
File size: 16,097 Bytes
baf42ee fef0fdd 58ecc1d baf42ee fef0fdd bfbe847 baf42ee bfbe847 fef0fdd bfbe847 fef0fdd bfbe847 baf42ee bfbe847 fef0fdd 3b25a60 fef0fdd 3b25a60 fef0fdd 0d8f539 fef0fdd 2edb097 fef0fdd 2edb097 fef0fdd 2edb097 8eadfcf bfbe847 baf42ee bfbe847 baf42ee fef0fdd bfbe847 baf42ee fef0fdd bfbe847 baf42ee bfbe847 fef0fdd bfbe847 baf42ee bfbe847 fef0fdd baf42ee fef0fdd baf42ee bfbe847 baf42ee bfbe847 baf42ee bfbe847 baf42ee 66f3676 baf42ee 66f3676 bfbe847 baf42ee 66f3676 bfbe847 66f3676 bfbe847 66f3676 bfbe847 66f3676 bfbe847 baf42ee bfbe847 baf42ee bfbe847 baf42ee 6fa807d baf42ee fef0fdd baf42ee fef0fdd bfbe847 baf42ee fef0fdd baf42ee fef0fdd baf42ee bfbe847 baf42ee bfbe847 baf42ee fef0fdd baf42ee fef0fdd baf42ee bfbe847 fef0fdd baf42ee fef0fdd baf42ee fef0fdd baf42ee fef0fdd b1102c3 baf42ee fef0fdd |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 |
---
license: apache-2.0
language:
- multilingual
- en
- fr
- de
- es
- pt
base_model:
- ibm-granite/granite-3.3-2b-instruct
library_name: transformers
---
# Granite-speech-3.3-2b (revision 3.3.2)
**Model Summary:**
Granite-speech-3.3-2b is a compact and efficient speech-language model, specifically designed for automatic speech recognition (ASR) and automatic speech translation (AST). Granite-speech-3.3-2b uses a two-pass design, unlike integrated models that combine speech and language into a single pass. Initial calls to granite-speech-3.3-2b will transcribe audio files into text. To process the transcribed text using the underlying Granite language model, users must make a second call as each step must be explicitly initiated.
The model was trained on a collection of public corpora comprising diverse datasets for ASR and AST as well as synthetic datasets tailored to support the speech translation task. Granite-speech-3.3-2b was trained by modality aligning granite-3.3-2b-instruct (https://huggingface.co/ibm-granite/granite-3.3-2b-instruct) to speech on publicly available open source corpora containing audio inputs and text targets. Compared to the initial release, revision 3.3.2
* supports multilingual speech inputs in English, French, German, Spanish and Portuguese,
* provides transcription accuracy improvements for English ASR by using a deeper acoustic encoder and additional training data.
**Evaluations:**
We evaluated granite-speech-3.3-2b revision 3.3.2 alongside granite-speech-3.3-8b (https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and other speech-language models in the less than 8b parameter range as well as dedicated ASR and AST systems on standard benchmarks. The evaluation spanned multiple public benchmarks, with particular emphasis on English ASR tasks while also including multilingual ASR and AST for X-En and En-X translations.
<br>

<br>

<br>

<br>

<br>
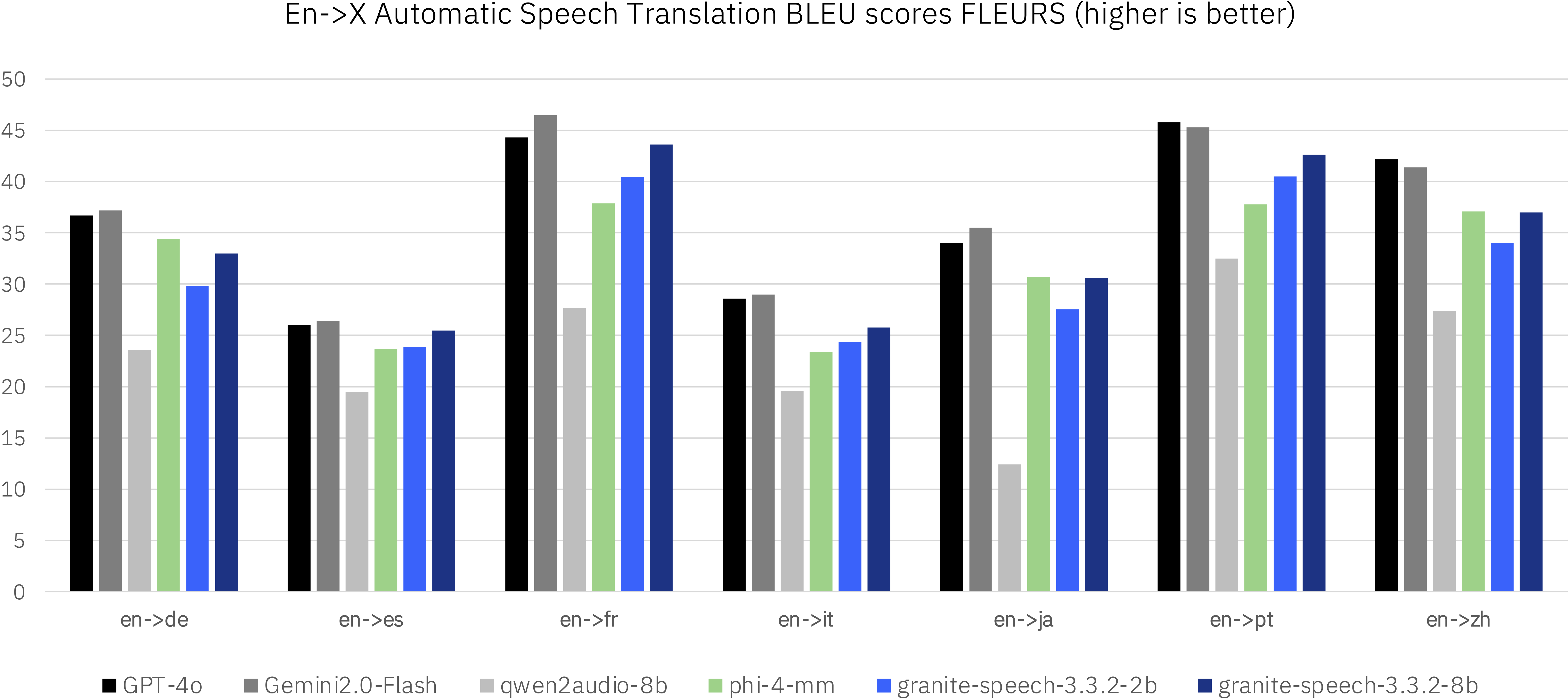
<br>
