---
title: VenusFactory
app_file: app.py
sdk: gradio
sdk_version: 5.24.0
---

[](https://github.com/tyang816/VenusFactory/stargazers) [](https://github.com/tyang816/VenusFactory/network/members) [](https://github.com/tyang816/VenusFactory/issues) [](https://github.com/tyang816/VenusFactory/blob/main/LICENSE)
[](https://www.python.org/) [](https://venusfactory.readthedocs.io/) [](https://github.com/tyang816/VenusFactory/releases)
Recent News:
- Welcome to VenusFactory! This project is developed by [**Liang's Lab**](https://lianglab.sjtu.edu.cn/) at [**Shanghai Jiao Tong University**](https://www.sjtu.edu.cn/).
- [2025-03-26] Add [VenusPLM-300M](https://huggingface.co/AI4Protein/VenusPLM-300M) model, trained based on **VenusPod**, is a protein language model independently developed by Hong Liang's research group at Shanghai Jiao Tong University.
- [2025-03-17] Add [Venus-PETA, Venus-ProPrime, Venus-ProSST models](https://huggingface.co/AI4Protein), for more details, please refer to [Supported Models](#-supported-models)
- [2025-03-05] 🎉 Congratulations! 🎉
🚀 Our latest research achievement, **VenusMutHub**, has been officially accepted by [**Acta Pharmaceutica Sinica B**](https://www.sciencedirect.com/science/article/pii/S2211383525001650) and is now featured in a series of [**leaderboards**](https://lianglab.sjtu.edu.cn/muthub/)!
💡 In this study, we built **900+ high-quality benchmark** [**datasets**](https://huggingface.co/datasets/AI4Protein/VenusMutHub) covering **500+ protein functional properties**. VenusMutHub not only offers a new collection of small-sample datasets for **real-world protein mutation engineering**, but also fills the gap in **diversity** within existing benchmarks, laying a stronger foundation for AI-driven protein mutation effect prediction.
## ✏️ Table of Contents
- [Features](#-features)
- [Supported Models](#-supported-models)
- [Supported Training Approaches](#-supported-training-approaches)
- [Supported Datasets](#-supported-datasets)
- [Supported Metrics](#-supported-metrics)
- [Requirements](#-requirements)
- [Installation Guide](#-installation-guide)
- [Quick Start with Venus Web UI](#-quick-start-with-venus-web-ui)
- [Code-line Usage](#-code-line-usage)
- [Citation](#-citation)
- [Acknowledgement](#-acknowledgement)
## 📑 Features
- **Vaious protein langugae models**: Venus series, ESM series, ProtTrans series, Ankh series, etc
- **Comprehensive supervised datasets**: Localization, Fitness, Solubility, Stability, etc
- **Easy and quick data collector**: AlphaFold2 Database, RCSB, InterPro, Uniprot, etc
- **Experiment moitors**: Wandb, Local
- **Friendly interface**: Gradio UI
## 🤖 Supported Models
### Pre-training Protein Language Models
Venus Series Models (Published by Liang's Lab)
| Model | Size | Parameters | GPU Memory | Features | Template |
|-------|------|------------|------------|----------|----------|
| ProSST-20 | 20 | 110M | 4GB+ | Mutation | [AI4Protein/ProSST-20](https://huggingface.co/AI4Protein/ProSST-20) |
| ProSST-128 | 128 | 110M | 4GB+ | Mutation | [AI4Protein/ProSST-128](https://huggingface.co/AI4Protein/ProSST-128) |
| ProSST-512 | 512 | 110M | 4GB+ | Mutation | [AI4Protein/ProSST-512](https://huggingface.co/AI4Protein/ProSST-512) |
| ProSST-2048 | 2048 | 110M | 4GB+ | Mutation | [AI4Protein/ProSST-2048](https://huggingface.co/AI4Protein/ProSST-2048) |
| ProSST-4096 | 4096 | 110M | 4GB+ | Mutation | [AI4Protein/ProSST-4096](https://huggingface.co/AI4Protein/ProSST-4096) |
| ProPrime-690M | 690M | 690M | 16GB+ | OGT-prediction | [AI4Protein/Prime_690M](https://huggingface.co/AI4Protein/Prime_690M) |
| VenusPLM-300M | 300M | 300M | 12GB+ | Protein-language | [AI4Protein/VenusPLM-300M](https://huggingface.co/AI4Protein/VenusPLM-300M) |
