Datasets:

license: apache-2.0
task_categories:
- visual-question-answering
language:
- en
tags:
- spatial-reasoning
- cross-viewpoint localization
pretty_name: ViewSpatial-Bench
size_categories:
- 1K<n<10K
configs:
- config_name: ViewSpatial-Bench
data_files:
- split: test
path: ViewSpatial-Bench.json
ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
Dataset Description
We introduce ViewSpatial-Bench, a comprehensive benchmark with over 5,700 question-answer pairs across 1,000+ 3D scenes from ScanNet and MS-COCO validation sets. This benchmark evaluates VLMs' spatial localization capabilities from multiple perspectives, specifically testing both egocentric (camera) and allocentric (human subject) viewpoints across five distinct task types.
ViewSpatial-Bench addresses a critical gap: while VLMs excel at spatial reasoning from their own perspective, they struggle with perspective-taking—adopting another entity's spatial frame of reference—which is essential for embodied interaction and multi-agent collaboration.The figure below shows the construction pipeline and example demonstrations of our benchmark.
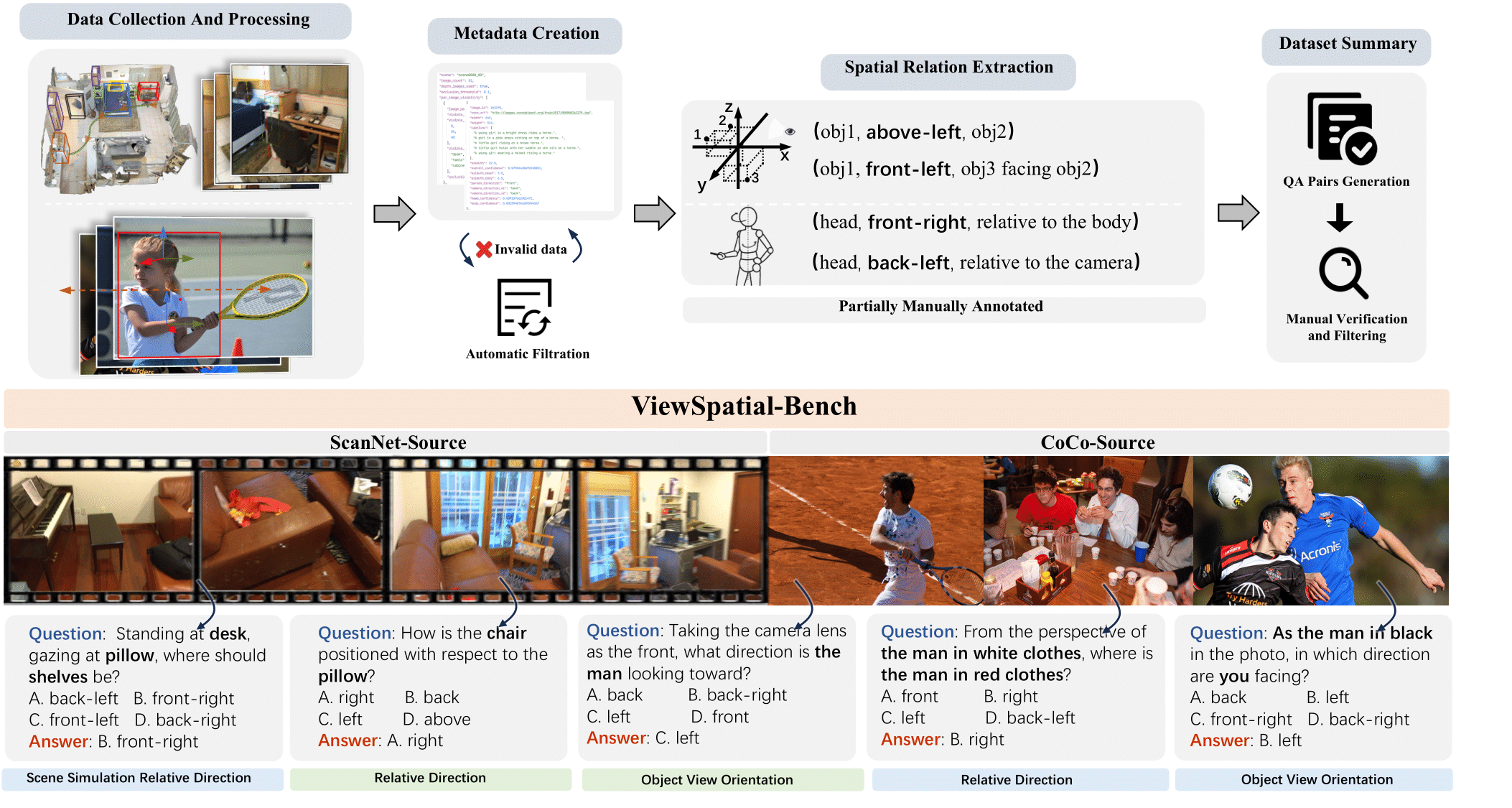
The dataset contains the following fields:
| Field Name | Description |
|---|---|
question_type |
Type of spatial reasoning task, includes 5 distinct categories for evaluating different spatial capabilities |
image_path |
Path to the source image, includes data from two sources: scannetv2_val (ScanNet validation set) and val2017 (MS-COCO validation set) |
question |
The spatial reasoning question posed to the model |
answer |
The correct answer to the question |
choices |
Multiple choice options available for the question |
- Language(s) (NLP): en
- License: apache-2.0
Uses
I. With HuggingFace datasets library.
from datasets import load_dataset
ds = load_dataset("lidingm/ViewSpatial-Bench")
II. Evaluation using Open-Source Code.
Evaluate using our open-source evaluation code available on Github.(Coming Soon)
# Clone the repository
git clone https://github.com/lidingm/ViewSpatial-Bench.git
cd ViewSpatial-Bench
# Install dependencies
pip install -r requirements.txt
# Run evaluation
python evaluate.py --model_path your_model_path
You can configure the appropriate model parameters and evaluation settings according to the framework's requirements to obtain performance evaluation results on the ViewSpatial-Bench dataset.
Benchamrk
We provide benchmark results for various open-source models as well as GPT-4o and Gemini 2.0 Flash on our benchmark. More model evaluations will be added.
| Model | Camera-based Tasks | Person-based Tasks | Overall | |||||
|---|---|---|---|---|---|---|---|---|
| Rel. Dir. | Obj. Ori. | Avg. | Obj. Ori. | Rel. Dir. | Sce. Sim. | Avg. | ||
| InternVL2.5 (2B) | 38.52 | 22.59 | 32.79 | 47.09 | 40.02 | 25.70 | 37.04 | 34.98 |
| Qwen2.5-VL (3B) | 43.43 | 33.33 | 39.80 | 39.16 | 28.62 | 28.51 | 32.14 | 35.85 |
| Qwen2.5-VL (7B) | 46.64 | 29.72 | 40.56 | 37.05 | 35.04 | 28.78 | 33.37 | 36.85 |
| LLaVA-NeXT-Video (7B) | 26.34 | 19.28 | 23.80 | 44.68 | 38.60 | 29.05 | 37.07 | 30.64 |
| LLaVA-OneVision (7B) | 29.84 | 26.10 | 28.49 | 22.39 | 31.00 | 26.88 | 26.54 | 27.49 |
| InternVL2.5 (8B) | 49.41 | 41.27 | 46.48 | 46.79 | 42.04 | 32.85 | 40.20 | 43.24 |
| Llama-3.2-Vision (11B) | 25.27 | 20.98 | 23.73 | 51.20 | 32.19 | 18.82 | 33.61 | 28.82 |
| InternVL3 (14B) | 54.65 | 33.63 | 47.09 | 33.43 | 37.05 | 31.86 | 33.88 | 40.28 |
| Kimi-VL-Instruct (16B) | 26.85 | 22.09 | 25.14 | 63.05 | 43.94 | 20.27 | 41.52 | 33.58 |
| GPT-4o | 41.46 | 19.58 | 33.57 | 42.97 | 40.86 | 26.79 | 36.29 | 34.98 |
| Gemini 2.0 Flash | 45.29 | 12.95 | 33.66 | 41.16 | 32.78 | 21.90 | 31.53 | 32.56 |
| Random Baseline | 25.16 | 26.10 | 25.50 | 24.60 | 31.12 | 26.33 | 27.12 | 26.33 |
Citation
@misc{li2025viewspatialbenchevaluatingmultiperspectivespatial,
title={ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models},
author={Dingming Li and Hongxing Li and Zixuan Wang and Yuchen Yan and Hang Zhang and Siqi Chen and Guiyang Hou and Shengpei Jiang and Wenqi Zhang and Yongliang Shen and Weiming Lu and Yueting Zhuang},
year={2025},
eprint={2505.21500},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.21500},
}