**Release Date**: June 19, 2025
**License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, French, German, Spanish, Portuguese
**Intended Use:**
The model is intended to be used in enterprise applications that involve processing of speech inputs. In particular, the model is well-suited for English, French, German, Spanish and Portuguese speech-to-text and speech translations to and from English for the same languages plus English-to-Japanese and English-to-Mandarin. The model can also be used for tasks that involve text-only input since it calls the underlying granite-3.3-2b-instruct when the user specifies a prompt that does not contain audio.
## Generation:
Granite Speech model is supported natively in `transformers` from the `main` branch. Below is a simple example of how to use the `granite-speech-3.3-2b` revision 3.3.2 model.
### Usage with `transformers`
First, make sure to install a recent version of transformers:
```shell
pip install transformers>=4.52.4 torchaudio peft soundfile
```
Then run the code:
```python
import torch
import torchaudio
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
from huggingface_hub import hf_hub_download
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "ibm-granite/granite-speech-3.3-2b"
processor = AutoProcessor.from_pretrained(model_name)
tokenizer = processor.tokenizer
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name, device_map=device, torch_dtype=torch.bfloat16
)
# load audio
audio_path = hf_hub_download(repo_id=model_name, filename="10226_10111_000000.wav")
wav, sr = torchaudio.load(audio_path, normalize=True)
assert wav.shape[0] == 1 and sr == 16000 # mono, 16khz
# create text prompt
system_prompt = "Knowledge Cutoff Date: April 2024.\nToday's Date: April 9, 2025.\nYou are Granite, developed by IBM. You are a helpful AI assistant"
user_prompt = "<|audio|>can you transcribe the speech into a written format?"
chat = [
dict(role="system", content=system_prompt),
dict(role="user", content=user_prompt),
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# run the processor+model
model_inputs = processor(prompt, wav, device=device, return_tensors="pt").to(device)
model_outputs = model.generate(**model_inputs, max_new_tokens=200, do_sample=False, num_beams=1)
# Transformers includes the input IDs in the response.
num_input_tokens = model_inputs["input_ids"].shape[-1]
new_tokens = torch.unsqueeze(model_outputs[0, num_input_tokens:], dim=0)
output_text = tokenizer.batch_decode(
new_tokens, add_special_tokens=False, skip_special_tokens=True
)
print(f"STT output = {output_text[0].upper()}")
```
### Usage with `vLLM`
First, make sure to install the latest version of vLLM:
```shell
pip install vllm --upgrade
```
* Code for offline mode:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.assets.audio import AudioAsset
from vllm.lora.request import LoRARequest
model_id = "ibm-granite/granite-speech-3.3-2b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_prompt(question: str, has_audio: bool):
"""Build the input prompt to send to vLLM."""
if has_audio:
question = f"<|audio|>{question}"
chat = [
{
"role": "user",
"content": question
}
]
return tokenizer.apply_chat_template(chat, tokenize=False)
# NOTE - you may see warnings about multimodal lora layers being ignored;
# this is okay as the lora in this model is only applied to the LLM.
model = LLM(
model=model_id,
enable_lora=True,
max_lora_rank=64,
max_model_len=2048, # This may be needed for lower resource devices.
limit_mm_per_prompt={"audio": 1},
)
### 1. Example with Audio [make sure to use the lora]
question = "can you transcribe the speech into a written format?"
prompt_with_audio = get_prompt(
question=question,
has_audio=True,
)
audio = AudioAsset("mary_had_lamb").audio_and_sample_rate
inputs = {
"prompt": prompt_with_audio,
"multi_modal_data": {
"audio": audio,
}
}
outputs = model.generate(
inputs,
sampling_params=SamplingParams(
temperature=0.2,
max_tokens=64,
),
lora_request=[LoRARequest("speech", 1, model_id)]
)
print(f"Audio Example - Question: {question}")
print(f"Generated text: {outputs[0].outputs[0].text}")
### 2. Example without Audio [do NOT use the lora]
question = "What is the capital of Brazil?"
prompt = get_prompt(
question=question,
has_audio=False,
)
outputs = model.generate(
{"prompt": prompt},
sampling_params=SamplingParams(
temperature=0.2,
max_tokens=12,
),
)
print(f"Text Only Example - Question: {question}")
print(f"Generated text: {outputs[0].outputs[0].text}")
```
* Code for online mode:
```python
"""
Launch the vLLM server with the following command:
vllm serve ibm-granite/granite-speech-3.3-2b \
--api-key token-abc123 \
--max-model-len 2048 \
--enable-lora \
--lora-modules speech=ibm-granite/granite-speech-3.3-2b \
--max-lora-rank 64
"""
import base64
import requests
from openai import OpenAI
from vllm.assets.audio import AudioAsset
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "token-abc123"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
base_model_name = "ibm-granite/granite-speech-3.3-2b"
lora_model_name = "speech"
# Any format supported by librosa is supported
audio_url = AudioAsset("mary_had_lamb").url
# Use base64 encoded audio in the payload
def encode_audio_base64_from_url(audio_url: str) -> str:
"""Encode an audio retrieved from a remote url to base64 format."""
with requests.get(audio_url) as response:
response.raise_for_status()
result = base64.b64encode(response.content).decode('utf-8')
return result
audio_base64 = encode_audio_base64_from_url(audio_url=audio_url)
### 1. Example with Audio
# NOTE: we pass the name of the lora model (`speech`) here because we have audio.
question = "can you transcribe the speech into a written format?"
chat_completion_with_audio = client.chat.completions.create(
messages=[{
"role": "user",
"content": [
{
"type": "text",
"text": question
},
{
"type": "audio_url",
"audio_url": {
# Any format supported by librosa is supported
"url": f"data:audio/ogg;base64,{audio_base64}"
},
},
],
}],
temperature=0.2,
max_tokens=64,
model=lora_model_name,
)
print(f"Audio Example - Question: {question}")
print(f"Generated text: {chat_completion_with_audio.choices[0].message.content}")
### 2. Example without Audio
# NOTE: we pass the name of the base model here because we do not have audio.
question = "What is the capital of Brazil?"
chat_completion_with_audio = client.chat.completions.create(
messages=[{
"role": "user",
"content": [
{
"type": "text",
"text": question
},
],
}],
temperature=0.2,
max_tokens=12,
model=base_model_name,
)
print(f"Text Only Example - Question: {question}")
print(f"Generated text: {chat_completion_with_audio.choices[0].message.content}")
```
**Model Architecture:**
The architecture of granite-speech-3.3-2b revision 3.3.2 consists of the following components:
(1) Speech encoder: 16 conformer blocks trained with Connectionist Temporal Classification (CTC) on character-level targets on the subset containing
only ASR corpora (see configuration below). In addition, our CTC encoder uses block-attention with 4-seconds audio blocks and self-conditioned CTC
from the middle layer.
| Configuration parameter | Value |
|-----------------|----------------------|
| Input dimension | 160 (80 logmels x 2) |
| Nb. of layers | 16 |
| Hidden dimension | 1024 |
| Nb. of attention heads | 8 |
| Attention head size | 128 |
| Convolution kernel size | 15 |
| Output dimension | 256 |
(2) Speech projector and temporal downsampler (speech-text modality adapter): we use a 2-layer window query transformer (q-former) operating on
blocks of 15 1024-dimensional acoustic embeddings coming out of the last conformer block of the speech encoder that get downsampled by a factor of 5
using 3 trainable queries per block and per layer. The total temporal downsampling factor is 10 (2x from the encoder and 5x from the projector)
resulting in a 10Hz acoustic embeddings rate for the LLM. The encoder, projector and LoRA adapters were fine-tuned/trained jointly on all the
corpora mentioned under **Training Data**.
(3) Large language model: granite-3.3-2b-instruct with 128k context length (https://huggingface.co/ibm-granite/granite-3.3-2b-instruct).
(4) LoRA adapters: rank=64 applied to the query, value projection matrices
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets (2) Synthetic data created from publicly
available datasets specifically targeting the speech translation task. A detailed description of the training datasets can be found in the table
below:
| Name | Task | Nb. hours | Source |
|-----------|--------------|----------------|--------------|
| CommonVoice-17 En,De,Es,Fr,Pt | ASR | 5600 | https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0 |
| MLS En,De,Es,Fr,Pt | ASR | 48000 | https://huggingface.co/datasets/facebook/multilingual_librispeech |
| Librispeech English | ASR | 1000 | https://huggingface.co/datasets/openslr/librispeech_asr |
| VoxPopuli En,De,Fr,Es | ASR | 1100 | https://huggingface.co/datasets/facebook/voxpopuli |
| AMI English | ASR | 100 | https://huggingface.co/datasets/edinburghcstr/ami |
| YODAS English | ASR | 10000 | https://huggingface.co/datasets/espnet/yodas |
| Earnings-22 English | ASR | 120 | https://huggingface.co/datasets/distil-whisper/earnings22 |
| Switchboard English | ASR | 260 | https://catalog.ldc.upenn.edu/LDC97S62 |
| CallHome English | ASR | 18 | https://catalog.ldc.upenn.edu/LDC97T14 |
| Fisher English | ASR | 2000 | https://catalog.ldc.upenn.edu/LDC2004S13 |
| Voicemail part I English | ASR | 40 | https://catalog.ldc.upenn.edu/LDC98S77 |
| Voicemail part II English | ASR | 40 | https://catalog.ldc.upenn.edu/LDC2002S35 |
| CommonVoice-17 De,Es,Fr,Pt->En | AST | 3000 | Translations with Granite-3 and Phi-4 |
| CommonVoice-17 En->De,Es,Fr,It,Ja,Pt,Zh | AST | 18000 | Translations with Phi-4 and MADLAD |
**Infrastructure:**
We train Granite Speech using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable
and efficient infrastructure for training our models over thousands of GPUs. The training of this particular model was completed in 13 days on 32
H100 GPUs.
**Ethical Considerations and Limitations:**
The use of Large Speech and Language Models can trigger certain risks and ethical considerations. Although our alignment processes include safety considerations, the model may in some cases produce inaccurate, biased, offensive or unwanted responses to user prompts. Additionally, whether smaller models may exhibit increased susceptibility to hallucination in generation scenarios due to their reduced sizes, which could limit their ability to generate coherent and contextually accurate responses, remains uncertain. This aspect is currently an active area of research, and we anticipate more rigorous exploration, comprehension, and mitigations in this domain.
IBM recommends using this model for automatic speech recognition and translation tasks. The model's modular design improves safety by limiting how audio inputs can influence the system. If an unfamiliar or malformed prompt is received, the model simply echoes it with its transcription. This minimizes the risk of adversarial inputs, unlike integrated models that directly interpret audio and may be more exposed to such attacks. Note that more general speech tasks may pose higher inherent risks of triggering unwanted outputs.
To enhance safety, we recommend using granite-speech-3.3-2b alongside Granite Guardian. Granite Guardian is a fine-tuned instruct model designed to detect and flag risks in prompts and responses across key dimensions outlined in the IBM AI Risk Atlas.
**Resources**
- 📄 Read the full technical report: https://arxiv.org/abs/2505.08699 (covers initial release only)
- 🔧 Notebooks: [Finetune on custom data](https://github.com/ibm-granite/granite-speech-models/blob/main/notebooks/fine_tuning_granite_speech.ipynb), [two-pass spoken question answering](https://github.com/ibm-granite/granite-speech-models/blob/main/notebooks/two_pass_spoken_qa.ipynb)
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 🚀 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources |