its meaningful manipulation. In this paper, we carefully study the latent space of StyleGAN, the state-of-the-art unconditional generator. We identify and analyze the existence of a distortion-editability tradeoff and a distortion-perception tradeoff within the StyleGAN latent space. We then suggest two principles for designing encoders in a manner that allows one to control the proximity of the inversions to regions that StyleGAN was originally trained on. We present an encoder based on our two principles that is specifically designed for facilitating editing on real images by balancing these tradeoffs. By evaluating its performance qualitatively and quantitatively on numerous challenging domains, including cars and horses, we show that our inversion method, followed by common editing techniques, achieves superior real-image editing quality, with only a small reconstruction accuracy drop.
+
+
+ [](http://colab.research.google.com/github/omertov/encoder4editing/blob/main/notebooks/inference_playground.ipynb)
+
+> Recently, there has been a surge of diverse methods for performing image editing by employing pre-trained unconditional generators. Applying these methods on real images, however, remains a challenge, as it necessarily requires the inversion of the images into their latent space. To successfully invert a real image, one needs to find a latent code that reconstructs the input image accurately, and more importantly, allows for its meaningful manipulation. In this paper, we carefully study the latent space of StyleGAN, the state-of-the-art unconditional generator. We identify and analyze the existence of a distortion-editability tradeoff and a distortion-perception tradeoff within the StyleGAN latent space. We then suggest two principles for designing encoders in a manner that allows one to control the proximity of the inversions to regions that StyleGAN was originally trained on. We present an encoder based on our two principles that is specifically designed for facilitating editing on real images by balancing these tradeoffs. By evaluating its performance qualitatively and quantitatively on numerous challenging domains, including cars and horses, we show that our inversion method, followed by common editing techniques, achieves superior real-image editing quality, with only a small reconstruction accuracy drop.
+
+
+ +
+
+
+## Description
+Official Implementation of "Designing an Encoder for StyleGAN Image Manipulation" paper for both training and evaluation.
+The e4e encoder is specifically designed to complement existing image manipulation techniques performed over StyleGAN's latent space.
+
+## Recent Updates
+`2021.08.17`: Add single style code encoder (use `--encoder_type SingleStyleCodeEncoder`).
+`2021.03.25`: Add pose editing direction.
+
+## Getting Started
+### Prerequisites
+- Linux or macOS
+- NVIDIA GPU + CUDA CuDNN (CPU may be possible with some modifications, but is not inherently supported)
+- Python 3
+
+### Installation
+- Clone the repository:
+```
+git clone https://github.com/omertov/encoder4editing.git
+cd encoder4editing
+```
+- Dependencies:
+We recommend running this repository using [Anaconda](https://docs.anaconda.com/anaconda/install/).
+All dependencies for defining the environment are provided in `environment/e4e_env.yaml`.
+
+### Inference Notebook
+We provide a Jupyter notebook found in `notebooks/inference_playground.ipynb` that allows one to encode and perform several editings on real images using StyleGAN.
+
+### Pretrained Models
+Please download the pre-trained models from the following links. Each e4e model contains the entire pSp framework architecture, including the encoder and decoder weights.
+| Path | Description
+| :--- | :----------
+|[FFHQ Inversion](https://drive.google.com/file/d/1cUv_reLE6k3604or78EranS7XzuVMWeO/view?usp=sharing) | FFHQ e4e encoder.
+|[Cars Inversion](https://drive.google.com/file/d/17faPqBce2m1AQeLCLHUVXaDfxMRU2QcV/view?usp=sharing) | Cars e4e encoder.
+|[Horse Inversion](https://drive.google.com/file/d/1TkLLnuX86B_BMo2ocYD0kX9kWh53rUVX/view?usp=sharing) | Horse e4e encoder.
+|[Church Inversion](https://drive.google.com/file/d/1-L0ZdnQLwtdy6-A_Ccgq5uNJGTqE7qBa/view?usp=sharing) | Church e4e encoder.
+
+If you wish to use one of the pretrained models for training or inference, you may do so using the flag `--checkpoint_path`.
+
+In addition, we provide various auxiliary models needed for training your own e4e model from scratch.
+| Path | Description
+| :--- | :----------
+|[FFHQ StyleGAN](https://drive.google.com/file/d/1EM87UquaoQmk17Q8d5kYIAHqu0dkYqdT/view?usp=sharing) | StyleGAN model pretrained on FFHQ taken from [rosinality](https://github.com/rosinality/stylegan2-pytorch) with 1024x1024 output resolution.
+|[IR-SE50 Model](https://drive.google.com/file/d/1KW7bjndL3QG3sxBbZxreGHigcCCpsDgn/view?usp=sharing) | Pretrained IR-SE50 model taken from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch) for use in our ID loss during training.
+|[MOCOv2 Model](https://drive.google.com/file/d/18rLcNGdteX5LwT7sv_F7HWr12HpVEzVe/view?usp=sharing) | Pretrained ResNet-50 model trained using MOCOv2 for use in our simmilarity loss for domains other then human faces during training.
+
+By default, we assume that all auxiliary models are downloaded and saved to the directory `pretrained_models`. However, you may use your own paths by changing the necessary values in `configs/path_configs.py`.
+
+## Training
+To train the e4e encoder, make sure the paths to the required models, as well as training and testing data is configured in `configs/path_configs.py` and `configs/data_configs.py`.
+#### **Training the e4e Encoder**
+```
+python scripts/train.py \
+--dataset_type cars_encode \
+--exp_dir new/experiment/directory \
+--start_from_latent_avg \
+--use_w_pool \
+--w_discriminator_lambda 0.1 \
+--progressive_start 20000 \
+--id_lambda 0.5 \
+--val_interval 10000 \
+--max_steps 200000 \
+--stylegan_size 512 \
+--stylegan_weights path/to/pretrained/stylegan.pt \
+--workers 8 \
+--batch_size 8 \
+--test_batch_size 4 \
+--test_workers 4
+```
+
+#### Training on your own dataset
+In order to train the e4e encoder on a custom dataset, perform the following adjustments:
+1. Insert the paths to your train and test data into the `dataset_paths` variable defined in `configs/paths_config.py`:
+```
+dataset_paths = {
+ 'my_train_data': '/path/to/train/images/directory',
+ 'my_test_data': '/path/to/test/images/directory'
+}
+```
+2. Configure a new dataset under the DATASETS variable defined in `configs/data_configs.py`:
+```
+DATASETS = {
+ 'my_data_encode': {
+ 'transforms': transforms_config.EncodeTransforms,
+ 'train_source_root': dataset_paths['my_train_data'],
+ 'train_target_root': dataset_paths['my_train_data'],
+ 'test_source_root': dataset_paths['my_test_data'],
+ 'test_target_root': dataset_paths['my_test_data']
+ }
+}
+```
+Refer to `configs/transforms_config.py` for the transformations applied to the train and test images during training.
+
+3. Finally, run a training session with `--dataset_type my_data_encode`.
+
+## Inference
+Having trained your model, you can use `scripts/inference.py` to apply the model on a set of images.
+For example,
+```
+python scripts/inference.py \
+--images_dir=/path/to/images/directory \
+--save_dir=/path/to/saving/directory \
+path/to/checkpoint.pt
+```
+
+## Latent Editing Consistency (LEC)
+As described in the paper, we suggest a new metric, Latent Editing Consistency (LEC), for evaluating the encoder's
+performance.
+We provide an example for calculating the metric over the FFHQ StyleGAN using the aging editing direction in
+`metrics/LEC.py`.
+
+To run the example:
+```
+cd metrics
+python LEC.py \
+--images_dir=/path/to/images/directory \
+path/to/checkpoint.pt
+```
+
+## Acknowledgments
+This code borrows heavily from [pixel2style2pixel](https://github.com/eladrich/pixel2style2pixel)
+
+## Citation
+If you use this code for your research, please cite our paper Designing an Encoder for StyleGAN Image Manipulation:
+
+```
+@article{tov2021designing,
+ title={Designing an Encoder for StyleGAN Image Manipulation},
+ author={Tov, Omer and Alaluf, Yuval and Nitzan, Yotam and Patashnik, Or and Cohen-Or, Daniel},
+ journal={arXiv preprint arXiv:2102.02766},
+ year={2021}
+}
+```
diff --git a/models/encoder4editing/configs/__init__.py b/models/encoder4editing/configs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/configs/data_configs.py b/models/encoder4editing/configs/data_configs.py
new file mode 100644
index 0000000000000000000000000000000000000000..deccb0b1c266ad4b6abaef53d67ec1ed0ddbd462
--- /dev/null
+++ b/models/encoder4editing/configs/data_configs.py
@@ -0,0 +1,41 @@
+from configs import transforms_config
+from configs.paths_config import dataset_paths
+
+
+DATASETS = {
+ 'ffhq_encode': {
+ 'transforms': transforms_config.EncodeTransforms,
+ 'train_source_root': dataset_paths['ffhq'],
+ 'train_target_root': dataset_paths['ffhq'],
+ 'test_source_root': dataset_paths['celeba_test'],
+ 'test_target_root': dataset_paths['celeba_test'],
+ },
+ 'cars_encode': {
+ 'transforms': transforms_config.CarsEncodeTransforms,
+ 'train_source_root': dataset_paths['cars_train'],
+ 'train_target_root': dataset_paths['cars_train'],
+ 'test_source_root': dataset_paths['cars_test'],
+ 'test_target_root': dataset_paths['cars_test'],
+ },
+ 'horse_encode': {
+ 'transforms': transforms_config.EncodeTransforms,
+ 'train_source_root': dataset_paths['horse_train'],
+ 'train_target_root': dataset_paths['horse_train'],
+ 'test_source_root': dataset_paths['horse_test'],
+ 'test_target_root': dataset_paths['horse_test'],
+ },
+ 'church_encode': {
+ 'transforms': transforms_config.EncodeTransforms,
+ 'train_source_root': dataset_paths['church_train'],
+ 'train_target_root': dataset_paths['church_train'],
+ 'test_source_root': dataset_paths['church_test'],
+ 'test_target_root': dataset_paths['church_test'],
+ },
+ 'cats_encode': {
+ 'transforms': transforms_config.EncodeTransforms,
+ 'train_source_root': dataset_paths['cats_train'],
+ 'train_target_root': dataset_paths['cats_train'],
+ 'test_source_root': dataset_paths['cats_test'],
+ 'test_target_root': dataset_paths['cats_test'],
+ }
+}
diff --git a/models/encoder4editing/configs/paths_config.py b/models/encoder4editing/configs/paths_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..8bc45c4a7ca33b1d074bd5582d57dc83caf77027
--- /dev/null
+++ b/models/encoder4editing/configs/paths_config.py
@@ -0,0 +1,28 @@
+dataset_paths = {
+ # Face Datasets (In the paper: FFHQ - scripts, CelebAHQ - test)
+ 'ffhq': '',
+ 'celeba_test': '',
+
+ # Cars Dataset (In the paper: Stanford cars)
+ 'cars_train': '',
+ 'cars_test': '',
+
+ # Horse Dataset (In the paper: LSUN Horse)
+ 'horse_train': '',
+ 'horse_test': '',
+
+ # Church Dataset (In the paper: LSUN Church)
+ 'church_train': '',
+ 'church_test': '',
+
+ # Cats Dataset (In the paper: LSUN Cat)
+ 'cats_train': '',
+ 'cats_test': ''
+}
+
+model_paths = {
+ 'stylegan_ffhq': 'pretrained_models/stylegan2-ffhq-config-f.pt',
+ 'ir_se50': 'pretrained_models/model_ir_se50.pth',
+ 'shape_predictor': 'pretrained_models/shape_predictor_68_face_landmarks.dat',
+ 'moco': 'pretrained_models/moco_v2_800ep_pretrain.pth'
+}
diff --git a/models/encoder4editing/configs/transforms_config.py b/models/encoder4editing/configs/transforms_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..ac12b5d5ba0571f21715e0f6b24b9c1ebe84bf72