> 💡 These models often excel in specific tasks or offer unique architectural benefits
Venus-PETA Models: Tokenization variants
#### BPE Tokenization Series
| Model | Vocab Size | Parameters | GPU Memory | Template |
|-------|------------|------------|------------|----------|
| PETA-base | base | 80M | 4GB+ | [AI4Protein/deep_base](https://huggingface.co/AI4Protein/deep_base) |
| PETA-bpe-50 | 50 | 80M | 4GB+ | [AI4Protein/deep_bpe_50](https://huggingface.co/AI4Protein/deep_bpe_50) |
| PETA-bpe-200 | 200 | 80M | 4GB+ | [AI4Protein/deep_bpe_200](https://huggingface.co/AI4Protein/deep_bpe_200) |
| PETA-bpe-400 | 400 | 80M | 4GB+ | [AI4Protein/deep_bpe_400](https://huggingface.co/AI4Protein/deep_bpe_400) |
| PETA-bpe-800 | 800 | 80M | 4GB+ | [AI4Protein/deep_bpe_800](https://huggingface.co/AI4Protein/deep_bpe_800) |
| PETA-bpe-1600 | 1600 | 80M | 4GB+ | [AI4Protein/deep_bpe_1600](https://huggingface.co/AI4Protein/deep_bpe_1600) |
| PETA-bpe-3200 | 3200 | 80M | 4GB+ | [AI4Protein/deep_bpe_3200](https://huggingface.co/AI4Protein/deep_bpe_3200) |
#### Unigram Tokenization Series
| Model | Vocab Size | Parameters | GPU Memory | Template |
|-------|------------|------------|------------|----------|
| PETA-unigram-50 | 50 | 80M | 4GB+ | [AI4Protein/deep_unigram_50](https://huggingface.co/AI4Protein/deep_unigram_50) |
| PETA-unigram-100 | 100 | 80M | 4GB+ | [AI4Protein/deep_unigram_100](https://huggingface.co/AI4Protein/deep_unigram_100) |
| PETA-unigram-200 | 200 | 80M | 4GB+ | [AI4Protein/deep_unigram_200](https://huggingface.co/AI4Protein/deep_unigram_200) |
| PETA-unigram-400 | 400 | 80M | 4GB+ | [AI4Protein/deep_unigram_400](https://huggingface.co/AI4Protein/deep_unigram_400) |
| PETA-unigram-800 | 800 | 80M | 4GB+ | [AI4Protein/deep_unigram_800](https://huggingface.co/AI4Protein/deep_unigram_800) |
| PETA-unigram-1600 | 1600 | 80M | 4GB+ | [AI4Protein/deep_unigram_1600](https://huggingface.co/AI4Protein/deep_unigram_1600) |
| PETA-unigram-3200 | 3200 | 80M | 4GB+ | [AI4Protein/deep_unigram_3200](https://huggingface.co/AI4Protein/deep_unigram_3200) |
> 💡 Different tokenization strategies may be better suited for specific tasks
ESM Series Models: Meta AI's protein language models
| Model | Size | Parameters | GPU Memory | Training Data | Template |
|-------|------|------------|------------|---------------|----------|
| ESM2-8M | 8M | 8M | 2GB+ | UR50/D | [facebook/esm2_t6_8M_UR50D](https://huggingface.co/facebook/esm2_t6_8M_UR50D) |
| ESM2-35M | 35M | 35M | 4GB+ | UR50/D | [facebook/esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) |
| ESM2-150M | 150M | 150M | 8GB+ | UR50/D | [facebook/esm2_t30_150M_UR50D](https://huggingface.co/facebook/esm2_t30_150M_UR50D) |
| ESM2-650M | 650M | 650M | 16GB+ | UR50/D | [facebook/esm2_t33_650M_UR50D](https://huggingface.co/facebook/esm2_t33_650M_UR50D) |
| ESM2-3B | 3B | 3B | 24GB+ | UR50/D | [facebook/esm2_t36_3B_UR50D](https://huggingface.co/facebook/esm2_t36_3B_UR50D) |
| ESM2-15B | 15B | 15B | 40GB+ | UR50/D | [facebook/esm2_t48_15B_UR50D](https://huggingface.co/facebook/esm2_t48_15B_UR50D) |
| ESM-1b | 650M | 650M | 16GB+ | UR50/S | [facebook/esm1b_t33_650M_UR50S](https://huggingface.co/facebook/esm1b_t33_650M_UR50S) |
| ESM-1v-1 | 650M | 650M | 16GB+ | UR90/S | [facebook/esm1v_t33_650M_UR90S_1](https://huggingface.co/facebook/esm1v_t33_650M_UR90S_1) |
| ESM-1v-2 | 650M | 650M | 16GB+ | UR90/S | [facebook/esm1v_t33_650M_UR90S_2](https://huggingface.co/facebook/esm1v_t33_650M_UR90S_2) |
| ESM-1v-3 | 650M | 650M | 16GB+ | UR90/S | [facebook/esm1v_t33_650M_UR90S_3](https://huggingface.co/facebook/esm1v_t33_650M_UR90S_3) |
| ESM-1v-4 | 650M | 650M | 16GB+ | UR90/S | [facebook/esm1v_t33_650M_UR90S_4](https://huggingface.co/facebook/esm1v_t33_650M_UR90S_4) |
| ESM-1v-5 | 650M | 650M | 16GB+ | UR90/S | [facebook/esm1v_t33_650M_UR90S_5](https://huggingface.co/facebook/esm1v_t33_650M_UR90S_5) |
> 💡 ESM2 models are the latest generation, offering better performance than ESM-1b/1v
BERT-based Models: Transformer encoder architecture
| Model | Size | Parameters | GPU Memory | Training Data | Template |
|-------|------|------------|------------|---------------|----------|
| ProtBert-Uniref100 | 420M | 420M | 12GB+ | UniRef100 | [Rostlab/prot_bert](https://huggingface.co/Rostlab/prot_bert) |
| ProtBert-BFD | 420M | 420M | 12GB+ | BFD100 | [Rostlab/prot_bert_bfd](https://huggingface.co/Rostlab/prot_bert_bfd) |
| IgBert | 420M | 420M | 12GB+ | Antibody | [Exscientia/IgBert](https://huggingface.co/Exscientia/IgBert) |
| IgBert-unpaired | 420M | 420M | 12GB+ | Antibody | [Exscientia/IgBert_unpaired](https://huggingface.co/Exscientia/IgBert_unpaired) |
> 💡 BFD-trained models generally show better performance on structure-related tasks
T5-based Models: Encoder-decoder architecture
| Model | Size | Parameters | GPU Memory | Training Data | Template |
|-------|------|------------|------------|---------------|----------|
| ProtT5-XL-UniRef50 | 3B | 3B | 24GB+ | UniRef50 | [Rostlab/prot_t5_xl_uniref50](https://huggingface.co/Rostlab/prot_t5_xl_uniref50) |
| ProtT5-XXL-UniRef50 | 11B | 11B | 40GB+ | UniRef50 | [Rostlab/prot_t5_xxl_uniref50](https://huggingface.co/Rostlab/prot_t5_xxl_uniref50) |
| ProtT5-XL-BFD | 3B | 3B | 24GB+ | BFD100 | [Rostlab/prot_t5_xl_bfd](https://huggingface.co/Rostlab/prot_t5_xl_bfd) |
| ProtT5-XXL-BFD | 11B | 11B | 40GB+ | BFD100 | [Rostlab/prot_t5_xxl_bfd](https://huggingface.co/Rostlab/prot_t5_xxl_bfd) |
| IgT5 | 3B | 3B | 24GB+ | Antibody | [Exscientia/IgT5](https://huggingface.co/Exscientia/IgT5) |
| IgT5-unpaired | 3B | 3B | 24GB+ | Antibody | [Exscientia/IgT5_unpaired](https://huggingface.co/Exscientia/IgT5_unpaired) |
| Ankh-base | 450M | 450M | 12GB+ | Encoder-decoder | [ElnaggarLab/ankh-base](https://huggingface.co/ElnaggarLab/ankh-base) |
| Ankh-large | 1.2B | 1.2B | 20GB+ | Encoder-decoder | [ElnaggarLab/ankh-large](https://huggingface.co/ElnaggarLab/ankh-large) |
> 💡 T5 models can be used for both encoding and generation tasks
### Model Selection Guide
How to choose the right model?
1. **Based on Hardware Constraints:**
- Limited GPU (<8GB): ESM2-8M, ESM2-35M, ProSST
- Medium GPU (8-16GB): ESM2-150M, ESM2-650M, ProtBert series
- High-end GPU (24GB+): ESM2-3B, ProtT5-XL, Ankh-large
- Multiple GPUs: ESM2-15B, ProtT5-XXL
2. **Based on Task Type:**
- Sequence classification: ESM2, ProtBert
- Structure prediction: ESM2, Ankh
- Generation tasks: ProtT5
- Antibody design: IgBert, IgT5
- Lightweight deployment: ProSST, PETA-base
3. **Based on Training Data:**
- General protein tasks: ESM2, ProtBert
- Structure-aware tasks: Ankh
- Antibody-specific: IgBert, IgT5
- Custom tokenization needs: PETA series
> 🔍 All models are available through the Hugging Face Hub and can be easily loaded using their templates.
## 🔬 Supported Training Approaches
Supported Training Approaches
| Approach | Full-tuning | Freeze-tuning | SES-Adapter | AdaLoRA | QLoRA | LoRA | DoRA | IA3 |
| ---------------------- | ----------- | ------------------ | ------------------ | ------------------ |----------- | ------------------ | -----------------| -----------------|
| Supervised Fine-Tuning | ✅ | ✅ | ✅ | ✅ |✅ | ✅ | ✅ | ✅ |
## 📚 Supported Datasets
Pre-training datasets
| dataset | data level | link |
|------------|------|------|
| CATH_V43_S40 | structures | [CATH_V43_S40](https://huggingface.co/datasets/tyang816/cath) |
| AGO_family | structures | [AGO_family](https://huggingface.co/datasets/tyang816/Ago_database_PDB) |
Zero-shot datasets
| dataset | task | link |
|------------|------|------|
| VenusMutHub | mutation effects prediction | [VenusMutHub](https://huggingface.co/datasets/AI4Protein/VenusMutHub) |
| ProteinGym | mutation effects prediction | [ProteinGym](https://proteingym.org/) |
Supervised fine-tuning datasets (amino acid sequences/ foldseek sequences/ ss8 sequences)
| dataset | task | data level | problem type | link |
|------------|------|----------|----------|------|
| DeepLocBinary | localization | protein-wise | single_label_classification | [DeepLocBinary_AlphaFold2](https://huggingface.co/datasets/tyang816/DeepLocBinary_AlphaFold2), [DeepLocBinary_ESMFold](https://huggingface.co/datasets/tyang816/DeepLocBinary_ESMFold) |
| DeepLocMulti | localization | protein-wise | multi_label_classification | [DeepLocMulti_AlphaFold2](https://huggingface.co/datasets/tyang816/DeepLocMulti_AlphaFold2), [DeepLocMulti_ESMFold](https://huggingface.co/datasets/tyang816/DeepLocMulti_ESMFold) |
| DeepLoc2Multi | localization | protein-wise | single_label_classification | [DeepLoc2Multi_AlphaFold2](https://huggingface.co/datasets/tyang816/DeepLoc2Multi_AlphaFold2), [DeepLoc2Multi_ESMFold](https://huggingface.co/datasets/tyang816/DeepLoc2Multi_ESMFold) |
| DeepSol | solubility | protein-wise | single_label_classification | [DeepSol_ESMFold](https://huggingface.co/datasets/tyang816/DeepSol_ESMFold) |
| DeepSoluE | solubility | protein-wise | single_label_classification | [DeepSoluE_ESMFold](https://huggingface.co/datasets/tyang816/DeepSoluE_ESMFold) |
| ProtSolM | solubility | protein-wise | single_label_classification | [ProtSolM_ESMFold](https://huggingface.co/datasets/tyang816/ProtSolM_ESMFold) |
| eSOL | solubility | protein-wise | regression | [eSOL_AlphaFold2](https://huggingface.co/datasets/tyang816/eSOL_AlphaFold2), [eSOL_ESMFold](https://huggingface.co/datasets/tyang816/eSOL_ESMFold) |
| DeepET_Topt | optimum temperature | protein-wise | regression | [DeepET_Topt_AlphaFold2](https://huggingface.co/datasets/tyang816/DeepET_Topt_AlphaFold2), [DeepET_Topt_ESMFold](https://huggingface.co/datasets/tyang816/DeepET_Topt_ESMFold) |
| EC | function | protein-wise | multi_label_classification | [EC_AlphaFold2](https://huggingface.co/datasets/tyang816/EC_AlphaFold2), [EC_ESMFold](https://huggingface.co/datasets/tyang816/EC_ESMFold) |
| GO_BP | function | protein-wise | multi_label_classification | [GO_BP_AlphaFold2](https://huggingface.co/datasets/tyang816/GO_BP_AlphaFold2), [GO_BP_ESMFold](https://huggingface.co/datasets/tyang816/GO_BP_ESMFold) |
| GO_CC | function | protein-wise | multi_label_classification | [GO_CC_AlphaFold2](https://huggingface.co/datasets/tyang816/GO_CC_AlphaFold2), [GO_CC_ESMFold](https://huggingface.co/datasets/tyang816/GO_CC_ESMFold) |
| GO_MF | function | protein-wise | multi_label_classification | [GO_MF_AlphaFold2](https://huggingface.co/datasets/tyang816/GO_MF_AlphaFold2), [GO_MF_ESMFold](https://huggingface.co/datasets/tyang816/GO_MF_ESMFold) |
| MetalIonBinding | binding | protein-wise | single_label_classification | [MetalIonBinding_AlphaFold2](https://huggingface.co/datasets/tyang816/MetalIonBinding_AlphaFold2), [MetalIonBinding_ESMFold](https://huggingface.co/datasets/tyang816/MetalIonBinding_ESMFold) |
| Thermostability | stability | protein-wise | regression | [Thermostability_AlphaFold2](https://huggingface.co/datasets/tyang816/Thermostability_AlphaFold2), [Thermostability_ESMFold](https://huggingface.co/datasets/tyang816/Thermostability_ESMFold) |
> ✨ Only structural sequences are different for the same dataset, for example, ``DeepLocBinary_ESMFold`` and ``DeepLocBinary_AlphaFold2`` share the same amino acid sequences, this means if you only want to use the ``aa_seqs``, both are ok!
Supervised fine-tuning datasets (amino acid sequences)
| dataset | task | data level | problem type | link |
|------------|------|----------|----------|------|
| Demo_Solubility | solubility | protein-wise | single_label_classification | [Demo_Solubility](https://huggingface.co/datasets/tyang816/Demo_Solubility) |
| DeepLocBinary | localization | protein-wise | single_label_classification | [DeepLocBinary](https://huggingface.co/datasets/tyang816/DeepLocBinary) |
| DeepLocMulti | localization | protein-wise | multi_label_classification | [DeepLocMulti](https://huggingface.co/datasets/tyang816/DeepLocMulti) |
| DeepLoc2Multi | localization | protein-wise | single_label_classification | [DeepLoc2Multi](https://huggingface.co/datasets/tyang816/DeepLoc2Multi) |
| DeepSol | solubility | protein-wise | single_label_classification | [DeepSol](https://huggingface.co/datasets/tyang816/DeepSol) |
| DeepSoluE | solubility | protein-wise | single_label_classification | [DeepSoluE](https://huggingface.co/datasets/tyang816/DeepSoluE) |
| ProtSolM | solubility | protein-wise | single_label_classification | [ProtSolM](https://huggingface.co/datasets/tyang816/ProtSolM) |
| eSOL | solubility | protein-wise | regression | [eSOL](https://huggingface.co/datasets/tyang816/eSOL) |
| DeepET_Topt | optimum temperature | protein-wise | regression | [DeepET_Topt](https://huggingface.co/datasets/tyang816/DeepET_Topt) |
| EC | function | protein-wise | multi_label_classification | [EC](https://huggingface.co/datasets/tyang816/EC) |
| GO_BP | function | protein-wise | multi_label_classification | [GO_BP](https://huggingface.co/datasets/tyang816/GO_BP) |
| GO_CC | function | protein-wise | multi_label_classification | [GO_CC](https://huggingface.co/datasets/tyang816/GO_CC) |
| GO_MF | function | protein-wise | multi_label_classification | [GO_MF](https://huggingface.co/datasets/tyang816/GO_MF) |
| MetalIonBinding | binding | protein-wise | single_label_classification | [MetalIonBinding](https://huggingface.co/datasets/tyang816/MetalIonBinding) |
| Thermostability | stability | protein-wise | regression | [Thermostability](https://huggingface.co/datasets/tyang816/Thermostability) |
| PaCRISPR | CRISPR | protein-wise | single_label_classification | [PaCRISPR](https://huggingface.co/datasets/tyang816/PaCRISPR) |
| PETA_CHS_Sol | solubility | protein-wise | single_label_classification | [PETA_CHS_Sol](https://huggingface.co/datasets/tyang816/PETA_CHS_Sol) |
| PETA_LGK_Sol | solubility | protein-wise | single_label_classification | [PETA_LGK_Sol](https://huggingface.co/datasets/tyang816/PETA_LGK_Sol) |
| PETA_TEM_Sol | solubility | protein-wise | single_label_classification | [PETA_TEM_Sol](https://huggingface.co/datasets/tyang816/PETA_TEM_Sol) |
| SortingSignal | sorting signal | protein-wise | single_label_classification | [SortingSignal](https://huggingface.co/datasets/tyang816/SortingSignal) |
| FLIP_AAV | mutation | protein-site | regression |
| FLIP_AAV_one-vs-rest | mutation | protein-site | single_label_classification | [FLIP_AAV_one-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_AAV_one-vs-rest) |
| FLIP_AAV_two-vs-rest | mutation | protein-site | single_label_classification | [FLIP_AAV_two-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_AAV_two-vs-rest) |
| FLIP_AAV_mut-des | mutation | protein-site | single_label_classification | [FLIP_AAV_mut-des](https://huggingface.co/datasets/tyang816/FLIP_AAV_mut-des) |
| FLIP_AAV_des-mut | mutation | protein-site | single_label_classification | [FLIP_AAV_des-mut](https://huggingface.co/datasets/tyang816/FLIP_AAV_des-mut) |
| FLIP_AAV_seven-vs-rest | mutation | protein-site | single_label_classification | [FLIP_AAV_seven-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_AAV_seven-vs-rest) |
| FLIP_AAV_low-vs-high | mutation | protein-site | single_label_classification | [FLIP_AAV_low-vs-high](https://huggingface.co/datasets/tyang816/FLIP_AAV_low-vs-high) |
| FLIP_AAV_sampled | mutation | protein-site | single_label_classification | [FLIP_AAV_sampled](https://huggingface.co/datasets/tyang816/FLIP_AAV_sampled) |
| FLIP_GB1 | mutation | protein-site | regression |
| FLIP_GB1_one-vs-rest | mutation | protein-site | single_label_classification | [FLIP_GB1_one-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_GB1_one-vs-rest) |
| FLIP_GB1_two-vs-rest | mutation | protein-site | single_label_classification | [FLIP_GB1_two-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_GB1_two-vs-rest) |
| FLIP_GB1_three-vs-rest | mutation | protein-site | single_label_classification | [FLIP_GB1_three-vs-rest](https://huggingface.co/datasets/tyang816/FLIP_GB1_three-vs-rest) |
| FLIP_GB1_low-vs-high | mutation | protein-site | single_label_classification | [FLIP_GB1_low-vs-high](https://huggingface.co/datasets/tyang816/FLIP_GB1_low-vs-high) |
| FLIP_GB1_sampled | mutation | protein-site | single_label_classification | [FLIP_GB1_sampled](https://huggingface.co/datasets/tyang816/FLIP_GB1_sampled) |
| TAPE_Fluorescence | fluorescence | protein-site | regression | [TAPE_Fluorescence](https://huggingface.co/datasets/tyang816/TAPE_Fluorescence) |
| TAPE_Stability | stability | protein-site | regression | [TAPE_Stability](https://huggingface.co/datasets/tyang816/TAPE_Stability) |
Supported Metrics
| Name | Torchmetrics | Problem Type |
| ------------- | ---------------- | ------------------------------------------------------- |
| accuracy | Accuracy | single_label_classification/ multi_label_classification |
| recall | Recall | single_label_classification/ multi_label_classification |
| precision | Precision | single_label_classification/ multi_label_classification |
| f1 | F1Score | single_label_classification/ multi_label_classification |
| mcc | MatthewsCorrCoef | single_label_classification/ multi_label_classification |
| auc | AUROC | single_label_classification/ multi_label_classification |
| f1_max | F1ScoreMax | multi_label_classification |
| spearman_corr | SpearmanCorrCoef | regression |
| mse | MeanSquaredError | regression |
## ✈️ Requirements
### Hardware Requirements
- Recommended: NVIDIA RTX 3090 (24GB) or better
- Actual requirements depend on your chosen protein language model
### Software Requirements
- [Anaconda3](https://www.anaconda.com/download) or [Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/)
- Python 3.10
## 📦 Installation Guide
Git start with macOS
## To achieve the best performance and experience, we recommend using Mac devices with M-series chips (such as M1, M2, M3, etc.).
## 1️⃣ Clone the repository
First, get the VenusFactory code:
```bash
git clone https://github.com/tyang816/VenusFactory.git
cd VenusFactory
```
## 2️⃣ Create a Conda environment
Ensure you have Anaconda or Miniconda installed. Then, create a new environment named `venus` with Python 3.10:
```bash
conda create -n venus python=3.10
conda activate venus
```
## 3️⃣ Install Pytorch and PyG dependencies
```bash
# Install PyTorch
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
# Install PyG dependencies
pip install torch_scatter torch-sparse torch-geometric -f https://data.pyg.org/whl/torch-2.2.0+cpu.html
```
## 4️⃣ Install remaining dependencies
Install the remaining dependencies using `requirements_for_macOS.txt`:
```bash
pip install -r requirements_for_macOS.txt
```
Git start with Windows or Linux on CUDA 12.x
## We recommend using CUDA 12.2
## 1️⃣ Clone the repository
First, get the VenusFactory code:
```bash
git clone https://github.com/tyang816/VenusFactory.git
cd VenusFactory
```
## 2️⃣ Create a Conda environment
Ensure you have Anaconda or Miniconda installed. Then, create a new environment named `venus` with Python 3.10:
```bash
conda create -n venus python=3.10
conda activate venus
```
## 3️⃣ Install Pytorch and PyG dependencies
```bash
# Install PyTorch
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu121
# Install PyG dependencies
pip install torch_geometric==2.6.1 -f https://pytorch-geometric.com/whl/torch-2.5.1+cu121.html
pip install --no-index torch_scatter==2.1.2 -f https://pytorch-geometric.com/whl/torch-2.5.1+cu121.html
```
## 4️⃣ Install remaining dependencies
Install the remaining dependencies using `requirements.txt`:
```bash
pip install -r requirements.txt
```
Git start with Windows or Linux on CUDA 11.x
## We recommend using CUDA 11.8 or later versions, as they support higher versions of PyTorch, providing a better experience.
## 1️⃣ Clone the repository
First, get the VenusFactory code:
```bash
git clone https://github.com/tyang816/VenusFactory.git
cd VenusFactory
```
## 2️⃣ Create a Conda environment
Ensure you have Anaconda or Miniconda installed. Then, create a new environment named `venus` with Python 3.10:
```bash
conda create -n venus python=3.10
conda activate venus
```
## 3️⃣ Install Pytorch and PyG dependencies
```bash
# Install PyTorch
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu118
# Install PyG dependencies
pip install torch_geometric==2.6.1 -f https://pytorch-geometric.com/whl/torch-2.5.1+cu118.html
pip install --no-index torch_scatter==2.1.2 -f https://pytorch-geometric.com/whl/torch-2.5.1+cu118.html
```
## 4️⃣ Install remaining dependencies
Install the remaining dependencies using `requirements.txt`:
```bash
pip install -r requirements.txt
```
Git start with Windows or Linux on CPU
## 1️⃣ Clone the repository
First, get the VenusFactory code:
```bash
git clone https://github.com/tyang816/VenusFactory.git
cd VenusFactory
```
## 2️⃣ Create a Conda environment
Ensure you have Anaconda or Miniconda installed. Then, create a new environment named `venus` with Python 3.10:
```bash
conda create -n venus python=3.10
conda activate venus
```
## 3️⃣ Install Pytorch and PyG dependencies
```bash
# Install PyTorch
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cpu
# Install PyG dependencies
pip install torch_geometric==2.6.1 -f https://pytorch-geometric.com/whl/torch-2.5.1+cpu.html
pip install --no-index torch_scatter==2.1.2 -f https://pytorch-geometric.com/whl/torch-2.5.1+cpu.html
```
## 4️⃣ Install remaining dependencies
Install the remaining dependencies using `requirements.txt`:
```bash
pip install -r requirements.txt
```
1. Training Tab: Train your own protein language model
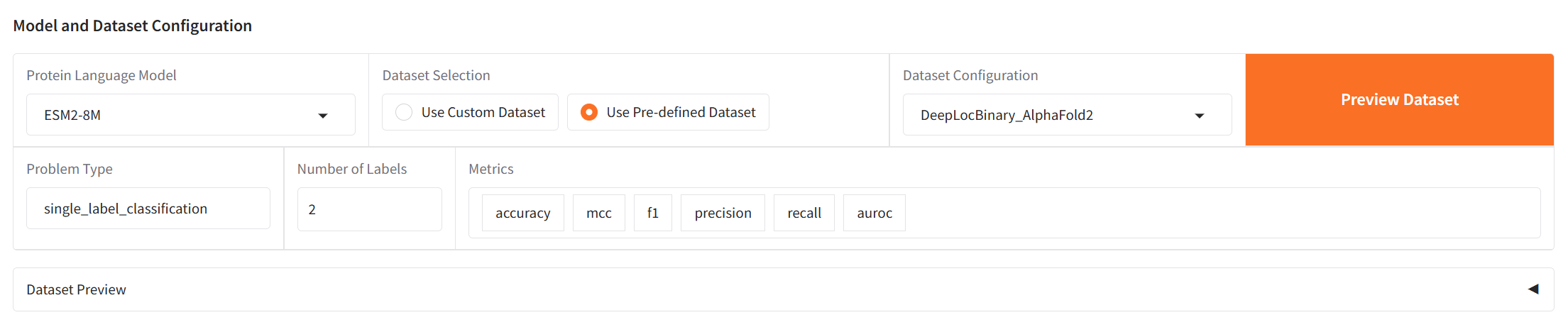
Select a protein language model from the dropdown menu. Upload your dataset or select from available datasets and choose metrics appropriate for your problem type.

Choose a training method (Freeze, SES-Adapter, LoRA, QLoRA etc.) and configure training parameters (batch size, learning rate, etc.).




Click "Start Training" and monitor progress in real-time.
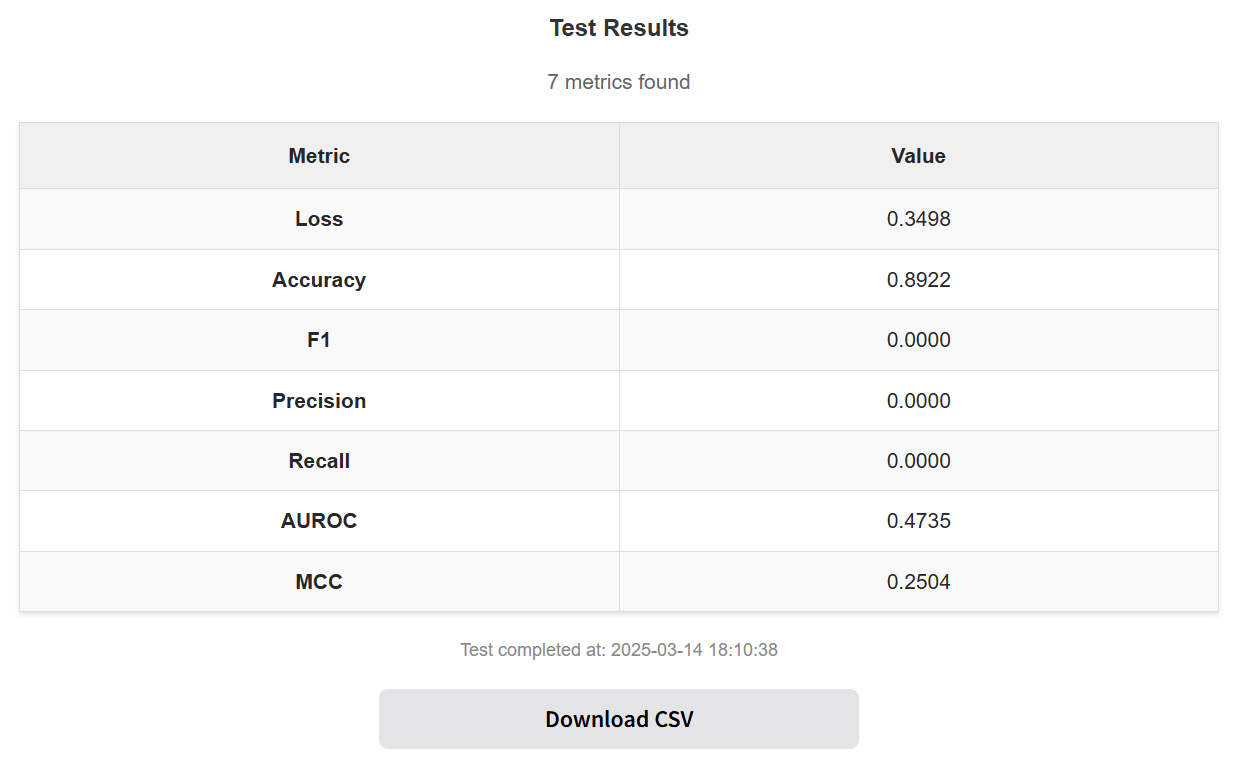
Click "Download CSV" to download the test metrics results.
2. Evaluation Tab: Evaluate your trained model within a benchmark

Load your trained model by specifying the model path. Select the same protein language model and model configs used during training. Select a test dataset and configure batch size. Choose evaluation metrics appropriate for your problem type. Finally, click "Start Evaluation" to view performance metrics.
3. Prediction Tab: Use your trained model to predict samples

Load your trained model by specifying the model path. Select the same protein language model and model configs used during training.
For single sequence: Enter a protein sequence in the text box.
For batch prediction: Upload a CSV file with sequences.

Click "Predict" to generate and view results.
4. Download Tab: Collect data from different sources with high efficiency
- **AlphaFold2 Structures**: Enter UniProt IDs to download protein structures
- **UniProt**: Search for protein information using keywords or IDs
- **InterPro**: Retrieve protein family and domain information
- **RCSB PDB**: Download experimental protein structures
5. Manual Tab: Detailed documentation and guides
Select a language (English/Chinese).
Navigate through the documentation using the table of contents and find step-by-step guides.
## 🧬 Code-line Usage
For users who prefer command-line interface, we provide comprehensive script solutions for different scenarios.
Training Methods: Various fine-tuning approaches for different needs
### Full Model Fine-tuning
```bash
# Freeze-tuning: Train only specific layers while freezing others
bash ./script/train/train_plm_vanilla.sh
```
### Parameter-Efficient Fine-tuning (PEFT)
```bash
# SES-Adapter: Selective and Efficient adapter fine-tuning
bash ./script/train/train_plm_ses-adapter.sh
# AdaLoRA: Adaptive Low-Rank Adaptation
bash ./script/train/train_plm_adalora.sh
# QLoRA: Quantized Low-Rank Adaptation
bash ./script/train/train_plm_qlora.sh
# LoRA: Low-Rank Adaptation
bash ./script/train/train_plm_lora.sh
# DoRA: Double Low-Rank Adaptation
bash ./script/train/train_plm_dora.sh
# IA3: Infused Adapter by Inhibiting and Amplifying Inner Activations
bash ./script/train/train_plm_ia3.sh
```
#### Training Method Comparison
| Method | Memory Usage | Training Speed | Performance |
|--------|--------------|----------------|-------------|
| Freeze | Low | Fast | Good |
| SES-Adapter | Medium | Medium | Better |
| AdaLoRA | Low | Medium | Better |
| QLoRA | Very Low | Slower | Good |
| LoRA | Low | Fast | Good |
| DoRA | Low | Medium | Better |
| IA3 | Very Low | Fast | Good |
Model Evaluation: Comprehensive evaluation tools
### Basic Evaluation
```bash
# Evaluate model performance on test sets
bash ./script/eval/eval.sh
```
### Available Metrics
- Classification: accuracy, precision, recall, F1, MCC, AUC
- Regression: MSE, Spearman correlation
- Multi-label: F1-max
### Visualization Tools
- Training curves
- Confusion matrices
- ROC curves
- Performance comparison plots
Structure Sequence Tools: Process protein structure information
### ESM Structure Sequence
```bash
# Generate structure sequences using ESM-3
bash ./script/get_get_structure_seq/get_esm3_structure_seq.sh
```
### Secondary Structure
```bash
# Predict protein secondary structure
bash ./script/get_get_structure_seq/get_secondary_structure_seq.sh
```
Features:
- Support for multiple sequence formats
- Batch processing capability
- Integration with popular structure prediction tools
Data Collection Tools: Multi-source protein data acquisition
### Format Conversion
```bash
# Convert CIF format to PDB
bash ./crawler/convert/maxit.sh
```
### Metadata Collection
```bash
# Download metadata from RCSB PDB
bash ./crawler/metadata/download_rcsb.sh
```
### Sequence Data
```bash
# Download protein sequences from UniProt
bash ./crawler/sequence/download_uniprot_seq.sh
```
### Structure Data
```bash
# Download from AlphaFold2 Database
bash ./crawler/structure/download_alphafold.sh
# Download from RCSB PDB
bash ./crawler/structure/download_rcsb.sh
```
Features:
- Automated batch downloading
- Resume interrupted downloads
- Data integrity verification
- Multiple source support
- Customizable search criteria
#### Supported Databases
| Database | Data Type | Access Method | Rate Limit |
|----------|-----------|---------------|------------|
| AlphaFold2 | Structures | REST API | Yes |
| RCSB PDB | Structures | FTP/HTTP | No |
| UniProt | Sequences | REST API | Yes |
| InterPro | Domains | REST API | Yes |
Usage Examples: Common scenarios and solutions
### Training Example
```bash
# Train a protein solubility predictor using ESM2
bash ./script/train/train_plm_lora.sh \
--model "facebook/esm2_t33_650M_UR50D" \
--dataset "DeepSol" \
--batch_size 32 \
--learning_rate 1e-4
```
### Evaluation Example
```bash
# Evaluate the trained model
bash ./script/eval/eval.sh \
--model_path "path/to/your/model" \
--test_dataset "DeepSol_test"
```
### Data Collection Example
```bash
# Download structures for a list of UniProt IDs
bash ./crawler/structure/download_alphafold.sh \
--input uniprot_ids.txt \
--output ./structures
```
> 💡 All scripts support additional command-line arguments for customization. Use `--help` with any script to see available options.
## 🙌 Citation
Please cite our work if you have used our code or data.
```bibtex
@article{tan2025venusfactory,
title={VenusFactory: A Unified Platform for Protein Engineering Data Retrieval and Language Model Fine-Tuning},
author={Tan, Yang and Liu, Chen and Gao, Jingyuan and Wu, Banghao and Li, Mingchen and Wang, Ruilin and Zhang, Lingrong and Yu, Huiqun and Fan, Guisheng and Hong, Liang and Zhou, Bingxin},
journal={arXiv preprint arXiv:2503.15438},
year={2025}
}
```
## 🎊 Acknowledgement
Thanks the support of [Liang's Lab](https://ins.sjtu.edu.cn/people/lhong/index.html).