
{kind=link}
EMMA-500
Collection
Enhancing massively multilingual adaptation of LLMs on 500+ languages https://mala-lm.github.io
•
9 items
•
Updated
•
4
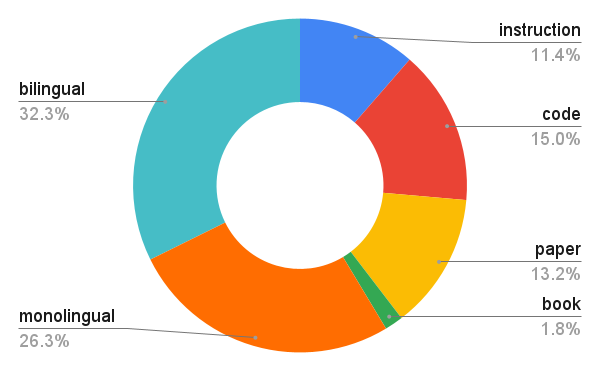
EMMA-500 Llama 3 8B is a state-of-the-art multilingual language model designed to improve language representation, especially in low-resource languages, through continual pre-training on the Llama 3 8B architecture. Leveraging the MaLA Corpus, which spans over 500 languages and is augmented with books, code, instruction data, and papers, EMMA-500 excels in multilingual tasks like commonsense reasoning, machine translation, and text classification.
EMMA-500 series
🤗MaLA Corpus Dataset Collection
You can use EMMA-500 for multilingual text generation. Below is an example to generate text using the model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MaLA-LM/emma-500-llama3-8b-bi"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "Once upon a time"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
If you find this model useful, please cite the paper below.
@article{ji2025emma2,
title={Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data},
author={Shaoxiong Ji and Zihao Li and Jaakko Paavola and Indraneil Paul and Hengyu Luo and Jörg Tiedemann},
year={2025},
journal={arXiv preprint 2506.00469},
url={https://arxiv.org/abs/2506.00469},
}
Check out the below paper for the precedent EMMA-500 model trained on Llama 2 (🤗MaLA-LM/emma-500-llama2-7b).
@article{ji2024emma500enhancingmassivelymultilingual,
title={{EMMA}-500: Enhancing Massively Multilingual Adaptation of Large Language Models},
author={Shaoxiong Ji and Zihao Li and Indraneil Paul and Jaakko Paavola and Peiqin Lin and Pinzhen Chen and Dayyán O'Brien and Hengyu Luo and Hinrich Schütze and Jörg Tiedemann and Barry Haddow},
year={2024},
journal={arXiv preprint 2409.17892},
url={https://arxiv.org/abs/2409.17892},
}