--- /dev/null
+++ b/models/encoder4editing/configs/transforms_config.py
@@ -0,0 +1,62 @@
+from abc import abstractmethod
+import torchvision.transforms as transforms
+
+
+class TransformsConfig(object):
+
+ def __init__(self, opts):
+ self.opts = opts
+
+ @abstractmethod
+ def get_transforms(self):
+ pass
+
+
+class EncodeTransforms(TransformsConfig):
+
+ def __init__(self, opts):
+ super(EncodeTransforms, self).__init__(opts)
+
+ def get_transforms(self):
+ transforms_dict = {
+ 'transform_gt_train': transforms.Compose([
+ transforms.Resize((256, 256)),
+ transforms.RandomHorizontalFlip(0.5),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
+ 'transform_source': None,
+ 'transform_test': transforms.Compose([
+ transforms.Resize((256, 256)),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
+ 'transform_inference': transforms.Compose([
+ transforms.Resize((256, 256)),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
+ }
+ return transforms_dict
+
+
+class CarsEncodeTransforms(TransformsConfig):
+
+ def __init__(self, opts):
+ super(CarsEncodeTransforms, self).__init__(opts)
+
+ def get_transforms(self):
+ transforms_dict = {
+ 'transform_gt_train': transforms.Compose([
+ transforms.Resize((192, 256)),
+ transforms.RandomHorizontalFlip(0.5),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
+ 'transform_source': None,
+ 'transform_test': transforms.Compose([
+ transforms.Resize((192, 256)),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
+ 'transform_inference': transforms.Compose([
+ transforms.Resize((192, 256)),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
+ }
+ return transforms_dict
diff --git a/models/encoder4editing/criteria/__init__.py b/models/encoder4editing/criteria/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/criteria/id_loss.py b/models/encoder4editing/criteria/id_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..bab806172eff18c0630536ae96817508c3197b8b
--- /dev/null
+++ b/models/encoder4editing/criteria/id_loss.py
@@ -0,0 +1,47 @@
+import torch
+from torch import nn
+from configs.paths_config import model_paths
+from models.encoders.model_irse import Backbone
+
+
+class IDLoss(nn.Module):
+ def __init__(self):
+ super(IDLoss, self).__init__()
+ print('Loading ResNet ArcFace')
+ self.facenet = Backbone(input_size=112, num_layers=50, drop_ratio=0.6, mode='ir_se')
+ self.facenet.load_state_dict(torch.load(model_paths['ir_se50']))
+ self.face_pool = torch.nn.AdaptiveAvgPool2d((112, 112))
+ self.facenet.eval()
+ for module in [self.facenet, self.face_pool]:
+ for param in module.parameters():
+ param.requires_grad = False
+
+ def extract_feats(self, x):
+ x = x[:, :, 35:223, 32:220] # Crop interesting region
+ x = self.face_pool(x)
+ x_feats = self.facenet(x)
+ return x_feats
+
+ def forward(self, y_hat, y, x):
+ n_samples = x.shape[0]
+ x_feats = self.extract_feats(x)
+ y_feats = self.extract_feats(y) # Otherwise use the feature from there
+ y_hat_feats = self.extract_feats(y_hat)
+ y_feats = y_feats.detach()
+ loss = 0
+ sim_improvement = 0
+ id_logs = []
+ count = 0
+ for i in range(n_samples):
+ diff_target = y_hat_feats[i].dot(y_feats[i])
+ diff_input = y_hat_feats[i].dot(x_feats[i])
+ diff_views = y_feats[i].dot(x_feats[i])
+ id_logs.append({'diff_target': float(diff_target),
+ 'diff_input': float(diff_input),
+ 'diff_views': float(diff_views)})
+ loss += 1 - diff_target
+ id_diff = float(diff_target) - float(diff_views)
+ sim_improvement += id_diff
+ count += 1
+
+ return loss / count, sim_improvement / count, id_logs
diff --git a/models/encoder4editing/criteria/lpips/__init__.py b/models/encoder4editing/criteria/lpips/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/criteria/lpips/lpips.py b/models/encoder4editing/criteria/lpips/lpips.py
new file mode 100644
index 0000000000000000000000000000000000000000..1add6acc84c1c04cfcb536cf31ec5acdf24b716b
--- /dev/null
+++ b/models/encoder4editing/criteria/lpips/lpips.py
@@ -0,0 +1,35 @@
+import torch
+import torch.nn as nn
+
+from criteria.lpips.networks import get_network, LinLayers
+from criteria.lpips.utils import get_state_dict
+
+
+class LPIPS(nn.Module):
+ r"""Creates a criterion that measures
+ Learned Perceptual Image Patch Similarity (LPIPS).
+ Arguments:
+ net_type (str): the network type to compare the features:
+ 'alex' | 'squeeze' | 'vgg'. Default: 'alex'.
+ version (str): the version of LPIPS. Default: 0.1.
+ """
+ def __init__(self, net_type: str = 'alex', version: str = '0.1'):
+
+ assert version in ['0.1'], 'v0.1 is only supported now'
+
+ super(LPIPS, self).__init__()
+
+ # pretrained network
+ self.net = get_network(net_type).to("cuda")
+
+ # linear layers
+ self.lin = LinLayers(self.net.n_channels_list).to("cuda")
+ self.lin.load_state_dict(get_state_dict(net_type, version))
+
+ def forward(self, x: torch.Tensor, y: torch.Tensor):
+ feat_x, feat_y = self.net(x), self.net(y)
+
+ diff = [(fx - fy) ** 2 for fx, fy in zip(feat_x, feat_y)]
+ res = [l(d).mean((2, 3), True) for d, l in zip(diff, self.lin)]
+
+ return torch.sum(torch.cat(res, 0)) / x.shape[0]
diff --git a/models/encoder4editing/criteria/lpips/networks.py b/models/encoder4editing/criteria/lpips/networks.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a0d13ad2d560278f16586da68d3a5eadb26e746
--- /dev/null
+++ b/models/encoder4editing/criteria/lpips/networks.py
@@ -0,0 +1,96 @@
+from typing import Sequence
+
+from itertools import chain
+
+import torch
+import torch.nn as nn
+from torchvision import models
+
+from criteria.lpips.utils import normalize_activation
+
+
+def get_network(net_type: str):
+ if net_type == 'alex':
+ return AlexNet()
+ elif net_type == 'squeeze':
+ return SqueezeNet()
+ elif net_type == 'vgg':
+ return VGG16()
+ else:
+ raise NotImplementedError('choose net_type from [alex, squeeze, vgg].')
+
+
+class LinLayers(nn.ModuleList):
+ def __init__(self, n_channels_list: Sequence[int]):
+ super(LinLayers, self).__init__([
+ nn.Sequential(
+ nn.Identity(),
+ nn.Conv2d(nc, 1, 1, 1, 0, bias=False)
+ ) for nc in n_channels_list
+ ])
+
+ for param in self.parameters():
+ param.requires_grad = False
+
+
+class BaseNet(nn.Module):
+ def __init__(self):
+ super(BaseNet, self).__init__()
+
+ # register buffer
+ self.register_buffer(
+ 'mean', torch.Tensor([-.030, -.088, -.188])[None, :, None, None])
+ self.register_buffer(
+ 'std', torch.Tensor([.458, .448, .450])[None, :, None, None])
+
+ def set_requires_grad(self, state: bool):
+ for param in chain(self.parameters(), self.buffers()):
+ param.requires_grad = state
+
+ def z_score(self, x: torch.Tensor):
+ return (x - self.mean) / self.std
+
+ def forward(self, x: torch.Tensor):
+ x = self.z_score(x)
+
+ output = []
+ for i, (_, layer) in enumerate(self.layers._modules.items(), 1):
+ x = layer(x)
+ if i in self.target_layers:
+ output.append(normalize_activation(x))
+ if len(output) == len(self.target_layers):
+ break
+ return output
+
+
+class SqueezeNet(BaseNet):
+ def __init__(self):
+ super(SqueezeNet, self).__init__()
+
+ self.layers = models.squeezenet1_1(True).features
+ self.target_layers = [2, 5, 8, 10, 11, 12, 13]
+ self.n_channels_list = [64, 128, 256, 384, 384, 512, 512]
+
+ self.set_requires_grad(False)
+
+
+class AlexNet(BaseNet):
+ def __init__(self):
+ super(AlexNet, self).__init__()
+
+ self.layers = models.alexnet(True).features
+ self.target_layers = [2, 5, 8, 10, 12]
+ self.n_channels_list = [64, 192, 384, 256, 256]
+
+ self.set_requires_grad(False)
+
+
+class VGG16(BaseNet):
+ def __init__(self):
+ super(VGG16, self).__init__()
+
+ self.layers = models.vgg16(True).features
+ self.target_layers = [4, 9, 16, 23, 30]
+ self.n_channels_list = [64, 128, 256, 512, 512]
+
+ self.set_requires_grad(False)
\ No newline at end of file
diff --git a/models/encoder4editing/criteria/lpips/utils.py b/models/encoder4editing/criteria/lpips/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d15a0983775810ef6239c561c67939b2b9ee3b5
--- /dev/null
+++ b/models/encoder4editing/criteria/lpips/utils.py
@@ -0,0 +1,30 @@
+from collections import OrderedDict
+
+import torch
+
+
+def normalize_activation(x, eps=1e-10):
+ norm_factor = torch.sqrt(torch.sum(x ** 2, dim=1, keepdim=True))
+ return x / (norm_factor + eps)
+
+
+def get_state_dict(net_type: str = 'alex', version: str = '0.1'):
+ # build url
+ url = 'https://raw.githubusercontent.com/richzhang/PerceptualSimilarity/' \
+ + f'master/lpips/weights/v{version}/{net_type}.pth'
+
+ # download
+ old_state_dict = torch.hub.load_state_dict_from_url(
+ url, progress=True,
+ map_location=None if torch.cuda.is_available() else torch.device('cpu')
+ )
+
+ # rename keys
+ new_state_dict = OrderedDict()
+ for key, val in old_state_dict.items():
+ new_key = key
+ new_key = new_key.replace('lin', '')
+ new_key = new_key.replace('model.', '')
+ new_state_dict[new_key] = val
+
+ return new_state_dict
diff --git a/models/encoder4editing/criteria/moco_loss.py b/models/encoder4editing/criteria/moco_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fb13fbd426202cff9014c876c85b0d5c4ec6a9d
--- /dev/null
+++ b/models/encoder4editing/criteria/moco_loss.py
@@ -0,0 +1,71 @@
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from configs.paths_config import model_paths
+
+
+class MocoLoss(nn.Module):
+
+ def __init__(self, opts):
+ super(MocoLoss, self).__init__()
+ print("Loading MOCO model from path: {}".format(model_paths["moco"]))
+ self.model = self.__load_model()
+ self.model.eval()
+ for param in self.model.parameters():
+ param.requires_grad = False
+
+ @staticmethod
+ def __load_model():
+ import torchvision.models as models
+ model = models.__dict__["resnet50"]()
+ # freeze all layers but the last fc
+ for name, param in model.named_parameters():
+ if name not in ['fc.weight', 'fc.bias']:
+ param.requires_grad = False
+ checkpoint = torch.load(model_paths['moco'], map_location="cpu")
+ state_dict = checkpoint['state_dict']
+ # rename moco pre-trained keys
+ for k in list(state_dict.keys()):
+ # retain only encoder_q up to before the embedding layer
+ if k.startswith('module.encoder_q') and not k.startswith('module.encoder_q.fc'):
+ # remove prefix
+ state_dict[k[len("module.encoder_q."):]] = state_dict[k]
+ # delete renamed or unused k
+ del state_dict[k]
+ msg = model.load_state_dict(state_dict, strict=False)
+ assert set(msg.missing_keys) == {"fc.weight", "fc.bias"}
+ # remove output layer
+ model = nn.Sequential(*list(model.children())[:-1]).cuda()
+ return model
+
+ def extract_feats(self, x):
+ x = F.interpolate(x, size=224)
+ x_feats = self.model(x)
+ x_feats = nn.functional.normalize(x_feats, dim=1)
+ x_feats = x_feats.squeeze()
+ return x_feats
+
+ def forward(self, y_hat, y, x):
+ n_samples = x.shape[0]
+ x_feats = self.extract_feats(x)
+ y_feats = self.extract_feats(y)
+ y_hat_feats = self.extract_feats(y_hat)
+ y_feats = y_feats.detach()
+ loss = 0
+ sim_improvement = 0
+ sim_logs = []
+ count = 0
+ for i in range(n_samples):
+ diff_target = y_hat_feats[i].dot(y_feats[i])
+ diff_input = y_hat_feats[i].dot(x_feats[i])
+ diff_views = y_feats[i].dot(x_feats[i])
+ sim_logs.append({'diff_target': float(diff_target),
+ 'diff_input': float(diff_input),
+ 'diff_views': float(diff_views)})
+ loss += 1 - diff_target
+ sim_diff = float(diff_target) - float(diff_views)
+ sim_improvement += sim_diff
+ count += 1
+
+ return loss / count, sim_improvement / count, sim_logs
diff --git a/models/encoder4editing/criteria/w_norm.py b/models/encoder4editing/criteria/w_norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..a45ab6f67d8a3f7051be4b7236fa2f38446fd2c1
--- /dev/null
+++ b/models/encoder4editing/criteria/w_norm.py
@@ -0,0 +1,14 @@
+import torch
+from torch import nn
+
+
+class WNormLoss(nn.Module):
+
+ def __init__(self, start_from_latent_avg=True):
+ super(WNormLoss, self).__init__()
+ self.start_from_latent_avg = start_from_latent_avg
+
+ def forward(self, latent, latent_avg=None):
+ if self.start_from_latent_avg:
+ latent = latent - latent_avg
+ return torch.sum(latent.norm(2, dim=(1, 2))) / latent.shape[0]
diff --git a/models/encoder4editing/datasets/__init__.py b/models/encoder4editing/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/datasets/gt_res_dataset.py b/models/encoder4editing/datasets/gt_res_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0beacfee5335aa10aa7e8b7cabe206d7f9a56f7
--- /dev/null
+++ b/models/encoder4editing/datasets/gt_res_dataset.py
@@ -0,0 +1,32 @@
+#!/usr/bin/python
+# encoding: utf-8
+import os
+from torch.utils.data import Dataset
+from PIL import Image
+import torch
+
+class GTResDataset(Dataset):
+
+ def __init__(self, root_path, gt_dir=None, transform=None, transform_train=None):
+ self.pairs = []
+ for f in os.listdir(root_path):
+ image_path = os.path.join(root_path, f)
+ gt_path = os.path.join(gt_dir, f)
+ if f.endswith(".jpg") or f.endswith(".png"):
+ self.pairs.append([image_path, gt_path.replace('.png', '.jpg'), None])
+ self.transform = transform
+ self.transform_train = transform_train
+
+ def __len__(self):
+ return len(self.pairs)
+
+ def __getitem__(self, index):
+ from_path, to_path, _ = self.pairs[index]
+ from_im = Image.open(from_path).convert('RGB')
+ to_im = Image.open(to_path).convert('RGB')
+
+ if self.transform:
+ to_im = self.transform(to_im)
+ from_im = self.transform(from_im)
+
+ return from_im, to_im
diff --git a/models/encoder4editing/datasets/images_dataset.py b/models/encoder4editing/datasets/images_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..8387117ece2643b356e7c792c1da8ec6d05fa772
--- /dev/null
+++ b/models/encoder4editing/datasets/images_dataset.py
@@ -0,0 +1,33 @@
+from torch.utils.data import Dataset
+from PIL import Image
+from ..utils import data_utils
+
+
+class ImagesDataset(Dataset):
+
+ def __init__(self, source_root, target_root, opts, target_transform=None, source_transform=None):
+ self.source_paths = sorted(data_utils.make_dataset(source_root))
+ self.target_paths = sorted(data_utils.make_dataset(target_root))
+ self.source_transform = source_transform
+ self.target_transform = target_transform
+ self.opts = opts
+
+ def __len__(self):
+ return len(self.source_paths)
+
+ def __getitem__(self, index):
+ from_path = self.source_paths[index]
+ from_im = Image.open(from_path)
+ from_im = from_im.convert('RGB')
+
+ to_path = self.target_paths[index]
+ to_im = Image.open(to_path).convert('RGB')
+ if self.target_transform:
+ to_im = self.target_transform(to_im)
+
+ if self.source_transform:
+ from_im = self.source_transform(from_im)
+ else:
+ from_im = to_im
+
+ return from_im, to_im
diff --git a/models/encoder4editing/datasets/inference_dataset.py b/models/encoder4editing/datasets/inference_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfccc5adbdf20e5b90739ec4d4772cc5f48c0357
--- /dev/null
+++ b/models/encoder4editing/datasets/inference_dataset.py
@@ -0,0 +1,25 @@
+from torch.utils.data import Dataset
+from PIL import Image
+from ..utils import data_utils
+
+
+class InferenceDataset(Dataset):
+
+ def __init__(self, root, opts, transform=None, preprocess=None):
+ self.paths = sorted(data_utils.make_dataset(root))
+ self.transform = transform
+ self.preprocess = preprocess
+ self.opts = opts
+
+ def __len__(self):
+ return len(self.paths)
+
+ def __getitem__(self, index):
+ from_path = self.paths[index]
+ if self.preprocess is not None:
+ from_im = self.preprocess(from_path)
+ else:
+ from_im = Image.open(from_path).convert('RGB')
+ if self.transform:
+ from_im = self.transform(from_im)
+ return from_im
diff --git a/models/encoder4editing/editings/ganspace.py b/models/encoder4editing/editings/ganspace.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c286a421280c542e9776a75e64bb65409da8fc7
--- /dev/null
+++ b/models/encoder4editing/editings/ganspace.py
@@ -0,0 +1,22 @@
+import torch
+
+
+def edit(latents, pca, edit_directions):
+ edit_latents = []
+ for latent in latents:
+ for pca_idx, start, end, strength in edit_directions:
+ delta = get_delta(pca, latent, pca_idx, strength)
+ delta_padded = torch.zeros(latent.shape).to('cuda')
+ delta_padded[start:end] += delta.repeat(end - start, 1)
+ edit_latents.append(latent + delta_padded)
+ return torch.stack(edit_latents)
+
+
+def get_delta(pca, latent, idx, strength):
+ # pca: ganspace checkpoint. latent: (16, 512) w+
+ w_centered = latent - pca['mean'].to('cuda')
+ lat_comp = pca['comp'].to('cuda')
+ lat_std = pca['std'].to('cuda')
+ w_coord = torch.sum(w_centered[0].reshape(-1)*lat_comp[idx].reshape(-1)) / lat_std[idx]
+ delta = (strength - w_coord)*lat_comp[idx]*lat_std[idx]
+ return delta
diff --git a/models/encoder4editing/editings/latent_editor.py b/models/encoder4editing/editings/latent_editor.py
new file mode 100644
index 0000000000000000000000000000000000000000..4bebca2f5c86f71b58fa1f30d24bfcb0da06d88f
--- /dev/null
+++ b/models/encoder4editing/editings/latent_editor.py
@@ -0,0 +1,45 @@
+import torch
+import sys
+sys.path.append(".")
+sys.path.append("..")
+from editings import ganspace, sefa
+from utils.common import tensor2im
+
+
+class LatentEditor(object):
+ def __init__(self, stylegan_generator, is_cars=False):
+ self.generator = stylegan_generator
+ self.is_cars = is_cars # Since the cars StyleGAN output is 384x512, there is a need to crop the 512x512 output.
+
+ def apply_ganspace(self, latent, ganspace_pca, edit_directions):
+ edit_latents = ganspace.edit(latent, ganspace_pca, edit_directions)
+ return self._latents_to_image(edit_latents)
+
+ def apply_interfacegan(self, latent, direction, factor=1, factor_range=None):
+ edit_latents = []
+ if factor_range is not None: # Apply a range of editing factors. for example, (-5, 5)
+ for f in range(*factor_range):
+ edit_latent = latent + f * direction
+ edit_latents.append(edit_latent)
+ edit_latents = torch.cat(edit_latents)
+ else:
+ edit_latents = latent + factor * direction
+ return self._latents_to_image(edit_latents)
+
+ def apply_sefa(self, latent, indices=[2, 3, 4, 5], **kwargs):
+ edit_latents = sefa.edit(self.generator, latent, indices, **kwargs)
+ return self._latents_to_image(edit_latents)
+
+ # Currently, in order to apply StyleFlow editings, one should run inference,
+ # save the latent codes and load them form the official StyleFlow repository.
+ # def apply_styleflow(self):
+ # pass
+
+ def _latents_to_image(self, latents):
+ with torch.no_grad():
+ images, _ = self.generator([latents], randomize_noise=False, input_is_latent=True)
+ if self.is_cars:
+ images = images[:, :, 64:448, :] # 512x512 -> 384x512
+ horizontal_concat_image = torch.cat(list(images), 2)
+ final_image = tensor2im(horizontal_concat_image)
+ return final_image
diff --git a/models/encoder4editing/editings/sefa.py b/models/encoder4editing/editings/sefa.py
new file mode 100644
index 0000000000000000000000000000000000000000..db7083ce463b765a7cf452807883a3b85fb63fa5
--- /dev/null
+++ b/models/encoder4editing/editings/sefa.py
@@ -0,0 +1,46 @@
+import torch
+import numpy as np
+from tqdm import tqdm
+
+
+def edit(generator, latents, indices, semantics=1, start_distance=-15.0, end_distance=15.0, num_samples=1, step=11):
+
+ layers, boundaries, values = factorize_weight(generator, indices)
+ codes = latents.detach().cpu().numpy() # (1,18,512)
+
+ # Generate visualization pages.
+ distances = np.linspace(start_distance, end_distance, step)
+ num_sam = num_samples
+ num_sem = semantics
+
+ edited_latents = []
+ for sem_id in tqdm(range(num_sem), desc='Semantic ', leave=False):
+ boundary = boundaries[sem_id:sem_id + 1]
+ for sam_id in tqdm(range(num_sam), desc='Sample ', leave=False):
+ code = codes[sam_id:sam_id + 1]
+ for col_id, d in enumerate(distances, start=1):
+ temp_code = code.copy()
+ temp_code[:, layers, :] += boundary * d
+ edited_latents.append(torch.from_numpy(temp_code).float().cuda())
+ return torch.cat(edited_latents)
+
+
+def factorize_weight(g_ema, layers='all'):
+
+ weights = []
+ if layers == 'all' or 0 in layers:
+ weight = g_ema.conv1.conv.modulation.weight.T
+ weights.append(weight.cpu().detach().numpy())
+
+ if layers == 'all':
+ layers = list(range(g_ema.num_layers - 1))
+ else:
+ layers = [l - 1 for l in layers if l != 0]
+
+ for idx in layers:
+ weight = g_ema.convs[idx].conv.modulation.weight.T
+ weights.append(weight.cpu().detach().numpy())
+ weight = np.concatenate(weights, axis=1).astype(np.float32)
+ weight = weight / np.linalg.norm(weight, axis=0, keepdims=True)
+ eigen_values, eigen_vectors = np.linalg.eig(weight.dot(weight.T))
+ return layers, eigen_vectors.T, eigen_values
diff --git a/models/encoder4editing/environment/e4e_env.yaml b/models/encoder4editing/environment/e4e_env.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..4f537615ebb47afd74b5a9856fb9cbea2e0c4bf4
--- /dev/null
+++ b/models/encoder4editing/environment/e4e_env.yaml
@@ -0,0 +1,73 @@
+name: e4e_env
+channels:
+ - conda-forge
+ - defaults
+dependencies:
+ - _libgcc_mutex=0.1=main
+ - ca-certificates=2020.4.5.1=hecc5488_0
+ - certifi=2020.4.5.1=py36h9f0ad1d_0
+ - libedit=3.1.20181209=hc058e9b_0
+ - libffi=3.2.1=hd88cf55_4
+ - libgcc-ng=9.1.0=hdf63c60_0
+ - libstdcxx-ng=9.1.0=hdf63c60_0
+ - ncurses=6.2=he6710b0_1
+ - ninja=1.10.0=hc9558a2_0
+ - openssl=1.1.1g=h516909a_0
+ - pip=20.0.2=py36_3
+ - python=3.6.7=h0371630_0
+ - python_abi=3.6=1_cp36m
+ - readline=7.0=h7b6447c_5
+ - setuptools=46.4.0=py36_0
+ - sqlite=3.31.1=h62c20be_1
+ - tk=8.6.8=hbc83047_0
+ - wheel=0.34.2=py36_0
+ - xz=5.2.5=h7b6447c_0
+ - zlib=1.2.11=h7b6447c_3
+ - pip:
+ - absl-py==0.9.0
+ - cachetools==4.1.0
+ - chardet==3.0.4
+ - cycler==0.10.0
+ - decorator==4.4.2
+ - future==0.18.2
+ - google-auth==1.15.0
+ - google-auth-oauthlib==0.4.1
+ - grpcio==1.29.0
+ - idna==2.9
+ - imageio==2.8.0
+ - importlib-metadata==1.6.0
+ - kiwisolver==1.2.0
+ - markdown==3.2.2
+ - matplotlib==3.2.1
+ - mxnet==1.6.0
+ - networkx==2.4
+ - numpy==1.18.4
+ - oauthlib==3.1.0
+ - opencv-python==4.2.0.34
+ - pillow==7.1.2
+ - protobuf==3.12.1
+ - pyasn1==0.4.8
+ - pyasn1-modules==0.2.8
+ - pyparsing==2.4.7
+ - python-dateutil==2.8.1
+ - pytorch-lightning==0.7.1
+ - pywavelets==1.1.1
+ - requests==2.23.0
+ - requests-oauthlib==1.3.0
+ - rsa==4.0
+ - scikit-image==0.17.2
+ - scipy==1.4.1
+ - six==1.15.0
+ - tensorboard==2.2.1
+ - tensorboard-plugin-wit==1.6.0.post3
+ - tensorboardx==1.9
+ - tifffile==2020.5.25
+ - torch==1.6.0
+ - torchvision==0.7.1
+ - tqdm==4.46.0
+ - urllib3==1.25.9
+ - werkzeug==1.0.1
+ - zipp==3.1.0
+ - pyaml
+prefix: ~/anaconda3/envs/e4e_env
+
diff --git a/models/encoder4editing/metrics/LEC.py b/models/encoder4editing/metrics/LEC.py
new file mode 100644
index 0000000000000000000000000000000000000000..3eef2d2f00a4d757a56b6e845a8fde16aab306ab
--- /dev/null
+++ b/models/encoder4editing/metrics/LEC.py
@@ -0,0 +1,134 @@
+import sys
+import argparse
+import torch
+import numpy as np
+from torch.utils.data import DataLoader
+
+sys.path.append(".")
+sys.path.append("..")
+
+from configs import data_configs
+from datasets.images_dataset import ImagesDataset
+from utils.model_utils import setup_model
+
+
+class LEC:
+ def __init__(self, net, is_cars=False):
+ """
+ Latent Editing Consistency metric as proposed in the main paper.
+ :param net: e4e model loaded over the pSp framework.
+ :param is_cars: An indication as to whether or not to crop the middle of the StyleGAN's output images.
+ """
+ self.net = net
+ self.is_cars = is_cars
+
+ def _encode(self, images):
+ """
+ Encodes the given images into StyleGAN's latent space.
+ :param images: Tensor of shape NxCxHxW representing the images to be encoded.
+ :return: Tensor of shape NxKx512 representing the latent space embeddings of the given image (in W(K, *) space).
+ """
+ codes = self.net.encoder(images)
+ assert codes.ndim == 3, f"Invalid latent codes shape, should be NxKx512 but is {codes.shape}"
+ # normalize with respect to the center of an average face
+ if self.net.opts.start_from_latent_avg:
+ codes = codes + self.net.latent_avg.repeat(codes.shape[0], 1, 1)
+ return codes
+
+ def _generate(self, codes):
+ """
+ Generate the StyleGAN2 images of the given codes
+ :param codes: Tensor of shape NxKx512 representing the StyleGAN's latent codes (in W(K, *) space).
+ :return: Tensor of shape NxCxHxW representing the generated images.
+ """
+ images, _ = self.net.decoder([codes], input_is_latent=True, randomize_noise=False, return_latents=True)
+ images = self.net.face_pool(images)
+ if self.is_cars:
+ images = images[:, :, 32:224, :]
+ return images
+
+ @staticmethod
+ def _filter_outliers(arr):
+ arr = np.array(arr)
+
+ lo = np.percentile(arr, 1, interpolation="lower")
+ hi = np.percentile(arr, 99, interpolation="higher")
+ return np.extract(
+ np.logical_and(lo <= arr, arr <= hi), arr
+ )
+
+ def calculate_metric(self, data_loader, edit_function, inverse_edit_function):
+ """
+ Calculate the LEC metric score.
+ :param data_loader: An iterable that returns a tuple of (images, _), similar to the training data loader.
+ :param edit_function: A function that receives latent codes and performs a semantically meaningful edit in the
+ latent space.
+ :param inverse_edit_function: A function that receives latent codes and performs the inverse edit of the
+ `edit_function` parameter.
+ :return: The LEC metric score.
+ """
+ distances = []
+ with torch.no_grad():
+ for batch in data_loader:
+ x, _ = batch
+ inputs = x.to(device).float()
+
+ codes = self._encode(inputs)
+ edited_codes = edit_function(codes)
+ edited_image = self._generate(edited_codes)
+ edited_image_inversion_codes = self._encode(edited_image)
+ inverse_edit_codes = inverse_edit_function(edited_image_inversion_codes)
+
+ dist = (codes - inverse_edit_codes).norm(2, dim=(1, 2)).mean()
+ distances.append(dist.to("cpu").numpy())
+
+ distances = self._filter_outliers(distances)
+ return distances.mean()
+
+
+if __name__ == "__main__":
+ device = "cuda"
+
+ parser = argparse.ArgumentParser(description="LEC metric calculator")
+
+ parser.add_argument("--batch", type=int, default=8, help="batch size for the models")
+ parser.add_argument("--images_dir", type=str, default=None,
+ help="Path to the images directory on which we calculate the LEC score")
+ parser.add_argument("ckpt", metavar="CHECKPOINT", help="path to the model checkpoints")
+
+ args = parser.parse_args()
+ print(args)
+
+ net, opts = setup_model(args.ckpt, device)
+ dataset_args = data_configs.DATASETS[opts.dataset_type]
+ transforms_dict = dataset_args['transforms'](opts).get_transforms()
+
+ images_directory = dataset_args['test_source_root'] if args.images_dir is None else args.images_dir
+ test_dataset = ImagesDataset(source_root=images_directory,
+ target_root=images_directory,
+ source_transform=transforms_dict['transform_source'],
+ target_transform=transforms_dict['transform_test'],
+ opts=opts)
+
+ data_loader = DataLoader(test_dataset,
+ batch_size=args.batch,
+ shuffle=False,
+ num_workers=2,
+ drop_last=True)
+
+ print(f'dataset length: {len(test_dataset)}')
+
+ # In the following example, we are using an InterfaceGAN based editing to calculate the LEC metric.
+ # Change the provided example according to your domain and needs.
+ direction = torch.load('../editings/interfacegan_directions/age.pt').to(device)
+
+ def edit_func_example(codes):
+ return codes + 3 * direction
+
+
+ def inverse_edit_func_example(codes):
+ return codes - 3 * direction
+
+ lec = LEC(net, is_cars='car' in opts.dataset_type)
+ result = lec.calculate_metric(data_loader, edit_func_example, inverse_edit_func_example)
+ print(f"LEC: {result}")
diff --git a/models/encoder4editing/models/.DS_Store b/models/encoder4editing/models/.DS_Store
new file mode 100644
index 0000000000000000000000000000000000000000..0eb37726d705b0ac8e70751bdbc647781f065da7
Binary files /dev/null and b/models/encoder4editing/models/.DS_Store differ
diff --git a/models/encoder4editing/models/__init__.py b/models/encoder4editing/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/models/discriminator.py b/models/encoder4editing/models/discriminator.py
new file mode 100644
index 0000000000000000000000000000000000000000..16bf3722c7f2e35cdc9bd177a33ed0975e67200d
--- /dev/null
+++ b/models/encoder4editing/models/discriminator.py
@@ -0,0 +1,20 @@
+from torch import nn
+
+
+class LatentCodesDiscriminator(nn.Module):
+ def __init__(self, style_dim, n_mlp):
+ super().__init__()
+
+ self.style_dim = style_dim
+
+ layers = []
+ for i in range(n_mlp-1):
+ layers.append(
+ nn.Linear(style_dim, style_dim)
+ )
+ layers.append(nn.LeakyReLU(0.2))
+ layers.append(nn.Linear(512, 1))
+ self.mlp = nn.Sequential(*layers)
+
+ def forward(self, w):
+ return self.mlp(w)
diff --git a/models/encoder4editing/models/encoders/__init__.py b/models/encoder4editing/models/encoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/models/encoders/helpers.py b/models/encoder4editing/models/encoders/helpers.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4a58b34ea5ca6912fe53c63dede0a8696f5c024
--- /dev/null
+++ b/models/encoder4editing/models/encoders/helpers.py
@@ -0,0 +1,140 @@
+from collections import namedtuple
+import torch
+import torch.nn.functional as F
+from torch.nn import Conv2d, BatchNorm2d, PReLU, ReLU, Sigmoid, MaxPool2d, AdaptiveAvgPool2d, Sequential, Module
+
+"""
+ArcFace implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
+"""
+
+
+class Flatten(Module):
+ def forward(self, input):
+ return input.view(input.size(0), -1)
+
+
+def l2_norm(input, axis=1):
+ norm = torch.norm(input, 2, axis, True)
+ output = torch.div(input, norm)
+ return output
+
+
+class Bottleneck(namedtuple('Block', ['in_channel', 'depth', 'stride'])):
+ """ A named tuple describing a ResNet block. """
+
+
+def get_block(in_channel, depth, num_units, stride=2):
+ return [Bottleneck(in_channel, depth, stride)] + [Bottleneck(depth, depth, 1) for i in range(num_units - 1)]
+
+
+def get_blocks(num_layers):
+ if num_layers == 50:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=4),
+ get_block(in_channel=128, depth=256, num_units=14),
+ get_block(in_channel=256, depth=512, num_units=3)
+ ]
+ elif num_layers == 100:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=13),
+ get_block(in_channel=128, depth=256, num_units=30),
+ get_block(in_channel=256, depth=512, num_units=3)
+ ]
+ elif num_layers == 152:
+ blocks = [
+ get_block(in_channel=64, depth=64, num_units=3),
+ get_block(in_channel=64, depth=128, num_units=8),
+ get_block(in_channel=128, depth=256, num_units=36),
+ get_block(in_channel=256, depth=512, num_units=3)
+ ]
+ else:
+ raise ValueError("Invalid number of layers: {}. Must be one of [50, 100, 152]".format(num_layers))
+ return blocks
+
+
+class SEModule(Module):
+ def __init__(self, channels, reduction):
+ super(SEModule, self).__init__()
+ self.avg_pool = AdaptiveAvgPool2d(1)
+ self.fc1 = Conv2d(channels, channels // reduction, kernel_size=1, padding=0, bias=False)
+ self.relu = ReLU(inplace=True)
+ self.fc2 = Conv2d(channels // reduction, channels, kernel_size=1, padding=0, bias=False)
+ self.sigmoid = Sigmoid()
+
+ def forward(self, x):
+ module_input = x
+ x = self.avg_pool(x)
+ x = self.fc1(x)
+ x = self.relu(x)
+ x = self.fc2(x)
+ x = self.sigmoid(x)
+ return module_input * x
+
+
+class bottleneck_IR(Module):
+ def __init__(self, in_channel, depth, stride):
+ super(bottleneck_IR, self).__init__()
+ if in_channel == depth:
+ self.shortcut_layer = MaxPool2d(1, stride)
+ else:
+ self.shortcut_layer = Sequential(
+ Conv2d(in_channel, depth, (1, 1), stride, bias=False),
+ BatchNorm2d(depth)
+ )
+ self.res_layer = Sequential(
+ BatchNorm2d(in_channel),
+ Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False), PReLU(depth),
+ Conv2d(depth, depth, (3, 3), stride, 1, bias=False), BatchNorm2d(depth)
+ )
+
+ def forward(self, x):
+ shortcut = self.shortcut_layer(x)
+ res = self.res_layer(x)
+ return res + shortcut
+
+
+class bottleneck_IR_SE(Module):
+ def __init__(self, in_channel, depth, stride):
+ super(bottleneck_IR_SE, self).__init__()
+ if in_channel == depth:
+ self.shortcut_layer = MaxPool2d(1, stride)
+ else:
+ self.shortcut_layer = Sequential(
+ Conv2d(in_channel, depth, (1, 1), stride, bias=False),
+ BatchNorm2d(depth)
+ )
+ self.res_layer = Sequential(
+ BatchNorm2d(in_channel),
+ Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
+ PReLU(depth),
+ Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
+ BatchNorm2d(depth),
+ SEModule(depth, 16)
+ )
+
+ def forward(self, x):
+ shortcut = self.shortcut_layer(x)
+ res = self.res_layer(x)
+ return res + shortcut
+
+
+def _upsample_add(x, y):
+ """Upsample and add two feature maps.
+ Args:
+ x: (Variable) top feature map to be upsampled.
+ y: (Variable) lateral feature map.
+ Returns:
+ (Variable) added feature map.
+ Note in PyTorch, when input size is odd, the upsampled feature map
+ with `F.upsample(..., scale_factor=2, mode='nearest')`
+ maybe not equal to the lateral feature map size.
+ e.g.
+ original input size: [N,_,15,15] ->
+ conv2d feature map size: [N,_,8,8] ->
+ upsampled feature map size: [N,_,16,16]
+ So we choose bilinear upsample which supports arbitrary output sizes.
+ """
+ _, _, H, W = y.size()
+ return F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True) + y
diff --git a/models/encoder4editing/models/encoders/model_irse.py b/models/encoder4editing/models/encoders/model_irse.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea6c6091c1e71279ff0bc7e013b0cea287cb01b3
--- /dev/null
+++ b/models/encoder4editing/models/encoders/model_irse.py
@@ -0,0 +1,84 @@
+from torch.nn import Linear, Conv2d, BatchNorm1d, BatchNorm2d, PReLU, Dropout, Sequential, Module
+from models.encoders.helpers import get_blocks, Flatten, bottleneck_IR, bottleneck_IR_SE, l2_norm
+
+"""
+Modified Backbone implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
+"""
+
+
+class Backbone(Module):
+ def __init__(self, input_size, num_layers, mode='ir', drop_ratio=0.4, affine=True):
+ super(Backbone, self).__init__()
+ assert input_size in [112, 224], "input_size should be 112 or 224"
+ assert num_layers in [50, 100, 152], "num_layers should be 50, 100 or 152"
+ assert mode in ['ir', 'ir_se'], "mode should be ir or ir_se"
+ blocks = get_blocks(num_layers)
+ if mode == 'ir':
+ unit_module = bottleneck_IR
+ elif mode == 'ir_se':
+ unit_module = bottleneck_IR_SE
+ self.input_layer = Sequential(Conv2d(3, 64, (3, 3), 1, 1, bias=False),
+ BatchNorm2d(64),
+ PReLU(64))
+ if input_size == 112:
+ self.output_layer = Sequential(BatchNorm2d(512),
+ Dropout(drop_ratio),
+ Flatten(),
+ Linear(512 * 7 * 7, 512),
+ BatchNorm1d(512, affine=affine))
+ else:
+ self.output_layer = Sequential(BatchNorm2d(512),
+ Dropout(drop_ratio),
+ Flatten(),
+ Linear(512 * 14 * 14, 512),
+ BatchNorm1d(512, affine=affine))
+
+ modules = []
+ for block in blocks:
+ for bottleneck in block:
+ modules.append(unit_module(bottleneck.in_channel,
+ bottleneck.depth,
+ bottleneck.stride))
+ self.body = Sequential(*modules)
+
+ def forward(self, x):
+ x = self.input_layer(x)
+ x = self.body(x)
+ x = self.output_layer(x)
+ return l2_norm(x)
+
+
+def IR_50(input_size):
+ """Constructs a ir-50 model."""
+ model = Backbone(input_size, num_layers=50, mode='ir', drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_101(input_size):
+ """Constructs a ir-101 model."""
+ model = Backbone(input_size, num_layers=100, mode='ir', drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_152(input_size):
+ """Constructs a ir-152 model."""
+ model = Backbone(input_size, num_layers=152, mode='ir', drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_SE_50(input_size):
+ """Constructs a ir_se-50 model."""
+ model = Backbone(input_size, num_layers=50, mode='ir_se', drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_SE_101(input_size):
+ """Constructs a ir_se-101 model."""
+ model = Backbone(input_size, num_layers=100, mode='ir_se', drop_ratio=0.4, affine=False)
+ return model
+
+
+def IR_SE_152(input_size):
+ """Constructs a ir_se-152 model."""
+ model = Backbone(input_size, num_layers=152, mode='ir_se', drop_ratio=0.4, affine=False)
+ return model
diff --git a/models/encoder4editing/models/encoders/psp_encoders.py b/models/encoder4editing/models/encoders/psp_encoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..183561be36853c6d35ff0ff338e28b45b0468c09
--- /dev/null
+++ b/models/encoder4editing/models/encoders/psp_encoders.py
@@ -0,0 +1,235 @@
+from enum import Enum
+import math
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import Conv2d, BatchNorm2d, PReLU, Sequential, Module
+
+from models.encoder4editing.models.encoders.helpers import get_blocks, bottleneck_IR, bottleneck_IR_SE, _upsample_add
+from models.encoder4editing.models.stylegan2.model import EqualLinear
+
+
+class ProgressiveStage(Enum):
+ WTraining = 0
+ Delta1Training = 1
+ Delta2Training = 2
+ Delta3Training = 3
+ Delta4Training = 4
+ Delta5Training = 5
+ Delta6Training = 6
+ Delta7Training = 7
+ Delta8Training = 8
+ Delta9Training = 9
+ Delta10Training = 10
+ Delta11Training = 11
+ Delta12Training = 12
+ Delta13Training = 13
+ Delta14Training = 14
+ Delta15Training = 15
+ Delta16Training = 16
+ Delta17Training = 17
+ Inference = 18
+
+
+class GradualStyleBlock(Module):
+ def __init__(self, in_c, out_c, spatial):
+ super(GradualStyleBlock, self).__init__()
+ self.out_c = out_c
+ self.spatial = spatial
+ num_pools = int(np.log2(spatial))
+ modules = []
+ modules += [Conv2d(in_c, out_c, kernel_size=3, stride=2, padding=1),
+ nn.LeakyReLU()]
+ for i in range(num_pools - 1):
+ modules += [
+ Conv2d(out_c, out_c, kernel_size=3, stride=2, padding=1),
+ nn.LeakyReLU()
+ ]
+ self.convs = nn.Sequential(*modules)
+ self.linear = EqualLinear(out_c, out_c, lr_mul=1)
+
+ def forward(self, x):
+ x = self.convs(x)
+ x = x.view(-1, self.out_c)
+ x = self.linear(x)
+ return x
+
+
+class GradualStyleEncoder(Module):
+ def __init__(self, num_layers, mode='ir', opts=None):
+ super(GradualStyleEncoder, self).__init__()
+ assert num_layers in [50, 100, 152], 'num_layers should be 50,100, or 152'
+ assert mode in ['ir', 'ir_se'], 'mode should be ir or ir_se'
+ blocks = get_blocks(num_layers)
+ if mode == 'ir':
+ unit_module = bottleneck_IR
+ elif mode == 'ir_se':
+ unit_module = bottleneck_IR_SE
+ self.input_layer = Sequential(Conv2d(3, 64, (3, 3), 1, 1, bias=False),
+ BatchNorm2d(64),
+ PReLU(64))
+ modules = []
+ for block in blocks:
+ for bottleneck in block:
+ modules.append(unit_module(bottleneck.in_channel,
+ bottleneck.depth,
+ bottleneck.stride))
+ self.body = Sequential(*modules)
+
+ self.styles = nn.ModuleList()
+ log_size = int(math.log(opts.stylegan_size, 2))
+ self.style_count = 2 * log_size - 2
+ self.coarse_ind = 3
+ self.middle_ind = 7
+ for i in range(self.style_count):
+ if i < self.coarse_ind:
+ style = GradualStyleBlock(512, 512, 16)
+ elif i < self.middle_ind:
+ style = GradualStyleBlock(512, 512, 32)
+ else:
+ style = GradualStyleBlock(512, 512, 64)
+ self.styles.append(style)
+ self.latlayer1 = nn.Conv2d(256, 512, kernel_size=1, stride=1, padding=0)
+ self.latlayer2 = nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x):
+ x = self.input_layer(x)
+
+ latents = []
+ modulelist = list(self.body._modules.values())
+ for i, l in enumerate(modulelist):
+ x = l(x)
+ if i == 6:
+ c1 = x
+ elif i == 20:
+ c2 = x
+ elif i == 23:
+ c3 = x
+
+ for j in range(self.coarse_ind):
+ latents.append(self.styles[j](c3))
+
+ p2 = _upsample_add(c3, self.latlayer1(c2))
+ for j in range(self.coarse_ind, self.middle_ind):
+ latents.append(self.styles[j](p2))
+
+ p1 = _upsample_add(p2, self.latlayer2(c1))
+ for j in range(self.middle_ind, self.style_count):
+ latents.append(self.styles[j](p1))
+
+ out = torch.stack(latents, dim=1)
+ return out
+
+
+class Encoder4Editing(Module):
+ def __init__(self, num_layers, mode='ir', opts=None):
+ super(Encoder4Editing, self).__init__()
+ assert num_layers in [50, 100, 152], 'num_layers should be 50,100, or 152'
+ assert mode in ['ir', 'ir_se'], 'mode should be ir or ir_se'
+ blocks = get_blocks(num_layers)
+ if mode == 'ir':
+ unit_module = bottleneck_IR
+ elif mode == 'ir_se':
+ unit_module = bottleneck_IR_SE
+ self.input_layer = Sequential(Conv2d(3, 64, (3, 3), 1, 1, bias=False),
+ BatchNorm2d(64),
+ PReLU(64))
+ modules = []
+ for block in blocks:
+ for bottleneck in block:
+ modules.append(unit_module(bottleneck.in_channel,
+ bottleneck.depth,
+ bottleneck.stride))
+ self.body = Sequential(*modules)
+
+ self.styles = nn.ModuleList()
+ log_size = int(math.log(opts.stylegan_size, 2))
+ self.style_count = 2 * log_size - 2
+ self.coarse_ind = 3
+ self.middle_ind = 7
+
+ for i in range(self.style_count):
+ if i < self.coarse_ind:
+ style = GradualStyleBlock(512, 512, 16)
+ elif i < self.middle_ind:
+ style = GradualStyleBlock(512, 512, 32)
+ else:
+ style = GradualStyleBlock(512, 512, 64)
+ self.styles.append(style)
+
+ self.latlayer1 = nn.Conv2d(256, 512, kernel_size=1, stride=1, padding=0)
+ self.latlayer2 = nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0)
+
+ self.progressive_stage = ProgressiveStage.Inference
+
+ def get_deltas_starting_dimensions(self):
+ ''' Get a list of the initial dimension of every delta from which it is applied '''
+ return list(range(self.style_count)) # Each dimension has a delta applied to it
+
+ def set_progressive_stage(self, new_stage: ProgressiveStage):
+ self.progressive_stage = new_stage
+ print('Changed progressive stage to: ', new_stage)
+
+ def forward(self, x):
+ x = self.input_layer(x)
+
+ modulelist = list(self.body._modules.values())
+ for i, l in enumerate(modulelist):
+ x = l(x)
+ if i == 6:
+ c1 = x
+ elif i == 20:
+ c2 = x
+ elif i == 23:
+ c3 = x
+
+ # Infer main W and duplicate it
+ w0 = self.styles[0](c3)
+ w = w0.repeat(self.style_count, 1, 1).permute(1, 0, 2)
+ stage = self.progressive_stage.value
+ features = c3
+ for i in range(1, min(stage + 1, self.style_count)): # Infer additional deltas
+ if i == self.coarse_ind:
+ p2 = _upsample_add(c3, self.latlayer1(c2)) # FPN's middle features
+ features = p2
+ elif i == self.middle_ind:
+ p1 = _upsample_add(p2, self.latlayer2(c1)) # FPN's fine features
+ features = p1
+ delta_i = self.styles[i](features)
+ w[:, i] += delta_i
+ return w
+
+
+class BackboneEncoderUsingLastLayerIntoW(Module):
+ def __init__(self, num_layers, mode='ir', opts=None):
+ super(BackboneEncoderUsingLastLayerIntoW, self).__init__()
+ print('Using BackboneEncoderUsingLastLayerIntoW')
+ assert num_layers in [50, 100, 152], 'num_layers should be 50,100, or 152'
+ assert mode in ['ir', 'ir_se'], 'mode should be ir or ir_se'
+ blocks = get_blocks(num_layers)
+ if mode == 'ir':
+ unit_module = bottleneck_IR
+ elif mode == 'ir_se':
+ unit_module = bottleneck_IR_SE
+ self.input_layer = Sequential(Conv2d(3, 64, (3, 3), 1, 1, bias=False),
+ BatchNorm2d(64),
+ PReLU(64))
+ self.output_pool = torch.nn.AdaptiveAvgPool2d((1, 1))
+ self.linear = EqualLinear(512, 512, lr_mul=1)
+ modules = []
+ for block in blocks:
+ for bottleneck in block:
+ modules.append(unit_module(bottleneck.in_channel,
+ bottleneck.depth,
+ bottleneck.stride))
+ self.body = Sequential(*modules)
+ log_size = int(math.log(opts.stylegan_size, 2))
+ self.style_count = 2 * log_size - 2
+
+ def forward(self, x):
+ x = self.input_layer(x)
+ x = self.body(x)
+ x = self.output_pool(x)
+ x = x.view(-1, 512)
+ x = self.linear(x)
+ return x.repeat(self.style_count, 1, 1).permute(1, 0, 2)
diff --git a/models/encoder4editing/models/latent_codes_pool.py b/models/encoder4editing/models/latent_codes_pool.py
new file mode 100644
index 0000000000000000000000000000000000000000..0281d4b5e80f8eb26e824fa35b4f908dcb6634e6
--- /dev/null
+++ b/models/encoder4editing/models/latent_codes_pool.py
@@ -0,0 +1,55 @@
+import random
+import torch
+
+
+class LatentCodesPool:
+ """This class implements latent codes buffer that stores previously generated w latent codes.
+ This buffer enables us to update discriminators using a history of generated w's
+ rather than the ones produced by the latest encoder.
+ """
+
+ def __init__(self, pool_size):
+ """Initialize the ImagePool class
+ Parameters:
+ pool_size (int) -- the size of image buffer, if pool_size=0, no buffer will be created
+ """
+ self.pool_size = pool_size
+ if self.pool_size > 0: # create an empty pool
+ self.num_ws = 0
+ self.ws = []
+
+ def query(self, ws):
+ """Return w's from the pool.
+ Parameters:
+ ws: the latest generated w's from the generator
+ Returns w's from the buffer.
+ By 50/100, the buffer will return input w's.
+ By 50/100, the buffer will return w's previously stored in the buffer,
+ and insert the current w's to the buffer.
+ """
+ if self.pool_size == 0: # if the buffer size is 0, do nothing
+ return ws
+ return_ws = []
+ for w in ws: # ws.shape: (batch, 512) or (batch, n_latent, 512)
+ # w = torch.unsqueeze(image.data, 0)
+ if w.ndim == 2:
+ i = random.randint(0, len(w) - 1) # apply a random latent index as a candidate
+ w = w[i]
+ self.handle_w(w, return_ws)
+ return_ws = torch.stack(return_ws, 0) # collect all the images and return
+ return return_ws
+
+ def handle_w(self, w, return_ws):
+ if self.num_ws < self.pool_size: # if the buffer is not full; keep inserting current codes to the buffer
+ self.num_ws = self.num_ws + 1
+ self.ws.append(w)
+ return_ws.append(w)
+ else:
+ p = random.uniform(0, 1)
+ if p > 0.5: # by 50% chance, the buffer will return a previously stored latent code, and insert the current code into the buffer
+ random_id = random.randint(0, self.pool_size - 1) # randint is inclusive
+ tmp = self.ws[random_id].clone()
+ self.ws[random_id] = w
+ return_ws.append(tmp)
+ else: # by another 50% chance, the buffer will return the current image
+ return_ws.append(w)
diff --git a/models/encoder4editing/models/psp.py b/models/encoder4editing/models/psp.py
new file mode 100644
index 0000000000000000000000000000000000000000..40b45c72022312fbf85076c2fb81f1d758729798
--- /dev/null
+++ b/models/encoder4editing/models/psp.py
@@ -0,0 +1,104 @@
+import matplotlib
+
+matplotlib.use('Agg')
+import torch
+from torch import nn
+from models.encoder4editing.models.encoders import psp_encoders
+from models.encoder4editing.models.stylegan2.model import Generator
+from models.encoder4editing.configs.paths_config import model_paths
+
+
+def get_keys(d, name):
+ if 'state_dict' in d:
+ d = d['state_dict']
+ d_filt = {k[len(name) + 1:]: v for k, v in d.items() if k[:len(name)] == name}
+ return d_filt
+
+
+class pSp(nn.Module):
+
+ def __init__(self, opts):
+ super(pSp, self).__init__()
+ self.opts = opts
+ # Define architecture
+ self.encoder = self.set_encoder()
+ self.decoder = Generator(opts.stylegan_size, 512, 8, channel_multiplier=2)
+ self.face_pool = torch.nn.AdaptiveAvgPool2d((256, 256))
+ # Load weights if needed
+ self.load_weights()
+
+ def set_encoder(self):
+ if self.opts.encoder_type == 'GradualStyleEncoder':
+ encoder = psp_encoders.GradualStyleEncoder(50, 'ir_se', self.opts)
+ elif self.opts.encoder_type == 'Encoder4Editing':
+ encoder = psp_encoders.Encoder4Editing(50, 'ir_se', self.opts)
+ elif self.opts.encoder_type == 'SingleStyleCodeEncoder':
+ encoder = psp_encoders.BackboneEncoderUsingLastLayerIntoW(50, 'ir_se', self.opts)
+ else:
+ raise Exception('{} is not a valid encoders'.format(self.opts.encoder_type))
+ return encoder
+
+ def load_weights(self):
+ if self.opts.checkpoint_path is not None:
+ print('Loading e4e over the pSp framework from checkpoint: {}'.format(self.opts.checkpoint_path))
+ ckpt = torch.load(self.opts.checkpoint_path, map_location='cpu')
+ self.encoder.load_state_dict(get_keys(ckpt, 'encoder'), strict=True)
+ self.decoder.load_state_dict(get_keys(ckpt, 'decoder'), strict=True)
+ self.__load_latent_avg(ckpt)
+ else:
+ print('Loading encoders weights from irse50!')
+ encoder_ckpt = torch.load(model_paths['ir_se50'])
+ self.encoder.load_state_dict(encoder_ckpt, strict=False)
+ print('Loading decoder weights from pretrained!')
+ ckpt = torch.load(self.opts.stylegan_weights)
+ self.decoder.load_state_dict(ckpt['g_ema'], strict=False)
+ self.__load_latent_avg(ckpt, repeat=self.encoder.style_count)
+
+ def forward(self, x, resize=True, latent_mask=None, input_code=False, randomize_noise=True,
+ inject_latent=None, return_latents=False, alpha=None):
+ if input_code:
+ codes = x
+ else:
+ codes = self.encoder(x)
+ # normalize with respect to the center of an average face
+ if self.opts.start_from_latent_avg:
+ if codes.ndim == 2:
+ codes = codes + self.latent_avg.repeat(codes.shape[0], 1, 1)[:, 0, :]
+ else:
+ codes = codes + self.latent_avg.repeat(codes.shape[0], 1, 1)
+
+ if latent_mask is not None:
+ for i in latent_mask:
+ if inject_latent is not None:
+ if alpha is not None:
+ codes[:, i] = alpha * inject_latent[:, i] + (1 - alpha) * codes[:, i]
+ else:
+ codes[:, i] = inject_latent[:, i]
+ else:
+ codes[:, i] = 0
+
+ input_is_latent = not input_code
+ images, result_latent = self.decoder([codes],
+ input_is_latent=input_is_latent,
+ randomize_noise=randomize_noise,
+ return_latents=return_latents)
+
+ if resize:
+ images = self.face_pool(images)
+
+ if return_latents:
+ return images, result_latent
+ else:
+ return images
+
+ def __load_latent_avg(self, ckpt, repeat=None):
+ if 'latent_avg' in ckpt:
+ self.latent_avg = ckpt['latent_avg'].to(self.opts.device)
+ elif self.opts.start_from_latent_avg:
+ # Compute mean code based on a large number of latents (10,000 here)
+ with torch.no_grad():
+ self.latent_avg = self.decoder.mean_latent(10000).to(self.opts.device)
+ else:
+ self.latent_avg = None
+ if repeat is not None and self.latent_avg is not None:
+ self.latent_avg = self.latent_avg.repeat(repeat, 1)
diff --git a/models/encoder4editing/models/stylegan2/__init__.py b/models/encoder4editing/models/stylegan2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/models/encoder4editing/models/stylegan2/model.py b/models/encoder4editing/models/stylegan2/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..54870486c6ef5a0d34e8e63b94ba5e3ac6e68944
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/model.py
@@ -0,0 +1,673 @@
+import math
+import random
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from models.stylegan2.op import FusedLeakyReLU, fused_leaky_relu, upfirdn2d
+
+
+class PixelNorm(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, input):
+ return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
+
+
+def make_kernel(k):
+ k = torch.tensor(k, dtype=torch.float32)
+
+ if k.ndim == 1:
+ k = k[None, :] * k[:, None]
+
+ k /= k.sum()
+
+ return k
+
+
+class Upsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel) * (factor ** 2)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
+
+ return out
+
+
+class Downsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
+
+ return out
+
+
+class Blur(nn.Module):
+ def __init__(self, kernel, pad, upsample_factor=1):
+ super().__init__()
+
+ kernel = make_kernel(kernel)
+
+ if upsample_factor > 1:
+ kernel = kernel * (upsample_factor ** 2)
+
+ self.register_buffer('kernel', kernel)
+
+ self.pad = pad
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, pad=self.pad)
+
+ return out
+
+
+class EqualConv2d(nn.Module):
+ def __init__(
+ self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(
+ torch.randn(out_channel, in_channel, kernel_size, kernel_size)
+ )
+ self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
+
+ self.stride = stride
+ self.padding = padding
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channel))
+
+ else:
+ self.bias = None
+
+ def forward(self, input):
+ out = F.conv2d(
+ input,
+ self.weight * self.scale,
+ bias=self.bias,
+ stride=self.stride,
+ padding=self.padding,
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
+ f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
+ )
+
+
+class EqualLinear(nn.Module):
+ def __init__(
+ self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
+
+ else:
+ self.bias = None
+
+ self.activation = activation
+
+ self.scale = (1 / math.sqrt(in_dim)) * lr_mul
+ self.lr_mul = lr_mul
+
+ def forward(self, input):
+ if self.activation:
+ out = F.linear(input, self.weight * self.scale)
+ out = fused_leaky_relu(out, self.bias * self.lr_mul)
+
+ else:
+ out = F.linear(
+ input, self.weight * self.scale, bias=self.bias * self.lr_mul
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
+ )
+
+
+class ScaledLeakyReLU(nn.Module):
+ def __init__(self, negative_slope=0.2):
+ super().__init__()
+
+ self.negative_slope = negative_slope
+
+ def forward(self, input):
+ out = F.leaky_relu(input, negative_slope=self.negative_slope)
+
+ return out * math.sqrt(2)
+
+
+class ModulatedConv2d(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ demodulate=True,
+ upsample=False,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ ):
+ super().__init__()
+
+ self.eps = 1e-8
+ self.kernel_size = kernel_size
+ self.in_channel = in_channel
+ self.out_channel = out_channel
+ self.upsample = upsample
+ self.downsample = downsample
+
+ if upsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) - (kernel_size - 1)
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2 + 1
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1))
+
+ fan_in = in_channel * kernel_size ** 2
+ self.scale = 1 / math.sqrt(fan_in)
+ self.padding = kernel_size // 2
+
+ self.weight = nn.Parameter(
+ torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
+ )
+
+ self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
+
+ self.demodulate = demodulate
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
+ f'upsample={self.upsample}, downsample={self.downsample})'
+ )
+
+ def forward(self, input, style):
+ batch, in_channel, height, width = input.shape
+
+ style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
+ weight = self.scale * self.weight * style
+
+ if self.demodulate:
+ demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
+ weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
+
+ weight = weight.view(
+ batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+
+ if self.upsample:
+ input = input.view(1, batch * in_channel, height, width)
+ weight = weight.view(
+ batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+ weight = weight.transpose(1, 2).reshape(
+ batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
+ )
+ out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+ out = self.blur(out)
+
+ elif self.downsample:
+ input = self.blur(input)
+ _, _, height, width = input.shape
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ else:
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=self.padding, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ return out
+
+
+class NoiseInjection(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.zeros(1))
+
+ def forward(self, image, noise=None):
+ if noise is None:
+ batch, _, height, width = image.shape
+ noise = image.new_empty(batch, 1, height, width).normal_()
+
+ return image + self.weight * noise
+
+
+class ConstantInput(nn.Module):
+ def __init__(self, channel, size=4):
+ super().__init__()
+
+ self.input = nn.Parameter(torch.randn(1, channel, size, size))
+
+ def forward(self, input):
+ batch = input.shape[0]
+ out = self.input.repeat(batch, 1, 1, 1)
+
+ return out
+
+
+class StyledConv(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ demodulate=True,
+ ):
+ super().__init__()
+
+ self.conv = ModulatedConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=upsample,
+ blur_kernel=blur_kernel,
+ demodulate=demodulate,
+ )
+
+ self.noise = NoiseInjection()
+ # self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
+ # self.activate = ScaledLeakyReLU(0.2)
+ self.activate = FusedLeakyReLU(out_channel)
+
+ def forward(self, input, style, noise=None):
+ out = self.conv(input, style)
+ out = self.noise(out, noise=noise)
+ # out = out + self.bias
+ out = self.activate(out)
+
+ return out
+
+
+class ToRGB(nn.Module):
+ def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ if upsample:
+ self.upsample = Upsample(blur_kernel)
+
+ self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
+ self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
+
+ def forward(self, input, style, skip=None):
+ out = self.conv(input, style)
+ out = out + self.bias
+
+ if skip is not None:
+ skip = self.upsample(skip)
+
+ out = out + skip
+
+ return out
+
+
+class Generator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+
+ self.size = size
+
+ self.style_dim = style_dim
+
+ layers = [PixelNorm()]
+
+ for i in range(n_mlp):
+ layers.append(
+ EqualLinear(
+ style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
+ )
+ )
+
+ self.style = nn.Sequential(*layers)
+
+ self.channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.input = ConstantInput(self.channels[4])
+ self.conv1 = StyledConv(
+ self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
+ )
+ self.to_rgb1 = ToRGB(self.channels[4], style_dim, upsample=False)
+
+ self.log_size = int(math.log(size, 2))
+ self.num_layers = (self.log_size - 2) * 2 + 1
+
+ self.convs = nn.ModuleList()
+ self.upsamples = nn.ModuleList()
+ self.to_rgbs = nn.ModuleList()
+ self.noises = nn.Module()
+
+ in_channel = self.channels[4]
+
+ for layer_idx in range(self.num_layers):
+ res = (layer_idx + 5) // 2
+ shape = [1, 1, 2 ** res, 2 ** res]
+ self.noises.register_buffer(f'noise_{layer_idx}', torch.randn(*shape))
+
+ for i in range(3, self.log_size + 1):
+ out_channel = self.channels[2 ** i]
+
+ self.convs.append(
+ StyledConv(
+ in_channel,
+ out_channel,
+ 3,
+ style_dim,
+ upsample=True,
+ blur_kernel=blur_kernel,
+ )
+ )
+
+ self.convs.append(
+ StyledConv(
+ out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel
+ )
+ )
+
+ self.to_rgbs.append(ToRGB(out_channel, style_dim))
+
+ in_channel = out_channel
+
+ self.n_latent = self.log_size * 2 - 2
+
+ def make_noise(self):
+ device = self.input.input.device
+
+ noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
+
+ for i in range(3, self.log_size + 1):
+ for _ in range(2):
+ noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
+
+ return noises
+
+ def mean_latent(self, n_latent):
+ latent_in = torch.randn(
+ n_latent, self.style_dim, device=self.input.input.device
+ )
+ latent = self.style(latent_in).mean(0, keepdim=True)
+
+ return latent
+
+ def get_latent(self, input):
+ return self.style(input)
+
+ def forward(
+ self,
+ styles,
+ return_latents=False,
+ return_features=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ noise=None,
+ randomize_noise=True,
+ ):
+ if not input_is_latent:
+ styles = [self.style(s) for s in styles]
+
+ if noise is None:
+ if randomize_noise:
+ noise = [None] * self.num_layers
+ else:
+ noise = [
+ getattr(self.noises, f'noise_{i}') for i in range(self.num_layers)
+ ]
+
+ if truncation < 1:
+ style_t = []
+
+ for style in styles:
+ style_t.append(
+ truncation_latent + truncation * (style - truncation_latent)
+ )
+
+ styles = style_t
+
+ if len(styles) < 2:
+ inject_index = self.n_latent
+
+ if styles[0].ndim < 3:
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ else:
+ latent = styles[0]
+
+ else:
+ if inject_index is None:
+ inject_index = random.randint(1, self.n_latent - 1)
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
+
+ latent = torch.cat([latent, latent2], 1)
+
+ out = self.input(latent)
+ out = self.conv1(out, latent[:, 0], noise=noise[0])
+
+ skip = self.to_rgb1(out, latent[:, 1])
+
+ i = 1
+ for conv1, conv2, noise1, noise2, to_rgb in zip(
+ self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
+ ):
+ out = conv1(out, latent[:, i], noise=noise1)
+ out = conv2(out, latent[:, i + 1], noise=noise2)
+ skip = to_rgb(out, latent[:, i + 2], skip)
+
+ i += 2
+
+ image = skip
+
+ if return_latents:
+ return image, latent
+ elif return_features:
+ return image, out
+ else:
+ return image, None
+
+
+class ConvLayer(nn.Sequential):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ bias=True,
+ activate=True,
+ ):
+ layers = []
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
+
+ stride = 2
+ self.padding = 0
+
+ else:
+ stride = 1
+ self.padding = kernel_size // 2
+
+ layers.append(
+ EqualConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ padding=self.padding,
+ stride=stride,
+ bias=bias and not activate,
+ )
+ )
+
+ if activate:
+ if bias:
+ layers.append(FusedLeakyReLU(out_channel))
+
+ else:
+ layers.append(ScaledLeakyReLU(0.2))
+
+ super().__init__(*layers)
+
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ self.conv1 = ConvLayer(in_channel, in_channel, 3)
+ self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
+
+ self.skip = ConvLayer(
+ in_channel, out_channel, 1, downsample=True, activate=False, bias=False
+ )
+
+ def forward(self, input):
+ out = self.conv1(input)
+ out = self.conv2(out)
+
+ skip = self.skip(input)
+ out = (out + skip) / math.sqrt(2)
+
+ return out
+
+
+class Discriminator(nn.Module):
+ def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ convs = [ConvLayer(3, channels[size], 1)]
+
+ log_size = int(math.log(size, 2))
+
+ in_channel = channels[size]
+
+ for i in range(log_size, 2, -1):
+ out_channel = channels[2 ** (i - 1)]
+
+ convs.append(ResBlock(in_channel, out_channel, blur_kernel))
+
+ in_channel = out_channel
+
+ self.convs = nn.Sequential(*convs)
+
+ self.stddev_group = 4
+ self.stddev_feat = 1
+
+ self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
+ self.final_linear = nn.Sequential(
+ EqualLinear(channels[4] * 4 * 4, channels[4], activation='fused_lrelu'),
+ EqualLinear(channels[4], 1),
+ )
+
+ def forward(self, input):
+ out = self.convs(input)
+
+ batch, channel, height, width = out.shape
+ group = min(batch, self.stddev_group)
+ stddev = out.view(
+ group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
+ )
+ stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
+ stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
+ stddev = stddev.repeat(group, 1, height, width)
+ out = torch.cat([out, stddev], 1)
+
+ out = self.final_conv(out)
+
+ out = out.view(batch, -1)
+ out = self.final_linear(out)
+
+ return out
diff --git a/models/encoder4editing/models/stylegan2/op/__init__.py b/models/encoder4editing/models/stylegan2/op/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0918d92285955855be89f00096b888ee5597ce3
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/__init__.py
@@ -0,0 +1,2 @@
+from .fused_act import FusedLeakyReLU, fused_leaky_relu
+from .upfirdn2d import upfirdn2d
diff --git a/models/encoder4editing/models/stylegan2/op/fused_act.py b/models/encoder4editing/models/stylegan2/op/fused_act.py
new file mode 100644
index 0000000000000000000000000000000000000000..973a84fffde53668d31397da5fb993bbc95f7be0
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/fused_act.py
@@ -0,0 +1,85 @@
+import os
+
+import torch
+from torch import nn
+from torch.autograd import Function
+from torch.utils.cpp_extension import load
+
+module_path = os.path.dirname(__file__)
+fused = load(
+ 'fused',
+ sources=[
+ os.path.join(module_path, 'fused_bias_act.cpp'),
+ os.path.join(module_path, 'fused_bias_act_kernel.cu'),
+ ],
+)
+
+
+class FusedLeakyReLUFunctionBackward(Function):
+ @staticmethod
+ def forward(ctx, grad_output, out, negative_slope, scale):
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ empty = grad_output.new_empty(0)
+
+ grad_input = fused.fused_bias_act(
+ grad_output, empty, out, 3, 1, negative_slope, scale
+ )
+
+ dim = [0]
+
+ if grad_input.ndim > 2:
+ dim += list(range(2, grad_input.ndim))
+
+ grad_bias = grad_input.sum(dim).detach()
+
+ return grad_input, grad_bias
+
+ @staticmethod
+ def backward(ctx, gradgrad_input, gradgrad_bias):
+ out, = ctx.saved_tensors
+ gradgrad_out = fused.fused_bias_act(
+ gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale
+ )
+
+ return gradgrad_out, None, None, None
+
+
+class FusedLeakyReLUFunction(Function):
+ @staticmethod
+ def forward(ctx, input, bias, negative_slope, scale):
+ empty = input.new_empty(0)
+ out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ out, = ctx.saved_tensors
+
+ grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
+ grad_output, out, ctx.negative_slope, ctx.scale
+ )
+
+ return grad_input, grad_bias, None, None
+
+
+class FusedLeakyReLU(nn.Module):
+ def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5):
+ super().__init__()
+
+ self.bias = nn.Parameter(torch.zeros(channel))
+ self.negative_slope = negative_slope
+ self.scale = scale
+
+ def forward(self, input):
+ return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
+
+
+def fused_leaky_relu(input, bias, negative_slope=0.2, scale=2 ** 0.5):
+ return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
diff --git a/models/encoder4editing/models/stylegan2/op/fused_bias_act.cpp b/models/encoder4editing/models/stylegan2/op/fused_bias_act.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..02be898f970bcc8ea297867fcaa4e71b24b3d949
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/fused_bias_act.cpp
@@ -0,0 +1,21 @@
+#include
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(bias);
+
+ return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
+}
\ No newline at end of file
diff --git a/models/encoder4editing/models/stylegan2/op/fused_bias_act_kernel.cu b/models/encoder4editing/models/stylegan2/op/fused_bias_act_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..c9fa56fea7ede7072dc8925cfb0148f136eb85b8
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/fused_bias_act_kernel.cu
@@ -0,0 +1,99 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+template
+static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
+ int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
+ int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
+
+ scalar_t zero = 0.0;
+
+ for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
+ scalar_t x = p_x[xi];
+
+ if (use_bias) {
+ x += p_b[(xi / step_b) % size_b];
+ }
+
+ scalar_t ref = use_ref ? p_ref[xi] : zero;
+
+ scalar_t y;
+
+ switch (act * 10 + grad) {
+ default:
+ case 10: y = x; break;
+ case 11: y = x; break;
+ case 12: y = 0.0; break;
+
+ case 30: y = (x > 0.0) ? x : x * alpha; break;
+ case 31: y = (ref > 0.0) ? x : x * alpha; break;
+ case 32: y = 0.0; break;
+ }
+
+ out[xi] = y * scale;
+ }
+}
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ auto x = input.contiguous();
+ auto b = bias.contiguous();
+ auto ref = refer.contiguous();
+
+ int use_bias = b.numel() ? 1 : 0;
+ int use_ref = ref.numel() ? 1 : 0;
+
+ int size_x = x.numel();
+ int size_b = b.numel();
+ int step_b = 1;
+
+ for (int i = 1 + 1; i < x.dim(); i++) {
+ step_b *= x.size(i);
+ }
+
+ int loop_x = 4;
+ int block_size = 4 * 32;
+ int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
+
+ auto y = torch::empty_like(x);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
+ fused_bias_act_kernel<<>>(
+ y.data_ptr(),
+ x.data_ptr(),
+ b.data_ptr(),
+ ref.data_ptr(),
+ act,
+ grad,
+ alpha,
+ scale,
+ loop_x,
+ size_x,
+ step_b,
+ size_b,
+ use_bias,
+ use_ref
+ );
+ });
+
+ return y;
+}
\ No newline at end of file
diff --git a/models/encoder4editing/models/stylegan2/op/upfirdn2d.cpp b/models/encoder4editing/models/stylegan2/op/upfirdn2d.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..d2e633dc896433c205e18bc3e455539192ff968e
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/upfirdn2d.cpp
@@ -0,0 +1,23 @@
+#include
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(kernel);
+
+ return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
+}
\ No newline at end of file
diff --git a/models/encoder4editing/models/stylegan2/op/upfirdn2d.py b/models/encoder4editing/models/stylegan2/op/upfirdn2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bc5a1e331c2bbb1893ac748cfd0f144ff0651b4
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/upfirdn2d.py
@@ -0,0 +1,184 @@
+import os
+
+import torch
+from torch.autograd import Function
+from torch.utils.cpp_extension import load
+
+module_path = os.path.dirname(__file__)
+upfirdn2d_op = load(
+ 'upfirdn2d',
+ sources=[
+ os.path.join(module_path, 'upfirdn2d.cpp'),
+ os.path.join(module_path, 'upfirdn2d_kernel.cu'),
+ ],
+)
+
+
+class UpFirDn2dBackward(Function):
+ @staticmethod
+ def forward(
+ ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
+ ):
+ up_x, up_y = up
+ down_x, down_y = down
+ g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
+
+ grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
+
+ grad_input = upfirdn2d_op.upfirdn2d(
+ grad_output,
+ grad_kernel,
+ down_x,
+ down_y,
+ up_x,
+ up_y,
+ g_pad_x0,
+ g_pad_x1,
+ g_pad_y0,
+ g_pad_y1,
+ )
+ grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
+
+ ctx.save_for_backward(kernel)
+
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ ctx.up_x = up_x
+ ctx.up_y = up_y
+ ctx.down_x = down_x
+ ctx.down_y = down_y
+ ctx.pad_x0 = pad_x0
+ ctx.pad_x1 = pad_x1
+ ctx.pad_y0 = pad_y0
+ ctx.pad_y1 = pad_y1
+ ctx.in_size = in_size
+ ctx.out_size = out_size
+
+ return grad_input
+
+ @staticmethod
+ def backward(ctx, gradgrad_input):
+ kernel, = ctx.saved_tensors
+
+ gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
+
+ gradgrad_out = upfirdn2d_op.upfirdn2d(
+ gradgrad_input,
+ kernel,
+ ctx.up_x,
+ ctx.up_y,
+ ctx.down_x,
+ ctx.down_y,
+ ctx.pad_x0,
+ ctx.pad_x1,
+ ctx.pad_y0,
+ ctx.pad_y1,
+ )
+ # gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
+ gradgrad_out = gradgrad_out.view(
+ ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
+ )
+
+ return gradgrad_out, None, None, None, None, None, None, None, None
+
+
+class UpFirDn2d(Function):
+ @staticmethod
+ def forward(ctx, input, kernel, up, down, pad):
+ up_x, up_y = up
+ down_x, down_y = down
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ kernel_h, kernel_w = kernel.shape
+ batch, channel, in_h, in_w = input.shape
+ ctx.in_size = input.shape
+
+ input = input.reshape(-1, in_h, in_w, 1)
+
+ ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+ ctx.out_size = (out_h, out_w)
+
+ ctx.up = (up_x, up_y)
+ ctx.down = (down_x, down_y)
+ ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
+
+ g_pad_x0 = kernel_w - pad_x0 - 1
+ g_pad_y0 = kernel_h - pad_y0 - 1
+ g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
+ g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
+
+ ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
+
+ out = upfirdn2d_op.upfirdn2d(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+ )
+ # out = out.view(major, out_h, out_w, minor)
+ out = out.view(-1, channel, out_h, out_w)
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ kernel, grad_kernel = ctx.saved_tensors
+
+ grad_input = UpFirDn2dBackward.apply(
+ grad_output,
+ kernel,
+ grad_kernel,
+ ctx.up,
+ ctx.down,
+ ctx.pad,
+ ctx.g_pad,
+ ctx.in_size,
+ ctx.out_size,
+ )
+
+ return grad_input, None, None, None, None
+
+
+def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
+ out = UpFirDn2d.apply(
+ input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
+ )
+
+ return out
+
+
+def upfirdn2d_native(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+):
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.view(-1, in_h, 1, in_w, 1, minor)
+ out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.view(-1, in_h * up_y, in_w * up_x, minor)
+
+ out = F.pad(
+ out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
+ )
+ out = out[
+ :,
+ max(-pad_y0, 0): out.shape[1] - max(-pad_y1, 0),
+ max(-pad_x0, 0): out.shape[2] - max(-pad_x1, 0),
+ :,
+ ]
+
+ out = out.permute(0, 3, 1, 2)
+ out = out.reshape(
+ [-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
+ )
+ w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ -1,
+ minor,
+ in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
+ in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
+ )
+ out = out.permute(0, 2, 3, 1)
+
+ return out[:, ::down_y, ::down_x, :]
diff --git a/models/encoder4editing/models/stylegan2/op/upfirdn2d_kernel.cu b/models/encoder4editing/models/stylegan2/op/upfirdn2d_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..2a710aa6adc3d43ac93136a1814e3c39970e1c7e
--- /dev/null
+++ b/models/encoder4editing/models/stylegan2/op/upfirdn2d_kernel.cu
@@ -0,0 +1,272 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
+ int c = a / b;
+
+ if (c * b > a) {
+ c--;
+ }
+
+ return c;
+}
+
+
+struct UpFirDn2DKernelParams {
+ int up_x;
+ int up_y;
+ int down_x;
+ int down_y;
+ int pad_x0;
+ int pad_x1;
+ int pad_y0;
+ int pad_y1;
+
+ int major_dim;
+ int in_h;
+ int in_w;
+ int minor_dim;
+ int kernel_h;
+ int kernel_w;
+ int out_h;
+ int out_w;
+ int loop_major;
+ int loop_x;
+};
+
+
+template
+__global__ void upfirdn2d_kernel(scalar_t* out, const scalar_t* input, const scalar_t* kernel, const UpFirDn2DKernelParams p) {
+ const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
+ const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
+
+ __shared__ volatile float sk[kernel_h][kernel_w];
+ __shared__ volatile float sx[tile_in_h][tile_in_w];
+
+ int minor_idx = blockIdx.x;
+ int tile_out_y = minor_idx / p.minor_dim;
+ minor_idx -= tile_out_y * p.minor_dim;
+ tile_out_y *= tile_out_h;
+ int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
+ int major_idx_base = blockIdx.z * p.loop_major;
+
+ if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h | major_idx_base >= p.major_dim) {
+ return;
+ }
+
+ for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w; tap_idx += blockDim.x) {
+ int ky = tap_idx / kernel_w;
+ int kx = tap_idx - ky * kernel_w;
+ scalar_t v = 0.0;
+
+ if (kx < p.kernel_w & ky < p.kernel_h) {
+ v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
+ }
+
+ sk[ky][kx] = v;
+ }
+
+ for (int loop_major = 0, major_idx = major_idx_base; loop_major < p.loop_major & major_idx < p.major_dim; loop_major++, major_idx++) {
+ for (int loop_x = 0, tile_out_x = tile_out_x_base; loop_x < p.loop_x & tile_out_x < p.out_w; loop_x++, tile_out_x += tile_out_w) {
+ int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
+ int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
+ int tile_in_x = floor_div(tile_mid_x, up_x);
+ int tile_in_y = floor_div(tile_mid_y, up_y);
+
+ __syncthreads();
+
+ for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w; in_idx += blockDim.x) {
+ int rel_in_y = in_idx / tile_in_w;
+ int rel_in_x = in_idx - rel_in_y * tile_in_w;
+ int in_x = rel_in_x + tile_in_x;
+ int in_y = rel_in_y + tile_in_y;
+
+ scalar_t v = 0.0;
+
+ if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
+ v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim + minor_idx];
+ }
+
+ sx[rel_in_y][rel_in_x] = v;
+ }
+
+ __syncthreads();
+ for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w; out_idx += blockDim.x) {
+ int rel_out_y = out_idx / tile_out_w;
+ int rel_out_x = out_idx - rel_out_y * tile_out_w;
+ int out_x = rel_out_x + tile_out_x;
+ int out_y = rel_out_y + tile_out_y;
+
+ int mid_x = tile_mid_x + rel_out_x * down_x;
+ int mid_y = tile_mid_y + rel_out_y * down_y;
+ int in_x = floor_div(mid_x, up_x);
+ int in_y = floor_div(mid_y, up_y);
+ int rel_in_x = in_x - tile_in_x;
+ int rel_in_y = in_y - tile_in_y;
+ int kernel_x = (in_x + 1) * up_x - mid_x - 1;
+ int kernel_y = (in_y + 1) * up_y - mid_y - 1;
+
+ scalar_t v = 0.0;
+
+ #pragma unroll
+ for (int y = 0; y < kernel_h / up_y; y++)
+ #pragma unroll
+ for (int x = 0; x < kernel_w / up_x; x++)
+ v += sx[rel_in_y + y][rel_in_x + x] * sk[kernel_y + y * up_y][kernel_x + x * up_x];
+
+ if (out_x < p.out_w & out_y < p.out_h) {
+ out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim + minor_idx] = v;
+ }
+ }
+ }
+ }
+}
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ UpFirDn2DKernelParams p;
+
+ auto x = input.contiguous();
+ auto k = kernel.contiguous();
+
+ p.major_dim = x.size(0);
+ p.in_h = x.size(1);
+ p.in_w = x.size(2);
+ p.minor_dim = x.size(3);
+ p.kernel_h = k.size(0);
+ p.kernel_w = k.size(1);
+ p.up_x = up_x;
+ p.up_y = up_y;
+ p.down_x = down_x;
+ p.down_y = down_y;
+ p.pad_x0 = pad_x0;
+ p.pad_x1 = pad_x1;
+ p.pad_y0 = pad_y0;
+ p.pad_y1 = pad_y1;
+
+ p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) / p.down_y;
+ p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) / p.down_x;
+
+ auto out = at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
+
+ int mode = -1;
+
+ int tile_out_h;
+ int tile_out_w;
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 1;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 3 && p.kernel_w <= 3) {
+ mode = 2;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 3;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 4;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 5;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 6;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ dim3 block_size;
+ dim3 grid_size;
+
+ if (tile_out_h > 0 && tile_out_w) {
+ p.loop_major = (p.major_dim - 1) / 16384 + 1;
+ p.loop_x = 1;
+ block_size = dim3(32 * 8, 1, 1);
+ grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
+ (p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
+ (p.major_dim - 1) / p.loop_major + 1);
+ }
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
+ switch (mode) {
+ case 1:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 2:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 3:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 4:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr